Автоматика и телемеханика, № 7, 2020
© 2020 г. Ю.П. ЕМЕЛЬЯНОВА, канд. физ.-мат. наук (emelianovajulia@gmail.com)
(Арзамасский политехнический институт (филиал)
Нижегородского государственного технического
университета им. Р.Е. Алексеева)
УПРАВЛЕНИЕ С ИТЕРАТИВНЫМ ОБУЧЕНИЕМ
НЕОПРЕДЕЛЕННОЙ СИСТЕМОЙ С НЕПРЕРЫВНЫМ ВРЕМЕНЕМ
НА ОСНОВЕ НАБЛЮДАТЕЛЯ СОСТОЯНИЯ1
Рассматриваются линейные системы с аффинной моделью параметри-
ческой неопределенности, функционирующие в повторяющемся режиме.
Для таких систем предлагается новый метод синтеза управления с итера-
тивным обучением. Этот метод основан на использовании наблюдателя
состояния полного порядка и вспомогательной 2D-модели в форме диф-
ференциального повторяющегося процесса, устойчивость которой гаран-
тирует сходимость процесса обучения. Для получения условий устойчи-
вости используется дивергентный метод векторных функций Ляпунова.
Приведен пример, демонстрирующий особенности и преимущества нового
метода.
Ключевые слова: управление с итеративным обучением, наблюдатель,
2D-системы, устойчивость, векторная функция Ляпунова, дифференци-
альные повторяющиеся процессы.
DOI: 10.31857/S0005231020070053
1. Введение
Управление с обратной связью является наиболее эффективным спосо-
бом достижения таких свойств системы, как устойчивость, робастность, оп-
тимальность в смысле заданного критерия и т.п. На практике существует
много систем, которые функционируют в повторяющемся режиме с одной
и той же продолжительностью каждого повторения, в течение которого си-
стемы должны отслеживать заданный сигнал с требуемой точностью. При
использовании обратной связи ошибка слежения будет одинаковой независи-
мо от количества повторений (итераций). Это обстоятельство заставило ис-
кать новые решения, которые обеспечили бы уменьшение ошибки слежения
с увеличением числа повторений.
Таким решением является управление с итеративным обучением, которое
организовано таким образом, чтобы последовательно уменьшать ошибку сле-
жения (обучения) в повторяющихся операциях. Задача управления с итера-
тивным обучением состоит в том, чтобы найти соответствующий управляю-
щий сигнал, который заставляет выходную переменную следить за желаемой
1 Работа выполнена при поддержке Российского научного фонда (грант № 18-79-00088).
79
траекторией, определенной на конечном интервале времени, за счет итератив-
ного уточнения этого сигнала. Такой тип управления использует информа-
цию об ошибке, информацию с предыдущих повторений, а также некоторую
предварительную информацию о системе, чтобы получить такой входной сиг-
нал, который обеспечит сходимость ошибки обучения к нулю по мере увели-
чения числа повторений. В отличие от адаптивного управления параметры
системы здесь остаются неизменными.
Обзорные публикации [1, 2] могут служить отправной точкой. Управление
с итеративным обучением успешно используется в огромном числе приложе-
ний от медицинских роботов для реабилитации после инсульта [3, 4] и для
поддержки желудочка сердца [5] до лазерного напыления металла [6], мор-
ских систем [7] и производственных систем [8].
Начиная с пионерской публикации [9] отмечено, что управление с итера-
тивным обучением адекватно моделируется двумерной (2D) системой. Дей-
ствительно, с одной стороны, управление с итеративным обучением застав-
ляет систему многократно выполнять одну и ту же команду на конечном
интервале времени. С другой стороны, управление с итеративным обучением
исправляет команду от повторения к повторению, чтобы уменьшить ошибку
обучения. Таким образом, в качестве двух независимых переменных высту-
пают шаг по оси времени и номер повторения по оси итераций.
Наиболее распространенными двумерными (2D) моделями управления с
итеративным обучением являются повторяющиеся процессы. Сведения об
этих процессах, включая теорию устойчивости в рамках линейной динамики
с использованием моделей в банаховом пространстве, можно найти в [10] и в
источниках из приведенной там библиографии. Теории устойчивости и дис-
сипативности повторяющихся процессов, основанные на векторных функци-
ях Ляпунова и векторных функциях накопления, были разработаны в [11] и
в предшествующих публикациях тех же авторов, приведенных в списке ли-
тературы. Основная особенность этих результатов заключается в том, что
для получения условий устойчивости вместо полной производной или пол-
ного приращения скалярной функции Ляпунова используется дивергенция
векторной функции или ее дискретный аналог.
Как правило, в алгоритмах управления с итеративным обучением не ис-
пользуются ни переменные состояния системы, ни их оценки. В то же время
ясно, что использование этих переменных может гарантировать более высо-
кое качество управления в смысле увеличения скорости сходимости процесса
обучения и в смысле достижения более высокой точности. В частности, это
демонстрирует публикация [12], в которой результаты были подтверждены
экспериментом. Алгоритмы управления с итеративным обучением с оценками
состояния, полученными наблюдателем полного порядка, были предложены
в [13-15], где рассматривались детерминированные системы с измеряемым
выходом.
В недавней работе автора [14] получен алгоритм управления с итератив-
ным обучением, использующий информацию о выходной переменной и оцен-
ках состояния на текущем и предыдущем повторениях для случая, когда па-
80
раметры системы точно известны. Данная статья развивает эти результаты
на случай систем с неопределенными параметрами.
В [14] были отмечены трудности подхода в рамках дифференциальных
моделей - конечные результаты выражаются через решение модифицирован-
ного неравенства Риккати, которое в известных публикациях не изучалось,
и для нахождения его решения пока можно предложить лишь эвристиче-
ские итерационные методы. В то же время для систем с неопределенными
параметрами использование дифференциальных моделей предпочтительно,
поскольку в этом случае неопределенности учитываются проще и нагляднее.
Попытки преодолеть эти трудности привели к разработке нового подхода,
позволяющего в случае систем с постоянными параметрами свести задачу к
решению линейного матричного неравенства вместо упомянутого сложного
неравенства типа Риккати. В случае систем с неопределенными параметра-
ми задача сводится к решению системы линейных матричных неравенств.
Таким образом, указанное затруднение удается обойти не только для случая,
изучаемого в [14], но и для более общего случая.
В данной статье рассматриваются линейные системы с непрерывным вре-
менем с аффинной моделью параметрической неопределенности. На основе
предложенного нового подхода решается задача синтеза управления с ите-
ративным обучением в предположении, что непосредственному измерению
доступен только вектор выхода. Закон управления формируется на основе
этого вектора и оценок вектора состояния номинальной модели. Выбор пара-
метров закона управления, обеспечивающих сходимость процесса обучения,
осуществляется на основе условий устойчивости вспомогательной 2D-модели
в форме дифференциального повторяющегося процесса, которые выводятся
на основе дивергентного метода векторных функций Ляпунова [11] и выра-
жаются в виде системы линейных матричных неравенств. Приведен пример,
демонстрирующий эффективность и преимущества нового метода.
2. Синтез управления с итеративным обучением
дифференциальными повторяющимися процессами
2.1. Постановка задачи
Рассмотрим линейную систему с неопределенными параметрами, которая
функционирует в повторяющемся режиме и описывается на k-м повторении
моделью в пространстве состояний
xk(t) = A(δ(t))xk(t) + B(δ(t))uk(t),
(1)
yk(t) = Cxk
(t), t ∈ [0, T ], k = 0, 1, . . . ,
где xk(t) ∈ Rnx
вектор состояния, uk(t) ∈ Rnu
вектор управления и
yk(t) ∈ Rny
вектор выходных переменных, называемый профилем повто-
рения, k номер повторения, T продолжительность повторения. Модель
неопределенности задается в форме
∑
∑
(2)
A(δ(t)) = A + δj (t)Aj , B(δ(t)) = B +
δj(t)Bj,
j=1
j=1
81
где A и B - матрицы номинальной модели, Aj и Bj (j = 1, 2, . . . , l) посто-
янные матрицы соответствующих размеров и δj (t) ∈ [δj, δj]. Далее повсюду
для компактности записи зависимость δ от t не указывается.
Обозначим
{
}
D = δ = [δ1 ...δl]T, δj ∈ [δj, δj] ,
{
}
Dv = δ = [δ1 ... δl]T, δj ∈ {δj, δj} ,
где Dv конечное множество из 2l элементов.
Пусть yref (t), 0 ≤ t ≤ T , заданная желаемая траектория. Тогда
(3)
ek(t) = yref(t) - yk
(t)
является ошибкой обучения на повторении k. Задача состоит в нахождении
такой последовательности управлений uk(t), k = 0, 1, . . . , которая обеспечи-
вает достижение заданной точности воспроизведения профиля за конечное
число повторений kfin и сохранение этой точности при дальнейших повторе-
ниях, т.е.
(4)
||ek(t)|| ≤ e∗, k ≥ kfin
,
0≤t≤T.
Величина kfin определяется требуемой точностью, и всегда желательно,
чтобы эта величина была как можно меньше. Прямой метод выбора этой ве-
личины неизвестен, и здесь прослеживается полная аналогия с достижением
требуемого времени переходного процесса в классических задачах управле-
ния.
Поставленная задача будет решена, если указанная последовательность
uk(t) удовлетворяет условиям
(5)
lim
||ek(t)|| = 0,
lim
||uk(t) - u∞
(t)|| = 0,
k→∞
k→∞
где u∞(p) ограниченная переменная, обычно называемая обученным управ-
лением.
Закон управления с итеративным обучением на текущем повторении фор-
мируется в виде
(6)
uk+1(t) = uk(t) + Δuk+1
(t),
где Δuk+1(t) корректирующая поправка, которая должна быть синтезиро-
вана так, чтобы обеспечить условия сходимости (5).
Выбор закона управления с обратной связью по текущему повторению
дает одинаковую ошибку на каждом повторении. Закон управления с ите-
ративным обучением должен изменять входной сигнал на основе состояния
на текущем повторении (xk+1(t)) и упреждающих значений выходной пере-
менной на предыдущем повторении (yk(t)). В данной статье предполагается,
что вектор состояния недоступен для измерения и вместо него используется
оценка.
82
Для построения оценки вектора состояния очевидным подходом являет-
ся использование наблюдателя полного порядка; некоторые результаты по
оценке вектора состояния при управлении с итеративным обучением для си-
стем с известными параметрами были опубликованы в [13-15] для систем с
известными параметрами. В [14] наблюдатель состояния используется в со-
четании с подходом на основе диссипативности 2D-моделей и дивергентного
метода векторных функций Ляпунова. Конечные результаты представлены
в виде линейных матричных неравенств. В [13], наблюдатель состояния ис-
пользовался в сочетании с синтезом управления с итеративным обучением
на основе линейных матричных неравенств в конечных частотных областях.
В [15] коэффициент усиления хорошо известного закона управления с итера-
тивным обучением P -типа обновлялся на каждом повторении путем решения
соответствующего дискретного уравнения Риккати. Данная статья развивает
результаты [14] на случай систем с неопределенными параметрами.
Зададим наблюдатель состояния для системы (1) в виде модели в про-
странстве состояний с номинальными параметрами
dxk(t)
(7)
= Axk(t) + Buk(t) + F[yk(t) - Cxk
(t)],
dt
где xk(t)
оценка вектора состояния на повторении k; F
матрица уси-
ления наблюдателя; и, как обычно, xk(t) = xk(t) - xk(t) обозначает ошибку
оценивания.
Потребуем, чтобы для начального состояния наблюдателя выполнялось
соотношение
(8)
ŷk(0) = C xk(0) = yref(0).
2.2. Дифференциальная 2D-модель
Для управления с итеративным обучением синтезу подлежит корректи-
рующая поправка Δuk+1(p), которая синтезируется как обычное управление с
обратной связью для вводимой далее в рассмотрение вспомогательной систе-
мы относительно приращений переменных приращения оценки и ошибки
оценивания:
ξk+1(t) = xk+1(t) - xk(t),
ξk+1(t) = xk+1(t) - xk(t).
В терминах этих переменных динамика системы (1) с наблюдателем (7)
может быть описана уравнениями
ξk+1(t)
=
ξk+1(t) + F
ξk+1(t) + Bvk+1(t),
dt
(9)
dξ
k+1(t)
=Aa(δ
ξk+1(t) + (A(δ) - FC
ξk+1(t) + Ba(δ)vk+1(t),
dt
83
где
∑
∑
Aa(δ) =
δjAj, Ba(δ) =
δjBj, vk+1(t) = Δuk+1(t).
j=1
j=1
Динамику процесса изменения ошибки относительно переменной k можно
описать только с использованием производной от ошибки, которая в рассмат-
риваемом случае недоступна измерению. В связи с этим будем использовать
оценку производной ошибки
ėk(t) = yref(t) - Cˆxk(t).
Обозначим εk(t) =ˆė(t). С учетом (9) изменение оценки ошибки обуче-
ния (3) в зависимости от числа повторений k опишется уравнением
(10)
εk+1(t) = εk(t) - CA(δ
ξk+1(t) - CFC(δ
ξk+1(t) - CB(δ)vk+1
(t).
[
]T
Обозначим ηk+1(t) =
ξk+1(t)T
ξk+1(t)T и запишем (9), (10) в стандарт-
ной форме дифференциального повторяющегося процесса
ηk+1(t) = A11(δ)ηk+1(t) + A12εk(t) + B1(δ)vk+1(t),
(11)
εk+1(t) = A21ηk+1(t) + A22εk(t) + B2vk+1(t),
где
[
]
A
FC
A11(δ) =
,
A12 = 0,
Aa(δ) A(δ) - FC
[
]
A21 =
-CA -CFC
,
A22 = I,
[
]
B
B1(δ) =
,
B2 = -CB.
Ba(δ)
Выберем корректирующую поправку в виде
(12)
Δuk+1(t) = K1
ξk+1(t) + K2εk(t),
и тогда (9), (10) с учетом (12) запишется уравнениями
ξk+1(t)
= (A + BK1
ξk+1(t) + F
ξk+1(t) + BK2εk(t),
dt
ξk+1(t)
(13)
= (Aa(δ) + Ba(δ)K1
ξk+1(t) + (A(δ) - FC
ξk+1(t) +
dt
+ Ba(δ)K2εk(t),
εk+1(t) = -C(A + BK1
ξk+1(t) - CF
ξk+1(t) + (I - CBK2)εk(t),
84
которые в более компактной форме имеют вид
ηk+1(t) = Ac11(δ)ηk+1(t) + Ac12εk(t),
(14)
εk+1(t) = Ac21ηk+1(t) + Ac22εk(t),
где
[
]
[
]
A+BK1
FC
BK2
Ac11(δ) =
,
Ac12 =
,
(Aa(δ) + Ba(δ)K1) A(δ) - F C
Ba(δ)K2
[
]
Ac21 =
-C(A + BK1) -CFC
,
Ac22 = I - CBK2.
2.3. Решение на основе дивергентного метода
векторных функций Ляпунова
Закон управления с итеративным обучением (12) должен обеспечивать
условия сходимости (5). Чтобы найти матрицы K1 и K2, гарантирующие это
свойство, воспользуемся методом векторных функций Ляпунова для диффе-
ренциальных повторяющихся процессов [11].
Определение. Дифференциальный повторяющийся процесс (14) назы-
вается экспоненциально устойчивым, если существуют действительные
числа κ > 0, λ > 0 и 0 < ζ < 1 такие, что
(15)
∥ηk(t)∥2 + ∥εk(t)∥2 ≤ κe-λtζk,
где κ, ζ и λ не зависят от продолжительности повторения T .
Рассмотрим векторную функцию Ляпунова вида
[
]
V1(ηk(t))
(16)
V (ηk(t), ek(t)) =
,
V2(εk(t))
где
V1(η) > 0, η = 0, V2(ε) > 0, e = 0, V1(0) = 0, V2(0) = 0.
Аналог оператора дивергенции, который будем называть далее дивергенцией,
для этой функции вдоль траекторий системы (13) задается в виде
dV1(ηk(t))
(17)
DcV (ηk(t),εk(t)) =
+ ΔkV2(εk
(t)),
dt
где
ΔkV2(εk(t)) = V2(εk+1(t)) - V2(εk(t)).
Следующая теорема дает достаточные условия экспоненциальной устойчиво-
сти.
85
Теорема
[11]. Дифференциальный повторяющийся процесс (14) экспо-
ненциально устойчив, если существуют векторная функция Ляпунова (16)
и положительные скаляры c1,c2 и c3, такие что
c1∥ηk(t)∥2 ≤ V1(ηk(t)) ≤ c2∥ηk(t)∥2,
c1∥εk(t)∥2 ≤ V2(εk(t)) ≤ c2∥εk(t)∥2,
DcV (ηk(t),εk(t)) ≤ -c3(∥ηk(t)∥|2 + ∥εk(t)∥2),
∂V1(ηk(t))
−c4∥ηk(t)∥.
≤
∂η
Если система (14) экспоненциально устойчива, то εk(t) → 0 при k → ∞.
Тогда поскольку выполняется (8), то êk(t) → 0 при k → ∞, и если при этом
ek = êk + ek будет удовлетворять заданным требованиям точности, то постав-
ленная задача будет решена.
Для дальнейшего анализа введем обозначения:
[
]
[
]
A11(δ) A12
Ac11(δ) Ac12
A(δ) =
,
Ac(δ) =
,
A21
A22
Ac21
Ac22
Acij(δ) = Aij(δ) + Bi(δ)Kj, i,j = 1,2,
[
]
[
]
[
]
I
0
0
0
B1(δ)
I(1,0) =
,
I(0,1) =
,
B(δ) =
0
0
0
I
B2
Пусть матрицы P = diag[P1 P2] и K = [K1 K2] удовлетворяют билинейно-
му матричному неравенству
ATc(δ)I(1,0)P + PI(1,0)A¯c(δ)
ATc(δ)I(0,1)
Ac(δ) - I(0,1)P +
(18)
+ Q + KTRK ≼ 0, δ ∈ D,
где Q = diag[Q1 Q2] ≻ 0 и R ≻ 0 весовые матрицы, которыеподлежат вы-
бору. Они аналогичны весовым матрицам в теории линейно-квадратичного
регулятора, и их выбор осуществляется на основе результатов этой теории.
Поскольку
ξ недоступна, то для дальнейшего анализа матрицы
Ac11(δ),Ac21 необходимо представить в виде
Ac11(δ) = A11 + B1(δ)K1C0,
(19)
Ac21 = A21 + B2K1C0,
где
C0 = [I 0] .
Выберем компоненты векторной функции Ляпунова (16) в виде квадра-
тичных форм V1(ηk(t)) = ηTk(t)P1ηk(t), V2(εk(t)) = εTk(t)P2εk(t), где P1 ≻ 0 и
86
P2 ≻ 0. Тогда, вычисляя DcV , получим, что при выполнении неравенства (18)
DcV ≤ -Q - KTRK и все условия теоремы оказываются выполненными, что
гарантирует экспоненциальную устойчивость (11). Используя формулу до-
полнения Шура, учитывая (19) и вводя вспомогательную переменную Z1
как решение уравнения C0X1 = Z1C0, сведем (18) к линейному матрично-
му неравенству относительно X = diag[X1 X2], где X1 = P-11 и X2 = P-12 и
Y1 = K1Z1, Y2 = K2X2:
(A11(δ)X1 + B1(δ)(Y1C0)) + (A11(δ)X1 + B1(δ)(Y1C0))T (A12X2 + B1(δ)Y2)
(A12X2 + B1(δ)Y2)T
-X2
0
0
(A21X1 + B2(Y1C0))
(A22X2 + B2Y2)
X1
0
0
X2
(Y1C0)
Y2
0
(A21X1 + B2(Y1C0))T X1
0
(Y1C0)T
0
(A22X2 + B2Y2)T
0
X2
YT2
−X1
0
0
0
0
(20)
0
-X2
0
0
0
≼ 0, δ ∈ D,
0
0
-Q-11
0
0
0
0
0
-Q-12
0
0
0
0
0
-R-1
C0X1 = Z1C0, X1 ≻ 0, X2 ≻ 0.
Поскольку (20) линейное неравенство и зависимость от δ аффинная,
то (20) будет выполняться для всех δ ∈ D тогда и только тогда, когда оно
выполняется для δ ∈ Dv.
Таким образом, если неравенство (20) разрешимо для δ ∈ Dv, то K =
= [K1C0 K2], K2 = Y2X-12 и поскольку матрица C0 имеет ранг, совпадаю-
щий с рангом единичной матрицы ее первого блока, то матрица Z1 будет
невырожденной и K1 = Y1Z-11.
Замечание. При практическом нахождении матрицы K целесообразно
вместо линейного матричного неравенства (20) решать задачу максимиза-
ции следа матрицы X при ограничениях в виде этого линейного матричного
неравенства. Это позволит ускорить процесс нахождения решения.
3. Пример
Рассмотрим модель однозвенного гибкого манипулятора [16], функциони-
рующего в повторяющемся режиме с постоянным периодом повторения. Ди-
намика движения манипулятора в пространстве состояний описывается урав-
87
[
]T
θ
нениями (1), где x =
θ α
α
, θ
угол поворота сервопривода, α
угол отклонения гибкого звена,
0
0
1
0
0
0
0
1
Ks
Beq
A=
0
-
0
,
Jeq
Jeq
Ks(Jl + Jeq) Beq
0
-
0
JlJeq
Jeq
0
0
1
B=
,
C = [1
0
0
0] ,
Jeq
1
-
Jeq
Beq коэффициент вязкого трения сервопривода, Ks жесткость гибкого
звена, Jl
момент инерции гибкого звена относительно центра масс, Jeq
момент инерции сервопривода. Движение гибкого звена происходит в гори-
зонтальной плоскости.
Задача состоит в том, чтобы найти алгоритм управления с итеративным
обучением, при котором выходная переменная y(t) воспроизводила бы же-
лаемую траекторию yref (t) с заданной точностью e∗. Непосредственному из-
мерению доступен только угол θ.
Для расчетов и моделирования были приняты следующие значения пара-
метров из [16]: Beq = 0,004 Н·м/(рад/с), Ks = 1,3 Н·м/рад, Jl = 0,038 кг·м2,
Jeq = 2,08 · 10-3 кг·м2. Продолжительность цикла повторения 3 c, требуемая
точность e∗ = 0,005 рад. При вычислениях использовался метод Эйлера с ша-
гом Ts = 0,001 c.
Желаемая траектория движения звена представлена на рис. 1 и описыва-
ется уравнением
2
πt
πt3
yref(t) =
-
,
t ∈ [0,T].
6
27
В данном примере CB = 0, а разработанная теория предполагает, чтобы
CB = 0. С целью обойти это затруднение воспользуемся тем, что для данной
системы
yk = C xk = C1xk,
где C1 = [0
0
1
0] .
Поскольку непосредственно измеряется только угол, то вместо производ-
ной можно использовать лишь ее оценкуˆyk = C1xk, где xk определяется на-
блюдателем (7). В этом случае динамику процесса изменения ошибки относи-
тельно переменной k можно описать только с использованием оценки второй
88
Желаемый угол поворота сервопривода (qref)
1,6
1,4
1,2
1,0
0,8
0,6
0,4
0,2
0
500
1000
1500
2000
2500
3000
Время t, мс
Рис. 1. Желаемая траектория.
производной
ëk = ÿref - C1
xk.
Обозначим ǫk =ëk, и тогда ошибка обучения опишется уравнением
(21)
ǫk+1 = ǫk - C1
ξk+1 - C1F
ξk+1 - C1BΔuk+1.
Динамика системы с учетом наблюдателя теперь будет описываться урав-
нениями
ηk+1(t) = A11(δ)ηk+1(t) + A12ǫk(t) + B1vk+1(t),
(22)
ǫk+1(t) = A21ηk+1(t) + A22ǫk(t) + B2vk+1(t),
где
[
]
A
FC
[
]
A11(δ) =
,
A12 = 0, A21 =
-C1A -C1FC
,
Aa(δ) A(δ) - FC
[
]
B
A22 = I, B1 =
,
B2 = -C1B.
0
Начальные условия для наблюдателя в дополнение к (8) должны удовле-
творять условию
yk(0) = Cˆxk(0) = yref(0).
Выберем корректирующую поправку в виде
Δuk+1 = K1
ξk+1 + K2ǫk.
89
1,0
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
1
2
3
4
5
6
7
8
9
10
k
Рис. 2. Cреднеквадратическая ошибка обучения при различных разбросах
неопределенных параметров Jl и Ks.
Тогда закон управления с итеративным обучением будет иметь вид
uk+1 = uk + Δuk+1 = uk + K1(xk+1 - xk) + K2(ÿref - C1xk) =
(23)
= uk + K1(xk+1 - xk) + K2(ÿref - C1Axk - C1Buk - C1F(yk - Cxk)).
Чтобы оценить эффективность этого закона управления с итеративным
обучением, для каждого повторения k введем среднеквадратическое откло-
нение ошибки обучения
v
u
u
∫
T
u
1
(24)
E(k) =
√
|ek(t)|2
dt.
T
0
Предположим, что момент инерции гибкого звена может принимать значе-
ния от Jl + ΔJl до Jl + ΔJl, что с физической точки зрения может означать
наличие или отсутствие груза на гибком звене или наличие различных гру-
зов. Также добавим неопределенность по жесткости Ks, полагая, что жест-
кость может принимать значения от Ks + ΔKs до Ks + ΔKs. В этом случае
матрица параметров A(δ) будет иметь вид
A(δ) = A + Aa(δ), Aa(δ) = δA, δ = {δ1; δ2} ,
δ1 = [Jl;Jl], δ2 = [Ks;Ks].
Параметры фильтра выберем с помощью стандартной функции lqr
пакета MATLAB из условия, что вещественные части собственных значений
матрицы (A - F C) меньше -0,15. Этому условию удовлетворяет матрица
F = [0,1881
- 0,0026 0,0127
- 0,0055]. Решая задачу максимизации tr[X]
при ограничениях в виде неравенства (20), с учетом очевидных изменений
90
Ошибка по углу q
2,0
1,5
1,0
0,5
0
10
3000
5
2000
1000
0
Рис. 3. Изменение ошибки обучения в зависимости от числа повторений.
Угол поворота сервопривода q
2,0
1,5
1,0
0,5
0
10
3000
5
2000
1000
0
Рис. 4. Изменение выходной переменной в зависимости от числа повторений.
матриц A11(δ), A12, A21, A22, B1(δ), B2, и задавая
ΔJl = 0,3Jl, ΔJl = -0,3Jl, ΔKs = 0,1Ks, ΔKs = -0,1Ks,
Q = diag[Q1 Q2], Q1 = 10-2I, Q2 = 10-3I,R = 1,
получим
K1 = [-0,0000
- 1,2385
0,0019
- 0,0004], K2 = 0,0020.
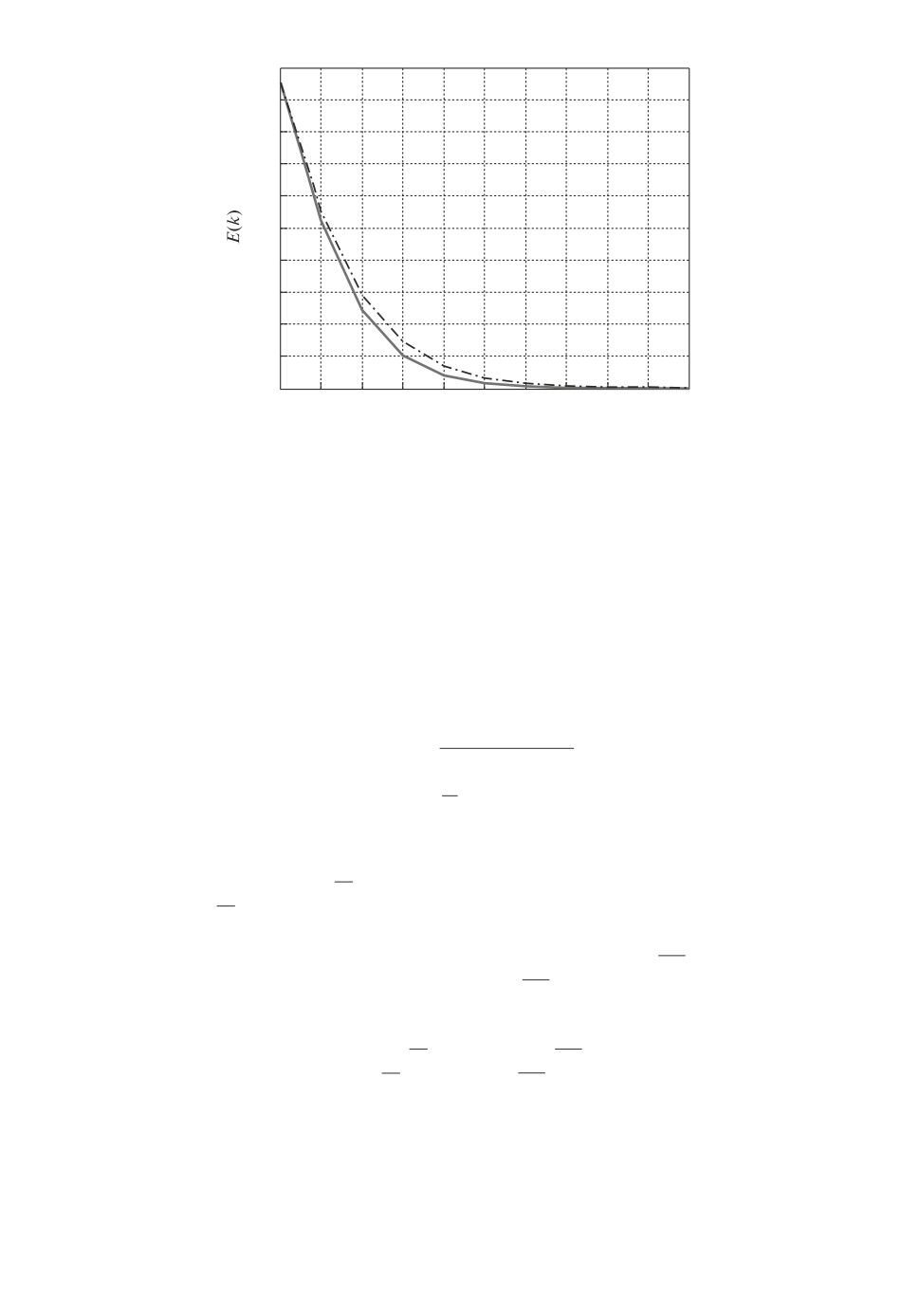
На рис. 2 представлен график изменения среднеквадратической ошибки
обучения (24) в зависимости от числа повторений k при указанном разбро-
се параметров Jl и Ks (штрихпунктирная линия). При меньшем разбросе
этих параметров ΔJl = 0,1Jl, ΔJl = -0,1Jl, ΔKs = 0,005Ks, ΔKs = -0,005Ks
91
Управление и
0,10
0,05
0
-0,05
-0,10
10
3000
5
2000
1000
0
Рис. 5. Изменение управления в зависимости от числа повторений.
1,0
0,9
0,8
0,7
0,6
0,5
0,4
0,3
0,2
0,1
0
1
2
3
4
5
6
7
8
9
10
k
Рис. 6. Cреднеквадратическая ошибка обучения в случае сочетания неопреде-
ленных параметров Jl и Ks на верхней границе (штрихпунктирная линия) и
на нижней границе.
ошибка сходится к нулю быстрее (сплошная линия). Требуемая точность
e∗ = 0,005 рад достигается за 8 повторений (kfin = 8, E(8) = 0,003454 рад ≈
≈ 0,2◦). При большем разбросе неопределенных параметров система может не
только не достичь требуемой точности, но и не стабилизироваться, это вполне
объяснимо энергии управления не хватает для компенсации неопределен-
ности.
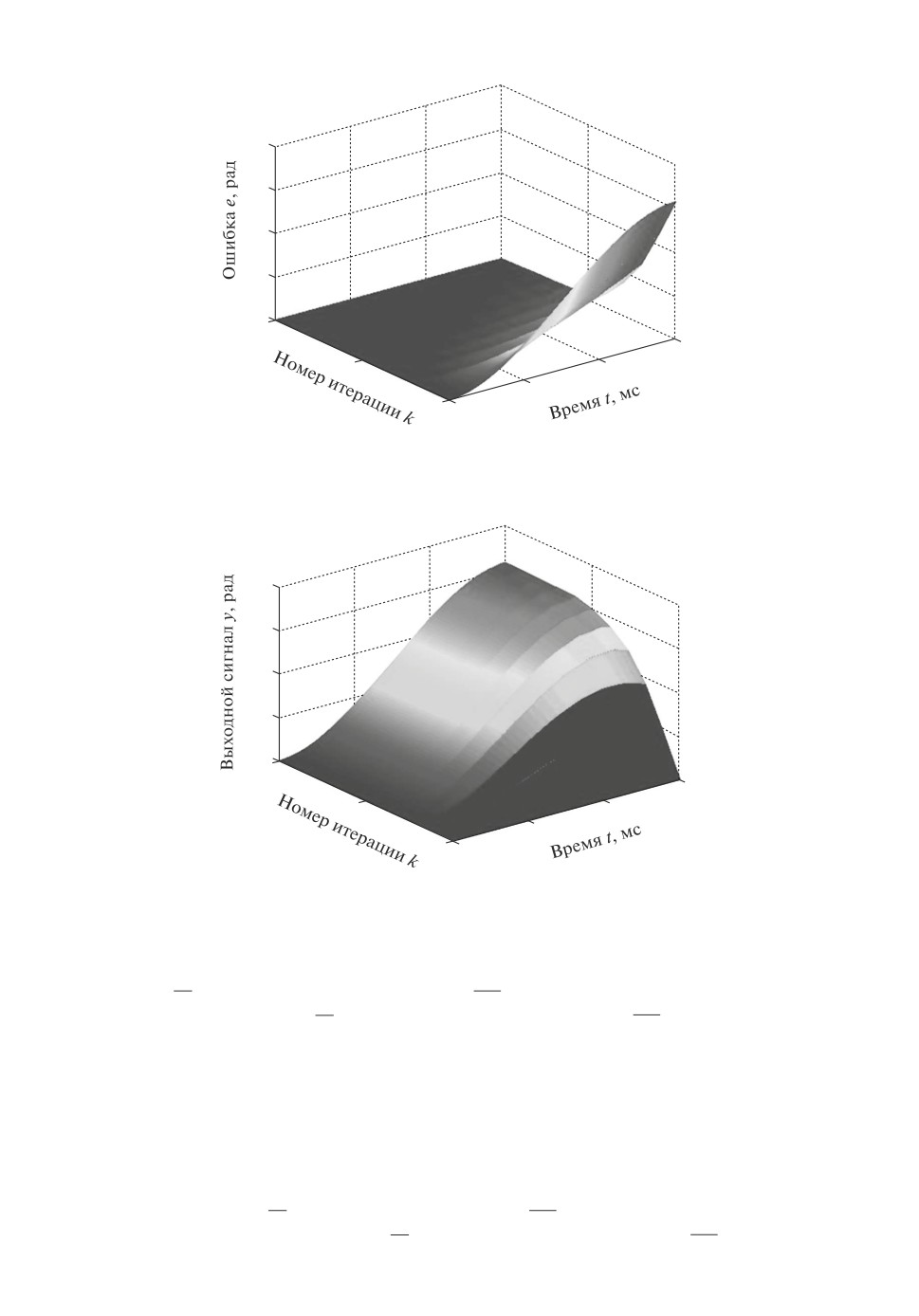
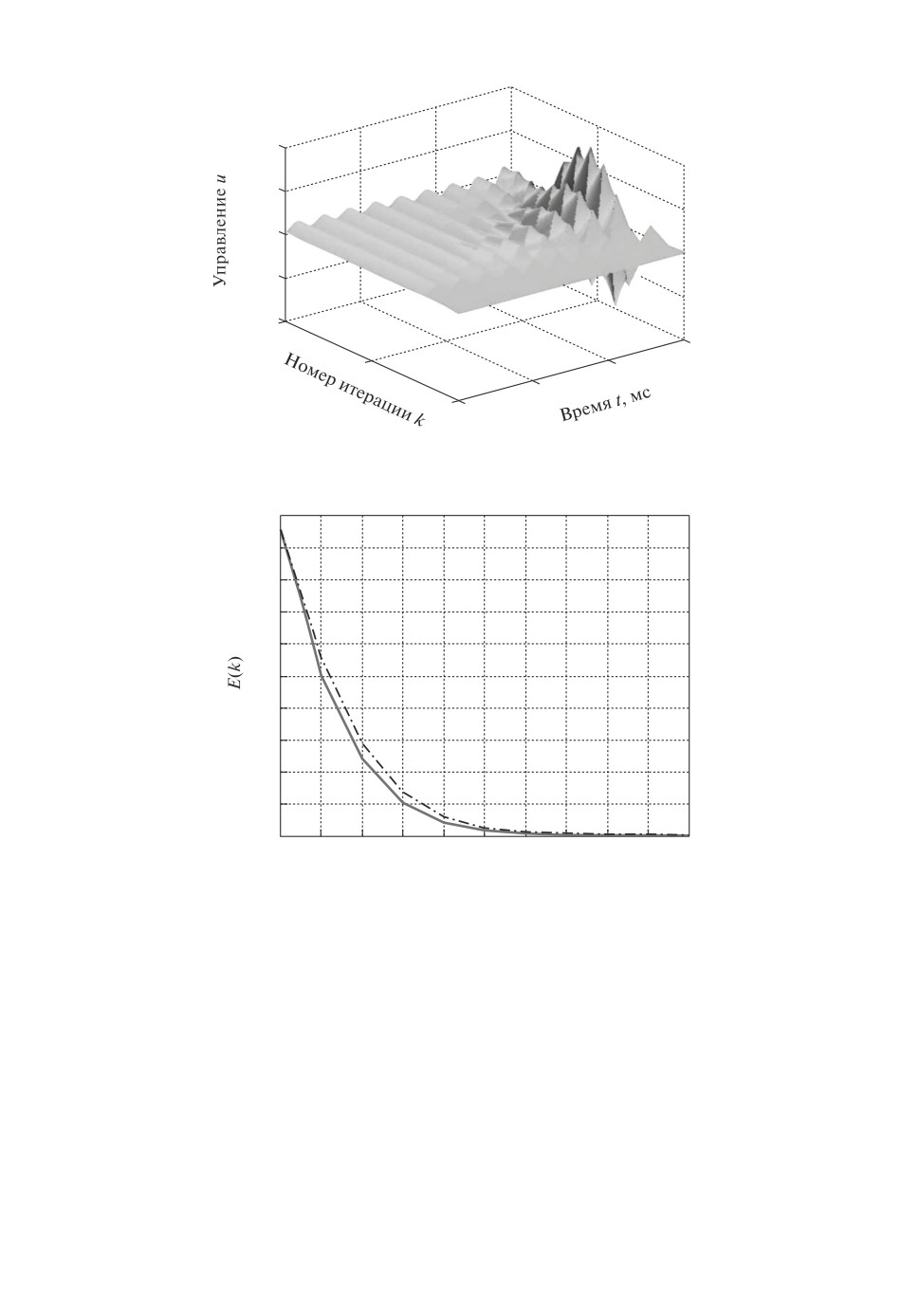
На рис. 3-5 представлены изменения ошибки, выходной переменной и
управления в зависимости от времени на текущем повторении и числа по-
вторений.
92
На рис. 6 представлен случай, когда оба неопределенных параметра Jl и Ks
находятся на верхней границе, а именно ΔJl = 0,3Jl, ΔKs = 0,1Ks (штрих-
пунктирная линия), или на нижней границе ΔJl = -0,3Jl, ΔKs = -0,1Ks
(сплошная линия).
4. Заключение
В данной статье разработан метод синтеза управления с итеративным обу-
чением с использованием наблюдателя состояния для случая дифференци-
альных повторяющихся процессов, когда модель объекта управления содер-
жит аффинные неопределенности. Результаты решения данной задачи поз-
воляют повысить скорость сходимости процессов управления с итеративным
обучением и обеспечить робастность этих процессов по отношению к различ-
ным неопределенностям, неизбежно возникающим при функционировании
реальных систем. Значительный интерес представляет исследование влия-
ния динамики наблюдателя на ошибку обучения. Эта задача пока остается
открытой. Сочетание управления с итеративным обучением и управления с
обратной связью также представляет интересную задачу для дальнейших ис-
следований.
СПИСОК ЛИТЕРАТУРЫ
1.
Bristow D.A., Tharayil M., Alleyne A.G. A Survey of Iterative Learning Control:
A Learning-Based Method for High-Performance Tracking Control // IEEE Control
Syst. Magaz. 2006. V. 26. No. 3. P. 96-114.
2.
Ahn H-S., Chen Y.Q., Moore K.L. Iterative Learning Control: Survey and Catego-
rization // IEEE Trans. Syst. Man Cybern. Part C: Appl. Rev. 2007. V. 37. No. 6.
P. 1099-1121.
3.
Freeman C.T., Rogers E., Hughes A.-M., Burridge J.H., Meadmore K.L. Iterative
Learning Control in Health Care: Electrical Stimulation and Robotic-Assisted Upper-
Limb Stroke Rehabilitation // IEEE Control Syst. Magaz. 2012. V. 47. P. 70-80.
4.
Meadmore K.L., Exell T.A., Hallewell E., Hughes A.-M., Freeman C.T., Kutlu M.,
Benson V., Rogers E., Burridge J.H. The Application of Precisely Controlled Func-
tional Electrical Stimulation to the Shoulder, Elbow and Wrist for Upper Limb
Stroke Rehabilitation: a Feasibility Study // J. NeuroEngineer. Rehabilitation. 2014.
P. 11-105.
5.
Ketelhut M., Stemmler S., Gesenhues J., Hein M., Abel D. Iterative Learning Control
of Ventricular Assist Devices with Variable Cycle Durations // Control Engin. Pract.
2019. V. 83. P. 33-44.
6.
Sammons P.M., Gegel M.L., Bristow D.A., Landers R.G. Repetitive Process Control
of Additive Manufacturing with Application to Laser Metal Deposition // IEEE
Trans. Control Syst. Technol. 2019. V. 27. No. 2. P. 566-575.
7.
Sornmo O., Bernhardsson B., Kroling O., Gunnarsson P., Tenghamn R. Frequency-
Domain Iterative Learning Control of a Marine Vibrator // Control Engin. Pract.
2016. V. 47. P. 70-80.
8.
Lim I., Hoelzle D.J., Barton K.L. A Multi-Objective Iterative Learning Control
Approach for Additive Manufacturing Applications // Control Eng. Pract. 2017.
V. 64. P. 74-87.
93
9. Arimoto S., Kawamura S., Miyazaki F. Bettering Operation of Robots by Learn-
ing // J. Robot. Syst. 1984. V. 1. P. 123-140.
10. Rogers E., Galkowski K., Owens D.H. Control Systems Theory and Applications
for Linear Repetitive Processes / Lect. Notes Control Inform. Sci. Berlin: Springer-
Verlag, 2007. V. 349.
11. Pakshin P., Emelianova J., Emelianov M., Galkowski K., Rogers E. Dissipivity and
Stabilization of Nonlinear Repetitive Processes // Syst. Control Lett. 2016. V. 91.
P. 14-20.
12. Hladowski L., Galkowski K., Cai Z., Rogers E., Freeman C., Lewin P. Experimen-
tally Supported 2D Systems Based Iterative Learning Control Law Design for Error
Convergence and Performance // Control Engin. Pract. 2010. V. 18. P. 339-348.
13. Paszke W., Rogers E., Patan K. Observer-Based Iterative Learning Control Design in
the Repetitive Process Setting // IFAC-PapersOnline. 2017. V. 50. No. 1. P. 13390-
13395.
14. Емельянова Ю.П., Пакшин П.В. Синтез управления с итеративным обучением
на основе наблюдателя состояния // АиТ. 2019. № 9. С. 9-24.
Emelianova J.P., Pakshin P.V. Iterative Learning Control Design Based on State
Observer // Autom. Remote Control. 2019. V. 80. No. 9. P. 1561-1573.
15. Jayawardhana R.N., Ghosh B.K. Kalman Filter Based Iterative Learning Control
for Discrete Time MIMO Systems // Proc. 30th Chinese Control and Decision Conf.
(2018 CCDC). 2018. P. 2257-2264.
16. Apkarian J., Karam P., Levis M. Workbook on Flexible Link Experiment for Mat-
lab/Simulink Users. Quanser, 2011.
Статья представлена к публикации членом редколлегии С.А. Красновой.
Поступила в редакцию 27.11.2019
После доработки 11.02.2020
Принята к публикации 04.03.2020
94