Автоматика и телемеханика, № 10, 2022
© 2022 г. Д.С. ОБУХОВ (bstodin@gmail.com)
(Новосибирский государственный технический университет)
КЛОНИРОВАНИЕ И КОНВЕРСИЯ ПРОИЗВОЛЬНОГО
ГОЛОСА С ИСПОЛЬЗОВАНИЕМ ГЕНЕРАТИВНЫХ ПОТОКОВ
С целью повышения качества формируемого речевого сигнала в дан-
ной работе предложен способ учета переменной во времени информации о
спикере. Благодаря этой технике система синтезирует более естественную
речь голосом, похожим на заданный целевой голос, как в задаче клони-
рования голоса, так и в задаче конверсии голоса.
Ключевые слова: клонирование голоса, конверсия голоса, синтез речи, по-
токовые генеративные модели, эмбеддинги спикера, частота основного
тона.
DOI: 10.31857/S0005231022100087, EDN: AKGYHA
1. Введение
В настоящее время сфера применения синтеза речи стремительно расши-
ряется и уже нашла свое применение в области медицины [1, 2], в голосовых
колонках, умных ассистентах и других окружающих человека умных устрой-
ствах [3, 4], а также в различных задачах бизнеса [5, 6]. Одним из актуаль-
ных направлений развития синтеза речи сегодня является синтез голосом
произвольного человека [7]. Умение генерировать речь с заданным голосом
является необходимым требованием для ряда задач, например, диалоговых
систем.
Современные подходы на основе глубокого обучения позволили эффектив-
но и качественно формировать естественную речь голосом одного заданного
диктора, представленного в наборе данных обучения. Предложенные недав-
но техники позволяют учитывать несколько дикторов при обучении, одна-
ко множество голосов, которыми формируется речь, по-прежнему остается
ограниченным. Построение систем клонирования и конверсии произвольно-
го голоса становится следующим вызовом в области формирования речевых
сигналов.
Задача клонирования голоса подразумевает использование заданного об-
разца речи человека для синтеза таким же голосом речевого сигнала с произ-
вольным содержанием, заданным текстом [8]. Важной отличительной чертой
клонирования голоса от обычного синтеза речи является то, что обученная
модель может синтезировать речь голосами даже тех спикеров, которые не
были представлены в наборе данных обучения.
Задача конверсии голоса заключается в преобразовании аудиосигнала с
голосом исходного спикера в аудиосигнал с тем же лингвистическим содер-
жанием, т.е. произнесенным текстом, но с произношением голосом целевого
80
спикера [9]. В зависимости от того, с какими голосами система может рабо-
тать, конверсия голоса подразделяется на: один к одному, несколько к одному,
несколько к нескольким, много к нескольким, много ко многим. Наибольший
интерес представляет конверсия много ко многим, поскольку при таком типе
конверсии происходит преобразование аудиосигнала с произвольными исход-
ным и целевым голосами.
В совокупности задачи клонирования и конверсии голоса обеспечивают
полный набор возможностей по преобразованию голоса речи как для слу-
чая, когда исходная речь имеет текстовое представление, так и для случая,
когда исходная речь задана в виде аудиосигнала.
За счет техники, предложенной в [10], которая заключается в использо-
вании открытых представлений, так называемых эмбеддингов спикера, со-
держащих информацию о скрытых характеристиках спикера, многоголосый
синтез речи можно обобщить на клонирование голоса. Современные системы
синтеза речи имеют нейросетевую архитектуру [11], как правило, на основе
трансформеров [12-14] и генеративных потоков [15-17]. Модели на основе ге-
неративных потоков ко всему прочему позволяют выполнять задачу конвер-
сии голоса за счет применения обратимых преобразований. Для построения
системы, способной выполнять и синтез речи, и конверсию голоса, в настоя-
щей работе предлагается использовать нейросетевую архитектуру на основе
генеративных потоков с использованием открытых эмбеддингов спикера.
В [16, 17] авторы также используют генеративные потоки и обращают
внимание на возможность выполнения конверсии голоса. Модели с исполь-
зованием генеративных потоков недавно показали впечатляющие результаты
в области синтеза речи, позволяя формировать разнообразные произнесения
заданного текста. Однако в этих работах авторы делают основной акцент на
качественный синтез речи голосом одного заданного диктора. Кроме того,
работы [16, 17] без дополнительных модификаций не предусматривают воз-
можность клонирования голоса. В отличие от [16, 17] решение, предложенное
в настоящей работе, позволяет выполнять и клонирование голоса, и конвер-
сию голоса.
Одним из недостатков моделей на основе генеративных потоков [16, 17] яв-
ляется монотонность синтезированной речи. Ранее в [12] было показано, что
учет основного тона позволяет добиться более совершенного произношения
заданным голосом. Частота основного тона является характеристикой спике-
ра, которая, будучи переменной во времени и зависящей от лингвистического
содержания речи, дополняет эмбеддинги спикера. В архитектурах моделей
синтеза речи, предложенных в [12, 14], используется информация о частоте
основного тона. Однако [12, 14] это трансформерные архитектуры, которые
лишены возможности конверсии голоса, поэтому предложенный в этих рабо-
тах подход хоть и может быть реализован в решениях на основе генеративных
потоков, но не позволяет учитывать питч сигнала при выполнении конверсии
голоса.
Предложенный в данной работе подход на основе потоковых генеративных
моделей позволяет выполнять задачу клонирования голоса за счет исполь-
зования полученных из внешней системы вещественных векторов фиксиро-
81
ванной размерности, содержащих информацию о спикере, т.н. эмбеддингов
спикера. За счет своих архитектурных возможностей генеративные потоки
позволяют одновременно с этим решать задачу конверсии голоса, таким об-
разом обеспечивая полный набор возможностей по преобразованию голоса
речи как для случая, когда исходная речь имеет текстовое представление,
так и для случая, когда исходная речь задана в виде аудиосигнала. С целью
улучшения конверсии голоса в настоящей работе предложен новый способ
учета частоты основного тона.
Таким образом, вклад автора в данной работе следующий:
объединены предложенные техники использования внешних эмбеддин-
гов спикера и декодировщика на основе генеративных потоков для со-
здания модели, способной одновременно выполнять задачи синтеза речи
несколькими голосами, клонирования голоса и конверсии голоса;
предложен новый способ учета информации о частоте основного тона
для задач синтеза речи, клонирования и конверсии голоса для решений
на основе генеративных потоков.
Структура работы следующая: во втором разделе приведена архитектура
предложенной модели и описан процесс ее обучения, также описана матема-
тическая модель, которая лежит в основе генеративных потоков. В третьем
разделе описан процесс выполнения клонирования голоса. В четвертом раз-
деле описан процесс выполнения задачи конверсии голоса. В пятом разделе
описаны возможные техники и предложен новый подход для учета инфор-
мации о частоте основного тона. В шестом разделе приведены результаты
экспериментов. Заключение дано в седьмом разделе.
2. Архитектура модели
Предложенная система для выполнения синтеза речи, а также клонирова-
ния и конверсии голоса схематично изображена на рис. 1. На этом рисунке
синим цветом показан сценарий синтеза речи и клонирования голоса, оранже-
Целевое
Исходное
Синтез.
Текст
Аудио
Аудио
Аудио
Модель
Short-time
Нормализация,
эмбеддингов
Fourier
Вокодер
Фонемизация
спикера
transform
Двунаправленный
декодировщик
Кодировщик
Внутреннее
представление
Рис. 1. Архитектура предложенной системы для выполнения синтеза речи,
клонирования и конверсии голоса.
82
вым цветом показан сценарий конверсии голоса, красным цветом обозначены
преобразования, относящиеся ко всем сценариям.
Технически, в предложенном подходе синтез речи и клонирование голо-
са выполняются одинаково, разница лишь в том, что при выполнении кло-
нирования голоса для получения эмбеддинга спикера используется целевое
аудио с голосом спикера, который не встречался в данных обучения модели.
Таким образом, при выполнении сценария синтеза речи и клонирования го-
лоса, текст нормализуется, т.е. приводится к упрощенному формату за счет
раскрытия чисел, сокращений и пр., и фонемизируется, т.е. преобразуется
в последовательность звуков, соответствующих произнесению этого текста.
Затем последовательность фонем подается на вход в кодировщик, после чего
полученное внутреннее представление декодируется с использованием эмбед-
динга, полученного из целевого аудиосигнала. На последнем шаге полученная
спектрограмма преобразуется в аудиосигнал. Подробнее сценарий клониро-
вания голоса описан в разделе 3.
Сценарий конверсии голоса выполняется другим образом. Спектрограмма
исходного аудиосигнала декодируется в обратном направлении с использо-
ванием эмбеддинга спикера, полученного из этого же сигнала, а затем по-
лученное внутреннее представление декодируется в прямом направлении с
использованием эмбеддинга, полученного из целевого сигнала. Полученная
спектрограмма преобразуется в аудиосигнал. Подробнее сценарий конверсии
голоса описан в разделе 4.
Два важных свойства обеспечивают выполнение описанного сценария. Во-
первых, внутреннее представление не зависит от характеристик спикера, а
зависит только от лингвистического содержания. Во-вторых, декодировщик
является двунаправленным. Это означает, что в прямом направлении деко-
дировщик преобразует внутреннее представление в спектрограмму, а в обрат-
ном направлении, наоборот, преобразует спектрограмму во внутреннее пред-
ставление, причем эти преобразования происходят без потерь. Далее по ходу
этого раздела будет показано, за счет чего данные свойства достигаются.
На приведенной схеме верхние четыре блока не являются обучаемыми.
Это либо детерминированные преобразования, как в случае с нормализацией
текста и преобразованием Фурье, либо преобразования, выполненные предоб-
ученными моделями. Для корректной работы предложенной системы требу-
ется обучить центральную часть акустическую модель, которая включает
кодировщик и декодировщик, а также несколько дополнительных модулей.
Предложенная акустическая модель состоит из нескольких основных мо-
дулей: текстовый кодировщик, потоковый декодировщик и модуль предска-
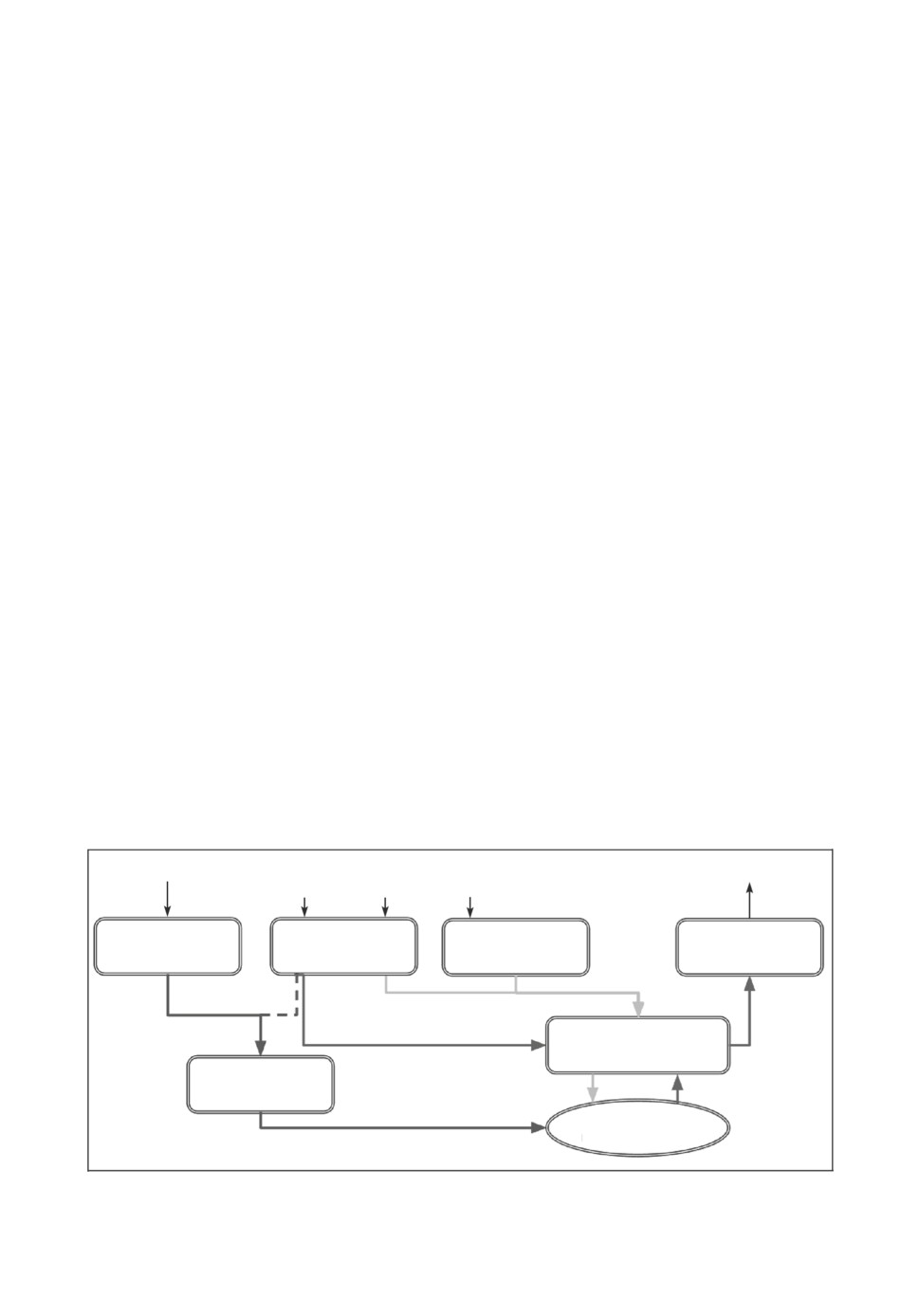
зания продолжительностей произнесения фонем. На рис. 2 приведена схема
взаимодействия этих компонент во время обучения системы. В описанной
схеме обучения рассматривается случай, когда дополнительная информация
о частоте основного тона не используется. Подходы учета этой информации
описаны в разделе 5.
Текстовый кодировщик отображает последовательность токенов фонем
x = x1:Ttext в скрытое векторное представление h = h1:Ttext. После тексто-
вого кодировщика два линейных слоя используются для получения стати-
83
Рис. 2. Схема обучения предложенной модели.
стик µ = µ1:Ttext и σ = σ1:Ttext априорного распределения потокового деко-
дера. В настоящей работе архитектура текстового кодировщика состоит из
прямо направленных трансформер блоков. Заметим, что такая архитектура
идентична предложенной в [16] за исключением того, что скрытая размер-
ность и число фильтров в слоях были увеличены.
По аналогии с [16] в данной работе моделируется условное распределение
спектрограмм Py(y | t, s) путем преобразования условного априорного распре-
деления Pz(z | t, s) через потоковый декодер fdec : z → y, где y, t и s обознача-
ют входную спектрограмму, текстовую последовательность и информацию о
спикере соответственно.
Потоковый декодировщик представляет из себя последовательность пото-
ковых слоев, которые применяют обратимые преобразования. Такие обрати-
мые преобразования гарантируют важное свойство потокового декодировщи-
ка его двунаправленность. На рис. 2 направление работы декодировщика
обозначено от спектрограммы y к внутреннему представлению z. В разде-
лах 3 и 4 при выполнении клонирования и конверсии голоса будет показано,
как декодировщик работает в обратном направлении.
Генеративные потоки позволяют оценить правдоподобие данных и обуча-
ются так, чтобы максимизировать это правдоподобие. Используя замену пе-
ременных, можно вычислить логарифм правдоподобия данных следующим
образом:
∂f-1dec(x)
(1)
log Py(y | c) = log Pz(z | c) + logdet
∂x
Априорное распределение Pz в (1) является изотропным многомерным рас-
пределением Гаусса, и процесс обучения выстраивается так, чтобы его стати-
стики соответствовали статистическим данным априорного распределения,
µ и σ, полученным из текстового кодировщика fenc.
84
Таким образом, априорное распределение можно выразить следующим об-
разом:
∑
(
)
(2)
log Pz(z | c; θ, A) =
log N
zj;µA(j),σA(j)
,
j=1
где Tmel обозначает продолжительность спектрограммы.
На этапе обучения параметры модели подбираются так, чтобы максими-
зировать логарифм правдоподобия:
(3)
maxL(θ, A) = maxlog Py
(y | c; θ, A).
θ,A
θ,A
Для обучения предложенной модели по формулам (2) и (3) статисти-
ки априорного распределения потокового декодера требуется выровнять по
фреймам спектрограммы, т.е. сопоставить индексы этих двух последователь-
ностей. На схеме рис. 2 этот блок обозначен как регуляция длины. Индек-
сы статистик соотносятся со спектрограммой за счет выравнивания A, по-
лученного из внешней системы. A(j) = i, если j-я фонема произносится на
i-м фрейме спектрограммы:
∑
(4)
di =
1A(j)=i, i = 1, . . . , Ttext.
j=1
Значения d можно интерпретировать как продолжительности фонем, по-
скольку до регуляции длины векторы статистик имеют такую же длину, как
и последовательность токенов фонем, которая подается на вход в текстовый
кодировщик.
По аналогии с системами FastPitch [12], FastSpeech [13], FastSpeech 2 [14]
для того, чтобы предсказывать продолжительности фонем при выполнении
клонирования голоса, обучается дополнительный модуль предсказатель
продолжительностей фонем, рис. 2,б. Для каждого токена входной последо-
вательности данный модуль предсказывает число log d логарифм количе-
ства фреймов, на протяжении которых будет длиться соответствующая фо-
нема. Для получения продолжительности фреймов d округляется до бли-
жайшего целого. Обучение модуля предсказания продолжительностей фо-
нем достигается за счет минимизации среднеквадратичной ошибки между
продолжительностями, полученными из выравниваний внешней системы и
предсказанными:
(5)
Ldur
= MSE(d,d).
Модуль предсказания продолжительности фонем аналогичен предложен-
ному в [13].
Заметим, что хоть на рис. 2 есть другие входы, помимо токенов тексто-
вой последовательности x и спектрограммы y, а именно продолжительности
85
фонем d и эмбеддинги спикера s, однако для их получения требуется только
аудио и текст.
Для построения продолжительностей фонем по формуле (4) используют-
ся выравнивания, полученные также из внешней системы. В рамках данной
работы обучена собственная модель для построения выравниваний на основе
смеси гауссовских моделей, на базе Kaldi Speech Recognition Toolkit [18].
Построение эмбеддингов спикера осуществляется за счет сторонней моде-
ли ECAPA-TDNN [19], так как имеет минимальную ошибку на задаче вери-
фикации спикера. Поскольку для построения эмбеддингов спикера исполь-
зуется предобученная модель, постольку по тексту настоящей работы они
называются внешними. Для построения такого эмбеддинга необходим только
аудиосигнал.
3. Клонирование голоса
Задача клонирования голоса заключается в том, чтобы синтезировать ре-
чевой сигнал образцом голоса, который не присутствовал в тренировочных
данных модели синтеза речи. Образец с речью целевого голоса обычно при-
лагается в виде аудиофайла.
Предложенный подход позволяет использовать эмбеддинг спикера, полу-
ченный из аудиофайла с образцом целевого голоса, для синтеза речи задан-
ным голосом. За счет того, что модель ECAPA-TDNN не ограничена никаким
фиксированным набором спикеров, возможно получить эмбеддинг для голоса
любого произвольного спикера.
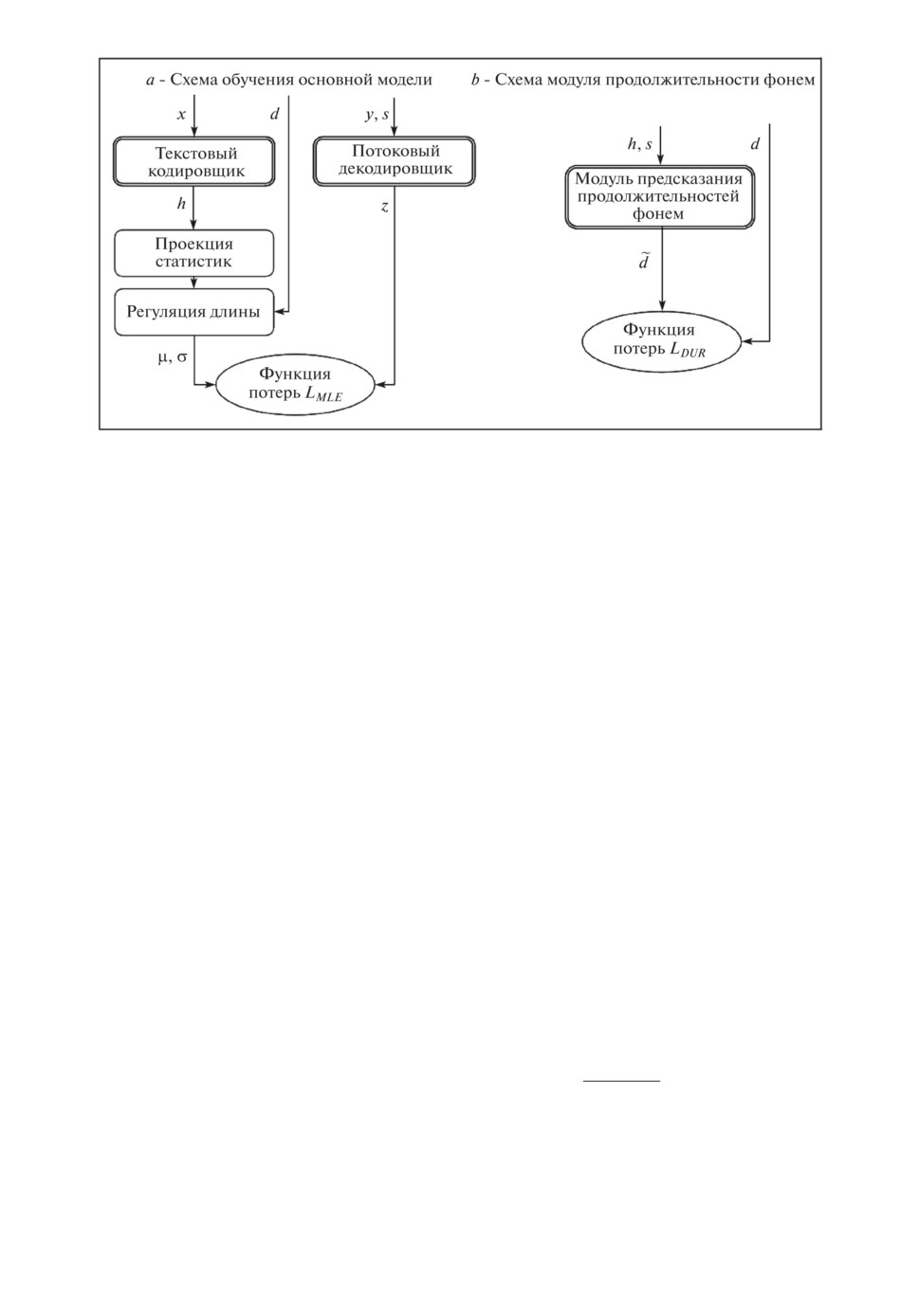
Более подробно процедура клонирования голоса изображена на рис. 3.
Сначала для заданного речевого сигнала с голосом целевого спикера стро-
ится вектор с характеристиками этого спикера, эмбеддинг спикер s. Текст,
y
s
x
Текстовый
Потоковый
кодировщик
декодировщик
h
Проекция
Модуль предсказания
статистик
продолжительностей
фонем
~
d
Регуляция длины
m, s
z
N(m, s)
Рис. 3. Схема выполнения клонирования голоса.
86
который требуется озвучить, представляется в виде последовательности то-
кенов x и направляется в текстовый кодировщик, как и во время обучения.
Выход текстового кодировщика h используется в двух местах. Во-первых,
вместе с эмбеддингом спикера s для предсказания продолжительностей d. Во-
вторых, для построения статистик µ и σ, длина которых регулируется за счет
продолжительностей d. Направление действия потокового декодировщика во
время работы клонирования голоса меняется на противоположное относи-
тельно обучения. Случайная величина из гауссовского распределения N(µ, σ)
проходит через потоковый декодировщик, а эмбеддинг спикера учитывается
в нем как дополнительное глобальное условие. Выходом декодировщика яв-
ляется спектрограмма y. Для того чтобы получить аудиосигнал из спектро-
граммы, в настоящей работе во всех экспериментах был использован вокодер
HiFi-GAN [20].
4. Конверсия голоса
Задача конверсии голоса заключается в преобразовании аудиосигнала с
голосом исходного спикера в аудиосигнал с тем же лингвистическим содер-
жанием, но произношением голосом целевого спикера. При этом конверсия
голоса позволяет копировать естественную интонацию и тембр голоса исход-
ного диктора. Образцы исходного аудиосигнала и сигнала с речью целевого
голоса обычно прилагаются в виде аудиофайла.
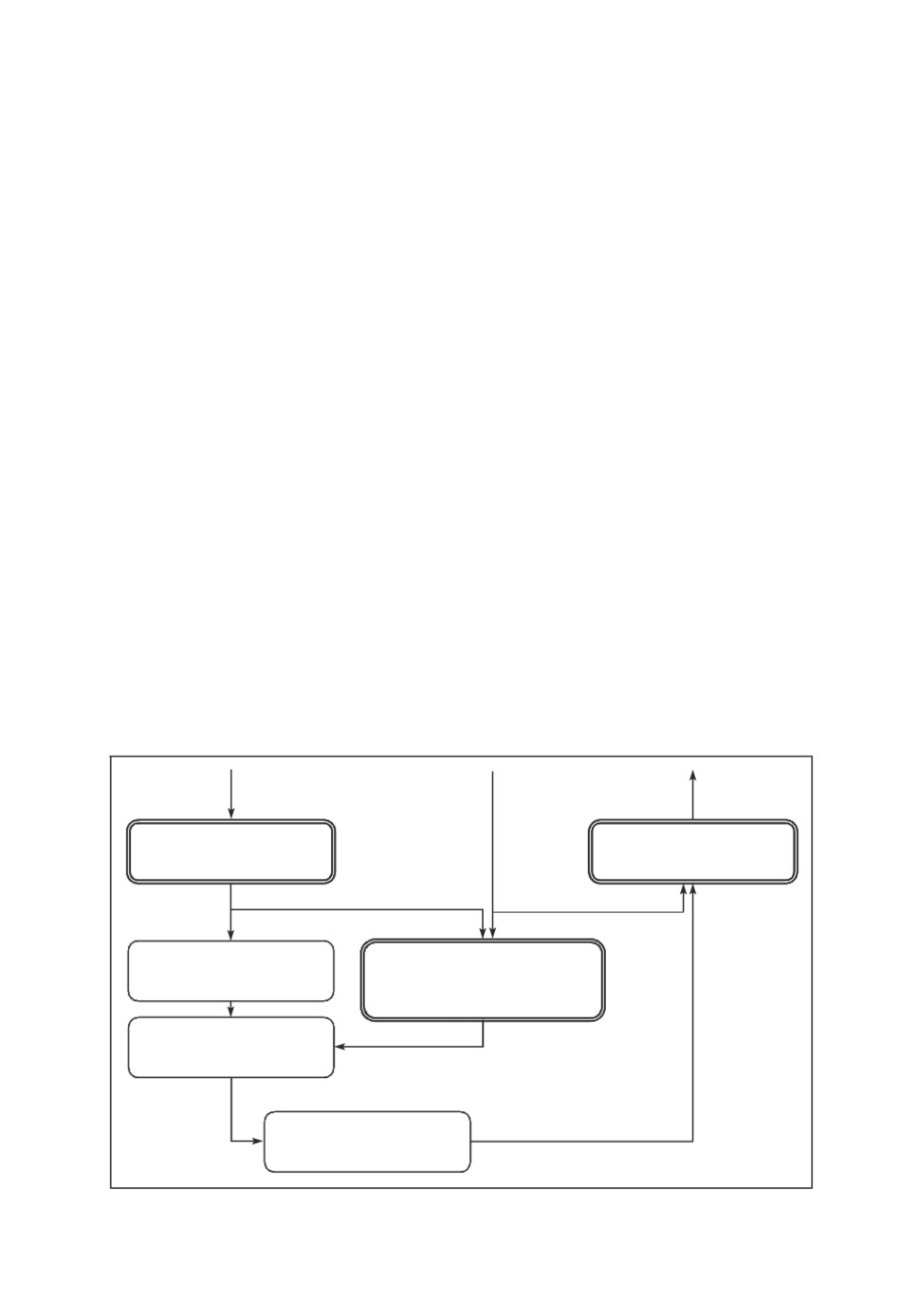
Схема выполнения конверсии голоса изображена на рис. 4.
Модель ECAPA-TDNN позволяет получить эмбеддинги спикеров с исход-
ным и целевым голосами ssource, starget. За счет двунаправленности потоково-
го декодера не составляет труда получить представление z для первоначаль-
ного аудиосигнала x, в котором содержится речь исходного спикера ssource:
(6)
z = f-1dec (y |ssource
).
Это представление не зависит от спикера, поскольку при обучении тре-
бовалось, чтобы апостериорное распределение являлось изотропным много-
мерным распределением Гаусса со статистиками, полученными из текстового
Рис. 4. Схема выполнения конверсии голоса.
87
энкодера. В свою очередь, эти статистики не зависят от спикера, а зависят
лишь от лингвистического содержания. Таким образом, применение прямого
прохода по декодировщику с условием, заданным в виде эмбеддинга целевого
спикера starget, позволяет получить аудиосигнал, с голосом целевого спикера
и исходным лингвистическим содержанием:
(7)
ytarget = fdec(z |starget
).
Поскольку в процессе выполнения этих преобразований не происходит из-
менений продолжительностей фонем, постольку целевой голос сохранит темп
речи, близкий к темпу речи исходного диктора.
Как уже упоминалось выше, модель ECAPA-TDNN позволяет получить
эмбеддинги даже для спикеров, не представленных в данных обучения пред-
ложенной модели. За счет этого предложенный подход позволяет выполнять
конверсию любого произвольного голоса в произвольный целевой голос, даже
если образцы речи с этими голосами не встречались в данных обучения.
5. Учет частоты основного тона
В описанном выше подходе вся информация, специфичная для спикера,
сосредоточена в одном эмбеддинге спикера. Однако это представление фик-
сированного размера и не зависящее от времени. Такое поведение не является
достаточным для описания всей вариативности человеческой речи, посколь-
ку в естественной речи присутствует и переменная во времени, специфичная
каждому голосу информация.
Частота основного тона является характеристикой переменной во времени
и специфичной для заданного спикера. Поэтому учет частоты основного тона
должен дополнить информацию из эмбеддинга спикера и сделать синтезируе-
мую речь более естественной.
В настоящей работе рассматриваются три следующие стратегии учета ча-
стоты основного тона:
не учитывать;
добавлять к выходам энкодера, по аналогии с подходами FastPitch [12]
и FastSpeech2 [14];
добавлять как локальное условие в декодер (предложенный подход).
Первая стратегия является базовым вариантом для сравнения.
Вторая стратегия используется в работах FastPitch [12] и FastSpeech2 [14].
Идея заключается в том, чтобы добавлять нормализованные значения ча-
стоты основного тона, либо полученные из них векторные представления, к
выходам энкодера h. На этапе инференса при таком подходе требуется пред-
сказывать значения частоты основного тона, для этого обучается дополни-
тельный модуль предсказания частоты основного тона.
Недостатком такого подхода в предложенной архитектуре на основе гене-
ративных потоков является то, что статистики µ и σ, полученные из пред-
ставления h, становятся зависимыми от частоты основного тона, а значит и
от переменных во времени характеристик спикера. Это не только нарушает
базовую идею, заложенную в подход, так как представление z перестает быть
88
независимым от спикера, но и ограничивает возможности эффективного вы-
полнения конверсии голоса.
Поэтому в настоящей работе предложена третья стратегия учета частоты
основного тона спикера. Вместо того, чтобы учитывать ее на выходе коди-
ровщика, здесь предполагается учитывать частоту основного тона в декодере
как дополнительное локальное условие [21]. На этапе инференса по-прежнему
потребуется предсказывать значения частоты основного тона, и для этого,
как и во втором подходе, необходимо обучить дополнительный модуль пред-
сказания частоты основного тона. Однако принципиальное отличие в том,
что статистики µ и σ априорного распределения потокового декодера, как и
внутреннее представление z, больше не зависят от характеристик спикера.
6. Эксперименты и результаты
Во всех экспериментах для обучения использованы открытые англоязыч-
ные данные. В табл. 1 приведена информация по каждому используемому
набору данных.
Все эксперименты были проведены на машине со следующей конфигура-
цией: CPU: AMD Ryzen Threadripper 2950X 16-Core Processor; GPU: 3x NVidia
GeForce RTX 2080 Ti.
На предварительном этапе до начала обучения тексты из набора данных
были нормализованы и фонемизированы. Нормализация включала раскры-
тие сокращений, чисел, аббревиатур и специальных знаков. Фонемизация тек-
ста заключается в преобразовании заданного текста в последовательность
фонем с учетом фонетических, морфологических и грамматических особен-
ностей языка. В данной работе нормализация и фонемизация выполнялись с
использованием инструмента Kyubyong/g2p [27]. Инструмент [27] также поз-
воляет расставлять ударения в словах.
Для обучения рассмотренных моделей для каждого из спикеров было ис-
пользовано не более двух часов данных. В обучающую выборку были вклю-
чены только спикеры, для которых имелось не менее 30 минут записанной
речи. Обучение каждой модели длилось три дня.
Для оценки предложенного подхода на задаче клонирования речи был про-
веден MOS (mean opinion score, усредненная оценка опрашиваемых) тест на
естественность речи и похожесть голоса.
В рамках MOS теста на естественность речи асессору предлагалось про-
слушать аудиозапись и оценить их по шкале от 1 до 5, где 1 это речь
Таблица 1. Используемые для обучения датасеты
Количество
Количество
Среднее количество
Набор данных
записей
часов обучения
часов на спикера
Blizzard 2013 [22]
147249
198,2
4,4
HiFi-TTS dataset [23]
323978
291,7
29,2
LibriTTS [24]
375086
585,8
0,26
LJSpeech [25]
13100
23,9
23,9
M AI Labs [26]
69853
143,6
35,9
89
Таблица 2. Сравнение предложенных систем на задаче клонирования голоса
Естественность
Похожесть голоса
речи
Оригинальная речь
3,969 ± 0,034
4,037 ± 0,043
Без учета частоты основного тона
3,711 ± 0,045
3,101 ± 0,053
Учет частоты основного тона сразу после
3,745 ± 0,043
3,237 ± 0,058
кодировщика
Учет частоты основного тона как локальное
3,795 ± 0,04
3,306 ± 0,062
условие в декодировщике
Таблица 3. Анализ MOS теста по оценке качества клонирования голоса
предложенного решения по категориям
Естественность речи
Похожесть голоса
Детские голоса
3,94 ± 0,081
3,24 ± 0,144
Женские голоса
3,883 ± 0,082
3,433 ± 0,121
Мужские голоса
3,64 ± 0,099
3,167 ± 0,152
совершенно неестественная, 5 речь не отличима от человеческой. Каждую
из записей оценивали по 20 раз. Всего в оценке принимало участие 75 записей
для каждой из моделей, по 3 записи для каждого из 5 мужских, 5 женских
и 5 детских голосов.
В рамках MOS теста на похожесть голоса асессору требовалось оценить,
насколько голос в двух предложенных записях похож. Одна из предложен-
ных записей являлась целевой записью с речью человека. Оценивание также
происходило по шкале от 1 до 5, и каждая из тех же 75 записей сравнивалась
с записями из оригинальной речи по 20 раз.
В табл. 2 приведено сравнение предложенных систем на задаче клониро-
вания голоса.
В первой строке табл. 2 приведена оценка для оригинальной человеческой
речи. В последующих строках приведены оценки для синтезированных запи-
сей в зависимости от способа учета в обученной модели частоты основного
тона. Во второй строке оценивались записи, полученные из модели, которая
не учитывает частоту основного тона никаким образом. В третьей строке
приведена оценка для модели, в которой частота основного тона учитывает-
ся в представлениях, полученных из текстового кодировщика. В четвертой
строке приведена оценка для модели, в которой учет частоты основного тона
происходит в потоковом декодировщике.
Анализ результатов этого MOS теста показал, что система работает ху-
же для голосов, которые в меньшем объеме были представлены в данных
обучения акустической модели, табл. 3. Так, для мужских и детских голо-
сов результаты похожести голоса ниже, чем для женских голосов, которые
присутствовали в данных обучения в большей степени. Интересно, что для
детских голосов естественность речи при этом высока, но это достигается за
счет того, что эти голоса больше звучат как женские, чем детские.
90
Таблица 4. Результаты MOS теста по оценке качества многоголосого син-
теза речи
Естественность речи
Похожесть голоса
Оригинальная речь
4,163 ± 0,067
3,872 ± 0,05
Предложенное решение
3,859 ± 0,076
3,751 ± 0,053
Модель FastPitch [12]
3,556 ± 0,084
3,785 ± 0,058
Модель FastSpeech 2 [14]
3,965 ± 0,065
3,701 ± 0,067
Модель Glow-TTS [16]
3,639 ± 0,056
3,639 ± 0,056
Кроме того, было проведено сравнение с другими решениями на задаче
синтеза речи. В табл. 4 приведены результаты MOS теста на задаче синтеза
речи. Помимо предложенного решения, в сравнении рассматривались упомя-
нутые модели из [12, 14, 16]. Поскольку результаты при учете частоты основ-
ного тона в декодировщике оказались лучше, постольку далее в сравнении с
другими системами рассматривался именно этот подход.
Несмотря на то что на задаче синтеза речи предложенное решение не явля-
ется лучшим по всем критериям, работы [12, 14, 16] не позволяют выполнять
клонирование голоса и работы [12, 14], не позволяют выполнять конверсию
голоса.
7. Заключение
В данной работе была предложена архитектура, позволяющая выполнять
задачи синтеза речи, клонирования и конверсии голоса. За счет использо-
вания внешних эмбеддингов спикера, предложенная архитектура, единожды
обучившись, позволяет выполнять данные задачи даже с голосами спикеров,
которые не встречались при обучении. Также предложена техника учета ча-
стоты основного тона, за счет которой удалось повысить естественность син-
тезированной речи и синтезировать речь, более похожую на заданный голос.
Несмотря на это, результаты показывают, что речь человека звучит более
естественно, а степень клонирования голоса остается недостаточно высокой.
Подход, предложенный в данной работе, является вычислительно эффек-
тивным, поскольку использует не авторегрессионный метод генерации по-
следовательности, за счет чего асимптотика генерации аудиосигнала отно-
сительно входной последовательности является линейной. За счет того, что
предложенная система требует однократного обучения, она является простой
в использовании и внедрении в другие продукты.
В будущем можно улучшить качество клонирования и конверсии голоса за
счет использования дополнительной информации из аудио, например, энер-
гии сигнала, а также за счет увеличения объема данных обучения, в том
числе и за счет данных из разных языков.
СПИСОК ЛИТЕРАТУРЫ
1. Cooper F.S., Gaitenby J.H., Nye P.W. Evolution of reading machines for the blind:
Haskins Laboratories’ research as a case history // J. of Rehabilit. Res. Development.
1984. No. 21.1. P. 51-87.
91
2.
Miyabe M., Yoshino T. Development of multilingual medical reception support sys-
tem with text-to-speech function to combine utterance data with voice synthesis /
ICIC ’10: Proceedings of the 3rd international conference on Intercultural collabora-
tion. 2010. P. 195-198.
3.
Kargathara A., Vaidya K., Kumbharana C.K. Analyzing Desktop and Mobile Appli-
cation for Text to Speech Conversation / Rising Threats in Expert Applications and
Solutions. 2020. P. 331-337.
4.
Sokol K., Flach P. Glass-Box: Explaining AI Decisions With Counterfactual State-
ments Through Conversation With a Voice-enabled Virtual Assistant / Proceedings
of the Twenty-Seventh International Joint Conference on Artificial Intelligence. 2018.
P. 5868-5870.
5.
Hoy M.B. Alexa, Siri, Cortana, and More: An Introduction to Voice Assistants //
Medical Reference Services Quarterly. 2018. No. 37. P. 81-88.
6.
Nasirian F., Ahmadian M., Lee O. AI-Based Voice Assistant Systems: Evaluating
from the Interaction and Trust Perspectives / Twenty-third Americas Conference on
Information Systems. 2017.
7.
Obukhov D.S. Многоголосый синтез естественной речи с использованием генера-
тивных потоков // Современные информационные технологии и ИТ-образова-
ние. 2021. No. 17.4.
8.
Xie Q., Tian X., Liu G., et. al. The Multi-Speaker Multi-Style Voice Cloning Chal-
lenge 2021 // International Conference on Acoustics, Speech, and Signal Processing.
2021.
9.
Sisman B., Yamagishi J., King S., Li H. An overview of voice conversion and its
challenges: From statistical modeling to deep learning // IEEE/ACM Transactions
on Audio, Speech, and Language Processing. 2020.
10.
Jia Y., Zhang Y., Weiss R.J., et. al. Transfer learning from speaker verification to
multispeaker text-to-speech synthesis / Conference on Neural Information Processing
Systems. 2018.
11.
Tan X., Qin T., Soong F., Liu T.-Y. A survey on neural speech synthesis / arXiv
обращения: 22.01.2022).
12.
Lancucki A. Fastpitch: Parallel text-to-speech with pitch prediction / arXiv preprint
ния: 22.01.2022).
13.
Ren Y., Ruan Y., Tan X., Qin T., Zhao S., Zhao Z., Liu T.-Y. Fastspeech: Fast, ro-
bust and controllable text to speech / In Advances in Neural Information Processing
Systems. 2019. P. 3165-3174.
14.
Ren Y., Hu C., Tan X., Qin T., Zhao S., Zhao Z., Liu T.-Y. Fastspeech 2:
Fast and high-quality end-to-end text to speech / arXiv:2006.0455. 2020. URL:
15.
Valle R., Shih K., Prenger R., Catanzaro B. Flowtron: an autoregressive flow-based
generative network for text-to-speech synthesis / arXiv preprint arXiv:2005.05957.
16.
Kim J., Kim S., Kong J., Yoon S. Glow-TTS: A Generative Flow for Text-to-Speech
via Monotonic Alignment Search / In Advances in Neural Information Processing
Systems 33: Annual Conference on Neural Information Processing Systems. 2020.
17.
Kim J., Kong J., Son J. Conditional variational autoencoder with adversarial learn-
ing for end-to-end text-to-speech / arXiv preprint arXiv:2106.06103. 2021. URL:
92
18.
Povey D., Ghoshal A., Boulianne G., et. al. The Kaldi Speech Recognition Toolkit /
In IEEE 2011 Workshop on Automatic Speech Recognition and Understanding. 2011.
19.
Desplanques B., Thienpondt J., Demuynck K. Ecapatdnn: Emphasized channel at-
tention, propagation and aggregation in tdnn based speaker verification, arXiv
обращения: 22.01.2022).
20.
Kong J., Kim J., Bae J. Hifi-gan: Generative adversarial networks for efficient and
high fidelity speech synthesis / Advances in Neural Information Processing Systems.
2020.
21.
Oord A., Dieleman S., Zen H., et. al. Wavenet: A generative model for raw audio /
ния: 22.01.2022).
22.
King S., Karaiskos V. The blizzard challenge 2013 / Proc. Blizzard Challenge work-
shop 2013. 2013.
23.
Bakhturina E., Lavrukhin V., Ginsburg B., Zhang Y. Hi-fi multi-speaker english tts
dataset / arXiv preprint arXiv:2104.01497. 2021.
24.
Zen H., Dang V., Clark R. et. al. LibriTTS: A corpus derived from LibriSpeech for
text-to-speech / arXiv preprint arXiv:1904.02882. 2019.
25.
Ito K., Johnson L., The LJ speech dataset / Электронный ресурс: The LJ Speech
22.01.2022).
26.
Solak I. The M-AILABS Speech Dataset / Электронный ресурс: The M-AILABS
dataset (дата обращения: 22.01.2022).
27.
Kyubyong P., Jongseok K. g2pE: A Simple Python Module for English Grapheme
To Phoneme Conversion / Электронный ресурс: GitHub repository. 2018. URL:
Статья представлена к публикации членом редколлегии А.А. Лазаревым.
Поступила в редакцию 22.01.2022
После доработки 25.04.2022
Принята к публикации 29.06.2022
93