Автоматика и телемеханика, № 7, 2020
Робастное, адаптивное и сетевое
управление
© 2020 г. П.Ш. ГЕЙДАРОВ, канд. техн. наук (plbaku2010@gmail.com)
(Институт систем управления НАН Азербайджана, Баку)
СРАВНИТЕЛЬНЫЙ АНАЛИЗ РЕЗУЛЬТАТОВ ОБУЧЕНИЙ
НЕЙРОННОЙ СЕТИ С ВЫЧИСЛЕННЫМИ ВЕСОВЫМИ
ЗНАЧЕНИЯМИ И С ГЕНЕРАЦИЕЙ ВЕСОВЫХ ЗНАЧЕНИЙ
СЛУЧАЙНЫМ ОБРАЗОМ
Нейронные сети на основе метрических методов распознавания позво-
ляют на основе начальных условий задачи распознавания, таких как ко-
личество образов и эталонов, определить структуру нейронной сети (ко-
личество нейронов, слоев, связей), а также позволяют аналитически вы-
числять значения весов связей нейронной сети. Будучи нейронными сетя-
ми прямого распространения, эти сети могут также обучаться классиче-
скими алгоритмами обучения. Возможность предварительного вычисле-
ния значений весов нейронной сети позволяет утверждать, что процедура
создания и дообучения нейронной сети прямого распространения ускоря-
ется по сравнению с классической схемой создания и обучения нейронной
сети, в которой значения весов генерируются случайным образом. В ста-
тье выполняются два эксперимента на базе рукописных цифр MNIST,
подтверждающие это утверждение.
Ключевые слова: нейронные сети, метрические методы распознавания,
метод ближайшего соседа, алгоритм обратного распространения ошибки,
случайная инициализация весов.
DOI: 10.31857/S0005231020070041
1. Введение
В современном мире применение нейронных сетей получило широкое при-
менение, в особенности в задачах распознавания образов. Несмотря на это,
на практике создание и обучение нейронных сетей остается сложной и часто
непредсказуемой работой. Это главным образом связано с тем, что процесс
создания и обучения нейронных сетей [1, 2] не является строго определенным,
что создает ряд сложностей и делает этот процесс трудоемким. Сложности
заключаются как в выборе самой структуры нейронной сети, так и в выборе
параметров обучения.
В публикациях [3, 4] предложена архитектура нейронной сети, реали-
зующая метрические методы распознавания [5]. Структура этих нейронных
сетей: количества нейронов, связей, слоев строго определяются на основе
начальных условий задачи метрических методов распознавания [5], таких
56
как количество используемых эталонов и количество распознаваемых обра-
зов. Значения весов связей для этих сетей также вычисляются аналитиче-
ски на основе метрических мер близости [5]. Такая возможность уже поз-
воляет получить работающую нейронную сеть без применения алгоритмов
обучения. Нейронные сети на основе метрических методов распознавания яв-
ляются частным случаем классического трех-четырехслойного многослойно-
го перцептрона, но при этом архитектуры этих сетей позволяют определить
структуру нейронной сети и аналитически определять значения весов. Кро-
ме того, архитектура этих сетей позволяет каскадно добавлять в нейронную
сеть новые эталоны и распознаваемые образы без изменения предыдущих ве-
совых значений, что также выгодно отличает эти сети от классических сетей
прямого распространения, в том числе и от глубоких сверточных сетей [6, 7].
Нужно сказать, что существуют нейронные сети с предварительно опре-
деляемыми весами, такие, например, как сети Хопфилда и Хемминга [1, 2].
Но эти сети не являются сетями прямого распространения, имеют обратные
связи и в связи с этим имеют ряд сложностей и нерешенных проблем, среди
которых и такие, как проблема неустойчивости этих сетей. Помимо этого,
предварительное фиксирование значений весов иногда применяется и в ней-
ронных сетях прямого распространения. Это так называемый подход “замо-
раживания весов” [8], что, например, применяется в случаях, когда необходи-
мо сократить время обучения путем замораживания веса скрытого нейрона,
если его выход не изменяется существенно в течение обучения, или когда
необходимо воспользоваться преимуществами ранее обученной нейронной се-
ти и использовать ее веса для дальнейшей настройки данной нейронной сети.
Но эти подходы не определяют значения весов, а направлены на корректи-
рование и ускорение процесса алгоритма обучения.
Поскольку нейронные сети на основе метрических методов распознавания
являются сетями прямого распространения, то эти сети могут также обучать-
ся и классическими алгоритмами обучения [1, 2]. В [9, 10] был приведен обоб-
щенный алгоритм определения значений весов для второго и третьего слоя
полносвязной нейронной сети, полученной на основе нейронной сети на осно-
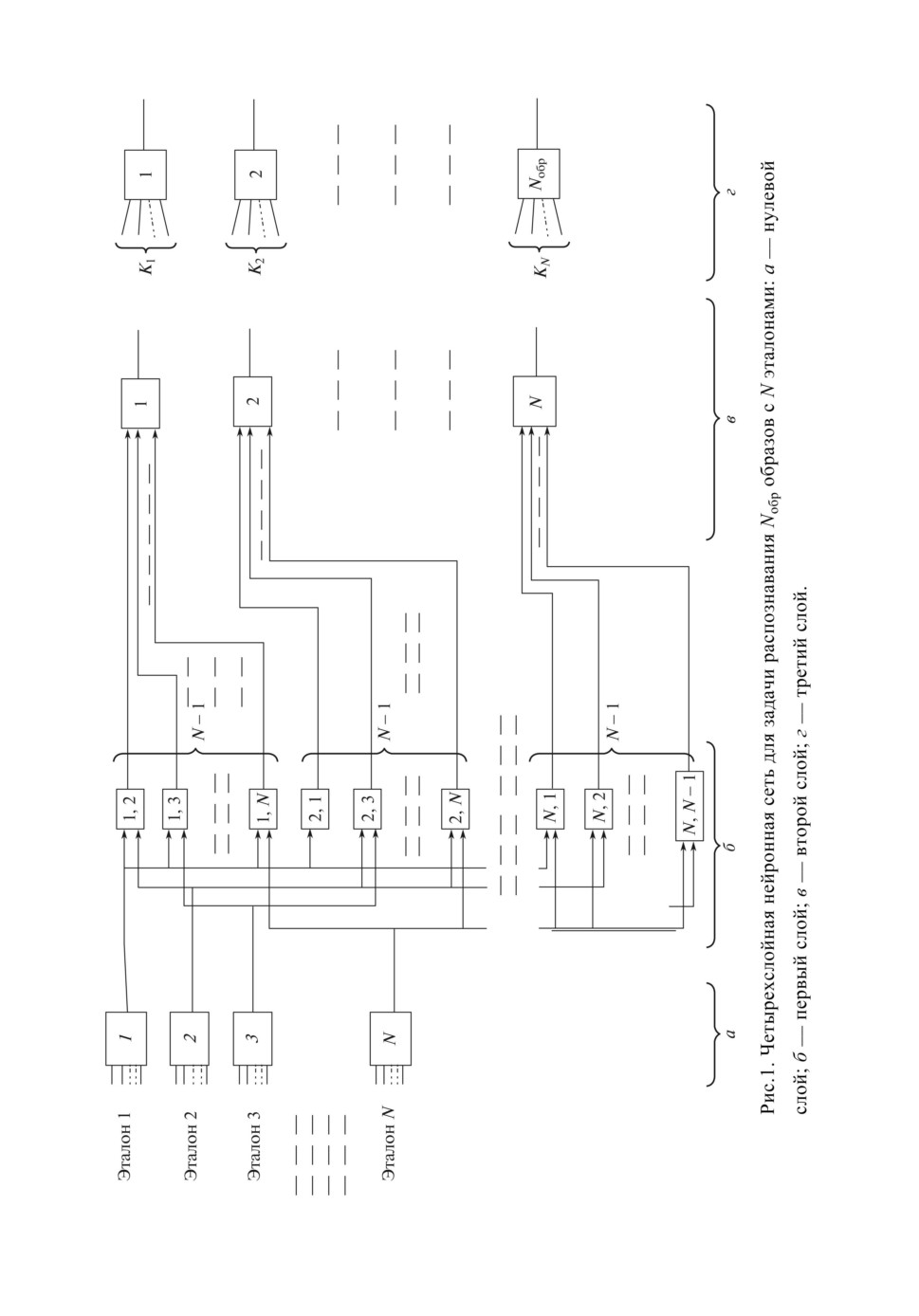
ве метрических методов распознавания (рис. 1). Данный алгоритм позволяет
вычислять всевозможные диапазоны значений весов и порогов нейронной се-
ти второго и третьего слоев, при которых логика работы нейронной сети на
рис. 1 сохраняется неизменной. Там же было сделано предположение, что
процесс вычисления и последующее за этим дообучение нейронной сети бу-
дет выполняться быстрее, чем это происходит классическим способом, когда
обучение нейронной сети выполняется на основе случайно сгенерированных
значений весов. Но такое предположение могло быть и ошибочным, поскольку
не исключает того, что процесс дообучения может, наоборот, уничтожать ре-
зультативность, основанную на предварительно вычисленных значениях ве-
сов, и в результате, возможно, еще больше удлинять процесс обучения. Дру-
гими словами, для проверки предположения в публикациях [9, 10] необходимо
наличие экспериментального подтверждения. С этой целью в данной статье
выполняется сравнительный эксперимент на базе MNIST обучений одной и
той же нейронной сети как с вычисленными, так и со случайно сгенерирован-
ными весовыми значениями. Кроме того, такой эксперимент также позволит
58
проверить работоспособность нейронных сетей на основе метрических мето-
дов распознавания на большой тестируемой базе, такой как база MNIST, а
также проверить возможность работы данных сетей с непрерывными функ-
циями активаций и соответственно возможность дообучения этих сетей ал-
горитмом обратного распространения ошибки. Принципиальная разница от
классических методов при таком подходе будет заключаться в ускорении про-
цедуры создания и обучения нейронной сети благодаря предварительному
вычислению значений весов связей нейронов, тогда как в классических схе-
мах создания и обучения нейронной сети ускорение реализуется при помощи
использования более быстрых алгоритмов обучения нейронной сети со слу-
чайной инициализацией весов.
Отметим, что возможность ускорения создания и обучения нейронной сети
посредством предварительного вычисления весов может быть особо актуаль-
ной для будущих нейронных сетей, близких к возможностям биологических
нейронных сетей, где количество распознаваемых образов будет значитель-
ным или даже огромным.
Цель статьи выполнить два эксперимента по обучению одной и той же
нейронной сети с одинаковым количеством эпох обучения как с предвари-
тельно вычисленными весами, так и с инициализацией значений весов слу-
чайными числами. В качестве базы данных используется база MNIST изоб-
ражений рукописных цифр. Окончательная цель заключается в сравнении
полученных результатов двух экспериментов с целью оценки как по резуль-
тативности распознанных цифр базы MNIST, так и по общему потраченному
времени создания и обучения нейронной сети.
2. Основные положения нейронных сетей на основе
метрических методов распознавания
Метрические методы распознавания это методы, которые определяют
принадлежность распознаваемого объекта к тому или иному образу в неко-
торой определенной признаковой системе координат на основе наименьшего
значения метрической характеристики близости к эталону или к группе эта-
лонов образа [5]. Здесь под “эталонами” понимаются выбранные (выделенные)
образцы от каждого образа в существующей выборке данных. Работоспособ-
ность метрических методов распознавания основана на гипотезе компактно-
сти, которая предполагает, что элементы одного класса (образа) в некоторой
признаковой системе координат находятся компактно друг к другу. В каче-
стве метрических характеристик близости для одной точки (ячейки таблицы,
пикселя) могут использоваться разные метрические выражения, например
выражения среднеквадратичной разности (2.1), (2.2):
(2.1)
wij,k = (yetal - j)2 ,
где wij,k
значение веса таблицы весов с координатами i, j для k-го нейро-
на нулевого слоя, yetal ближайшая по вертикали к координате j активная
ячейка бинарной матрицы. Выражение (2.1) применимо, например, для за-
59
а
б
в
r
wc, r
Нейрон
6
0
x4, 6w4, 6
5
1
0
0
-1
0
x4, 5w4, 5
3
0
-1
0
1
4
Sn
F(Sn)
-2
0
1
1
(с1, r1)
3
xc, rwc, r
2
-1
-1
0
2
(сp, rp)
(сp, rp)
d1
1
-1
1
1
4
x0, 1w0, 1
d2
1
2
5
8
0
x0, 0w0, 0
(с2, r2 )
0
1
2
3
4
c
Рис. 2. Пример таблицы весов с размерностью 5 × 7 для пары эталонов {7, 2}:
а формирование таблицы весов для нулевого слоя; б таблица весов для
нейрона первого слоя; в нейрон первого слоя.
дачи распознавания кривых
(
)
(2.2)
w(0)c,r = d21 = (c1 - cp)2 + (r1 - rp)2
Формула (2.2) еще одно возможное выражение определения значения веса
для нейрона нулевого слоя, где (cp, rp) координаты точки (ячейки таблицы
весов), для которой вычисляется значение веса, (c1, r1) ближайшие коор-
динаты активных точек (ячеек таблицы весов) для точки (ячейки) с коорди-
натами (cp, rp) (рис. 2,а).
К метрическим методам относятся такие методы, как: метод построения
эталонов (метод эталона), метод ближайшего соседа, метод ближайших N со-
седей, метод потенциальных функций и т.д. [5]. Приведенная на рис. 1 схема
нейронной сети реализует метод ближайшего соседа, алгоритм которого реа-
лизуется следующим образом:
• Определяется характеристика (коэффициент) близости, например по вы-
ражениям (2.1), (2.2), для каждого эталона;
• Определяется минимальное значение коэффициента близости;
• По принадлежности ближайшего эталона к тому или иному образу опре-
деляется наименование ближайшего образа (класса).
В нейронной сети на рис. 1 каждому выбранному эталону соответствует
один нейрон в нулевом слое и согласно п. 1 алгоритма метода ближайшего
соседа в каждом нейроне нулевого слоя определяется суммарное значение
коэффициента близости между входным элементом X и эталоном, которому
соответствует данный нейрон:
∑∑
(2.3)
Sn(0)k =
xijwi,j,
i=1 j=1
где Sn(0)k
значение функции состояния k-го нейрона нулевого слоя, xij
значение ячейки бинарной матрицы входного распознаваемого элемента.
R, C число колонок и рядов таблицы весов и бинарной матрицы. При этом
60
здесь нейроны нулевого слоя являются линейными нейронами, т.е. нейрона-
ми, для которых функция активации равна функции состояния нейрона:
(2.4)
f (Sn(0)k) = Sn(0)k.
Далее, согласно п. 2 алгоритма метода ближайшего соседа определяется
эталон (нулевой нейрон) с минимальным значением коэффициента близо-
сти Sn(0)k, который соответствует самому ближайшему эталону к распознавае-
мому элементу X. Для этого в первом слое выполняется попарное сравнение
всех выходов нулевого слоя, рис. 1,б , например, для первого нейрона первого
слоя функция состояния определяется выражением
(
)
(
)
(2.5)
Sn(1)1 = w(1)2f Sn(0)
-w(1)1f Sn(0)
,
2
1
где w(1)2 = w(1)1 = 1, а функция активации для этого нейрона определяется
условиями:
(
)
(1)
f Sn(1)
= 1, если Sn
< 0,
1
1
(2.6)
(
)
(1)
f Sn(1)
= 0, если Sn
> 0.
1
1
А в нейроне второго слоя (рис. 1,в) выполняется суммирование всех вы-
ходов первого слоя, соответствующих одному эталону (одному нейрону нуле-
вого слоя):
∑ (
)
(2.7)
Sn(2)k =
f Sn(1)
,
k,j
j=1,j=k
где активный выход второго слоя выделяется пороговым значением H(2) =
= N - 1 и определяет ближайший эталон к распознаваемому объекту X:
(
)
(2)
f Sn(2)
= 1, если Sn
≥ (N - 1) = H(2),
k
k
(2.8)
(
)
(2)
f Sn(2)
= 0, если Sn
< (N - 1) = H(2).
k
k
Каждый k-й нейрон третьего слоя нейронной сети суммирует выходы ней-
ронов второго слоя, принадлежащих к эталонам одного k-го образа
∑ (
)
(2.9)
Sn(3)k =
f Sn(2)
,
i
i∈k
где Kk количество эталонов для k-го распознаваемого образа, и проверяет
на активность хотя бы один вход нейрона при помощи функции активации:
(
)
(3)
f Sn(3)
= 1, если Sn
> 0,
k
k
(2.10)
(
)
(3)
f Sn(3)
= 0, если Sn
≤ 0.
k
k
61
Значения весов для каждого входа нейронов второго и третьего слоев вы-
числяются либо по приведенному в [9, 10] обобщенному алгоритму опреде-
ления значения весов второго и третьего слоя, либо в простейшем случае
принимаются равными единице:
(2.11)
w(2)i,j = w(3)i,j
= 1.
Таким образом, согласно п. 3 алгоритма метода ближайшего соседа поряд-
ковый номер активного выхода третьего слоя определяет ближайший образ
для распознаваемого элемента X.
На рис. 1 приведена расширенная схема нейронной сети на основе мет-
рических методов распознавания, реализующая метод ближайшего соседа.
Нейронная сеть строится на основе набора выбранных эталонов и количе-
ства распознаваемых в задаче образов (классов).
На схеме рис. 1 количество нейронов второго слоя равно количеству ис-
пользуемых эталонов n(2) = N, а количество нейронов третьего слоя соответ-
ствует количеству распознаваемых образов n(3) = Nобр. Количество нейронов
1-го слоя в расширенной схеме на рис. 1,б определяется количеством всевоз-
можных пар эталонов:
(2.12)
n(1)
= N(N - 1).
Нейронная сеть на рис. 1 может быть и без нулевого слоя, тогда для каж-
дого нейрона первого слоя вычисляется таблица весов, где значения весов
связей нейронов первого слоя вычисляются аналитически на основе метриче-
ских выражений близости двух нейронов нулевого слоя, например, выраже-
нием
(
)
(
)
(2.13)
w(1)c,r = d21 - d22 = (c1 - cp)2 + (r1 - rp)2
- (c2 - cp)2 + (r2 - rp)2 ,
где (cp, rp)
координаты точки (ячейки таблицы весов), для которой вы-
числяется значение веса, (c1, r1) и (c2, r2) ближайшие координаты актив-
ных точек (ячеек таблицы весов) для точки (ячейки) с координатами (cp, rp)
(рис. 2,а и 2,б ). В качестве выражений меры близости могут использоваться и
другие более простые или сложные выражения, отличные от (2.13). В данной
статье при создании нейронной сети используется выражение (2.13).
Отметим, что на основе схемы на рис. 1 с незначительными дополнениями
и поправками могут быть также реализованы другие метрические методы
распознавания.
3. Создание нейронной сети и вычисление значений весов
В данной статье нейронная сеть создается на базе MNIST. Это означает,
что набор эталонов набирается из базы MNIST (рис. 3), размерность таблицы
весов определяется также на основе размерности матрицы изображений базы
MNIST, превышая ее в два раза и будет равна 28×56. Дальнейшее дообучение
сети выполняется также на базе MNIST.
62
Рис. 3. Программный модуль для распознавания и обучения изображений ба-
зы MNIST, реализованный в среде Builder C++.
0_157
1_135
2_172
3_32
4_121
5_102
6_21
7_0
8_128
9_125
0
0_25
1_2
2_35
3_51
4_24
5_120
6_217
7_64
8_61
9_151
1
0_28
1_46
2_77
3_63
4_56
5_23
6_22
7_97
8_84
9_20
2
Рис. 4. Выбранные эталоны из контрольной базы MNIST, наименование изоб-
ражения включает название образа и порядковый номер изображения в базе
MNIST.
Напомним, что база MNIST состоит из обучающей базы, в который вхо-
дят 60000 изображений рукописных цифр, и контрольной (тестовой) базы,
состоящей из 10000 образцов изображений цифр. Каждой базе также прила-
гается своя база наименований цифр, порядок расположения которых такой
же, как и порядок расположения изображений цифр в обучающей и кон-
трольной базах. Изображения цифр в базах описаны в виде матрицы цифр
размерностью 28 × 28. Каждая цифра матрицы определяет значение тональ-
ности одного пикселя изображения цифры в диапазоне [0, 255].
В качестве эталонов было выбрано по три образца изображений цифр от
каждого образа. Итого использовалось 30 эталонов, приведенных на рис. 4.
Эталоны были выбраны интуитивно из первых 250 изображений цифр кон-
трольной базы MNIST. На рис. 4 над каждым выбранным эталоном приве-
63
дено наименование изображения, например 2_1, в котором первая цифра
указывает образ, которому принадлежит изображение цифры, вторая циф-
ра указывает порядковый номер данного изображения цифры в базе MNIST.
Далее по тексту изображения базы MNIST будут обозначаться так, как пред-
ставлено. Поскольку количество эталонов равно 30, то в соответствии с ар-
хитектурой нейронных сетей, реализующих метрические методы распозна-
вания, количество нейронов второго слоя будет равно тоже 30, где каждый
i-й выход соответствует i-му эталону и определяет принадлежность распозна-
ваемого изображения к i-му эталону.
Для эталонов в рассматриваемой задаче выбран порядок расположения
в той последовательности, который приведен на рис. 4. Сначала столбец с
изображениями цифры “0”, потом цифры “1” и т.д. В соответствии с этим
схема сети на рис. 1 определяет и выходы второго слоя. Например, эталону
0_157 соответствует k = 0 выход второго слоя, а эталону 5_23 соответствует
k = 5 · 3 + 3 - 1 = 17 выход второго слоя и т.д. Количество нейронов третье-
го слоя равно количеству распознаваемых образов цифр, n(3) = 10. Каждый
i-й выход третьего слоя определяет принадлежность распознаваемого элемен-
та к i-му образу цифры. Порядок образов цифр определен последовательно
от 0 до 9.
Количество нейронов первого слоя определяется выражением (2.12):
(3.1)
n(1)
= 30 · 29 = 870.
Для того чтобы упростить и ускорить вычисление таблиц весов первого
слоя, вычисляются таблицы весов нулевого слоя [4] по формуле (2.2), на ос-
нове которых далее вычисляются таблицы весов первого слоя (2.13).
В процессе распознавания или обучения для каждого входного распозна-
ваемого изображения составляется бинарная матрица, которая состоит из
двух частей. В первой части бинарной матрицы единицы определяют свет-
лые пиксели изображения, значения которых >150 и, наоборот, нули опре-
деляют затемненные пиксели изображения, значения которых <150. Другая
часть матрицы зеркально противоположна, определяет активными (=1) тем-
ные пиксели изображений (<150) и неактивными (=0) светлые пиксели
изображений (>150). Размерность бинарной матрицы равна 28 × 56. Соот-
ветственно каждая таблица весов нулевого слоя соразмерна с бинарной мат-
рицей и состоит тоже из двух частей, приведенных на рис. 5. На рис. 5 можно
видеть, что в отличие от входной бинарной матрицы распознаваемых изоб-
ражений в таблицах весов нулевого слоя активным пикселям изображения
соответствуют нули. Для каждого эталона вычисляется своя таблица весов
нулевого слоя, подобная таблице на рис. 5.
Таблица весов первого слоя определяется на основе таблиц весов нулевого
слоя путем вычитания двух попарно сравниваемых таблиц весов нейронов
нулевого слоя выражением
(3.2)
W(1)i,j = W(0)i - W(0)j.
64
Рис. 6. Таблица весов первого слоя для нейрона, выполняющего сравнение
эталонов 2_172 и 5_102: а для части бинарной матрицы, в которой свет-
лым пикселям изображения (>150) соответствует 1; б для части бинарной
матрицы, в которой затемненным пикселям изображения (<150) соответству-
ет 1.
Поскольку значения весов первого слоя получаются большими, в основ-
ном располагающиеся в диапазоне [0, 100], что неестественно для алгоритма
back propagation, то каждое значение веса первого слоя делится на 100. На
рис. 6 приведен пример таблицы весов первого слоя, вычисленных для па-
ры эталонов 2_172 и 5_102. Таким образом, для каждого нейрона первого
слоя вычисляется таблица весов. Итого вычисляется 870 таблиц весов для
первого слоя. При этом нужно сказать, что в дальнейшем при обучении ней-
ронной сети нейроны нулевого слоя далее не используются, рассматриваться
будет только полученная трехслойная сеть, состоящая из первого, второго и
третьего слоев (рис. 1,б , 1,в и 1,г).
66
а
б
Рис. 7. а фрагмент весов для второго слоя; б все веса третьего слоя.
Прежде чем начать обучение нейронной сети на рис. 1 алгоритмом back
propagation, необходимо провести некоторые преобразования в сети. На
рис. 1,б , 1,в и 1,г нейронная сеть является сетью прямого распространения,
но при этом второй и третий слои сети не являются полносвязными, соответ-
ственно и сама сеть неполносвязная. В [9, 10] был приведен обобщенный ал-
горитм создания полносвязной нейронной сети и вычисления значений весов
второго и третьего слоев, при которых сохраняется первоначальная логика
работы сети. Но в простейшем случае из схемы на рис. 1 полносвязную ней-
ронную сеть можно получить добавлением всех недостающих связей второго
и третьего слоев, значения весов которых будут приравнены нулю. В то вре-
мя как значения связей (не добавленных) второго и третьего слоя на рис. 1
останутся, как и прежде, равными единице. В этом случае логика работы се-
ти на рис. 1 также не изменится. На рис. 7 приведены значения весов связей
нейронов второго и третьего слоев, расположенных горизонтально в строках.
Каждому нейрону второго и третьего слоев соответствует строка последова-
тельности значений весов связей: единиц и нулей. Например, на рис. 7,б ко-
личество последовательных единиц в строке определяется количеством эта-
лонов, принадлежащих одному образу цифры. В рассматриваемом примере
это значение одинаково для всех образов и равно трем (рис. 4). На рис. 7 над
каждой строкой приведены также пороговые значения нейронов. Для второ-
го слоя согласно выражению (2.8) это значение одинаково для всех нейронов
67
2_174
4_19
6_22
2_1
Рис. 8. Образцы изображений цифр из контрольной базы MNIST.
второго слоев и равно H(2) = N - 1 = 30 - 1 = 29, для третьего слоя H(3) = 0.
Пороговое значение, представленное в качестве веса, противоположно по зна-
ку пороговому значению H, (Wh2 = -H = -29).
В качестве функции активации нейронов использовалась сигмоидная
функция активации
1
(3.3)
f (Sw) =
1+e-Sw
Поскольку для схемы сети на рис. 1 все весовые значения нейронов второго
и третьего слоев являются положительными, то соответственно и все выхо-
ды нейронов третьего слоя, вычисленные с сигмоидной функцией активации,
Таблица 1. Выходы третьего слоя нейронной сети с пороговой и сигмоидальной
функцией активации при распознавании символа 2_174 (рис. 8) из контрольной
базы MNIST
с пороговой функцией активации
0
Sw3 = 0
Yout = 0
1
Sw3 = 0
Yout = 0
2
Sw3 = 1
Yout = 1
3
Sw3 = 0
Yout = 0
4
Sw3 = 0
Yout = 0
5
Sw3 = 0
Yout = 0
6
Sw3 = 0
Yout = 0
7
Sw3 = 0
Yout = 0
8
Sw3 = 0
Yout = 0
9
Sw3 = 0
Yout = 0
с сигмоидной функцией активации
0
Sw3 = 0,000270242677595017
Yout = 0,500067560668988
1
Sw3 = 3,43951083407716E-6
Yout = 0,500000859877708
2
Sw3 = 0,0526576299057448
Yout = 0,513161366435398
3
Sw3 = 0,0109778057331013
Yout = 0,502744423871947
4
Sw3 = 9,28464982946175E-6
Yout = 0,500002321162457
5
Sw3 = 0,000934588149375769
Yout = 0,500233647020337
6
Sw3 = 0,000250751415905857
Yout = 0,500062687853648
7
Sw3 = 1,20144980966343E-7
Yout = 0,500000030036245
8
Sw3 = 0,014626235919069
Yout = 0,503656493794839
9
Sw3 = 0,00149247436075622
Yout = 0,50037311852093
68
Таблица 2. Результаты распознавания контрольной базы MNIST
(10000 символов) без обучения
s0 = 834
i0 = 980
p0 = 85 %
s1 = 968
i1 = 1135
p1 = 85 %
s2 = 530
i2 = 1032
p2 = 51 %
s3 = 454
i3 = 1010
p3 = 44 %
s4 = 410
i4 = 982
p4 = 41 %
s5 = 411
i5 = 892
p5 = 46 %
s6 = 586
i6 = 958
p6 = 61 %
s7 = 556
i7 = 1028
p7 = 54 %
s8 = 773
i8 = 974
p8 = 79 %
s9 = 750
i9 = 1009
p9 = 74 %
Итого: i = 10000, s = 6272, p = 62 %
больше 0,5. Это можно наблюдать в табл. 1, где приведены выходы третьего
слоя при распознавании изображения 2_174 (рис. 8). В данных эксперимен-
тах в качестве правила сравнения на выходе нейронной сети было использо-
вано определение активности выхода нейрона третьего слоя по наибольшему
значению выхода Yi нейронной сети, например в табл. 1 наибольший выход
соответствует выходу 2.
Все вычисления, описанные в данной статье, проводились на одном ком-
пьютере в программном модуле, приведенном на рис. 3, реализованном в сре-
де Builder C++. На весь процесс создания нейронной сети и вычисления всех
весов в программном модуле на рис. 3 было зафиксировано общее потрачен-
ное время tсозд = 0,5469 с, т.е. меньше секунды.
В табл. 2 приведены результаты распознавания контрольной базы MNIST
(10000 изображений) на основе полученной нейронной сети с использованием
как пороговой, так и сигмоидной функции активации. Также приведены ко-
личество и процент правильно идентифицированных объектов контрольной
базы MNIST отдельно для каждого образа цифры (sj, pj, где j наиме-
нование образа), а также приводится общее количество изображений ij для
каждого j образа в контрольной базе MNIST.
По данным табл. 2 можно видеть, что общее количество правильно иден-
тифицированных изображений MNIST составило 62 % для нейронной сети
с пороговой функцией активации. Результат вычисленных значений весов
сохраняется и с сигмоидной функцией активации, что подтверждается так-
же распознаванием контрольной базы MNIST нейронной сети с сигмоидной
функцией активацией и с проверкой на выходе нейронной сети по наибольше-
му значению выхода Yi. В этом случае результат нейронной сети с сигмоид-
ной функцией активации идентичен результату нейронной сети с пороговой
функцией активации и равен также 62 %.
Нужно также сказать, что в данных экспериментах для сигмоидной функ-
ции активации значение веса-порога Wh2 = -29 увеличивалась до значения
Wh2 = -27, что было сделано для того, чтобы повысить пропускную способ-
ность нейронов второго слоя, поскольку известно, что в отличие от пороговой
69
функции активации сигмоидная функция стремится к единице, но не дости-
гает ее.
Возможно, в этом изменении и не было никакой необходимости, поскольку
процент распознавания по контрольной базе MNIST с сигмоидной функцией
активации и с проверкой на выходе нейронной сети по наибольшему значению
выхода сети одинаков по результату и для случая Wh2 = -27 и для случая
Wh2 = -29 и равен 62 %, т.е. равен результату тестирования нейронной сети
с пороговой функцией активации.
Обучение нейронной сети выполнялось стохастическим алгоритмом обрат-
ного распространения ошибки (back propagation) с использованием обучаю-
щей выборки MNIST (60000 изображений). Поправки вносились после каж-
дого представления нового объекта на входы сети в случае наличия ошиб-
ки распознавания на выходе нейронной сети. В случае отсутствия ошибки
распознавания правки не вносились. При обратном распространении в каче-
стве правильного активного выхода нейронной сети рассматривалось значе-
ние ycorr = 0,7, а для правильного неактивного выхода значение ycorr = 0,2,
т.е. в процессе обучения значения выходов нейронной сети подтягивались к
этим значениям. Для каждого эксперимента обучения нейронной сети исполь-
зовались три эпохи, первые две из которых обучались со скоростью nk = 0,1,
а последняя эпоха со скоростью nk = 0,02. Ошибка обучения Serr вычис-
лялась для каждой эпохи по формуле:
∑
Nобр-1∑(
(
))2
1
(3.4)
Serr =
y(corr)k - f Sn(3)k
,
2
i=0
k=0
где y(corr)k
правильное значение k-го выхода третьего слоя для активного
выхода y(corr)k = 0,7, а для неактивного y(corr)k = 0,2; P
количество непра-
вильно идентифицированных изображений обучающей базы MNIST, для ко-
торых в процессе эпохи делались правки весов алгоритмом обратного рас-
пространения ошибки. Во втором эксперименте также выполнялось обуче-
ние полученной выше нейронной сети, но на этот раз значения всех весов
генерировались случайным образом в диапазоне [-0,5; 0,5].
Стохастический алгоритм обратного распространения ошибки, реализо-
ванный в программном модуле рис. 3, выполняется следующим образом:
1. В последовательном порядке выбирается из обучающей базы MNIST
изображение обучающей выборки, для которой создается бинарная матрица
изображения, которая подается на вход нейронной сети с предварительно
вычисленными или сгенерированными случайными весовыми значениями;
2. Выполняется прямое распространение по нейронной сети с последова-
тельным вычислением значений функций состояний и активаций нейронов
по выражениям (2.5)-(2.10), начиная c первого слоя и кончая третьим;
3. Проверяются выходы нейронной сети по правилу наибольшего значения
выхода сети. Если активный выход нейронной сети соответствует установлен-
ному выходу образа, которому принадлежит изображение, то выполняется
возвращение к п. 1, если не соответствует, то реализуется обратное распро-
70
странение ошибки по сети от третьего слоя к первому, для чего выполняется
переход к п. 4;
4. Для каждого i-го нейрона третьего слоя вычисляется новое весовое по-
роговое значение (смещение):
(3.5)
Wh3[i][0] = Wh3[i][0] + dWh3[i][0],
где dWh3[i][0] приращение весового порогового значения i-го нейрона тре-
тьего слоя
(3.6)
dWh3[i][0] = nk · Sig3[i],
здесь nk коэффициент скорости обучения (на рис. 3 поле nk), а Sig3[i]
ошибка для i-го выхода третьего слоя нейронной сети, определяемая по вы-
ражению:
(3.7)
Sig3[i] = (Ycorr - Yout[i]) · Yout[i] · (1 - Yout[i]),
где Yout[i]
текущее i-е выходное значение третьего слоя, Ycorr
ожи-
даемое i-е выходное значение третьего слоя. Для ожидаемого правильного
выхода Ycorr = 0,7, для ожидаемого неправильного выхода нейронной се-
ти Ycorr = 0,2. На этом же этапе вычисляется также поправка суммарной
квадратичной ошибки (3.4) Serr для данного изображения и добавляется к
предыдущему значению Serr:
Nобр-1∑
(3.8)
Serr = Serr +
(Ycorr - Yout[i])2 ;
i=0
5. Вычисляются новые весовые значения для третьего слоя по выражению:
(3.9)
W3[i][k] = W3[i][k] + dW3[i][k],
здесь dW3[i][k] приращение значения веса W3[i][k], связывающего k-й ней-
рон второго слоя и i-й нейрон третьего слоя, и определяется по выражению:
(3.10)
dW3[i][k] = nk · Sig3[i] · F2[k],
где F2[k] выход k-го нейрона второго слоя. Вычисляются весовые пороговые
значения нейронов второго слоя:
(3.11)
Wh2[k][0] = Wh2[k][0] + dWh2[k][0],
где dWh2[k][0]
приращение весового порогового значения Wh2[k][0] для
k-го нейрона второго слоя, определяемое выражением:
(3.12)
dWh2[k][0] = nk · Sig2[k],
здесь ошибка
Nобр-1∑
(3.13)
Sig2 [k] =
(Sig3 [i] · W3 [i] [k]) ;
i=0
71
6. Вычисляются новые весовые значения для второго слоя по выражению:
(3.14)
W2[i][k][k1] = W2[i][k][k1] + dW2[i][k][k1],
где dW2[i][k][k1]
приращение значения веса W2[i][k][k1] для связи, связы-
вающего i-й нейрон второго слоя и нейрон первого слоя, который выполняет
идентификацию пары эталонов с порядковыми номерами k и k1. dW2[i][k][k1]
вычисляется выражением:
(3.15)
dW2[i][k][k1] = nk · Sig2[i] · F1[k][k1],
где F1[k][k1] выход нейрона первого слоя, выполняющий сравнение k и k1
эталонов.
Вычисляются весовые пороговые значения для нейронов первого слоя:
(3.16)
Wh1[k][k1][0] = Wh1[k][k1][0] + dWh1[k][k1][0],
где dWh1[k][k1][0]
приращение весового порогового значения веса
Wh1[k][k1][0] для нейрона первого слоя, выполняющее распознавание k и k1
эталонов
(3.17)
dWh1[k][k1][0] = nk · Sig1[k][k1],
где ошибка
∑
(3.18)
Sig1 [k] [k1] =
(Sig2[i] · W2[i] [k] [k1]);
i=0
7. Вычисляются новые весовые значения отдельно для двух частей таблиц
весов первого слоя по выражениям:
(3.19)
W1[k][k1][0] [r] [c] = W1[k][k1][0] [r] [c] + dW1[k][k1][0] [r] [c] ,
(3.20)
W1[k][k1][1] [r] [c] = W1[k][k1][1] [r] [c] + dW1[k][k1][1] [r] [c] ,
где dW1[k][k1][0] [r] [c] приращение весового значения W1[k][k1][0] [r] [c] для
связи, связывающего ячейку первой части таблицы весов с координатами
(r, c) с нейроном первого слоя, который выполняет попарную идентифика-
цию эталонов с порядковыми номерами k и k1, а dW1[k][k1][1] [r] [c] прира-
щение весового значения W1[k][k1][1] [r] [c] для связи, связывающего ячейку
второй части таблицы весов с координатами (r, c) с нейроном первого слоя,
который выполняет попарную идентификацию эталонов с порядковыми но-
мерами k и k1. Значения dW1[k][k1][0] [r] [c] и dW1[k][k1][1] [r] [c] определяются
выражениями:
(3.21)
dW1[k][k1][0][r][c] = nk · Sig1[k][k1] · BinX[0][r][c] ,
(3.22)
dW1[k][k1][1][r][c] = nk · Sig1[k][k1] · BinX[1][r][c] ,
где BinX[0] [r] [c], BinX[1] [r] [c]
значения ячеек с координатами (r, c) для
первой и второй частей бинарной матрицы входного изображения обучающей
базы MNIST;
72
Таблица 3. Сравнение результатов обучения нейронной сети по обучающей
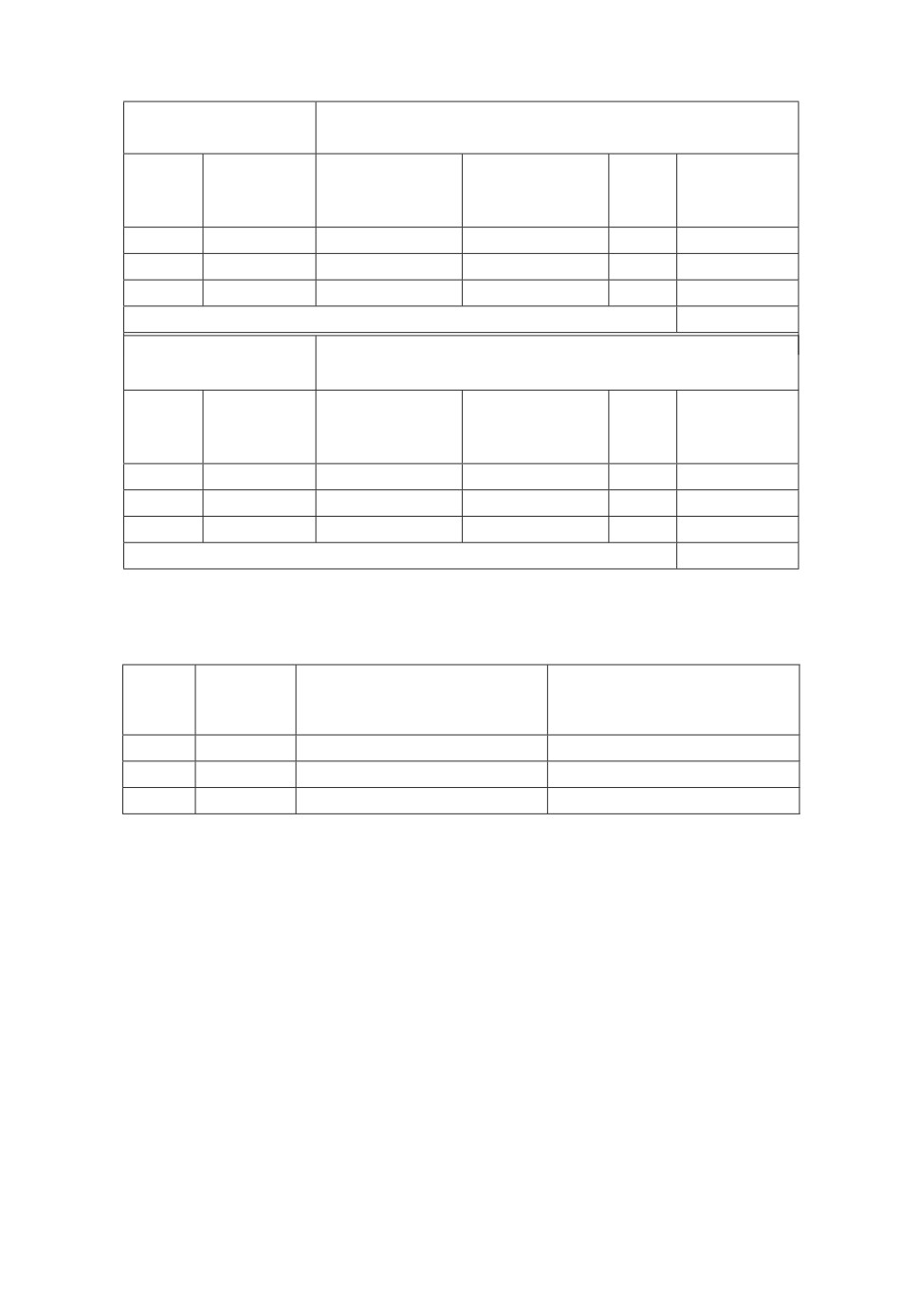
выборке MNIST (60000 изображений) для каждой эпохи обучения
Обучение нейронной сети с предварительно
вычисленными весами
Количество
Процент
№ Скорость
время в
узнанных
узнанных
Serr
эпохи обучения
минутах
изображений изображений
1
0,1
43932
73 %
1199
159
2
0,1
49748
83 %
737
98
3
0,02
52285
87 %
545
72
Общее время обучения в минутах
329
Обучение нейронной сети с случайной
инициализацией весов в диапазоне [-0,5; 0,5]
Количество
Процент
№ Скорость
время в
узнанных
узнанных
Serr
эпохи обучения
минутах
изображений изображений
1
0,1
35370
59 %
1935
256
2
0,1
46033
76 %
1051
139
3
0,02
49195
82 %
784
104
Общее время обучения в минутах
499
Таблица 4. Сравнение результатов обучения нейронной сети с проверкой
на контрольной выборке MNIST (10000 изображений) для каждой эпохи
обучения
Скорость
Обучение нейронной сети
Обучение нейронной сети
№
обучения
с предварительно
с случайной
эпохи
в эпохе
вычисленными весами
инициализацией весов
1
0,1
9145
8894
2
0,1
9282
9116
3
0,02
9449
9256
8. Если были последнее, 60000-е, изображение обучающей базы MNIST
и последняя заданная эпоха (рис. 3), то алгоритм на этом завершается, в
противном случае выполняется переход к п. 1.
Отметим, что при программной реализации нейронных сетей на основе
метрических методов распознавания в какой-либо программной среде, целе-
сообразно и удобно нумерацию нейронов первого слоя вести не по количеству
нейронов, как это делается при реализации классических схем, а по номерам
двух эталонов, которые сравниваются в данном нейроне, как это было по-
казано выше, например W1[k][k1][0] [r] [c]. Такой подход позволяет удобно и
понятно реализовать структуру схемы на рис. 1, а также функции: предвари-
тельного вычисления значений весов, распознавания входного изображения,
обучения нейронной сети, вывода полученных результатов и т.д.
В табл. 3 приведены результаты обучений полученной нейронной сети как
с предварительно вычисленными значениями весов нейронной сети, так и
классическим образом со случайной инициализацией весов.
73
В табл. 4 приведены результаты проверки полученной нейронной сети по-
сле каждой эпохи обучения на контрольной базе MNIST (10000 изображений).
4. Сравнение полученных результатов двух экспериментов
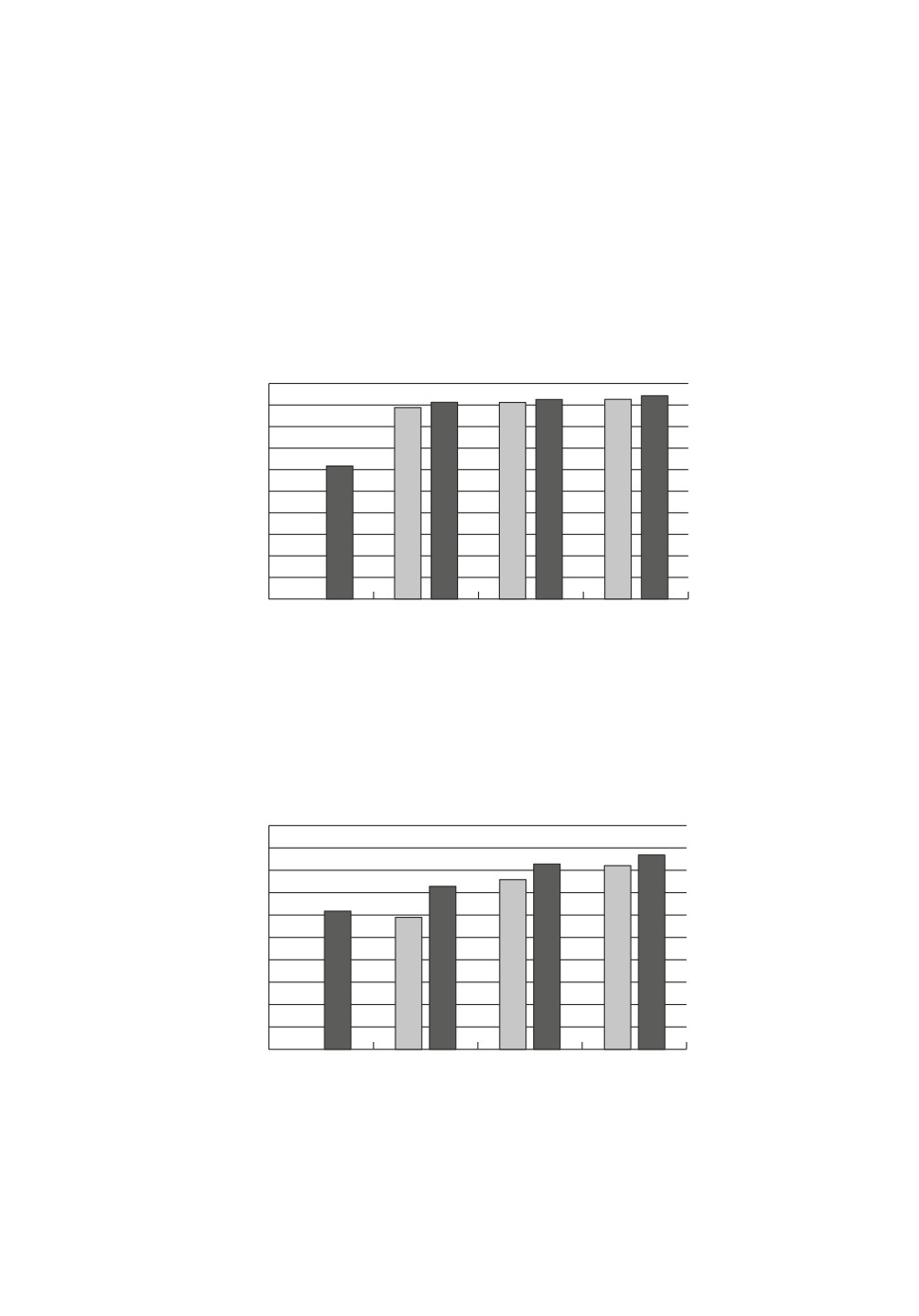
По результатам табл. 3 и 4 построим диаграммы как для контрольной ба-
зы MNIST (рис. 9), так и для обучающей базы MNIST (рис. 10). На диаграм-
мах можно видеть, что результативность нейронной сети с предварительно
вычисленными весами выше после каждой эпохи обучения по сравнению с
результативностью обученной сети, для которой начальные значения весов
генерировались случайным образов. По-видимому, это связано с тем, что у
100
90
80
70
60
50
40
30
20
10
0
Результат
Эпоха 1
Эпоха 2
Эпоха 3
до обучения
Рис. 9. Диаграмма процентов количества правильно узнанных изображений
контрольной базы MNIST (10000 изображений): светлые столбцы результа-
ты обучения нейронной сети с нуля без предварительных вычислений значе-
ний весов; темные столбцы результаты обучения нейронной сети с предва-
рительно вычисленными значениями весов.
100
90
80
70
60
50
40
30
20
10
0
Результат
Эпоха 1
Эпоха 2
Эпоха 3
до обучения
Рис. 10. Диаграмма процентов количества правильно узнанных изображений,
выполненных по обучающей выборке MNIST (60000 изображений) для двух
экспериментов: светлые столбцы результаты обучения нейронной сети с
нуля без предварительных вычислений весов; темные столбцы результаты
обучения нейронной сети с предварительно вычисленными весами.
74
2500
2000
1500
1000
500
0
Эпоха 1
Эпоха 2
Эпоха 3
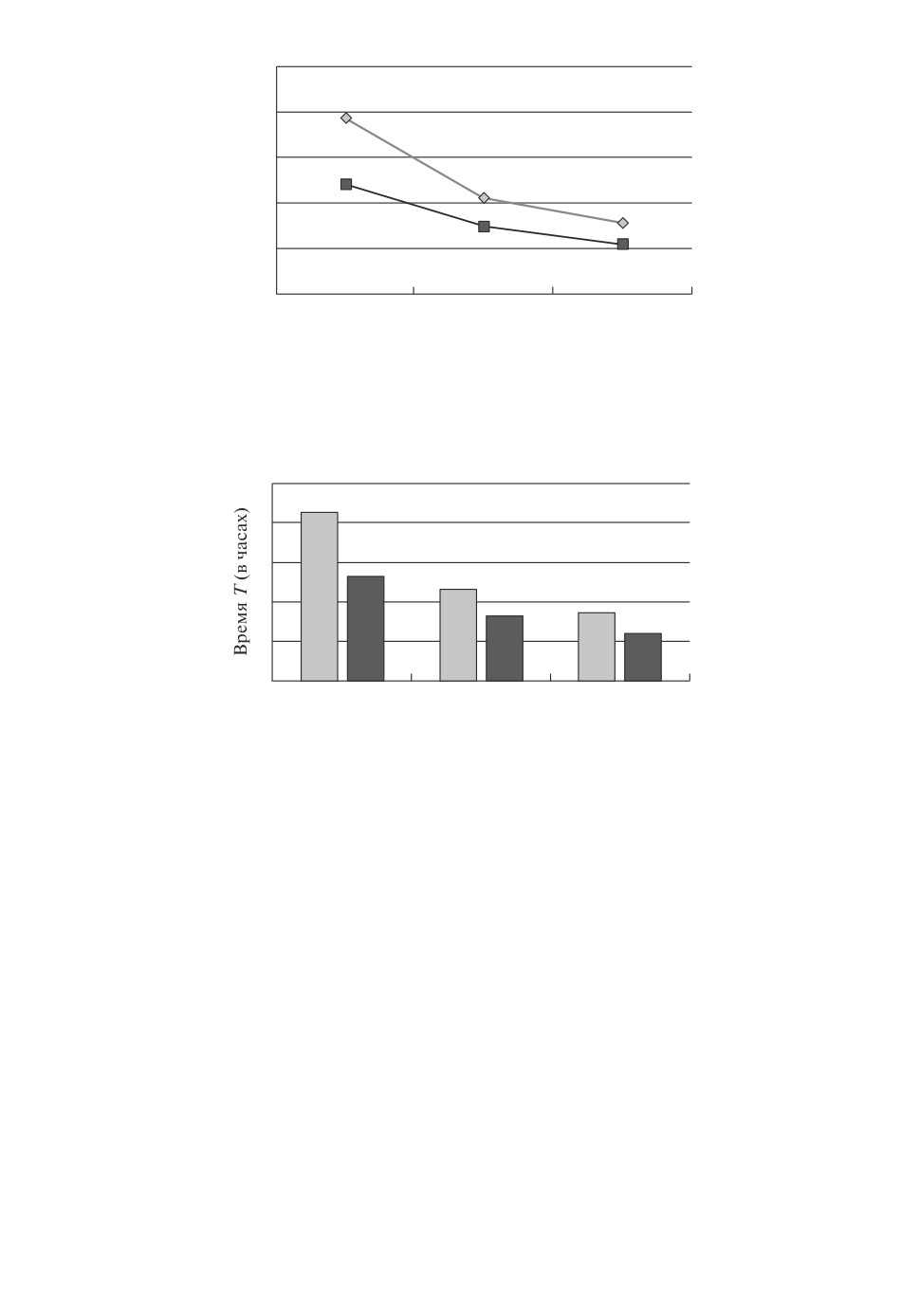
Рис. 11. Графики изменений ошибки Serr после каждой эпохи для двух экс-
периментов: светлая кривая ошибка Serr при обучении с нуля без предва-
рительных вычислений весов; темная кривая
ошибка Serr до обучении с
предварительно вычисленными весами.
5
4
3
2
1
0
Эпоха 1
Эпоха 2
Эпоха 3
Рис. 12. Диаграмма сравнения затраченного времени (в часах) на каждую эпо-
ху для двух экспериментов: светлые столбцы обучение с нуля без предвари-
тельных вычислений весов; темные столбцы до обучение с предварительно
вычисленными весами.
нейронной сети с вычисленными весовыми значениями, согласно графикам
на рис. 9 и 10, в запасе больше времени и в то же время короче путь, кото-
рый требуется для того, чтобы добраться до более лучших результатов как
по количеству правильно распознанных изображений базы MNIST, так и для
достижения более низких значений ошибок Serr (рис. 11).
Время, потраченное на обучение нейронной сети с вычисленными весо-
выми значениями, также меньше на всех эпохах по сравнению с нейронной
сетью, обучаемой с нуля (рис. 12). При этом на диаграмме (рис. 12) можно
также наблюдать, что основное преимущество по времени накапливается в
первой эпохе. В целом, на обучение нейронной сети с вычисленными весовы-
ми значениями было затрачено 329 мин = 5 ч. 29 мин, а при обучении ней-
ронной сети с нуля общее время обучения составило 499 мин = 8 ч. 19 мин,
т.е. для второго эксперимента понадобилось почти на 3 часа больше.
Отметим также, что приведенные результаты были получены при наборе
эталонов, приведенных на рис. 4, который по-видимому не является самым
75
Рис. 13. Фрагменты значений весов после третьей эпохи обучения для нейрон-
ной сети с предварительно вычисленными значениями весов: а для второго
слоя; б для третьего слоя.
лучшим ни по качеству, ни по количеству. Другими словами, при более каче-
ственном и при большем количестве эталонов результаты могли бы быть еще
более заметными. Итоговая результативность обучения может также быть
выше при использовании алгоритмов обучения [1], которые дают лучшие ре-
зультаты по сравнению с использованным в экспериментах стохастическим
алгоритмом обратного распространения ошибки.
Результаты на рис. 9-12, в целом, показывают также, что алгоритм обуче-
ния обратного распространения не уничтожает результативность нейронной
сети с предварительно вычисленными весовыми значениями, а ищет решение
еще лучше, отталкиваясь от уже существующего начального результата.
Это же подтверждают и весовые значения второго и третьего слоев, при-
веденные на рис. 13. На рис. 13 можно видеть, что изначальные значения
76
Таблица 5. Фрагмент (9 из 30) выходов второго слоя при распознавании
символа 2_1 (рис. 8) из контрольной выборки MNIST. Сеть дообучена в
трех эпохах
№ Y2 Эталоны
Sw2
F2
0
0_157
Sw2 = -2,25757884565147
F2 = 0,0946977310982947
1
0_25
Sw2 = -14,7120863080901 F2 = 4,07964075748757E - 7
2
0_28
Sw2 = -2,45988516820271
F2 = 0,0787186646034626
3
1_135
Sw2 = -16,1987387416131 F2 = 9,22522804629833E - 8
4
1_2
Sw2 = -21,1151249699638 F2 = 6,75799304608105E - 10
5
1_46
Sw2 = -14,8256166236525 F2 = 3,64180217856173E - 7
6
2_172
Sw2 = 1,78349180153865 F2 = 0,85612749736249
7
2_35
Sw2 = -0,45514766242243
F2 = 0,388137562543613
8
2_77
Sw2 = -6,77250084528418 F2 = 0,00114351889764061
9
3_32
Sw2 = -0,268545411318517
F2 = 0,433264229225887
весов единиц и нулей, а также установленных порогов второго и третьего
слоев в процессе всего обучения изменились незначительно в положитель-
ную или отрицательную сторону, сохранив при этом основную логику сети.
То же самое подтверждают и выходы второго слоя нейронной сети, например,
приведенных в табл. 5 для изображения 2_1 из контрольной базы (рис. 8).
В табл. 5 можно видеть, что активный выход второго слоя для распознава-
емого изображения 2_1 соответствует тому же выходу, который был изна-
чально установлен в схеме сети для эталона 2_172 на рис. 1,в. Другими сло-
вами, каких-либо значительных изменений в структуре и логике обученной
нейронной сети не наблюдается.
5. Заключение
На основе проведенных экспериментов и полученных результатов можно
сделать следующие заключения:
1. Время создания и вычисления всех весовых значений нейронной сети,
включая веса нулевого слоя, для формата изображений базы MNIST состав-
ляет доли секунд (для рассмотренного примера tсозд = 0,5469 с). Можно ска-
зать, что по сравнению с затратами времени на обучение сети создание ней-
ронной сети и вычисление всех весовых значений выполняется практически
мгновенно;
2. Нейроны нейронной сети на основе метрических методов распознава-
ния могут иметь и непрерывную функцию активации, например сигмоидную
функцию активации;
3. Нейронная сеть на основе метрических методов распознавания обучаема
алгоритмом обратного распространения ошибки (back propagation);
4. Процесс дообучения нейронной сети с вычисленными весами требует
меньше времени по сравнению с классическим обучением нейронной сети с
генерированием случайных значений весов. В рассмотренном примере выиг-
рыш по времени составил 2 ч. 50 мин;
77
5. Приведенный пример показал также, что результативность нейронной
сети с вычисленными весами на всех трех эпохах имеет более хороший ре-
зультат распознавания по базе MNIST. Наибольший результат распознавания
контрольной базы MNIST по результатам трех эпох обучения нейронной сети
с вычисленными весами составил 94 %;
6. На основе приведенных результатов экспериментов можно предполо-
жить, что при более качественном подборе эталонного набора, а также при
большем количестве выбранных эталонов в приведенных на рис. 9-12 диа-
граммах и графиках преимущественные отличия могут быть еще более зна-
чимыми;
7. Приведенная технология предварительного вычисления значений весов
может быть предположительно использована и в других архитектурах ней-
ронных сетей прямого распространения, например в глубоких сетях [6, 7], что
может позволить ускорить процедуру создания и обучения этих сетей.
СПИСОК ЛИТЕРАТУРЫ
1. Круглов В.В., Борисов В.В. Искусственные нейронные сети. Теория и практика.
М.: Горячая линия-Телеком, 2001.
2. Уоссермэн Ф. Нейрокомпьютерная техника. Теория и практика. М.: Мир, 1992.
3. Geidarov P.Sh. Neural Networks on the Basis of the Sample Method // Automat.
Contr. Comput. Sci. N.Y.: Alerton Press, 2009. V. 43. No. 4. P. 203-210.
4. Гейдаров П.Ш. Многозадачное применение нейронных сетей, реализующих мет-
рические методы распознавания // АиТ. 2013. № 9. С. 53-67.
Geidarov P.Sh. Multitasking Application of Neural Networks Implementing Metric
Methods of Recognition // Autom. Remote Control. 2013. V. 74. No. 9. P. 1474-1485.
5. Биргер И.А. Техническая диагностика. М.: Машиностроение, 1978.
6. LeCun Y., Bengio Y., Hinton G. Deep learning // Nature. 2015. No. 521. P. 436-444.
7. Schmidhuber J. Deep Learning in Neural Networks: An overview // Neural Networks.
2015. No. 61. P. 85-117.
8. Srivastava N. et al. A Simple Way to Prevent Neural Networks from Overfitting //
J. Mach. Learn. Res. 2014. V. 15. No. 1 P. 1929-1958.
9. Geidarov P.Sh. Clearly Defined Architectures of Neural Networks and Multilayer
Perceptron // Opt. Mem. Neural Network. 2017. V. 26. P. 62-76.
10. Гейдаров П.Ш. Алгоритм реализации метода ближайшего соседа в многослой-
ном персептроне // Тр. СПИИРАН. Вып. 51. 2017. С. 123-151.
Статья представлена к публикации членом редколлегии О.П. Кузнецовым.
Поступила в редакцию 03.12.2018
После доработки 24.10.2019
Принята к публикации 28.11.2019
78