Автоматика и телемеханика, № 12, 2020
Интеллектуальные системы управления,
анализ данных
© 2020 г. А.В. ГЛАЗКОВА, канд. техн. наук (a.v.glazkova@utmn.ru)
(Тюменский государственный университет)
ТЕМАТИЧЕСКАЯ КЛАССИФИКАЦИЯ ТЕКСТОВЫХ ФРАГМЕНТОВ
С УЧЕТОМ ИХ БЛИЖАЙШЕГО КОНТЕКСТА1
Описывается подход к проведению тематической классификации от-
рывков биографического текста, учитывающий ближайший контекст
классифицируемых фрагментов, с помощью нейронной сети с несколь-
кими входами. Выбор архитектуры модели обоснован предположением
о том, что, поскольку тексты, написанные на естественном языке, от-
личаются логичностью и связностью, контекст отрывка может быть ис-
пользован в качестве дополнительных входных данных. Модель обуче-
на и протестирована на корпусе биографических текстов, составленном
автором работы. Результаты, полученные с использованием предложен-
ного подхода, превзошли результаты моделей, не учитывающих контекст
отрывка.
Ключевые слова: классификация предложений, интеллектуальный ана-
лиз данных, рекуррентные нейронные сети, обработка естественного язы-
ка, биографический текст, контекст, корпус текстов, биографическое ис-
следование, Word2Vec, BERT.
DOI: 10.31857/S0005231020120090
1. Введение
Интерпретация неструктурированной информации, представленной в ви-
де текста на естественном языке, является одной из ключевых задач ин-
теллектуального анализа данных и информационного поиска. Частной зада-
чей информационного поиска является поиск биографической информации,
актуальной при проведении биографических исследований, сборе историко-
генеалогических данных и биографических фактов из жизни индивидуума.
Спецификой данной задачи является, во-первых, жанровое многообразие ис-
точников биографической информации (автобиографии, заметки, очерки и
т.д.), и, во-вторых, многоплановость биографической информации, включаю-
щей в себя разнообразные аспекты жизни человека: политический, личный,
общественный, культурный.
1 Работа выполнена при финансовой поддержке Российского фонда фундаментальных
исследований (проект № 18-37-00272).
153
Развитие методов поиска биографической информации осуществляется в
основном в двух направлениях [1]:
1) предметный или ¾косвенный¿ поиск, когда пользователь поисковой си-
стемы формулирует запросы, основываясь на известных ему биографических
фактах о некоторой персоне и пытаясь на их основе найти недостающую ин-
формацию;
2) свободный поиск, при котором пользователь не имеет начальных сведе-
ний об интересующей его персоне. Свободный поиск подразумевает просмотр
биографических текстов, посвященных персоне, в целях обнаружения кон-
кретной биографической информации, релевантной требованиям пользовате-
ля (например, информации о профессиональной деятельности или о личной
жизни).
Во втором случае пользователь вынужден просматривать большие объемы
текстов. Сократить затраты временных ресурсов при свободном поиске био-
графической информации мог бы помочь инструмент автоматической обра-
ботки биографических текстов, извлекающий из них фрагменты, связанные с
тем или иным типом биографической информации. Такой инструмент может
быть реализован на основе методов автоматической классификации текстов.
В этом случае текст, предварительно разделенный на фрагменты, подается
на вход классификатора, определяющего тематику каждого фрагмента.
Различные тексты в зависимости от жанра могут иметь стандартизи-
рованную структуру (к таким текстам относятся, например, документы
официально-делового стиля) или обладать структурированностью, заложен-
ной не в расположении структурных частей, а в логическом единстве [2].
Биографические тексты могут послужить примером второго типа текстов
за счет того, что информация в них, как правило, изложена в хронологи-
ческом порядке, и знание тематики отрывка такого текста позволяет пред-
положить, какой фрагмент ему предшествует и какой располагается после.
Эта особенность позволяет предположить, что принятие во внимание логи-
ки изложения биографических текстов и учет ближайшего контекста фраг-
ментов даст возможность улучшить качество тематической классификации
отрывков.
В данной работе предлагается подход к тематической классификации
фрагментов биографического текста на основе их ближайшего контекста.
В качестве фрагмента рассматривается предложение, так как данная языко-
вая единица представляет собой грамматически организованное соединение
слов (или слово), обладающее смысловой законченностью [3]. В статье при-
водится сравнение нескольких моделей машинного обучения для классифи-
кации фрагментов биографических текстов с учетом ближайшего контекста
и без него. Эксперименты проводятся на корпусе биографических текстов,
собранном автором работы.
2. Работы по близкой тематике
Тематика работы в основном затрагивает две задачи обработки естествен-
ного языка:
154
1) извлечение биографической информации (биографических фактов);
2) тематическая классификация предложений.
Существующие работы, посвященные решению указанных задач, пресле-
дуют различные практические цели и используют разные подходы. Однако
в целом в литературе по данной тематике извлечение информации и класси-
фикацию текстов определяют как слабоформализуемые задачи, а применяе-
мые для их решения методы как зависящие от специфики обрабатываемых
текстов [4, 5]. Методы поиска и извлечения биографической информации раз-
виваются преимущественно в трех направлениях: детерминированные подхо-
ды, основанные на применении шаблонов и правил; подходы, основанные на
применении методов машинного обучения (в частности, нейронных сетей);
гибридные подходы. Детерминированные подходы показывают достаточно
высокую результативность во многих задачах, однако требуют разработки
большого количества признаков, отражающих структурные, семантические и
лексические особенности текстов. К преимуществам подходов, основанных на
машинном обучении, можно отнести автоматическую настройку параметров
моделей с помощью множества примеров, а также возможность не только со-
относить результаты обработки текстов с их отдельными характеристиками,
но и выявлять более сложные скрытые зависимости и закономерности [6].
Однако реализация подходов, использующих методы машинного обучения,
требует построения обучающих выборок текстов, сопровождающихся каче-
ственной разметкой, что также бывает сложно осуществимо в реальных усло-
виях. Одним из трендов обработки естественного языка являются предобу-
ченные модели на основе глубоких нейронных сетей (transfer learning) [7, 8],
когда заранее обученная модель дообучается для решения специфических
задач [9].
К детерминированным подходам к извлечению биографической инфор-
мации можно отнести работу [1], в которой описана технология, представ-
ляющая биографический факт в виде древовидной структуры, корнем ко-
торой является тип факта (например, “рождение”), а листьями - связанные
с фактом сущности. В [10] предлагается подход к извлечению биографиче-
ских событий на основе трафика Википедии. В [11] описывается набор правил
для извлечения биографической информации для текстов на русском языке.
В [12] проводится сравнение нескольких подходов, основанных на правилах, а
также предлагается таксономия биографических фактов, включающая в се-
бя семь типов отношений. Существует достаточно много работ, авторы кото-
рых применяли различные методы машинного обучения для классификации
фрагментов биографических текстов или извлечения биографических фак-
тов. Так, в [13] используется наивный байесовский классификатор, в [14] -
метод опорных векторов и деревья решений, в [15, 16] нейронные сети.
В [17] проводилось сравнение подходов, основанных на правилах, с методом
опорных векторов на примере бинарной классификации фраз, содержащих и
не содержащих биографическую информацию, в результате которого метод
опорных векторов продемонстрировал значительно более высокое качество.
В [18] сравнивались различные типы машинного обучения для извлечения
отношений в биографических текстах (по сути извлечения фактов) на при-
155
мере португальского языка. Среди гибридных подходов могут быть назва-
ны [19, 20].
Во многих работах, связанных с поиском биографической информации,
эксперименты проводились на текстах Википедии (в частности, [21-26]). Это
связано с тем, что Википедия содержит в себе богатый и разнообразный ма-
териал для исследований, представленный тем не менее в стандартизованном
виде.
Особенностями задачи классификации предложений являются, во-первых,
сравнительно небольшая длина классифицируемых текстов и, во-вторых, на-
личие контекста у предложений, который также может приниматься во вни-
мание алгоритмами классификации. Будет ли во время классификации учи-
тываться контекст, зависит от специфики решаемой задачи и данных, имею-
щихся для проведения исследования. Многие существующие системы для
классификации коротких текстов используют алгоритмы, построенные на ис-
пользовании вероятностных и статистических методов: байесовского класси-
фикатора [27], условных случайных полей [28], скрытых марковских моде-
лей [29], логистической регрессии [30]. Для решения задач классификации
текстов широко применяются рекуррентные нейронные сети, обученные с
помощью векторных представлений символов и слов. В частности, подходы
к обработке естественного языка, основанные на применении рекуррентных
нейронных сетей, представлены в [31-35]. В последние годы высокие резуль-
таты в классификации коротких текстов демонстрируют инструменты, ис-
пользующие модели ELMo и BERT (в частности, [36-38]).
Среди исследований, связанных с использованием контекста, можно на-
звать работу [39], где была предложена архитектура нейронной сети для клас-
сификации реплик в диалоге. Описанная в указанной работе модель имела
несколько входов, один из которых принимал текущую реплику, а другие -
ее контекст, т.е. предшествующие фразы. Модель, построенная таким обра-
зом, продемонстрировала более высокое качество классификации в сравне-
нии с обычной рекуррентной нейронной сетью на англоязычных диалоговых
текстовых корпусах. В [40, 41] тем же коллективом автором были предложе-
ны нейросетевая модель для разбиения фрагментов аннотаций медицинских
статей по пяти имеющимся классам: введение, обзор существующих работ,
методология, результаты и выводы. В [42] описывается подход к классифи-
кации предложений по тональности с использованием ряда дискурсивных
признаков.
3. Методы
В данной работе предлагается нейросетевая архитектура для классифи-
кации фрагментов биографических текстов, основанная на архитектуре для
классификации реплик в диалоге, описанной в [39]. Предлагаемая модель
включает в себя несколько входов, раздельно обрабатывающих текущий тек-
стовый фрагмент, а также предыдущие и последующие фрагменты. Векторы,
являющиеся результатами обработки фрагментов во входных блоках, объеди-
няются в общий слой нейронной сети. Для оценки качества классификации
используется корпус биографических текстов, собранный и размеченный ав-
156
тором работы в полуавтоматическом режиме [43]. В работе рассматриваются
два варианта нейросетевой архитектуры, использующие разные типы пред-
ставления предложений:
1) рекуррентная нейронная сеть. Текст представляется в виде последо-
вательностей слов. В качестве матрицы векторных представлений слов (для
слоя Embedding) используются предобученные вектора модели Word2Vec [44];
2) сеть прямого распространения, обученная на векторных представлениях
предложений, полученных с помощью модели BERT [7].
3.1. Архитектура
Рекуррентная модель основана на использовании рекуррентных слоев дол-
гой краткосрочной памяти (long short-term memory, LSTM), в которых в отли-
чие от классических рекуррентных архитектур предусмотрен механизм хра-
нения долгосрочных зависимостей, позволяющий избежать проблемы затуха-
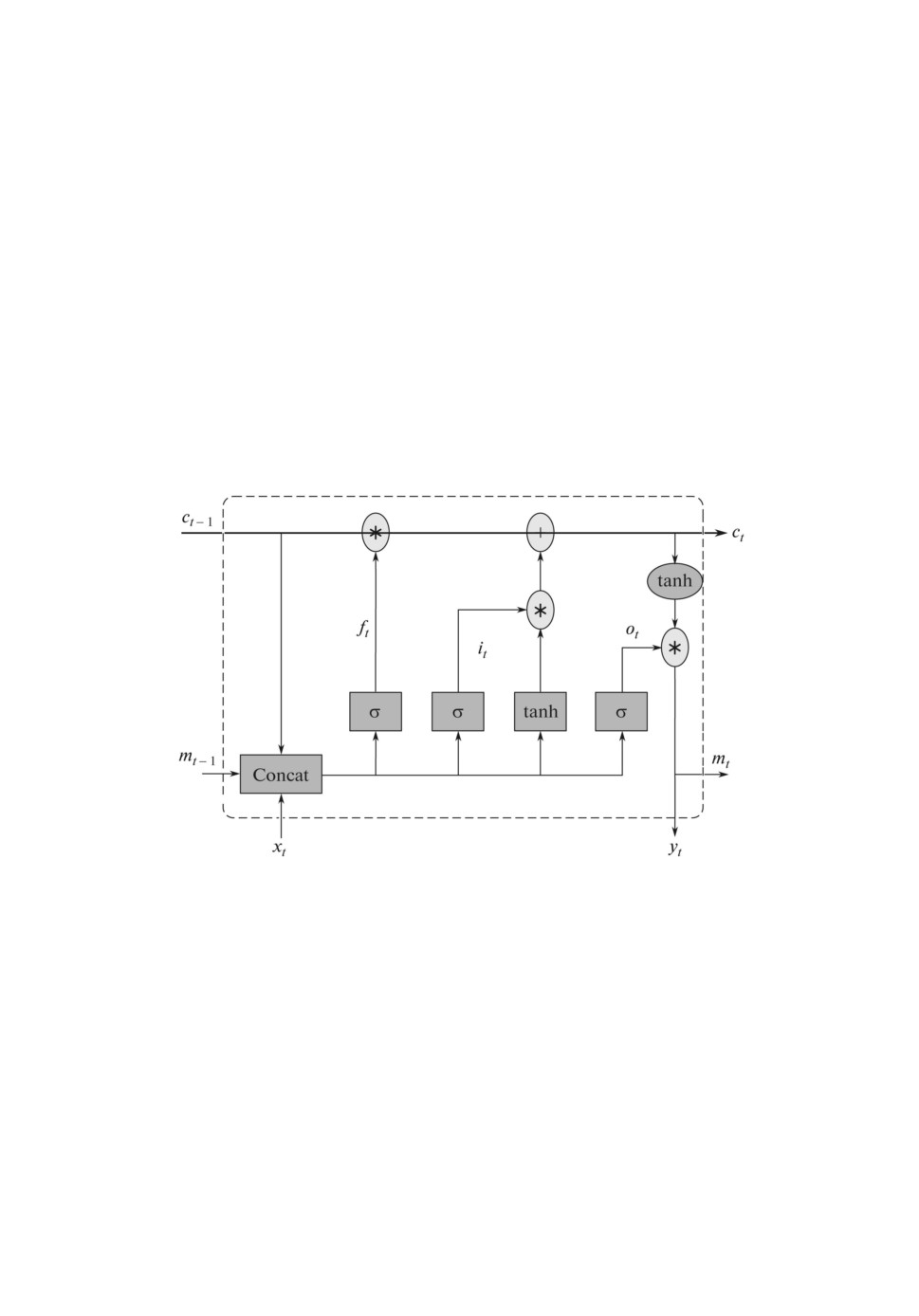
ния градиента [45]. Структура ячейки LSTM-сети представлена на рис. 1 [46].
Рис. 1. Структура ячейки LSTM.
Пусть xt и yt - входной и выходной сигналы соответственно в момент
времени t, а ct и mt - состояние ячейки и выхода в момент t. Преобразование
входного сигнала в выходной при этом происходит следующим образом:
(
)
it = σ
Wixxt + Wimmt-1 + Wicci-1 + bi
,
(
)
ft = σ
Wfxxt + Wfmmt-1 + Wfcci-1 + bf
,
(
)
ot = σ
Woxxt + Wommt-1 + Wocci-1 + bo
,
(1)
mt = ot ⊙ h(ct),
(
)
yt = ϕ
Wymmt + by
,
(
)
ct = ft ⊙ ct-1 + it ⊙ g
Wcxxt + Wcmmt-1 + bc
,
157
где Wcx, Wix, Wfx, Wox - веса входов, Wcm, Wim, Wfm, Wom - веса состояний
ячеек, bo, bi, bf - смещения, Wic, Wfc, Woc - веса связей между ячейками и
слоем выходного фильтра, Wym и by - вес и смещение для выхода, σ, g, h
представляют собой некоторые нелинейные функции.
В сети прямого распространения рекуррентные слои заменены слоями пря-
мого распространения, т.е. слоями без рекуррентных связей, с функцией ак-
тивации “гиперболический тангенс”.
Входными данными моделей являются текущее предложение и его кон-
текст, т.е. n предшествующих и n последующих предложений. Пусть sj -
предложение с порядковым номером j. Тогда входом служит множество пред-
ложений S:
{
}
(2)
S =
sj-n,... ,sj-1,sj,sj+1,... ,sj+n
,
j ∈ [n + 1,J - n],
J - количество предложений в тексте.
В том случае, когда j < n + 1 или j > J - n , предложение контекста sk,
k ∈ {j - n,...,j - 1,j + 1,...,j + n} подается на вход сети, если 1 ≤ k ≤ J.
В противном случае в качестве входных данных для соответствующей пози-
ции подаются метки начала (для k < 1) или конца текста (k > J).
Каждому предложению из множества S соответствует отдельный вход се-
ти. Таким образом, входными данными сети являются 2n + 1 предложений,
а выходными данными входных блоков являются векторы, соответствующие
входным предложениям.
3.2. Варианты учета контекста
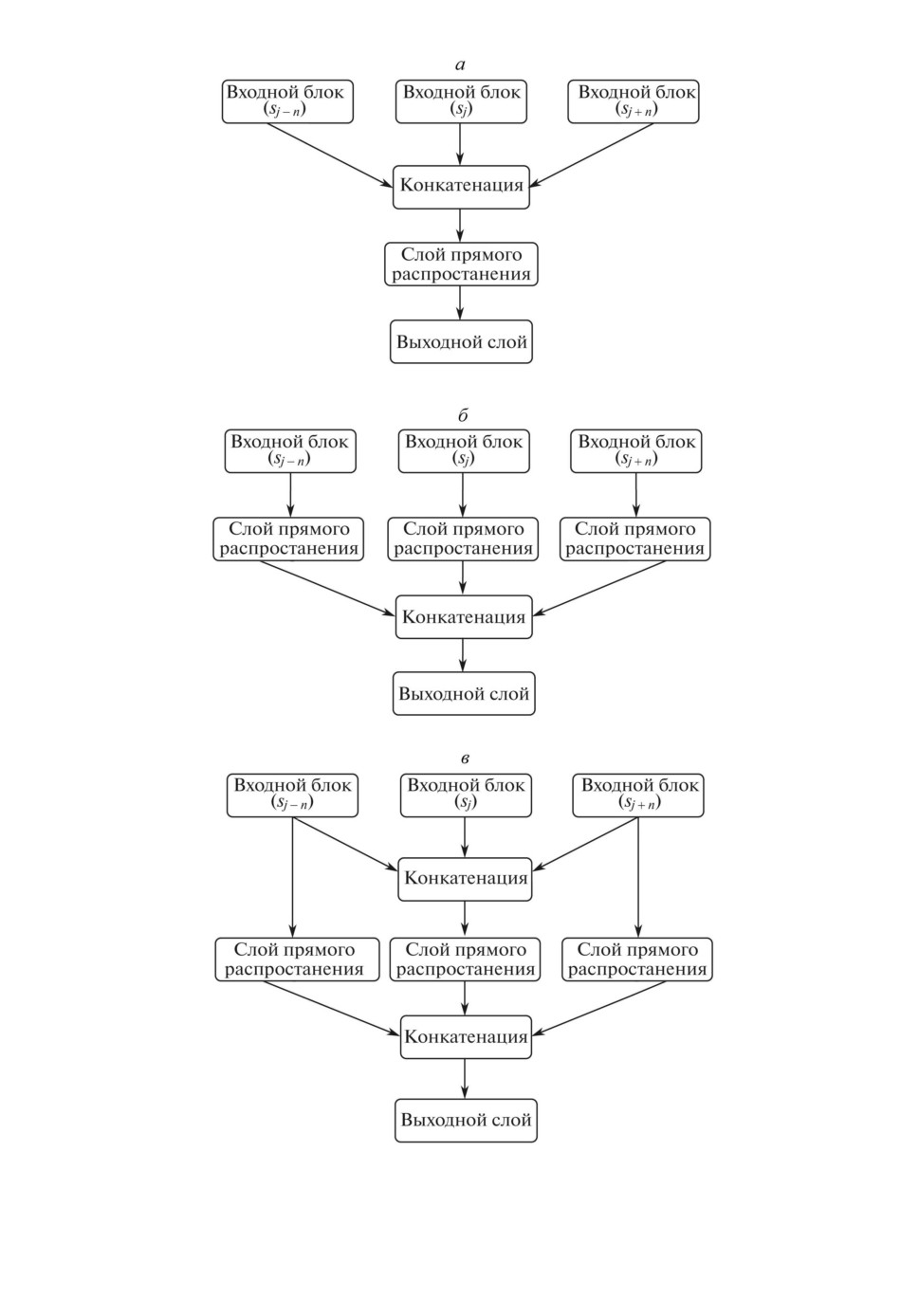
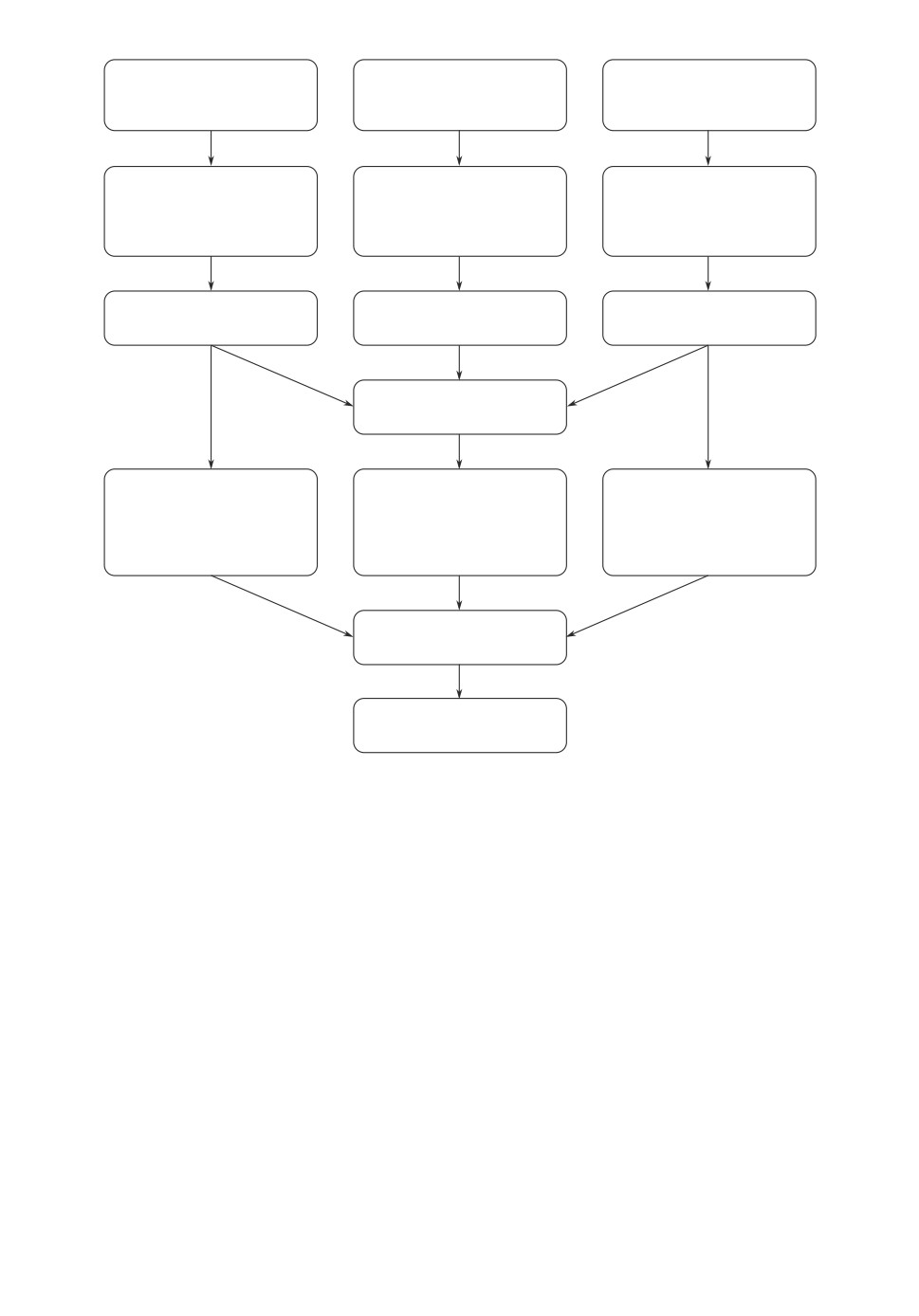
Далее рассматривались три варианта архитектуры каждой модели:
1) в первом случае результат конкатенации выходных векторов входных
блоков подается на слой прямого распространения. Результирующие величи-
ны поступают в выходной слой модели, также представляющий собой слой
прямого распространения, имеющий размерность, равную количеству клас-
сов, и функцию активации softmax. Выходной слой сети возвращает рас-
пределение вероятностей между тематическими классами для предложения
(рис. 2,а);
2) во втором варианте к каждому входному блоку добавляется по одно-
му слою прямого распространения, после чего осуществляется конкатенация,
результат которой подается на выходной слой. Таким образом, учет влияния
контекста происходит на уровне последнего слоя модели (рис. 2,б );
3) третий вариант представляет собой комбинацию первых двух. Выполня-
ется конкатенация выходных векторов входных блоков и обработка резуль-
тата слоем прямого распространения. Одновременно с этим выходные век-
торы входных блоков, соответствующих предложениям контекста, подаются
на вход слоев прямого распространения. Осуществляется конкатенация всех
результирующих векторов, результат подается на выходной слой. Так, влия-
ние контекста учитывается как на уровне выходных векторов рекуррентных
блоков, так и на уровне последнего слоя модели (рис. 2,в).
158
Рис. 2. Варианты архитектуры модели.
159
4. Эксперименты
4.1. Данные
Для обучения и тестирования моделей был составлен корпус биографиче-
ских текстов. Он представляет собой коллекцию, содержащую биографиче-
ские тексты из онлайн-энциклопедии Википедия, разбитые на предложения
и снабженные тематической разметкой. В версии корпуса, использованной
для экспериментов, содержатся 200 текстов, описывающих биографии людей,
живших или живущих в XX-XXI вв. Корпус находится в свободном доступе
на сайте [47].
Каждому предложению в корпусе биографических текстов сопоставлена
метка класса, наиболее полно соответствующего его тематике: рождение, ин-
формация о родительской семье, место жительства, род занятий, место рабо-
ты, семья, образование, личные события, профессиональные события, смерть.
Некоторым предложениям в корпусе соответствуют два класса - основной и
дополнительный. В данной работе при классификации таких предложений
использовалась метка основного класса. Таким образом, каждый фрагмент
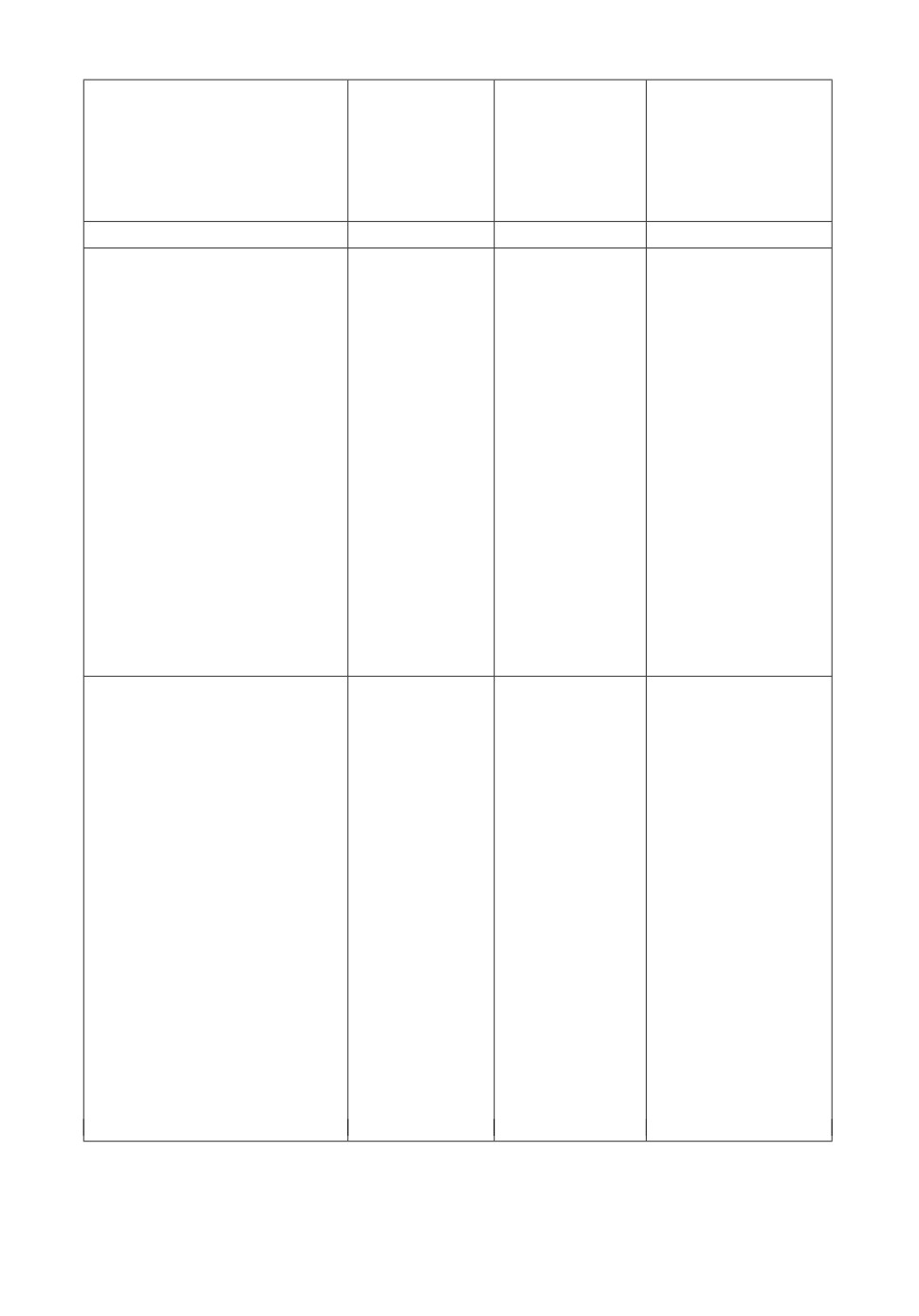
соответствует одному из 10 классов. Характеристики корпуса представлены
в табл. 1.
Для выравнивания количества примеров в классах был проведен простой
оверсэмплинг, т.е. дублирование случайных элементов миноритарных клас-
сов. Общее количество элементов для обучения и валидации моделей после
проведения оверсэмплинга - 8251, объем тестовой выборки, на которой оце-
нивалось финальное качество моделей, - 177 предложений. Предварительная
обработка данных включала в себя приведение текста к нижнему регистру,
удаление специальных символов, стоп-слов и знаков препинания, а также
приведение слов к начальной форме.
Таблица 1. Характеристики корпуса
Средний
Средняя
размер
длина
Количество
Класс
контекста
предложения
примеров
для n = 1
(в токенах)
(в токенах)
Рождение
13,9
13,25
134
Информация о родительской семье
13,05
28,9
86
Место жительства
13,17
31,23
94
Род занятий
16,93
32,4
943
Место работы
14,4
32,27
113
Семья
11,83
24,25
48
Образование
15,73
30,04
374
Личные события
20,35
38,07
105
Профессиональные события
21,36
37,72
490
Смерть
10,56
22,15
111
Все предложения
16,83
31,52
2498
160
В случае отсутствия необходимого числа соседних предложений в тексте
на вход моделей подавались специальные метки “begin” и “end” - для предше-
ствующих (sj-1, sj-2, . . . , sj-n) и последующих (sj+1, sj+2, . . . , sj+n) предло-
жений соответственно. Так, в случае j = 1 (порядковый номер предложения в
тексте), J = 3 (количество предложений в тексте) и n = 3 (размер контекста)
входные данные будут иметь следующий вид:
sj-3 = “begin”,
sj-2 = “begin”,
sj-1 = “begin”,
sj = “Текст предложения sj”,
sj+1 = “Текст предложения sj+1”,
sj+2 = “Текст предложения sj+2”,
sj+3 = “end”.
4.2. Реализация и обучение моделей
В ходе экспериментов было проведено сравнение моделей, учитывающих
контекст, с нейронными сетями, основанными на transformer-архитектуре,
а также с методом опорных векторов, испытанным на представлениях пред-
ложений в виде Bag-of-Words TF-IDF. В данной работе использовались две
модели BERT:
1) mBERT (multilingual BERT), поддерживающая 104 языка [7];
2) RuBERT, модель BERT для русского языка, обученная на русскоязыч-
ной Википедии и текстах новостных порталов [48]. Для русскоязычных
текстов данная модель на ряде задач показала качество, значительно
превосходящее качество многоязычной модели BERT.
Таблица 2. Оптимизация параметров моделей
Множество
Выбранное
Параметр
параметров
значение
Функция активации на внутренних слоях гиперболический гиперболический
(рекуррентная сеть)
тангенс, relu
тангенс
Функция активации на внутренних слоях гиперболический гиперболический
(сеть прямого распространения)
тангенс, relu
тангенс
Размерность слоя LSTM (рекуррентная степени 2 из диа-
64
сеть)
пазона [32;256]
Размерность слоя прямого распростране-
степени 2 из диа-
256
ния во входном блоке (сеть прямого распро-
пазона [64;512]
странения)
Размерность общего слоя прямого распро- степени 2 из диа-
32
странения (рекуррентная сеть)
пазона [32;128]
Размерность общего слоя прямого распро- степени 2 из диа-
32
странения (сеть прямого распространения) пазона [32;128]
161
Рис. 3. Модели без учета контекста: а рекуррентная сеть; б сеть прямого
распространения.
Реализация моделей, основанных на transformer-архитектуре, выполнена с
помощью библиотек Transformers [49] и PyTorch [50] и языка программирова-
ния Python 3.6. В качестве элемента входных данных для модели BERT вы-
ступает предложение, заключенное в токены [CLS] и [SEP]. Предложение об-
рабатывается токенизатором, преобразующим токены в последовательности
индексов в соответствии со словарем модели. Размерность элемента входной
последовательности для BERT ограничена 512 токенами, размер батча - 8,
количество эпох обучения - 3.
Метод опорных векторов реализован с помощью библиотеки Scikit-Learn
(LinearSVC) [51]. В качестве входных данных использованы представления
предложений по модели Bag-of-Words TF-IDF (матрица Bag-of-Words, где на
пересечении строки и столбца располагается значение меры TF-IDF для дан-
ного слова в заданном документе). Размерность векторных представлений -
5000 признаков.
Реализация моделей, использующих контекст, выполнена с помощью
средств библиотеки Keras [52] и языка программирования Python 3.6. Вход-
ные блоки рекуррентных сетей состоят из входного слоя, слоя матрицы весо-
вых коэффициентов (embedding layer) и рекуррентного слоя LSTM. Размер-
ность слоя LSTM составляет 64 нейрона, слоев прямого распространения -
162
Входной слой
Входной слой
(предыдущее
Входной слой
(следующее
предложение)
предложение)
Слой векторных
Слой векторных
Слой векторных
представлений слов
представлений слов
представлений слов
(embedding layer)
(embedding layer)
(embedding layer)
LSTM (64)
LSTM (64)
LSTM (64)
Конкатенация
Полносвязный слой
прямого
распространения
(32)
Выходной слой
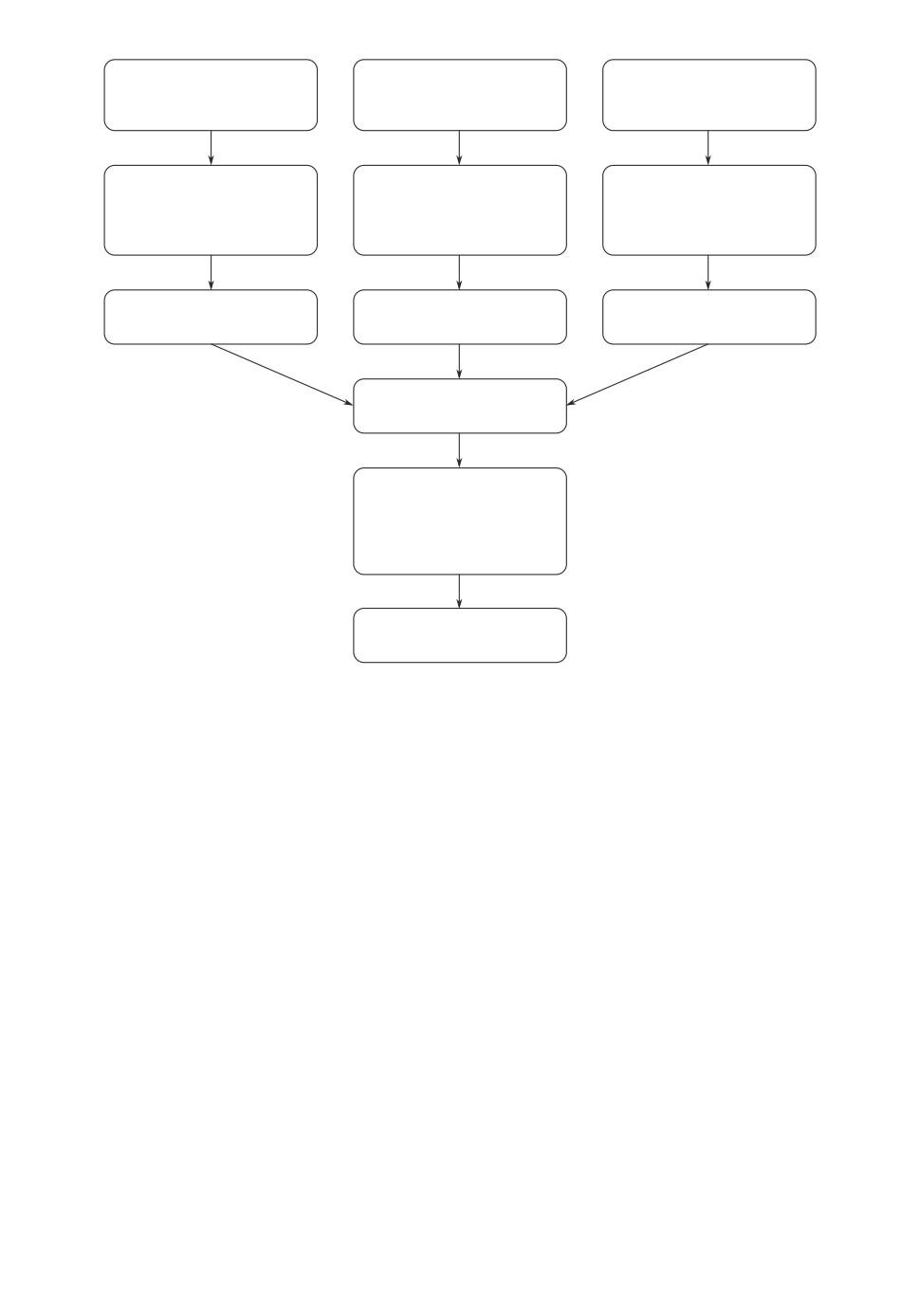
Рис. 4,a. Визуализация рекуррентных моделей при n = 1.
32 нейрона. Входные блоки сетей прямого распространения включают в себя
входной слой и один слой прямого распространения. Размерность слоев пря-
мого распространения во входных блоках составляет 256 нейронов, в общем
слое - 32 нейрона. Функция активации для внутренних слоев - гиперболиче-
ский тангенс, для выходного слоя - softmax. Оптимизация гиперпараметров
моделей проводилась на примере моделей без учета контекста с помощью про-
стого поиска по решетке (grid search). Список оптимизируемых параметров и
их диапазонов приводится в табл. 2. В качестве оптимизационного алгоритма
для всех моделей использован adaptive moment estimation (adam optimizer),
в качестве функции ошибки - категориальная кросс-энтропия.
На рис. 3 изображены схемы рекуррентной модели и сети прямого рас-
пространения без учета контекста. Наклонным шрифтом выделены входные
блоки. В моделях с учетом контекста (когда n > 0) каждому входному пред-
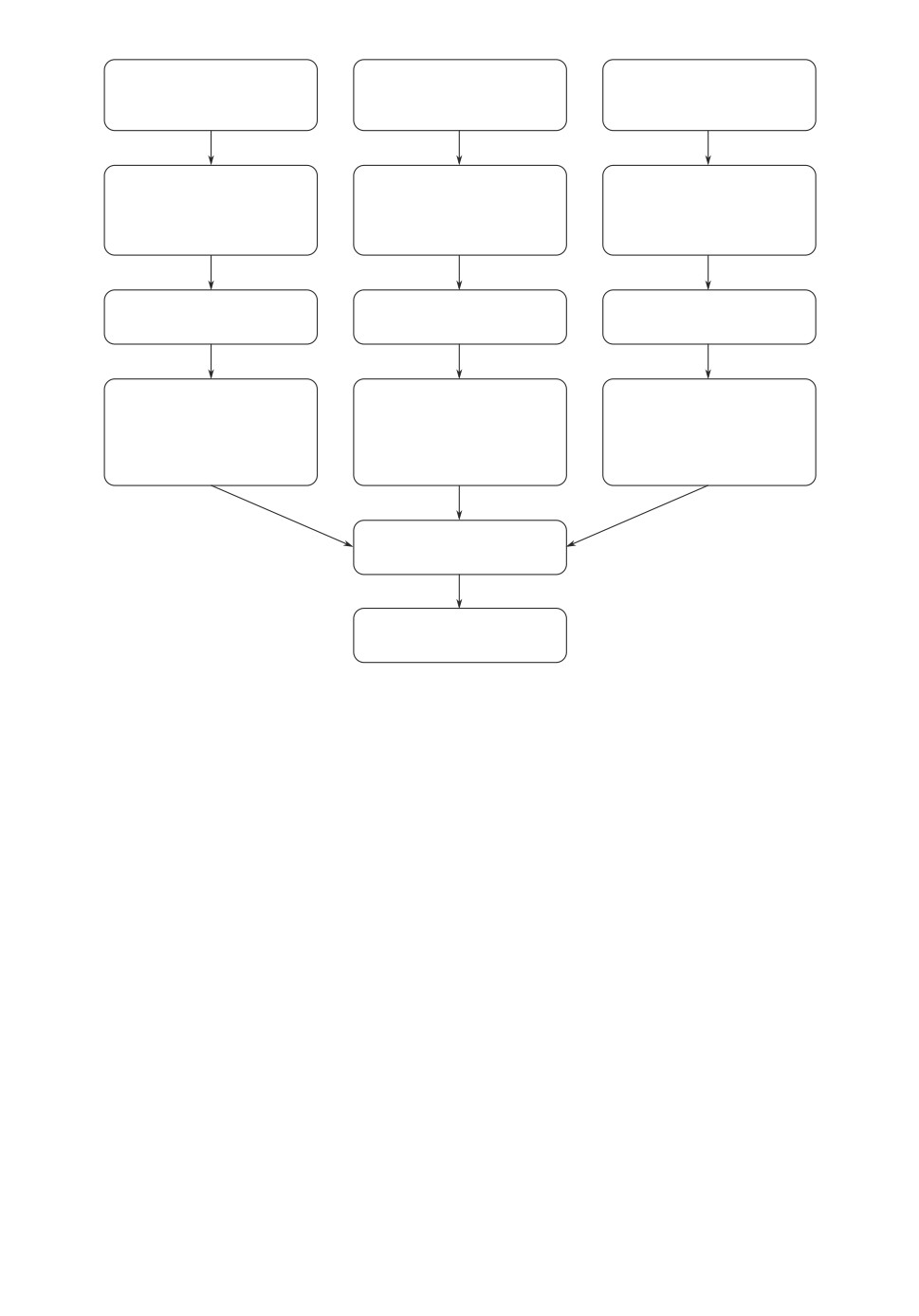
ложению из множества S соответствует отдельный входной блок. На рис. 4 в
качестве примера представлена визуализация трех вариантов рекуррентной
модели для n = 1. Модели для n > 1 имеют аналогичный вид при большем
количестве входов.
Данные для обучения нейросетевых моделей были разделены на обучаю-
щую и валидационную выборки. Обучение проводилось с использованием
163
Входной слой
Входной слой
(предыдущее
Входной слой
(следующее
предложение)
предложение)
Слой векторных
Слой векторных
Слой векторных
представлений слов
представлений слов
представлений слов
(embedding layer)
(embedding layer)
(embedding layer)
LSTM (64)
LSTM (64)
LSTM (64)
Полносвязный слой
Полносвязный слой
Полносвязный слой
прямого
прямого
прямого
распространения
распространения
распространения
(32)
(32)
(32)
Конкатенация
Выходной слой
Рис. 4,б . Визуализация рекуррентных моделей при n = 1.
обучающей выборки, остановка обучения выполнялась согласно показате-
лям модели на валидационной выборке. Финальное тестирование модели
осуществлялось на независимой тестовой выборке, не участвовавшей в про-
цессе обучения. Для рекуррентных сетей входные данные подавались в мо-
дели в виде последовательностей слов (sequences) на основе матрицы век-
торных представлений слов, составленной из векторов модели Word2Vec и
множества лексем, представленных в обучающей выборке. В качестве моде-
ли Word2Vec использовалась модель, обученная на текстах русскоязычной
Википедии и Национального корпуса русского языка за 2018 г. с исполь-
зованием алгоритма обучения Skip-gram [53]. Размерность векторного пред-
ставления слова в модели равна 300. Входные данные сетей прямого распро-
странения выглядят как одномерный вектор размерностью 768, полученный
для текущего фрагмента текста из модели RuBERT c помощью библиотеки
DeepPavlov [54].
Исходный код всех моделей доступен по ссылке [55].
4.3. Результаты
Для оценки результатов использовалась F-мера (macro-averaging), кото-
рая определялась как средняя величина значений F-меры, рассчитанных для
164
Входной слой
Входной слой
(предыдущее
Входной слой
(следующее
предложение)
предложение)
Слой векторных
Слой векторных
Слой векторных
представлений слов
представлений слов
представлений слов
(embedding layer)
(embedding layer)
(embedding layer)
LSTM (64)
LSTM (64)
LSTM (64)
Конкатенация
Полносвязный слой
Полносвязный слой
Полносвязный слой
прямого
прямого
прямого
распространения
распространения
распространения
(32)
(32)
(32)
Конкатенация
Выходной слой
Рис. 4,в. Визуализация рекуррентных моделей при n = 1.
каждого класса по показателям точности (precision) и полноты (recall). Значе-
ния точности и полноты приведены в скобках после значения F-меры (первый
показатель - precision, второй - recall).
В табл. 3 представлены показатели качества классификации. Поскольку
ввиду случайной инициализации начальных параметров результаты класси-
фикации могут варьироваться при разных запусках моделей, каждая ней-
росетевая модель была запущена m раз, в таблице указаны средние значе-
ния. В данной работе m = 5. В экспериментах рассматривались значения для
моделей, учитывающих контекст фрагмента в диапазоне 0 ≤ n ≤ 3, так как
дальнейшее увеличение величины n не давало роста качества классификации
и отрицательно сказывалось на временной сложности модели.
Полужирным шрифтом в таблице выделены наиболее высокие значе-
ния F-меры среди всех рассмотренных моделей (рекуррентная - вариант
1, 94,77%) и среди моделей, не учитывающих контекст (RuBERT, 93,16%).
Как показывают данные таблицы, в большинстве случаев добавление пред-
165
Таблица 3. Качество моделей (F-мера (Precision / Recall), значения указаны в %)
Значение n
Архитектура
0
1
2
3
Рекуррентная
-
91,25
93,13
94,77
(вариант 1)
(90,31 / 92,15)
(91,23 / 94,13)
(91,33 / 95,77)
Рекуррентная
-
92,54
93
92,9
(вариант 2)
(91,45 / 92,56)
(91,98 / 94,03)
(91,56 / 92,35)
Рекуррентная
-
92,07
92,3
94,07
(вариант 3)
(92,01 / 91,87)
(92,12 / 91,96)
(91,4 / 95,88)
Прямого распростра-
-
86,23
87,14
87,45
нения (вариант 1)
(85,89 / 88,42)
(84,78 / 89,2)
(85,91 / 88,45)
Прямого распростра-
-
87,18
87,03
87,5
нения (вариант 2)
(86,56 / 89,12)
(86,22 / 88,14)
(87,02 / 88,49)
Прямого распростра-
-
87,35
87,56
87,14
нения (вариант 3)
(87,53 / 89,36)
(87,34 / 89,01)
(87,02 / 88,32)
Рекуррентная (без
89,46
-
-
-
учета контекста)
(90,13 / 88,3)
Прямого распростра-
86,83
-
-
-
нения (без учета кон-
(89,3 / 88,26)
текста)
LinearSVC
66,37
(64,39 / 77,44)
mBERT
89,01
-
-
-
(92,11 / 88,12)
RuBERT
93,16
-
-
-
(90,72 / 97,05)
ложений контекста позволило улучшить качество классификации фрагмен-
тов. Причем для рекуррентных моделей наилучший результат был достиг-
нут при n = 3, а для сетей прямого распространения - при n = 2. Наиболь-
шие абсолютные показатели улучшения заметны для рекуррентных моделей
(+5,31%).
В табл. 4 приводятся примеры предложений, ошибочно классифицирован-
ных рекуррентной моделью с использованием контекста и моделью RuBERT.
В большинстве случаев ошибки связаны с фрагментами, тематически свя-
занными более чем с одним классом. Многие из этих фрагментов име-
ли в оригинальном корпусе метку дополнительного класса. Так, предло-
жению из первого примера (фрагмент биографии художника Б.В. Эндера)
разметчики корпуса сопоставили класс “Информация о родительской се-
мье” в качестве основного и класс “Рождение” в качестве дополнительно-
го. Выбор метки основного класса связан с тем, что предложение описыва-
ет происхождение персоны, а не конкретизирует факт рождения (дата, ме-
сто). Обе сети отнесли данный отрывок к классу “Рождение”. Второе пред-
ложение является примером, характеризующим сильные стороны модели с
использованием контекста. Вероятно, фрагмент, описывающий профессио-
166
Таблица 4. Примеры ошибок моделей
Результат
классификации
Результат
(рекуррентная
Фрагмент
Разметка
классификации
модель с
(RuBERT)
использованием
контекста)
1
2
3
4
sj-3: “begin”
Информация о
Рождение
Рождение
sj-2: “begin”
родительской
sj-1: “begin”
семье
sj: “Родился в семье агроно-
ма, происходящего из рода
обрусевших немцев.”
sj+1: “Две его младшие сест-
ры - Ксения (1894-1955) и
Мария (1897-1942) - также
стали художницами.”
sj+2:
“В
1905-1907 брал
частные уроки рисования у
И.Я. Билибина.”
sj+3:
“В
1911
г. сблизил-
ся с М.В. Матюшиным и
Е.Г. Гуро, часто бывал в их
квартире в доме на Песоч-
ной улице.”
sj-3: “begin”
Род занятий
Семья
Род занятий
sj-2: “begin”
sj-1: “Училась в школе №1,
индустриальном техни-
куме.”
sj:
“1935
- аэроклуб, по-
сле гражданская авиация в
Грузии вместе с мужем.”
sj+1:
“1941
- инструктор
(200 курсантов).”
sj+2:
“Апрель
1944
- Са-
ранск, 3-е Военно-Морское
летное училище (летчики-
штурмовики).”
sj+3: “По окончании - на-
значение в 7 ГвПШАП ВВС
КБФ (командир полка два-
жды Герой Советского Сою-
за А.Е. Мазуренко).”
167
Таблица 4 (окончание)
1
2
3
4
sj-3: “В 1918 г., после демо-
Личные
Личные
Профессиональные
билизации, поступил в
события
события
события
Петроградские Государст-
венные свободные художест-
венные мастерские, зани-
мался у К.С. Петрова-Вод-
кина, затем у Матюшина.”
sj-2: “Завершив обучения в
1923 г., продолжил работать
под началом Матюшина в
Отделе органической куль-
туры Инхука, вошел в
созданную им группу ¾Зор-
вед¿.”
sj-1: “В 1920-е принимал ак-
тивное участие в выставках
¾мастерской пространствен-
ного реализма¿.”
sj: “Познакомился с
К.С. Малевичем, Н.М. Суе-
тиным, И.Н. Харджиевым,
И.Г. Эренбургом, поддер-
живал с ними постоянную
переписку.”
sj+1: “В 1927 г. переехал в
Москву.”
sj+2:
“В
1930-х гг. много
работал в области монумен-
тального искусства.”
sj+3:
“Принимал участие
в оформлении павильона
СССР на Международной
выставке в Париже (1937).”
нальную деятельность советской летчицы Л.И. Шулайкиной и упоминаю-
щий ее супруга, верно отнесен к классу “Род занятий” за счет тематики
контекста, в то время как модель RuBERT классифицировала этот фраг-
мент как элемент класса “Семья”. Противоположный пример представля-
ет собой третье предложение (фрагмент биографии Б.В. Эндера), которое
отнесено разметчиками корпуса к классу “Личные события”, так как опи-
сывает встречи и личные знакомства художника. Модель с учетом контек-
ста классифицировала данный фрагмент как “Профессиональные события”
(в корпусе данному классу соответствуют упоминания официальных встреч
и наград). Возможно, полученный результат обусловлен “профессиональной”
тематикой контекста.
168
5. Заключение
В работе представлен подход к выполнению тематической классификации
отрывков текста, учитывающий их ближайший контекст. Модель апробирова-
на на примере корпуса биографических текстов. Поскольку биографический
текст отличается хронологической последовательностью изложения, все мо-
дели, принимающие в качестве входных данных контекст отрывка, показали
лучшие результаты в сравнении с моделью без учета контекста.
Архитектура, предложенная в данной статье, может быть применена при
решении сходных задач тематической классификации отрывков текстов, об-
ладающих явной логической структурой и последовательностью изложения.
СПИСОК ЛИТЕРАТУРЫ
1.
Адамович И.М., Волков О.И. Система извлечения биографических фактов из
текстов исторической направленности // Системы и средства информатики.
2.
Голуб И.Б. Стилистика русского языка: Учеб. пособие. М.: Рольф; Айрис-пресс,
1997.
3.
Валгина Н.С., Розенталь Д.Э., Фомина М.И. Современный русский язык. Учеб-
ник. 6-е изд., перераб. и доп. М.: Логос, 2002.
4.
Manning C., Raghavan P., Schütze H. Introduction to Information Retrieval. Cam-
bridge University Press, 2008.
5.
Большакова Е.И., Воронцов К.В., Ефремова Н.Э. и др. Автоматическая обра-
ботка текстов на естественном языке и анализ данных: учеб. пособие. М.: Изд-во
НИУ ВШЭ, 2017.
6.
Захарова И.Г. Big Data и управление образовательным процессом // Вестн.
Тюмен. гос. ун-та. Гуманитарные исследования. Humanitates. 2017. Т. 3. № 1.
7.
Devlin J., Chang M.W., Lee K., et al. Bert: Pre-training of deep bidirectional trans-
formers for language understanding. arXiv preprint arXiv:1810.04805. 2018.
8.
Peters M.E., Neumann M., Iyyer M., et al. Deep contextualized word representa-
tions // Proc. NAACL-HLT. V. 1. 2018. P. 2227-2237.
9.
Барахнин В.Б., Кожемякина О.Ю., Мухамедиев Р.И. и др. Проектирование
структуры программной системы обработки корпусов текстовых документов //
Бизнес-информатика. 2019. Т. 13. № 4. C. 60-72.
10.
Hogue A., Nothman J., Curran J.R. Unsupervised biographical event extraction us-
ing wikipedia traffic // Proc. Australasian Language Technology Association Work-
shop. 2014. P. 41-49.
11.
Bonch-Osmolovskaya A., Kolbasov M. Tolstoy Digital: Mining Biographical Data in
Literary Heritage Editions // CEUR Workshop Proc. 1. BD 2015 - Proc. 1st Conf.
on Biographical Data in a Digital World 2015. 2015. P. 48-52.
12.
Garera N., Yarowsky D. Structural, transitive and latent models for biographic fact
extraction // Proc. 12th Conf. of the Eur. Chapter of the ACL (EACL 2009). 2009.
13.
Conway M. Mining a corpus of biographical texts using keywords // Liter. Lingist.
169
14.
Zhou L., Ticrea M., Hovy E. Multi-document biography summarization // Proc.
2004 Conf. on Empirical Methods in Natural Language Processing. 2004. P. 434-
441.
15.
Vempala A., Blanco E. Extracting Biographical Spatial Timelines: Corpus and Ex-
periments // IEEE/ACM Transactions on Audio, Speech, and Language Processing.
16.
Chisholm A., Radford W., Hachey B. Learning to generate one-sentence biographies
from wikidata // Proc. 15th Conf. of the Eur. Chapter of the Association for Com-
putational Linguistics: V. 1, Long Papers. 2017. P. 633-642.
17.
Yu D., Ji H., Li S., et al. Why read if you can scan? Trigger scoping strategy for
biographical fact extraction // Proc. 2015 Conf. of the North American Chapter of
the Association for Computational Linguistics: Human Language Technologies. 2015.
18.
Garcia M., Gamallo P. Exploring the effectiveness of linguistic knowledge for bio-
graphical relation extraction // Natural Language Engineering. 2015. V. 21. No. 4.
19.
Jing H., Kambhatla N., Roukos S. Extracting social networks and biographical facts
from conversational speech transcripts // Proc. 45th Annual Meeting of the Associ-
ation of Computational Linguistics. 2007. P. 1040-1047.
20.
Biadsy F., Hirschberg J., Filatova E. An unsupervised approach to biography pro-
duction using Wikipedia // Proc. ACL-08: HLT. 2008. P. 807-815.
21.
Gotti F., Langlais P. From French Wikipedia to Erudit: A test case for cross-domain
open information extraction // Computational Intelligence. 2018. V. 34. No. 2.
22.
Menini S., Sprugnoli R., Moretti G. et al. Ramble on: tracing movements of pop-
ular historical figures // Proc. Software Demonstrations of the 15th Conf. of the
Eur. Chapter of the Association for Computational Linguistics. 2017. P. 77-80.
23.
Russo I., Caselli T., Monachini M. Extracting and Visualising Biographical Events
from Wikipedia // BD. 2015. P. 111-115.
24.
Plum A., Zampieri M., Orasan C. et al. Large-scale data harvesting for biographical
data // Biographical Data in a Digital World. At: Varna, Bulgaria. 2019.
25.
Flekova L., Ferschke O., Gurevych I. What makes a good biography? Multidimen-
sional quality analysis based on Wikipedia article feedback data // Proc. 23rd Int.
Conf. on World wide web. 2014. P. 855-866.
26.
Petrasova S., Khairova N., Lewoniewski W. et al. Similar text fragments extraction
for identifying common Wikipedia communities // Data. 2018. V. 3. No. 4. P. 66.
27.
Huang K.C., Chiang I.J., Xiao F., et al. PICO element detection in medical text
without metadata: Are first sentences enough? // J. Biomed. Inform. 2013. No. 5.
28.
Yamamoto Y., Takagi T. A sentence classification system for multi biomedical litera-
ture summarization // 21st Int. Conf. on Data Engineering Workshops (ICDEW’05).
29.
Xu R., Supekar K., Huang Y. et al. Combining text classification and Hidden
Markov Modeling techniques for categorizing sentences in randomized clinical trial
abstracts // Annual Symposium proceedings. AMIA Symposium. American Medical
Informatics Association. 2006. P. 824-828.
170
30.
Mikhalkova E.V., Ganzherli N.V., Karyakin Y.E., et al. Machine learning classifi-
cation of user interests across languages and social networks // Komp. Lingvistika i
Intel. Tehn. 2018. P. 501-511.
31.
Chen T., Xu R., He Y., et al. Improving sentiment analysis via sentence type classi-
fication using BiLSTM-CRF and CNN // Expert Systems with Applications. 2017.
32.
Kim Y. Convolutional Neural Networks for Sentence Classification // Proc. 2014
Conf. on Empirical Methods in Natural Language Processing (EMNLP). 2014.
33.
Wang J., Yu L.C., Lai K.R., et al. Dimensional sentiment analysis using a regional
CNN-LSTM model // Proc. 54th Annual Meeting of the Association for Computa-
tional Linguistics (V. 2: Short Papers). 2016. P. 225-230.
34.
Trofimovich J. Comparison of neural network architectures for sentiment analysis
of russian tweets // Computational Linguistics and Intellectual Technologies: Proc.
Int. Conf. Dialogue. 2016. P. 50-59.
35.
Gordeev D. Detecting state of aggression in sentences using CNN // Int. Conf. on
Speech and Computer. Springer, Cham. 2016. P. 240-245.
36.
Miftahutdinov Z., Alimova I., Tutubalina E. KFU NLP Team at SMM4H 2019 Tasks:
Want to Extract Adverse Drugs Reactions from Tweets? BERT to The Rescue //
Proc. Fourth Social Media Mining for Health Applications (# SMM4H) Workshop
37.
Mapes N., White A., Medury R., et al. Divisive Language and Propaganda Detection
using Multi-head Attention Transformers with Deep Learning BERT-based Language
Models for Binary Classification // Proc. Second Workshop on Natural Language
Processing for Internet Freedom: Censorship, Disinformation, and Propaganda. 2019.
38.
Peng Y., Yan S., Lu Z. Transfer Learning in Biomedical Natural Language Process-
ing: An Evaluation of BERT and ELMo on Ten Benchmarking Datasets // Proc.
18th BioNLP Workshop and Shared Task. 2019. P. 58-65.
39.
Lee J.Y., Dernoncourt F. Sequential Short-Text Classification with Recurrent
and Convolutional Neural Networks // Proc. NAACL-HLT, 2016. P. 515-520.
40.
Dernoncourt F., Lee J.Y., Szolovits P. Neural Networks for Joint Sentence Classifi-
cation in Medical Paper Abstracts // Proc. 15th Conf. of the Eur. Chapter of the
Association for Computational Linguistics: V. 2, Short Papers. 2017. P. 694-700.
41.
Jin D., Szolovits P. Hierarchical Neural Networks for Sequential Sentence Classifi-
cation in Medical Scientific Abstracts // Proc. 2018 Conf. on Empirical Methods in
Natural Language Processing. 2018. P. 3100-3109.
42.
Yang B., Cardie C. Context-aware learning for sentence-level sentiment analysis with
posterior regularization // Proc. 52nd Annual Meeting of the Association for Com-
putational Linguistics (V. 1: Long Papers). 2014. P. 325-335.
43.
Глазкова А.В. Автоматический поиск фрагментов, содержащих биографиче-
скую информацию, в тексте на естественном языке // Тр. ин-та сист. прогр.
171
44.
Mikolov T., Chen K., Corrado G., et al. Efficient estimation of word representations
in vector space. arXiv preprint arXiv:1301.3781. 2013.
45.
Hochreiter S., Schmidhuber J. Long Short-term Memory // Neural. Comput. 1997.
No. 8. P. 1735-1780.
46.
Bai T., Dou H.J., Zhao W.X., et al. An Experimental Study of Text Representation
Methods for Cross-Site Purchase Preference Prediction Using the Social Text Data //
J. Comput. Sci. Technol. 2017. No. 4. P. 828-842.
47.
Дата доступа: 06.10.19.
48.
Kuratov Y., Arkhipov M. Adaptation of deep bidirectional multilingual transformers
for Russian language. arXiv preprint arXiv:1905.07213. 2019.
49.
50.
51.
Scikit-Learn. Machine Learning in Python.
52.
17.09.19.
53.
Kutuzov A., Kuzmenko E. WebVectors: A Toolkit for Building Web Interfaces for
Vector Semantic Models // Communicat. Comput. Inform. Sci. V. 661. P. 155-161.
54.
DeepPavlov: an open source conversational AI framework.
55.
Тематическая классификация фрагментов биографии с учетом их ближай-
27.05.20.
Статья представлена к публикации членом редколлегии О.П. Кузнецовым.
Поступила в редакцию 08.10.2019
После доработки 30.05.2020
Принята к публикации 09.07.2020
172