Автоматика и телемеханика, № 11, 2020
© 2020 г. А.В. ПАНТЕЛЕЕВ, д-р физ.-мат. наук (avpanteleev@inbox.ru),
А.В. ЛОБАНОВ (lobbsasha@mail.ru)
(Московский авиационный институт)
МИНИПАКЕТНЫЙ МЕТОД АДАПТИВНОГО СЛУЧАЙНОГО ПОИСКА
ДЛЯ ПАРАМЕТРИЧЕСКОЙ ИДЕНТИФИКАЦИИ
ДИНАМИЧЕСКИХ СИСТЕМ
Рассматривается один из возможных способов решения задачи
оценки неизвестных параметров динамических моделей, описываемых
дифференциально-алгебраическими уравнениями. Оценка параметров
производится по результатам наблюдений за поведением математической
модели. Значения параметров находятся в результате минимизации кри-
терия, описывающего суммарное квадратическое отклонение значений
координат вектора состояния от полученных при измерениях точных зна-
чений в различные моменты времени. На значения параметров наложены
ограничения параллелепипедного типа. Для решения задачи оптимиза-
ции предлагается пакетный метод адаптивного случайного поиска, разви-
вающий идеи методов оптимизации, применяемых в машинном обучении.
Предложенный метод применен при решении трех модельных задач, их
результаты сравнивались с полученными при помощи градиентных ме-
тодов оптимизации, используемых в процедурах машинного обучения, и
метаэвристических алгоритмов.
Ключевые слова: параметрическая идентификация, динамическая систе-
ма, градиентные методы оптимизации, минипакетный метод, адаптивный
случайный поиск.
DOI: 10.31857/S0005231020110070
1. Введение
В статье рассматривается математическая модель динамической систе-
мы с неизвестными параметрами, описываемая системой дифференциально-
алгебраических уравнений. На каждый параметр могут быть наложены огра-
ничения в виде отрезка возможных значений с фиксированными концами.
Известны результаты наблюдения за состоянием системы в определенные
моменты времени функционирования системы. Целевая функция представ-
ляется в виде суммы квадратов отклонений значений всех компонент реше-
ния системы дифференциальных уравнений в заданные моменты времени
от полученных в результате точных измерений значений координат векто-
ра состояния модели. Ставится задача минимизации целевой функции на
множестве возможных значений параметров, удовлетворяющих заданным
ограничениям.
Большинство публикаций в области идентификации параметров основано
на вероятностном подходе (метод максимального правдоподобия, построение
доверительных интервалов и т.д.) [1, 2]. Другим направлением исследований
112
является применение методов оптимизации [3, 4]. Применяются метод кол-
локаций совместно с линеаризацией и последовательным квадратичным про-
граммированием, методы Гаусса-Ньютона, генетические алгоритмы с уточне-
нием на основе алгоритма Левенберга-Марквардта, метод ветвей и границ,
метод Лууса и др. [5-14]. Могут быть использованы классические методы
нулевого, первого и второго порядков, однако их реализация при больших
объемах измерений может быть затруднительной. Альтернативой является
применение метаэвристических алгоритмов [15-17], которые при отсутствии
теоретического доказательства сходимости позволяют получить решение до-
статочно хорошего качества за приемлемое время. Однако с ростом числа пе-
ременных их эффективное применение требует значительных вычислитель-
ных ресурсов.
Поскольку в решаемой задаче целевая функция представляется суммой
некоторых функций, то задача параметрической идентификации может быть
решена с помощью алгоритмов оптимизации, применяемых в машинном обу-
чении, в частности градиентных методов оптимизации, таких как: метод сто-
хастического градиентного спуска (Stochastic Gradient Descent, SGD), мини-
пакетный метод градиентного спуска (Mini-batch Gradient Descent), классиче-
ский метод моментов (Classical Momentum), ускоренный градиентный метод
Нестерова (Nesterov Accelerated Gradient, NAG), метод адаптивного гради-
ента (Adaptive Gradient, AdaGrad), метод скользящего среднего (Root Mean
Square Propagation, RMSProp), метод адаптивной оценки моментов (Adaptive
Moment Estimation, Adam), модификация метода Adam (Adamax), ускорен-
ный по Нестерову метод адаптивной оценки моментов (Nesterov-accelerated
Adaptive Moment Estimation, Nadam) [18-21]. В градиентных методах, при-
меняемых в машинном обучении, упрощается процедура поиска за счет вы-
числения градиента по одной (SGD) или нескольким реализациям (минипа-
кетный метод градиентного спуска), накапливания информации о величине
составляющей градиента или ее квадрате по соответствующей координате
вектора неизвестных параметров, покоординатной организации вычислений
за счет применения операций поэлементного деления и умножения векторов
(по Адамару).
Предлагается распространить идею методов стохастического и минипакет-
ного градиентного спуска на методы нулевого порядка, использующие при по-
иске информацию только о величине функции. Среди методов этой группы
выбран адаптивный метод случайного поиска [22], хорошо зарекомендовав-
ший себя при решении классических задач оптимизации. При подсчете значе-
ния целевой функции предлагается выбирать случайным образом одну, две,
три и т.д. реализации, образующие минипакет. За счет этого вычислительные
затраты могут существенно сокращаться, однако с уменьшением числа реа-
лизаций может убывать точность решения задачи и ухудшаться сходимость.
Кроме изменения способа вычисления целевой функции в методе должны
учитываться ограничения параллелепипедного типа, накладываемые на мно-
жество возможных значений оцениваемых параметров. По сравнению с гра-
диентными процедурами и методами второго порядка (Ньютона, Левенберга-
Марквардта, Ньютона-Гаусса) нет необходимости приближенно вычислять
градиент и аппроксимацию матрицы Гессе. Статья посвящена исследованию
113
предложенной минипакетной модификации адаптивного метода случайного
поиска в приложении к задачам идентификации параметров динамических
систем, описываемых дифференциально-алгебраическими уравнениями.
2. Постановка задачи
Сформулируем задачу параметрической идентификации параметров нели-
нейных динамических систем по результатам измерений.
Пусть заданы:
целевая функция
∑∑
(1)
E(θ) =
(xi(tj) - xi(θ,tj))2 →min,
θ∈Θ
j=1 i=1
и ограничения
{
x(t) = f(t, x(t), θ),
(2)
x(t0) = x0,
{
}
(3)
θ ∈ Θ = θ ∈ Rp|ai ≤ θi ≤ bi, i = 1,...,p
где x ∈ Rn - вектор состояния системы, x0 ∈ Rn - вектор начального состоя-
ния; θ - вектор неизвестных параметров системы, Θ ⊆ Rp - множество воз-
можных значений параметров, определяемое параллелепипедными ограниче-
ниями (3); t ∈ [t0, tT ] - время функционирования системы, f(t, x, θ) - извест-
ная непрерывно-дифференцируемая вектор-функция. На промежутке време-
ни [t0, tT ] известны наблюдения x(t) за вектором состояния системы в момен-
ты времени t = tj ∈ [t0, tT ], j = 1, . . . , T ; T - заданное число реализаций. При
фиксированном векторе параметров θ можно найти решение x(θ, t) системы
дифференциальных уравнений аналитически или численным методом.
Требуется найти оценкуθ вектора неизвестных параметров θ, при которой
x(θ, t) наилучшим образом согласуется с наблюдениями, т.е. обеспечивается
минимальное значение целевой функции E(θ).
3. Минипакетный адаптивный метод случайного поиска
3.1. Стратегия поиска
Задается объем минипакета d(1 ≤ d ≤ T ), определяющий способ вычисле-
ния целевой функции Ed(θ) (при d = T справедливо Ed(θ) = E(θ)). Минипа-
кет образуют попарно несовпадающие моменты времени tqj ∈ [t0, tT ] со слу-
чайными номерами. Случайный номер qj (j = 1, 2, . . . , T ) выбирается из мно-
жества возможных номеров qj ∈ {1, . . . , T } с равной вероятностью, затем он
исключается из множества, и процесс выбора продолжается, т.е. q1 = q2 =
...=qd:
∑∑(
)2
(4)
Ed(θ) =
xi(tqj ) - xi(θ,tqj )
→min,
θ∈Θ
j=1 i=1
114
где xi(θ, tqj ) - значение соответствующей координаты решения задачи Ко-
ши (2), определяемое одним из известных численных методов в случае систе-
мы нелинейных дифференциальных уравнений или аналитически (если воз-
можно) в случае линейных систем. Выражение (4) используется вместо (1) в
ходе поиска вектора наилучших оценокθd.
При решении задачи идентификации параметров возможны следующие
варианты задания минипакета:
• фиксировать число d;
• последовательно увеличивать число d, т.е. d = 1, 2, . . . , T (этот способ при-
меняется в описанной далее методике для проведения сравнения работо-
способности метода при различных объемах минипакета);
• изменять объем пакета динамически в зависимости от достижения задан-
ной точности оценивания, определяемой величиной критерия (1).
Если объем минипакета и суммарное число итераций применяемого алго-
ритма оптимизации фиксированы, то результат применения алгоритма может
изменяться при каждом его новом запуске в силу случайного характера вы-
бора моментов tqj , входящих в минипакет. Поэтому предлагается выполнить
заданное число запусков метода Smax, найти наилучшую оценкуθd по всем
запускам, а с целью анализа процесса поиска найти оценку среднего значения
критерия (4) по всем запускам и оценку среднеквадратического отклонения:
∑
v
s
u
E
d
u
1
∑
[
]2
√
(5)
Ed
= s=1
,
σEd =
Esd - Ed
,
Smax
Smax - 1
s=1
гдеθsd и Esd = Esd(θsd) - вектор оценок и значение целевой функции (4), по-
лученные в результате s-го запуска (s = 1, . . . , Smax). По завершении Smax
запусков алгоритма завершается проход.
Поскольку численные значения показателей Ed и σEd меняются при реали-
зации независимых проходов, для проведения более детального анализа влия-
ния объема минипакета предлагается провести повторное осреднение по за-
данному числу проходов Bmax и найти оценку математического ожидания и
оценку среднеквадратического отклонения оценок средних значений крите-
рия (4):
∑
v
b
u
E
d
u
∑
[
]2
1
√
(6)
Ed
= b=1
,
σE
=
Ebd - Ed
,
d
Bmax
Bmax - 1
b=1
где Ebd - значение Ed после b-го прохода (b = 1, . . . , Bmax). В итоге можно
найти наилучшую оценкуθ∗d после Bmax проходов, в каждом из которых реа-
лизуется Smax запусков алгоритма минимизации, и ее рассматривать в каче-
стве финального результата поиска. Для анализа результирующей точности
оценивания находится значение E(θ∗d) целевой функции (1).
115
Для решения задачи (4) применяется известный метод адаптивного слу-
чайного поиска [22], относящийся к методам минимизации нулевого порядка
(без использования информации о производных), модифицированный про-
веркой, процедурами обеспечения выполнения ограничений и минипакетным
способом вычисления значений целевой функции. При выполнении одного
s-го запуска алгоритма выполняются следующие операции.
Задается начальная точка θs,0d. Каждая последующая точка находится по
формуле
θs,k+1d = θs,kd + tkξk,
где tk > 0 - величина шага; ξk - случайный вектор единичной длины, опреде-
ляющий направление поиска; k - номер итерации. На текущей итерации при
помощи генерирования случайных векторов ξk получаются точки, лежащие
на гиперсфере радиуса tk с центром в точке θs,kd. Полученная точка прове-
ряется на принадлежность множеству допустимых решений, определяемому
параллелепипедными ограничениями (3). Если по какой-либо i-й координа-
те ограничения не выполняются, то возможны несколько последовательных
вариантов: генерировать решение заново, взять в качестве координаты по-
ложение ближайшей границы отрезка [ai, bi], генерировать случайную точку
согласно равномерному распределению на отрезке [ai, bi]. Значение функции
находится по формуле (4).
Если значение функции в полученной точке θs,k+1d не меньше, чем в цен-
тре, шаг считается неудачным. Если число неудачных шагов из текущей точ-
ки достигает некоторого числа M, дальнейший поиск продолжается из той
же точки, но с меньшим шагом до тех пор, пока он не станет меньше за-
ранее заданной величины R. Если же значение функции в полученной точке
меньше, чем в центре, шаг считается удачным и в найденном направлении де-
лается увеличенный шаг, играющий роль ускоряющего шага (как при поиске
по образцу в известном методе конфигураций [22]). Если при этом значе-
ние функции снова меньше, чем в центре, направление считается удачным, и
дальнейший поиск продолжается из этой точки. Если же значение функции
стало не меньше, чем в центре, направление считается неудачным, и поиск
продолжается из старого центра.
Процедура завершается либо при достижении заданного максимального
числа итераций N, либо в случае, если радиус окрестности текущего реше-
ния станет меньше величины R. В результате запуска находятся наилучшее
решениеθsd и соответствующее значение Esd = Esd(θsd) целевой функции (4).
3.2. Методика решения задачи
Обозначим: Esd - минимальное значение функции после s-го запуска;θsd -
наилучший вектор параметров после запуска.
Шаг 0. Задать:
d = 1 - начальное число реализаций (в общем случае можно начать с лю-
бого значения 1 ≤ d ≤ T );
Smax - максимальное число запусков;
116
Bmax - максимальное число проходов;
α ≥ 1 - коэффициент расширения;
0 < β < 1 - коэффициент сжатия;
M - максимальное число неудачно выполненных испытаний на текущей
итерации;
t0 = 1 - начальную величину шага (можно задать любую величину t0 > R);
R - минимальную величину шага;
N - максимальное число итераций в процедуре запуска.
Шаг 1. Положить:
b = 1 (счетчик числа проходов);
Pd = 0 (начальная величина суммы средних значений целевой функции).
Шаг 2. Положить:
s = 1 (счетчик числа запусков);
E1d = 108 ÷ 1010 (начальное значение критерия);
Sd = 0 (начальная величина суммы значений целевой функции).
Шаг 3. Задать начальную точку θs,0d, удовлетворяющую параллелепипед-
ным ограничениям (3). Положить k = 0, j = 1.
(
)T
Шаг 4. Получить случайный вектор ξj =
ξ1j,... ,ξnj
, где ξij - случай-
ная величина, равномерно распределенная на промежутке [-1, 1].
j
ξ
Шаг 5. Вычислить yj = θs,k
+tk
d
∥ξj ∥
Проверить принадлежность решения yj множеству допустимых решений Θ.
При негативном результате возможны следующие варианты действий:
а) выбрать в качестве нового положения ближайшую граничную точку
множества допустимых решений;
б) генерировать новое положение заново, так как в расчетных формулах
используются случайные величины и есть вероятность, что при других их
реализациях новое решение будет принадлежать множеству допустимых ре-
шений;
в) если вне множества Θ оказывается i-я компонента вектора yj, т.е. yji,
в качестве нового положения выбрать точку на отрезке, соединяющем yji и ai,
если yji > bi (yji и bi, если yji < ai):
(
)
yj,Newi = ai + γ yj
- ai , если yji > bi;
i
(
)
yj,Newi = bi - γ bi - yj
, если yji < ai;
i
параметр γ можно задать, например, случайным образом на основе закона
равномерного распределения, γ ∼ R[0, 1];
г) комбинировать описанные выше способы, например несколько раз про-
бовать сгенерировать положение заново и если после определенного количе-
ства попыток новое решение все равно оказывается вне множества Θ, поло-
жить yji = ai, если yji < ai (yji = bi, если yji > bi).
117
Шаг 6. Генерировать минипакет (tq1,...,tqd) объема d, где tq1,...,tqd -
попарно несовпадающие моменты времени из множества (t1, . . . , tT ). Подсчи-
тать величину Ed(yj ) по формуле (4).
Проверить выполнение условий:
(
)
а) если Ed(yj) < Ed(θs,kd), шаг удачный. Положить zj = θs,kd +α yj - θs,k
d
Определить, является ли текущее направление yj - θs,kd удачным:
• если Ed(zj ) < Ed(θs,kd), направление поиска удачное.
Положить θs,k+1d = zj , tk+1 = αtk, k = k + 1 и проверить условие оконча-
ния. Если k < N, положить j = 1 и перейти к шагу 4. Если k = N, поиск
завершить:θsd = θs,kd, перейти к шагу 8;
• если Ed(zj ) ≥ Ed(θs,kd), направление поиска неудачное, перейти к шагу 7;
б) если Ed(yj) ≥ Ed(θs,kd), шаг неудачный и перейти к шагу 7.
Шаг 7. Оценить число неудачных шагов из текущей точки:
а) если j < M, следует положить j = j + 1 и перейти к шагу 4;
б) если j = M, проверить условие окончания:
• если tk ≤ R, процесс закончить:θsd = θs,kd, Esd = Ed(θs,kd), перейти к шагу 8;
• если tk > R, положить tk = βtk, j = 1 и перейти к шагу 4.
Шаг 8. Проверить улучшение значения целевой функции в результате s-го
запуска:
• если Ed(θs,kd) < Esd, следует положить Esd = Ed(θs,kd),θsd = θs,kd и перейти
к шагу 9;
• если Ed(θs,kd) ≥ Esd, перейти к шагу 9;
Шаг 9. Вычислить Sd = Sd + Esd и проверить выполнение условий окон-
чания числа запусков:
а) если s < Smax, следует положить s = s + 1 и перейти к шагу 3;
б) если s = Smax, то положитьθd =θsd - наилучшее решение в течение b-го
прохода при заданном d; вычислить
v
u
u
∑[
]2
Ssd
1
√
Ed =
,
σEd =
Esd - Ed
Smax
Smax - 1
s=1
и перейти к шагу 10.
Шаг 10. Положить Pd = Pd+Ed, Ebd = Ed и проверить условие завершения
заданного числа проходов:
а) если b < Bmax, следует положить b = b + 1 и перейти к шагу 2;
б) если b = Bmax, вычислить:
v
u
u
∑
[
]2
Pd
1
√
Ed =
,
σE
=
Ebd - Ed
d
Bmax
Bmax - 1
b=1
118
Шаг 11. Проверить условие завершения исследований влияния объема
минипакета:
• если d < T , положить d = d + 1, s = 1 и перейти к шагу 1;
• если d = T , перейти к шагу 12.
Шаг 12. В результате найти наилучшую оценкуθ∗d после Bmax проходов
и показатели Ed, σ при каждом значении объема минипакета d. Для ана-E
d
лиза результирующей точности оценивания найти значение E(θ∗d) критерия
точности оценивания (1):
∑∑(
)2
E(θ∗d) =
xi(tj) - xi(θ∗d,tj)
j=1 i=1
Шаги 10 и 11 выполняются при необходимости.
Рекомендации по выбору параметров метода. Величина ξij , равномерно
распределенная на отрезке [-1, 1], генерируется обычно с помощью датчиков
псевдослучайных чисел. Вырабатывается случайная величина ηji , равномерно
распределенная на [0, 1], а затем используется линейное преобразование: ξji =
= 2ηji -1. Параметры алгоритма: коэффициент расширения α ≥ 1: α = 1,618;
коэффициент сжатия 0 < β < 1: β = 0,618; максимальное число неудачно вы-
полненных испытаний на текущей итерации M = 3n; начальный шаг t0 > R
можно задавать произвольно.
4. Модельные примеры
Пример 1. Математическая модель описывает необратимую реакцию
первого порядка, в которой измеряются концентрации x1, x2 компонент ве-
ществ, а θ1, θ2 - коэффициенты скоростей реакций соответственно [7, 8]:
{
x1(t) = -θ1x1(t),
x1(0) = 1,
(7)
x2(t) = θ1x1(t) - θ2x2(t), x2(0) = 0.
Целевая функция имеет вид:
∑∑
(8)
E(θ) =
[xi(tj) - xi(θ,tj)]2 → min ,
θ ∈ Θ
j=1 i=1
где T = 10, n = 2. Ограничения на параметры: 0 ≤ θ1 ≤ 10, 0 ≤ θ2 ≤ 10.
В табл. 1 представлены результаты наблюдений за реакцией.
Таблица 1. Наблюдения
j
1
2
3
4
5
6
7
8
9
10
tj
0,100
0,200
0,300
0,400
0,500
0,600
0,700
0,800
0,900
1
x1
0,606
0,368
0,223
0,135
0,082
0,050
0,030
0,018
0,011
0,007
x2
0,373
0,564
0,647
0,669
0,656
0,624
0,583
0,539
0,494
0,451
119
а
б
Результат метода МАМСП
Результат метода МАМСП
0,6
0,6
0,5
0,5
0,4
0,4
0,3
0,3
0,2
0,2
1
0,1
2
0,1
4
3
0
0
5
6
0
2,5
5,0
7,5 10,0 12,5
15,0
17,5
0
2,5
5,0
7,5 10,0 12,5
15,0
17,5
Количество итераций
Количество итераций
в
г
Результат метода МАМСП
Результат метода МАМСП
0,6
0,6
0,5
0,5
0,4
0,4
0,3
0,3
0,2
0,2
0,1
0,1
7
9
0
8
0
1
0
0
2,5
5,0
7,5 10,0 12,5
15,0
17,5
0
2,5
5,0
7,5 10,0 12,5
15,0
17,5
Количество итераций
Количество итераций
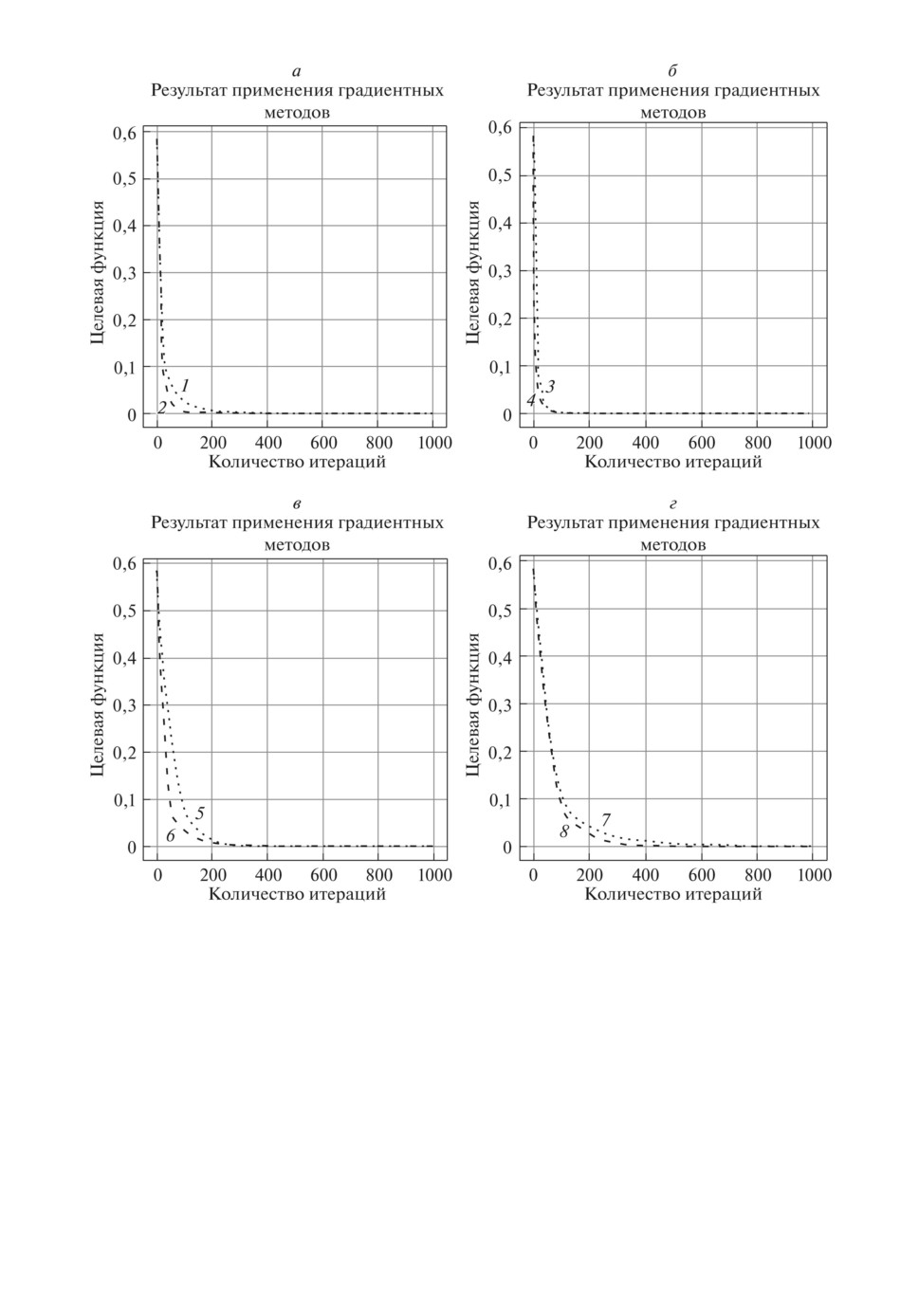
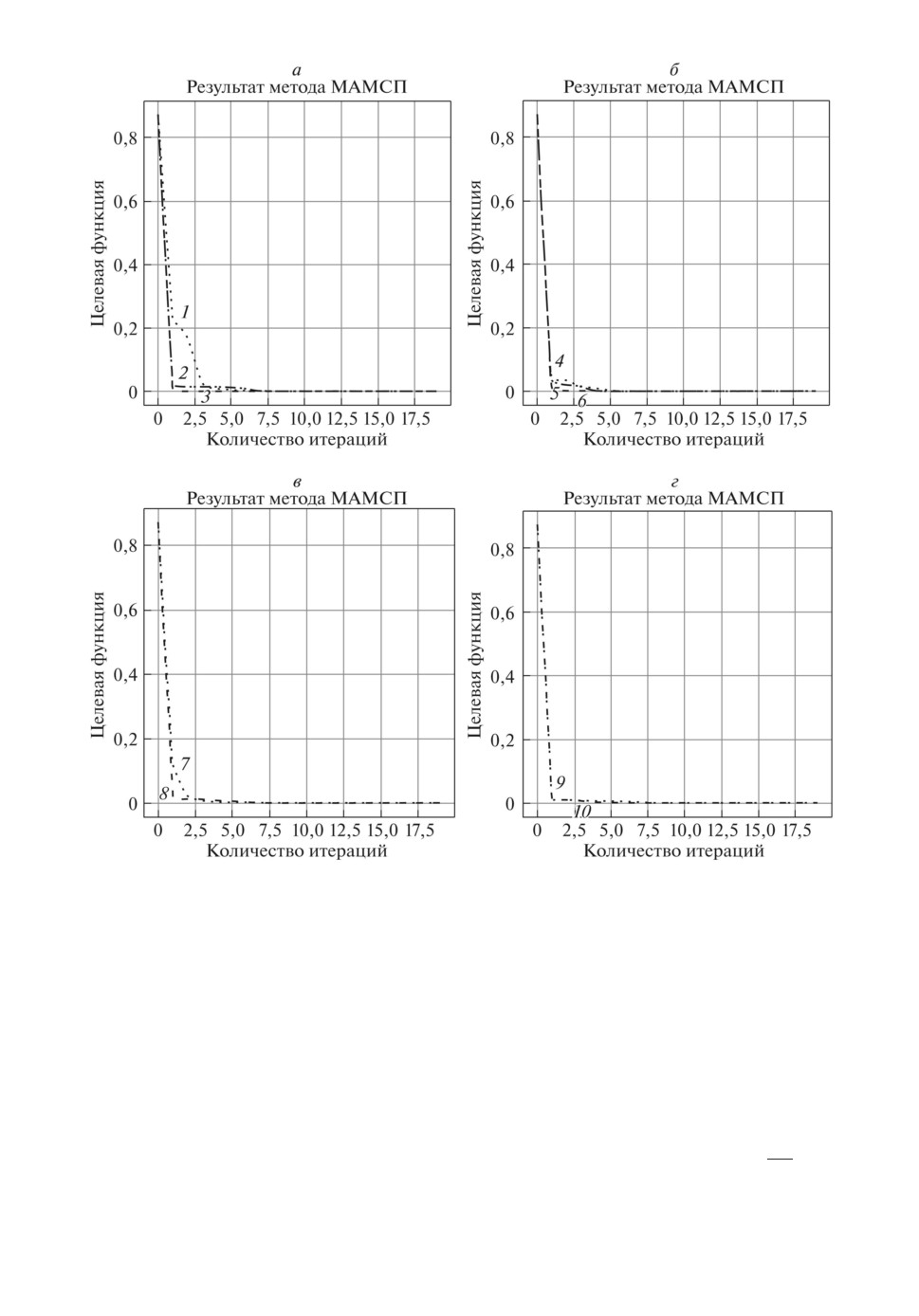
Рис. 1. Результат работы минипакетного адаптивного метода случайного по-
иска в зависимости от объема минипакета: 1 - [d = 1], 2 - [d = 2], 3 - [d = 3],
4 - [d = 4], 5 - [d = 5], 6 - [d = 6], 7 - [d = 7], 8 - [d = 8], 9 - [d = 9], 10 - [d = 10].
Наилучшее известное решение
[7, 8]: значение целевой функции
(1)
1,18584 · 10-6; вектор параметров: θ = (5,0035; 1,0000)T. Сравнимые резуль-
таты, полученные с помощью метаэвристических алгоритмов без использо-
вания минипакетов: методом фейерверков, методом большого взрыва - боль-
шого сжатия и методом гранат, приведены в [17].
Результаты решения минипакетным адаптивным методом случайного по-
иска представлены на рис. 1 и в табл. 2. На рис. 1 приведены решения в за-
висимости от объема минипакета. В табл. 2 показаны лучшие результаты в
зависимости от объема минипакета. Во всех тестах N = 150 - максимальное
число итераций, M = 10 - максимальное число неудачно выполненных ис-
120
Таблица 2. Результат решения минипакетным адаптивным методом
случайного поиска (МАМСП)
d
θ∗1d
θ∗2d
E(θ∗d)
Ed
σEd
1
5,00486
1,00006
1,24600 · 10-6
0,02034
0,25643
2
5,00269
0,99998
1,20612 · 10-6
0,00513
0,15234
3
5,00343
0,99999
1,18608 · 10-6
0,00149
0,09354
4
5,00323
0,99997
1,18844 · 10-6
0,00034
0,04729
5
5,00365
1,00001
1,18673 · 10-6
0,00025
0,03888
6
5,00342
1,00003
1,18663 · 10-6
1,30989 · 10-6
0,00115
7
5,00350
1,00000
1,18595 · 10-6
1,25257 · 10-6
0,00112
8
5,00346
1,00002
1,18623 · 10-6
1,22674 · 10-6
0,00111
9
5,00341
1,00001
1,18624 · 10-6
1,20433 · 10-6
0,00110
10
5,00349
1,00000
1,18595 · 10-6
1,18595 · 10-6
0,00109
Таблица 3. Результаты сравнения МАМСП (E(θ∗10) = 1, 18595 · 10-6)
с градиентными методами по наилучшей достигнутой величине кри-
терия (1) (наилучшее известное решение E(θ) = 1, 18584 · 10-6)
SGD
ClassMom
NAG
AdaGrad
1,37131 · 10-6
1,05923 · 10-6
9,32474 · 10-7
1,82699 · 10-6
RMSProp
ADAM
AdaMax
Nadam
7,13530 · 10-5
9,83579 · 10-7
1,18653 · 10-6
1,33935 · 10-6
пытаний на текущей итерации, R = 8 · 10-10 - минимальная величина шага,
Smax = 100 - максимальное число запусков, Bmax = 100 - максимальное чис-
ло проходов, α = 1,618 - коэффициент расширения, β = 0,618 - коэффициент
сжатия, Ed и σ
- оценка математического ожидания и оценка среднеквадра-
Ed
тического отклонения оценок средних значений критерия (4), θs,0d = (2, 3)T -
начальная точка.
В табл. 2 представлены результаты решения примера 1 минипакетным
адаптивным методом случайного поиска при различных объемах минипакета
1 ≤ d ≤ 10 (суммарное время работы алгоритма составило 57 c (процессор
intel CORE i5 2.10 GHz)).
Анализ табл. 2 позволяет сделать вывод о том, что сходимость к извест-
ному результату достигается при всех объемах минипакета, точность оценок
возрастает с увеличением d, при d = 10 ответ практически совпадает с извест-
ным. Следует отметить, что зависимость величины паказателя Ed от объема
минипакета, как правило, является монотонной, а показателя Ed может быть
не монотонной в силу случайности генерации минипакета.
Так как система дифференциальных уравнений (7) линейная, то удает-
ся найти ее аналитическое решение, что позволяет находить производные
целевой функции по параметру θ и пользоваться градиентными методами
оптимизации процедур машинного обучения. В табл. 3 представлены резуль-
таты сравнения решений, полученных предложенным методом и известными
градиентными методами машинного обучения.
121
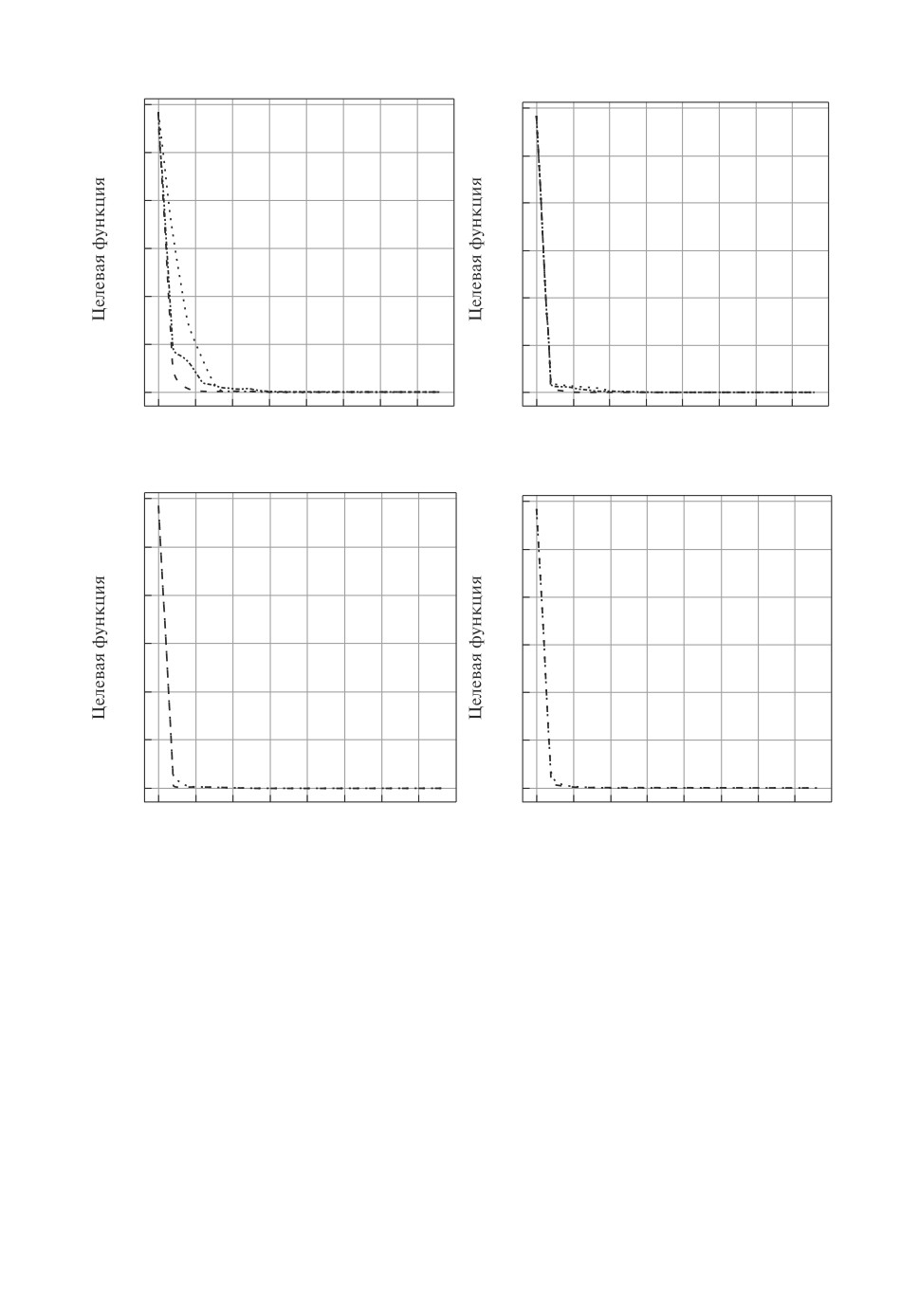
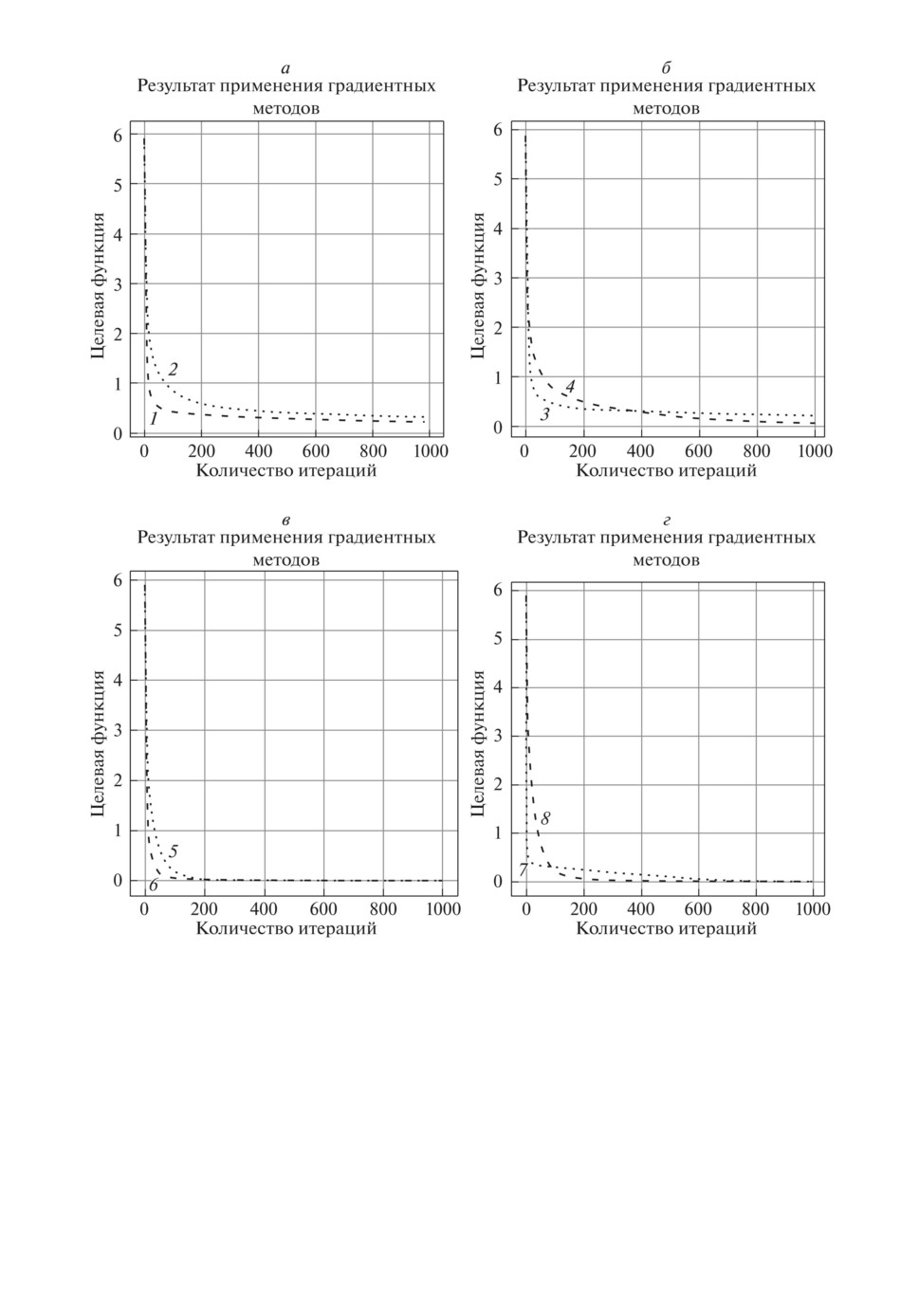
Рис. 2. Результаты применения градиентных методов оптимизации: 1 - SGD,
2 - ClasMom, 3 - NAG, 4 - AdaGrad, 5 - RMSProp, 6 - ADAM, 7 - AdaMax,
8 - Nadam.
На рис. 2 приведены результаты решения примера 1 (изменение целевой
функции с ростом числа итераций) при выбранных для обеспечения сходимо-
сти значениях шага градиентных методов машинного обучения. Рисунок 2 со-
ответствует начальной точке θs,0d = (2, 3)T, значениям шага SGD - 0,2; Class-
Mom - 0,2; NAG - 0,2; AdaGrad - 0,3; RMSProp - 0,02; ADAM - 0,02; AdaMax -
0,02; Nadam - 0,02 (краткое описание методов приведено в Приложении).
Пример 2. Модель описывает каталитический крекинг для превращения
газойля в бензин. x1, x2 - концентрации компонент, θ1, θ2, θ3 - коэффициенты
122
Таблица 4. Наблюдения
j
1
2
3
4
5
6
7
8
9
10
tj
0,0250
0,0500
0,0750
0,1000
0,1250
0,1500
0,1750
0,2000
0,2250
0,2500
x1
0,7307
0,5982
0,4678
0,4276
0,3436
0,3126
0,2808
0,2692
0,2210
0,2122
x2
0,1954
0,2808
0,3175
0,3047
0,2991
0,2619
0,2391
0,2210
0,1898
0,1801
j
11
12
13
14
15
16
17
18
19
20
tj
0,3000
0,3500
0,4000
0,4500
0,5000
0,5500
0,6500
0,7500
0,8500
0,9500
x1
0,1903
0,1735
0,1615
0,1240
0,1190
0,1109
0,0890
0,0820
0,0745
0,0639
x2
0,1503
0,1030
0,0964
0,0581
0,0417
0,0413
0,0367
0,0219
0,0124
0,0089
Таблица 5. Результат решения минипакетным адаптивным методом
случайного поиска
d
θ∗1d
θ∗2d
θ∗3d
E(θ∗d)
Ed
σEd
L
1
12,71954
8,62194
1,94031
3,87373 · 10-3
0,09323
0,24901
4
2
12,19646
8,30268
2,10194
3,15674 · 10-3
0,02092
0,07256
19
3
12,31779
8,13561
2,04472
2,77824 · 10-3
0,01287
0,04473
21
4
12,41866
8,13885
2,03050
2,78531 · 10-3
0,00421
0,00457
52
5
12,13970
7,97463
2,15734
2,81254 · 10-3
0,00391
0,00408
56
6
12,26164
8,07087
2,17864
2,76099 · 10-3
0,00352
0,00361
72
7
12,21603
8,01094
2,10274
2,79811 · 10-3
0,00327
0,00330
84
8
12,26468
8,03486
2,25584
2,78409 · 10-3
0,00312
0,00314
93
9
12,27566
8,05249
2,12116
2,75432 · 10-3
0,00309
0,00312
93
10
12,20370
8,03736
2,15236
2,76500 · 10-3
0,00305
0,00311
96
11
12,23648
8,01906
2,19338
2,74747 · 10-3
0,00300
0,00310
98
12
12,17853
7,97887
2,21586
2,75452 · 10-3
0,00294
0,00300
98
13
12,21782
8,01541
2,20164
2,74887 · 10-3
0,00291
0,00295
100
14
12,22653
8,01777
2,19107
2,74819 · 10-3
0,00287
0,00292
100
15
12,18114
7,97683
2,21814
2,75350 · 10-3
0,00283
0,00287
100
16
12,23149
7,99277
2,21086
2,74755 · 10-3
0,00282
0,00282
100
17
12,22948
7,98994
2,21324
2,74755 · 10-3
0,00279
0,00279
100
18
12,22944
8,00584
2,19629
2,74727 · 10-3
0,00277
0,00277
100
19
12,23437
8,00666
2,19891
2,74701 · 10-3
0,00276
0,00276
100
20
12,23645
8,00809
2,19849
2,74699 · 10-3
0,00274
0,00274
100
скоростей реакций [7, 8]:
{
x1(t) = -(θ1 + θ3)x21(t), x1(0) = 1,
(9)
x2(t) = θ1x21(t) - θ2x2(t), x2(0) = 0.
Целевая функция имеет вид:
∑∑
(10)
E(θ) =
[xi(tj) - xi(θ,tj)]2 → min,
θ∈Θ
j=1 i=1
где T = 20, n = 2. Ограничения на параметры: 0 ≤ θ1 ≤ 20, 0 ≤ θ2 ≤ 20,
0 ≤ θ3 ≤ 20.
В табл. 4 представлены результаты наблюдений за реакцией.
123
а
б
Результат метода МАМСП
Результат метода МАМСП
6
6
5
5
4
4
3
3
2
2
1
1
1
4
2
5
0
0
3
6
0
2,5 5,0
7,5 10,0 12,5
15,0
17,5
0
2,5 5,0
7,5 10,0 12,5
15,0
17,5
Количество итераций
Количество итераций
в
г
Результат метода МАМСП
Результат метода МАМСП
6
6
5
5
4
4
3
3
2
2
1
1
9
7
0
0
8
10
0
2,5
5,0
7,5 10,0 12,5
15,0 17,5
0
2,5
5,0
7,5 10,0 12,5
15,0
17,5
Количество итераций
Количество итераций
Рис. 3. Результат работы минипакетного адаптивного метода случайного по-
иска в зависимости от объема минипакета: 1 - [d = 1], 2 - [d = 2], 3 - [d = 3],
4 - [d = 4], 5 - [d = 5], 6 - [d = 6], 7 - [d = 7], 8 - [d = 8], 9 - [d = 9], 10 - [d = 10].
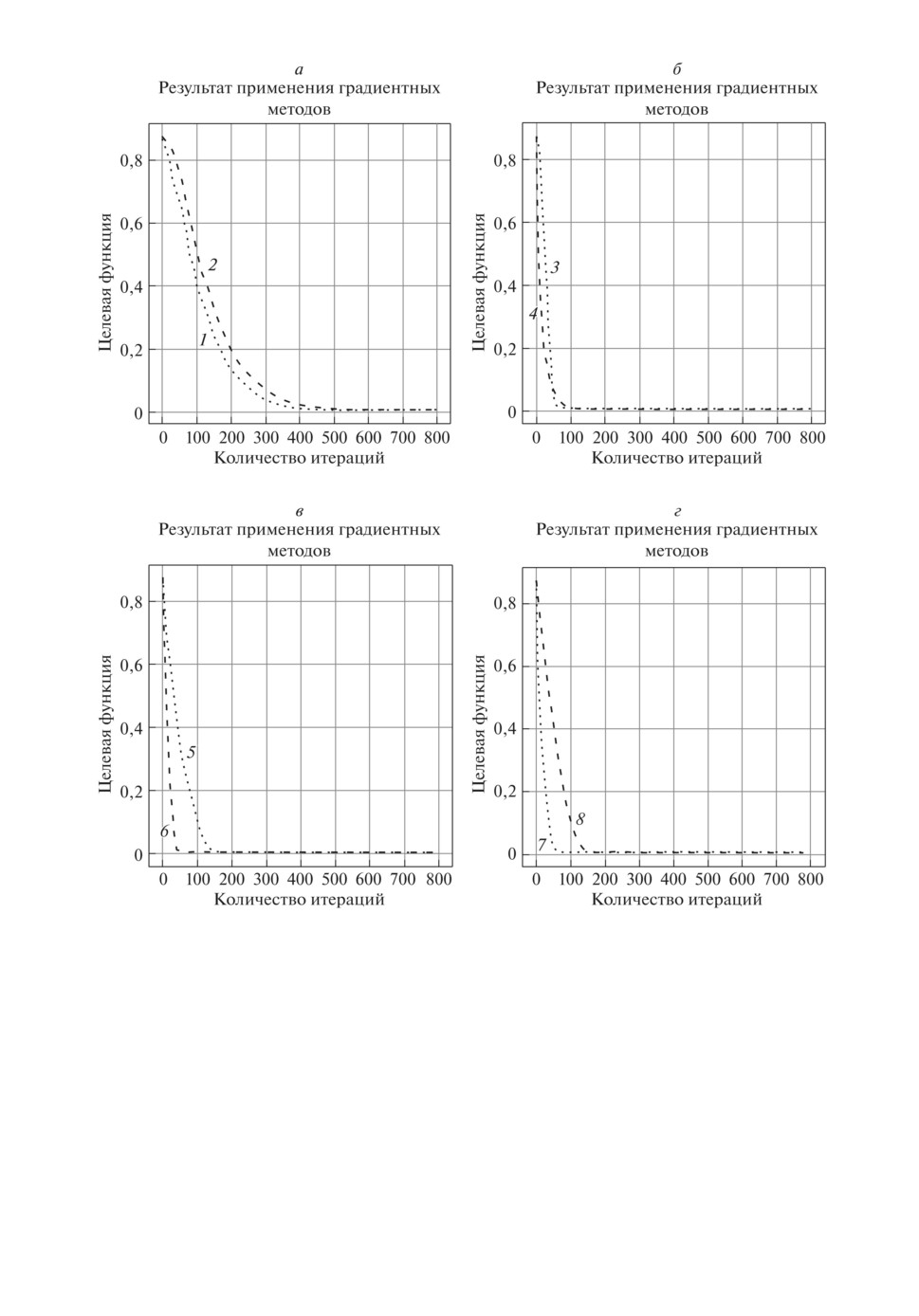
Наилучшее известное решение [7, 8]: значение целевой функции: 2,65567×
×10-3, вектор параметров: θ = (12,214; 7,9798; 2,2216)T.
Сравнимые результаты, полученные с помощью метаэвристических алго-
ритмов без использования минипакетов: методом фейерверков, методом боль-
шого взрыва - большого сжатия и методом гранат, приведены в [17].
Результат решения минипакетным адаптивным методом случайного поис-
ка представлены в табл. 5 и на рис. 3. На рис. 3 приведены решения в за-
висимости от объема минипакета. В табл. 5 показаны лучшие результаты в
зависимости от объема минипакета. Во всех тестах N = 150 - максимальное
124
Таблица 6. Результаты сравнения МАМСП (E(θ∗20) = 2,74699 · 10-3)
с градиентными методами по наилучшей достигнутой величине кри-
терия (1) (наилучшее известное решение E(θ) = 2,65567 · 10-3)
SGD
ClassMom
NAG
AdaGrad
8,60908 · 10-3
3,06110 · 10-3
3,51929 · 10-3
7,01255 · 10-3
RMSProp
ADAM
AdaMax
Nadam
4,11410 · 10-3
2,95625 · 10-3
5,81047 · 10-3
3,01257 · 10-3
число итераций, M = 20 - максимальное число неудачно выполненных ис-
пытаний на текущей итерации, R = 8 · 10-10 - минимальная величина шага,
Smax = 100 - максимальное число запусков, α = 1,618 - коэффициент рас-
ширения, β = 0,618 - коэффициент сжатия, Ed - оценка математического
ожидания, σEd - оценка среднеквадратического отклонения, L - количество
попаданий (значение E(θ) попало в ε-окрестность известного значения целе-
вой функции, где ε = 0,001), θs,0d = (1, 20, 0)T - начальная точка.
В табл. 5 представлены результаты решения примера 2 минипакетным
адаптивным методом случайного поиска при различных объемах минипакета
1 ≤ d ≤ 20 (суммарное время работы алгоритма составило 18 мин (процессор
intel CORE i5 2.10 GHz)).
На рис. 3 представлены результаты решения задачи с применением ми-
нипакетного адаптивного метода случайного поиска при объеме минипакета
1≤ d ≤ 10. При 10 ≤ d ≤ 20 характер изменения такой же, как на рис. 3,г.
При этом с увеличением объема минипакета характеристика отклонения от
наилучшего известного решения уменьшается.
Так как система дифференциальных уравнений (9) нелинейная, то для
нахождения градиента функции будем использовать конечно-разностные ап-
проксимации, а решение системы дифференциальных уравнений находим
численным методом Рунге-Кутты 4-го порядка (с шагом 0,005). В данном
случае градиент целевой функции имеет вид:
∂E(θ)
∂E(θ)
= E(θ1+Δ;θ2;θ3)-E(θ1;θ2;θ3)
,
∂θ1
∂θ1
Δ
∂E(θ)
∂E(θ)
= E(θ1;θ2+Δ;θ3)-E(θ1;θ2;θ3)
∇θE(θ) =
,
,
∂θ2
∂θ2
Δ
∂E(θ)
∂E(θ)
= E(θ1;θ2;θ3+Δ)-E(θ1;θ2;θ3)
,
∂θ3
∂θ3
Δ
где Δ = 0,01.
В табл. 6 представлены результаты сравнения решений, полученных пред-
ложенным методом и известными градиентными методами машинного обу-
чения.
На рис. 4 приведены результаты решения примера (изменение целевой
функции с ростом числа итераций) при разных значениях шага. Рисунок 3
соответствует начальной точке θs,0d = (1, 20, 0)T и значениям шага SGD - 1;
125
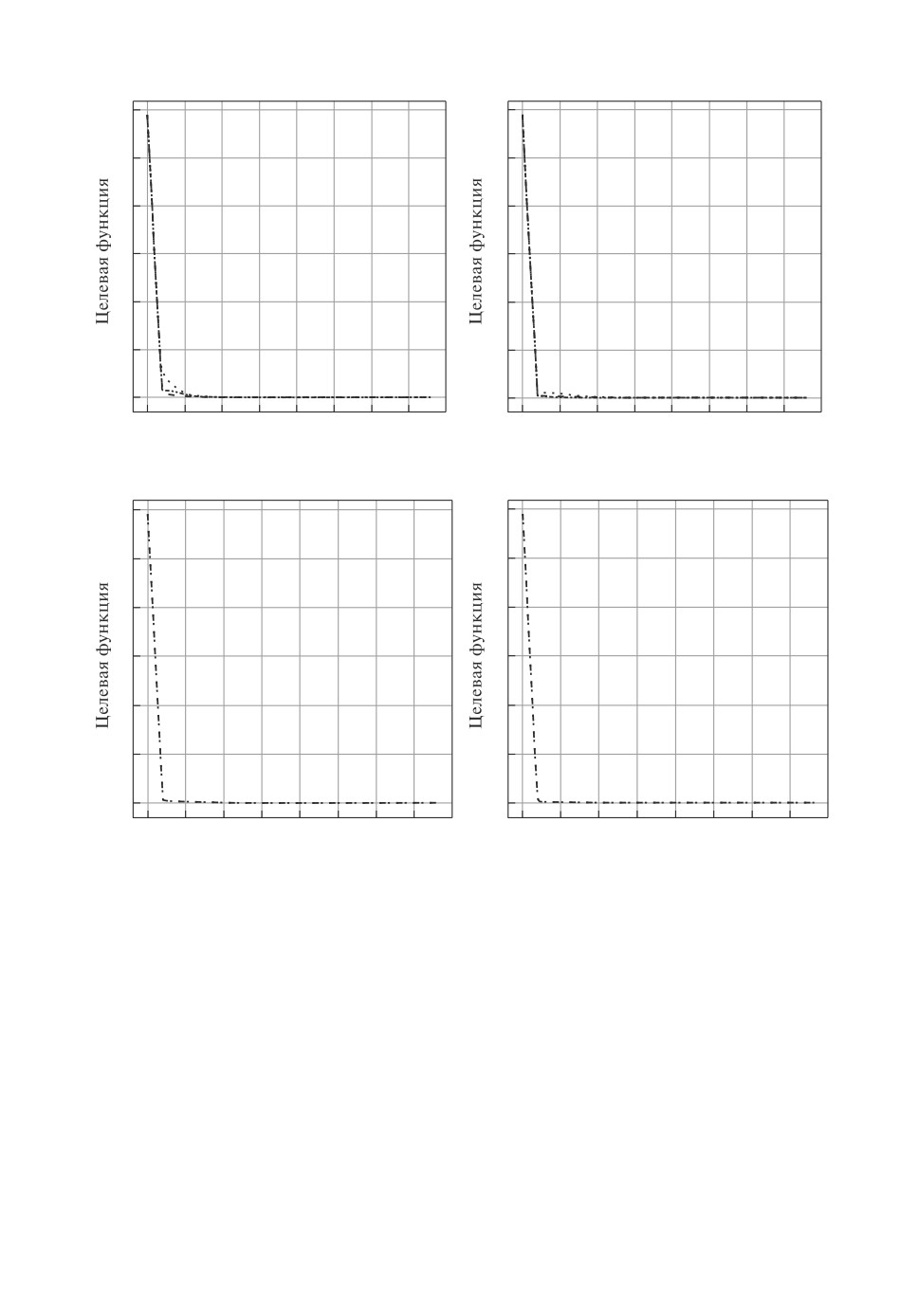
Рис. 4. Результаты применения градиентных методов оптимизации: 1 - SGD,
2 - ClasMom, 3 - NAG, 4 - AdaGrad, 5 - RMSProp, 6 - ADAM, 7 - AdaMax,
8 - Nadam.
ClassMom - 0,3; NAG - 0,3; AdaGrad - 0,3; RMSProp - 0,3; ADAM - 0,3;
AdaMax - 1; Nadam - 0,1.
Пример 3. Математическая модель имеет вид:
{x1(t) = θ1x1(t)(1 - x2(t)), x1(0) = 1,
(11)
x2(t) = θ2x2(t)(x1(t) - 1), x2(0) = 0.
126
Таблица 7. Наблюдения
j
1
2
3
4
5
6
7
8
9
10
tj
1,0000 2,0000 3,0000 4,0000 5,0000 6,0000 7,0000 8,0000 9,0000 10,0000
x1 0,7990 0,8731 1,2487 1,0362 0,7483 1,0024 1,2816 0,8944 0,7852
1,1527
x2 1,0758 0,8711 0,9393 1,1468 1,0027 0,8577 1,0274 1,1369 0,9325
0,9074
Таблица 8. Результат решения минипакетным адаптивным методом
случайного поиска
d
θ∗1d
θ∗2d
E(θ∗d)
E(θ)
Ed
σEd
1
3,15622
0,95191
0,001501
1,24924 · 10-3
0,64113
0,78286
2
3,27374
0,91270
0,001268
1,24924 · 10-3
0,74766
0,85022
3
3,24234
0,92115
0,001250
1,24924 · 10-3
0,67812
0,74912
4
3,22817
0,92447
0,001276
1,24924 · 10-3
0,64793
0,71009
5
3,25294
0,91882
0,001255
1,24924 · 10-3
0,58970
0,68599
6
3,26656
0,91384
0,001256
1,24924 · 10-3
0,66807
0,71758
7
3,26416
0,91397
0,001264
1,24924 · 10-3
0,61353
0,67164
8
3,24321
0,92107
0,001249
1,24924 · 10-3
0,45911
0,54942
9
3,24711
0,91979
0,001250
1,24924 · 10-3
0,36868
0,42101
10
3,24444
0,92080
0,001249
1,24924 · 10-3
0,30586
0,34670
Модель описывает взаимодействие двух биологических видов: “хищник”-
“жертва”. x1 - число особей “жертва”, x2 - число особей “хищник”. θ1 - ко-
эффициент роста и истребления популяции вида “жертва”, θ2 - коэффициент
роста и смертности популяции вида “хищник”. Различные методы решения
задач анализа и фильтрации в вольтерровских системах изложены в [23, 24].
Целевая функция имеет вид:
∑∑
(12)
E(θ) =
[xi(tj) - xi(θ,tj)]2 → min ,
θ ∈ Θ
j=1 i=1
где T = 10, n = 2. Ограничения на параметры: 0 ≤ θ1 ≤ 10, 0 ≤ θ2 ≤ 10.
В табл. 7 представлены результаты наблюдений за реакцией.
Наилучшее известное решение [7, 8]: значение целевой функции: 1,24924×
×10-3, вектор параметров: θ = (3,2434; 0,9209)T.
Сравнимые результаты, полученные с помощью метаэвристических алго-
ритмов без использования минипакетов: методом фейерверков, методом боль-
шого взрыва - большого сжатия и методом гранат, приведены в [17].
Результат решения минипакетным адаптивным методом случайного поис-
ка представлены в табл. 8 и на рис. 5. В табл. 8 показаны лучшие результаты
в зависимости от объема минипакета. На рис. 5 приведены решения в за-
висимости от объема минипакета. Во всех тестах N = 150 - максимальное
число итераций, M = 15 - максимальное число неудачно выполненных ис-
пытаний на текущей итерации, R = 8 · 10-10 - минимальная величина шага,
Smax = 100 - максимальное число запусков, α = 1,618 - коэффициент рас-
ширения, β = 0,618 - коэффициент сжатия, Ed - оценка математического
127
Рис. 5. Результат работы минипакетного адаптивного метода случайного по-
иска в зависимости от объема минипакета: 1 - [d = 1], 2 - [d = 2], 3 - [d = 3],
4 - [d = 4], 5 - [d = 5], 6 - [d = 6], 7 - [d = 7], 8 - [d = 8], 9 - [d = 9], 10 - [d = 10].
ожидания, σEd - оценка среднеквадратического отклонения, θs,0d = (4, 1)T -
начальная точка.
В табл. 8 представлены результаты решения примера 3 минипакетным
адаптивным методом случайного поиска при различных объемах минипакета
1 ≤ d ≤ 10 (суммарное время работы алгоритма составило 20 минут (процес-
сор intel CORE i5 2.10 GHz)).
Анализ данных табл. 8 показывает, что значения характеристики Ed зна-
чительно отличаются от наилучших значений критерия E(θ∗d) при всех рас-
сматриваемых объемах минипакета. Это свидетельствует о том, что для по-
128
Рис. 6. Результаты применения градиентных методов оптимизации: 1 - SGD,
2 - ClasMom, 3 - NAG, 4 - AdaGrad, 5 - RMSProp, 6 - ADAM, 7 - AdaMax,
8 - Nadam.
лучения приемлемого результата потребуется реализация достаточного коли-
чества запусков (здесь Smax = 100).
Cистема дифференциальных уравнений (11) является нелинейной, и для
нахождения градиента функции будем использовать конечно-разностные ап-
проксимации (Δ = 0,01). Решение системы дифференциальных уравнений
находим численным методом Рунге-Кутты 4-го порядка (с шагом 0,2). На
рис. 6 приведены результаты решения примера (изменение целевой функции
129
Таблица 9. Результаты сравнения МАМСП (E(θ∗10) = 1, 24924 · 10-3)
с градиентными методами по наилучшей достигнутой величине кри-
терия (1) (наилучшее известное решение E(θ) = 1, 24924 · 10-3)
SGD
ClassMom
NAG
AdaGrad
7,05873 · 10-3
7,03563 · 10-3
6,85268 · 10-3
4,39537 · 10-3
RMSProp
ADAM
AdaMax
Nadam
4,55656 · 10-3
3,28811 · 10-3
6,85572 · 10-3
4,51559 · 10-3
с ростом числа итераций) при разных значениях шага. Рисунок 6 соответ-
ствует начальной точке θs,0d = (4, 1)T, значениям шага SGD - 0,002; Class-
Mom - 0,0002; NAG - 0,002; AdaGrad - 0,02; RMSProp - 0,002; ADAM - 0,002;
AdaMax - 0,02; Nadam - 0,002.
В табл. 9 представлены результаты сравнения решений, полученных пред-
ложенным методом и известными градиентными методами машинного обу-
чения.
Как следует из сравнительного анализа рис. 1, 3, 5 и рис. 2, 4, 6, метод
МАМСП не только не уступает известным градиентным методам, но и превос-
ходит большинство методов при достаточном объеме минипакета d. Характер
сходимости алгоритма МАМСП к наилучшему известному результату срав-
ним с поведением метода ADAM - наилучшего из приведенных градиентных
методов.
5. Заключение
Предложен минипакетный алгоритм адаптивного случайного поиска для
решения задачи оценивания параметров динамических систем, использую-
щий идеи популярных методов оптимизации, применяемых в машинном обу-
чении. Приведены результаты сравнения эффективности его применения по
сравнению с известными градиентными методами оптимизации: SGD, Clas-
sical Momentum, NAG, AdaGrad, RMSProp, Adam, Adamax, Nadam на трех
модельных примерах. На данный момент представляется возможным его при-
менение в задачах параметрического синтеза субоптимального управления
пучками траекторий детерминированных систем, а также управления стоха-
стическими системами при неполной информации о состоянии, в том числе
систем совместного оценивания и управления, в которых критерий качества
управления может быть приближенно представлен в виде суммы некоторых
функций.
ПРИЛОЖЕНИЕ
А. Метод стохастического градиентного спуска (Stochastic Gradient De-
scent, SGD):
θk+1 = θk - αk∇θ L(θk, x(tj),tj) =
[
]
∑
=θk -αk∇θ
(xi(tj) - xi(θ,tj))2
,
i=1
|
{z
}
L(θk ,x(tj ),tj )
130
где αk > 0, k = 0, 1, . . . , - величина шага, tj - случайный момент времени на
множестве T , выбираемый на каждой k-й итерации заново; ∇θ - градиент по
вектору параметров.
Б. Классический метод моментов (Classical Momentum, ClassMom):
θk+1 = θk - αkvk,
vk+1 = βvk + (1 - β)∇θL(θk, x(tj),tj),
где v0 = o - нулевой вектор-столбец, β = 0,9.
В. Ускоренный градиентный метод Нестерова (Nesterov Accelerated Gradi-
ent, NAG) для решения задачи f(x∗) = minx∈Rn f(x).
Шаг 1. Задать параметры: γ, γ ∈ (0,1), - коэффициент сохранения
(γ = 0,9); η - коэффициент влияния новой информации; x0 ∈ Rn - началь-
ная точка; v0 = o; ε1 > 0.
Положить k = 0.
Шаг 2. Положить k = k + 1 и выполнить:
yk = xk - γvk-1, gk = ∇fk(yk), vk = γvk-1 + ηgk.
Шаг 3. Вычислить xk = xk-1 - vk.
Шаг 4. Проверить выполнение условия
xk - xk-1< ε1.
Если условие выполнено, то x∗ = xk. Иначе перейти к шагу 2.
Г. Метод адаптивного градиента (Adaptive Gradient, AdaGrad) для реше-
ния задачи f(x∗) = minx∈Rn f(x).
Шаг 1. Задать параметры: γ, γ ∈ (0,1), - коэффициент сохранения (γ =
= 0,9); η - скорость обучения (обычно η = 0,01); x0 ∈ Rn - начальная точка;
ε = 10-6 ÷ 10-8 - сглаживающий параметр; ε1 > 0; G-1 = o.
Положить k = 0.
Шаг 2. Положить
gk = ∇fk(xk); Gk = Gk-1 + gk ⊙ gk,
где ⊙ - поэлементное произведение матриц по Адамару.
Шаг 3. Вычислить
√
xk+1 = xk - ηgk ⊘ Gk + ε,
где ⊘ - операция поэлементного деления матриц.
Шаг 4. Проверить выполнение условия
xk+1 - xk< ε1.
Если условие выполнено, то x∗ = xk+1. Иначе положить k = k + 1 и перей-
ти к шагу 2.
Д. Метод скользящего среднего (Root Mean Square Propagation, RMSProp)
для решения задачи f(x∗) = minx∈Rn f(x).
131
Шаг 1. Задать параметры: γ, γ ∈ (0,1), - коэффициент сохранения
(γ = 0,9); x0 ∈ Rn - начальная точка; ε = 10-6 ÷ 10-8 - сглаживающий па-
раметр; ε1 > 0; η - величина шага (обычно η = 0,001); M-1 = o.
Положить k = 0.
Шаг 2. Положить gk = ∇fk(xk); Gk = gk ⊙ gk; Mk = γMk-1 + (1 - γ)Gk.
√
Шаг 3. Вычислить xk+1 = xk - ηgk ⊘
Mk + ε.
Шаг 4. Проверить выполнение условия
xk+1 - xk< ε1.
Если условие выполнено, то x∗ = xk+1. Иначе положить k = k+1 и перейти
к шагу 2.
Е. Метод адаптивной оценки моментов (Adaptive Moment Estimation,
Adam) для решения задачи M[f(x)] → min, в которой имеются случайные
реализации f1(x), f2(x), . . . , fK (x).
Шаг 1. Задать параметры: α = 0,001 - величина шага; β1 = 0,9; β2 =
= 0,999 - параметры оценки моментов, x0 ∈ Rn - начальная точка; ε = 10-8 -
сглаживающий параметр; ε1 > 0; m0 = o - начальное значение первого век-
тора моментов M[∇f(x)]; v0 = o - начальное значение второго вектора мо-
ментов M[∇f(x) ⊙ ∇f(x)].
Положить k = 0.
Шаг 2. Положить k = k + 1,
gk = ∇fk(xk-1); mk = β1mk-1 + (1 - β1)gk;
Gk = gk ⊙ gk; vk = β2vk-1 + (1 - β2)Gk;
k
m
vk
mk =
;
vk =
k
1-β1k
1-β2
√
Шаг 3. Вычислить xk = xk-1 - α mk ⊘
vk + ε.
xk+1-xk
Шаг 4. Проверить выполнение условия
<ε1.
Если условие выполнено, то x∗ = xk. Иначе перейти к шагу 2.
Ж. Модификация метода Adam (Adamax) для решения задачи M[f(x)] →
→ min, где f(x)∈C1. Имеются случайные реализации f1(x),f2(x),... ,fK(x).
Шаг 1. Задать параметры: α = 0,002 - величина шага; β1 = 0,9; β2 =
= 0,999 - параметры оценки моментов, β2 ∈ [0, 1); x0 ∈ Rn - начальная точ-
ка; ε = 10-8 - сглаживающий параметр; ε1 > 0, m0 = o - начальное значение
первого вектора моментов M[∇f(x)]; u0 = o.
Положить k = 0.
Шаг 2. Положить k = k + 1,
gk = ∇fk(xk-1); mk = β1mk-1 + (1 - β1)gk,
{
}
uk = max β2uk-1,gk
(операция max выполняется поэлементно).
α
Шаг 3. Вычислить xk = xk-1 -
mk ⊘ uk.
k
1-β1
132
Шаг 4. Проверить выполнение условия
xk+1 - xk< ε1.
Если условие выполнено, то x∗ = xk. Иначе перейти к шагу 2.
З. Ускоренный по Нестерову метод адаптивной оценки моментов (Neste-
rov-accelerated Adaptive Moment Estimation, Nadam).
Шаг 1. Задать параметры: α = 0,002 - величина шага; β1 = 0,975; β2 =
= 0,999 - параметры оценки моментов, x0 ∈ Rn - начальная точка; ε = 10-8 -
сглаживающий параметр; m0 = o - начальное значение первого вектора мо-
ментов M[∇f(x)]; v0 = o - начальное значение второго вектора моментов
M [∇f(x) ⊙ ∇f(x)]. Положить k = 0.
Шаг 2. Положить k = k + 1,
gk = ∇fk(xk-1); mk = β1mk-1 + (1 - β1)gk;
Gk = gk ⊙ gk; vk = β2vk-1 + (1 - β2)Gk;
k
β1m
(1 - β1)gk
β2vk
mk =
-
;
vk =
k
1-β1k+1
1-β1k
1-β2
√
Шаг 3. Вычислить xk = xk-1 - α mk ⊘
vk + ε.
Шаг 4. Проверить выполнение условия
xk+1 - xk< ε1.
Если условие выполнено, то x∗ = xk. Иначе перейти к шагу 2.
И. Минипакетный метод градиентного спуска (Mini-batch Gradient De-
scent):
θk+1 = θk - αk∇θ Q(θk), αk > 0, k = 0,1,... ,
где αk - величина шага (learning rate),
2
∑
∑
∑
1
1
Q(θ) =
θjfj(xi) - yi
=
L(θ, xi, yi),
m
m
i∈Jm j=1
i∈Jm
|
{z
}
L(θ,xi,yi)
где Jm - набор из m номеров произвольных элементов (xi, yi) ∈ Xl обучаю-
щей выборки (можно взять m подряд идущих элементов). Чтобы реализовать
одно улучшение параметров, требуется использовать не весь набор данных
(dataset), а его небольшую часть (в прикладных задачах обычно от 50 до
256 элементов).
СПИСОК ЛИТЕРАТУРЫ
1. Bard Y. Nonlinear parameter estimation. N.Y.: Acad. Press, 1974.
2. Ивченко Г.И., Медведев Ю.И. Введение в математическую статистику. М.:
Книжный дом “ЛИБРОКОМ”, 2014.
3. Stewart W.E., Caracotsios M., Sorensen J.P. Parameter Estimation from Multire-
sponse Data // AIChE J. 1992. 38 (5). P. 641-650.
133
4.
Biegler L.T. Optimization Algorithms for Parameter Estimation and Data Reconcil-
iation. Carnegie Mellon Center.
5.
Csendes T. Nonlinear Parameter Estimation by Global Opitmization - Efficiency
and reliability // Acta Cybernetica, 1988. 8 (4). P. 361-372.
6.
Arora N., Bieglera L.T. Trust Region SQP Algorithm for Equality Constrained Pa-
rameter Estimation with Simple Parameter Bounds // Comput. Optim. Appl. 2004.
No. 28. P. 51-86.
7.
Floudas C.A., Pardalos P.M., Adjimann C.S., Esposito W.R., Gumus Z.H., Hard-
ing S.T., Schweiger C.A. Handbook of test problems in local and global optimization,
8.
Tjoa I.B., Biegler L.T. Simultaneous Solution and Optimization Strategies for Pa-
rameter Estimation of Differential-algebraic Equation Systems // Industrial & En-
gineering Chemistry Research. 1991. V. 30. No. 2. P. 376-385.
9.
Bock H.G. Recent Advances in Parameter Identification Techniques in ODE / Deu-
flhard P., Hairer E. (eds.). Numerical treatment of inverse problems in differential
and integral equations. P. 95-121. Birkhauser, 1983.
10.
Panteleev A.V., Letova T.A., Pomazueva E.A. Parametric Design of Optimal in Av-
erage Fractional-Order PID Controller in Flight Control Problem // Autom. Remote
Control. 2018. V. 79. № 1. P. 153-166.
Пантелеев А.В., Летова Т.А., Помазуева Е.А. Параметрический синтез опти-
мального в среднем дробного ПИД-регулятора в задаче управления полетом //
Управление большими системами. 2015. Вып. 56. С. 176-200.
11.
Esposito W.R., Floudas C.A. Global Optimization for the Parameter Estimation of
Differential-Algebraic Systems // Ind. Eng. Chem. Res. 2000. V. 39. P. 1291-1310.
12.
Osborne M.R. On Estimation Algorithms for Ordinary Differential Equations //
ANZIAM J. 2008. No. 50. P. 107-120.
13.
Adjiman C.S., Androulakis I.P., Floudas C.A., Neumaier A.A. Global Optimization
Method for General Twice-Differentiable NLPs, II. Implementation and Computa-
tional Results // Comput. Chem. Eng. 1998. No. 22 (9). P. 1159.
14.
Cizniar M., Podmajersky M., Hirmajer T., Fikar M. Global Optimization for Pa-
rameter Estimation of Differential-algebraic Systems // CHEM PAP. 2009. V. 63 (3).
P. 274-283.
15.
Floudas C.A., Pardalos P.M. (eds.) Encyclopedia of optimization. Springer, 2009.
16.
Glover F.W., Kochenberger G.A. Handbook of methaheuristics. Boston, MA: Kluwer
Acad. Publishers, 2003.
17.
Пантелеев А.В., Крючков А.Ю. Метаэвристические методы оптимизации в за-
дачах оценки параметров динамических систем // Науч. вестн. Моск. гос. тех-
нического ун-та гражданской авиации. 2017. T. 20. № 2. С. 37-45.
18.
Ruder S. An Overview of Gradient Descent Optimization Algorithms.
arXiv:1609.04747v2 [cs.LG] 15 Jun 2017.
19.
Karpathy Andrej (2017). A Peek at Trends in Machine Learning.
ab8a1085a106
20.
Sra Suvrit, Nowozin Sebastian, Wright Stephen J. Optimization for machine learning.
MIT Press, 2012.
134
21. Пантелеев А.В., Лобанов А.В. Градиентные методы оптимизации в машинном
обучении идентификации параметров динамических систем // Моделирование
и анализ данных. 2019. № 4. С. 88-99.
22. Пантелеев А.В. Методы оптимизации. Уч. пос. / А.В. Пантелеев, Т.А. Летова.
М.: Логос, 2011.
23. Синицын И.Н., Синицын В.И. Условно-оптимальное линейное оценивание нор-
мальных процессов в вольтерровских стохастических системах // Системы и
средства информатики. 2019. Т. 29. № 3. С. 16-28.
24. Синицын И.Н., Синицын В.И. Аналитическое моделирование процессов в воль-
терровских стохастических системах методом канонических разложений // Си-
стемы и средства информатики. 2019. Т. 29. № 1. С. 109-127.
Статья представлена к публикации членом редколлегии А.И. Кибзуном.
Поступила в редакцию 02.03.2020
После доработки 21.05.2020
Принята к публикации 09.07.2020
135