Автоматика и телемеханика, № 6, 2019
Управление в технических системах
© 2019 г. Д.В. ЕФАНОВ, д-р техн. наук (TrES-4b@yandex.ru)
(ООО “ЛокоТех-Сигнал”, Российский университет транспорта, Москва),
В.В. САПОЖНИКОВ, д-р техн. наук (port.at.pgups@gmail.com),
Вл.В. САПОЖНИКОВ, д-р техн. наук (at.pgups@gmail.com)
(Петербургский государственный университет путей сообщения
Императора Александра I, Санкт-Петербург)
КОДЫ С СУММИРОВАНИЕМ С ФИКСИРОВАННЫМИ ЗНАЧЕНИЯМИ
КРАТНОСТЕЙ ОБНАРУЖИВАЕМЫХ МОНОТОННЫХ
И АСИММЕТРИЧНЫХ ОШИБОК ДЛЯ СИСТЕМ
ТЕХНИЧЕСКОГО ДИАГНОСТИРОВАНИЯ
Введено понятие о кодах с суммированием с фиксированными зна-
чениями кратностей обнаруживаемых монотонных и асимметричных
ошибок в информационных векторах. Показано, что такие коды могут
быть построены на основе взвешивания одного из разрядов информа-
ционного вектора натуральным числом w ≥ 2 и последующего подсче-
та суммарного веса информационного вектора по модулю кода Бергера
(M = 2⌈log2(m+1)⌉). Установлены основные характеристики нового клас-
са кодов с суммированием. По сравнению с кодом Бергера предлагаемые
коды обладают преимуществом обнаружения симметричных ошибок при
сохранении свойства обнаружения любых монотонных и асимметричных
ошибок до фиксированных кратностей. Такие коды могут быть эффек-
тивно использованы при построении систем функционального контроля
комбинационных логических устройств и, особенно, при построении си-
стем с обнаружением всех одиночных неисправностей в контролируемом
устройстве.
Ключевые слова: техническая диагностика; коды с суммированием; коды
Бергера; информационный вектор; монотонная ошибка; асимметричная
ошибка; свойства кода; комбинационное логическое устройство; система
функционального контроля.
DOI: 10.1134/S0005231019060072
1. Введение
В задачах технической диагностики при разработке и эксплуатации на-
дежных дискретных систем часто используются равномерные коды, имею-
щие небольшую избыточность (меньшую, чем при дублировании) и ориенти-
рованные на обнаружение ошибок в информационных векторах [1-4]. К та-
ким кодам относятся неразделимые равновесные коды и разделимые коды с
суммированием [5].
Различные коды с суммированием обладают различными характеристи-
ками обнаружения ошибок в информационных векторах: как по кратностям
121
ошибок, так и по их видам. Возникающая в информационном векторе ошибка
может относиться к одному из четырех видов: одиночная, монотонная, сим-
метричная или асимметричная [6]. Одиночные ошибки связаны с искажением
только одного разряда информационного вектора и помехоустойчивыми ко-
дами с суммированием должны обнаруживаться всегда. Монотонная ошибка
возникает при условии искажения только нулевых или только единичных ин-
формационных разрядов. Симметричная ошибка происходит при одинаковом
количестве искажений нулевых и единичных разрядов, а асимметричная -
при неравном количестве искажений нулевых и единичных разрядов.
Особенности обнаружения ошибок различных видов кодами с суммиро-
ванием часто используются при организации систем диагностирования со
100%-ным обнаружением неисправностей из заданного класса. Например,
классическими кодами Бергера [7], или S(m, k)-кодами (m и k - длины ин-
формационных и контрольных векторов кода), обнаруживаются любые мо-
нотонные искажения в информационных векторах. Это свойство использует-
ся при контроле комбинационных логических устройств и предполагает вы-
деление во множестве их выходов подмножеств, образующих группы моно-
тонно независимых выходов (МН-группы), или же специальное преобразова-
ние структуры устройства в контролепригодную структуру, выходы которой
образуют одну МН-группу. МН-группы выходов контролируются на основе
S(m, k)-кода [8]. Помимо возможности обнаружения любых монотонных ис-
кажений в информационных векторах, S(m, k)-коды также обнаруживают
и любые асимметричные искажения. В [9] определены условия построения
систем функционального контроля с обнаружением любых одиночных неис-
правностей, учитывающие эту особенность кода Бергера.
В литературе известны специальные классы кодов с суммированием, ори-
ентированные на обнаружение ошибок различных видов до определенной
их кратности. Часто применяются модульные коды с суммированием, или
SM(m,k)-коды (M - значение модуля; наиболее часто применяют коды
со значением M = 4, M = 8 и M = 12) [10, 11]. Данные коды не об⌊ар⌋
m
живают все монотонные ошибки с кратностями d = jM, j = 1, 2, . . . ,
,
M
и некотору⌊ дол⌋ю асимметричных ошибок с кратностями d = M + 2j,
m-M
j = 1,2,...,
, d≤m [12]. Такие коды отнесем к dυ-UED(m, k) и
2
dα-AED(m,k) кодам1, где dυ и dα обозначают минимальные кратности
необнаруживаемых кодами монотонных и асимметричных ошибок соответ-
ственно. Введем обозначение кода, совмещающее оба отмеченных свойства —
dυ,dα-UAED(m,k)-код. Так как коды Бергера обнаруживают любые моно-
тонные и асимметричные ошибки, то они являются UAED(m, k)-кодами.
В [13] показано, что S(m, k) и SM(m, k) коды имеют следующую важную
особенность: ими не обнаруживается 100% симметричных ошибок в инфор-
мационных векторах. Это обстоятельство влияет на то, что в классе необна-
руживаемых данными кодами ошибок оказывается большое количество оши-
бок малой кратностью, например, 50% двукратных и 37,5% четырехкратных
ошибок. Таким образом, возникает задача улучшения характеристик обнару-
1 UED(m,k) - unidirectional error-detection code; AED(m,k) - asymmetrical error-
detection code.
122
жения данными кодами ошибок в информационных векторах, в особенности,
в области малой кратности.
В [14] разработан алгоритм модификации S(m, k)-кода в RS(m, k)-код, об-
ладающий улучшенными характеристиками обнаружения ошибок при ана-
логичном количестве разрядов в контрольных векторах. Применение данно-
го алгоритма модификации при установлении модулей M позволяет строить
модифицированные модульные коды с улучшенными характеристиками об-
наружения ошибок [15].
В данной статье описывается еще один способ построения модифициро-
ванного кода с суммированием с таким же количеством контрольных раз-
рядов, как и у классического кода Бергера, а также определены условия,
при которых разработанный код будет являться dυ, dα-UAED(m, k)-кодом с
заданными значениями dυ и dα.
2. Модульные коды Бергера с одним взвешенным разрядом
Улучшить характеристики обнаружения ошибок по сравнению с класси-
ческими кодами Бергера можно за счет установления неравноправия между
разрядами информационного вектора путем приписывания им весовых коэф-
фициентов [16]. Как показано в [17], эффективным оказывается даже взве-
шивание одного из разрядов информационного вектора. Такие коды (коды
с суммированием единичных и одного взвешенного разрядов) обозначим как
WS(m,k,w)-коды, где w - некоторое, заранее выбранное, натуральное число,
w ≥ 2.
WS(m,k,w)-коды эффективнее, чем коды Бергера, обнаруживают ошиб-
ки в информационных векторах и, что особенно важно, в области ошибок
малой кратностью: например, W S(m, k, w)-кодами обнаруживается пример-
но вдвое больше двукратных ошибок, чем классическими кодами Бергера
[18, 19].
Наилучшими характеристиками обнаружения ошибок в информационных
векторах обладает W S(m, k, w)-код, при построении которого значение веса
взвешенного разряда w = m [20]. У такого кода максимальное значение сум-
марного веса информационного вектора равно m + (m - 1) = 2m - 1. Во всех
случаях, кроме m = 2⌈log2(m+1)⌉-1, это приводит к увеличению по сравнению с
кодом Бергера количества контрольных разрядов на единицу. В итоге, часть
контрольных векторов, как и у кода Бергера, не формируется, что снижает
эффективность использования разрядов контрольных векторов и усложняет
процедуру построения полностью самопроверяемых генераторов кодов [8].
WS(m,k,w)-код с таким же количеством разрядов в контрольных векто-
рах, как и у кода Бергера, может быть построен при условии соблюдения
следующего соотношения [20]:
(1)
w + (m - 1) ≤ 2⌈log2(m+1)⌉
− 1.
Другими словами, значение веса W S(m, k, w)-кода для того, чтобы длина
контрольного вектора была такой же, как и у кода Бергера, для данной длины
123
информационного вектора, должно удовлетворять неравенству:
(2)
w≤2⌈log2(m+1)⌉
− m.
Например, при m = 5 имеем w ≤ 2⌈log2(5+1)⌉ - 5 = 3. Таким образом, взве-
сить один разряд можно двумя способами — числами w = 2 и w = 3. В про-
тивном случае взвешенный код с суммированием будет иметь большее коли-
чество контрольных разрядов, чем код Бергера.
Эффективность использования разрядов контрольных векторов
WS(m,k,w)-кодами можно улучшить за счет применения модуля, ко-
торый используется при определении суммарного веса информационного
вектора
[21]. Значения разрядов контрольных векторов получают по
следующим правилам.
Алгоритм 1. Правила получения значений разрядов контрольных век-
торов модульного кода Бергера с одним взвешенным информационным раз-
рядом:
1. Устанавливается значение модуля M = 2⌈log2(m+1)⌉.
2. Произвольно выбирается взвешиваемый разряд информационного век-
тора и фиксируется значение его весового коэффициента w ∈ {2; 3;
...;2⌈log2(m+1)⌉ - 1}.
3. Вычисляется значение суммарного веса единичных разрядов информа-
ционных векторов:
∑
(3)
W = wifi,
i=1
где fi - значение i-го разряда информационного вектора.
4. Определяется наименьший неотрицательный вычет числа W по моду-
лю M:
(4)
WM
= W (modM).
5. Значение числа WM представляется в двоичном виде и записывается в
разряды контрольного вектора.
Получаемые таким образом коды с суммированием назовем модуль-
ными кодами Бергера с одним взвешенным разрядом и обозначим как
WSM(m,k,w)-коды. WSM(m,k,w)-коды, также как и коды Бергера, име-
ют избыточность k = ⌈log2 (m + 1)⌉.
Для примера в табл. 1 задан W S8(4, 3, 6)-код, у которого взвешен старший
информационный разряд.
Взвешивание разряда информационного вектора приводит к перерас-
пределению информационных векторов между контрольными векторами
по сравнению с распределением векторов для классического кода Бергера
(табл. 2). Информационные векторы классического кода Бергера при взве-
шивании одного разряда сдвигаются вправо в таблице распределения. При
этом сдвигается ровно половина информационных векторов в группы с номе-
рами w + r - 1, где r — истинный вес информационного вектора. Достигнув
124
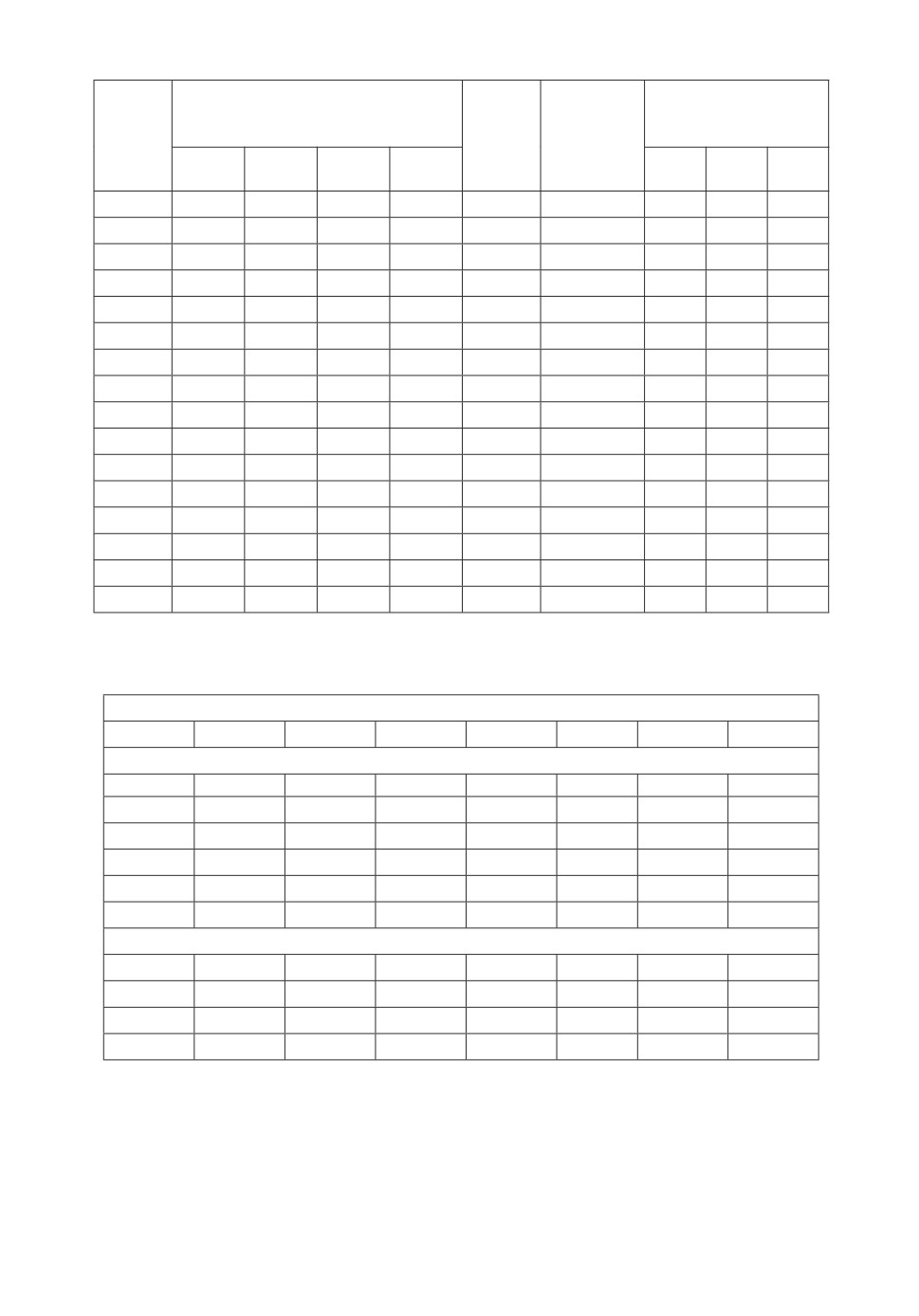
Таблица 1. W S8(4, 3, 6)-код
Разряды
Разряды
информационного
контрольного
№
вектора
W W(mod8)
вектора
f4
f3
f2
f1
g3
g2
g1
w4 = 6
w3 = 1
w2 = 1
w1 = 1
0
0
0
0
0
0
0
0
0
0
1
0
0
0
1
1
1
0
0
1
2
0
0
1
0
1
1
0
0
1
3
0
0
1
1
2
2
0
1
0
4
0
1
0
0
1
1
0
0
1
5
0
1
0
1
2
2
0
1
0
6
0
1
1
0
2
2
0
1
0
7
0
1
1
1
3
3
0
1
1
8
1
0
0
0
6
6
1
1
0
9
1
0
0
1
7
7
1
1
1
10
1
0
1
0
7
7
1
1
1
11
1
0
1
1
8
0
0
0
0
12
1
1
0
0
7
7
1
1
1
13
1
1
0
1
8
0
0
0
0
14
1
1
1
0
8
0
0
0
0
15
1
1
1
1
9
1
0
0
1
Таблица 2. Распределения информационных векторов между контрольными
векторами в S(4, 3) и WS8(4, 3, 6)-кодах
Контрольные группы
000
001
010
011
100
101
110
111
Информационные векторы S(4, 3)-кода
0000
0001
0011
0111
1111
0010
0101
1011
0100
0110
1101
1000
1001
1110
1010
1100
Информационные векторы W S8(4, 3, 6)-кода
0000
0001
0011
0111
1000
1001
1011
0010
0101
1010
1101
0100
0110
1100
1110
1111
«граничной» группы с весом, равным log2 M, вектор с весом W = w + r - 1
при изменении значения весового коэффициента продолжает сдвигаться, на-
чиная с нулевой группы (контрольной группы <00. . . 00>). Такое перерас-
пределение приводит к уменьшению количества информационных векторов
в части контрольных групп, что, в свою очередь, приводит к уменьшению
125
количества необнаруживаемых кодом ошибок. Так, например, S(4, 3)-кодом
не обнаруживается 54 симметричные ошибки (48 двукратных и 6 четырех-
кратных), а W S8(4, 3, 6)-кодом - 36 ошибок (24 двукратные симметричные
ошибки и 12 трехкратных монотонных ошибок).
Взвешенным может быть любой разряд информационного вектора, при-
чем, значение весового коэффициента w может быть любым натуральным
числом. Однако количество W SM(m, k, w)-кодов с различными характери-
стиками обнаружения ограничено.
Утверждение 1. Характеристики обнаружения ошибок WSM(m,k,w)-
кодами не зависят от того, какой из разрядов информационного вектора
взвешен, а зависят только от значения весового коэффициента.
Это следует из того факта, что при рассмотрении характеристик обнару-
жения ошибок кодами с суммированием анализируются возникающие необ-
наруживаемые искажения на полном множестве информационных векторов -
анализируются 2m информационных векторов. Поскольку каждый из разря-
дов в таком случае в 2m-1 информационных векторах принимает нулевое
значение и в таком же количестве информационных векторов - единичное
значение, то свойства кода определяются только тем, каково значение весо-
вого коэффициента.
Существует еще одно ограничение на количество способов построения ко-
дов с суммированием с различными характеристиками обнаружения ошибок
в информационных векторах.
Утверждение 2. Для данного значения длины информационного век-
тора существует ровно M - 1 = 2⌈log2(m+1)⌉-1 - 1 вариант построения мо-
дульно взвешенных кодов с суммированием (включая код Бергера при w = 1)
с различными характеристиками обнаружения ошибок в информационных
векторах.
Справедливость формулировки положения утверждения 2 вытекает из
особенностей определения наименьших неотрицательных вычетов для значе-
ний весовых коэффициентов. Количество способов построения кодов зависит
от того, какое значение можно приписать взвешенному разряду. Существует
ограничение w = M. Если w = M имеем:
W (modM) = (m - 1 + M)(modM) = (m - 1) (mod M) + M (modM) =
= (m - 1) (mod M) + 0 = (m - 1) (mod M) .
Другими словами, если w = M, то значение взвешенного разряда не
контролируется разрядами контрольного вектора. Например, если взвешен
старший разряд в информационном векторе, то возможны необнаруживае-
мые одиночные искажения, переводящие векторы < 0fm fm-1 . . . f2 f1> и
< 1fm-1 . . . f2 f1> друг в друга. Это нарушает свойство помехоустойчивости
кода.
Поскольку w (mod M) = (w + jM) (mod M), j = 1, 2, . . ., то свойства обна-
ружения ошибок у W SM(m, k, w)-кодов с данными значениями весовых ко-
эффициентов взвешенного разряда будут одинаковыми.
126
15
14
13
12
11
10
9
8
70
16
32
48
Значение весового коэффициента взвешенного разряда
в информационном векторе, w
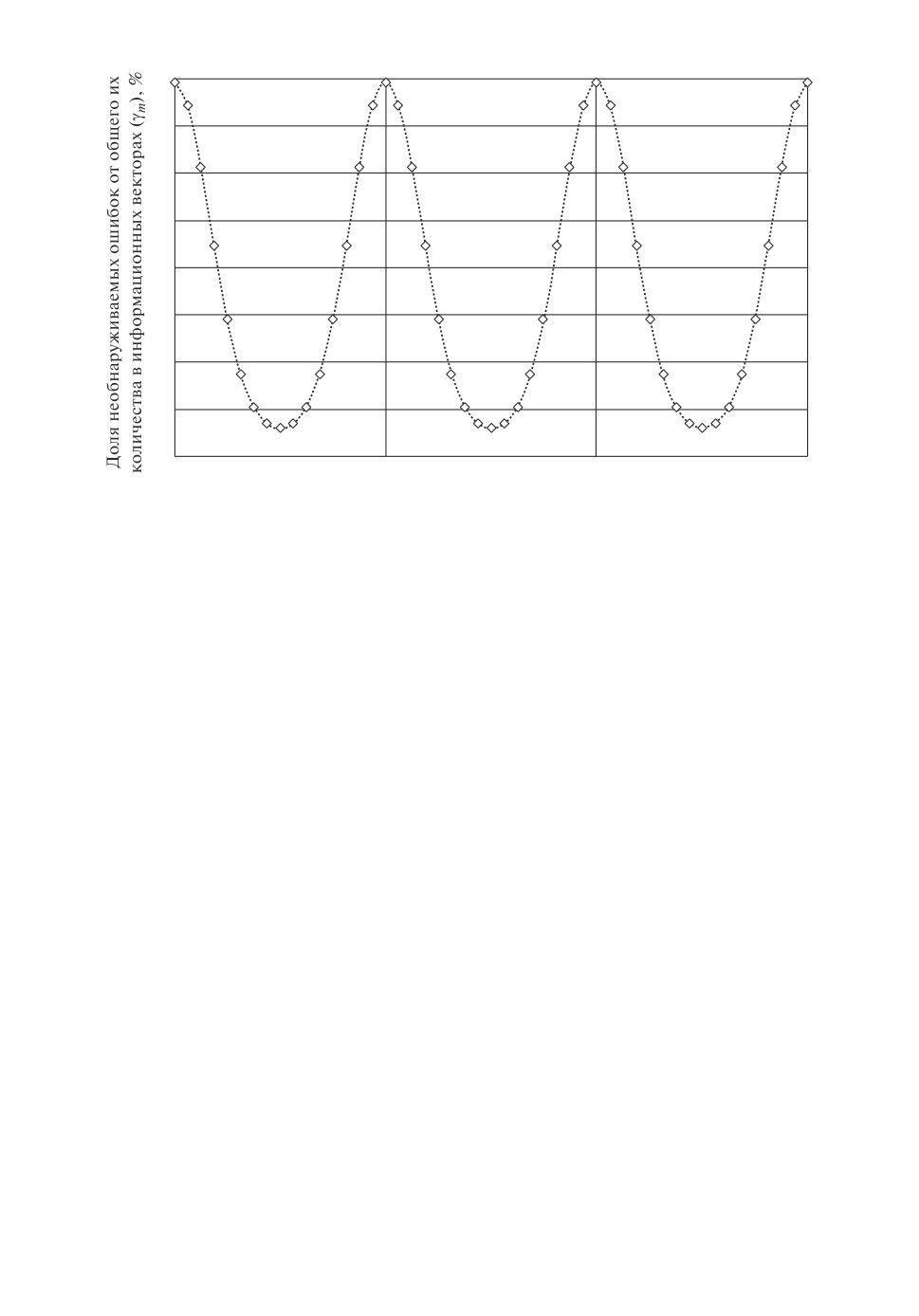
Рис. 1. Зависимость доли необнаруживаемых ошибок от общего их количе-
ства в информационных векторах WSM(15, k, w)-кодов при увеличении зна-
чения w.
На рис. 1 точками показаны значения долей необнаруживаемых
WSM(15,4,w)-кодами ошибок от общего количества ошибок в информацион-
ных векторах (величины γm, %) при различных значениях w ∈ {0; 48}. Коды
со значениями весового коэффициента w = jM, j = 0, 1, 2, . . . , не являются
помехоустойчивыми. Коды со значениями w = 1 + jM, j = 1, 2, . . . , являют-
ся классическими кодами Бергера.
Из графика на рис. 1 следует, что до определенного значения весового ко-
эффициента происходит уменьшение общего количества необнаруживаемых
WSM(m,k,w)-кодами ошибок (величины Nm) в информационных векторах,
а по его достижении происходит постепенное увеличение величины Nm. По-
добная особенность W SM(m, k, w)-кодов связана с распределением инфор-
мационных векторов между всеми контрольными векторами (на контроль-
ные группы). Например, в табл. 3 приведены распределения информацион-
ных векторов на контрольные группы для всех W SM(5, 3, w)-кодов с различ-
ными характеристиками обнаружения ошибок.
Рассмотрим последовательное увеличение значения весового коэффициен-
та от величины w = 1 до величины w = 2⌈log2(m+1)⌉-1 - 1 = 7 и принцип рас-
пределения информационных векторов в контрольные группы при построе-
нии W SM(m, k, w)-кодов.
В табл. 3 информационные векторы W SM(5, 3, w)-кодов разделены на
две группы: «неизменяемая часть» — те информационные векторы, кото-
рые не меняют своего положения относительно «базового» распределения
для кода Бергера; «перераспределенные векторы» - информационные векто-
127
Таблица 3. Распределения информационных векторов между контрольными век-
торами
Контрольные группы
000
001
010
011
100
101
110
111
Неизменяемая часть распределения информационных векторов
00000
00001
00011
00111
01111
00010
00101
01011
00100
00110
01101
01000
01001
01110
10000
01010
01100
Расположение информационных векторов при взвешивании старшего разряда
w=
1
10001
10110
10111
11111
10010
11001
11011
10100
11010
11101
11000
11100
11110
10011
10101
w=
2
10000
10001
10011
10111
11111
10010
10101
11011
10100
10110
11101
11000
11001
11110
11010
11100
w=
3
10000
10001
10011
10111
11111
10010
10101
11011
10100
10110
11101
11000
11001
11110
11010
11100
w=
4
11111
10000
10001
10011
10111
10010
10101
11011
10100
10110
11101
11000
11001
11110
11010
11100
128
Таблица 3. (продолжение)
w=5
10111
11111
10000
10001
10011
11011
10010
10101
11101
10100
10110
11110
11000
11001
11010
11100
w=6
10011
10111
11111
10000
10001
10101
11011
10010
10110
11101
10100
11001
11110
11000
11010
11100
w=7
10001
10011
10111
11111
10000
10010
10101
11011
10100
10110
11101
11000
11001
11110
11010
11100
ры, которые были сдвинуты в контрольные группы, соответствующие весу
r∗ = r + w (mod M) - 1 (r - истинный вес информационного вектора) отно-
сительно распределения для кода Бергера. При w = 1 рассматриваемый код
является кодом Бергера. Взвешивание старшего разряда числом w = 2 дает
сдвиг всех векторов <1˜˜˜˜> в контрольные группы с весом r∗ = r + 1. Так
как сдвигается половина информационных векторов, то сдвиг обуславливает
уменьшение количества необнаруживаемых симметричных ошибок пример-
но вдвое (симметричные ошибки возникают только при переходе векторов с
одинаковым истинным весом друг в друга). Так как значение веса r∗ стано-
вится отличным от значения истинного веса информационных векторов кон-
трольной группы, то переходы между векторами с различным весом будут
иметь кратность d ≥ 3. Все соответствующие ошибки будут принадлежать
к классу асимметричных ошибок. Причем, их количество будет постепенно
уменьшаться при увеличении значения весового коэффициента до величи-
ны w = 2⌈log2(m+1)⌉ - m (см. формулу 2). Это следует из того факта, что с
увеличением значения весового коэффициента будут постепенно заполнять-
ся пустые контрольные группы в таблице распределения. Так будет происхо-
дить до достижения «граничного» значения максимального суммарного веса
информационного вектора при w = 3.
С увеличением значения весового коэффициента от величины w =
= 2⌈log2(m+1)⌉ - m + 1 начинают появляться монотонные необнаруживаемые
ошибки, что связано с подсчетом вычета по модулю M = 2⌈log2(m+1)⌉-1. При
129
этом количество асимметричных необнаруживаемых ошибок будет продол-
жать уменьшаться при увеличении значения w до величины w =M2 (с даль-
нейшим увеличением значения w количество асимметричных необнаруживае-
мых ошибок вновь начнет возрастать). При w = 4 в W SM(5, 3, w)-кодах по-
являются необнаруживаемые монотонные ошибки только кратностью d = 5,
при w = 5 — необнаруживаемые монотонные ошибки только кратностью
d = 4, и т.д. При w = 7 кодом с суммированием не будут обнаруживаться
некоторые монотонные ошибки с кратностью d = 2. При w = 8 в силу того,
что M = 8, значение старшего разряда информационного вектора контроли-
роваться не будет, что обуславливает появление 25 = 32 одиночных необнару-
живаемых ошибок. При последующем увеличении значения w характеристи-
ки обнаружения ошибок кодами начинают повторяться с характеристиками
уже рассмотренных кодов. W SM(m, k, w)-коды со значениями весовых ко-
эффициентов w и w + jM (j = 1, 2, . . .) имеют одинаковые характеристики
обнаружения ошибок в информационных векторах.
3. Генераторы W SM(m, k, w)-кодов
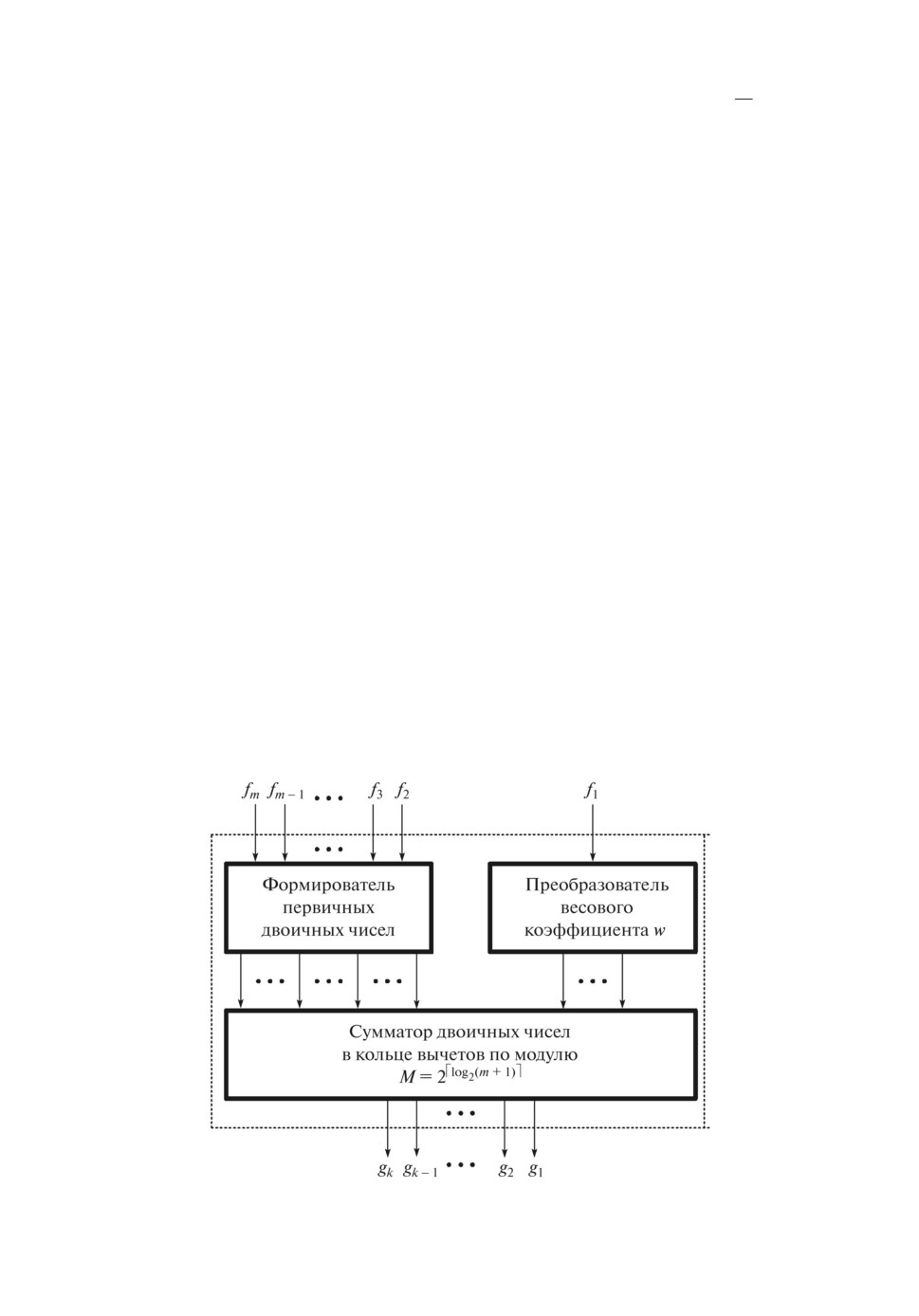
Рассмотрим особенности реализации генераторов кодовых слов
WSM(m,k,w)-кодов. Данные структуры реализуются в виде счетчиков
единичных и взвешенных весовых коэффициентов в кольце вычетов по
модулю M = 2⌈log2(m+1)⌉. При этом один из вариантов реализации гене-
ратора состоит в следующем (рис. 2). Предварительно преобразовывается
значение веса взвешенного разряда в двоичное число, а из m - 1 единичных
информационных разрядов формируются первичные двоичные числа с
числом разрядов log2 M. На следующем каскаде осуществляется сложение
полученных двоичных чисел в кольце вычетов по модулю M = 2⌈log2(m+1)⌉.
Рис. 2. Организационная структура генератора W SM(m, k, w)-кода.
130
Таблица 4. Характеристики сложности реализации генераторов кодов с сумми-
рованием
Число
Удельное количество
w
функциональных
транзисторов
w, %
элементов
в генераторе
FA
HA
XOR
WS16(14,5,w)-коды
1
9
9
2
303
100
2
9
8
2
294
97,03
3
10
8
2
318
104,95
4
9
7
2
285
94,059
5
10
8
2
318
104,95
6
10
7
2
309
101,98
7
11
7
2
333
109,901
8
9
6
2
276
91,089
9
9
9
3
306
100,99
10
10
7
3
312
102,97
11
10
8
3
321
105,941
12
10
6
3
303
100
13
10
8
3
321
105,941
14
11
6
3
327
107,921
15
11
7
3
336
110,891
WS16(15,5,w)-коды
1
10
8
2
318
100
2
10
7
2
309
97,17
3
11
7
2
333
104,717
4
10
6
2
300
94,34
5
11
7
2
333
104,717
6
11
6
2
324
101,887
7
12
6
2
348
109,434
8
10
5
2
291
91,509
9
10
8
3
321
100,943
10
11
6
3
327
102,83
11
11
7
3
336
105,66
12
11
5
3
318
100
13
11
7
3
336
105,66
14
12
5
3
342
107,547
15
12
6
3
351
110,377
Усложнение генератора W SM(m, k, w)-кода по сравнению с генератором
S(m, k)-кода, реализованного по тому же методу, будет определяться значени-
ем весового коэффициента взвешенного разряда. При нечетных значениях w
генератор W SM(m, k, w)-кода будет всегда сложнее генератора S(m, k)-кода,
что связано с наличием значащего младшего разряда в двоичном представле-
нии числа w. Это усложнение, как показывают исследования, не превышает
131
a
115
110
105
100
95
90
85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
б
115
110
105
100
95
90
85
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Значение веса взвешенного разряда w
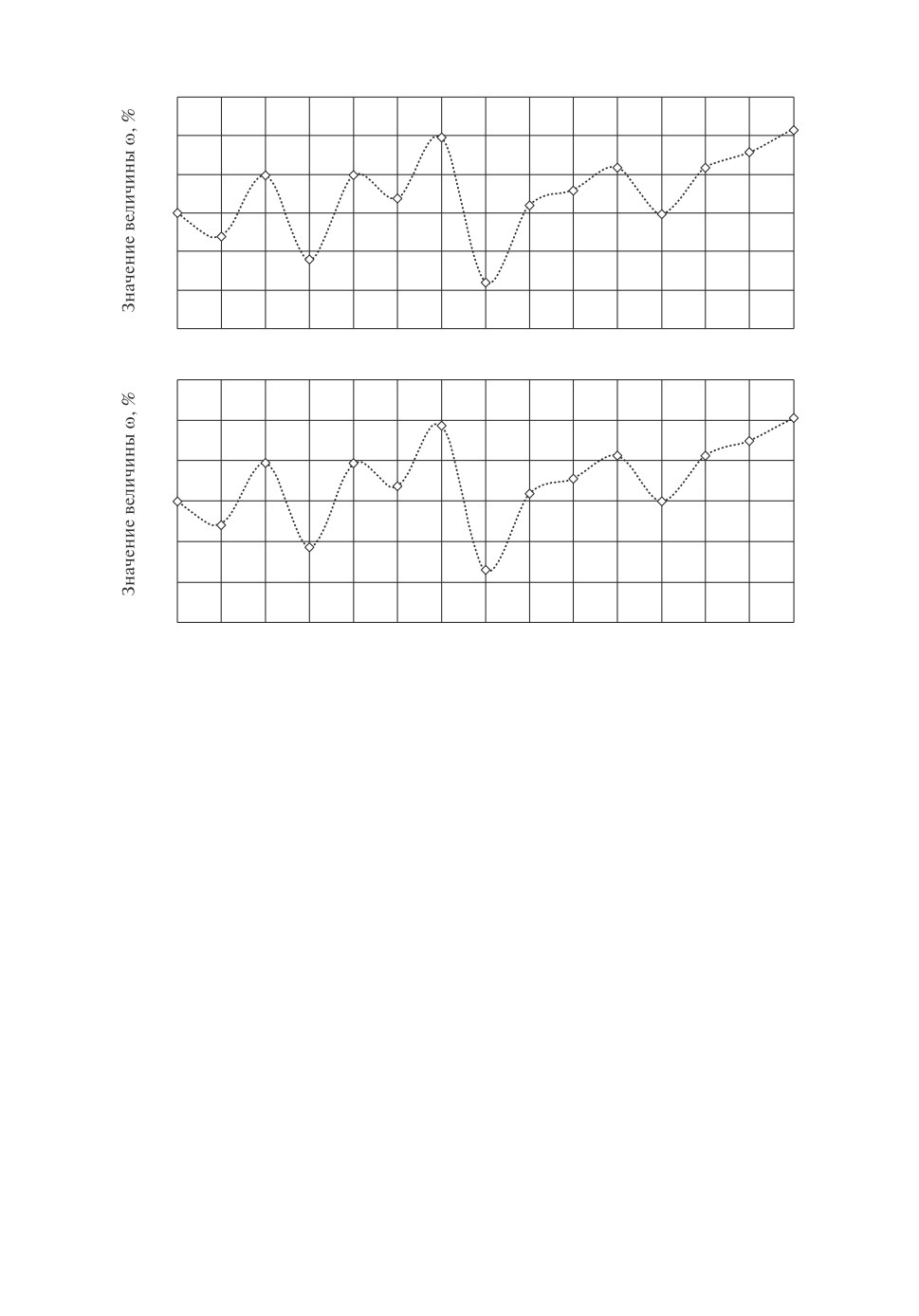
Рис. 3. Значения величины ω: а — для W S16(14, 5, w)-кодов;
б — для WS16(15,5,w)-кодов.
20% от сложности реализации генератора кода Бергера. При четных значе-
ниях w генератор W SM(m, k, w)-кода будет во многих случаях иметь более
простую структуру, чем генератор S(m, k)-кода. Чем меньше значащих раз-
рядов в двоичном представлении числа w, тем проще будет и реализация. Для
примера в таблице приводятся данные о сложности реализации генераторов
кодов с суммированием при m = 14 и m = 15. Генераторы реализованы на
стандартных сумматорах единиц. В табл. 4 рассчитан удельный показатель
сложности реализации — по числу транзисторов в составе элементов для наи-
более простой реализации по КМОП-технологии (полный сумматор (FA) —
24 транзистора, полусумматор (HA) — 9 транзисторов и сумматор по модулю
два (XOR) — 3 транзистора).
На рис. 3 сравнения дается график зависимости отношения сложности
генератора W SM(m, k, w)-кода к сложности генератора кода Бергера (вели-
чины ω, %) от значения w для семейств кодов при m = 14 и m = 15.
4. Характеристики модульных кодов Бергера с одним взвешенным разрядом
С использованием специального программного обеспечения, разработан-
ного авторами по алгоритмам анализа табличной формы задания кода (см.
132
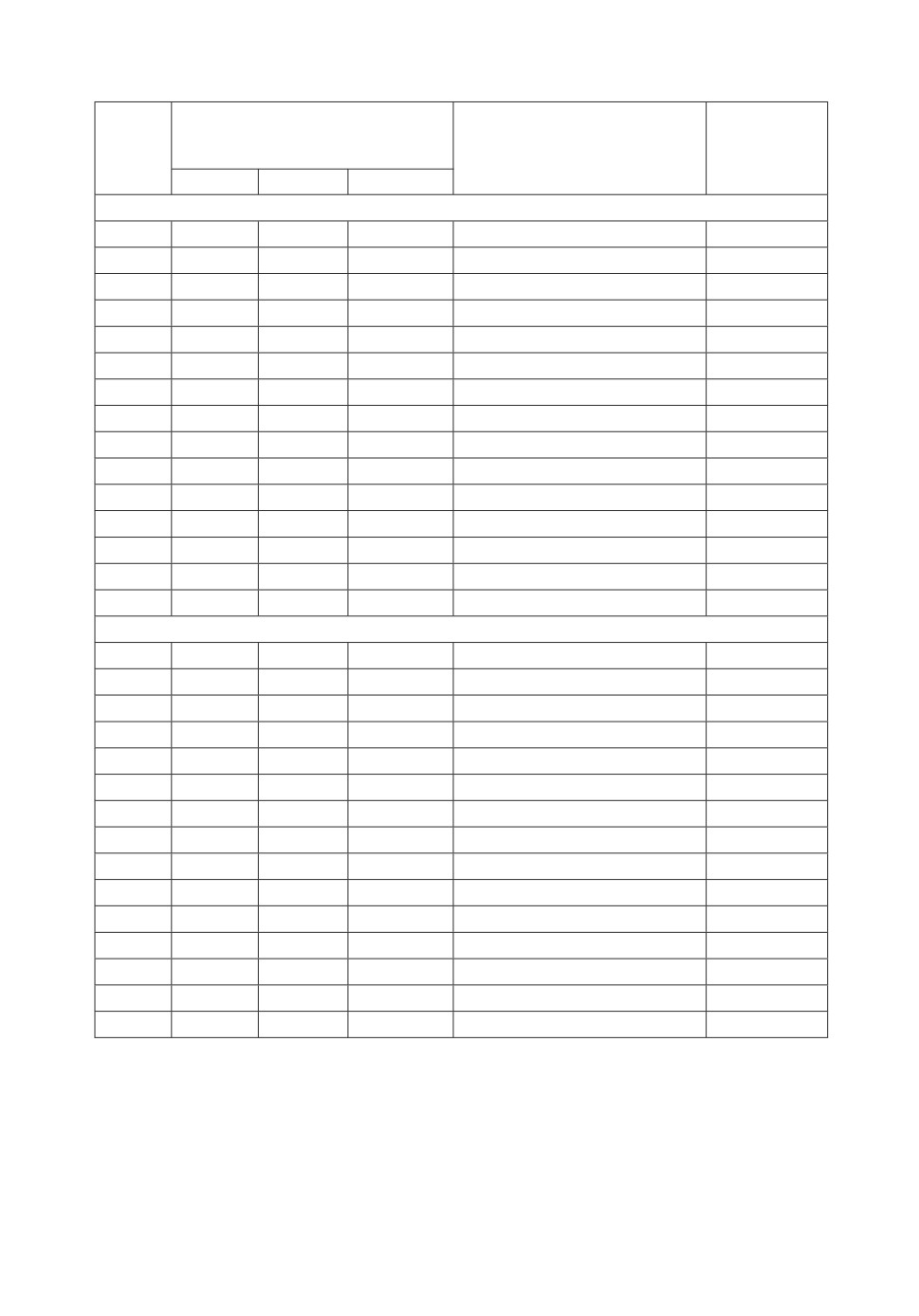
Таблица 5. Характеристики обнаружения ошибок по кратностям в W S16(10, 4, w)-
кодах
w
Количество необнаруживаемых ошибок кратностью d
Nm
1
2
3
4
5
6
7
8
9
10
1
0
23040
0
80640
0
67200
0
12600
0
252
183732
2
0
18432
9216
48384
32256
26880
20160
2520
2016
0
159864
3
0
18432
0
59136
0
47040
0
8568
0
168
133344
4
0
18432
0
48384
8064
26880
8064
2520
1008
0
113352
5
0
18432
0
48384
0
30912
0
4536
0
72
102336
6
0
18432
0
48384
0
26880
1344
2520
288
0
97848
7
0
18432
0
48384
0
26880
0
2808
0
20
96524
8
0
18432
0
48384
0
26880
0
2520
72
0
96288
9
0
18432
0
48384
0
26880
0
2808
0
20
96524
10
0
18432
0
48384
0
26880
1344
2520
288
0
97848
11
0
18432
0
48384
0
30912
0
4536
0
72
102336
12
0
18432
0
48384
8064
26880
8064
2520
1008
0
113352
13
0
18432
0
59136
0
47040
0
8568
0
168
133344
14
0
18432
9216
48384
32256
26880
20160
2520
2016
0
159864
15
0
23040
0
80640
0
67200
0
12600
0
252
183732
16
1024
18432
18432
48384
48384
26880
26880
2520
2520
0
193456
табл. 2 и 3), были рассчитаны числа необнаруживаемых ошибок по их видам
и кратностям для W SM(m, k, w)-кодов с длинами информационных векторов
m = 4 ÷ 20. Таблицы 5 и 6 являются примерами подобных характеристиче-
ских таблиц.
Подробный анализ характеристических таблиц позволил установить клю-
чевые закономерности, присущие рассматриваемому классу кодов с сумми-
рованием:
1. Общее количество необнаруживаемых ошибок по каждой кратности для
WSM(m,k,w)-кодов с данной длиной информационного вектора одинаково
{
}
при значениях весовых коэффициентов w = t и w = M - t, t ∈
1;M2
2. Минимальное общее количество необнаруживаемых ошибок в инфор-
мационных векторах имеет W SM(m, k, w)-код со значением w =M2 .
3. W SM(m, k, w)-коды со значениями весовых коэффициентов w ≤ M - m
обнаруживают любые монотонные ошибки в информационных векторах.
4. W SM(m, k, w)-коды со значениями весовых коэффициентов w > M - m
обнаруживают любые монотонные ошибки, за исключением монотонных
ошибок кратностью d = M + 1 - w.
5. W SM(m, k, w)-кодами при фиксированной длине информационного век-
тора вне зависимости от значения весового коэффициента не обнаруживается
одинаковое количество симметричных ошибок в информационных векторах
по каждой четной кратности.
6. W SM(m, k, w)-коды при значениях длин информационных векто-
{M
}
ров m = 2j (j = 1, 2, . . .) и w =
;M2 + 1;M2 + 2
, а также при значениях
2
133
Таблица 6. Характеристики обнаружения ошибок по видам в W S16(10, 4, w)-кодах
Количество необнаруживаемых
w
Nυm
монотонных ошибок кратностью d
1
2
3
4
5
6
7
8
9
10
1÷6
0
0
0
0
0
0
0
0
0
0
0
7
0
0
0
0
0
0
0
0
0
2
2
8
0
0
0
0
0
0
0
0
36
0
36
9
0
0
0
0
0
0
0
288
0
0
288
10
0
0
0
0
0
0
1344
0
0
0
1344
11
0
0
0
0
0
4032
0
0
0
0
4032
12
0
0
0
0
8064
0
0
0
0
0
8064
13
0
0
0
10752
0
0
0
0
0
0
10752
14
0
0
9216
0
0
0
0
0
0
0
9216
15
0
4608
0
0
0
0
0
0
0
0
4608
16
1024
0
0
0
0
0
0
0
0
0
1024
Количество необнаруживаемых
w
Nσm
симметричных ошибок кратностью d
1
2
3
4
5
6
7
8
9
10
1
0
23040
0
80640
0
67200
0
12600
0
252
183732
2 ÷ 16
0
18432
0
48384
0
26880
0
2520
0
0
96216
Количество необнаруживаемых
w
Nαm
асимметричных ошибок кратностью d
1
2
3
4
5
6
7
8
9
10
1
0
0
0
0
0
0
0
0
0
0
0
2
0
0
9216
0
32256
0
20160
0
2016
0
63648
3
0
0
0
10752
0
20160
0
6048
0
168
37128
4
0
0
0
0
8064
0
8064
0
1008
0
17136
5
0
0
0
0
0
4032
0
2016
0
72
6120
6
0
0
0
0
0
0
1344
0
288
0
1632
7
0
0
0
0
0
0
0
288
0
18
306
8
0
0
0
0
0
0
0
0
36
0
36
9
0
0
0
0
0
0
0
0
0
20
20
10
0
0
0
0
0
0
0
0
288
0
288
11
0
0
0
0
0
0
0
2016
0
72
2088
12
0
0
0
0
0
0
8064
0
1008
0
9072
13
0
0
0
0
0
20160
0
6048
0
168
26376
14
0
0
0
0
32256
0
20160
0
2016
0
54432
15
0
0
0
32256
0
40320
0
10080
0
252
82908
16
0
0
18432
0
48384
0
26880
0
2520
0
96216
m = 2j + 1 (j = 1,2,...) и w = M2 = m обнаруживают любые асимметричные
ошибки в информационных векторах.
7. W SM(m, k, w)-коды обнаруживают любые асимметричные ошибки
кратностью d < w + 1 при w ≤M2 + 1 и d < M - w + 3 при w >M2 + 1 и
134
не обнаруживают некоторую долю асимметричных ошибок кратностью
d = w + 1 + 2j, j = 0,1,... (d ≤ m) при w ≤ M2 + 1 и d = M - w + 3 + 2j,
j = 0,1,... (d ≤ m) при w > M2 + 1.
8. W SM(m, k, w)-коды имеют одинаковое количество двукратных необна-
руживаемых ошибок в информационных векторах при w ∈ {2; 3; . . . ; M - 2},
меньшее, чем у классических кодов Бергера; причем эти ошибки относятся к
виду симметричных.
9. W SM(m, k, w)-коды при m ≥ 4, в отличие от классических кодов Бер-
гера, обнаруживают примерно половину симметричных ошибок.
10. W SM(m, k, w)-коды с четными значениями m при любом значении
w ≥ 2 обнаруживают любые симметричные ошибки максимальной кратно-
стью d = m.
WSM(m,k,w)-коды по сравнению с классическими кодами Бергера имеют
улучшенные характеристики обнаружения симметричных ошибок в инфор-
мационных векторах.
Практически все W SM(m, k, w)-коды относятся к dυ, dα-UAED(m, k)-
кодам. Параметры dυ и dα для W SM(m, k, w)-кодов определяются следую-
щим образом. При значениях весового коэффициента w ∈ {2; 3; . . . ; M - m}
WSM(m,k,w)-коды обнаруживают любые монотонные ошибки в инфор-
мационных векторах, на этом же и{тервале данн}е коды являются dα-
AED(m, k)-кодами, причем при w ∈
2; 3; . . . ;M2 + 1
параметр dα = w + 1,
{M
}
а при w ∈
+ 2; M2 + 3; . . . ; M - m
— dα = M - w + 3. При значени-
2
{M
}
ях весового коэффициента w ∈
+ 1; M2 + 2; . . . ; M
WSM(m,k,w)-коды
2
являются dυ, dα-UAED(m, k)-кодами с параметрами dυ = M + 1 - w и
dα = M - w + 3.
Таким образом, построены W SM(m, k, w)-коды, которые при определен-
ных значениях w, также как и классические коды Бергера, обнаруживают
любые монотонные и любые асимметричные ошибки, и кроме того, обнару-
живают практически половину общего количества симметричных ошибок в
информационных векторах.
5. Применение модульных кодов Бергера с одним взвешенным разрядом
при организации контроля логических устройств
WSM(m,k,w)-коды могут, как и классические коды Бергера, использо-
ваться при решении задач технической диагностики в процессе разработки и
эксплуатации контролепригодных дискретных систем. Одним из направлений
их использования является организация систем функционального контроля
(СФК) комбинационных логических устройств [2, 3].
В системе функционального контроля исходное логическое устройство
(объект диагностирования) снабжается специализированной схемой контро-
ля, позволяющей в процессе эксплуатации системы косвенно по результа-
там вычислений фиксировать техническое состояние объекта диагностирова-
ния [23]. Схема контроля при этом реализуется на принципе дополнения реа-
лизуемого на выходах объекта диагностирования информационного вектора
контрольным вектором заранее выбранного разделимого кода [8]. От свойств
135
Таблица 7. Параметры W S16(10, 4, w)-кодов
w
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
dυ
∅
∅
∅
∅
∅
∅
10
9
8
7
6
5
4
3
2
1
dα
∅
3
4
5
6
7
8
9
10
9
8
7
6
5
4
3
выбранного кода будут зависеть такие важные показатели системы диагно-
стирования, как обнаруживающая способность и структурная избыточность.
Рассмотрим особенности применения W SM(m, k, w)-кодов при организации
систем функционального контроля.
Обозначим как dmax - максимальное количество выходов логического
устройства, связанных путями с одним из логических элементов его внутрен-
ней структуры. Другими словами, величина dmax будет соответствовать мак-
симальной кратности, возможной на выходах логического устройства ошиб-
ки.
Анализ характеристических таблиц W SM(m, k, w)-кодов при различных
значениях длин информационных векторов (см., например, табл. 6) позволя-
ет установить следующую особенность данных кодов.
Утверждение 3. На выходах логического устройства будут обнару-
живаться любые монотонные и асимметричные ошибки в системе функ-
ционального контроля на основе WSM(m,k,w)-кода при условии, что:
{
M
dmax ≤
;
(5)
2
w ∈ {dmax,dmax + 1,...,M - dmax}.
Например, если логическое устройство имеет m = 10 выходов и макси-
мальная кратность ошибки на выходах определяется величиной dmax = 5,
то для контроля может быть использован W S16(10, 4, w)-код со значени-
ем w = 5 ÷ 11. Использование такого кода обеспечит обнаружение на выхо-
дах устройства любых монотонных и асимметричных ошибок. В самом де-
ле, из табл. 6 следует, что данный код обнаруживает все монотонные ошиб-
ки при значениях w = 1 ÷ 11, а все асимметричные ошибки — при значе-
ниях w = 5 ÷ 13. Для удобства анализа параметры dυ и dα для семейства
WS16(10,4,w)-кодов сведены в табл. 7.
При выборе W SM(m, k, w)-кода также могут отдельно учитываться мак-
симальные значения монотонных и асимметричных ошибок — числа dmax,υ и
dmax,α. Например, для устройства с m = 10 выходами при значении dmax = 5
и при dmax,υ = 5 и dmax,α = 3 диапазон допустимых значений весового ко-
эффициента w можно расширить до w = 3 ÷ 11. Это на практике может
дать уменьшение сложности реализации кодирующих устройств и схемы
контроля.
Свойства рассматриваемых кодов с фиксированными значениями кратно-
стей необнаруживаемых ошибок позволяют предложить дальнейшее разви-
тие метода обеспечения 100%-ного обнаружения одиночных неисправностей
логического устройства за счет преобразования его исходной структуры, ко-
торый развит в [24-27]. В этом случае строится СФК на основе кода Бер-
136
гера. Затем путем анализа внутренней структуры устройства определяются
логические элементы, неисправности которых не обнаруживаются в СФК.
Резервируются выявленные элементы (а также при необходимости другие
элементы) таким образом, чтобы обеспечить обнаружение всех одиночных
неисправностей.
Рассмотрим следующий подход к решению данной задачи. Обозначим че-
рез Q множество логических элементов комбинационного устройства.
Алгоритм 2. Способ построения СФК комбинационного логического
устройства.
1. При помощи метода [8, 28] определяется множество логических элемен-
тов Q0 ⊂ Q, неисправности которых искажают только один выход.
2. При помощи метода [25, 26] определяется множество Qυ ⊂ {Q\Q0} ло-
гических элементов, неисправности которых вызывают на выходах схемы мо-
нотонные искажения.
3. При помощи метода [9] определяется множество Qα ⊂ {(Q\Q0) \Qυ} ло-
гических элементов, неисправности которых вызывают на выходах схемы
асимметричную ошибку.
4. Определяется множество Qσ логических элементов, не вошедших в под-
множества Q0, Qυ и Qα, неисправности которых вызывают на выходах схемы
симметричную ошибку.
5. Для рассматриваемого устройства определяется параметр dmax и выби-
рается W SM(m, k, w)-код, удовлетворяющий условию (8).
6. Строится СФК на основе выбранного кода.
7. Моделируется работа СФК при внесении в устройство одиночных неис-
правностей элементов из множества Qσ.
8. Составляется множество Q∗σ ⊂ Qσ логических элементов, для которых
моделирование показало, что их неисправности не обнаруживаются в постро-
енной СФК.
9. Осуществляется преобразование исходной структуры логического
устройства на основе резервирования элементов из множества Q∗σ при по-
мощи методов, изложенных в [25, 26].
Как отмечалось ранее, W SM(m, k, w)-коды обнаруживают примерно 50%
симметричных ошибок. Поэтому в СФК на основе W SM(m, k, w)-кода обна-
руживаются неисправности всех элементов, входящих в подмножества Q0, Qυ
и Qα, а также определенная часть неисправностей из подмножества Qσ. Так
как последние не обнаруживаются при применении кода Бергера, то предло-
женный подход обеспечивает уменьшение избыточности при преобразовании
исходной структуры устройства по сравнению с известными методами [24-27].
Рассмотрим для примера приведенное на рис. 4 логическое устройство с
m = 10 выходами. Схема устройства является двухуровневой, а отказы эле-
ментов G1 ÷ G8 первого каскада влияют сразу же на несколько выходов са-
мого устройства, что вызывает ошибки различных видов и кратностей. Ана-
лиз схемы показывает, что максимальная допустимая кратность монотонной
ошибки υ = 5 (такие ошибки могут быть вызваны отказами элемента G5), а
асимметричной — α = 3 (такие ошибки могут быть вызваны отказами эле-
137
G1
x2
&
1
1
1
2
f1
5
x3
6
G2
x2
2
&
1
2
7
f2
x3
8
G3
x1
&
1
1
3
5
f3
x2
6
G4
x3
&
2
1
4
3
f4
4
x4
5
G5
x1
&
4
1
5
f5
x3
5
G6
x2
&
2
1
6
f6
x4
7
G7
x1
&
1
1
7
5
f7
x3
7
G8
x1
&
3
1
8
f8
x2
7
4
1
f9
8
1
1
f10
3
Рис. 4. Комбинационное логическое устройство.
138
ментов G2 и G3). Таким образом, dmax = 5. Анализ схемы устройства также
показал, что отказы элементов G2, G3 и G8 вызывают на выходах схемы на
некоторых входных наборах симметричные ошибки. Такие ошибки не будут
обнаружены классическими кодами Бергера, а значит, для решения зада-
чи обеспечения обнаружения любых одиночных неисправностей потребуется
резервировать все три элемента. Если же при организации системы функцио-
нального контроля учесть особенности обнаружения ошибок W SM(m, k, w)-
кодами и, например, использовать для контроля W S16(10, 4, w)-код со зна-
чением w = 5 ÷ 11 и взвесить разряд f2, то все симметричные ошибки, вы-
зываемые неисправностями элементов G2 и G8, будут идентифицированы в
системе функционального контроля. Потребуется резервирование только эле-
мента G3.
Следует отметить, что это только пример особенностей реализации СФК
с учетом свойств WSM(m,k,w)-кодов на случай использования устройств,
реализованных на элементарных логических элементах. Однако поскольку
речь идет о функциональном принципе описания логических устройств, пред-
ложенная методика синтеза СФК может быть использована при их реали-
зации на любой элементной базе. Результаты, полученные в исследовани-
ях W SM(m, k, w)-кодов, могут быть с практической точки зрения исполь-
зованы при совершенствовании средств автоматизированного проектирова-
ния цифровых систем с учетом возможностей анализа топологий логических
устройств и свойств обнаружения ошибок кодами с суммированием. Это, од-
нако, требует дополнительных исследований и адаптации представленного
алгоритма в программное обеспечение средств автоматизированного логиче-
ского проектирования.
6. Заключение
Предложенные в статье W SM(m, k, w)-коды, которые для конкретного
значения длины информационного вектора имеют модификации с фиксиро-
ванными значениями кратностей обнаруживаемых монотонных и асиммет-
ричных ошибок, позволяют получить СФК логических устройств с лучшими
(по сравнению с кодами Бергера) характеристиками по обнаружению неис-
правностей. Применение данных кодов обеспечивает обнаружение на выходах
устройства не только всех монотонных и асимметричных ошибок (как при
применении кода Бергера), но и существенного числа симметричных оши-
бок. Кроме того, данные коды позволяют строить СФК со 100%-ным обна-
ружением одиночных неисправностей в логическом устройстве с наименьшей
избыточностью, связанной с резервированием элементов в контролируемом
устройстве, по сравнению с известными методами.
СПИСОК ЛИТЕРАТУРЫ
1. McCluskey E.J. Logic Design Principles: With Emphasis on Testable Semicustom
Circuits. N.J.: Prentice Hall PTR, 1986.
2. Nicolaidis M., Zorian Y. On-Line Testing for VLSI - А Compendium of Approaches
// J. Electron. Testing: Theory Appl. 1998. V. 12. Iss. 1-2. P. 7-20. DOI:
10.1023/A:1008244815697.
139
3.
Mitra S., McCluskey E.J. Which Concurrent Error Detection Scheme to Сhoose? //
Proc. Int. Test Conf. 2000, USA, NJ, Atlantic City, NJ, 3-5 October 2000. P. 985-994.
DOI: 10.1109/TEST.2000.894311.
4.
Fujiwara E. Code Design for Dependable Systems: Theory and Practical
Applications. John Wiley & Sons, 2006.
5.
Freiman C.V. Optimal Error Detection Codes for Completely Asymmetric Binary
Channels // Inform. Control. 1962. V. 5. Is. 1. P. 64-71. DOI: 10.1016/S0019-
9958(62)90223-1.
6.
Сапожников В.В., Сапожников Вл.В., Ефанов Д.В. Классификация ошибок в
информационных векторах систематических кодов // Изв. вузов. Приборост-
роение. 2015. Т. 58. № 5. С. 333-343. DOI: 10.17586/0021-3454-2015-58-5-333-343.
7.
Berger J.M. A Note on Error Detection Codes for Asymmetric Channels // Inf.
Control. 1961. V. 4. Iss. 1. P. 68-73. DOI: 10.1016/S0019-9958(61)80037-5.
8.
Согомонян Е.С., Слабаков Е.В. Самопроверяемые устройства и отказоустойчи-
вые системы. М.: Радио и связь, 1989.
9.
Ефанов Д.В., Сапожников В.В., Сапожников Вл.В. Условия обнаружения неис-
правности логического элемента в комбинационном устройстве при функцио-
нальном контроле на основе кода Бергера // АиТ. 2017. № 5. С. 152-165.
Efanov D.V., Sapozhnikov V.V., Sapozhnikov Vl.V. Conditions for Detecting a
Logical Element Fault in a Combination Device under Concurrent Checking Based
on Berger‘s Code // Autom. Remote Control. 2017. V. 78. No. 5. P. 891-901. DOI:
10.1134/S0005117917040113.
10.
Piestrak S.J. Design of Self-Testing Checkers for Unidirectional Error Detecting
Codes. Wroclaw: Oficyna Wydawnicza Politechniki Wroclavskiej, 1995.
11.
Das D., Touba N.A. Synthesis of Circuits with Low-Cost Concurrent Error Detection
Based on Bose-Lin Codes // J. Electron. Testing: Theory Appl. 1999. V. 15. Iss. 1-2.
P. 145-155. DOI: 10.1023/A:1008344603814.
12.
Sapozhnikov V., Sapozhnikov Vl., Efanov D. Modular Sum Code in Building
Testable Discrete Systems // Proc. 13 IEEE East-West Design & Test Sympos.
(EWDTS‘2015), Batumi, Georgia, September
26-29, 2015. P.
181-187. DOI:
10.1109/EWDTS.2015.7493133.
13.
Сапожников В.В., Сапожников Вл.В., Ефанов Д.В., Черепанова М.Р. Модуль-
ные коды с суммированием в системах функционального контроля. I // Элек-
тронное моделирование. 2016. Т. 38. № 2. С. 27-48.
14.
Блюдов А.А., Ефанов Д.В., Сапожников В.В., Сапожников Вл.В. Построение
модифицированного кода Бергера с минимальным числом необнаруживаемых
ошибок информационных разрядов // Электронное моделирование. 2012. Т. 34.
№ 6. С. 17-29.
15.
Блюдов А.А., Ефанов Д.В., Сапожников В.В., Сапожников Вл.В. О кодах с
суммированием единичных разрядов в системах функционального контроля //
АиТ. 2014. № 8. С. 131-145.
Blyudov A.A., Efanov D.V., Sapozhnikov V.V., Sapozhnikov Vl.V. On Codes with
Summation of Unit Bits in Concurrent Error Detection Systems // Autom. Remote
Control. 2014. V. 75. No. 8. P. 1460-1470. DOI: 10.1134/S0005117914080098.
16.
Das D., Touba N.A. Weight-Based Codes and Their Application to Concurrent Error
Detection of Multilevel Circuits // Proc. 17 IEEE Test Symposium, California, USA,
1999. P. 370-376.
17.
Sapozhnikov V., Sapozhnikov Vl., Efanov D., Nikitin D. Combinational Circuits
Checking on the Base of Sum Codes with One Weighted Data Bit // Proc. 12 IEEE
140
East-West Design & Test Sympos. (EWDTS‘2014), Kyev, Ukraine, September 26-29,
2014. P. 126-136. DOI: 10.1109/EWDTS.2014.7027064.
18.
Сапожников В.В., Сапожников Вл.В., Ефанов Д.В. Построение кодов с сумми-
рованием с наименьшим количеством необнаруживаемых симметричных оши-
бок в информационных векторах // Радиоэлектроника и информатика. 2014.
№ 4. С. 46-55.
19.
Сапожников В.В., Сапожников Вл.В., Ефанов Д.В. Контроль комбинационных
схем на основе кодов с суммированием с одним взвешенным информационным
разрядом // Автоматика на транспорте. 2016. Т. 2. № 4. С. 564-597.
20.
Сапожников В.В., Сапожников Вл.В., Ефанов Д.В., Никитин Д.А. Исследо-
вание свойств кодов с суммированием с одним взвешенным информационным
разрядом в системах функционального контроля // Электронное моделирова-
ние. 2015. Т. 37. № 1. С. 25-48.
21.
Efanov D., Sapozhnikov V., Sapozhnikov Vl. On Variety of Sum Codes with On-Data
Bits and One Weighted Data Bit in Concurrent Error Detection Systems // Proc.
2 Int. Conf. Indust. Engineer., Appl. Manufactur. (ICIEAM), Chelyabinsk, Russia,
19-20 May, 2016. DOI: 10.1109/ICIEAM.2016.7911684.
22.
Ефанов Д.В., Сапожников В.В., Сапожников Вл.В. О свойствах кода с сумми-
рованием в схемах функционального контроля // АиT. 2010. № 6. С. 155-162.
Efanov D.V., Sapozhnikov V.V., Sapozhnikov Vl.V. On Summation Code Properties
in Functional Control Circuits // Autom. Remote Control. 2010. V. 71. No. 6.
P. 1117-1123. DOI: 10.1134/S0005117910060123.
23.
Дрозд А.В. Нетрадиционный взгляд на рабочее диагностирование вычислитель-
ных устройств // Проблемы управления. 2008. № 2. С. 48-56.
24.
Busaba F.Y., Lala P.K. Self-Checking Combinational Circuit Design for Single and
Unidirectional Multibit Errors // J. Electron. Testing: Theory Appl. 1994. Iss. 1.
P. 19-28. DOI: 10.1007/BF00971960.
25.
Morosow A., Sapozhnikov V.V., Sapozhnikov Vl.V., Goessel M. Self-Checking
Combinational Circuits with Unidirectionally Independent Outputs // VLSI Design.
1998. V. 5. Iss. 4. P. 333-345. DOI: 10.1155/1998/20389.
26.
Saposhnikov V.V., Morosov A., Saposhnikov Vl.V., Göessel M. A New
Design Method for Self-Checking Unidirectional Combinational Circuits
//
J. Electron. Testing: Theory Appl.
1998. V.
12. Iss.
1-2. P.
41-53. DOI:
10.1023/A:1008257118423.
27.
Göessel M., Ocheretny V., Sogomonyan E., Marienfeld D. New Methods of
Concurrent Checking: Edition 1. Dordrecht: Springer Science+Business Media, 2008.
28.
Гессель М., Согомонян Е.С. Построение самотестируемых и самопроверяемых
комбинационных устройств со слабонезависимыми выходами // АиТ. 1992. № 8.
С. 150-160.
Goessel M., Sogomonyan E.S. Formation of Self-Testing and Self-Checking
Combinational Circuits with Weakly Independent Outputs // Autom. Remote
Control. 1992. V. 53. No. 8. P. 1264-1272.
Статья представлена к публикации членом редколлегии М.Ф. Караваем.
Поступила в редакцию 28.11.2017
После доработки 23.10.2018
Принята к публикации 08.11.2018
141