Автоматика и телемеханика, № 12, 2022
© 2022 г. Ю.Ю. ДЮЛИЧЕВА, канд. физ.-мат. наук
(dyulichevayuyu@cfuv.ru)
(ФГАОУ ВО ¾Крымский федеральный университет
им. В.И. Вернадского¿, Симферополь)
ВЫЯВЛЕНИЕ АФФЕКТИВНЫХ СОСТОЯНИЙ
НА ОСНОВЕ АВТОМАТИЧЕСКОГО АНАЛИЗА ТЕКСТОВ
КОММЕНТАРИЕВ В СОЦИАЛЬНЫХ СЕТЯХ
В статье рассмотрена задача классификации 3553 англоязычных ком-
ментариев из социальной сети Reddit на основе различных подходов к век-
торизации текстов комментариев: мешок слов, TF-IDF, анализ биграмм
на основе точечной взаимной информации PMI и сентимента, глубокая
модель представления языка BERT. Применение гибридного подхода на
основе векторизации текстов с помощью BERT и анализа биграмм позво-
лило повысить качество классификации комментариев до 91%. На основе
кластерного анализа 1857 англоязычных комментариев, содержащих опи-
сание тревожностей, с помощью BERT+k-Means были выделены класте-
ры. В исследовании предложен гибридный подход, основанный на приме-
нении метода тематического моделирования LDA, метода анализа тональ-
ности VADER, точечной взаимной информации, анализа частей речи и
позволяющий выделять биграммы и триграммы для описания кластеров
комментариев. Для визуализации извлеченных закономерностей в виде
триграмм был построен граф знаний, описывающий предметную область,
а сопоставление слов выделенных целевых триграмм со словами кастом-
ного словаря, описывающего различные аффективные расстройства, поз-
волило определить типы психосоциологических стрессоров, c которыми
связаны аффективные расстройства.
Ключевые слова: биграммы, сентиментный анализ, LDA, BERT, VADER,
BoW, TF-IDF, граф знаний, ментальное здоровье.
DOI: 10.31857/S0005231022120029, EDN: KRIUIZ
1. Введение
Анализ негативных настроений на основе текстов комментариев в соци-
альных медиа, связанных с проявлением страха, тревожности, скуки, печа-
ли и т.п. является перспективным направлением для оценивания состояния
ментального здоровья, в целом, и выявления различных аффективных со-
стояний, в частности. Некоторые исследователи отмечают, что в социальных
сетях люди описывают проблемы, симптомы и проявление своей ментальной
болезни более свободно, чем на приеме у врача [1, 2]. По этой причине на-
блюдается рост интереса со стороны исследователей к применению методов
обработки естественного языка для выявления закономерностей в текстах
5
комментариев, характерных для различных типов расстройств и их диагно-
стики. Копперсмит и др. выявили преобладание личных местоимений пер-
вого лица в депрессивных комментариях на основе анализа частей речи [3];
Сарсам и др. отмечают преобладание эмоциональных состояний, связанных
с выражением печали в сообщениях суицидального характера [4]. Некоторые
исследователи отмечают, что измененное эмоциональное состояние и желание
намеренно исказить смысл влияют на лингвистические показатели текста, ко-
торые могут быть использованы на этапе векторизации текстов комментариев
для улучшения качества классификации [5, 6].
Пандемия COVID-19 и, в частности, самоизоляция, масочный режим и
вакцинация привели к росту проявления аффективных состояний в коммен-
тариях социальных сетей. Так, Зенг и др. исследовали влияние пандемии
COVID-19 на выражение депрессивных эмоций в твиттах [7]; Саифуллах и др.
продемонстрировали эффективность применения случайного леса совместно
с подходом к векторизации на основе TF-IDF для классификации тревожных
комментариев на Youtube, связанных с COVID-19 [8].
Разработка новых методов анализа текстов комментариев в области ис-
следования ментального здоровья направлена не только на выявление ком-
ментариев, относящихся к различным видам аффективных расстройств, но
и на создание систем поддержки принятия решений по оказанию персона-
лизированной помощи людям, страдающим такими расстройствами. Интерес
представляет и задача определения той точки невозврата в сообщениях, когда
негативное эмоциональное состояние и негативное отношение ко всем аспек-
там жизни приводят к суицидальной идеации [4].
Целью работы является исследование эффективности применения различ-
ных подходов к векторизации текстов комментариев и, в частности, на основе
анализа биграмм для решения задач классификации и кластеризации ком-
ментариев с описанием различных аффективных расстройств, а также выяв-
ление закономерностей, способствующих пониманию психосоциологических
стрессоров, c которыми связаны аффективные расстройства.
2. Обзор литературы по тематике исследования
Наиболее исследованной платформой социальных медиа с точки зрения
выявления аффективных расстройств на основе анализа текстов комментари-
ев является Твиттер. В табл. 1 приведены некоторые исследования, направ-
ленные на извлечение закономерностей из твиттов, способствующих улучше-
нию качества классификации аффективных комментариев.
Волк и др. продемонстрировали эффективность классификации текстов
комментариев с учетом сентимента и выявления депрессивных состояний
на основе анализа колл-грамм и модели представления языка BERT [5],
а Мойин и др. отмечают, что векторизация на основе биграмм существен-
но увеличивает качество классификации в отличие от использования три-
грамм [11], поэтому исследование авторов было направлено на выявление би-
6
Таблица 1. Анализ твиттов для выявления некоторых типов аффективных
расстройств
Тип
Методы
Авторы
аффективного Датасет
Особенности анализа
Результаты
расстройства
текстов
1
2
3
4
5
6
Бирджали
cуицидальное
892 твитта
Авторский
Векториза-
Наиболь-
и др. [1]
расстройство
со словами
словарь
ция текстов
шая точ-
из словаря
слов, связан-
на основе
ность клас-
суицидаль-
ных с суици-
признаков
сификации
ных слов
дальным на-
частотнос-
(precision)
строением
ти, анализа
89,5% до-
(мыслями)
n-грамм и
стигнута
и оценка се-
распозна-
на основе
мантической
вания час-
SMO
схожести
тей речи,
на основе
классифи-
WordNet
кация твит-
тов на ос-
нове SVM,
ME и NB
Рабани
cуицидальное
4266 твиттов
Применение
Векториза-
Наиболь-
и др. [2]
расстройство
ансамблей
ция на ос-
шая точ-
методов
нове BoW,
ность клас-
машинного
TF-IDF,
сификации
обучения
классифи-
(accuracy)
кация твит-
98,5% до-
тов на осно-
стигнута
ве беггин-
на основе
га, ансамб-
случайного
ля голосо-
леса
вания,
AdaBoost,
случайного
леса, сте-
кинга
Сарсам
cуицидальное
4987 твиттов,
Использова-
Векториза-
Наиболь-
и др. [4]
расстройство
из них 1000
ние сенти-
ция на
шая точ-
твиттов (для
ментных
основе
ность клас-
обучения мо-
признаков,
мешка слов
сификации
дели) из двух
выявленных
(BoW), ме-
(accuracy)
классов:
на основе
тоды на
86,97%
твитты c
NRC Affect
основе
достигнута
проявлением
Intensity
лексикона,
на основе
суицидаль-
Lexicon и
алгоритмы
YATSI+
ных мыслей
SentiStrength
классифи-
сенти-
и обычные
кации
ментные
твитты
YATSI и
признаки
LLGC
7
Таблица
1. (окончание)
1
2
3
4
5
6
Пиллай
стрессовое/
1000 твиттов
Введение
Предобра-
Улучшение
и др. [9]
расслаблен-
шкалы бал-
ботка текста
точности
ное состояние
лов для оце-
твиттов на
алгоритмов
нивания экс-
основе ана-
класси-
пертами сте-
лиза повто-
фикации
пени стрес-
ряющихся
за счет ис-
сового/рас-
букв, эмоти-
следования
слабленного
конов, пунк-
неоднознач-
состояния и
туации, сен-
ности смыс-
исследова-
тимента и
ла слов
ние неодно-
теггирова-
значности
ние твиттов
смысла слов
с учетом
смысла слов
Ораби
депрессивное
1145 пользо-
Оптимиза-
Векториза-
Наилучший
и др. [10]
состояние
вателей с ис-
ция вектор-
ция на осно-
результат
следованием
ного пред-
ве скип-
достигнут
слов твиттов
ставления с
грамм и не-
на основе
этих пользо-
учетом спе-
прерывного
однослой-
вателей
цифичных
мешка слов
ной свер-
слов для
точной ней-
предметной
ронной сети
области
со слоем
глобального
максималь-
ного пуллин-
га и опти-
мизацией
векторного
представле-
ния и со-
ставляет
86,967%
(AUC-
оценка)
грамм и триграмм, описывающих предметную область, и рассмотрение под-
ходов к векторизации текстов комментариев на основе анализа биграмм и их
характеристик для решения задач классификации и кластеризации коммен-
тариев, содержащих описание аффективных расстройств.
Несмотря на разработку эффективных подходов для предобработки, век-
торизации и классификации твиттов и текстов комментариев в социальных
сетях по классам, соответствующим различным аффективным состояниям,
исследования, направленные на извлечение закономерностей, описывающих
причины таких состояний, остаются актуальными. Следует отметить, что
8
комментарии в социальных сетях существенно отличаются от твиттов, по-
скольку позволяют более подробно описывать мысли и чувства. В частности,
людям, страдающим депрессиями, свойственна смена настроения при напи-
сании комментариев в социальных сетях [12]. Кроме того, в комментариях
людей, страдающих депрессией, отмечается описание позитивного прошло-
го, которое сменяется описанием негативного настоящего, поэтому требуется
разработка специальных методов от этапа предобработки текстов коммента-
риев до этапа классификации, кластеризации и извлечения закономерностей
из них с учетом особенностей аффективных расстройств.
3. Датасет и методология исследования
3.1. Классификация текстовых сообщений из двух классов:
класс с описанием аффективных состояний
и класс обычных комментариев
В исследовании использовался сбалансированный датасет из 3553 ком-
ментариев: 1857 комментариев с описанием тревожностей и 1696 обычных
комментариев из социальной сети Reddit. Разметка комментариев по двум
классам выполнялась вручную с привлечением двух практикующих экспер-
тов, оказывающих помощь людям с различными типами аффективных рас-
стройств. Рассмотренный датасет является частью датасета, описанного в
работе [13] и представленного на платформе Kaggle.
В качестве базового алгоритма классификации рассматривался алгоритм
случайного леса. Для повышения качества алгоритма классификации изуча-
лись различные подходы к векторизации текста:
1) применение мешка слов (BoW);
2) применение меры TF-IDF;
3) применение глубокой модели представления языка BERT;
4) применение анализа биграмм на основе точечной взаимной информа-
ции, а также числовых оценок сентимента, полученных с помощью метода
VADER, реализованного в python-библиотеке vaderSentiment.
Кратко опишем методы, перечисленные выше. Модель ¾мешок слов¿
(BoW) основана на извлечении всех слов из текстов комментариев и сопо-
ставлении им частотности их появления в комментариях. Мера TF-IDF (TF
term frequency, IDF inverse document frequency) вычисляется как произве-
дение отношения числа вхождений выбранного слова к общему количеству
слов в комментарии и инверсии частоты, с которой некоторое слово встре-
чается в комментариях корпуса [14]. Глубокая модель представления языка
BERT (Bidirectional Encoder Representations from Transformers) реализует ар-
хитектуру трансформер и позволяет учитывать контекст и представление
токена, а также его положение внутри предложения и номер предложения в
корпусе [15].
9
Для оценки качества классификации исследуемых подходов на сбаланси-
рованном датасете использовались показатели (1)-(4), приведенные ниже, и
5-кратная перекрестная проверка.
TP +TN
(1)
Accuracy =
,
TP +TN+FP +FN
TP
(2)
Precision =
,
TP +FP
TP
(3)
Recall =
,
TP +FN
Precision · Recall
(4)
F1 - score = 2 ·
,
Precision + Recall
где T P , T N, F P , F N истинно положительные, истинно отрицательные,
ложно положительные, ложно отрицательные значения соответственно.
3.2. Кластеризация текстовых сообщений, содержащих описания
аффективных состояний
На этапе кластеризации был использован датасет из 1857 сообщений с
описанием различных тревожностей. Приведем пример случайного коммен-
тария с авторской орфографией из исследуемого датасета: ¾Приступ длился
несколько часов. Это было похоже на проблемы с кровообращением, и я за-
паниковал и, конечно же, снова оказался в отделении неотложной помощи.
На этот раз ко мне сразу же приехал врач. Он хотел поговорить о моем тре-
вожном состоянии. Он сказал, что может провести еще несколько тестов, но
не думает, что это поможет.¿
Следуя методологии для выявления математической тревожности на ос-
нове анализа комментариев МООК, изложенной в работе [16], для выделе-
ния кластеров использовалась векторизация текстов комментариев на осно-
ве глубокой модели представления языка BERT и алгоритма кластеризации
k-Means.
Рассмотрим гибридный подход, основанный на применении метода тема-
тического моделирования LDA, метода анализа тональности VADER, точеч-
ной взаимной информации, анализа частей речи, и позволяющий выделять
биграммы и триграммы для описания кластеров комментариев.
Алгоритм анализа биграмм и построение на их основе триграмм основан
на следующих основных этапах:
1) извлечение M ключевых слов с наибольшей частотой из тем, определен-
ных на основе латентного размещения Дирихле (LDA) и выделение на основе
анализа частей речи существительных или глаголов. Латентное размещение
Дирихле направлено на извлечение скрытых (латентных) тем из докумен-
тов, причем при построении тематической модели и определении количества
10
тем учитывался показатель когерентности для обеспечения схожести термов
в рамках одной темы;
2) извлечение ключевых биграмм кластера, у которых левый и/или пра-
вый токен является одним из M ключевых слов тем;
3) во множестве всех биграмм для ключевой биграммы извлекается левая
и правая соседняя биграмма и осуществляется склеивание по общим словам
для получения триграммы;
4) на основе анализа частей речи удаляются триграммы, содержащие MD
(модальные глаголы), более двух наречий или прилагательных (RB, JJ) и т.п.;
5) множество целевых триграмм формируется на основе редких триграмм,
имеющих негативную тональность. Редкие триграммы извлекаются на основе
значений pPMI согласно (5), а негативная тональность определяется с помо-
щью метода сентиментного анализа VADER (Valence Aware Dictionary and
sentiment Reasoner). Метод VADER основан на правилах и словарях, в кото-
рых словам из словаря экспертами сопоставлены оценки полярности [17].
Точечная взаимная информация (PMI) вычисляется по формуле
(
)
P (w1, w2, w3)
PMI(w1,w2,w3) = log2
,
P (w1)P (w2)P (w3)
где P (w1), P (w2), P (w3) вероятность появления токена (слова) w1, w2, w3
соответственно в тексте комментария, P (w1, w2, w3) вероятность появления
тройки слов (w1, w2, w3) - триграммы в тексте комментария.
Для выявления редких триграмм использовалась модификация pPMI, вы-
числяемая по формуле
(5)
pPMI(w1,w2,w3) = max(0,PMI(w1,w2,w3
)).
Алгоритм анализа триграмм основан на построении всех триграмм для
каждого кластера и выделении редких триграмм с негативной тонально-
стью с последующим анализом частей речи на основе шаблонов: (JJ, VB,
NN), (NN(P), VBD, NN(S)), (NN, VBN, NN), (NNP, VBG, NNP), (JJ, VBG,
NN), (JJ, VB+VB, NN), (NN, JJ, NN) и т.п. или центральное слово три-
граммы имеет тег зависимости ROOT, где JJ прилагательное, NN(NNP,
NNS) существительное множественного или единственного числа, VBG
герундий или простое причастие, VB глагол, VBN причастие прошед-
шего времени. Например, на основе шаблона (NN|JJ, VB, NN(S)|JJ) (суще-
ствительное | прилагательное, глагол, существительное (множественное чис-
ло) | прилагательное) были извлечены триграммы: (паническая, произойти,
атака), (кататония, обнаружить, симптомы), (нападение, влиять, травмати-
ческий) и т.п.
Для сопоставления ключевых слов триграмм каждого кластера с типами
психосоциологических стрессоров использовался психолингвистический сло-
варь LIWC [19] и построенный на его основе кастомный словарь, содержащий
11
различные синонимы слов ¾тревожность¿, ¾страх¿, ¾одиночество¿, а также
слова, описывающие различные родственные отношения и социальные связи
(для сопоставления с социологическим стрессором, связанным с построением
отношений); слова, описывающие различные типы боли, части тела, учреж-
дения здравоохранения (для сопоставления с социологическим стрессором,
связанным с состоянием здоровья и здравоохранением) и т.п.
4. Результаты исследования
4.1. Классификация текстовых сообщений из двух классов:
класс с описанием аффективных состояний
и класс обычных комментариев
Результаты 5-кратной перекрестной проверки для оценки качества алго-
ритма классификации (случайный лес (RF)) в зависимости от различных
подходов к векторизации текстов комментариев представлены в табл. 2.
Как видно из табл. 2, наилучшая точность классификации была достигну-
та за счет расширения векторного пространства на основе анализа биграмм
и составила 91,1%.
4.2. Кластеризация текстовых сообщений, содержащих описания
аффективных состояний
Предварительный этап обработки комментариев включал удаление пунк-
туации, стоп-слов, токенизацию, приведение к нормальной форме. Оптималь-
ное количество кластеров для решения задачи кластерного анализа 1857 сооб-
щений, содержащих описание аффективных состояний, оценивалось на осно-
ве голосования различных методов определения числа кластеров (силуэтный
метод, метод локтя и т.д.), реализованного в R-пакете NbClust [18], и равно 7.
В табл. 3 приведен фрагмент результатов кластерного анализа на основе
BERT+k-Means c выделением биграмм и триграмм с негативным сентимен-
том, содержащих ключевые слова, определенные на основе тематического
Таблица 2. Оценка эффективности различных подходов к векторизации текстов
комментариев
Подходы
Accuracy
Precision
Recall
F1
BoW+ RF
0,696 ± 0,018
0,679 ± 0,022
0,848 ± 0,014
0,760 ± 0,013
TF-IDF + RF
0,712 ± 0,019
0,700 ± 0,014
0,837 ± 0,034
0,763 ± 0,015
BERT + RF
0,723 ± 0,018
0,736 ± 0,017
0,770 ± 0,018
0,750 ± 0,015
Биграммы (pPMI +
0,714 ± 0,016
0,725 ± 0,020
0,796 ± 0,026
0,759 ± 0,013
+ сентимент)+ RF
TF-IDF +
0,824 ± 0,012 0,832 ± 0,013 0,876 ± 0,020 0,854 ± 0,011
+ Биграммы + RF
BERT+
0,911 ± 0,018 0,926 ± 0,019 0,934 ± 0,014 0,928 ± 0,015
+ Биграммы + RF
12
Таблица 3. Пример трех выделенных кластеров и построение их описаний на
основе анализа биграмм и триграмм
Примеры триграмм, полученных
Примеры триграмм
Кластеры
Мощность
слиянием биграмм, построенных
на основе VADER
на основе LDA, pPMI, VADER
и pPMI
Кластер 1
304
(паническая, происходить, атака),
(прикрытие,
вы-
(стресс, не верить, личность), (ка-
нужденный, отсут-
татония, обнаружить, симптомы),
ствие), (плохой, по-
(класс, напугать, наркотик), (бо-
лучить, место), (ра-
лезнь, притворяющийся, парень),
боты, побочная, зар-
(старая, вращающаяся, дверь),
плата), (работы, об-
(заснуть, падать, поворачивать-
служивать, оплата),
ся), (выпускной, травмирующий,
(площадь, сказать,
школа), (маленький, сжимающий,
покидать), (книги,
паника), (жилье, плохой, школа)
не являться, собы-
тие), (расходы, вы-
нудить, покрывать)
Кластер 2
289
(желудок, физически, больной),
(злой, говорить, рев-
(тревожность, влиять, страх),
нивый), (чувство,
(свадьба, хронический, тревож-
не являться,
ность), (мысль, относить, ипохон-
что-нибудь)
дрия), (терапевт, кликнуть, игра),
(мчащийся, постоянно, тревож-
ность), (эмоциональный, чувство-
вать, сексуальный), (гадость, об-
лажаться, симптомы), (гадость,
облажаться, игра), (злой, чувст-
вовать, учащенно дышащий),
(тревожность, числа, драма), (ин-
цест, начать, жестокое обраще-
ние), (боль, сердце, вдохновение),
(сердце, чувствовать, общение),
(сердце, отслеживание, частота),
(парень, чувствовать, обманутый),
(нападение, повлиять, травмати-
ческий)
Кластер 3
251
(продукты, бороться, явный),
(демоны, уничто-
(клинический, ноги, депрессия),
жить, жизнь), (бо-
(депрессия, посттравматический
лезнь, битва, пост-
стрессовый синдром, гнев), (объ-
травматический
ект, проблемы, плохое обраще-
стрессовый син-
ние), (диагностируемый, тревож-
дром), (дыхание,
ность, депрессия), (наркотики,
мысли, страх),
проблемы, злоупотребление), (ди-
(страхи, исказить,
ета, подразумевать, ненависть),
реальность)
(дети, доставлять боль, нам), (же-
стокое обращение, инвалидность,
ребенок), (квартира, проблемы,
жестокое обращение)
13
моделирования с помощью LDA и ранжирования с помощью точечной вза-
имной информации.
Например, из триграмм кластера 1 можно выделить закономерности, опи-
сывающие панические приступы, состояние кататонии, бессоницы, тревожно-
стей, связанных со школой, наркотиками, условиями проживания и поиском
работы.
Для реализации алгоритма анализа биграмм использовались следующие
python-библиотеки анализа данных: nltk, gensim, spacy, sentence-transformers.
Для каждого кластера отдельно выполнялся частотный анализ слов три-
грамм на основе кастомного словаря, описывающего психосоциологические
стрессоры. Например, частотный анализ триграмм кластера 2 позволил
определить, что большая часть комментариев рассматриваемого кластера
(48% всех триграмм кластера) описывает проблемы, связанные со здоровьем,
например, (сердце, отслеживание, частота), (желудок, физически, больной),
(мысль, относить, ипохондрия) и т.п. Значительная часть комментариев рас-
сматриваемого кластера (21% всех триграмм кластера) описывает проблемы,
связанные с построением социальных отношений, например, (свадьба, хро-
нический, тревожность), (злой, говорить, ревнивый), (парень, чувствовать,
обманутый), (инцест, начать, жестокое обращение) и т.п.
4.3. Построение графа знаний на основе анализа биграмм и триграмм
Графы знаний хорошо зарекомендовали себя в области визуализации из-
влеченных закономерностей, выделении основных характеристик и демон-
страции взаимосвязей между ними. Графы знаний широко применяются в
области медицины, например, для представления медицинских знаний по ин-
сультам [20], для демонстрации персонализированных предложений по под-
бору рациона для людей, страдающих диабетом [21], однако исследования,
связанные с представлением в виде графа знаний закономерностей, описы-
вающих проблемы с ментальным здоровьем, автору неизвестны. Далее пред-
лагается построение графа знаний для описания аффективных состояний на
основе полученных триграмм.
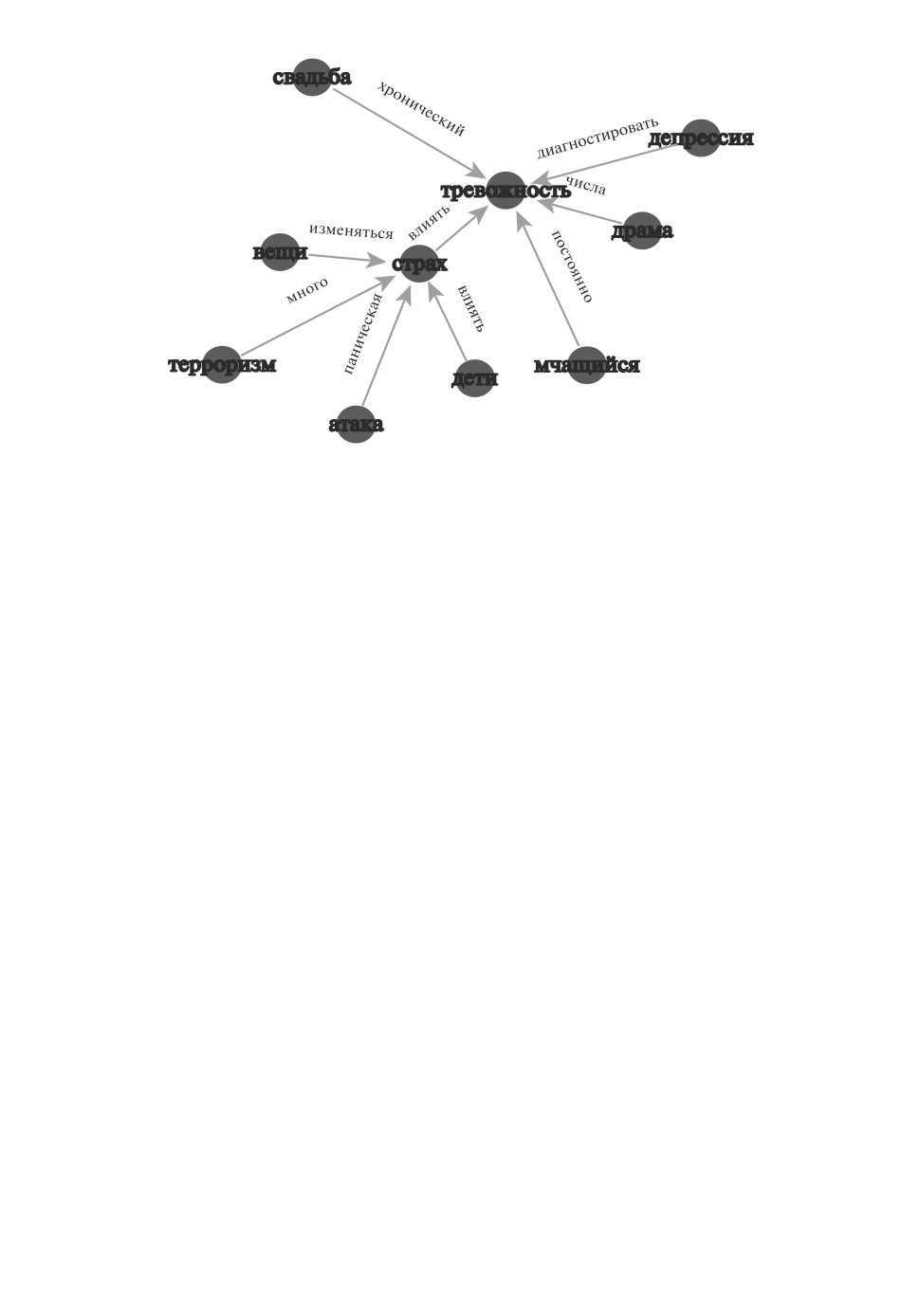
Для каждой триграммы (wi-1, wi, wi+1) строятся вершины графа с метка-
ми wi-1 и wi+1, а также ребро с меткой wi. Сначала выбирается целевое слово
из словаря аффективных расстройств, например, ¾тревожность¿, извлека-
ются все триграммы, построенные на основе предложенных выше шаблонов
со словом ¾тревожность¿, например, (свадьба, хронический, тревожность),
(тревожность, влиять, страх), (мчащийся, постоянно, тревожность), (тревож-
ность, числа, драма), (тревожность, диагностировать, депрессия) и т.п. Вер-
шинами графа становится целевое слово, например, ¾тревожность¿, а также
слова следующих частей речи, входящие в триграмму: существительное или
любое слово с тегом ROOT (корневое слово). Ориентированным ребрам гра-
фа приписываются слова триграмм, связанные с описанием аффективного
состояния и относящиеся к частям речи прилагательное, наречие, причастие,
14
свадьба
депрессия
тревожность
драма
вещи
страх
терроризм
мчащийся
дети
атака
Фрагмент графа знаний для слов ¾тревожность¿ и ¾страх¿, относящихся
к проявлению аффективных состояний, составлено автором.
если слов таких частей речи нет в триграмме, то ребру приписывается остав-
шееся в триграмме слово. Для построения графа знаний использовалась биб-
лиотека для распознавания частей речи spacy и библиотека для построения
графов PyViz. Фрагмент графа знаний, демонстрирующий построенные зако-
номерности для слов ¾тревожность¿ и ¾страх¿, относящихся к аффективным
состояниям, представлен на рисунке.
Из графа знаний, представленного на рисунке, видны тревожности, вы-
званные депрессией, свадьбой, драмой, а также описание тревожности, как
хронической, связанной с числами, или возникающей под влиянием страха.
5. Заключение
Активное использование социальных сетей привело к накапливанию
огромного количества комментариев, которые оставляют пользователи. Ме-
тоды обработки естественного языка совместно с алгоритмами машинного
обучения позволили получить интересные результаты в области оценки эмо-
ционального состояния, как отдельных групп пользователей социальных се-
тей, так и общества в целом. В последнее время активно развивается такое
направление киберпсихологии как оценивание психического состояния на ос-
нове анализа комментариев в социальных сетях и влияние различного кон-
тента на физическое и ментальное здоровье человека.
В работе продемонстрирована эффективность применения биграмм для
повышения качества классификации комментариев, содержащих описание
аффективных расстройств, и возможности извлечения биграмм и триграмм
для описания предметной области. Дальнейшие исследования автора будут
15
направлены на улучшение качества извлекаемых закономерностей для выяв-
ления причин различных типов психосоциологических стрессоров, приводя-
щих к проявлению тревожных расстройств в текстах комментариев социаль-
ных медиа.
СПИСОК ЛИТЕРАТУРЫ
1.
Birjali M., Beni-Hssane A., Erritali M. Machine Learning and Semantic Sentiment
Analysis based Algorithms for Suicide Sentiment Prediction in Social Networks //
8th Int. Conf. Emerging Ubiquitous Systems and Pervasive Networks, Procedia Com-
puter Science. 2017. V. 113. P. 65-72.
2.
Rabani S.T., Khan O.R., Khanday Akib Mohi U.D. Detection of Suicidal Ideation on
Twitter using Machine Learning & Ensemble Approaches // Baghdad Sci. J. 2020.
V. 17. No. 4. P. 1328-1339.
3.
Coppersmith G., Dredze M., Harman C. Quantifying Mental Health Signals in Twit-
ter // Proc. Workshop Comput. Linguist. Clinical Psychol.: From Linguist. Signal
Clinical Reality. Associat. Comput. Linguist. 2014. P. 51-60.
4.
Sarsam S.M., Al-Samarraie H.A., Ahmed I., Alnumay A., Smith A.P. A Lexicon-
based Approach to Detecting Suicide-related Text on Twitter // Biomed. Signal
Proc. Control. 2021. V. 65. No. 102355.
5.
Wolk A., Chlasta K., Holas P. Hybrid Approach to Detecting Symptoms of Depres-
sion in Social Media Entries // Twenty-Fifth Pacific Asia Conf. Information Systems.
2021. arXiv:2106.10485.
6.
Gillam L., Tariq M., Ahmad K. Terminology and the Construction of Ontology //
Terminology. 2005. V. 11. No. 1. P. 55-81.
7.
Zhang Y., Lyu H., Liu Y., Zhang X., Wang Yu., Luo J. Monitoring Depression Trend
on Twitter during the COVID-19 Pandemic: Observational Study // JMIR Format.
Res. 2020. 39 p.
8.
Saifullah S., Fauziah Yu., Aribowo A.S. Comparison of Machine Learning for Senti-
ment Analysis in Detecting Anxiety based on Social Media Data // arXiv:2101.06353,
2021.
9.
Pillai R.G., Thelwall M., Orasan C. Detection of Stress and Relaxation Magnitudes
for Tweets // WWW ’18: Compan. Proc. Web Conf. 2018. P. 1677-1684.
10.
Orabi A.H., Buddhitha P., Orabi M.H., Inkpen D. Deep Learning for Depression
Detection of Twitter Users // Proc. Fifth Workshop Comput. Linguist. Clinical Psy-
chol.: From Keyboard Clinic. 2018. P. 88-97.
11.
Moyeen S.I., Mabud Md.S.R, Nayem Z., Mamun Md.Al. Sentiment Analysis of En-
glish Tweets using Bigram Collocations // EPRA Int. J. Res. Development (IJRD).
2021. V. 6. I. 9. P. 220-227.
12.
Величко А.Н., Карпов А.А. Аналитический обзор систем автоматического опре-
деления депрессии по речи // Artificial Intellig., Knowledge and Data Engineer.
2021. No. 3. P. 497-529.
13.
Turcan E., McKeown K. Dreddit: A Reddit Datasets for Stress Analysis in Social
Media // arXiv: 1911.00133v1. 2019.
14.
Jones K.S. A Statistical Interpretation of Term Specificity and Its Application in
Retrieval // J. Document. 2004. V. 60. No. 5. P. 493-502.
16
15. Devlin J., Chang M.-W., Lee K., Toutanova K. BERT: Pre-training of Deep Bidi-
rectional Transformers for Language Understanding // arXiv: 1810.04805. 2018.
16. Дюличева Ю.Ю. Учебная аналитика МООК как инструмент анализа матема-
тической тревожности // Вопросы образования (Educat. Stud. Moscow). 2021.
No. 4. С. 243-265.
17. Hutto C., Gilbert E. VADER: A Parsimonious Rule-Based Model for Sentiment Anal-
ysis of Social Media Text // Eight Int. AAAI Conf. Weblogs and Social Media. 2014.
V. 8. No. 1. P. 216-225.
18. Charrad M., Ghazzali N., Boiteau V., Niknafs A. NbClust: An R Package for De-
termining the Relevant Number of Clusters in DataSet // J. Statist. Software. 2014.
19. Tausczik Y.R., Pennebaker J.W. The Psychological Meaning of Words: LIWC and
Computerized Text Analysis Methods // J. Lang Soc Psychol. 2010. V. 29. No. 1.
P. 24-54.
20. Cheng B., Zhang J., Liu H., Cai M., Wang Y. Research on Medical Knowledge
Graph for Stroke // J. Healthcare Engineer. 2021. V. 2021 (5531327).
21. Haussmann S., Seneviratne O., Chen Y. et al. FoodKG: A Semantics-Driven Knowl-
edge Graph for Food Recommendation // Semant.-Web - ISWC. 2019. P. 146-162.
Статья представлена к публикации членом редколлегии А.А. Лазаревым.
Поступила в редакцию 31.01.2022
После доработки 28.05.2022
Принята к публикации 29.06.2022
17