Автоматика и телемеханика, № 10, 2021
© 2021 г. З.М. ШИБЗУХОВ, д-р физ.-мат. наук (intellimath@mail.ru)
(Институт математики и информатики Московского
педагогического государственного университета;
Московский физико-технический институт)
ОБ ОДНОМ РОБАСТНОМ ПОДХОДЕ К ПОИСКУ
ЦЕНТРОВ КЛАСТЕРОВ1
Предложен новый подход к построению алгоритмов кластеризации
k-means, в котором вместо евклидова расстояния используется расстоя-
ние Махаланобиса. Подход основан на минимизации дифференцируемых
оценок среднего значения, нечувствительных к выбросам. На иллюстра-
тивных примерах убедительно показана возможность устойчивости пред-
ложенного алгоритма по отношению к большим объемам выбросов в дан-
ных.
Ключевые слова: центр кластера, робастное среднее, расстояние Маха-
ланобиса, итеративное перевзвешивание, робастный алгоритм.
DOI: 10.31857/S0005231021100111
1. Введение
Задача кластеризации одна из классических задач машинного обучения.
В основе одного классического подхода для разбиения конечного множества
точек на кластеры лежит процедура поиска центров кластеров. Центр класте-
ра это точка, от которой сумма обобщенных расстояний до всех его точек
минимальна. Разбиение на кластеры осуществляется по простому правилу:
точка относится к тому кластеру, до центра которого расстояние минималь-
но. Формально это можно выразить следующим образом.
2. Классическая постановка задачи
{
}
Пусть U ⊂ Rn открытое множество, X =
x1,... ,xN
⊂ U конечное
множество, которое требуется разбить на K кластеров. Пусть d: U × U →
→ R+ функция обобщенного расстояния между точками из U. Она об-
ладает свойствами, которые достаточны для того, чтобы следующая задача
минимизации
∑
c∗ = arg min d(xj , c)
c∈S j=1
1 Работа выполнена при поддержке Российского фонда фундаментальных исследований
(проект №18-01-00050).
140
для поиска центра произвольного кластера C ⊂ U имела решение. Точное
формальное определение функции d можно найти в [1].
Если заданы центры кластеров c1, . . . , cK , то произвольная точка x будет
относиться к кластеру с центром ct (1 ≤ t ≤ K), если
d(x, ct) = min
d(x, cj ).
1≤j≤K
Задачу поиска центров кластеров можно сформулировать как задачу мини-
мизации
(1)
c∗1, . . . , c∗K = arg min Q(c1, . . . , cK
),
c1,...,cK
где
∑
(2)
Q(c1, . . . , cK ) =
νk min
d(xk, cj
),
1≤j≤K
k=1
величина νk ≥ 0 соответствует значимости k-й точки, ν1 + . . . + νN = 1.
3. Постановка задачи с выпуклыми функциями среднего по Колмогорову
В [1] рассматривается более общая постановка задачи, в которой наряду
с функцией min в формуле (2) используются выпуклые функции среднего
по Колмогорову:
∑
1
hs(xj)
,
Ghs(x1,...,xK)=hs-1
K
j=1
где hs : R+ → R+ непрерывно-дифференцируемая строго монотонно убы-
вающая неотрицательная биективная функция. При этом
lim
xj.
Ghs(x1,...,xK)=min
s→∞
j=1,...,K
Например:
}
1
{1
(
)
1) Ge-sx (x1, . . . , xK ) = -
ln
e-sx1 + ... + e-sxK
;
s
K
)-1/s
(1
(
)
2) Gx-s (x1, . . . , xK ) =
x-s1 + ... + x-sK
K
Целевая функция (2) принимает вид:
∑
(
)
(3)
Q(c1, . . . , cK ) =
νkGhs
d(xk, c1), . . . , d(xk, cK )
k=1
141
Градиенты целевой функции Q принимают вид:
∂Q
∑
∂d(xk, cj )
=
νkvjk(c1,... ,cK)
,
∂cj
∂cj
k=1
где
h′s(d(xk,cj))
vjk(c1,... ,cK) =
(
(
)).
h′s
Ghs
d(xk, c1), . . . , d(xk, cK )
В случае Gh∞ = min
{
1, если d(x, cj) = min
d(x, ct),
t=1,...,K
vjk(c1,... ,cK) =
0
иначе.
Алгоритм SKM.
Для поиска центров в [1] предложен алгоритм SKM (Smooth k-Means) и
при определенных условиях доказана его сходимость к решению задачи ми-
нимизации (3).
procedure SKM(X, {ν1, . . . , νN }, {c01, . . . , c0K })
t←0
repeat
for all j = 1, . . . , K do
νtjk = νkvk(ct1,... ,ctK),
∑
νtjk
ct+1j ← arg min
νtjkd(xk,c), где νtjk =
c
νtj1 + ··· + νtjN
k=1
end for
t←t+1
until значения целевой функции не стабилизируются
return ct1, . . . , ctK
end
Если d - Евклидово расстояние, а G - min, то SKM представляет собой
алгоритм KMeans. В [1] показано, что SKM обобщает хорошо известные ал-
горитмы кластеризации, такие как FCM [2], EM [3], DA [4], Bergman Soft
Clustering [5].
3.1. Вариант алгоритма SKM для расстояния Махаланобиса
Рассмотрим случай, когда
d(x, c, S) = ln |S| + (x - c)′S-1(x - c)
регуляризованный квадрат расстояния Махаланобиса с ковариационной
матрицей S.2 Поэтому кроме центров кластеров необходимо искать ковариа-
ционные матрицы, ассоциированные с ними. Целевая функция записывается
(
{
})
2 d(x,c, S) = - ln
|S|-1/2 exp
-1(x - c)′S-1(x - c)
2
142
в виде
∑
(
)
(4)
Q(c1, . . . , cK ; S1, . . . , SK ) =
νkGhs
d(xk, c1, S1), . . . , d(xk, cK , SK )
k=1
Чтобы избежать вырождения, добавим дополнительное условие |S| = 1. При
фиксированных значениях S1, . . . , SK центры находятся при помощи алго-
ритма SKM вида:
procedure SKM_M1(X, {ν1, . . . , νN }, {c1, . . . , cK };{S1, . . . , SK })
t←0
repeat
for all j = 1, . . . , K do
νtjk = νkvk(ct1,... ,ctK;S1,... ,SK),
∑
νtjk
ct+1j ←
νtjkxk, где νtjk =
νtj1 + ··· + νtjN
k=1
end for
t←t+1
until значения целевой функции не стабилизируются
return c1, . . . , cK
end
При фиксированных значениях c1, . . . , cK ковариационные матрицы мож-
но найти при помощи следующего алгоритма:
procedure SKM_M2(X, {ν1, . . . , νN }, {S1, . . . , SK };{c1, . . . , cK })
t←0
repeat
for all j = 1, . . . , K do
νtjk = νkvk(c1,... ,cK;St1,... ,StK),
∑
St+1j ←
νtjk(xk - cj)′(xk - cj), где
k=1
νtjk
νtjk =
νtj1 + ··· + νtjN
end for
t←t+1
until значения целевой функции не стабилизируются
return ct1, . . . , ctK
end
143
Для поиска центров и ковариационных матриц применяется метод альтер-
нативных направлений:
procedure SKM_M(X, {ν1, . . . , νN }, {c1, . . . , cK }, {S1, . . . , SK })
s←0
repeat
cs+11, . . . , cs+1K← SKM_M1(X, {ν1, . . . , νN }, {c1, . . . , cK }; {S1, . . . , SK })
Ss+11,... ,Ss+1K← SKM_M2(X,{ν1,... ,νN},{S1,... ,SK};{c1+1,... ,cK+1})
s←s+1
until значения целевой функции не стабилизируются
return (cs1, . . . , csK ),(Ss1, . . . , SsK )
end
4. Проблема выбросов
Алгоритм SKM_MM хорошо справляется с задачей поиска центров кла-
стеров и ковариационных матриц расстояний Махаланобиса, ассоцииро-
ванных с ними, до тех пор, пока в эмпирическом распределении значе-
(
)
ний {D1(x1), . . . , DN (xN )}, где Dk(x) = Ghs
d(xk, c1, S1), . . . , d(xk, cK , SK )
,
не появятся выбросы.
К выбросам можно отнести те данные, которые совершенно (или в доста-
точно большой степени) не соответствуют модели распределения точек. Их
присутствие приводит к искажению положений центров кластеров.
Можно указать две основные причины появления выбросов:
• часть данных (<50 %) содержит существенные ошибки или неустранимые
искажения;
• часть данных (<50 %) подчиняется другому закону распределения, основ-
ная часть (>50 %).
В таких случаях среднее взвешенное среднее арифметическое может сохра-
нять свою устойчивость по отношению к выбросам, если веса точек νk, соот-
ветствующих выбросам, достаточно малы, чтобы предотвратить их влияние
на величину оценки эмпирического среднего. Но на практике изначально веса
примеров, как правило, неизвестны, а поиск значений весов примеров, спо-
собных подавить влияние выбросов, является задачей, сопоставимой по труд-
ности с задачей идентификации самих выбросов. Поэтому естественный вы-
ход из такой ситуации это использование оценок среднего значения, кото-
рые нечувствительны к выбросам. Например, медиана, квантили, усеченные
средние арифметические, винзоризированные средние. Но проблема состоит
в том, что частные производные таких оценок среднего значения имеют син-
гулярные свойства, что создает неустранимое препятствие для применения
градиентных алгоритмов минимизации, которые используются при построе-
нии алгоритмов SKM, SKM_M1, SKM_M2 и SKM_M.
В данной статье для преодоления проблемы выбросов предлагается расши-
рить принцип разбиения на кластеры. Для этого в определении (3) целевой
144
функции Q будем использовать непрерывно-дифференцируемые усредняю-
щие агрегирующие функции, устойчивые к выбросам, вместо взвешенного
среднего арифметического. Теперь
(5)
Q(c1, . . . , cK ) = M{D(x1; c1, . . . , cN ), . . . , D(xN ; c1, . . . , cN
)},
где M{z1, . . . , zN } дифференцируемая усредняющая агрегирующая функ-
ция, нечувствительная к определенной доле выбросов в {z1, . . . , zN },
D(xk; c1, . . . , cN ) = min
d(xk, cj )
1≤j≤K
или
(
)
D(xk; c1, . . . , cN ) = Ghs
d(xk, c1), . . . , d(xk, cK )
Это позволяет расширить описанный выше подход для построения робастных
алгоритмов кластеризации.
Для случая расстояний Махаланобиса
Q(c1, . . . , cK ; S1, . . . , SK ) =
= M{D(x1;c1,...,cK;S1,...,SK),...,D(x1;c1,...,cK;S1,...,SK)}.
Если M среднее арифметическое, то получим задачу, эквивалентную задаче
минимизации (2) и (3).
Далее рассмотрим некоторые способы построения дифференцируемых
усредняющих агрегирующих функций, нечувствительных к определенной до-
ле выбросов.
4.1. Оценки среднего, нечувствительные к выбросам
Оценки среднего, нечувствительные к выбросам, можно построить
несколькими способами.
Первый способ основан на приближении медианы на базе М-средних [6, 7].
Определим М-среднее как решение следующей задачи [8]:
∑
Mρ{r1,... ,rm} = arg min
ρ(rj - s).
s
j=1
Если ρ(r) строго выпуклая функция и ρ(0) = 0, то Mρ усредняющая
агрегирующая функция [9, 10].
Если существует ρ′′(r), то
∂Mρ
ρ′′(rj - r)
=
,
∂rj
ρ′′(r1 - r) + ... + ρ′′(rm - r)
где r = Mρ{r1, . . . , rm}.
145
Второй способ основан на применении цензурированного среднего ариф-
метического, в котором пороговое значение оценивается при помощи сгла-
женного варианта α-квантиля:
∑
1
(6)
WMρ,α{z1,... ,zN} =
min{zk, zρα,},
N
k=1
где ρα(r) - функция, при которой Mρα выступает в качестве приближения
медианы,
αρ(r),
если r > 0,
1(
)
(7)
ρα(r) =
αρ(0+) + (1 - α)ρ(0+)
,
если r = 0,
2
(1 - α)ρ(r),
если r < 0,
является функцией, для которой Mρα {z1, . . . , zN } выступает в качестве при-
ближения α-квантиля.
Частные производные имеют вид
)
∂WMρα
(1
m ∂Mρα
=
[zk < zρα ] +
,
∂zk
N
N ∂zk
где m - число значений zk ≥ zρα . В обоих случаях∂M∂z
≥0и∂M∂z
+...+∂M = 1.∂z
k
1
N
Алгоритм SRKM.
Рассмотрим обобщение путем замены взвешенного среднего арифметиче-
ского в (2) и (3) на дифференцируемые оценки среднего M, определенные
выше.
Градиент Q по cj (1 ≤ j ≤ K) имеет вид
∑
∂Q
∂d
=
νk(c1,... ,cN )vjk(c1,... ,cN )
,
∂cj
∂cj
k=1
где
∂Mρ{r1,... ,rN }
νk(c1,... ,cN ) =
,
rk = D(xk;c1,... ,cN ).
∂rk
Для минимизации (5) запишем алгоритм SRKM (Smooth Robust k-Means) -
обобщение алгоритма SKM.
procedure SRKM({x1, . . . , xN }, {c01, . . . , c0K })
t←0
repeat
νtk = νk(ct1,... ,ctK)
ct+11, . . . , ct+1K← SKM(X, {νt1, . . . , νN }, {ct1, . . . , ctK })
t←t+1
until значения целевой функции не стабилизируются
return ct1, . . . , ctK
end
146
Алгоритм SRKM можно рассматривать как робастный вариант алгоритма
SKM.
В случае применения расстояния Махаланобиса получим вариант SRKM
с применением метода альтернативных направлений для поиска центров и
ковариационных матриц.
procedure SRKM_M({x1, . . . , xN }, {c1, . . . , cK },{S1, . . . , SK })
s←0
repeat
νsk = νk(cs1,... ,csK)
cs+11, . . . , cs+1K← SKM_M1(X, {ν1, . . . , νN }, {c1, . . . , cK }, {S1, . . . , SK })
Ss+11,... ,Ss+1K← SKM_M2(X,{ν1,... ,νN },{c1+1,... ,cK+1},{S1,... ,SK})
s←s+1
until значения целевой функции не стабилизируются
return (cs1, . . . , csK ),(Ss1, . . . , SsK )
end
Нетрудно видеть, что алгоритм SRKM отличается от SKM тем, что на
каждом шаге s вычисляются веса точек νs1, . . . , νsN как частные производ-
ные дифференцируемой робастной оценки среднего значения от минималь-
ных расстояний от точек до ближайшего кластера, вычисляемых при помощи
min или Ghs .
Алгоритм SRKM_M является робастным вариантом SKM_M, которые
представляют собой варианты алгоритмов SRKM и SRKM соответственно,
когда используется расстояние Махаланобиса d(x, c, S), в котором учитыва-
ется ковариационная матрица, с помощью которой может учитываться эл-
липсоидальная форма распределения точек в кластере. В прилагаемых далее
иллюстративных примерах применяется расстояние Махаланобиса.
5. Иллюстративные примеры
Для иллюстрациии возможностей алгоритма SRKM-M рассмотрим ряд
примеров. Они наглядно демонстрируют его способность находить центры,
которые лежат достаточно близко к настоящим центрам кластеров в услови-
ях, когда данные содержат выбросы или когда ищутся центры не всех кла-
стеров, а лишь некоторой части из них. Если в первом случае причиной сме-
щения найденных центров являются выбросы, то во втором случае причиной
смещения являются избыточные кластеры.
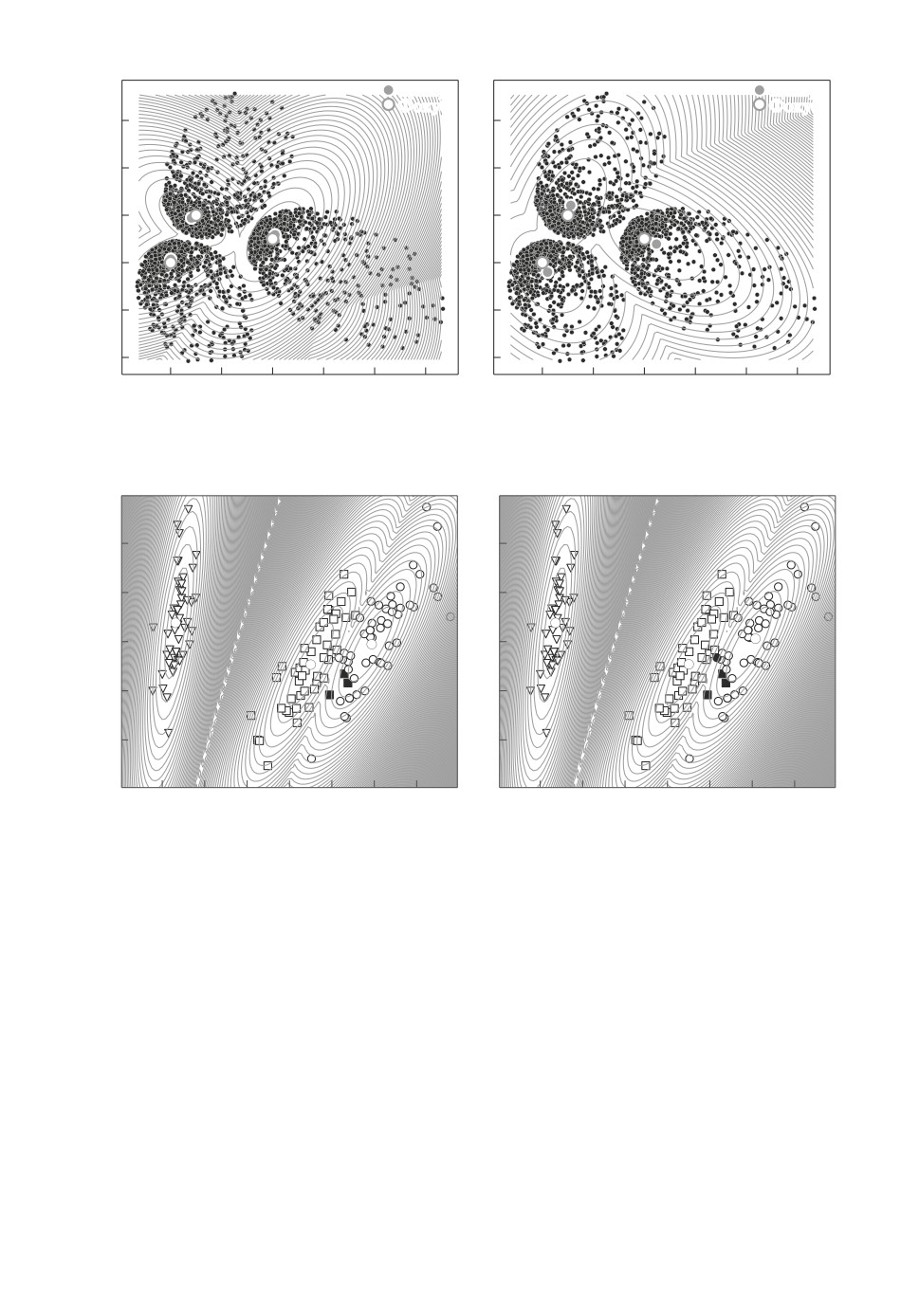
Пример 1. В этом примере сравнивается п√менение алгоритмов SKM_M
и SRKM_M с M-средним Mρα,ε, где ρε(r) =
ε2 + r2, ε = 10-3, для поиска
центров трех кластеров. Здесь расстояние d - Евклидово. Точки искусственно
сгенерированного набора данных принадлежат трем кластерам с несиммет-
ричным распределением расстояний точек кластера от своего центра, которое
имеет эллипсоидную форму с центром в одном из фокусов, плотность рас-
пределения убывает по мере удаления от фокуса. Все кластеры содержат по
147
SRKM-M
SKM-M
Центр
Центр
Фокус
Фокус
60
60
40
40
20
20
0
0
-20
-20
-40
-40
0
20
40
60
80
100
0
20
40
60
80
100
Рис. 1. Применение алгоритмов SKM_M и SRKM-M в примере 1.
SRKM-M
SKM-M
1.0
1.0
0.5
0.5
0
0
-0.5
-0.5
-1.0
-1.0
-3
-2
-1
0
1
2
3
-3
-2
-1
0
1
2
3
Рис. 2. Применение алгоритма SRKM_M и SKM_M в примере 2.
1000 точек. Метод SKM_M выдает центры кластеров, смещенные в направ-
лении противоположного фокуса. Робастный алгоритм SRKM_M с α = 0,4
позволяет найти центры, которые расположены вблизи фокусов, в то время
как алгоритм SKM_M находит центры, которые более удалены от настоя-
щих фокусов эллипсов. Это достигается за счет того, что основная масса то-
чек сосредоточена около фокусов эллипсов. Поиск фокусов эллипсов можно
искать по той части точек, которые как раз находятся около фокусов. Ро-
бастный алгоритм обеспечивает возможность нахождения центра множества
точек, расположенных вблизи фокусов, не испытывая существенного влия-
ния со стороны более удаленных от фокусов точек. Результаты представлены
на рис. 1.
Пример 2. Расcмотрим классический набор данных iris. Как правило,
он используется для задач классификации. Попытаемся идентифицировать
148
Робастный алгоритм
Классический алгоритм
8
8
6
6
4
4
2
2
2
4
6
8
2
4
6
8
Рис. 3. S4: Результаты алгоритмов SRKM_M и SKM_M из примера 3.
100
100
Robust (S)
Robust (S)
Regular (S)
Regular (S)
10-1
10-1
10-2
10-2
10-3
10-3
10-4
10-4
10-5
10-5
10-6
10-6
100
101
102
103
100
101
102
103
Рис. 4. S4: Распределение расстояний до центра ближайшего кластера для
алгоритмов SRKM_M (слева) и SKM_M (справа) из примера 3.
классы при помощи кластеризации, используя расстояния Махаланобиса вме-
сто Евклидового. На рис. 1 представлен результат кластеризации при помощи
алгоритмов SRKM_M и SKM_M. При помощи алгоритма SRKM_M можно
получить разбиение, которое отличается от заданного в 3 точках из 150. При
помощи алгоритма SKM_M можно получить разбиение, которое отличается
от заданного в 4 точках из 150. Хотя преимущество минимальное, но с учетом
того что наилучшие надежные алгоритмы классификации по данным набора
iris как раз дают 98 % точности и выше, то это можно считать хорошим ре-
зультатом. Он показывает, что с применением предложенного здесь подхода
на основе реалистичного набора признаков можно получать разбиения, ко-
торые практически соответствуют естественной классификации. Результаты
представлены на рис. 2.
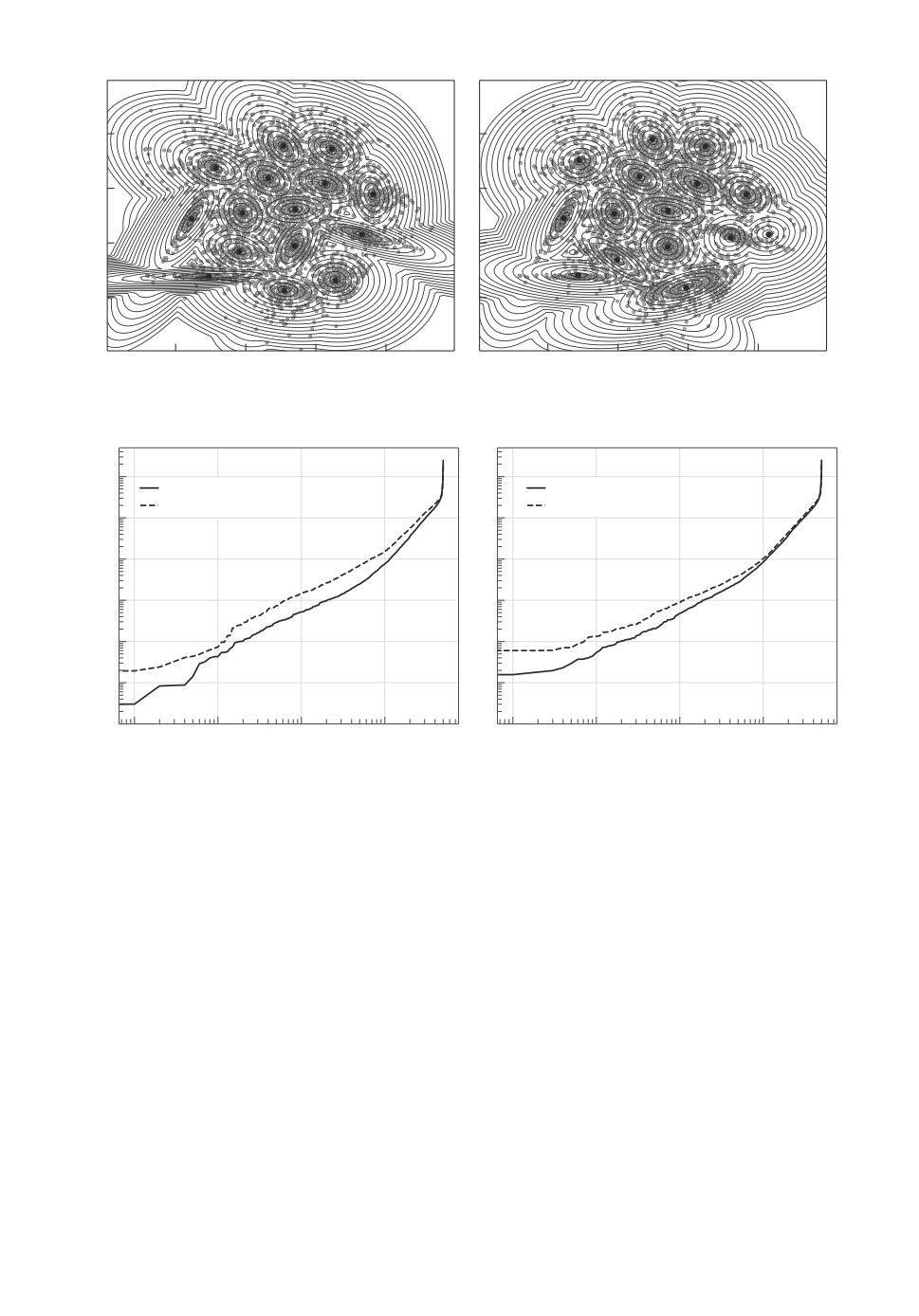
Пример 3. Рассмотрим наборы данных S3-S4 из [11, 12]. Они содержат
5000 точек, 15 кластеров. Среди наборов данных S1-S4 [12] в S4 наблюдается
149
наибольшая вариация в распределении точек на плоскости, что затрудняет
поиск центров кластеров. Именно поэтому он представляет наибольший инте-
рес. Для сравнения приведем результаты применения алгоритмов SRKM_M
и SKM_M. На рис. 3 представлены результаты кластеризации для S4. Рису-
нок 4 иллюстрирует зазоры между распределением расстояний от точкек до
ближайшего к ним кластера. Применение робастного варианта алгоритмов
показывает уменьшение значений расстояний. Он также наглядно иллюстри-
рует увеличение этого зазора при применении алгоритма SRKM_M.
6. Заключение
Применение дифференциуемых оценок среднего значения, нечувствитель-
ных к выбросам, позволило построить новые робастные процедуры поиска
центров кластеров SRKM и SRKM_M, которые обобщают SKM и SKM_M,
позволяя использовать широкий спектр методов поиска среднего значения
как для четкого, так и для нечеткого отнесения точек к кластерам. Предло-
женный метод и алгоритмы SRKM и SRKM_M наследуют структуру ал-
горитмов SKM и SKM_M, однако отличаются методом расчета весов точек.
Особенность предложенного подхода состоит в том, что веса точек вычис-
ляются как значения частных производных дифференцируемой робастной
оценки среднего значения от минимальных расстояний от точек до ближай-
шего кластера, вычисляемых при помощи min или Ghs . В результате веса
точек убывают с ростом модуля разности между соответствующим аргумен-
том робастной усредняющей агрегирующей функции и величиной среднего
значения. Наибольшие значения весов соответствуют точкам, которые соот-
ветствуют аргументам усредняющей агрегирующей функции, которые нахо-
дятся вблизи величины среднего значения. Это объясняет, почему предло-
женный подход способен преодолевать влияние выбросов. Приведенные ил-
люстративные примеры убедительно показывают устойчивость предложен-
ных алгоритмов по отношению к относительно большим объемам выбросов.
СПИСОК ЛИТЕРАТУРЫ
1. Teboulle M. A Unified Continuous Optimization Framework for Center-Based Clus-
tering Method // J. Machine Learning Research. 2007. No. 8. P. 65-102.
2. Bezdek J.C. Pattern Recognition with Fuzzy Objective Function Algorithms. N.Y.:
Plenum Press, 1981.
3. Duda R.O., Hart P.E., Stork D.G. Pattern Classification. John Wiley & Sons, Inc.,
2-nd edition. 2001.
4. Rose K.A, Gurewitz E., Fox C.G. Deterministic annealing approach to clustering //
Pattern Recognition Letters. 1990. V. 11. No. 9. P. 589-594.
5. Banerjee A., Merugu S., Dhillon I.S., Ghosh J. Clustering with Bregman Diver-
gences // J. Machine Learning Research. 2005. No. 6. P. 1705-1749.
6. Mesiar R., Komornikova M., Kolesarova A., Calvo T. Aggregation functions: A
revision / H. Bustince, F. Herrera, J. Montero, eds., Fuzzy Sets and Their Extensions:
Representation, Aggregation and Models. Berlin-Heidelberg: Springer, 2008.
150
7. Grabich M., Marichal J.-L., Pap E. Aggregation Functions. Series: Encyclopedia of
Mathematics and its Applications. No. 127. Cambridge University Press, 2009.
8. Шибзухов З.М. О принципе минимизации эмпирического риска на основе усред-
няющих агрегирующих функций // Докл. РАН. 2017. Т. 476. № 5. С. 495-499.
9. Calvo T., Beliakov G. Aggregation functions based on penalties // Fuzzy Sets and
Systems. 2010. V. 161. No. 10. P. 1420-1436.
10. Beliakov G., Sola H., Calvo T. Practical Guide to Averaging Functions. Springer,
2016.
11. Franti P., Sieranoja S. K-means Properties on Six Clustering Benchmark Datasets //
Applied Intelligence. 2018. V. 48. No. 12. P. 4743-4759.
Статья представлена к публикации членом редколлегии А.А. Лазаревым.
Поступила в редакцию 24.01.2021
После доработки 26.04.2021
Принята к публикации 30.06.2021
151