Автоматика и телемеханика, № 10, 2021
© 2021 г. Е.Л. ГЛАДИН (gladin.el@phystech.edu),
M. АЛКУСА, канд. физ.-мат. наук (mohammad.alkousa@phystech.edu),
А.В. ГАСНИКОВ, д-р физ.-мат. наук (gasnikov.av@mipt.ru)
(Московский физико-технический институт, Долгопрудный;
Институт проблем передачи информации им. А. А. Харкевича РАН, Москва)
О РЕШЕНИИ ВЫПУКЛЫХ MIN-MIN ЗАДАЧ
С ГЛАДКОСТЬЮ И СИЛЬНОЙ ВЫПУКЛОСТЬЮ
ПО ОДНОЙ ИЗ ГРУПП ПЕРЕМЕННЫХ
И МАЛОЙ РАЗМЕРНОСТЬЮ ДРУГОЙ1
Статья посвящена некоторым подходам к решению выпуклых задач
вида min-min с гладкостью и сильной выпуклостью только по одной из
двух групп переменных. Показано, что предложенные подходы, основан-
ные на методе Вайды, быстром градиентном методе и ускоренном гра-
диентном методе с редукцией дисперсии, имеют линейную сходимость.
Для решения внешней задачи предлагается использовать методы Вайды,
для решения внутренней (гладкой и сильно выпуклой) быстрый гради-
ентный метод. Ввиду важности для приложений в машинном обучении
отдельно рассмотрен случай, когда целевая функция является суммой
большого числа функций. В этом случае вместо быстрого градиентного
метода используется ускоренный градиентный метод с редукцией диспер-
сии. Приведены результаты численных экспериментов, иллюстрирующие
преимущества предложенных процедур для задачи логистической регрес-
сии, в которой есть априорное распределение на одну из двух групп пе-
ременных.
Ключевые слова: выпуклая оптимизация, метод секущей плоскости, ме-
тод Вайды, редукция дисперсии, быстрый градиентный метод, логисти-
ческая регрессия.
DOI: 10.31857/S0005231021100068
1. Введение
Одним из основных направлений исследований численных методов выпук-
лой оптимизации в последнее десятилетие стало повсеместное распростране-
ние конструкции ускорения обычного градиентного метода, предложенной
в 1983 г. Ю.Е. Нестеровым [1], на различные другие численные методы опти-
мизации. За последние 15 лет ускоренный метод был успешно перенесен на
гладкие задачи условной выпуклой оптимизации, на задачи со структурой
1 Работа выполнена при поддержке Министерства науки и высшего образования Рос-
сийской Федерации (госзадание) № 075-00337-20-03, номер проекта 0714-2020-0005. Работа
А.В. Гасникова была также частично поддержана Российским фондом фундаментальных
исследований (проект № 18-29-03071 мк).
60
(в частности, так называемые композитные задачи), безградиентные и рандо-
мизированные методы (например, ускоренный градиентный метод с редукци-
ей дисперсии для задач минимизации суммы функций [2]). Также ускорение
было успешно перенесено на методы, использующие старшие производные.
Детали и более подробный обзор публикаций можно найти в [3].
Задачи оптимизации вида min-max и седловые задачи широко изучались в
литературе из-за их широкого спектра приложений в статистике, машинном
обучении, компьютерной графике, теории игр и других областях. В послед-
нее время многие исследователи активно работают над темой ускоренных
методов решения этих задач, учитывающих их структуру: [4-8] и это лишь
некоторые из последних публикаций. В некоторых приложениях существует
задача, аналогичная задаче min-max, которая остается в значительной сте-
пени неизученной это задача вида min-min:
(1)
min
min
F (x, y),
x∈Qx
y∈Qy
где Qx ⊂ Rd, Qy ⊂ Rn непустые компактные выпуклые множества, размер-
ность d относительно небольшая (d ≪ n), функция F (x, y) выпуклая по со-
вокупности переменных, а также L-гладкая и µ-сильно выпуклая по y. Под
L-гладкостью по y понимается свойство
∥∇yF (x, y) - ∇yF (x, y′)∥2 ≤ L∥y - y′∥2
∀x ∈ Qx, y,y′ ∈ Qy.
Такая постановка возникает, например, при поиске равновесий в транспорт-
ных сетях [9]. В машинном обучении задачи такого типа соответствуют слу-
чаю, когда регуляризация применяется к одной из двух групп параметров
модели (отсюда сильная выпуклость только по одной группе переменных из
двух). Например, когда в датасете большая группа признаков являются раз-
реженными, то регуляризация может использоваться только для весов моде-
ли, соответствующих этим признакам. В качестве еще одного примера можно
привести логистическую регрессию, в которой есть априорное распределение
на часть параметров. Задаче min-min посвящено несколько публикаций, сре-
ди которых [10-12]. Например, в [10] авторы предложили новые алгоритмы
для задач min-max, шаги которых настраиваются автоматически, но предло-
женные методы также применяются и к задачам min-min.
В данной статье рассматриваются два подхода к решению задачи (1),
имеющие линейную скорость сходимости. Предлагается свести рассматривае-
мую задачу к совокупности вспомогательных задач (внутренней и внешней).
Внешняя задача (минимизация по x) решается методом Вайды (метод секу-
щей плоскости) [13, 14].
В случае когда целевая функция F простая, т.е. не является суммой боль-
шого количества функций, внутренняя задача (минимизация по y) решается
быстрым градиентным методом для задач сильно выпуклой оптимизации.
В результате такого подхода приближенное решение задачи (1) может быть(
√
)
L
достигнуто за
O (d) вычислений ∂xF
O d
вычислений ∇yF , см. тео-
µ
61
рему 5. Здесь и далее
O(·) = O(·) с точностью до небольшой степени лога-
рифмического множителя, обычно эта степень равна единице или двум.
Оптимизация суммы большого количества функций в течение последних
нескольких лет является предметом интенсивных исследований из-за широ-
кого спектра приложений в машинном обучении, статистике, обработке изоб-
ражений и других математических и инженерных приложениях. Поэтому
отдельно рассматривается случай, когда целевая функция F представляет
собой сумму (или среднее арифметическое) большого числа m функций, в
котором использование быстрого градиентного метода для задач сильно вы-
пуклой оптимизации потребовало бы вычисления градиентов m слагаемых
на каждом шаге, что может занимать много времени. Вместо этого пред-
лагаем использовать ускоренный градиентный метод с редукцией диспер-
сии [2, 15], который также имеет линейную сходимость. В результате такого
подхода решение задачи может быть достигнуто з
O (md) вычислений ∂xF
(
√
)
mL
и з
O md + d
вычислений ∇yF , см. теорему 6.
µ
Используя два предложенных подхода, получаем линейную скорость схо-
димости для задачи min-min (1). Отметим, что гладкость и сильная выпук-
лость требуются только по одной из двух групп переменных.
Статья состоит из 5 разделов и Приложения. В разделе 2 приводятся ис-
пользуемые алгоритмы и их сложность, а именно: быстрый градиентный ме-
тод, метод Вайды (метод секущей плоскости) и метод ускоренного градиент-
ного спуска с редукцией дисперсии. В разделе 3 формулируется постанов-
ка задачи и приводятся подходы к рассматриваемой задаче для различных
случаев целевой функции, в одном из которых целевая функция является
суммой или средним арифметическим большого числа функций. В разделе 4
приводятся результаты вычислительных экспериментов и сравнение скоро-
сти работы предложенных подходов. Отметим, что полные доказательства
теорем 4, 5, 6 и вспомогательного утверждения 1 приводятся в Приложении.
2. Используемые алгоритмы
Приведем алгоритмы, используемые в предлагаемых в статье подходах к
решению задачи (1). Сначала приводится быстрый градиентный метод, затем
метод Вайды (метод секущей плоскости) и, наконец, ускоренный градиент-
ный метод с редукцией дисперсии.
2.1. Быстрый градиентный метод
В [16] предложен адаптивный алгоритм для решения задачи оптимизации
(2)
f (y) → min ,
y∈Qy
где Qy ⊂ Rn непустое компактное выпуклое множество, f L-гладкая вы-
пуклая функция. Этот алгоритм, получивший название быстрого градиент-
ного метода, позволяет ускорить сходимость обычного градиентного спуска
62
(1
)
(1
)
с O
до O
, где N
количество итерации алгоритма. Быстрый гра-
N
N2
диентный метод (не адаптивный вариант) приведен далее как алгоритм 1.
Алгоритм 1. Быстрый градиентный метод [16].
Вход: Количество шагов N, начальная точка y0 ∈ Qy, параметр L > 0.
1:
0-шаг: z0 := y0, u0 := y0, α0 := 0, A0 := 0.
2: for k = 0, 1, . . . , N - 1 do
3:
Находим наибольший корень αk+1 такой, что Ak + αk+1 = Lα2k+1,
4:
Ak+1 := Ak + αk+1,
αk+1uk + Akyk
5:
zk+1 :=
,
Ak+1
{
}
D (
)
E
1
6:
uk+1 := arg min
αk+1
∇f zk+1
,y-zk+1
+
∥y - uk∥2
,
2
y∈Qy
2
yk
αk+1uk+1 + Ak
7:
yk+1 :=
,
Ak+1
8: end for
Выход: yN .
Следующая теорема дает оценку сложности (скорости сходимости) алго-
ритма 1.
Теорема 1
[16]. Пусть функция f : Qy → R является L-гладкой и вы-
пуклой, тогда алгоритм 1 возвращает такую точку yN , что
(
)
2
8LR
f
yN
- f(y∗) ≤
,
(N + 1)2
где y∗
решение задачи (2), R2 =12∥y0 - y∗∥22.
Опишем далее технику рестартов (перезапусков) быстрого градиентного
метода (алгоритм 1) для случая µ-сильно выпуклой функции.
Ввиду µ-сильной выпуклости f имеем
µ
L
∥z - y∥22 ≤ f(z) - (f(y) + 〈∇f(y), z - y〉) ≤
∥z - y∥22
∀y,z ∈ Qy.
2
2
Тогда после N1 итераций алгоритма 1 с учетом теоремы 1 получаем
µ
(
)
4L∥y0 - y∗∥22
(3)
∥yN1 - y∗∥22 ≤ f
yN1
- f (y∗) ≤
,
2
N2
1
отсюда
8L
∥yN1 - y∗∥22 ≤
∥y0 - y∗∥22.
µN2
1
63
⌈
√
⌉
L
Поэтому, выбирая N1 =
4
, где ⌈·⌉
округление вверх, получим
µ
1
∥yN1 - y∗∥22 ≤
∥y0 - y∗∥22.
2
После этого выберем для алгоритма 1 в качестве точки старта yN1 , снова
сделаем N1 итераций и т.д. Для достижения приемлемого качества решения
можно выбрать количество рестартов алгоритма 1 (параметр p алгоритма 2)
следующим образом:
)⌉
2
⌈1
(µR
p=
ln
2
ε
В таком случае общее число итераций алгоритма 2 будет
⌈
√
⌉
)⌉
2
⌈1
(µR
L
N =
ln
·
4
,
2
ε
µ
т.е.
(√
(√
)
))
2
L
(µR
L
(4)
N =O
ln
=
O
µ
ε
µ
Алгоритм 2. Быстрый градиентный метод для задач сильно выпуклой
оптимизации, рестарты алгоритма 1.
(
)⌉
⌈1
µR2
Вход: начальная точка y0 ∈ Qy, L > 0, число рестартов p =
ln
ε
2
1: for j = 1, . . . , p do
⌈
√L⌉
2:
Выполнить Nj =
4
итераций алгоритма 1,
µ
3:
y0 := yNj .
4: end for
Выход: ŷ := yNp .
2.2. Метод Вайды
Метод Вайды (метод секущей плоскости) был предложен Вайдой в [13, 14]
для решения условной задачи оптимизации
(5)
f (x) → min ,
x∈Qx
где Qx ⊂ Rd выпуклое компактное множество с непустой внутренностью, а
целевая функция f, определенная на Qx, непрерывна и выпукла.
64
Пусть P = {x ∈ Rd : Ax ≥ b} ограниченный d-мерный многогранник,
где A ∈ Rm×d и b ∈ Rm. Логарифмический барьер множества P определяется
как
∑ (
)
Barr(x) = - log a⊤x-bi
,
i
i=1
где a⊤i i-я строка матрицы A. Гессиан H(x) функции Barr(x) равен
∑
aia⊤i
H(x) =
(
)2 .
a⊤ix - bi
i=1
Матрица H(x) положительно определена для всех x из внутренности P . Во-
люметрический барьер (volumetric barrier) V определяется как
1
V(x) =
log (det (H(x))) ,
2
где det (H(x)) обозначает детерминант H(x). Будем называть точку миниму-
ма функции V на P волюметрическим центром множества P .
Обозначим
a⊤i (H(x))-1 ai
(6)
σi(x) =
(
)2
,
1 ≤ i ≤ m,
a⊤ix - bi
тогда градиент волюметрического барьера V может быть записан как
∑
ai
∇V(x) = -
σi(x)
ai⊤x - bi
i=1
Пусть Q(x) определяется как
∑
aia⊤i
Q(x) =
σi(x)(
)2 .
a⊤ix - bi
i=1
Заметим, что Q(x) положительно определена на внутренности P , а также
Q(x) является хорошим приближением гессиана функции V(x), т.е. ∇2V(x).
Метод Вайды производит последовательность пар (Ak, bk) ∈ Rm×d × Rm
таких, что соответствующие многогранники содержат решение. В качестве
начального многогранника, задаваемого парой (A0, b0), обычно берется сим-
плекс (алгоритм может начинать с любого выпуклого ограниченного n-мерно-
го многогранника, для которого легко вычислить волюметрический центр
например, с n-прямоугольника).
Параметром алгоритма является небольшое число γ ≤ 0,006, смысл кото-
рого более подробно раскрывается в книге [17]. Пусть xk (k ≥ 0) обозначает
волюметрический центр многогранника, заданного парой (Ak, bk), и пусть для
него вычислены величины {σi(xk)}1≤i≤m (см. (6)). Следующий многогранник
(Ak+1, bk+1) получается из текущего в результате либо присоединения, либо
удаления ограничения:
65
1) Если для некоторого i ∈ {1, . . . , m} выполняется σi(xk) = min
)<
σj(xk
1≤j≤m
< γ, тогда (Ak+1,bk+1) получается исключением i-й строки из (Ak,bk);(
)
2) иначе если min
σj(xk) ≥ γ оракул, вызванный в текущей точ-
1≤j≤m
{
ке xk, возвращает вектор ck такой, что f(x) ≤ f(xk) ∀x ∈ z ∈ Qx :
}
:c⊤kz ≥ c⊤kxk , т.е. ck ∈ -∂f(xk). Выберем βk ∈ R таким, что
c⊤k (H(xk))-1 ck
1
(
)2
=
√γ.
x⊤kck - βk
5
Определим (Ak+1, bk+1) добавлением строки (ck, βk) к (Ak, bk).
Волюметрический барьер Vk является самосогласованной функцией, поэтому
может быть эффективно минимизирован методом Ньютона. Достаточно од-
ного шага метода Ньютона для Vk, сделанного из xk-1. Подробности и анализ
метода Вайды можно найти в [13, 14, 17].
Следующая теорема дает оценку сложности алгоритма Вайды.
Теорема 2. Пусть Bρ и BR некоторые евклидовы шары радиусов ρ
и R соответственно такие, что Bρ⊆Qx⊆BR, и пусть число B > 0 таково,
что |f(x) - f(x′)| ≤ B ∀x, x′ ∈ Qx. Тогда метод Вайды находит ε-решение(
)
задачи (5) за O d logdBR
шагов.
ρε
Замечание 1. Как показано в [18], метод Вайды можно использовать с
неточным субградиентом без накопления ошибки.
Замечание 2. Помимо вычисления субградиента, в стоимость итерации
метода Вайды входит стоимость обращения матрицы размера d×d и решения
системы линейных уравнений.
2.3. Ускоренный градиентный метод с редукцией дисперсии
Рассмотрим задачу
(7)
f (y) → min ,
y∈Qy
где Qy ⊆ Rn замкнутое выпуклое множество, а целевая функция f пред-
ставляет собой сумму (или среднее арифметическое) большого числа m глад-
∑m
ких выпуклых функций fi, т.е. f(y) =1
fi(y). При решении (7) с по-
m i=1
мощью быстрого градиентного метода для задач сильно выпуклой оптими-
зации (алгоритм 2) потребуется вычислять градиент m функций на каждой
итерации, что очень дорого. Поэтому предпочтительнее вместо алгоритма 2
использовать рандомизированный градиентный метод, а именно ускоренный
градиентный метод с редукцией дисперсии, также называемый Varag [2, 15].
Приведенный далее алгоритм 3 представляет собой ускоренный градиентный
метод с редукцией дисперсии (Varag) для гладкой сильно выпуклой задачи
оптимизации конечной суммы (7). Этот алгоритм был предложен Г. Ланом
и др. в [15].
66
Предположим, что для каждого i ∈ {1, . . . , m}, существует Li > 0 такое,
что
∥∇fi(y) - ∇fi(z)∥2 ≤ Li∥y - z∥2
∀y,z ∈ Qy.
∑m
Ясно, что f имеет липшицев градиент с константой не более L :=1
Li.
m i=1
Предположим также, что целевая функция f сильно выпуклая с константой
µ > 0, т.е.
µ
f (z) ≥ f(y) + 〈∇f(y), z - y〉 +
∥y - z∥2
∀y,z ∈ Qy.
2
Определение 1. Случайный вектор y, принимающий значения из Qy,
называется стохастическим ε-решением задачи (7), если E[f(y) - f(y∗)] ≤
≤ ε, где y∗ точное решение задачи (7).
Алгоритм Varag содержит вложенные циклы внешний и внутренний
(индексируемые переменными s и t соответственно). На каждой итерации
внешнего цикла вычисляется полный градиент ∇f(y) в точке y, который за-
тем используется во внутреннем цикле для определения оценок градиента Gt.
Каждая итерация внутреннего цикла требует информацию о градиенте толь-
ко одного случайно выбранного слагаемого fit и содержит три основные по-
следовательности: {yt}, {yt} и {yt}.
Обозначим s0 := ⌊log2 m⌋ + 1, где ⌊·⌋ округление вниз. Параметры ал-
горитма 3 {q1, . . . , qm}, {θt}, {αs}, {γs}, {ps} и {Ts} описываются следующим
образом:
1
∑m
• Вероятности qi =
Li ∀i ∈ {1,... ,m};
Li
i=1
√
12L
• Веса {θt} при 1 ≤ s ≤ s0 или s0 < s ≤ s0 +
- 4, m < 3L4µ равны
mµ
γs
(αs + ps) ,
1 ≤ t ≤ Ts - 1,
αs
(8)
θt =
γs ,
t=Ts.
αs
В остальных случаях они равны
{ Γt-1 - (1 - αs - ps) Γt, 1 ≤ t ≤ Ts - 1,
(9)
θt =
Γt-1,
t=Ts,
где Γt = (1 + µγs)t;
• Параметры {Ts}, {γs} и {ps} определяются как
{
2s-1, s ≤ s
0,
1
1
(10)
Ts =
γs =
, ps =
;
Ts0, s > s0,
3Lαs
2
• Наконец,
1
,
s≤s0,
2
(11)
αs =
{
{√
}}
2
mµ
1
max
,min
,
, s>s0.
s-s0 +4
3L
2
67
Алгоритм 3. Ускоренный градиентный метод с редукцией дисперсии
(Varag) [15].
Вход: y0 ∈ Qy, {Ts}, {γs}, {αs}, {ps}, {θt} и распределение вероятностей
{q1, . . . , qm} на {1, . . . , m}.
1:
y0 := y0.
2: for s = 1, 2, . . . , do
3:
y := ys-1, g := ∇f(y).
4:
y0 := ys-1, y0 = y, T := Ts.
5:
for t = 1, 2, . . . , T do
6:
Выбрать it ∈ {1, . . . , m} случайным образом согласно {q1, . . . , qm}.
1
7:
y
t
:= (1 + µγs(1 - αs))[(1+µγs)(1-αs -ps)yt-1 +αsyt-1 +(1+µγs)ps y].
(
(
)
)
1
8:
Gt :=
∇fit y
- ∇fit(y)
+ g.
t
(qitm)
{
}
(
)
µ
1
9:
yt := arg min
γs
〈Gt, y〉 +
∥yt - y∥2
+
∥yt-1 - y∥2
2
2
y∈Qy
2
2
10:
yt := (1 - αs - ps) yt-1 + αsyt + ps y.
11:
end for
1
∑
12:
ys := yT , ys :=
∑
(θtyt).
T
θt t=1
t=1
13: end for
Следующий результат дает оценку сложности алгоритма 3.
Теорема 3
[15]. Если параметры алгоритма 3 {θt}, {αs}, {γs}, {ps}
и {Ts} заданы согласно формулам (8), (9), (10) и (11), то общее количество
вычислений градиентов функций fi, выполняемых алгоритмом 3 для нахож-
дения стохастического ε-решения задачи (7), ограничено
{
}
D0
D0
3L
O mlog
,
m≥
или m ≥
,
ε
ε
4µ
{
}
√
mD0
D0
3L
(12)
N :=
O mlogm +
,
m<
≤
,
ε
ε
4µ
{
}
√mL
D0/ε
3L
D0
O mlogm +
log
, m<
≤
,
µ
3L/4µ
4µ
ε
(
)
где D0 = 2
f (y0) - f(y∗)
+3L2∥y0 - y∗∥22, где y∗ решение задачи (7).
(
√
)
mL
Заметим, что оценку (12) можно записать как N
O m+
, где
µ
O(·) = O(·) с точностью до логарифмического множителя по m, L, µ, ε и D0.
68
3. Постановка задачи и полученные результаты
Рассмотрим задачу
(13)
min
min
F (x, y),
x∈Qx
y∈Qy
где Qx ⊂ Rd, Qy ⊂ Rn непустые компактные выпуклые множества, раз-
мерность d относительно небольшая (d ≪ n), функция F (x, y) выпуклая
по совокупности переменных, а также L-гладкая и µ-сильно выпуклая по y.
Под L-гладкостью по y понимается свойство
∥∇yF (x, y) - ∇yF (x, y′)∥2 ≤ L∥y - y′∥2
∀x ∈ Qx, y,y′ ∈ Qy.
Введем функцию
(14)
f (x) = min
F (x, y).
y∈Qy
Задачу (13) можно переписать в виде
(15)
f (x) → min .
x∈Qx
При решении (15) некоторым итерационным методом необходимо на каждом
его шаге решать вспомогательную задачу (14), чтобы приближенно находить
субградиент ∂f(x). Обратимся к следующему определению.
Определение 2 ([19], с. 123). Пусть δ ≥ 0, Qx ⊆ Rd выпуклое мно-
жество, f : Qx → R выпуклая функция. Вектор g ∈ Rd называется δ-суб-
градиентом f в точке x′ ∈ Qx, если
f (x) ≥ f(x′) + 〈g, x - x′〉 - δ
∀x ∈ Qx.
Множество δ-субградиентов f в точке x′ обозначается ∂δf(x′).
Обозначим D := maxy,z∈Qy ∥y - z∥2, y(x) := arg miny∈Qy F (x, y). Следую-
щая теорема говорит о том, как вычислить δ-субградиент функции f(x), при-
ближенно решая вспомогательную задачу (15).
Теорема 4. Пусть найден такой y ∈ Qx, что F(x, y) - f(x) ≤ ε, тогда
(
)
√ 2ε
∂xF(x, y) ∈ ∂δf(x), δ =
LD + ∥∇yF (x,y(x))∥2
µ
Эта теорема непосредственно следует из двух утверждений.
Утверждение 1. Пусть g : Qy → R
L-гладкая µ-сильно выпуклая
функция, точка y ∈ Qy такова, что g(y) - g(y∗) ≤ ε, тогда
√ 2ε
max
〈∇g(y), y - y〉 ≤ δ, δ = (LD + ∥∇g (y∗)∥2)
,
y∈Qy
µ
где y∗ = arg miny∈Qy g(y).
69
Утверждение 2 ([20], с. 12). Пусть найден такой y ∈ Qy, что
max 〈∇yF (x, y), y - y〉 ≤ δ,
y∈Qy
тогда ∂xF(x, y) ∈ ∂δf(x).
Интуитивно теорема 4 говорит о том, что, решив вспомогательную зада-
чу (14) достаточно точно, получим хорошее приближение субградиента ∂f(x),
которое может быть использовано для решения внешней задачи (15). На этой
идее основан предлагаемый подход к решению (13).
Подход 1 (основной случай). Внешняя задача (15) решается методом Вай-
ды. Вспомогательная задача (14) решается быстрым градиентным методом
для задач сильно выпуклой оптимизации (алгоритм 2).
Теорема 5. Подход 1 позволяет получить ε-решение задачи (13) после(
√
)
L
O (d) вычислений ∂xF и обращений матриц размера d×d, а такж
O d
µ
вычислений ∇yF .
Замечание 3. Обращение матриц появляется в сложности предлагаемо-
го подхода из-за того, что оно производится на каждом шаге метода Вайды.
3.1. Минимизация суммы большого числа функций
Пусть в задаче (13)
∑
1
(16)
F (x, y) =
Fi
(x, y),
m
i=1
где функции Fi являются выпуклыми по совокупности переменных и Li-глад-
кими по y, а F является µ-сильно выпуклой по y. Из этого следует, что F яв-
ляется выпуклой по совокупности переменных и гладкой по y с константой
∑m
гладкости не более L :=1
Li.
m i=1
Подход 2 (сумма функций). Внешняя задача (15) решается методом Вай-
ды. Вспомогательная задача (14) решается ускоренным градиентным мето-
дом с редукцией дисперсии (алгоритм 3).
Теорема 6. Подход2позволяетполучитьε-решениезадачи(13)з
O(md)
(
√
)
mL
вычислений ∂xFi
O (d) обращений матриц размера d × d
O dm + d
µ
вычислений ∇yFi.
4. Эксперименты
Рассмотрим модель логистической регрессии для задачи бинарной класси-
фикации. Ошибка модели с параметрами w на обучающем объекте с вектором
признаков z, принадлежащем классу t ∈ {-1, 1}, записывается как
(
)
ℓz(w) = log
1+e-t〈w,z〉
70
a
30
20
10
6
4
2
2
1
0
10 000
20 000
30 000
40 000
50 000
60 000
Количество вычислений ÑyFi
б
30
20
10
6
4
2
2
1
0
20 000
40 000
60 000
80 000
Количество вычислений ÑyFi
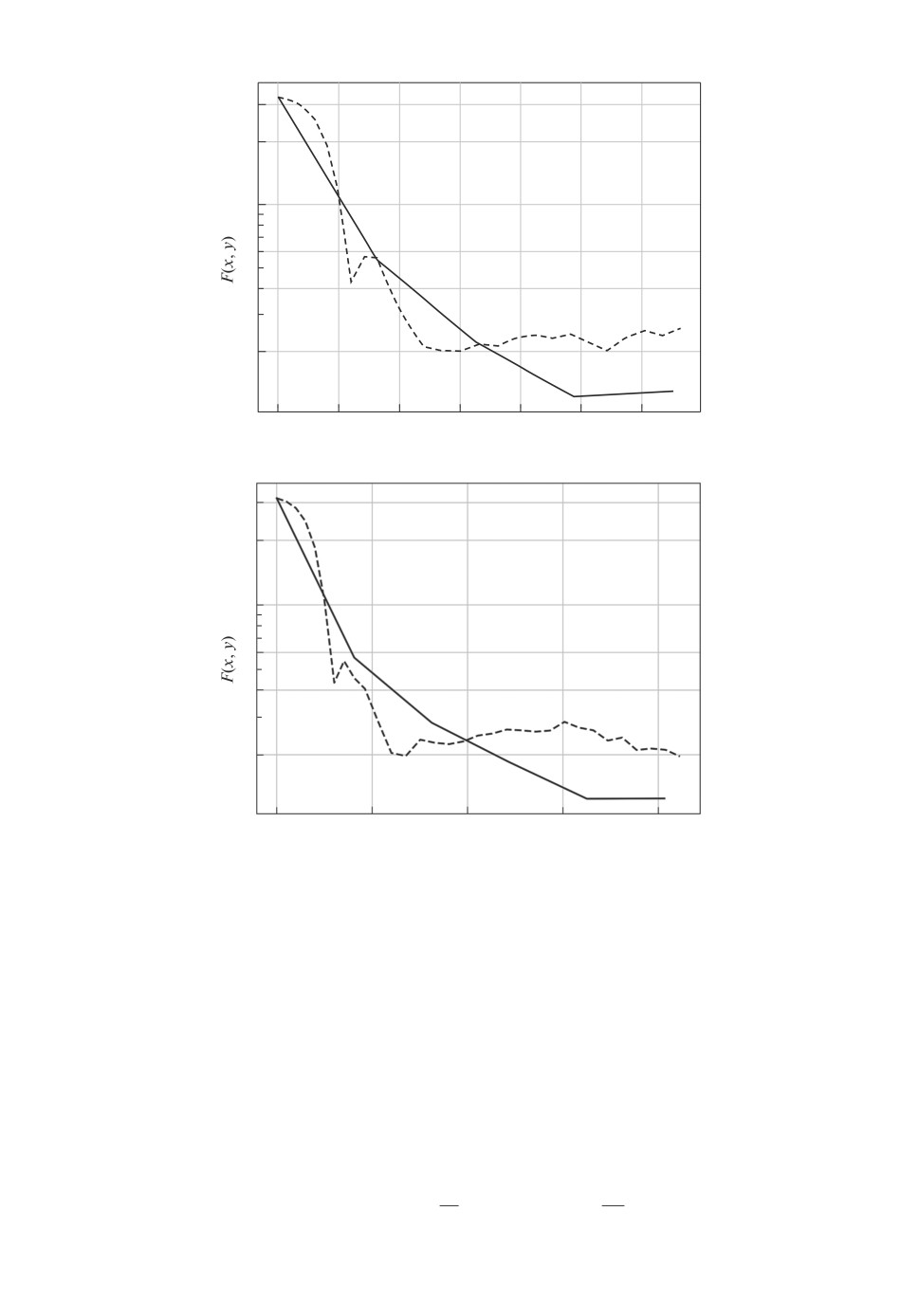
Рис. 1. а и б соответствуют размерностям d = 20 и d = 30 соответственно.
Графики 1 и 2 показывают сходимость предлагаемого подхода и метода Varag
соответственно.
Пусть параметры модели состоят из двух групп: w = (x, y), x ∈ Rd, y ∈ Rn,
причем для группы y задано гауссовское априорное распределение:
(
)
y∼N
0, σ2In
,
где In единичная матрица размера n. Максимизация апостериорной веро-
ятности приведет (см. [21], § 4.5.1) к задаче
{
}
m
∑
1
1
(17)
min
min
F (x, y) :=
ℓzi(x,y) +
∥y∥2
,
2
x∈Qx
y∈Qy
m
σ2
i=1
71
где в качестве Qx и Qy можно взять евклидовы шары достаточно большого
радиуса.
Будем решать задачу (17) при помощи подхода 2 и сравним его работу
с работой метода Varag (алгоритм 3). Заметим, что эта задача не является
сильно выпуклой по совокупности переменных. Для такой постановки можно
использовать Varag, задавая параметры θt по формуле (8), а все остальные па-
раметры по формулам для сильно выпуклого случая, положив µ = 0, см. [15].(
)
√
mD0
При этом стохастическое ε-решение будет найдено за O
+ mlogm
ε
(
)
вычислений градиентов функций Fi, где D0 = 2
F (x0, y0) - F (x∗, y∗)
+
+3L2∥(x0,y0) - (x∗,y∗)∥22, (x∗,y∗)
решение задачи (17). Эта сублинейная
оценка уступает предлагаемому в статье подходу, см. теорему 2.
Для экспериментов использовался датасет madelon, представленный
2000 объектов, имеющих 500 признаков. Был выбран небольшой коэффици-
1
ент регуляризации
= 0,005 и проведены эксперименты для двух размер-
σ2
ностей d, равных 20 и 30.
На рис. 1 отражены результаты эксперимента. По оси x откладывается
количество вычислений градиентов ∇yFi, которое для Varag совпадает с ко-
личеством вычислений ∇xFi. Отметим, что предложенный подход требует
меньше вычислений ∇xFi, поскольку они выполняются только во внешнем
цикле. Так, график 1 на рис. 1,а соответствует четырем итерациям внешнего
цикла (т.е. 8000 вычислений ∇xFi), а график 1 на рис. 1,б пяти итераци-
ям (т.е. 10 000 вычислений ∇xFi). В данном эксперименте подход 2 позволил
достичь меньших значений целевой функции.
Исходный код и результаты экспериментов могут быть найдены в репози-
5. Заключение
В статье рассмотрена задача вида min-min:
(18)
min
min
F (x, y),
x∈Qx
y∈Qy
где Qx ⊂ Rd, Qy ⊂ Rn непустые компактные выпуклые множества, размер-
ность d относительно небольшая (d ≪ n), функция F (x, y) выпуклая по
совокупности переменных, а также L-гладкая и µ-сильно выпуклая по y.
Предложено два подхода к решению задачи (18), в которых она сводит-
ся к совокупности вспомогательных задач (внутренней и внешней). Внешняя
задача (минимизация по x) решается методом Вайды, а внутренняя (мини-
мизация по y) быстрым градиентным методом для задач сильно выпуклой
оптимизации или, если минимизируется сумма большого количества функ-
ций, ускоренным градиентным методом с редукцией дисперсии. Это позволя-
ет достигать приближенного решения задачи (18) з
O (d) вычислений ∂xF
(
√
)
L
и
O d
вычислений ∇yF , см. теорему 5. Для сравнения, если бы за-
µ
дача (18) была гладкой по совокупности переменных, то ее решение при
72
ис(ользов)нии только быстрого градиентного метода имело бы сложность
√
O LR2
, где R
расстояние от начального приближения до решения.
ε
В случае суммы с m слагаемыми решение задачи может быть достигнуто(
√
)
mL
за
O (md) вычислений ∂xF и з
O md + d
вычислений ∇yF , см. тео-
µ
рему 6.
Проведен численный эксперимент, в котором один из предлагаемых подхо-
дов применен к задаче логистической регрессии с регуляризацией, применяе-
мой к одной из двух групп параметров модели. По сравнению с алгоритмом
Varag, предложенный подход достиг меньших значений функции при мень-
шем числе вызовов оракулов.
Отметим также, что если функция F (x, y)
µ-сильно выпуклая по
совокупности переменных, то функция g(y) = minx∈Qx F (x, y) также будет
µ-сильно выпуклая. Более того, все это можно сформулировать в терминах
(δ, µ, L)-оракула (см. [3] и цитированную там литературу). При µ = 0 это
сделано в [20], при µ > 0 доказательство практически дословно повторяет
утверждения 1 и 3 из [20] (см. также [9]). Приведенное наблюдение позволяет
обоснованно (с теоретической проработкой) использовать для решения внут-
ренней задачи метод Вайды, а для решения внешней задачи использовать,
например, быстрый градиентный метод. Однако такой подход будет предпо-
чтительнее рассмотренного в данной статье только при весьма специальных
(как правило, трудно выполнимых) условиях [5].
ПРИЛОЖЕНИЕ
Доказательство утверждения 1. Рассмотрим произвольный y ∈Qy
(Π.1)
〈∇g(y), y - y〉 = 〈∇g(y) - ∇g(y∗), y - y〉 + 〈∇g(y∗
), y - y〉 .
Оценим сверху первое слагаемое, используя неравенство Коши-Буняковского
и определение липшицевости градиента:
〈∇g(y) - ∇g(y∗), y - y〉 ≤ ∥∇g(y) - ∇g(y∗)∥2 ∥y - y∥2 ≤
(Π.2)
≤L∥y-y∗∥2∥y-y∥2.
Из сильной выпуклости следует, что
µ
g(y) ≥ g(y∗) + 〈∇g(y∗), y - y∗〉 +
∥y-y∗∥22.
2
Воспользовавшись неравенствами g(y) - g(y∗) ≤ ε и 〈∇g(y∗), y - y∗〉 ≥ 0 ∀y ∈
∈ Qy, получим
√
√
2ε
(Π.2)
2ε
(Π.3)
∥y-y∗∥2 ≤
=⇒ 〈∇g(y) - ∇g(y∗), y - y〉 ≤ L ∥y - y∥2
µ
µ
Теперь оценим сверху второе слагаемое в (Π.1)
〈∇g(y∗), y - y〉 = 〈∇g(y∗), y - y∗〉 + 〈∇g(y∗), y∗ - y〉 .
73
Снова воспользовавшись критерием оптимальности точки y∗ и неравенством
Коши-Буняковского, получим
(Π.3)
√ 2ε
〈∇g(y∗), y - y〉 ≤ ∥∇g(y∗)∥2∥y - y∗∥2
≤ ∥∇g(y∗)∥2
µ
Объединив верхние оценки для обоих слагаемых, получим
√
2ε
〈∇g(y), y - y〉 ≤ (L ∥y - y∥2 + ∥∇g(y∗)∥2)
,
µ
откуда следует доказываемое утверждение 1.
Доказательство теоремы 4. Зафиксировав x∈Qx, применим утверж-
дение 1 к функции g(y) := F (x, y) и утверждение 2. Теорема 4 доказана.
Доказательство теоремы 5. Согласно (4) алгоритм 2 сходится ли-
нейно, поэтому можно считать, что вспомогательная задача miny∈Qy F (x, y)
(√
)
L
решается сколь угодно точно за врем
O
. Согласно теореме 4 это позво-
µ
ляет использовать δ-субградиент, где δ убывает со скоростью геометрической
прогрессии. Для внешней задачи используется метод Вайды, который также
сходится линейно и имеет сложност
O (d). Таким образом, для решения за-
дачи (13) достаточно
O (d) вычислений ∂xF и обращений матриц размера
(
√
)
L
d×d, атакж
O d
вычислений ∇yF . Теорема 5 доказана.
µ
Доказательство теоремы 6. Согласно теореме 3 Varag сходится ли-
нейно, поэтому можно считать, что вспомогательная задача miny∈Qy F (x, y)
(
√
)
mL
решается сколь угодно точно за врем
O m+
. Согласно теореме 4 это
µ
позволяет использовать δ-субградиент, где δ убывает со скоростью геометри-
ческой прогрессии. Для внешней задачи используется метод Вайды, который
также сходится линейно и имеет сложность
O (d) итераций. На каждой его
итерации необходимо вычислять субградиенты всех m слагаемых ∂xFi. Та-
ким образом, для решения задачи достаточн
O (md) вычислений ∂xFi
O (d)
(
√
)
mL
обращений матриц размера d × d
O dm + d
вычислений ∇yFi. Тео-
µ
рема 6 доказана.
СПИСОК ЛИТЕРАТУРЫ
1. Нестеров Ю.Е. Метод минимизации выпуклых функций со скоростью сходимо-
сти O(1/k2) // Докл. АН СССР. 1983. Т. 269. № 3. С. 543-547.
2. Lan G. First-order and Stochastic Optimization Methods for Machine Learning. At-
lanta: Springer, 2020.
3. Гасников А.В. Современные численные методы оптимизации. Метод универ-
сального градиентного спуска. М.: МЦНМО, 2020.
4. Alkousa M.S., Dvinskikh D.M., Stonyakin F.S., Gasnikov A.V., Kovalev D. Accel-
erated Methods for Saddle Point Problems // Comput. Math. Math. Phys. 2020.
V. 60. No. 11. P. 1787-1809.
74
5.
Gladin E., Kuruzov I., Stonyakin F., Pasechnyuk D., Alkousa M., Gasnikov A. Solv-
ing strongly convex-concave composite saddle point problems with a small dimension
6.
Tianyi L., Chi J., Michael I.J. Near-Optimal Algorithms for Minimax Optimization.
7.
Yuanhao W., Jian L. Improved Algorithms for Convex-Concave Minimax Optimiza-
8.
Zhongruo Wang, Krishnakumar Balasubramanian, Shiqian Ma, Meisam Razaviyayn.
Zeroth-Order Algorithms for Nonconvex Minimax Problems with Improved Com-
9.
Гасников А.В., Гасникова Е.В. Модели равновесного распределения транспорт-
ных потоков в больших сетях. Уч. пос. М.: МФТИ, 2020.
10.
Bolte J., Glaudin L., Pauwels E., Serrurier M. A Hölderian backtracking method
11.
Jungers M., Trélat E., Abou-Kandil H. Min-Max and Min-Min Stackelberg Strategies
with Closed-Loop Information Structure // J. Dynamical and Control Syst. Springer
Verlag, 2011. No. 17 (3). P. 387-425.
12.
Konur D., Farhangi H. Set-based Min-max and Min-min Robustness for Multi-
objective Robust Optimization // Proc. 2017 Industrial and Systems Engineering
Research Conf. K. Coperich, E. Cudney, H. Nembhard, eds.
13.
Vaidya P.M. A New Algorithm for Minimizing Convex Functions over Convex Sets //
Foundations of Computer Science, 1989. 30th Annual Sympos. 1989. P. 338-343.
14.
Vaidya P.M. A new algorithm for minimizing convex functions over convex sets //
Mathematical Programming 73. Springer, 1996. P. 291-341.
15.
Lan G., Zhize Li, Yi Zhou. A unified variance-reduced accelerated gradient method
for convex optimization // 33rd Conf. on Neural Information Processing Systems
16.
Tyurin A.I., Gasnikov A.V. Fast Gradient Descent Method for Convex Optimization
Problems with an Oracle That Generates a (δ, L)-model of a Function in a Requested
Point // Comput. Math. Math. Phys. 2019. V. 59. No. 7. P. 1137-1150.
17.
Bubeck S. Convex Optimization: Algorithms and Complexity // Foundations and
Trends in Machine Learning. 2015. V. 8. No. 3-4. P. 231-357.
18.
Gladin E., Sadiev A., Gasnikov A., Stonyakin F., Dvurechensky P., Beznosikov A.,
Alkousa M. Solving smooth min-min and min-max problems by mixed oracle algo-
19.
Поляк Б.Т. Введение в оптимизацию. М.: Наука, 1983.
20.
Гасников А.В., Двуреченский П.Е., Камзолов Д.И., Нестеров Ю.Е., Спокой-
ный В.Г., Стецюк П.И., Суворикова А.Л., Чернов А.В. Поиск равновесий в мно-
гостадийных транспортных моделях // Тр. Московского физико-технического
института. 2015. № 7.4 (28).
21.
Bishop C. Pattern recognition and machine learning. Springer, 2006.
Статья представлена к публикации членом редколлегии А.А. Лазаревым.
Поступила в редакцию 28.01.2021
После доработки 26.04.2021
Принята к публикации 30.06.2021
75