Автоматика и телемеханика, № 10, 2019
© 2019 г. А.Б. ЮДИЦКИЙ, канд. тех. наук
(anatoli.juditsky@univ-grenoble-alpes.fr)
(LJK, Университет Гренобль-Альпы, Гренобль, Франция),
А.С. НЕМИРОВСКИЙ, д-р физ.-мат. наук (nemirovs@isye.gatech.edu)
(ISyE, Технологический институт Джорджии, Атланта, США)
ВОССТАНОВЛЕНИЕ СИГНАЛОВ С ПОМОЩЬЮ
СТОХАСТИЧЕСКОЙ ОПТИМИЗАЦИИ1
Рассматривается подход к восстановлению сигналов в обобщенных ли-
нейных моделях, при котором задача оценивания сигналов сводится к ре-
шению стохастических монотонных вариационных неравенств (ВН). Ре-
шения таких ВН могут быть получены с помощью эффективно вычисли-
тельных процедур, а в случае сильно монотонных ВН допускают верхнюю
границу на конечном времени для ожидаемой ошибки ∥ · ∥22, сходящуюся
к нулю со скоростью O(1/K) с ростом числа K наблюдений. Принятые
структурные предположения существенно слабее тех, которые необходи-
мы для обеспечения выпуклости оптимизационной задачи, возникающей
при применении метода максимального правдоподобия. Прослеживается
связь предлагаемого подхода с идеями, лежащими в основе алгоритма
персептрона Розенблата.
Ключевые слова: обобщенные линейные модели, задача статистического
оценивания, стохастическая оптимизация, вариационные неравенства.
DOI: 10.1134/S0005231019100088
1. Введение
Задачи статистического оценивания составляют одну из важнейших при-
кладных областей стохастической оптимизации. Типичная постановка задачи
выглядит следующим образом (например, см. [1] и обширную библиографию,
приведенную в этой книге). Допустим, что имеются независимые одинаково
распределенные наблюдения ωK = (ω1, . . . , ωK ), ωk = (ηk, yk), где ηk ∈ Rn×m,
yk ∈ Rm — реализации регрессоров (независимые переменные) и отклики
(метки) соответственно. Предполагаем, что наблюдения описываются обоб-
щенной линейной моделью (ОЛМ) [2, 3], т.е. условное (по η) математическое
ожидание y равно f(ηTx), гдe верхний индексT — знак транспонирования,
f (·) : Rm → Rm — известная функция связи, а x ∈ Rm — неизвестный “сиг-
нал”, т.е. вектор параметров модели. Цель состоит в “подгонке модели”, т.е. в
восстановлении вектора x по наблюдениям ωK . При стандартном подходе к
решению задачи оценивания выбирают функцию потерь ℓ(y, θ) : Rm × Rm →
→ R и в качестве оценки x принимают оптимальное решение оптимизацион-
1 Работа первого автора поддержана грантом 2016-2032H, PGMO. Работа первого и вто-
рого авторов финансировалась грантом CCF-1523768, NSF.
153
ной задачи
{
}
(1)
minEω∼Px
ℓ(y, f(ηTu))
,
u∈X
где Px — функция распределения наблюдений ω = (η, y), отвечающая “истин-
ному сигналу x”, а X — априори известное множество сигналов. Иными сло-
вами, задача статистического оценивания сводится к задаче стохастической
оптимизации (1), которая должна решаться приближенно, исходя из имею-
щихся наблюдений ωK . Это может быть сделано или напрямую (“пакетно”)
путем минимизации по u ∈ X аппроксимации выборочного среднего (ВСА)
∑
1
(2)
ℓ(yk, f(ηTk
u))
K
k=1
для математического ожидания в
(1) (например, см. [4]) или путем приме-
нения итеративных алгоритмов стохастической оптимизации типа стохасти-
ческой аппроксимации (СА) [5, 6].
Пусть функция условного по η распределения Px|η величины y, индуциро-
ванная распределением Px, принадлежит известному параметрическому се-
мейству P = {Pθ : θ ∈ Θ ⊂ Rm}, а именно, Px|η = Pf(ηTx); тогда стандартный
выбор функции потерь дается методом максимального правдоподобия (МП).
Иными словами, считая, что распределения Pθ имеют плотности pθ относи-
тельно некоторой меры Π, полагают
ℓ(y, θ) = - ln(pθ(y)).
Например, в классической логистической регрессии имеем m = 1, f(s) =
= (1 + e-s)-1, Θ = (0, 1), а Pθ, θ ∈ Θ, — распределение Бернулли, т.е. y при-
нимает значение единица с вероятностью q = (1 + exp{-ηTx})-1 и нуль с ве-
роятностью 1 - q, что приводит к
(
)
(3)
ℓ(y, f(ηTu)) = ln
1 + exp{ηTu}
- yηT
u.
В этом случае задача (1) становится оптимизационной задачей вида
{
}
(4)
minE(η,y)∼Px
ln(1 + exp{ηTu}) - y ηTu
,
u∈X
и соответствующая задача ВСА записывается как
∑[
]
1
(5)
min
ln(1 + exp{ηTku}) - ykηTku
,
u∈X K
k=1
а ее оптимальное решение xML(ωK ) и есть МП-оценка сигнала x. При пред-
положении о выпуклости множества X сигналов обе эти задачи выпуклы и,
следовательно, глобальный оптимум в задаче ВСА может быть эффективно
вычислен, а для алгоритмов СА для
(4) могут быть получены гарантиро-
ванные скорости сходимости.
154
В более общем случае, когда распределения наблюдений образуют семей-
ство условных экспоненциальных распределений [7, 8], функция правдоподо-
бия имеет вид
ℓ(y, ηTu) = F (ηTu) - yηTu
с выпуклой кумулянтной функцией F , а соответствующая задача (1) мини-
мизации риска записывается как
{
}
(6)
minE(η,y)∼Px
F (ηTu) - yηTu
u∈X
В этом случае, так же как и при логистической регрессии, для получения
МП-оценок параметров модели можно применять ВСА или СА.
Заметим, однако, что предположение о принадлежности распределений
экспоненциальному семейству довольно ограничительно. С другой стороны,
для распределений, которые не удовлетворяют этому предположению, вы-
пуклость оптимизационной задачи, получающейся при выборе функции по-
терь ℓ(·) по методу максимального правдоподобия, является скорее исключе-
нием, чем правилом. Например, рассмотрим нелинейную схему наименьших
квадратов, в которой величина y получается из f(ηTx) добавлением центри-
рованного гауссовского шума, не зависящего от регрессоров:
y = f(ηTx) + ξ, ξ ∼ N(0,σ2Im).
В этом случае задача (1) и ее ВС-аппроксимация при выборе ℓ(·) по методу
максимального правдоподобия приобретают вид
{
}
minEη∼Q ∥f(ηTx) - f(ηTu)∥2
,
2
u∈X
{
}
k
∑
1
(7)
min
∥yk - f(ηTku)∥2
,
2
u∈X K
k=1
где Q — распределение регрессоров (они предполагаются независимыми от
сигнала). Если функция f нелинейна, то обе эти задачи обычно невыпук-
лы, и их численное решение затруднено. Аналогично, в задаче “неэкспонен-
циальной логистической регрессии”, в которой сигмоидная функция f(s) =
= (1 + exp{-s})-1 заменена на общего вида неубывающую функцию свя-
зи f(s) : R → (0, 1) (например, так называемая пробит-функция или допол-
няющая log - log функция), МП-выбор функции потерь, как правило, влечет
невыпуклость задачи (1) и ее ВС-аппроксимации.
Цель последующего изложения — предложить альтернативу решению за-
дачи настройки модели, основанному на решении оптимизационной зада-
чи (1) с МП-выбором функции потерь при оценивании сигнала по наблюдени-
ям в ОЛМ. Идеи, лежащие в основе подхода, предлагаемого в настоящей ста-
тье, восходят к итеративному алroритму персептрона Розенблата [9, 10] и его
“пакетной” версии [11]. В этом случае структурные требования, предъявляе-
мые к модели, оказываются существенно слабее тех, которые приводят к вы-
155
пуклости задач (1) с МП-выбором функции потерь и их ВС-аппроксимаций2.
При этих предположениях вместо того, чтобы использовать классический
подход с формированием задачи стохастической оптимизации
(1) и функ-
ции потерь [12-16], задача оценивания сводится к другой задаче с выпук-
лой структурой — сильно монотонному вариационному неравенству (ВН),
представимому в виде стохастического оракула. Полученное вариационное
неравенство может быть эквивалентно задаче выпуклой минимизации (на-
пример, при m = 1 такое ВН эквивалентно задаче выпуклой оптимизации,
аналогичной
(6)); но даже и в этом случае получающаяся задача, как пра-
вило, отличается от МП-версии задачи (1). Решение такого ВН может быть
получено в результате эффективной численной процедуры, и оно оказывает-
ся “хорошей” оценкой “истинного” сигнала по имеющимся наблюдениям. Для
этой оценки здесь доказываются верхние границы на ожидаемую квадратич-
ную ошибку в норме ∥ · ∥22, сходящуюся к нулю со скоростью O(1/K) при
K →∞3.
2. Постановка задачи
Рассматривается обобщенная линейная модель наблюдений, характери-
зующаяся следующими предположениями.
Наблюдения зависят от неизвестного сигнала x, принадлежащего задан-
ному выпуклому компактному множеству X ⊂ Rn, и представлены в виде
(8)
ωK = {ωk = (ηk,yk
), 1 ≤ k ≤ K},
где ωk, 1 ≤ k ≤ K, — независимые одинаково распределенные реализации
случайной пары (η, y) с распределением Px таким, что
• регрессор η является случайной (n × m)-матрицей с некоторым вероят-
ностным распределением Q, не зависящим от x;
• отклик (“метка”) y является m-мерным случайным вектором таким, что
его условное по η распределение, индуцированное распределением Px, имеет
математическое ожидание f(ηTx):
(9)
Ex|η{y} = f(ηT
x),
где Ex|η — условное по η математическое ожидание метки y, задаваемое рас-
пределением Px величины ω = (η, y), а f(·) : Rm → Rm — заданное отобра-
жение.
Ниже будут сформулированы предположения о параметрах обобщенной
линейной модели (а именно, условия на f(·) и на распределение Px, x ∈ X
пары (η, y)), необходимые для обоснования предлагаемого подхода.
2 Например, в нелинейной схеме наименьших квадратов с m = 1 и в неэкспоненциаль-
ной логистической регрессии от функции f требовалась лишь непрерывная дифференци-
руемость и положительность производной, а от множества X сигналов — выпуклость.
3 Несмотря на простоту приводимых ниже выкладок, авторам не удалось найти упоми-
нание о предлагаемом подходе в статистической литературе.
156
2.1. Предварительные сведения: монотонные векторные поля
Монотонное векторное поле на Rm — это однозначное всюду определенное
отображение g(·) : Rm → Rm, обладающее свойством монотонности:
[g(z) - g(z′)]T[z - z′] ≥ 0
∀z, z′ ∈ Rm.
Скажем, что такое поле монотонно с модулем κ ≥ 0 на замкнутом выпуклом
множестве Z ⊂ Rm, если
[g(z) - g(z′)]T[z - z′] ≥ κ∥z - z′∥22
∀z, z′ ∈ Z;
назовем g сильно монотонным на Z, если модуль монотонности κ поля g
на Z положителен. Очевидно, что для монотонного векторного поля f, непре-
рывно дифференцируемого на замкнутом выпуклом множестве Z с непустой
внутренностью, условие
(10)
dTf′(z)d ≥ κdTd
∀(d ∈ Rn
,z∈Z)
является необходимым и достаточным условием монотонности с модулем κ.
Стандартными примерами монотонных векторных полей являются
• градиентные поля
∇φ(x) непрерывно дифференцируемых выпуклых
функций m переменных, а также векторные поля [∇xφ(x, y); -∇yφ(x, y)],
порожденные непрерывно дифференцируемыми функциями φ(x, y), вы-
пуклыми по x и вогнутыми по y;
• “диагональные” векторные поля f(x) = [f1(x1); . . . ; fm(xm)] с монотонно
неубывающими компонентами fi(·) — функциями одного аргумента. Ес-
ли, кроме того, fi(·) непрерывно дифференцируемы с положительными
производными, то соответствующее поле f сильно монотонно на любом
компактном выпуклом подмножестве в Rm с модулем монотонности, за-
висящим от подмножества.
Монотонные векторные поля на Rn допускают выполнение простых опе-
раций, включающих, например, следующие:
I. [аффинная подстановка аргумента]: Если f(·) — монотонное векторное по-
ле на Rm и A есть (n × m)-матрица, то векторное поле
g(x) = Af(ATx + a)
также монотонно на Rn; если, кроме того, поле f монотонно с модулем
κ ≥ 0 на замкнутом выпуклом множестве Z ⊂ Rm, а множество X ⊂ Rn
замкнуто, выпукло и обладает свойством ATx + a ∈ Z для всех x ∈ X, то
поле g монотонно с модулем σ2κ на X, где σ — минимальное сингулярное
значение матрицы A.
II. [суммирование]: Пусть S — польское пространство, f(x, s) : Rm × S →
→ Rm — борелевская векторнозначная функция, монотонная по x при
каждом s ∈ S, а μ(ds) — борелевская вероятностная мера на S такая, что
векторное поле
∫
F (x) = f(x, s)μ(ds)
S
157
определено для всех x; тогда F (·) монотонно. Если, кроме того, X — за-
мкнутое выпуклое множество в Rm, а f(·, s) монотонно на X с борелев-
∫ким по s модулем κ(s) для всякого s ∈ S, то F монотонно на X с модулем
κ(s)μ(ds).
S
2.2. Предположения
В дальнейшем потребуются следующие предположения об основных ком-
понентах задачи оценивания, описанной во введении.
A.1. Векторное поле f(·) непрерывно и монотонно, а векторное поле
{
}
F (z) = Eη∼Q
ηf(ηTz)
корректно определено (следовательно, монотонно, как и поле f, см. I, II).
A.2. Множество X сигналов непусто, выпукло и компактно, а векторное
поле F монотонно с положительным модулем κ на X .
A.3. Для соответствующим образом выбранного M < ∞ и всякого x ∈ X
верно
{
}
(11)
E(η,y)∼Px
∥ηy∥22
≤M2.
Простое достаточное условие выполнения предположений A.1-A.3 с соответ-
ствующим образом выбранным M < ∞ и κ > 0 заключается в следующем:
• распределение Q регрессора η имеет конечные моменты всех порядков и
Eη∼Q{ηηT} ≻ 0;
• функция f непрерывно дифференцируема, и dTf′(z)d > 0 для всех d = 0
и всех z. Кроме того, f имеет полиномиальный рост, т.е. для некоторых
констант C ≥ 0 и p ≥ 0 и всех z выполнено ∥f(z)∥2 ≤ C(1 + ∥z∥p2).
Проверка достаточности осуществляется непосредственно.
3. Построения и основной результат
Сформулируем ключевое наблюдение, лежащее в основе представляемых
ниже конструкций.
Предложение 1. Пусть выполнены предположения A.1-A.3. Сопоста-
вим паре (η, y) ∈ Rn×m × Rm векторное поле
(12)
G(η,y)(z) = ηf(ηTz) - ηy : Rn → Rn.
Тогда для любого x ∈ X имеем
{
}
(a)
E(η,y)∼Px
= F(z) - F(x)
∀z ∈ Rn
G(η,y)(z)
(13)
(b)
∥F (z)∥2 ≤ M
∀z ∈ X
{
}
(c) E(η,y)∼Px
∥G(η,y)(z)∥22
≤ 4M2
∀z ∈ X.
158
Доказательство. Пусть x ∈ X. Тогда, пользуясь соотношением (9) и
определением поля F , имеем
{
}
{
}
E(η,y)∼Px {ηy} = Eη∼Q Ex|η{ηy}
=Eη
ηf(ηTx)
= F(x).
Отсюда получаем
{
}
{
}
E(η,y)∼Px
G(η,y)(z)
=E(η,y)∼Px
ηf(ηTz) - ηy
=
{
}
=E(η,y)∼Px
ηf(ηTz)
- F(x) =
{
}
=Eη∼Q
ηf(ηTz)
- F(x) = F(z) - F(x);
последнее неравенство следует из (13.a). Кроме того, для x, z ∈ X обозначим
через Pz|η условное по η распределение величины z, индуцированное распре-
делением Pz величины (η, y) = ηTy. С учетом того, что маргинальное распре-
деление величины η, индуцированное распределением Pz, есть не что иное
как Q, приходим к
{
}
{
}
E(η,y)∼Px
∥ηf(ηTz)∥22
=Eη∼Q
∥ηf(ηTz)∥22
=
{
}
=Eη∼Q
∥Ey∼P z
{ηy}∥2
≤
[поскольку Ey∼P z {y} = f(ηTz)]
|η
2
|η
{
{
}}
≤Eη∼Q Ey∼Pz
∥ηy∥22
=
[по неравенству Йенсена]
|η
{
}
=E⃗η,y)∼Pz
∥ηy∥22
≤M2
[по A.3, поскольку z ∈ X ].
В совокупности с соотношением E(η,y)∼Px {∥ηy∥22} ≤ M2, справедливым в
соответствии с A.3 (поскольку x ∈ X ), это влечет выполнение (13.b) и (13.c).
3.1. Основной результат
Напомним, что целью статьи является восстановление сигнала x ∈ X по
наблюдениям (8). В предположениях A.1-A.3 точка x есть корень монотон-
ного векторного поля
{
}
(14)
G(z) = F (z) - F (x), F (z) = Eη∼Q
ηf(ηTz)
;
причем известно, что этот корень принадлежит множеству X и он единствен,
поскольку поле G(·) сильно монотонно на X , равно как и поле F (·). Известно,
что для заданного выпуклого компактного множества X задача отыскания
такого корня эффективно разрешима при наличии “оракула”, который, имея
на входе точку z ∈ X , выдает значение G(z) поля в этой точке. Это не совсем
та ситуация, которая здесь описана, поскольку поле G есть математическое
ожидание случайного поля:
{
}
G(z) = E(η,y)∼Px
ηf(ηTz) - ηy
и заранее не известно, каково то распределение, по которому берется ожида-
ние. Однако выборка из этого распределения доступна, причем выборочные
159
значения в точности и есть наблюдения (8); эти выборочные значения мо-
гут использоваться для аппроксимации поля G тем или иным способом с
последующим применением этой аппроксимации для восстановления сигна-
ла x. Два стандартных пути реализации этой простой идеи суть ВСА и СА,
упоминавшиеся выше. Обсудим эти два метода применительно к ситуации, в
которой находимся.
3.1.1. Оценивание: аппроксимация выборочным средним. Идея, лежащая
в основе аппроксимации по выборочному среднему (ВСА), совершенно про-
зрачна: имея наблюдения (8), будем аппроксимировать неизвестное поле G
его эмпирическим аналогом
∑[
]
1
ηkf(ηTkz) - ηkyk
GωK (z) =
K
k=1
По закону больших чисел при K → ∞ эмпирическое поле GωK сходится к ин-
тересующему нас полю G, поэтому при некоторых необременительных усло-
виях регулярности с большой вероятностью поле GωK будет равномерно на X
близко к полю G для достаточно больших значений K. Вследствие сильной
монотонности G отсюда следует, что множество “почти нулей” поля GωK на X
будет близко к нулю x поля G, т.е. к сигналу, который и подлежит восстанов-
лению. Вопрос теперь заключается в том, как правильно определить понятие
“почти нуля” поля GωK на X4. В данной ситуации это удобно сделать исходя
из понятия слабого решения вариационного неравенства (ВН) с монотонным
оператором, определяемого (в данном конкретном случае) следующим обра-
зом.
Пусть X ⊂ Rn — непустое выпуклое компактное множество и пусть H(z):
X →Rn — монотонное векторное поле (т.е. [H(z)-H(z′)]T[z-z′]≥0 для
всех z, z′ ∈ X ). Вектор z∗ ∈ X называется слабым решением вариацион-
ного неравенства, связанного с H, X , если
H(z)T(z - z∗) ≥ 0
∀z ∈ X.
Пусть X ⊂ Rn — непустое выпуклое компактное множество и пусть H
монотонно на X . Хорошо известно, что
• ВН, связанное с H, X (обозначим его через VI(H, X )), всегда имеет слабое
решение. Ясно, что если z ∈ X — корень H, то z — слабое решение для
VI(H, X ).5
• Если поле H непрерывно на X , то любое слабое решение z неравенства
VI(H, X ) также является и сильным решением в том смысле, что
(15)
HT
(z)(z - z) ≥ 0 ∀z ∈ X .
4 Заметим, что “почти нуль” поля GωK на X не может быть определен как корень GωK
на этом множестве. Если у G действительно имеется корень, принадлежащий множеству X,
то у GωK такого корня может и не быть.
5 Если z∈ X и H(z) = 0, то монотонность H влечет H(z)T[z - z] = [H(z) - H(z)]T[z - z] ≥
≥0 для всех z ∈ X, т.е. z — слабое решение для VI(H,X).
160
Действительно, соотношение (15) очевидным образом выполнено для z =
= z. При z = z, положив zt = z + t(z - z), 0 < t ≤ 1, имеем HT(zt)(zt -
- z) ≥ 0 (так как z является слабым решением), откуда HT(zt)(z - z) ≥ 0
(поскольку z - z кратно zt - z с положительным множителем). Перехо-
дя к пределу при t → +0 и вспоминая про непрерывность H, получаем
желаемое HT(z)(z - z) ≥ 0.
• Если H — градиентное поле непрерывно дифференцируемой выпуклой
на X функции (такое поле монотонно), слабые (или сильные, что в случае
непрерывного H одно и то же) решения неравенства VI(H, X ) являются
точками минимума функции на X .
Заметим еще, что сильное решение неравенства VI(H, X ) с монотонным
H всегда является и слабым решением: если z ∈ X удовлетворяет условию
HT(z)(z - z) ≥ 0 при всех z ∈ X, то и H(z)T(z - z) ≥ 0 при всех z ∈ X,
поскольку вследствие монотонности имеем H(z)T(z - z) ≥ HT(z)(z - z).
В дальнейшем будем существенно использовать следующий простой и хо-
рошо известный факт.
Лемма 1. Пусть X — выпуклое компактное множество и пусть H —
монотонное векторное поле на X с модулем монотонности κ > 0, т.е.
[H(z) - H(z′)]T[z - z′] ≥ κ∥z - z′∥22
∀z,z′ ∈ X.
Пусть также z — слабое решение неравенства VI(H, X ). Тогда слабое ре-
шение VI(H,X) единственно. Кроме того,
(16)
HT(z)[z - z] ≥ κ∥z - z∥22.
Доказательство. В условиях леммы положим z ∈ X, и пусть z есть
слабое решение неравенства VI(H, X ) (помним, что оно существует!). Поло-
жив zt = z + t(z - z) при t ∈ (0, 1), получаем цепочку неравенств
HT(z)[z - zt] ≥ HT(zt)[z - zt] + κ∥z - zt∥2 ≥ κ∥z - zt∥2,
первое из которых справедливо в силу сильной монотонности H, а второе
следует из того, что величина HT(zt)[z - zt] кратна HT(zt)[zt - z] с поло-
жительным коэффициентом. Последняя величина неотрицательна, посколь-
ку z является слабым решением исследуемого ВН. Таким образом, име-
ем HT(z)(z - zt) ≥ κ∥z - zt∥22 и, переходя к пределу при t → +0, приходим
к (16).
Для доказательства единственности слабого решения предположим, что
помимо слабого решения z имеется отличное от него слабое решение z, и
положим z′ =12 [z + z]. Поскольку и z, и z — слабые решения, то обе величины
HT(z′)[z′ - z] и HT(z′)[z′ - z] должны быть неотрицательны, а поскольку в
сумме они равны нулю, то каждое из них равно нулю. Поэтому, применяя (16)
к z = z′, получаем z′ = z, откуда также и z = z.
Вернемся теперь к исходной задаче оценивания. Пусть предположения
A.1-A.3 выполнены, так что векторные поля G(ηk ,yk)(z), определенные в (12),
161
а следовательно, и векторное поле GωK (z) непрерывны и монотонны. При ис-
пользовании ВСА было найдено слабое решение x(ωK ) вариационного нера-
венства VI(GωK , X ) и принято в качестве ВСА-оценки сигнала x по наблюде-
ниям (8). Поскольку векторное поле GωK (·) монотонно и его значения эффек-
тивно вычислимы — при условии, что таковым является f, — задача вычисле-
ния слабого решения ВН VI(GωK , X ) (точнее, очень хорошего приближения
к нему) также является эффективно разрешимой (например, см. [17]). Хотя
авторы не ставили перед собой такой задачи в настоящей работе, исполь-
зуя методологию из [16, 18-20] и дополняя предположения A.1-A.3 необреме-
нительными условиями регулярности, можно доказать неасимптотическую
верхнюю границу, например, для ожидаемой ошибки ∥ · ∥22 ВСА-оценки как
функцию размера выборки K и найти скорость, с которой эта верхняя гра-
ница сходится к нулю с ростом K → ∞.
Рассмотрим ВСА-оценки в схеме логистической регрессии. Имеем f(u) =
= (1 + e-u)-1 и
[
]
exp{ηTkz}
G(ηk ,yk)(z) =
-yk ηk,
1 + exp{ηTk z}
[
]
∑
1
exp{ηTkz}
GωK (z) =
-yk ηk =
K
1 + exp{ηTkz}
k=1
]
[∑(
(
)
)
1
=
∇z
ln
1 + exp{ηTk z}
-ykηTkz
K
k
Иначе говоря, GωK (z) является градиентным полем отрицательного логариф-
ма эмпирического МП ℓ(z, ωK ), см. (5). В результате слабые решения ВН
VI(GωK , X ) дают в точности оптимальные решения задаче (5), т.е. в схеме
логистической регрессии ВСА-оценки есть оценки максимального правдопо-
добия xML(ωK)6. С другой стороны, в примере для нелинейной схемы наи-
6 Заметим, что это явление специфично для модели логистической регрессии. То, что в
этом случае ВСА-оценки совпадают с МП-оценками, объясняется тем, что логистическая
сигмоида f(s) = exp{s}/(1 + exp{s}) удовлетворяет тождеству f′(s) = f(s)(1 - f(s)). При
ее замене на f(s) = φ(s)/(1 + φ(s)) с дифференцируемой монотонно неубывающей положи-
тельной φ(·) ВСА-оценка доствляет слабое решение вариационному неравенству VI(Φ, X ) с
[
]
∑
φ(ηTkz)
Φ(z) =
-yk ηk.
1 + φ(ηTkz)
k
С другой стороны, градиентное поле отрицательного логарифма МП
∑[
]
1
-
yk ln(f(ηTkz)) + (1 - yk) ln(1 - f(ηTkz))
,
K
k
которое должно минимизироваться при отыскании МП-оценок, имеет вид
[
]
∑
φ′(ηTkz)
φ(ηTkz)
Ψ(z) =
-yk ηk.
φ(ηTkz)
1 + φ(ηTkz)
k
При k > 1 и неэкспоненциальной φ поля Φ и Ψ “существенно различны”; соответственно,
ВСА-оценка, как правило, отлична от МП-оценки.
162
меньших квадратов, приведенном во введении, с монотонной (для простоты
скалярной) функцией f(·) векторное поле GωK (·) имеет вид
∑[
]
1
f (ηTkz) - yk
ηk,
GωK (z) =
K
k=1
“существенно отличный” (при условии нелинейности f) от градиентного поля
∑
[
]
2
Ψ(z) =
f′(ηTkz)
f (ηTkz) - yk
ηk
K
k=1
для МП (7). В результате в этом случае МП-оценка (7), вообще говоря, от-
личается от ВСА-оценки, но в отличие от МП-оценки ВСА-оценка гораздо
проще с вычислительной точки зрения.
3.1.2. Оценивание: стохастическая аппроксимация. Оценки метода стоха-
стической аппроксимации (СА) генерируются простым алгоритмом субгра-
диентного спуска решения вариационного неравенства VI(G,X). Если бы
значения векторного поля G(·) были доступны, можно было бы аппрокси-
мировать корень x ∈ X этого ВН, пользуясь рекурсией
zk = ProjX [zk-1 - γkG(zk-1)], k = 1,... ,K,
где
• ProjX [z] — метрическая проекция Rn на X:
ProjX [z] = argmin ∥z - u∥2;
u∈X
• γk > 0 — заданная длина шага;
• начальное приближение z0 — произвольная точка из X .
Хорошо известно, что в предположениях A.1-A.3 такая рекуррентная проце-
дура с надлежащим выбором длины шага и начальной точкой из X позволяет
аппроксимировать корень поля G (на самом деле, также и любое слабое реше-
ние VI(G, X )) с произвольно высокой точностью, если K достаточно велико.
Здесь, однако, имеем ситуацию, когда истинные значения поля G недоступ-
ны; стандартный способ преодоления этой трудности заключается в замене
“ненаблюдаемых” значений G(zk-1) поля G, присутствующих в рекуррентной
процедуре, их несмещенными случайными оценками G(ηk ,yk)(zk-1). Такая мо-
дификация приводит к процедуре стохастической аппроксимации (восходя-
щей к [21]) — рекурсии вида
(17)
zk = ProjX [zk-1 - γkG(ηk,yk)(zk-1
)],
1 ≤ k ≤ K,
где z0 — раз и навсегда выбранная точка из X , а γk > 0 — детерминированные
скалярные множители.
Анализ сходимости. Приводимый ниже результат очень хорошо известен;
для полноты изложения приводим стандартное доказательство этого утвер-
ждения в Приложении.
163
Предложение 2. В предположениях A.1-A.3 при выборе длины шага
(18)
γk = [κ(k + 1)]-1
,
k = 1,2,...
для последовательности оценок xk(ωk) = zk любого сигнала x ∈ X , даваемой
процедурой СА (17) с ωk = (ηk,yk), определенными в (8) для любого k, выпол-
няется следующая оценка:
{
}
4M2
(19)
∥xk(ωk) - x∥2
≤
,
k = 0,1,...,
Eωk∼Pkx
2
κ2(k + 1)
где Px — распределение пары (η, y), обусловленное сигналом x.
3.2. Численный пример
Для иллюстрации изложенных выше построений приведем результаты
некоторых численных экспериментов. Для наглядности рассматриваем про-
стейшие ситуации, а именно:
• X = {x ∈ Rn : ∥x∥2 ≤ R};
• распределение Q регрессора η есть N (0, In);
• f — монотонное векторное поле на R, задаваемое одним из следующих
четырех способов:
A. f(s) = exp{s}/(1 + exp{s});
B. f(s) = s;
C. f(s) = max[s, 0];
D. f(s) = min[1, max[s, 0]].
• условное по η распределение y, индуцированное распределением Px, есть
— распределение Бернулли с вероятностью f(ηTx) исхода единица в слу-
чае A (т.е. этот случай соответствует логистической модели),
— гауссовское распределение N (f(ηTx), In) в случаях B-D.
Обратим внимание, что в рассматриваемом примере поле F (z) легко вычис-
ляется. Действительно, для всех z ∈ Rn имеем
(
)
T
zz
zzT
η=
η+ In -
η
∥z∥22
∥z∥2
2
<
=>
?
η⊥
и в силу независимости ηTz и η⊥ получаем
}
{zzTη
F (z) = Eη∼N(0,I){ηf(ηTz)} = Eη∼N(0,I)
f (ηTz)
=
∥z∥2
2
z
=
Eζ∼N(0,1){ζf(∥z∥2ζ)},
∥z∥2
т.е. F (z) пропорционально z/∥z∥2 с коэффициентом
h(∥z∥2) = Eζ∼N(0,1){ζf(∥z∥2ζ)}.
164
5,0
0
10
4,5
4,0
3,5
3,0
2,5
2,0
101
1,5
1,0
0,5
0
0,5
1,0
1,5
2,0
2,5
3,0
3,5
4,0
4,5
5,0
0
0,2
0,4 0,6 0,8 1,0 1,2 1,4 1,6 1,8 2,0
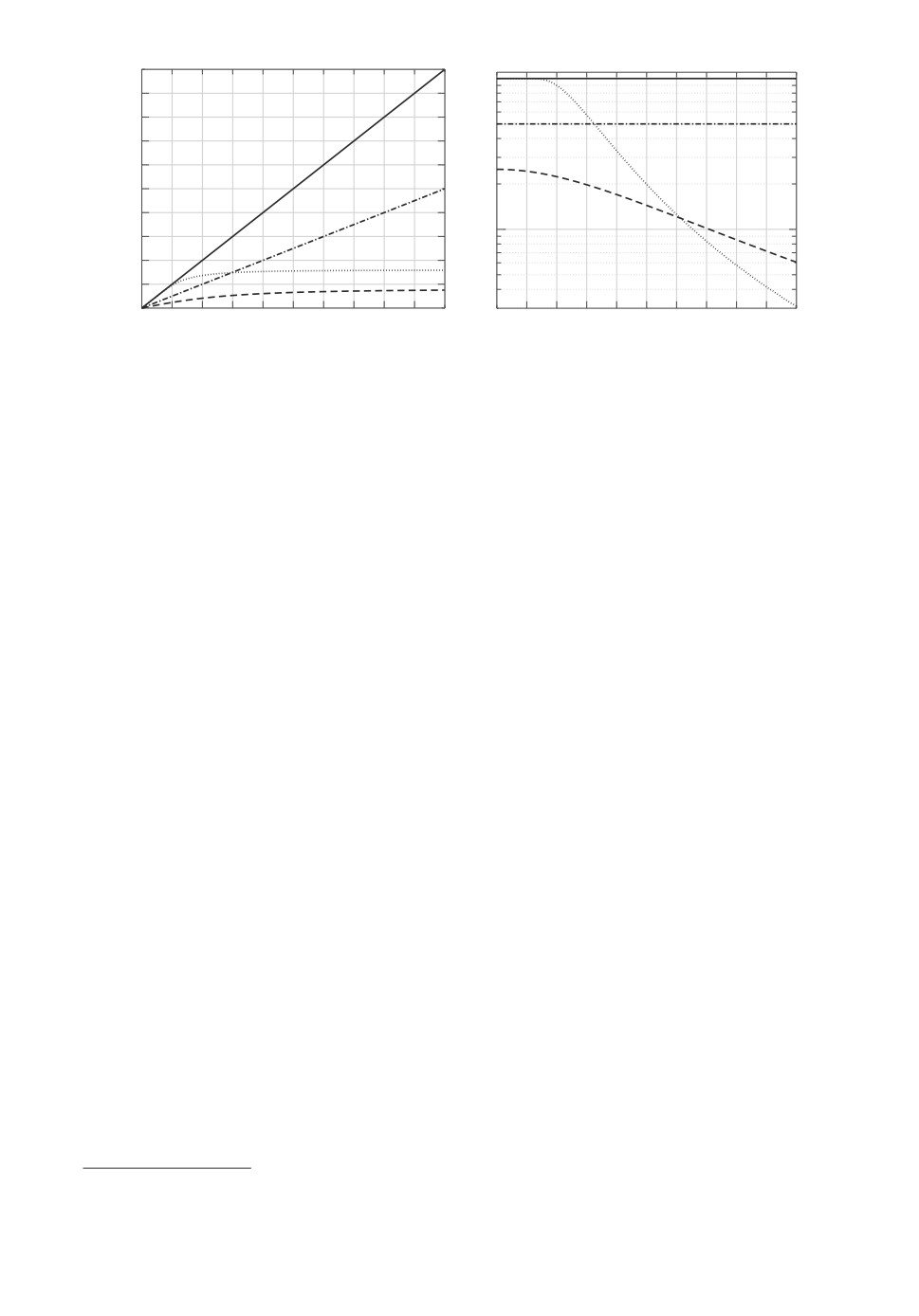
Рис. 1. Слева: функции h; справа: модули сильной монотонности операторов
F (·) на X = {z : ∥z∥2 ≤ R} как функции R. Пунктирные линии — случай A,
сплошные линии — случай B, штрих-пунктирные линии — случай C, точечные
линии — случай D.
На рис. 1 представлены графики функции h(t) для случаев A-D, а также за-
висимости модулей сильной монотонности соответствующих отображений F
на шаре X от радиуса R шара. Размерность n во всех экспериментах пола-
галась равной 100, а количество K наблюдений полагалось 400, 103, 4·103,
104 и 4 · 104. Для каждой комбинации параметров проводилось 10 модели-
рований сигнала x, порождающего наблюдения (8), генерируемого случайно
равномерно на единичной сфере (границе множества X ).
В каждом эксперименте вычислялись ВСА-оценки и СА-оценки (заметим,
что в случаях A и B оценки, даваемые ВСА, совпадают с МП-оценками).
Длина γk шага в СА выбиралась в соответствии с (18) при “эмпирическом”
выборе величины κ7. Точнее, полученные наблюдения ωk = (ηk, yk), k ≤ K
(8) использовались для построения СА-оценок в два этапа:
— на этапе настройки генерировался случайный “обучающий сигнал” x′ ∈ X ,
после чего генерировались метки y′k так, как если бы x′ являлся истинным
сигналом. Например, в случае A метке y′k придавалось значение единица с
вероятностью q = f(ηTkx′) и нуль с вероятностью 1 - q. После того как сге-
нерированы “обучающий сигнал” и соответствующие метки, к полученным
искусственным наблюдениям применялась схема СА с различными значения-
ми κ, вычислялась точность полученных оценок и выбиралось то значение κ,
которое приводит к наилучшему восстановлению сигнала;
— на этапе исполнения алгоритм СА прогонялся на фактических данных с
шагом (18), определяемым тем значением κ, которое было найдено на этапе
настройки.
Результаты некоторых численных экспериментов представлены на рис. 2.
Подчеркнем, что время вычислений включает в себя оба этапа. Вывод из
результатов экспериментов таков: будучи лишь немногим лучше СА по ка-
7 Для величины модуля сильной монотонности векторных полей F(·) могут быть ана-
литически получены нижние границы, однако это требует немалых усилий, а границы
оказываются консервативными.
165
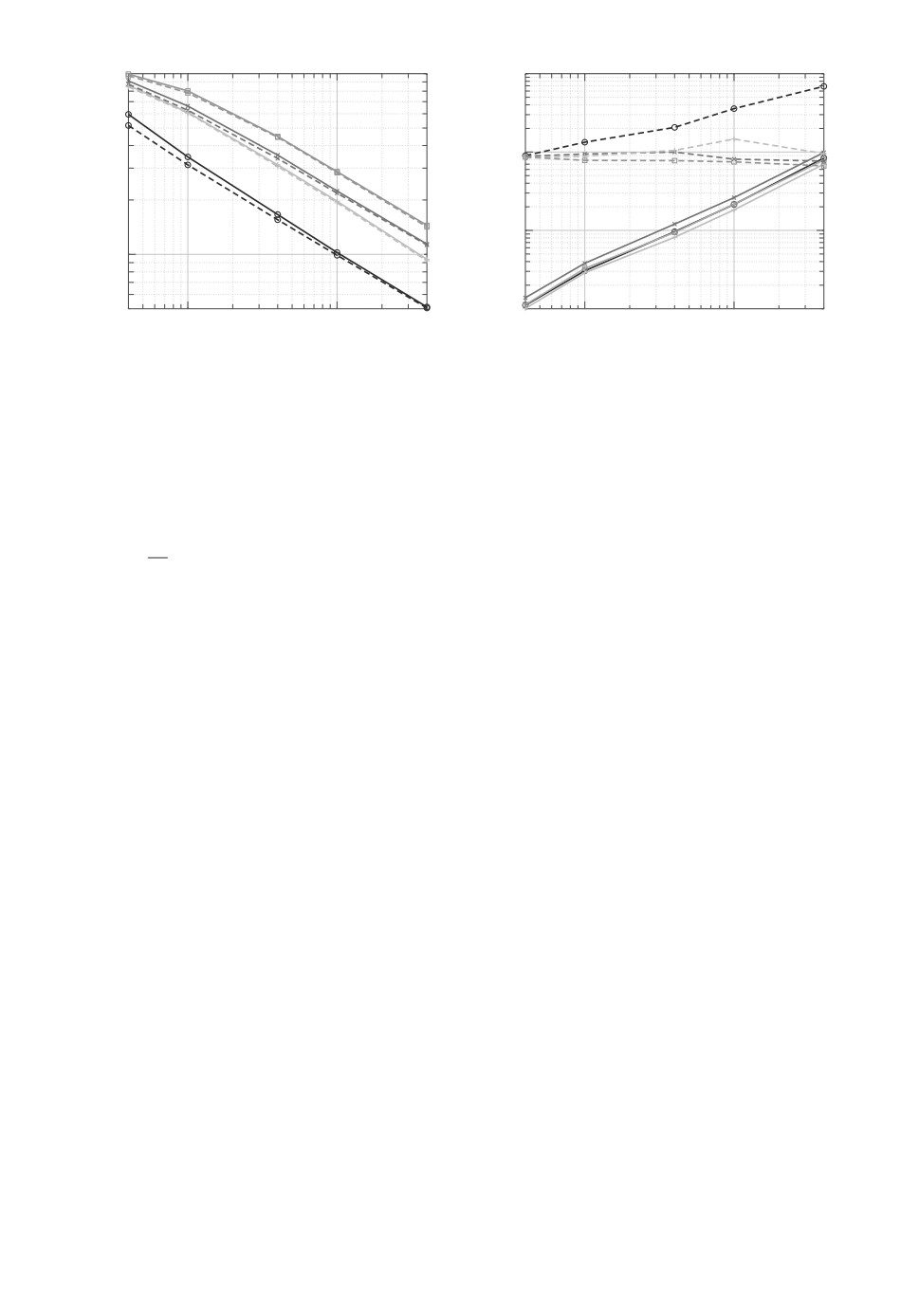
100
102
101
100
101
101
103
104
103
104
Cредняя ошибка оценивания
x
Время вычислений
k(k) x 2
Рис. 2. Численные результаты: средние ошибки и время вычислений для
СА-оценок (сплошная линия) и ВСА-оценок (пунктирная линия). o — слу-
чай A, × — случай B, + — случай C, □ — случай D.
честву оценивания, ВСА значительно проигрывает ему по времени исполне-
ния. Заметим также, что наблюдаемая в экспериментах зависимость ошибок
восст√новления от размера K выборки соответствует скорости сходимости
O(1/
K), установленной в предложении 2.
4. Случай “одного наблюдения”
Исследуем один специальный случай задачи оценивания, в котором по-
следовательность η1, . . . , ηK регрессоров в (8) детерминированная. На пер-
вый взгляд, такая формулировка не укладывается в рамки рассматриваемой
здесь общей постановки, в которой регрессоры предполагаются случайны-
ми независимыми, одинаково распределенными, выбираемыми из некоторого
распределения Q. Однако имеется возможность обойти это “противоречие”,
считая, что находимся в ситуации с одним наблюдением, где регрессором яв-
ляется матрица [η1, . . . , ηK ], а Q — вырожденное одноточечное распределение.
Конкретно, пусть имеем наблюдение
(20)
ω = (η,y) ∈ Rn×mK × RmK
(m, n, K — известные натуральные числа), а распределение Px наблюдений,
порожденных сигналом x ∈ Rn, имеет следующую форму:
• η — заданная детерминированная матрица, не зависящая от x;
• метка y случайна, и распределение y, индуцированное распределением Px,
имеет среднее φ(ηTx), где φ : RmK → RmK — некоторое заданное отобра-
жение.
В качестве информативного примера, связывающего рассматриваемую по-
становку с предыдущей, приведем конструкцию, в которой η = [η1, . . . , ηK ]
с n × m детерминированными “индивидуальными регрессорами” ηk, y =
= [y1; . . . ; yK ], имеющими “индивидуальные метки” yk ∈ Rm, которые условно
(при данном x) независимы по k и такими, что математические ожидания yk,
166
индуцированные сигналом x, имеют вид f(ηTkx) для некоторой f : Rm → Rm.
Положим φ([u1; . . . ; uK ]) = [f(u1); . . . ; f(uK )]. Полученная модель “одного на-
блюдения” представляет собой естественный аналог модели K наблюдений,
которая и рассматривалась до сих пор. Единственная разница состоит в том,
что индивидуальные регрессоры теперь образуют детерминированную после-
довательность, не являясь выборкой некоторой случайной матрицы.
Как и повсюду, в настоящей работе цель — использовать наблюдения (20)
для восстановления неизвестного сигнала x, порождающего, как объяснено
выше, распределение наблюдения. Формально находимся в ситуации K = 1
в исходной задаче восстановления, в которой носителем распределения Q яв-
ляется точка {η}, поэтому можем пользоваться всеми предложенными ранее
конструкциями. Конкретно:
• векторное поле F (z), соответствующее задаче, имеет вид
F (z) = ηφ(ηTz)
(ранее было Eη∼Q{ηf(ηTz)}), а векторное поле G(z) = F (z) - F (x), где x —
сигнал, породивший наблюдение (20), имеет вид
G(z) = E(η,y)∼Px {F (z) - ηy}
(ср. с (14)). Как и ранее, восстанавливаемый сигнал является нулем это-
го поля G(·). Обратим внимание на то, что теперь векторное поле F (z)
наблюдаемо, а векторное поле G по-прежнему является математическим
ожиданием (по Px) наблюдаемого векторного поля:
G(z) = E(η,y)∼Px {ηφ(ηTz) - ηy},
<
=>
?
Gy (z)
ср. с леммой 1.
• предположения A.1-A.2 теперь принимают следующий вид.
A.1′. Векторное поле φ(·) : RmK → RmK непрерывно и монотонно, так
что F (·) также непрерывно и монотонно.
A.2′. Множество X непусто, компактно и выпукло, а поле F сильно моно-
тонно на X с модулем κ > 0.
Простым достаточным условием выполнения приведенных выше условий
монотонности является положительная определенность матрицы ηηT в сово-
купности с сильной монотонностью φ на любом ограниченном множестве.
• Предположение A.3 удобно переписать в следующей эквивалентной фор-
ме:
A.3′. Для надлежащим образом выбранного σ ≥ 0 и всякого x ∈ X спра-
ведливо
{
}
E(η,y)∼Px
∥η[y - φ(ηTx)]∥22
≤σ2.
167
Теперь в новой постановке ВСА-оценка x(y) является единственным сла-
бым решением ВН VI(Gy, X ), а качество этой оценки дается следующим
утверждением.
Предложение 3. Пусть в рассматриваемой ситуации выполнены
предположения A.1′-A3′. Тогда для всякого x ∈ X и любой реализации со-
ответствующих наблюдений (η,y) (20) справедливо
(21)
∥x(y) - x∥2 ≤ κ-1∥ η[y - φ(ηTx)]∥2,
<
=>
?
Δ(x,y)
откуда также следует
(22)
E(η,y)∼Px {∥x(y) - x∥22} ≤ σ2/κ2.
Доказательство. Пусть x ∈ X — сигнал, породивший наблюдения (20)
и пусть G(z) = F (z) - F (x) — соответствующее векторное поле G. Имеем
Gy(z) = F (z) - ηy = F (z) - F (x) + [F (x) - ηy] =
= G(z) - η[y - φ(ηTx)] = G(z) - Δ(x, y).
При фиксированном y точка z = x(y) является слабым, а, следовательно, и
сильным (так как Gy(·) непрерывно) решением ВН VI(Gy , X ), что в силу
x ∈ X, влечет
0 ≤ GTy (z)[x - z] = GT(z)[x - z] - ΔT(x,y)[x - z],
откуда
-GT(z)[x - z] ≤ -ΔT(x,y)[x - z].
Кроме того, G(x) = 0, откуда GT(x)[x - z] = 0, так что приходим к
[G(x) - G(z)]T[x - z] ≤ -ΔT(x, y)[x - z],
откуда также следует
κ∥x - z∥22 ≤ -ΔT(x, y)[x - z],
поскольку наряду с F поле G сильно монотонно на X с модулем κ, а x, z ∈ X .
Применяя неравенство Коши, приходим к (21).
Пример 1. Пусть m = 1, φ сильно монотонна на всем RK с модулем
κφ > 0, а η в (20) выбирается случайно из “гауссовского ансамбля”, т.е. столб-
цы ηk матрицы η размера n × K — независимые случайные векторы с рас-
пределением N (0, In). Пусть шум в наблюдениях также гауссовский:
y = φ(ηTx) + λξ, ξ ∼ N(0,IK).
Хорошо известно, что при K/n → ∞ минимальное сингулярное значение
(n × n)-матрицы ηηT с большой вероятностью имеет порядок по крайней
168
100
70
65
60
55
50
45
40
35
101
30
25
20
15
102
103
104
103
104
Cредняя ошибка оценивания
x
k(k) x 2
Время вычисления, сек
Рис. 3. Средние ошибки и время вычисления для стандартного уклонения
λ = 1 (пунктир) и λ = 0,1 (сплошная линия).
мере O(1)K, откуда следует, что при K/n ≫ 1 для величины модуля силь-
ной монотонности поля F (·), “как правило”, верно κ ≥ O(1)Kκφ. Более того,
в ситуации при K/n → ∞ фробениусова норма матрицы η с большой веро-
√
ятностью имеет порядок не более O(1)
nK. Иными словами, для больших
значений K/n задача восстановления по описанному выше ансамблю, “как
правило”, удовлетворяет предположению 3 с κ = O(1)Kκφ и σ2 = O(λ2nK).
В результате (22) дает
{
}
λ2n
E(η,y)∼Px
∥x(y) - x∥22
≤ O(1)
,
[K ≫ n].
κ2φK
Известно, что для стандартного случая линейной регрессии, где φ(x) = κφx,
получающаяся граница почти оптимальна при условии, что X достаточно
велико.
Численная иллюстрация. В условиях рассмотренного выше примера поло-
жим m = 1, n = 100 и примем
φ(u) = arctan[u] := [arctan(u1); . . . ; arctan(uK )] : RK → RK .
Множество X — единичный шар {x ∈ Rn : ∥x∥2 ≤ 1}. В конкретном экспери-
менте η выбиралась случайно из гауссовского ансамбля, как описано выше,
сигнал x ∈ X , порождающий наблюдения (20), выбирался случайно, помеха
y-φ(ηTx) в наблюдении имеет распределение N(0,λ2IK). Результаты 10 экс-
периментов для каждой комбинации размера выборки и дисперсии λ2 шума
представлены на рис. 3.
5. Заключение
Рассмотрен подход к восстановлению сигналов в обобщенных линейных
моделях, основанный на сведении к решению стохастических вариационных
169
неравенств. Рассмотрены условия, при которых соответствующие ВН силь-
но монотонны. Показано, что в этом случае полученные оценки допускают
верхнюю границу на конечном времени для ожидаемой ошибки в ℓ2-норме,
сходящуюся к нулю со скоростью O(1/K) с ростом числа K наблюдений.
ПРИЛОЖЕНИЕ
Доказательство предложения
2.
Во-первых, заметим, что zk
являются детерминированными функциями zk = Zk(ωk) “начальных фраг-
ментов” ωk = {ωt, 1 ≤ t ≤ k} ∼ Px × . . . × Px
последовательности наблюдений
<
=>
?
Pkx
ωK = {ωk = (ηk,yk),1 ≤ k ≤ K}. Введем
1
1
Dk(ωk) =
∥Zk(ωk) - x∥22 =
∥zk - x∥22, dk = Eωk∼P k{Dk(ωk)},
x
2
2
где x ∈ X — сигнал, породивший наблюдения (8). Напомним, что метриче-
ская проекция на замкнутое выпуклое множество X является сжимающим
отображением:
∀(z ∈ Rn, u ∈ X ) : ∥ProjX [z] - u∥2 ≤ ∥z - u∥2.
Соответственно, при 1 ≤ k ≤ K имеем
1
Dk(ωk) =
∥ProjX [zk-1 - γkGωk (zk-1) - x]∥22 ≤
2
1
≤
∥zk-1 - γkGωk (zk-1) - x∥22 =
2
1
1
=
∥zk-1 - x∥22 - γkGTω
(zk-1)(zk-1 - x) +
γ2k∥Gω
(zk-1)∥22.
k
k
2
2
Беря математическое ожидание относительно ωk ∼ Pkx от обеих частей полу-
ченного неравенства и учитывая соотношения (13) вместе с тем фактом, что
zk-1 ∈ X, получаем
{
}
(Π.1)
G(zk-1)T(zk-1 - x)
+ 2γ2kM2.
dk ≤ dk-1 - γkEωk-1∼Pk-1x
Поскольку в данном случае поле G сильно монотонно на X с модулем κ > 0,
x является слабым решением ВН VI(G, X ), а zk-1 принимает значения в X ,
то, привлекая (16), получаем, что величина математического ожидания в
(Π.1) равна по крайней мере 2κdk, и приходим к соотношению
(Π.2)
dk ≤ (1 - 2κγk)dk-1 + 2γ2kM2.
Положим
2
2M
κS
1
S =
,
γk =
=
;
κ2
4M2(k + 1)
κ(k + 1)
170
заметим, что γk есть в точности длины шагов в (18). Проверим по индукции
по k, что соотношение
dk ≤ (k + 1)-1S
(∗k)
выполнено для k = 0, 1, . . . , K.
Основание индукции k = 0. Через D обозначим ∥·∥2-диаметр множества X ,
и пусть z± ∈ Z таково, что ∥z+ -z-∥2 = D. Согласно (13) имеем ∥F (z)∥2 ≤ M
для всех z ∈ X , а сильная монотонность поля G(·) на X влечет
[G(z+) - G(z-)]T[z+ - z-] = [F (z+) - F (z-)][z+ - z-] ≥ κ∥z+ - z-∥22 = κD2.
По неравенству Коши левая часть последнего неравенства не превосходит
2MD, поэтому
2M
D≤
,
κ
откуда S ≥ D2/2. С другой стороны, по определению d0 имеем d0 ≤ D2/2.
Таким образом, (∗0) выполнено.
Шаг индукции (∗k-1) ⇒ (∗k). Предположим теперь, что (∗k-1) выполнено
при некотором k, 1 ≤ k ≤ K, и докажем, что (∗k) также выполнено. Посколь-
ку κγk = (k + 1)-1 ≤ 1/2, то
dk ≤ dk-1(1 - 2κγk) + 2γ2kM2 ≤
[по (Π.2)]
S
≤
(1 - 2κγk) + 2γ2kM2 =
[по (∗k-1) и вследствие κγk ≤ 1/2]
k
(
)
)
S
2
S
S
(k-1
1
S
=
1-
+
=
+
≤
,
k
k+1
(k + 1)2
k+1
k
k+1
k+1
поэтому (∗k) справедливо. Индукция закончена. Остается заметить, что по
определению величины dk имеем dk =12 E{∥xk - x∥22}.
СПИСОК ЛИТЕРАТУРЫ
1. Devroye L., Györfi L., Lugosi G. A Probabilistic Theory of Pattern Recognition
(Stochastic Modelling and Applied Probability No. 31). N.Y.: Springer Sci. &
Business Media, 2013.
2. Nelder J.A., Wedderburn R.W.M. Generalized Linear Models // J. Royal Statist.
Soc., Ser. A (General). 1972. V. 135. No. 3. P. 370-384.
3. McCullagh P., Nelder J.A. Generalized Linear Models. Boca Raton: CRC Press,
1989.
4. Shapiro A., Dentcheva D., Ruszczynski A. Lectures on Stochastic Programming:
Modeling and Theory. 2nd ed. Philadelphia: SIAM, 2014.
5. Robbins H., Monro S. A Stochastic Approximation Method // Ann. Math. Statist.
1951. V. 22. No. 3. P. 400-407.
6. Wolfowitz J. On the Stochastic Approximation Method of Robbins and Monro //
Ann. Math. Statist. 1952. V. 23. No. 3. P. 457-461.
171
7.
Barndorff-Nielsen O. Information and Exponential Families in Statistical Theory.
N.Y.: Wiley, 1978.
8.
Feigin P.D. Conditional Exponential Families and a Representation Theorem for
Asympotic Inference // Ann. Statist. 1981. V. 9. No. 3. P. 597-603.
9.
Rosenblatt F. The Perceptron: A Probabilistic Model for Information Storage and
Organization in the Brain // Psychol. Rev. 1958. V. 65. No. 6. P. 386-408.
10.
Block H.-D. The perceptron: A model for brain functioning. I // Rev. Modern Phys.
1962. V. 134. No. 1. P. 123.
11.
Helmbold D.P., Warmuth M.K. On Weak Learning // J. Comput. Syst. Sci. 1995.
V. 50. No. 3. P. 551-573.
12.
Айзерман М.А., Браверман Э.М., Розоноэр Л.И. Теоретические основы метода
потенциальных функций в задаче об обучении автоматов разделению входных
ситуаций на классы // АиТ. 1964. Т. 25. № 6. С. 917-936.
Aizerman M.A., Braverman E.M., Rozonoer L.I. Theoretical Foundations of the
Potential Function Method in Pattern Recognition Learning // Autom. Remote
Control. 1964. V. 25. No. 6. P. 821-837.
13.
Девятериков И.П., Пропой А.И., Цыпкин Я.З. О рекуррентных алгоритмах
обучения распознаванию образов // АиТ. 1967. № 1. С. 122-132.
Devyaterikov I.P., Propoi A.I., Tsypkin Ya.Z. Iterative Learning Algorithms for
Pattern Recognition // Autom. Remote Control. 1967. V. 28. No. 1. P. 108-117.
14.
Айзерман М.А., Браверман Э.М., Розоноэр Л.И. Метод потенциальных функций
в теории обучения машин. М.: Наука, 1970.
15.
Bousquet O., Boucheron S., Lugosi G. Introduction to Statistical Learning Theory /
Bousquet O., von Luxburg U., Rätsch G. (eds) Advanced Lectures on Machine
Learning. ML 2003. Lecture Notes in Computer Science, vol 3176. Springer, Berlin,
Heidelberg. P. 169-207.
16.
Sridharan K., Shalev-Shwartz S., Srebro N. Fast Rates for Regularized Objectives //
Advances in Neural Information Proc. Syst. No. 21. 2009. P. 1545-1552.
17.
Nemirovski A., Onn S., Rothblum U. Accuracy Ccertificates for Computational
Problems with Convex Structure // Math. Oper. Res. 2010. V. 35. No. 1. P. 52-78.
18.
Bousquet O., Elisseeff A. Stability and Generalization // J. Machine Learning Res.
2002. V. 2. P. 499-526.
19.
Rakhlin A., Mukherjee S., Poggio T. Stability Results in Learning Theory // Anal.
Appl. 2005. V. 3. No. 4. P. 397-417.
20.
Shalev-Shwartz S., Shamir O., Srebro N., Sridharan K. Stochastic Convex
Optimization // Conf. Learning Theory. 2009.
21.
Kiefer J., Wolfowitz J. Stochastic Estimation of the Maximum of a Regression
Function // Ann. Mat. Statist. 1952. V. 23. No. 3. P. 462-466.
Статья представлена к публикации членом редколлегии А.В. Назиным.
Поступила в редакцию 19.07.2018
После доработки 12.09.2018
Принята к публикации 08.11.2019
172