Автоматика и телемеханика, № 10, 2021
© 2021 г. А.В. ЯМАЕВ (rewin1996@gmail.com)
(МГУ им. М.В. Ломоносова; ООО Смарт Энджинс Сервис, Москва),
М.В. ЧУКАЛИНА, канд. физ.-мат. наук (m.chukalina@smartengines.com)
(Федеральный научно-исследовательский центр
“Кристаллография и фотоника” РАН, Москва;
ООО Смарт Энджинс Сервис, Москва),
Д.П. НИКОЛАЕВ, канд. физ.-мат. наук (d.p.nikolaev@smartengines.com)
(Институт проблем передачи информации РАН, Москва;
ООО Смарт Энджинс Сервис, Москва),
А.В. ШЕШКУС (asheshkus@smartengines.com)
(Федеральный исследовательский центр
“Информатика и управление” РАН, Москва;
ООО Смарт Энджинс Сервис, Москва),
А.И. ЧУЛИЧКОВ, д-р физ.-мат. наук (achulichkov@gmail.com)
(МГУ им. М.В. Ломоносова)
НЕЙРОННАЯ СЕТЬ ДЛЯ ПРЕДВАРИТЕЛЬНОЙ ОБРАБОТКИ
ДАННЫХ В КОМПЬЮТЕРНОЙ ТОМОГРАФИИ1
Предложена легковесная шумоподавляющая фильтрующая нейронная
сеть, которая реализует этап фильтрации в алгоритме томографической
реконструкции свертки и обратного проецирования (FBP). Приведено
обоснование нейросетевой архитектуры, выбранной на основе возможно-
сти аппроксимации с достаточной точностью операции рамп-фильтрации.
Работоспособность сети продемонстрирована на синтетических данных,
которые имитируют томографические проекции, зарегистрированные с
малой экспозицией. При генерации синтетических данных учитывались
квантовая природа рентгеновского излучения, время экспозиции одного
кадра и нелинейный отклик детектора ионизирующего излучения. Время
выполнения реконструкции с использованием предложенной сети в 11 раз
меньше по сравнению с выбранными для сравнения тяжелыми сетями,
при качестве реконструкции по метрике SSIM выше 0,9.
Ключевые слова: низкодозовая компьютерная томография, нейронные се-
ти, UNet, быстрые вычисления.
DOI: 10.31857/S0005231021100123
1. Введение
Рентгеновская компьютерная томография (КТ) является широко исполь-
зуемым неразрушающим методом восстановления внутренней структуры
объекта. В медицине при использовании КТ стремятся минимизировать по-
лучаемую пациентом дозу рентгеновского излучения, но чтобы по резуль-
тату реконструкции врач мог определить патологии и поставить диагноз.
1 Работа выполнена при частичной финансовой поддержке Российского фонда фунда-
ментальных исследований (проекты № 19-01-00790 и № 18-29-26017).
152
Уменьшают получаемую дозу, к примеру, следующими двумя способами:
уменьшением числа измеренных изображений [1, 2] и уменьшением време-
ни экспозиции.
Уменьшение времени экспозиции ведет к увеличению шума на зарегистри-
рованных данных. Как следствие, это приводит к увеличению шума и на ре-
конструкции. Для его подавления используют алгоритмы следующих клас-
сов: на основе статистического анализа [3], нелинейные фильтры [3], итера-
тивные оптимизационные алгоритмы [4] и нейронные сети. Нейронные сети
при зашумленных данных могут выступать в роли операции шумоподавле-
ния после реконструкции (постпроцессинг), в роли операции шумоподавления
на синограмме (препроцессинг) [5] и в роли полноценного оператора рекон-
струкции [6]. Для решения этих задач используют различные нейросетевые
модели, к примеру, сверточные нейронные сети, нейронные сети, работаю-
щие в вейвлет пространстве (шумоподавление постпроцессингом), а также
множество модификаций [7-10] и нейросети Хопфилда (постпроцессинг [11]),
сети, работающие как в пространстве реконструкций, так и в пространстве
измеренных данных, генеративные нейронные сети (шумоподавление пост-
процессингом [12]).
Несмотря на большое разнообразие различных подходов к решению зада-
чи низкодозовой компьютерной томографии, существует мало представите-
лей быстрых нейросетевых методов. Использование быстрых алгоритмов да-
ет возможность производить реконструкцию во время проведения исследова-
ния и, следовательно, останавливать исследование в процессе его проведения
в момент достижения достаточного качества реконструкции для понижения
полученной пациентом дозы [13].
В статье предложен подход, при котором нейронная сеть выполняет опера-
цию фильтрации данных перед этапом обратного проецирования в алгоритме
FBP. Таким образом, нейронная сеть выступает не только в качестве филь-
тра перед обратным проецированием, но и в качестве шумоподавляющего
алгоритма. В статье показано, что фильтр в алгоритме FBP можно заме-
нить одним сверточным слоем сети. Нейронная сеть, выполняющая функ-
цию фильтрации данных, позволяет уменьшить объем вычислений и повы-
сить точность реконструкции. Для обучения нейронной сети использовалась
функция потерь в виде суммы по обучающей выборке {xi, yi}
∑
(1)
Loss = - SSIM(yi, BP (F (xi
,v))),
i
где F - функция нейронной сети, xi - зашумленная синограмма, подающаю-
ся на вход нейронной сети и полученная из проекций с малыми временами
экспозиций, v - параметры и веса нейронной сети, BP - операция обратно-
го проецирования, yi - фантом, послуживший основой для создания сино-
граммы xi, SSIM (Structure Similarity) - метрика структурного подобия [14].
Метрика SSIM была выбрана по причине того, что проведенные экспери-
менты показали значительное увеличение качества результатов работы сети
после обучения по этой метрике, чем при обучении по метрике L2. Архитек-
153
тура предложенной нейронной сети основана на модификации архитектуры
UNet [15] и свойствах FBP алгоритма и описана в разделе 4. Таким обра-
зом, в настоящей статье предлагается обоснованная архитектура нейронной
сети, используется специально подобранная под задачу функция потерь и об-
суждаются полученные в ходе работы результаты, которые сравниваются с
другими обученными нейросетевыми моделями на синтетических данных.
Обобщая изложенное, выделим основную новизну предлагаемого подхода.
Во-первых, использование одномерной нейронной сети приводит к независи-
мости алгоритма от угловой схемы измерения, что аналитически невозмож-
но для обычных двумерных сетей по типу UNet. Во-вторых, использование
SSIM функции потерь. Использование этой функции потерь повышает мет-
рику PSNR и SSIM в финале обучения по сравнению c использованием сред-
неквадратичной функции потерь.
Статья организована следующим образом: в разделе 2 приводится обос-
нование минимальных требований к фильтрующей синограмму нейросетевой
архитектуре, в разделе 3 описывается процесс генерации синтетических дан-
ных, используемых для обучения и проверки нейросетевых моделей, в раз-
деле 4 приводится предлагаемая в этой статье нейросетевая архитектура, в
разделе 5 описываются и объясняются результаты сравнительных экспери-
ментов, заключение находится в разделе 6.
2. Нейросетевая аппроксимация рамп-фильтра
Каждое измеренное изображение представляется как результат операции
Радона над некоторым неизвестным объемом плотностей объекта при некото-
ром заданном угле. Операция Радона - это интегральная сумма вдоль задан-
ного луча. Для двумерной реконструкции, рассматриваемой в этой статье,
координаты луча задаются полярной системой координат (r, φ). И соответ-
ственно измеренные изображения являются одномерными и зависят только
от координаты r. Такие измеренные изображения называются проекциями.
Набор проекций же называется синограммой. Для восстановления неизвест-
ного объема плотностей широко используют алгоритм свертки и обратного
проецирования (FBP, Filtered Back Projection). Он состоит из двух шагов:
(Filter) фильтрация проекций и (Back Projection) обратное проецирование,
представимое в виде транспонированного оператора Радона. FBP алгоритм
можно представить в операторном виде
(2)
FBP(Sin) = BP(FT-1
(h(w) ∗ F T (Sin))),
где BP - обратное проецирование, Sin - синограмма, h(w) - рамп-фильтр,
FT - одномерное фурье преобразование вдоль r. При этом рамп-фильтр име-
ет вид в частотной области
|w|
(3)
h(w) =
,
W
где w - частота, W - нормировочный коэффициент, обычно принимаемый
вид максимальной частоты дискретного преобразования Фурье, примененно-
154
1,0
0,8
0,6
0,4
0,2
0
-0,2
-0,4
-20
-10
0
10
20
Пиксели ядра свертки
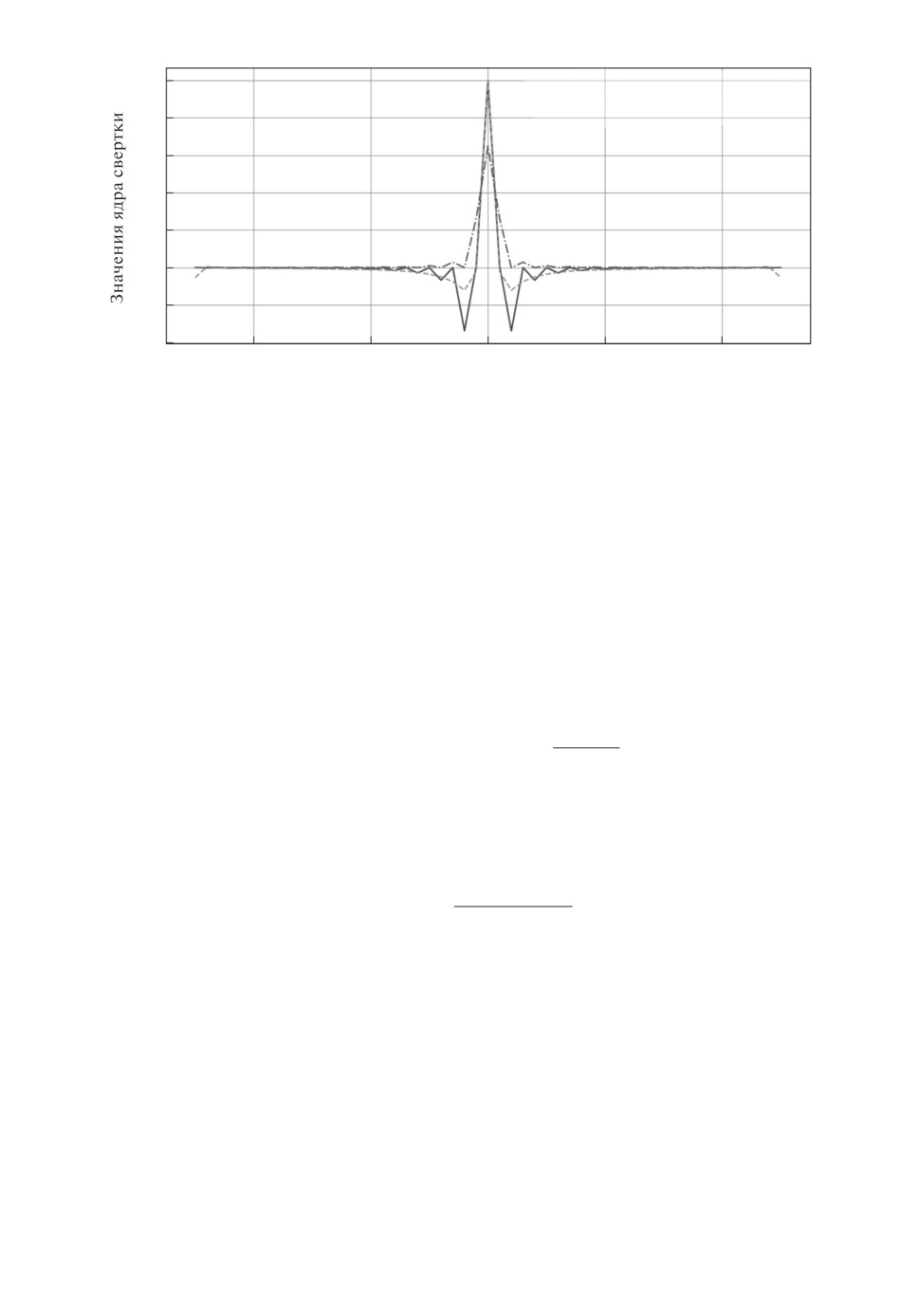
Рис. 1. Ядра свертки рамп-фильтра из приближения и нейросетевого обучения.
го к исходным данным синограммы. Основные особенности этого алгоритма -
простота реализации и скорость работы.
Следуя операторному виду F BP , F T-1(h(w) ∗ F T (Sin)) представимо в
виде операции свертки
(4)
(H ∗ Sin)(x),
где H(x) - представление рамп-фильтра в пространстве синограммы имеет
интегральный вид
∫∞
∫
∞
|w|eixw
(5)
H(x) = h(w)eixw dw =
dw.
W
-∞
-∞
Поскольку этот интеграл расходящийся, то используют различные его
приближения [16]. Одним из них является формула
1 + cos(Wx)
(6)
H(x) = W2
π2 - x2W2
На рис. 1 в соответствии с (6) сплошной линией изображено приближен-
ное ядро свертки, штриховой линией изображено обученное ядро свертки и
штрихпунктирной линией обратное Фурье преобразование рамп-фильтра.
Однако FBP является точным решением только для случая непрерывной
незашумленной синограммы [17]. Реальные же данные зашумлены и имеют
дискретный вид, что делает нецелесообразным использование FBP для полу-
чения высокой точности реконструкций. Однако также следуя изложенному,
реконструирующий алгоритм должен иметь возможность с определенно за-
данной точностью повторить рамп-фильтр. Исследуя свойства стандартных
нейросетевых слоев, авторы настоящей статьи пришли к выводу, что рамп-
фильтр локализован и с некоторой точностью может быть воспроизведен
155
100
10-1
10-2
0,001738
10-3
10-4
10-5
0
25
50
75
100
125
150
175
Ширина обученного ядра свертки в пикселях
Рис. 2. Нормированный график зависимости среднеквадратичной ошибки обу-
ченной линейной одномерной свертки от ширины ядра свертки.
1 пиксель
25 пикселей
0
0
25
25
50
50
75
75
100
100
125
125
150
150
175
175
0
50
100
150
0
50
100
150
51 пиксель
FBP
0
0
25
25
50
50
75
75
100
100
125
125
150
150
175
175
0
50
100
150
0
50
100
150
Рис. 3. Реконструкции, полученные при фильтрации синограмм обученными
свертками различного размера.
156
обученной сверткой меньшего размера. Обучая свертки различного разме-
ра, от одного пикселя детектора до полного покрытия синограммы, была по-
лучена зависимость среднеквадратичной ошибки повторения сверткой рамп-
фильтра от ширины ядра используемой свертки. График этой зависимости
приведен на рис. 2. Данные для обучения состояли из синограмм и фильтро-
ванных синограмм, построенных от фантомов из раздела 3 и фильтрованных
рамп функцией наборов псевдо-дельта функций.
Визуально пропало различие в реконструкциях примерно при свертке раз-
мером в 51 пиксель детектора. На основе данных рис. 2 и 3 было решено счи-
тать рецептивное поле в 50-51 пиксель проекции достаточным для аппрокси-
мации рамп-фильтра. Веса обученной свертки в выбранной точке показаны
на рис. 1. Из этого следует, что нейронные сети со сверточной архитектурой,
покрывающей рецептивным полем не менее 51 пикселя проекции, могут быть
использованы как фильтрующие нейронные сети.
3. Генерация данных
Для генерации обучающих данных использовался пакет Adler [18]. Па-
кет позволяет моделировать двумерные изображения наложенных друг на
друга эллипсов. Были выбраны только изображения с неотрицательными
яркостями.
Синограммы строились с помощью пакетов ODL [18] и Astra Toolbox [19]
и зашумлялись на основе квантовых свойств излучения. Синограммы имели
ширину в 183 пикселей детектора и 128 углов, распределенных от 0◦ до 180◦
градусов (не включая 180◦). Зашумленные синограммы использовались как
входные данные нейронной сети.
Процедура зашумления происходила по следующей схеме. Выбира-
лась интенсивность maxI и вычислялась дисперсия аддитивного шума
sigma = maxI/100 000. На основе квантовой природы рентгеновского излу-
чения и его пуассоновского поведения рассчитывается зашумленная сино-
грамма по формулам
(7)
Se = maxI ∗ e-S,
где S - незашумленная синнограмма,
(8)
S′e = P(Se
) + N(0,sigma),
где P и N - пуассоновские и нормальные случайные распределения соответ-
ственно,
(9)
I′0
= P(maxI) + N(0,sigma),
(10)
S′ = log I′0 - log S′e,
где S′ - синограмма, искаженная случайным шумом. Зашумленная и неза-
шумленная синограммы и их реконструкции показаны на рис. 4. Всего было
набрано 20 000 тренировочных синограмм, 5 % из которых были выделены
под валидацию. Все используемые в статье нейронные сети обучались на од-
них и тех же тренировочных данных.
157
0
0
20
20
3,0
40
40
4
60
60
2,5
80
80
100
100
3
2,0
120
120
0
50
100
1
50
0
50
100
0
0
1,5
2
20
20
40
40
1,0
60
60
1
80
80
0,5
100
100
120
0
120
0
50
100
150
0
50
100
Пиксели детектора
Рис. 4. Примеры данных, используемых в обучении. Слева - незашумленная
и зашумленная синограммы, справа - результаты реконструкции.
4. Предлагаемый подход
В медицине требуется быстро обрабатывать данные, что мотивирует ис-
пользовать одномерные модели вместо двумерных, так как они требуют мень-
шего объема вычислений при увеличении размерности, чем большинство дву-
мерных моделей. В настоящей статье была разработана одномерная нейрон-
ная сеть, принимающая на вход строки синограммы.
Структура модели была основана на UNet-архитектуре, в которой все дву-
мерные свертки заменены на одномерные. При этом количество слоев UNet-
архитектуры было подобрано так, чтобы рецептивное поле нейронной сети со-
ставляло примерно, но не меньше, 50 пикселей детектора. Как было показано
в разделе 2, такого по ширине рецептивного поля достаточно для выполне-
ния операции рамп-фильтрации. Архитектура сети показана на рис. 5. UNet
часто применяется для задач сегментации, шумоподавления или преобразо-
вания изображения. Более того, для UNet-архитектур характерны высокая
обучаемость на небольшом количестве данных и высокая скорость работы.
На основе этих характеристик UNet в одномерном виде была выбрана как
целевая архитектура.
5. Результаты
Основываясь на том, что рамп-фильтр можно с достаточной точностью ап-
проксимировать локализованной одномерной сверткой, в статье вместо филь-
тра в FBP для реконструкции зашумленных данных применялись легковес-
ные нейронные сети.
В качестве исследуемых моделей были взяты: линейная одномерная сверт-
ка (рис. 6), трехслойная сверточная одномерная нейронная сеть (рис. 7),
UNet-подобная одномерная архитектура (рис. 5). Эти сети сравниваются по
158
Рис. 5. Изображение архитектуры предложенного одномерного UNet, где в
обозначение к Conv первое число - это высота по Y ядра свертки, второе
число - это ширина по X ядра свертки, третье число - количество каналов
выхода слоя.
Рис. 6. Изображение архитектуры сети из одной линейной одномерной свертки.
Рис. 7. Изображение архитектуры трехслойной нейронной сверточной одно-
мерной сети.
159
Рис. 8. Изображение архитектуры UNet.
Таблица 1. Таблица с результатами различных архитектур
Трехслойная
Линейная
Нейронная сеть
FBP
нейронная
UNet 1D UNet
свертка
сеть
Количество умножений
0
8,35 · 105
2,62 · 107
2,89 · 108
1,72 · 109
на одну синограмму
Ширина рецептивная
183 × 128
51
50
50
50 × 50
поля
Количество обучаемых
0
52
1 633
46400
1 125633
параметров
Количество умножений
0
16069
16053
6 237
1 530
на один параметр
PSNR
25
24,5
31,35
33,29
34,03
SSIM
0,5086
0,6143
0,8544
0,9058
0,9223
Время работы, мс
44
21
81
111
100
Таблица 2. Таблица с результатами нейронной сети из LPDR, обученной методом
из этой статьи и с полученной в статье LPDR
Нейронная сеть
LPDR
LPDR (SSIM)
Количество умножений на одну синограмму
4,11 · 109
4,11 · 109
Ширина рецептивная поля
183 ×128
183 ×128
Количество обучаемых параметров
251980
251980
Количество умножений на один параметр
16292
16292
PSNR
38,73
35,49
SSIM
0,9635
0,9581
Время работы, мс
1214
1214
160
0
0
1,0
0
a
0,08
б
в
20
0,07
20
20
0,4
0,8
0,06
40
40
40
0,3
0,05
0,6
60
60
60
0,04
0,4
0,2
80
0,03
80
80
0,02
100
100
0,2
100
0,1
120
0,01 120
120
0
0
0
0
20 40 60 80 100120
0
20 40 60 80 100120
0
20
40 60 80 100120
0
0
0
г
д
е
0,5
0,5
20
0,5
20
20
40
0,4
40
0,4
40
0,4
60
0,3
60
0,3
60
0,3
80
80
80
0,2
0,2
0,2
100
100
100
0,1
0,1
0,1
120
120
120
0
0
0
0
20 40
60 80 100120
0
20 40 60 80 100120
0
20
40 60 80 100120
0
0
0,5
ж
0,5
з
20
20
0,4
0,4
40
40
0,3
60
0,3
60
0,2
80
0,2
80
100
0,1
100
0,1
120
120
0
0
0
20 40 60 80 100120
0
20 40 60 80 100120
Рис. 9. Результаты различных реконструкций: a - фантом, б - FBP рекон-
струкция, в - линейная свертка, г - трехслойная сеть, д - UNet1D, е - UNet,
ж - LPDR, з - LPDR (SSIM функция потерь).
эффективности с двумерными сетями: UNet (рис. 8) и нейросетевой моделью
из статьи Learned Primal Dual Reconstruction (LPDR) [6]. Результаты обуче-
ния нейронных сетей, а также измеренные характеристики выбранных ар-
хитектур представлены в табл. 1 и 2. Результаты реконструкций с помощью
сравниваемых архитектур показаны на рис. 9.
При этом размеры сверток в трехслойной нейронной сети, одномерной
UNet, двумерной UNet были подобраны так, чтобы рецептивные поля сетей
составляли не менее 50 пикселей детектора в ширину, так как эта ширина
достаточна для выполнения операции рамп-фильтрации. Также трехслойная
нейронная сеть добавлена в сравнение как один из простейших возможных
сверточных нейросетевых алгоритмов.
Согласно данным табл. 1 двумерная UNet является лучшей по метрикам
PSNR и SSIM. Однако ее преимущества перед более простой UNet1D незна-
чительны. Несмотря на то что использование SSIM в функции потерь вместо
L2 улучшило PSNR и SSIM метрики для всех сетей из табл. 1, в эксперимен-
тах использование этой функции потерь не улучшило результаты для LPDR
161
а Фантом
б FBP
в UNet1D
0
0
0
0,07
20
20
20
0,06
40
40
40
0,05
60
60
60
0,04
0,03
80
80
80
0,02
100
100
100
0,01
120
120
120
0
0
20
40
60
80 100 120
0
20
40
60
80 100 120
0
20
40
60
80 100 120
г Срез реконструкции
д Разница между FBP
е Разница между UNet1D
от FBP и UNet1D
и фантомом
и фантомом
0
0
UNet1D
0,07
FBP
20
20
0,06
40
40
0,05
0,04
60
60
0,03
80
80
0,02
100
100
0,01
0
120
120
0
20 40 60 80 100120
0
20
40
60
80 100 120
0
20
40
60
80 100 120
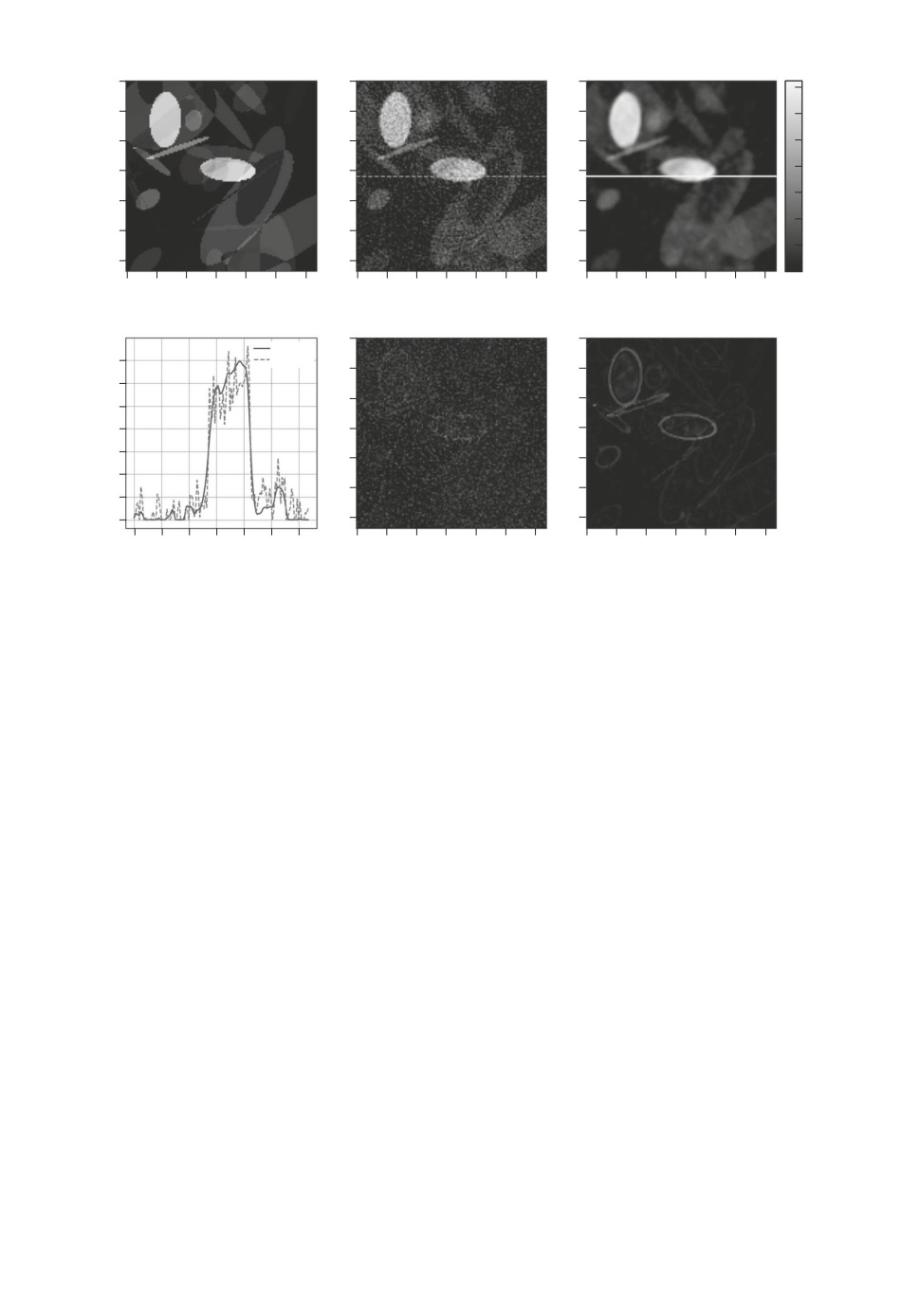
Рис. 10. Анализ ошибки предложенной UNet1D модели: а - фантом для про-
верки, б - FBP реконструкция, в - реконструкция предложенным в статье
подходом, г - срезы реконструкций б и в, отмеченные штриховой и сплошной
линиями соответственно, д - абсолютная разница между FBP реконструкцией
и фантомом, е - абсолютная разница между реконструкцией предложенным
в статье методом и фантомом. Все полутоновые картинки выполнены в одной
шкале значений, указанной справа.
сети, как видно из табл. 2. Время работы нейронных сетей считалось исклю-
чительно на процессоре без использования видеокарты, включая требуемые
для реконструкции операции преобразования Радона.
На рис. 9 видно, что при использовании UNet1D отсутствует однородный
высокочастотный шум, однако границы объектов имеют однопиксельное раз-
мытие. Такие артефакты размытия, очевидно, отсутствуют в LPDR сети, это
связано с отсутствием в UNet1D каких-либо нейронных слоев в пространстве
реконструкций, которые бы поправили недостатки метода обратного проеци-
рования.
Нейросеть, код для запуска нейросети и примеры синтетических данных
доступны по ссылке
6. Заключение
В статье предложен метод фильтрации зашумленной синограммы для за-
дачи низкодозовой компьютерной томографии. Основная идея метода заклю-
162
чается в применении нейронной сети перед выполнением оператора обрат-
ного проецирования. Показано, что рамп-фильтр возможно заменить с до-
статочной точностью на один одномерный сверточный слой нейронной сети,
размер рецептивного поля которого равен 51 пикселю одномерного детек-
тора при ширине рецептивного поля в 183 пикселя детектора. Добавление
еще нескольких слоев позволяет подавлять шум, возникающий вследствие
сокращения времени экспозиции при регистрации одного томографического
изображения. Таким образом, построенная в статье одномерная нейронная
сеть заменила фильтр в алгоритме FBP, обучаясь на невязке реконструкции
с фантомом по метрике SSIM и обогнав оригинальный FBP оператор. Ис-
следование результатов работы сети проведено на синтетических данных и
сравнивалось с широко используемыми нейросетевыми архитектурами. По-
казано, что предложенный подход производит реконструкцию с точностью
выше 0,9 по метрике SSIM в среднем. Кроме того, при таком подходе вре-
мя выполнения реконструкции на CPU в среднем в 11 раз меньше, чем при
использовании LPDR. Также показана эффективность использования опера-
тивной памяти вычислительного устройства при использовании описанного
одномерного подхода по сравнению с рассматриваемыми двумерными сетями.
СПИСОК ЛИТЕРАТУРЫ
1.
Hu Z., et al. An Improved Statistical Iterative Algorithm for Sparse-view and
Limited-angle CT Image Reconstruction // Scientific reports. 2017. V. 7. No. 1.
P. 1-9.
2.
Swensen S.J., et al. Screening for Lung Cancer with Low-dose Spiral Computed
Tomography // Amer. J. Respiratory and Critical Care Medicine. 2002. V. 165.
No. 4. P. 508-513.
3.
Thanh D., et al. A Review on CT And X-ray Images Denoising Methods // Infor-
matica. 2019. V. 43. No. 2.
4.
Johnson C.A., Sofer A. A Data-parallel Algorithm for Iterative Tomographic Image
Reconstruction // Proc. Frontiers’ 99. Seventh Sympos. on the Frontiers of Massively
Parallel Computation. IEEE, 1999. P. 126-137.
5.
Yang H.K., et al. Slice-wise Reconstruction for Low-dose Cone-beam CT Using a
Deep Residual Convolutional Neural Network // Nuclear Science and Techniques.
2019. V. 30. No. 4. P. 1-9.
6.
Adler J., Oktem O. Learned Primal-dual Reconstruction // IEEE Trans. Medical
Imaging. 2018. V. 37. No. 6. P. 1322-1332.
7.
Mizusawa S., et al. Computed Tomography Image Reconstruction Using Stacked
U-Net // Computerized Medical Imaging and Graphics. 2021. V. 90. P. 101920.
8.
Han Y., Ye J.C. Framing U-Net via Deep Convolutional Framelets: Application to
Sparse-view CT // IEEE Trans. Medical Imaging. 2018. V. 37. No. 6. P. 1418-1429.
9.
Nakai H., et al. Quantitative and Qualitative Evaluation of Convolutional Neural
Networks with a Deeper U-net for Sparse-view Computed Tomography Reconstruc-
tion // Academic radiology. 2020. V. 27. No. 4. P. 563-574.
10.
Zhu L., et al. Metal Artifact Reduction for X-ray Computed Tomography Using
U-net in Image Domain // IEEE Access. 2019. V. 7. P. 98743-98754.
163
11. Cierniak R. A 2D Approach to Tomographic Image Reconstruction Using a Hopfield-
type Neural Network // Artificial Intelligence in Medicine. 2008. V. 43. No. 2.
P. 113-125.
12. Yang Q., et al. Low-dose CT Image Denoising Using a Generative Adversarial Net-
work with Wasserstein Distance and Perceptual Loss // IEEE Trans. Medical Imag-
ing. 2018. V. 37. No. 6. P. 1348-1357.
13. Bulatov K., et al. Monitored Reconstruction: Computed Tomography as an Anytime
Algorithm // IEEE Access. 2020. V. 8. P. 110759-110774.
14. Hore A., Ziou D. Image Quality Metrics: PSNR vs. SSIM // 2010 20th international
conference on pattern recognition. IEEE, 2010. P. 2366-2369.
15. Kofler A., et al. A U-Nets Cascade for Sparse View Computed Tomography // Int.
Workshop on Machine Learning for Medical Image Reconstruction. Springer, Cham,
2018. P. 91-99.
16. Wei Y., Wang G., Hsieh J. An Intuitive Discussion on the Ideal Ramp Filter in
Computed Tomography (I) // Comput. Math. Appl. 2005. V. 49. No. 5-6. P. 731-740.
17. Kak A.C., Slaney M., Wang G. Principles of Computerized Tomographic Imaging.
2002.
18. Adler J., Kohr H.,
Öktem O. ODL
a Python Framework for Rapid Pro-
totyping in Inverse Problems. 2017. Code and documentation available online:
19. Van Aarle W., et al. The ASTRA Toolbox: A Platform for Advanced Algorithm
Development in Electron Tomography // Ultramicroscopy. 2015. V. 157. P. 35-47.
Статья представлена к публикации членом редколлегии А.А. Лазаревым.
Поступила в редакцию 24.01.2021
После доработки 01.06.2021
Принята к публикации 30.06.2021
164