

Журнал вычислительной математики и математической физики, 2019, T. 59, № 8, стр. 1448-1456
Многорубежная модель “нападение–оборона” на сетях
А. Г. Перевозчиков 1, *, В. Ю Решетов 2, **, И. Е. Яночкин 1, ***
1 АО “НПО “РусБИТех-Тверь”, Департамент проектирования систем
(г. Тверь); отдел проектирования математических моделей
и информационно-расчетных задач (г. Тверь)
170000 Тверь, пр-т Калинина, 17, Россия
2 МГУ, ВМК
119999 Москва, Ленинские горы, Россия
* E-mail: pere501@yandex.ru
** E-mail: kadry@cs.msu.ru
*** E-mail: i-yanochkin@yandex.ru
Поступила в редакцию 19.07.2018
После доработки 20.03.2019
Принята к публикации 10.04.2019
Аннотация
Статья обобщает классическую игру “нападение–оборона” Ю.Б. Гермейера в части учета многорубежности обороны, имеющей сетевую структуру, и основана на работе R. Hohzaki, V. Tanaka. В отличие от последней, оборона на каждом из возможных направлений движения между вершинами сети, заданными ориентированными ребрами, может иметь несколько рубежей, что приводит в общем случае к выпуклым минимаксным задачам, которые могут быть решены методом субградиентного спуска. В частности, предложенная модель обобщает классическую игру нападение–оборона на многорубежный случай без упрощающего предположения о том, что эффективность средств обороны не зависит от рубежа. Библ. 15. Фиг. 1. Табл. 1.
ВВЕДЕНИЕ
Работа основана на результатах из [1], [2] и является дальнейшим развитием построений в [3], [4]. Классическая модель “нападение–оборона” Ю.Б. Гермейера была определена и изучена в работе [5]. Она является модификацией модели О. Гросса [6]. В военных моделях пункты интерпретируются обычно как направления и характеризуют пространственное распределение ресурсов защиты по ширине. Однако реально имеет место также пространственное распределение ресурсов обороны по глубине, характеризующейся количеством уровней рубежей на данном направлении.
Простейшая модель, учитывающая рубежность обороны, состоит в модификации классической модели [5], в которой функция выигрыша нападения имеет вид (см. [1])
В работе [7] исследована игровая модель, обобщающая модели Гросса и Гермейера, в которой получено конструктивное описание множества всех оптимальных смешанных стратегий нападения. В работе [8] изучалась модель Гросса с непротивоположными интересами сторон, в работах [9], [10] – динамические расширения модели. В работе [11] было предложено прямое обобщение игры нападение–оборона на сетях, описывающих топологию путей, ведущих к обороняемым объектам.
Дальнейшее обобщение классической игры нападение–оборона может состоять в учете рубежности обороны, имеющей сетевую структуру, что приводит в общем случае к выпуклым минимаксным задачам, которые могут быть решены методом субградиентного спуска. В частном случае параллельной сетевой структуры, когда пути из источника $s$ в сток $t$ не пересекаются и могут быть отождествлены с направлениями, а ребра однорубежны, предложенная модель формально обобщает игру нападение–оборона Ю.Б. Гермейера на многорубежный случай без упрощающих предположений, использованных в [11].
1. СЕТЕВОЕ ОБОБЩЕНИЕ МОДЕЛИ
Обобщая модель, предложенную в [11], определим игру нападение–оборона на ориентированном графе $G$, состоящем из множества вершин $N = \left\{ i \right\}$ и множества $L = \left\{ {(i,j)} \right\}$ ориентированных ребер ($i$, $j$), ведущих из $i$ в $j$, без контуров с одним источником $s$ и стоком $t$. Далее – орграфе $G$. Пусть
Каждое ориентированное ребро характеризуется величинами: ${{p}_{{ij}}}$, означающими вероятность поражения одного средства нападения одним средством обороны, которые считаются однородными, величинами ${{q}_{{ij}}} = 1 - {{p}_{{ij}}}$ соответственно – не поражения, и количеством ${{T}_{{ij}}}$ рубежей на оперативном направлении, задаваемом ребром ($i$, $j$).
Стратегии $\rho $ нападения и обороны $u$ принадлежат множествам
Используя известный алгоритм (см. [12, с. 252]), разобьем все вершины на ранги
так, чтоОпределим поток $x = x(\rho ,u)$ в сети из источника $s$ в сток $t$ при помощи рекуррентного соотношения последовательно по мере увеличения ранга $k = 0,\; \ldots ,\;K$. Положим
Пусть для вершин $j$-го ранга $j < k$ определены величины узловых потоков ${{X}_{i}}$, $i \in \bigcup\nolimits_{j < k}^{} {{{N}_{j}}} $.
Определим
Таким образом, стратегия нападения (${{\rho }^{i}}$, $i \in N{\backslash }t$), определяющая поток однородных средств нападения (${{x}_{{ij}}}$, $(i,j) \in L$) с потерями, из источника $s$ в сток $t$, представляет собой набор векторов ${{\rho }^{i}} = (\rho _{j}^{i},j \in \pi (i))$ целераспределения узлового потока ${{X}_{i}}$, по вытекающим из него инцидентным дугам, обеспечивающим баланс входящего и выходящего из узла потоков. Величина
Содержательно модель интерпретируется следующим образом: нападению нужно проникнуть из источника базирования к объекту обороны, представляющему сток, преодолев оборону в виде сети, которая задает возможные пути подлета к объекту. Каждая дуга сети интерпретируется как одно операционное направление, на котором нужно преодолеть локальную эшелонированную оборону противника. Результат боевого столкновения на одном рубеже обороны дается функцией
которая представляет собой результат дискретной одношаговой модели динамики средних Осипова–Ланчестера. Она получается следующим образом: количество средств нападения, получивших воздействие на данном рубеже, равно ${{n}_{{ij}}} = \min [{{x}_{{ij}}};{{u}_{{ij}}}]$ при условии, что на одно средство нападения назначается ровно одно средство обороны. Математическое количество потерь нападения составит ${{m}_{{ij}}} = {{p}_{{ij}}}{{n}_{{ij}}}$. В результате математическое ожидание числа прорвавшихся средств составитПример 1. Рассмотрим орграф $G$ из [11], состоящей из множества вершин $N = \left\{ {1,2,3,4,5} \right\}$, $s = 1$, $t = 5$ и множества ориентированных ребер $L = \left\{ {(1,2),\left( {1,3} \right),\left( {2,4} \right),\left( {3,4} \right),\left( {2,5} \right),\left( {3,5} \right),\left( {4,5} \right)} \right\}$, представленный на фигуре. Требуется ранжировать его вершины.
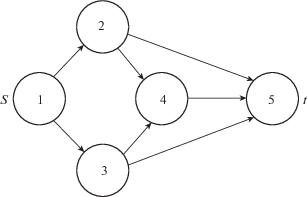
Решение. Используя указанный алгоритм ранжирования вершин из (см. [12, с. 252]), получаем разбиение $N = \bigcup\nolimits_k^{} {{{N}_{k}}} $, где ${{N}_{0}} = \left\{ 1 \right\}$, ${{N}_{1}} = \left\{ {2,3} \right\}$, ${{N}_{2}} = \left\{ 4 \right\}$, ${{N}_{3}} = \left\{ 5 \right\}$.
2. МИНИМАКСНАЯ СТРАТЕГИЯ ОБОРОНЫ
Из выпуклости критерия по $u$ следует, что определенная на сети игра допускает исследование полученной игры в чистых и смешанных стратегиях по схеме [13]. Наилучший гарантированный результат (НГР) обороны, совпадающий со значением игры, равен
Все угловые точки множества $R$ описываются как множество точек вида
С учетом выпуклости функции $I(\rho ,u) = {{X}_{t}}$ по ${{\rho }^{i}} = (\rho _{j}^{i},j \in \pi (i))$ величину $\bar {v}$ можно записать в виде
Множество ${{R}_{0}}$ отображается на множество $\Omega $ путей $l$ из $s$ в $t$, т.е. последовательности дуг, примыкающих друг к другу с учетом их ориентации. Это отображение осуществляется следующим образом. Каждому элементу
(2.1)
$\bar {v} = \mathop {\min }\limits_{u \in V} \mathop {\max }\limits_{l \in \Omega } I({{\rho }^{{(l)}}},u),$(2.2)
$V = \left\{ {\left( {{{u}_{{ij}}},(i,j) \in L} \right)\left| {\sum\limits_{(i,j) \in L}^{} {{{u}_{i}}_{j} \leqslant U,\;{{u}_{i}}_{j} \geqslant 0} } \right.} \right\}.$Таким образом, задача нахождения чистой оптимальной стратегии обороны состоит в нахождении такого $u$, принадлежащего множеству $V$, определенному в (2.2), которые реализуют минимум в (2.1). Такую стратегию обороны, следуя [5], назовем минимаксной, а задачу ее определения для краткости будем называть в дальнейшем задачей (2.1), (2.2).
3. СМЕШАННАЯ СТРАТЕГИЯ НАПАДЕНИЯ
Рассмотрим смешанную стратегию вида
Теорема 1. Для того чтобы стратегия ${{\varphi }_{0}}$ была оптимальной смешанной стратегией нападения, достаточно, чтобы
(3.1)
${{p}^{0}} \in \operatorname{Arg} \mathop {\max }\limits_{p_{{}}^{0} \in \Lambda } \mathop {\min }\limits_{u \in V} \sum\limits_{l \in \Omega } {p_{l}^{0}} I({{\rho }^{{(l)}}},u),$(3.2)
$\Lambda = \left\{ {{{p}^{0}} = (p_{l}^{0},l \in \Omega )\left| {\sum\limits_{l \in \Omega }^{} {p_{l}^{0}} = 1,\;p_{l}^{0} \geqslant 0,\;l \in \Omega } \right.} \right\}.$Таким образом, задача нахождения смешанной оптимальной стратегии нападения состоит в нахождении таких ${{p}^{0}}$, принадлежащих множеству $\Lambda $, определенному (3.2), которые реализуют максимум в (3.1). Эту задачу для краткости будем в дальнейшем обозначать (3.1), (3.2).
4. ЧИСЛЕННЫЕ МЕТОДЫ РЕШЕНИЯ ЗАДАЧ НАХОЖДЕНИЯ ОПТИМАЛЬНЫХ СТРАТЕГИЙ СТОРОН
В силу выпуклости функций $I({{\rho }^{{(l)}}},u)$ по $u \in Y$ и линейности функций
по $p_{{}}^{0} \in \Lambda $ задачи (2.1), (2.2) и (3.1), (3.2) представляют собой задачи выпукло-вогнутого программирования и могут быть решены субградиентным методом. При этом нахождение субградиентов $g \in \partial I({{\rho }^{{(l)}}},u)$ функций $I({{\rho }^{{(l)}}},u)$ может быть сведено к решению двойственных задач линейного программирования по схеме, предложенной в [3].Рассмотрим произвольный путь $l \in \Omega $ из $s$ в $t$
Задачу определения $I({{\rho }^{{(l)}}},u) = {{x}_{L}}$ можно свести к вспомогательной задаче линейного программирования
Формально будем считать, что на переменные ${{x}_{k}}$ дополнительно наложены условия не отрицательности ${{x}_{k}} \geqslant 0$, которые очевидно выполняются автоматически. Матрица $A$ этой системы имеет вид представленной в следующей таблице.
Таблица.
Матрица вспомогательной задачи линейного программирования
| $x_{0}^{{}}$ | $x_{1}^{{}}$ | $x_{2}^{{}}$ | … | $x_{{L - 2}}^{{}}$ | $x_{{L - 1}}^{{}}$ | $x_{L}^{{}}$ | 1 | |
|---|---|---|---|---|---|---|---|---|
| y–1 | –1 | 0 | 0 | … | –X | |||
| y0 | $q_{0}^{{{{T}_{0}}}}$ | –1 | 0 | … | 0 | |||
| y1 | 0 | $q_{1}^{{{{T}_{1}}}}$ | –1 | … | 0 | |||
| … | … | … | … | … | … | … | … | … |
| yT–2 | … | $q_{{L - 2}}^{{{{T}_{{L - 2}}}}}$ | –1 | 0 | 0 | |||
| yT–1 | … | 0 | $q_{{L - 1}}^{{{{T}_{{L - 1}}}}}$ | –1 | 0 | |||
| z0 | 1 | –1 | 0 | … | p0u0 | |||
| z1 | 0 | 1 | –1 | … | p1u1 | |||
| … | … | … | … | … | … | … | … | … |
| zL–2 | … | 1 | –1 | 0 | pL–2uL–2 | |||
| zL–1 | … | 0 | 1 | –1 | pL–1uL–1 | |||
| 1 | … | 0 | 0 | –1 |
Здесь через $(y,z)$, $y = ({{y}_{{ - 1}}},{{y}_{0}},\; \ldots ,\;{{y}_{{L - 1}}}) \in {{E}^{{L + 1}}}$, $z = ({{z}_{0}},\; \ldots ,\;{{z}_{{L - 1}}}) \in {{E}^{L}}$, обозначен вектор двойственных переменных.
Теперь можно записать двойственную задачу в виде
Имея субдифференциал ${{\partial }_{{{{u}^{l}}}}}I({{\rho }^{{(l)}}},u)$ можно записать общий вид субградиента ${{g}^{l}} \in {{\partial }_{u}}I({{\rho }^{{(l)}}},u)$ можно записать в виде
5. СУБГРАДИЕНТНЫЙ МЕТОД В ЗАДАЧЕ (2.1), (2.2)
Введем функцию внутреннего максимума в (2.1):
Лемма 1. Справедлива формула для субдифференциала $\partial L(u)$ выпуклой функции $L(u)$
(5.1)
$\partial L(u) = {\text{conv}}\{ {{g}^{l}},\;{{g}^{l}} \in \partial I({{\rho }^{{(l)}}},u),\;l \in \tilde {\Omega }(u)\} ,$Доказательство следует из той же формулы для субдифференциала функции максимума из [14].
Формула (5.1) позволяет решить максиминную задачу (2.1), (2.2) определения $\bar {v}$ методом субградиентного спуска. Введем функцию в ограничении $u \in Y$:
Функция $G(u)$ будет линейной и ее градиент $\nabla G(u) = (1,\; \ldots ,\;1)$ есть постоянный вектор. Имея градиент функции в ограничении $u \in Y$ для решения задачи выпуклого программирования (2.1), можно теперь воспользоваться комбинированным методом субградиентного спуска и проекции субградиентов (см. [15, с. 259]) с программным шагом
(5.2)
$\begin{gathered} {{u}_{{ij}}}(s + 1) = \left\{ \begin{gathered} {{P}_{{ij}}}({{u}_{{ij}}}(s) - {{h}_{s}}\nu _{{ij}}^{s}),\quad G(u(s)) \geqslant 0, \hfill \\ {{P}_{{ij}}}({{u}_{{ij}}}(s) - {{h}_{s}}r_{{ij}}^{s}),\quad G(u(s)) < 0; \hfill \\ \end{gathered} \right. \\ (i,j) \in L,\quad s = 1,2,\; \ldots , \\ \end{gathered} $Очевидно, что множество $Y$ допустимых решений задачи вогнутого программирования (2.1), (2.2) имеет внутренние точки, тогда в силу теоремы 7 в [15, с. 259] справедлива
Теорема 2. Все предельные точки последовательности $u(s)$ в методе (5.2) являются решениями задачи (2.1), (2.2).
6. СУБГРАДИЕНТНЫЙ МЕТОД В ЗАДАЧЕ (3.1), (3.2)
Введем функцию внутреннего минимума в (3.1):
(6.1)
$M({{p}^{0}}) = \mathop {\min }\limits_{u \in V} \sum\limits_{l \in \Omega } {p_{l}^{0}} I \geqslant ({{\rho }^{{(l)}}},u).$Лемма 2. Функция минимума $M({{p}^{0}})$ с распадающимися переменными будет вогнутой и ее субдифференциал $\partial M({{p}^{0}})$ определяется по формуле
(6.2)
$\partial M({{p}^{0}}) = {\text{conv}}\{ (I({{\rho }^{{(l)}}},u),\;l \in \Omega ),\;u \in \tilde {V}({{p}^{0}})\} ,$(6.3)
$\tilde {V}({{p}^{0}}) = \operatorname{Arg} \mathop {\min }\limits_{u \in V} \sum\limits_{l \in \Omega } {p_{l}^{0}} I({{\rho }^{{(l)}}},u).$Доказательство следует из формулы для субдифференциала функции максимума из [14].
Полученная формула позволяет решить максиминную задачу (3.1) определения ${{p}^{0}}$ методом субградиентного подъема. Введем агрегированную функцию в ограничении ${{p}^{0}} \in \Lambda $:
Имея субградиенты функции внутреннего минимума (6.1) для решения задачи выпуклого программирования (3.1), можно теперь воспользоваться комбинированным методом субградиентного спуска и проекции субградиентов (см. [15, с. 259]) с программным шагом
(6.4)
$\begin{gathered} p_{l}^{0}(s + 1) = \left\{ \begin{gathered} {{P}_{l}}(p_{l}^{0}(s) + {{h}_{s}}\nu _{l}^{s}),\quad D({{p}^{0}}(s)) \leqslant 0, \\ {{P}_{i}}({{p}_{i}}(s) + {{h}_{s}}r_{l}^{s}),\quad D({{p}^{0}}(s)) > 0, \\ \end{gathered} \right. \\ l \in \Omega ,\quad s = 1,2,\; \ldots , \\ \end{gathered} $Очевидно, что множество $\Lambda $ допустимых решений задачи вогнутого программирования (3.1), (3.2) имеет внутренние точки, тогда в силу теоремы 7 из [15, с. 259] справедлива
Теорема 3. Все предельные точки последовательности $p(s)$ в методе (6.4) являются решениями задачи (3.1), (3.2).
Замечание 1. Для определения некоторого решения $u(s) \in \tilde {V}({{p}^{0}}(s))$ в выпуклой задаче минимизации (6.1) на каждом шаге также можно воспользоваться методом субградиентного подъема.
Введем функцию внутреннего минимума в (6.1)
Имея субдифференциал $\partial I({{\rho }^{{(l)}}},u)$ вогнутой функции $I({{\rho }^{{(l)}}},u)$, можно вычислить субдифференциал ${{\partial }_{u}}N(p,u)$ с использованием формулы для субдифференциала суммы из [15]:
(6.5)
${{\partial }_{u}}N(p,u) = {\text{conv}}\left\{ {\sum\limits_{l \in \Omega } {p_{l}^{0}{{g}^{l}}} ,\;{{g}^{l}} \in \partial I({{\rho }^{{(l)}}},u),\;i = 1,\; \ldots ,\;n} \right\},$Воспользуемся ранее введенной агрегированной функцией $G(u)$ в ограничении $u \in Y$. Имея субградиенты агрегированной функции $G(u)$ для решения задачи определения некоторого решения $u \in \tilde {V}({{p}^{0}})$ в выпуклой задаче минимизации (6.1), можно теперь воспользоваться комбинированным методом субградиентного спуска и проекции субградиентов (см. [15, с. 259]) с программным шагом
(6.6)
$\begin{gathered} {{u}_{{ij}}}(s + 1) = \left\{ \begin{gathered} {{P}_{{ij}}}({{u}_{{ij}}}(s) + {{h}_{s}}\nu _{{ij}}^{s}),\quad G(u(s)) \geqslant 0, \hfill \\ {{P}_{{ij}}}({{u}_{{ij}}}(s) + {{h}_{s}}r_{{ij}}^{s}),\quad G(u(s)) < 0, \hfill \\ \end{gathered} \right. \\ (i,j) \in L,\quad s = 1,2,\; \ldots , \\ \end{gathered} $Тогда в силу теоремы 7 из [15, с. 259] все предельные точки последовательности $u(s)$ в методе (6.6) принадлежат множеству (6.3).
Список литературы
Перевозчиков А.Г., Лесик И.А., Шаповалов Т.Г. Многоуровневое обобщение модели “нападение–оборона” // Вестник ТвГУ. Сер. Прикл. матем. 2017. № 1. С. 39–51.
Решетов В.Ю., Перевозчиков А.Г., Лесик И.А. Модель преодоления многоуровневой системы защиты нападением // Прикл. матем. и информатика. Труды факультета ВМК МГУ / Под ред. В.И. Дмитриева. М.: МАКС Пресс, 2015. № 49. С. 80–96.
Решетов В.Ю., Перевозчиков А.Г., Лесик И.А. Модель преодоления многоуровневой системы защиты нападением с несколькими фазовыми ограничениями // Вестник МГУ. Серия 15. Вычисл. матем. и кибернетика. 2017. № 1. С. 26–32.
Перевозчиков А.Г., Решетов В.Ю., Яночкин И.Е. Модель “нападение–оборона” с неоднородными ресурсами сторон // Ж. вычисл. матем. и матем. физ. 2018. Т. 58. № 1. С. 41–50.
Гермейер Ю.Б. Введение в теорию исследования операций. М.: Наука, 1971.
Карлин С. Математические методы в теории игр, программировании и экономике. М.: Мир, 1964.
Огарышев В.Ф. Смешанные стратегии в одном обобщении задачи Гросса // Ж. вычисл. матем. и матем. физ. 1973. Т. 13. № 1. С. 59–70.
Молодцов Д.А. Модель Гросса в случае непротивоположных интересов // Ж. вычисл. матем. и матем. физ. 1972. Т. 12. № 2. С. 309–320.
Данильченко Т.Н., Масевич К.К. Многошаговая игра двух лиц при “осторожном” втором игроке и последовательной передаче информации // Ж. вычисл. матем. и матем. физ. 1974. Т. 19. № 5. С. 1323–1327.
Крутов Б.П. Динамические квазиинформационные расширения игр с расширяемой коалиционной структурой. М.: ВЦ РАН, 1986.
Hohzaki R., Tanaka V. The effects of players recognition about the acquisition of his information by his opponent in an attrition game on a network // In Abstract of 27th European conference on Operation Research (EURO2015). 12–15 July 2015, University of Strathclyde.
Танаев В.С., Сотсков Ю.Н., Струсевич В.А. Теория расписаний. Многостадийные системы. М.: Наука, 1989.
Васин А.А., Морозов В.В. Теория игр и модели математической экономики. М.: МАКС Пресс, 2005.
Сухарев А.Г., Тимохов А.В., Федоров В.В. Курс методов оптимизации. М.: Наука, 1986.
Поляк Б.Т. Введение в оптимизацию. М.: Наука, 1983.
Дополнительные материалы отсутствуют.
Инструменты
Журнал вычислительной математики и математической физики