Автоматика и телемеханика, № 2, 2019
© 2019 г. И.А. ХОДАШИНСКИЙ, д-р техн. наук (hodashn@rambler.ru),
К.С. САРИН, канд. техн. наук (sks@security.tomsk.ru)
(Томский университет систем управления и радиоэлектроники)
ОТБОР КЛАССИФИЦИРУЮЩИХ ПРИЗНАКОВ
С ПОМОЩЬЮ ПОПУЛЯЦИОННОГО СЛУЧАЙНОГО
ПОИСКА С ПАМЯТЬЮ1
Предложен новый метод отбора признаков. Концепция, лежащая в ос-
нове предлагаемого метода, — сочетание стратегий случайного и эвристи-
ческого поиска. Решение представляется в виде бинарного вектора, раз-
мерность которого определена количеством признаков в наборе данных.
Генерация новых решений проводится случайным образом с использова-
нием нормального и равномерного распределения. Эвристика, лежащая в
основе предлагаемого подхода, формулируется следующим образом: шанс
признака попасть в следующую генерацию пропорционален частоте при-
сутствия этого признака в предыдущих лучших решениях. Предложен-
ный метод протестирован на нескольких наборах данных из репозитория
KEEL. Проведено сравнение с алгоритмами-аналогами.
Ключевые слова: отбор признаков, нечеткий классификатор, бинарная
оптимизация, метаэвристики, случайный поиск с памятью.
DOI: 10.1134/S0005231019020107
1. Введение
Снижение размерности входных данных как этап предварительной обра-
ботки встречается во многих областях, таких как распознавание образов, ма-
шинное обучение, интеллектуальный анализ данных. Цель этапа — повыше-
ние эффективности хранения и обработки данных путем нахождения мини-
мального набора признаков и/или репрезентативного подмножества входных
данных меньшего размера. Снижение размерности обусловлено необходимо-
стью убрать те данные исходного набора, которые являются избыточными
или выбросами и могут ухудшить эффективность классификации [1, 2]. При
классификации больших наборов данных время построения классификаторов
значительно возрастает, главным образом, из-за вычисления целевой функ-
ции. Ускорение обучения возможно как за счет сокращения размера обучаю-
щей выборки, так и за счет сокращения количества признаков (атрибутов,
переменных). Однако в данной работе рассматривается только проблема со-
кращения количества признаков.
Исследования в области отбора признаков начались в 1960-е гг. Автор [3]
описал изменение точности байесовского классификатора в зависимости от
количества признаков. С тех пор интерес к этому научному направлению не
1 Работа выполнена при финансовой поддержке Российского фонда фундаментальных
исследований (проект № 16-07-00034).
161
ослабевает, число книг и статей по данной проблеме постоянно растет [4]. Вы-
деляют два подхода к решению проблемы получения минимального набора
признаков: отбор информативных признаков (feature selection) и формирова-
ние или выделение множества новых признаков (feature construction, feature
extraction). Классическими методами формирования множества новых при-
знаков являются метод главных компонент, линейный дискриминантный и
корреляционный анализы. Методы отбора не предполагают создания нового
множества признаков, в процессе реализации этого метода сокращается ис-
ходное пространство признаков. Применение методов отбора или формирова-
ния новых признаков зависит от области приложения и классифицируемого
набора данных [5].
Методы отбора признаков можно разделить на две категории: фильтры
(filter) и обертки (wrapper) [4, 6]. Фильтры основаны на определенных метри-
ках, таких как энтропия, распределение вероятностей или взаимная инфор-
мация [7], и не предполагают использования классифицирующего алгоритма
в процессе работы. Обертки используют классификатор для оценки подмно-
жества признаков, при этом сам классификатор как бы «завернут» в цикл
отбора признаков. Методы фильтров и оберток имеют свои достоинства и
недостатки. Достоинствами методов, основанных на фильтрах, являются их
масштабируемость и более высокая скорость выполнения. Общий недоста-
ток заключается в том, что отсутствие взаимодействия с классификатором и
игнорирование учета зависимости между признаками приводят к различной
для разных классификаторов невысокой точности классификации.
Преимущество методов оберток заключается в том, что они работают
совместно с конкретным алгоритмом классификации и учитывают синер-
гетический эффект от совместного использования отобранных признаков.
Недостатками методов оберток являются более высокий риск переобучения
и большие временные затраты по причине необходимости вычисления точ-
ности классификации [5]. Метод оберток предполагает использование кон-
кретного классификатора. Выполняется метод оберток в два этапа: 1) поиск
подмножества признаков; 2) оценка качества подмножества признаков на ос-
нове точности классификатора, построенного на отобранном подмножестве.
Указанные этапы повторяются до тех пор, пока не будут выполнены задан-
ные условия останова. Поиск подмножества признаков может быть выполнен
полным перебором, вычислительная сложность которого равна O(2|A|), где
A — исходное множество признаков. Если |A| велико, полный перебор неце-
лесообразен. Поэтому для поиска подмножества признаков применяют иные
стратегии, которые можно разделить на две категории: детерминированные
и стохастические (или метаэвристические) методы. Типичным примером де-
терминированного метода является жадный алгоритм, который итеративно
добавляет или удаляет признаки, пока не будет достигнут необходимый эф-
фект. Алгоритм обладает полиномиальной сложностью, прост в реализации и
эффективен для наборов данных с небольшим множеством признаков. Одна-
ко у данного алгоритма есть существенный недостаток, он не учитывает вза-
имозависимости между признаками. Стохастические методы способны найти
субоптимальные решения как с точки зрения точности, так и размера подмно-
жества признаков, примером является Las Vegas Filter алгоритм, быстро со-
162
кращающий количество признаков на ранних стадиях и способный находить
оптимальные решения, если позволяют вычислительные ресурсы [8]. В реаль-
ных приложениях специалисты больше заинтересованы в получении приемле-
мых решений в разумные сроки, и необязательно эти решения должны быть
гарантированно оптимальными. Использование метаэвристических методов
позволяет получить такие решения без исследования всего пространства по-
иска [9]. Для решения проблемы отбора признаков давно и успешно применя-
ются роевые и эволюционные алгоритмы, такие как генетический алгоритм
[10, 11], алгоритм роящихся частиц [12, 13], алгоритмы муравьиной [14] и
пчелиной колонии [15, 16], гармонический поиск [17, 18], дифференциальная
эволюция [19].
Цель работы — описание нового метода обертки, где в качестве классифи-
цирующего алгоритма используется нечеткий классификатор. Достоинство
нечетких классификаторов — понятность пользователю полученных правил
и их интерпретируемость. Нечеткий классификатор состоит из ЕСЛИ-ТО
правил с нечеткими антецедентами (ЕСЛИ-часть) и метками класса в кон-
секвентах (ТО-часть). Антецедентные части правил разбивают входное про-
странство признаков на множество нечетких областей, а консеквенты задают
выход классификатора, помечая эти области меткой класса.
2. Постановка задачи
Пусть имеется универсум U = (A, G), где A = {x1, . . . , xn} — множе-
ство входных признаков, G = {1, . . . , m} — множество меток классов. Пусть
X = x1 × ... × xn ∈ ℜn — n мерное пространство признаков. Объект в задан-
ном универсуме характеризуется своим вектором значений признаков.
Задача классификации заключается в предсказании класса объекта по
вектору значений признаков. Задача отбора признаков заключается в поиске
на заданном множестве признаков X такого их подмножества, которое при
уменьшении числа признаков не приводило бы к существенному уменьшению
точности классификации или увеличивало бы ее. Решение представляется в
виде вектора S = (s1, . . . , sn)T, где si = 0 означает, что i-й признак не участ-
вует в классификации, si = 1 означает, что i-й признак используется клас-
сификатором. Для каждого подмножества признаков оценивается точность
классификации. Традиционный классификатор может быть определен как
функция
f : ℜn → {0,1}m,
где f(x; Θ) = (β1, . . . , βm)T, причем βi = 1, а βj = 0, j = 1, m , i = j, когда
объект, заданный вектором x, принадлежит к классу i; Θ — вектор парамет-
ров классификатора.
Нечеткий классификатор может быть представлен в виде функции, ко-
торая присваивает точке в пространстве входных признаков метки класса с
вычисляемой степенью уверенности:
f : ℜn → [0,g]m,
163
Рис. 1. Схема построения классификатора.
где g ∈ ℜ и определяется индивидуальными особенностями классификато-
ра. Основой нечеткого классификатора является продукционное правило сле-
дующего вида:
Ri : ЕСЛИ s1 ∧ x1 = A1i И ... И sn ∧ xn = Ani ТО y = Li,
где Li ∈ {1, . . . , m} — выход i-го правила (i = 1, r), r — число правил, Aki —
нечеткий терм, характеризующий k-й признак в i-м правиле (k = 1, n); запись
sk ∧ xk указывает на наличие (sk = 1) или отсутствие (sk = 0) признака в
классификаторе.
Выход нечеткого классификатора представляет собой вектор (β1, . . . , βm)T,
где
∑
∏
βj =
μki(xk),
(i=1,r);(Li=j) k=1
j = 1,m, μki(xk) — значение функции принадлежности нечеткого терма Aki
в точке xk. На основе полученного вектора класс определяется по принципу
«команда победителей получает всё»:
class = arg max βj .
j=1,m
На таблице наблюдений {(xp, cp), p = 1, z} мера точности классификации мо-
жет быть выражена следующим образом:
z
{ 1, если cp = arg max fj(xp; Θ, S),
j=1,m
p=1
0 иначе
(1)
E(Θ, S) =
,
z
164
где f(xp; Θ, S) — выход нечеткого классификатора с параметрами Θ и при-
знаками S в точке xp. Проблема построения нечеткого классификатора сво-
дится к поиску максимума указанной функции в пространстве S и Θ =
= (θ1, . . . , θD):
⎧
⎪
E(Θ, S) → max,
⎨
θimin ≤ θi ≤ θimax, i = 1,D,
⎪
⎩ sj ∈ {0,1}, j = 1,n,
где θimin, θimax — нижняя и верхняя границы каждого параметра соответствен-
но. Проблема относится к классу NP-трудных, поэтому невозможно гаран-
тировать получение оптимального решения за исключением случаев, когда
выполняется полный перебор в пространстве решений. В данной работе пред-
лагается решать указанную проблему с помощью популяционного случайного
поиска с памятью. Схема представлена на рис. 1.
3. Алгоритм популяционного случайного поиска с памятью
Алгоритм основан на сочетании стратегий случайного и эвристического
поиска. Важнейшим элементом алгоритма является кодирующий признаки
вектор-решение S. Работа алгоритма начинается с формирования популя-
ции — набора сгенерированных случайным или иным образом векторов S.
Число векторов в популяции — это наперед заданное целое число, назы-
ваемое размером популяции. Для каждого вектора вычисляется мера точ-
ности классификации E (формула 1). На каждой итерации определяется
вектор с максимальным значением E — лучшее решение на текущей ите-
рации. Другим важным элементом алгоритма является вектор B, в кото-
ром bi хранит число появлений i-го признака в лучших решениях на преды-
дущих итерациях, размерность этого вектора совпадает с размерностью S.
Вектор B служит для реализации следующей эвристики: шанс признака по-
пасть в новую популяцию пропорционален частоте присутствия этого при-
знака в предыдущих лучших решениях. Новая популяция формируется на
основе указанной эвристики и случайного поиска. Нормально распределен-
ная случайная величина u ∼ N(0,σg) определяет механизм сокращения
или добавления признаков, а также количество сокращенных/добавленных
признаков. Если значение u больше или равно нулю, то происходит до-
бавление новых признаков путем увеличения количества единиц в векто-
ре S, иначе происходит сокращение признаков. Количество потенциально
возможных изменяемых признаков определяется размерностью вектора S,
равной n, и числом единиц в векторе S, положим, равное r. Если значе-
ние u меньше нуля, то среди r элементов вектора S, содержащих едини-
цы, случайным образом выбираются l признаков-кандидатов на сокращение
по формуле l = round(r| tanh(u)|). Определение числа добавляемых призна-
ков выполняется по формуле l = round((n - r)| tanh(u)|). Однако собствен-
но изменение значения элемента si определяется значением bi ∈ B, а имен-
но, относительной частотой появления i-го признака в лучших решениях,
вычисляемой на итерации t ≥ tg как bi/t, где tg — итерация, по дости-
165
жении которой вероятность включения признака определяется относитель-
ной частотой. Тогда новое значение si будет равно 1, если rand(0, 1) ≤ bi/t,
иначе si будет равно
0. Чтобы избежать ранней сходимости алгорит-
ма, необходимо добавить ограничение на значение относительной частоты:
1 - pg ≤ p ≤ pg, где pg — пороговое значение. Алгоритм выполняется итера-
ционно, после выполнения заданного числа итераций производится декодиро-
вание лучшего вектора в полученное решение, которое интерпретируется как
оптимальное.
4. Алгоритм построения нечеткого классификатора
Алгоритм основан на нечеткой кластеризации обучающих данных. Каж-
дому кластеру ставится в соответствие нечеткое правило. ТО-часть правила
определяет класс, функции принадлежности нечетких термов имеют гауссо-
вый тип
μ=e-(xσs)2
с параметром среднего, определяемого центром кластера, и с отклонением,
которое представляет собой средневзвешенное квадратичное отклонение обу-
чающих данных относительно центра. Одному классу соответствует один
или несколько кластеров. Кластеризация выполняется известным алгорит-
мом Fuzzy C-means (FCM) [20]. FCM — итеративный алгоритм, в котором на
каждой итерации происходит определение степени принадлежности данных
кластеру и новых положений центров кластеров:
∑
xkj
(μkj)h
1
μki =
(
)2/(h-1) , vij
= k=1m
,
∑
∥ xk- vi∥
∑ (μkj )h
∥ xk- vj∥
j=1
k=1
где c — число кластеров, μki — степень принадлежности k-го экземпляра дан-
ных i-му кластеру, vi — вектор центра i-го кластера, h — константа больше 1
(обычно h = 2). Алгоритм начинает свою работу с определения значений век-
торов центров кластеров случайным образом и заканчивает, когда выполнено
условие
∑
∥vnewi - voldi∥ ≤ ε,
i=1
где voldi и vnewi вектор i-го кластера до и после итерации соответственно, ε —
малая величина (в данной работе ε = 0,0001). Число кластеров c задается
перед выполнением алгоритма.
Ниже представлен алгоритм построения нечеткого классификатора. На
вход алгоритма подается таблица наблюдений из z элементов и вектор c, в
котором cj соответствует числу кластеров, на которое должно быть разбито
пространство данных j-го класса, j = 1, m (в экспериментах данной рабо-
ты cj = 1).
166
Алгоритм построения нечеткого классификатора.
1. Инициализация k = 1.
2. Разбить пространство данных k-го класса на ck кластеров алгоритмом
FCM.
3. Добавить в базу правил классификатора правила, соответствующие
каждому кластеру. Выходом правила, соответствующего i-му кластеру, будет
метка k-го класса, а параметрами среднего и отклонения функции принад-
лежности j-й переменной — соответственно
>
(
)
?
?
∑
?2
μpi(xpj - vij)2
?
?
p=1
sj = vij, σj =
?
√
∑
μpi
p=1
4. Если рассмотрены все классы (k = m), то завершить работу алгоритма,
иначе k = k + 1 и перейти на шаг 2.
5. Эксперимент
5.1. Эмпирический критерий оценки эффективности алгоритма
Для сравнения эффективности алгоритмов отбора признаков необходим
критерий, позволяющий оценить их работу. Задача отбора сводится к на-
хождению такого множества признаков, на котором классификатор показы-
вал бы лучшую точность классификации при минимально возможном чис-
ле пробных вычислений точности в процессе работы алгоритма. Точность
классификации является целевой функцией при отборе признаков по мето-
ду обертки, для вычисления ее значения необходимо построение классифи-
катора на обучающих данных с пробным множеством признаков. Основная
вычислительная нагрузка ложится на получение этого значения. Алгоритм
считается эффективным, если с его помощью найдено множество признаков,
на котором построенный классификатор показывает лучшую точность клас-
сификации. Если точности совпадают, то эффективным считается алгоритм с
меньшим числом пробных вычислений точности. Поскольку в данной работе
производится сравнение популяционных алгоритмов, вычислительной едини-
цей будем считать итерацию. Чтобы трудоемкость итераций была одинакова,
для всех сравниваемых алгоритмов выбран одинаковый размер популяции.
На основании изложенного выше предлагается эмпирически оценить эффек-
тивность алгоритмов. Если проводить сравнение алгоритмов на одном на-
боре данных, то в качестве критерия эффективности можно взять точность
классификации на итерации tmin, на которой найдено лучшее решение од-
ним из алгоритмов. При оценивании работы на нескольких наборах данных
необходимо учитывать суммарную составляющую эффективности каждого
алгоритма для каждого набора данных. Суммарная составляющая основана
на нормированных значениях эффективности алгоритма по каждому набо-
ру. Введем эмпирический критерий эффективности работы алгоритма отбора
признаков ξ, который вычисляется приведенным ниже способом.
167
Алгоритм нахождения значения критерия эффективности.
Вход: a — число вариантов алгоритмов отбора признаков, d — число на-
боров данных.
Выход: ξi — значение критерия эффективности для каждого варианта ал-
горитма, где i = 1, a .
1. Найти tmin и Ei
(i = 1, a, j = 1, d), где Ei
— усредненное значение
jtjmin
jtj
min
точности i-го алгоритма на j-м наборе данных и итерации tjmin.
2. Провести суммирование нормированных значений точностей:
i
E
- min
Ei
∑
jtj
jtjmin
min
i=1,n
ξi =
i
max
E
- min
Ei
j=1
jtj
jtj
i=1,n
min
i=1,n
min
Большее значение критерия соответствует более эффективному алгоритму.
Значение критерия варьируется в диапазоне [0, a].
5.2. Определение рабочих параметров алгоритма
Для определения рабочих значений параметров σg, pg, tg алгоритма пред-
лагается найти критерий эффективности работы с различными значениями
параметров и выбрать те, на которых алгоритм покажет лучший резуль-
тат. Для оценки эффективности использовались 10 реальных наборов дан-
на в табл. 1. Использовались следующие варианты параметров: σg ∈ {1, 2},
pg ∈ {0,75, 0,85, 1}, tg ∈ {1, 50, 200}. Точность классификации на каждой
итерации для вычисления критерия эффективности бралась как среднее зна-
чение точности по 20 запускам алгоритма. Максимальное число итераций
t = 300, размер популяции — 20. Лучшее значение критерия эффективности
получил алгоритм с параметрами pg = 0,75, tg = 1 и σg = 2. Указанные зна-
чения параметров являются рабочими для выполнения сравнений с другими
алгоритмами.
Таблица 1. Наборы данных для проведения эксперимента
Название набора Число переменных Число классов Объем выборки
Wine
13
3
178
Heart
13
2
270
Cleveland
13
5
297
Vowel
13
11
990
Australian
14
2
690
Vehicle
18
4
846
Hepatitis
19
2
80
Bands
19
2
365
Ionosphere
33
2
351
Dermatology
34
6
358
168
5.3. Сравнение с алгоритмами-аналогами
Эффективность алгоритма случайного поиска с памятью (АСПП) срав-
нивалась с алгоритмом роящихся частиц (АРЧ) [21], бинарным алгоритмом
кукушкин поиск» (АКП) [22] и алгоритмом случайного поиска (АСП). В ал-
горитмах использовался размер популяции, равный 20, максимальное число
итераций t = 300. Точность классификации на каждой итерации вычисля-
лась как среднее значение по 20 запускам алгоритма. Параметры алгорит-
мов «кукушкин поиск» и роящихся частиц устанавливались в значения, ре-
комендуемые в [21, 22] соответственно. В табл. 2 показаны значения точно-
сти классификации на итерации tmin; в позициях лучших значений в скобках
приведено tmin. В табл. 3 приведены значения критерия ξ, алгоритм АСПП
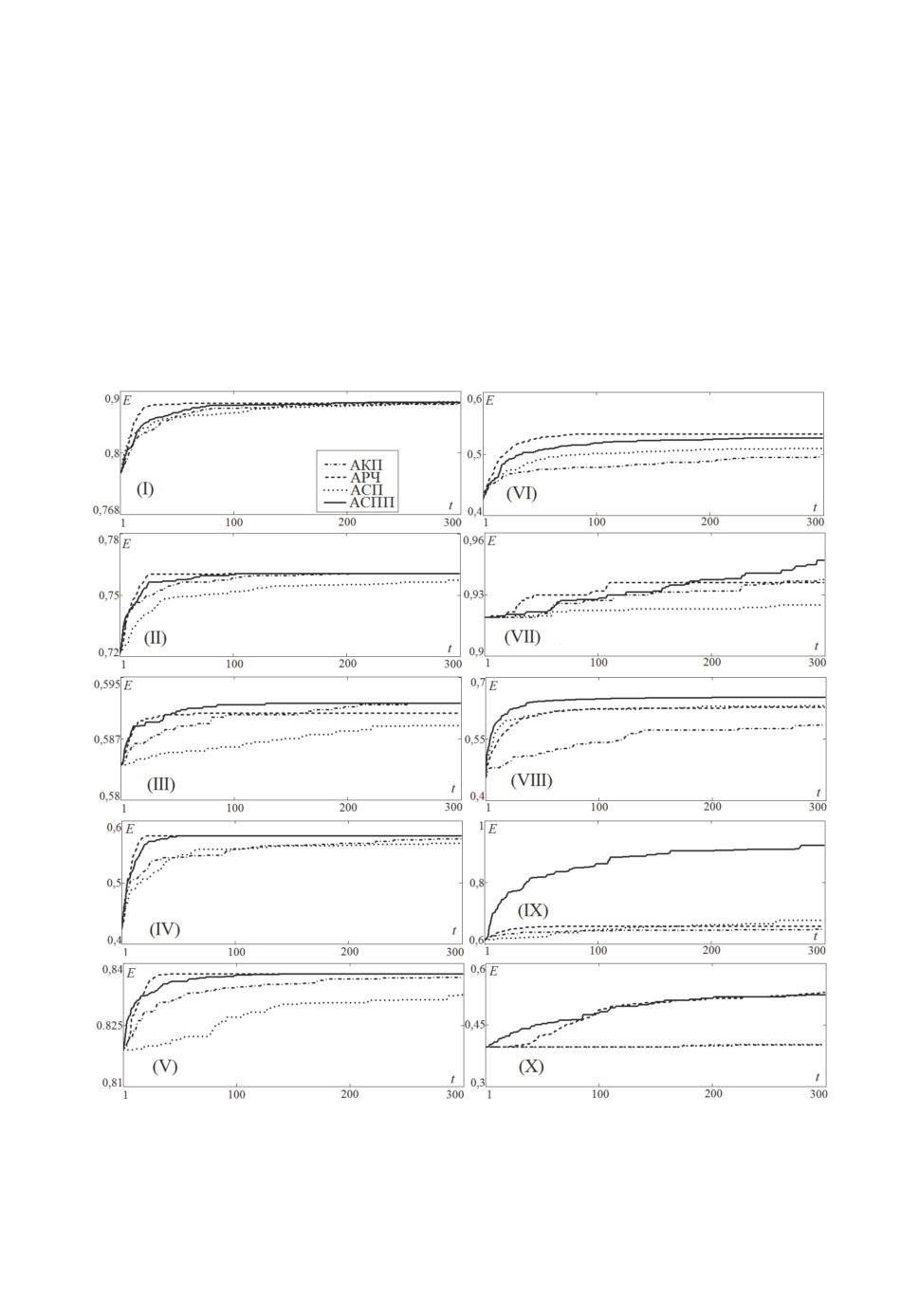
Рис. 2. Зависимость точности классификации от итерации на наборах данных
(I) — Wine, (II) — Heart, (III) — Cleveland, (IV) — Vowel, (V) — Australian,
(VI) — Vehicle, (VII) — Hepatitis, (VIII) — Bands, (IX) — Ionosphere, (X) —
Dermatology.
169
Таблица 2. Значения точности классификации
Название набора АКП АРЧ
АСП
АСПП
Wine
0,879
0,881
0,883 (279)
0,882
Heart
0,757
0,761 (94)
0,751
0,759
Cleveland
0,589
0,59
0,586
0,592 (54)
Vowel
0,518
0,576 (21)
0,505
0,562
Australian
0,828
0,837 (28)
0,82
0,833
Vehicle
0,478
0,532 (81)
0,499
0,514
Hepatitis
0,937
0,936
0,925
0,947 (294)
Bands
0,571
0,628
0,63
0,652 (216)
Ionosphere
0,647
0,658
0,677
0,921 (280)
Dermatology
0,401
0,53(296)
0,402
0,524
Таблица 3. Значения критерия эффективности
Название набора АКП АРЧ АСП АСПП
Wine
0
0,43
1
0,8
Heart
0,66
1
0
0,9
Cleveland
0,62
0,88
0
1
Vowel
0,18
1
0
0,81
Australian
0,5
1
0
0,78
Vehicle
0
1
0,38
0,67
Hepatitis
0,53
0,5
0
1
Bands
0
0,71
0,73
1
Ionosphere
0
0,04
0,11
1
Dermatology
0
1
0,01
0,95
ξ
2,49
7,57
2,23
8,91
на каждом наборе данных показал либо лучшее, либо второе по значимости
решение.
На рис. 2 представлены зависимости точности классификации от числа
итераций поиска. Точность классификации определялась средним значением
по 20 запускам алгоритмов. Бинарные алгоритмы роящихся частиц и слу-
чайного поиска с памятью демонстрируют наиболее быструю сходимость к
лучшему значению.
6. Заключение
В статье предложен подход к отбору признаков, основанный на популяци-
онном случайном поиске с памятью. Отбор признаков выполняется по методу
оберток с использованием нечеткого классификатора. Алгоритм отбора при-
знаков основан на стратегии случайного поиска, управляемого следующей
эвристикой: шанс признака попасть в новую популяцию пропорционален ча-
стоте присутствия этого признака в предыдущих лучших решениях. Важным
преимуществом алгоритма является сбалансированное сочетание диверсифи-
кации и интенсификации поиска решений. Диверсификацию обеспечивает
170
случайный поиск по всему пространству решений, интенсификацию — при-
нятая эвристика, позволяющая помнить лучшие решения и тем самым учи-
тывать ландшафт пространства поиска. Описан способ задания параметров
алгоритма отбора признаков. Также был рассмотрен алгоритм построения
нечеткого классификатора, основанный на нечеткой кластеризации обучаю-
щих данных. Проведено сравнение предложенного алгоритма отбора призна-
ков с общеизвестными алгоритмами-аналогами. Результаты сравнений сви-
детельствуют о конкурентоспособности предлагаемого подхода.
Дальнейшее развитие алгоритма предполагает исследование повышения
диверсификации за счет генерации исходных решений на основе квазислу-
чайных последовательностей и хаотической оппозиции. Адаптационные воз-
можности алгоритма предполагается увеличить путем изменения значений
отклонения при генерации нормально распределенных чисел и путем введе-
ния изменяемого параметра в функцию гиперболического тангенса. Еще одна
предполагаемая модификация алгоритма — введение списка ранее сформиро-
ванных решений, что позволит предотвратить преждевременную сходимость
алгоритма и сократить время работы алгоритма.
СПИСОК ЛИТЕРАТУРЫ
1.
Lin W-C., Tsai C-F., Ke S-W., Hung C.-W., Eberle W. Learning to detect
representative data for large scale instance selection // J. Syst. Software. 2015.
V. 106. P. 1-8.
2.
Tsai C-F., Chen Z-Y. Towards high dimensional instance selection: An evolutionary
approach // Decision Support Syst. 2014. V. 61. P. 79-92.
3.
Hughes G. On the mean accuracy of statistical pattern recognizers // IEEE Trans.
Inf. Theory. 1968. V. 14. No. 1. P. 55-63.
4.
Bolon-Canedo V., Sanchez-Marono N., Alonso-Betanzos A. Feature Selection for
High-Dimensional Data. London: Springer, 2015.
5.
Veerabhadrappa, Rangarajan L. Multi-level dimensionality reduction methods using
feature selection and feature extraction // Int. J. Artif. Intell. Appl. 2010. V. 1.
No. 4. P. 54-68.
6.
Kohavi R., John G.H. Wrappers for feature subset selection // Artif. Intell. 1997.
V. 97. No. 1. P. 273-324.
7.
Цурко В.В., Михальский А.И. Метод контрастирования для отбора информа-
тивных признаков по эмпирическим данным // АиТ. 2016. № 12. С. 136-154.
Tsurko V.V., Michalski A.I. The Contrast Features Selection with Empirical Data //
Autom. Remote Control. 2016. V. 77. No. 12. P. 2212-2226.
8.
Dash M., Liu H. Consistency-based search in feature selection // Artif. Intell. 2003.
V. 151. No. 1-2. P. 155-176.
9.
Yusta S.C. Different metaheuristic strategies to solve the feature selection
problem // Pattern Recognit. Lett. 2009. V. 30. No. 5. P. 525-534.
10.
Leardi R., Boggia R., Terrile M. Genetic algorithms as a strategy for feature
selection // J. Chemom. 1992. V. 6. No. 5. P. 267-281.
11.
Yang J., Honavar V. Feature subset selection using a genetic algorithm // IEEE
Intell. Syst. 1998. V. 13. No. 2. P. 44-49.
12.
Chuang L.-Y., Tsai S.-W., Yang C.-H. Improved binary particle swarm optimization
using catfish effect for feature selection // Expert Syst. Appl. 2011. V. 38. No. 10.
P. 12699-12707.
171
13. Xue B., Zhang M., Browne W.N. Particle swarm optimisation for feature selection in
classification: Novel initialisation and updating mechanisms // Appl. Soft Comput.
2014. V. 18. P. 261-276.
14. Wan Y., Wang M., Ye Z., Lai X. A feature selection method based on modified
binary coded ant colony optimization algorithm // Appl. Soft Comput. 2016. V. 49.
P. 248-258.
15. Hancer E., Xue B., Zhang M., Karaboga D., Akay B. Pareto front feature selection
based on artificial bee colony optimization // Inform. Sci. 2018. V. 422. P. 462-479.
16. Shunmugapriya P., Kanmani S. A hybrid algorithm using ant and bee colony
optimization for feature selection and classification // Swarm Evol. Comput. 2017.
V. 36. P. 27-36.
17. Diao R., Shen Q. Feature selection with harmony search // IEEE Trans. Syst. Man
Cybern. Part B Cybern. 2012. V. 42. No. 6. P. 1509-1523.
18. Ходашинский И.А., Мех М.А. Построение нечеткого классификатора на основе
методов гармонического поиска // Программирование. 2017. № 1. С. 54-65.
19. Sikdar U.K., Ekbal A., Saha S. MODE: multiobjective differential evolution for
feature selection and classifier ensemble // Soft Comput. 2015. V. 19. No. 12.
P. 3529-3549.
20. Bezdek J.C. Ehrlih R., Full W. FCM: the fuzzy c-means clustering algorithm //
Comput. Geosci. 1984. V. 10. No. 2-3. P. 191-203.
21. Kennedy J., Eberhart R. A discrete binary version of the particle swarm algorithm //
IEEE Int. Conf. Syst., Man, Cybernet. 1997. V. 5. P. 4104-4108.
22. Pereria L.A.M, Rodrigues D., Almedia T.N.S., et al. A binary Cuckoo Search and
its application for feature selection / Cuckoo search and firefly algorithm. Studies in
computational intelligence 516. London: Springer, 2014. P. 141-154.
Статья представлена к публикации членом редколлегии В.И. Васильевым.
Поступила в редакцию 30.01.2018
После доработки 03.06.2018
Принята к публикации 08.11.2018
172