Автоматика и телемеханика, № 12, 2022
Интеллектуальные системы управления,
анализ данных
© 2022 г. А.А. ЗУЕНКО, канд. техн. наук (zuenko@iimm.ru),
(Кольский научный центр РАН, Апатиты)
МЕТОД МАШИННОГО ОБУЧЕНИЯ ДЛЯ ВЫЯВЛЕНИЯ
ЗАМКНУТЫХ МНОЖЕСТВ ОБЩИХ ПРИЗНАКОВ
ОБЪЕКТОВ С ПРИМЕНЕНИЕМ ТЕХНОЛОГИИ
ПРОГРАММИРОВАНИЯ В ОГРАНИЧЕНИЯХ1
Для решения задач машинного обучения разработан метод выявления
замкнутых множеств общих признаков объектов (паттернов) обучающей
выборки. Оригинальность метода заключается в том, что он реализован
в рамках концепции программирования в ограничениях и использует для
внутреннего представления и обработки обучающей выборки новый вид
табличных ограничений сжатые таблицы D-типа. Сокращение пере-
бора достигается за счет применения предложенного способа ветвления
дерева поиска и использования отношений частичного порядка на мно-
жествах объектов (признаков) для отсечения неперспективных ветвей.
Метод обладает оценкой вычислительной сложности, которая для неко-
торых типов входных данных лучше оценок, полученных для исследован-
ных прототипов.
Ключевые слова: машинное обучение, программирование в ограничениях,
табличные ограничения, замкнутые паттерны, формальные понятия.
DOI: 10.31857/S000523102212011X, EDN: KTHRSW
1. Введение
В статье рассматриваются задачи выявления паттернов (Pattern Discov-
ery), использующие объектно-признаковое представление данных [1, 2]. Ме-
тоды выявления замкнутых множеств общих признаков объектов (паттер-
нов) являются востребованными в рамках различных направлений машин-
ного обучения, в частности при поиске ассоциативных правил [3], генера-
ции ДСМ-гипотез [4], анализе формальных понятий (АФП) [5-7] и т.п. В ос-
нове подобных методов лежат идеи и подходы, направленные на снижение
трудоемкости вычислений. В [8] предложен подход к выявлению часто сов-
местно встречающихся признаков, где данная задача представлена как за-
дача удовлетворения ограничений (ЗУО). Также для решения обозначен-
ной проблемы развивается направление АФП, которое является прикладной
1 Исследование выполнено при финансовой поддержке Российского фонда фундамен-
тальных исследований (проект № 20-07-00708-а).
156
ветвью алгебраической теории решеток [5-7]. В [9] приведен обзор алгорит-
мов нахождения множества формальных понятий, их алгоритмическая слож-
ность составляет O (|G| |M| |L| min (|G| , |M|)), где |G| количество объектов,
|M| количество признаков, |L| конечный размер решетки, оцениваемый
как 2min(|G|,|M|).
В настоящей работе предлагается подход, основанный на представлении
задачи выявления паттернов в рамках парадигмы программирования в огра-
ничениях (Constraint Programming) в форме специализированных табличных
ограничений сжатых таблиц.
2. Выявление сходства объектов в задачах машинного обучения
Методы выявления паттернов (Pattern Discovery) применяются во мно-
жестве прикладных областей, включая анализ поведения покупателей, ме-
дицину, биоинформатику, интеллектуальный анализ данных из всемирной
паутины и т.п. [2]. К задачам выявления паттернов относятся, например:
извлечение частотных наборов признаков (frequent itemsets mining FIM ),
ассоциативных правил (association rule mining ARM ), последовательных
паттернов (sequential patterns mining SPM ) и т.п.
При использовании математического аппарата АФП [7] для решения обо-
значенного класса задач термину “Замкнутый паттерн” соответствует термин
“Содержание формального понятия”, а термину “Покрытие замкнутого пат-
терна” термин “Объем формального понятия”. Формальные понятия опре-
деляются с помощью соответствия Галуа и представляют собой пары мно-
жеств вида: (объем, содержание) [5, 6]. Контекстом в АФП называют трой-
ку K = (G, M, I), где G множество объектов, M множество признаков,
а отношение I ⊆ G × M говорит о том, какие объекты какими признаками
обладают. Для произвольных A ⊆ G и B ⊆ M определены операторы Галуа:
A′ = {m ∈ M|∀g ∈ A(g I m)}, B′ = {g ∈ G|∀m ∈ B (g I m)}.
Двукратное применение оператора Галуа является оператором замыкания.
Множество объектов A ⊆ G, при условии, что A′′ = A, называется замкну-
тым. Пара множеств (A, B), при условии, что A ⊆ G, B ⊆ M, A′ = B и B′ = A,
называется формальным понятием контекста K. Для множества объектов A
множество их общих признаков A′ служит описанием сходства объектов из
множества A, а замкнутое множество A′′ является кластером сходных объ-
ектов (с множеством общих признаков A′).
Задача, которая ставится в исследовании, заключается в разработке эф-
фективных методов поиска замкнутых паттернов обучающей выборки, что
можно свести к задаче создания методов эффективного порождения фор-
мальных понятий. Данная задача актуальна, ввиду того, что результаты ее
решения можно использовать как составные части при построении многих
процедур машинного обучения.
157
3. Табличные ограничения в рамках технологии
программирования в ограничениях
Согласно [10] ЗУО (Constraint Satisfaction Problem) заключается в по-
иске решений для сети ограничений (Constraint Network). Сеть ограниче-
ний задается тремя компонентами: < X, D, C >: X множество переменных
{X1, X2, . . . , Xn}, D множество доменов переменных {D1, D2, . . . , Dn}, C
множество ограничений {C1, C2, . . . , Cm}, которые регламентируют допусти-
мые сочетания значений переменных. Каждый домен Di описывает множе-
ство допустимых значений {v1, . . . , vk} для переменной Xi.
Ограничение Cj со схемой Sj = {Xj1 , Xj2 , . . . , Xjk } ⊆ X будем обозначать
Cj[Sj] и понимать под этим обозначением следующее:
Cj[Sj] = {t : χCj (t) = 1},
где: t = {(Xj1 , aj1 ), (Xj2 , aj2 ), . . . , (Xjk , ajk )}, причем, ajk ∈ Djk .
χCj (t) характеристическая функция ограничения Cj[Sj], областью опре-
деления которой являются все возможные отображения из Sj в множе-
⋃
ство
Di.
i=1
Схожая формализация отношений, где кортеж трактуется как отображе-
ние, а отношение как конечное множество отображений, встречается в [11].
Многоместные отношения, заданные экстенсионально, могут быть выра-
жены более компактно, чем полным перечислением своих кортежей. В [12]
приводится обзор видов табличных ограничений, к которым, в частности от-
носятся, сжатые таблицы (compressed-table, compact-table), а также смарт-
таблицы или умные таблицы (smart-таблицы) [12-16]. Там же предложено
классифицировать табличные ограничения на ограничения C-типа и ограни-
чения D-типа. В настоящей работе используется два вида табличных ограни-
чений, где в качестве ячеек выступают не отдельные элементы, а множества.
Первый вид это сжатые таблицы C-типа. Под сжатой таблицей C-типа
размерности m × n будем понимать следующее:
X1
X2
··· Xn
D1
D2
··· Dn
{
K11
K12
··· K
1n
{
}
def=
(X1, a1) , . . . , (Xn, an)
:
K21
K22
··· K2n
Km1 Km2 ··· Kmn
(
)
(
)
}
n
m
n
∧
χDj (aj)
∧
∨∧
χKij (aj)
=1 .
j=1
i=1
j=1
Здесь Kij обозначает компоненту-множество, χDj (aj ) и χKij (aj) харак-
теристические функции множества Dj , χKij (aj ) и множества Kij соответ-
158
ственно. Областью определения обеих характеристических функций являет-
⋃
ся множество Di.
i=1
В верхних двух строках таблицы (заголовок таблицы) перечисляются име-
на переменных и соответствующие переменным домены. Заголовок может
отсутствовать.
Другой вид используемых в работе табличных ограничений это сжатые
таблицы D-типа, которые записываются в обратных скобках:
X1
X2
···
Xn
D1
D2
···
Dn
{
K11
K12
··· K
{
}
1n
def=
(X1, a1) , . . . , (Xn, an)
:
K21
K22
··· K2n
Km1 Km2 ··· Kmn
(
)
(
)
}
n
m
n
∧
χDj (aj)
∧
∧∨
χKij (aj)
=1 .
j=1
i=1
j=1
В [12, 16] описаны правила распространения табличных ограничений, ко-
торые могут быть использованы для дополнительного ускорения предлагае-
мого метода. К сжатым таблицам могут быть применены операции реляци-
онной алгебры, также к ним применяется операция дополнения многомест-
ных отношений, которая практически не используется в реляционных СУБД.
Приведем теорему, из формулировки которой видна низкая вычислительная
сложность операции дополнения для сжатых таблиц.
Теорема 1. Пусть дана сжатая таблица C-типа, содержащая m строк
и n столбцов
K11
K12
··· K1n
K21
K22
··· K2n
T [X1, X2, . . . , Xn] =
,
Km1 Km2
··· Kmn
тогда ее дополнение T [X1,X2,... ,Xn] относительно универсума
{
(
)
}
{
}
n
U [X1, X2, . . . , Xn] =
(X1, a1) , . . . , (Xn, an)
:
∧
χDj (aj)
=1
j=1
может быть представлено в виде сжатой таблицы D-типа той же раз-
мерности, где каждая компонента является дополнением соответствую-
159
щей компоненты исходной таблицы C-типа:
K11
K12
··· K
1n
K21
K22
··· K2n
T [X1, X2, . . . , Xn] =
.
Km1 Km2
··· Kmn
Доказательство. Поскольку под T [X1,X2,...,Xn] понимается выра-
жение: T [X1, X2, . . . , Xn] = U [X1, X2, . . . , Xn] \T [X1, X2, . . . , Xn] , то
(
)
n
χU\T (t) =
∧
χDj (aj)
∧¬
j=1
[(
)
(
)]
n
m
n
¬
∧
χDj (aj)
∧
∨∧
χKij (aj)
=
j=1
i=1
j=1
(
)
(
)
n
m
n
=
∧
χDj (aj)
∧
∧
∨
¬χKij (aj)
j=1
i=1
j=1
Полученная функция в точности описывает сжатую таблицу
T [X1, X2, . . . , Xn], что и требовалось доказать.
4. Выявление замкнутых множеств общих признаков объектов
с помощью методов программирования в ограничениях
Разработанный метод состоит из двух этапов: на первом этапе генериру-
ются кандидаты в формальные понятия, на втором выполняется проверка,
удовлетворяют ли кандидаты требованиям к формальным понятиям.
Особенности первого этапа
На первом этапе важно исключить как можно больше заведомо неперспек-
тивных вариантов. Для этого необходимо выполнить следующие шаги:
1) представить обучающую выборку в виде сжатой таблицы D-типа;
2) преобразовать полученную сжатую таблицу D-типа в эквивалентную
ей сжатую таблицу C-типа, используя оригинальные способы ветвления и
отсечения неперспективных ветвей дерева поиска.
В данном случае решение ЗУО состоит не в поиске элементарных кор-
тежей, которые удовлетворяют сжатой таблице D-типа, сформированной на
первом шаге, а в нахождении всех таких сжатых кортежей (compressed tuples)
C-типа, которые описывают кандидатов в формальные понятия и представ-
ляют собой области в пространстве признаков X, Y .
В процессе решения каждому уровню дерева поиска сопоставляется одна
из строк сжатой таблицы D-типа, а узлу конкретная компонента данной
160
Таблица 1. Пример формального контекста
m1
m2
m3
m4
g1
0
0
1
1
g2
0
1
1
0
g3
1
0
0
1
g4
1
1
1
0
строки. Каждое решение ЗУО формируется путем выбора по одной компо-
ненте из каждой строки сжатой таблицы D-типа. В качестве примера для ил-
люстрации работы предлагаемого метода рассмотрим следующую объектно-
признаковую таблицу (табл. 1).
Для данного примера выпишем следующую сжатую таблицу C-типа
K[XY ], где доменом атрибута X является множество G (множество объек-
тов), а в качестве домена атрибута Y выступает множество M (множество
признаков этих объектов):
{g1, g2}
{m1 }
{g1, g3}
{m2 }
K[XY ] =
{g3 }
{m3 }
{g2, g4}
{m4 }
Каждая строка данной сжатой таблицы соответствует столбцу табл. 1 и
описывает множество клеток, где не стоят “единички”.
Сжатая таблица целиком описывает дополнение отношения, представлен-
ного табл. 1.
Тогда, согласно теореме 1, дополнением отношения K[XY ], которое соот-
ветствует самой табл. 1, будет следующая сжатая таблица K[XY ]:
{g3, g4}
{m2, m3, m4}
{g2, g4}
{m1, m3, m4}
K[XY ] =
{g1,g2, g4}
{m1, m2, m4}
{g1, g3}
{m1, m2, m3}
Сжатую таблицу D-типа K[XY ], описывающую формальный контекст,
можно выписать по исходной табл. 1 без использования промежуточной
сжатой таблицы C-типа, просматривая каждый столбец табл. 1 и сопостав-
ляя ему соответствующий сжатый кортеж D-типа. Так, первый столбец
табл. 1. (столбец m1) соотносится с первым кортежем сжатой таблицы D-ти-
па K[XY ]. Компонента Y данного кортежа вычисляется следующим обра-
зом: {m2, m3, m4} = M\{m1}. Компонента X представляет собой множество
{g3, g4}, т.е. множество объектов, напротив которых стоят “единички” в столб-
це m1 табл. 1. Вычислительная сложность преобразования объектно-призна-
кового представления формального контекста в сжатую таблицу D-типа оце-
нивается как O(|G||M|).
161
X Î {g1, ..., g4}
Y Î {m1, ..., m4}
X Î {g1, g2, g3, g4}
X Î {g3, g4}
Y Î {m2, m3, m4}
Y Î {m1, m2, m3, m4}
X Î {g1, g2, g3, g4}
X Î {g4}
X Î {g3, g4}
X Î {g2, g4}
Y Î {m3, m4}
Y Î {m1, m2, m3, m4}
Y Î {m1, m3, m4}
Y Î {m2, m3, m4}
X Î {g4}
X Î {g4}
X Î {g2, g4}
X Î {g2, g4}
Y Î {m1, m2, m3, m4}
Y Î {m1, m3, m4}
Y Î {m2, m3, m4}
Y Î {m2, m4}
X Î {g1, g2, g3, g4}
Y Î {m3}
X Î {g2, g4}
X Î {g2, g4}
X Î {g4}
X Î {g4}
Y Î {m2, m3}
Y Î {m2}
Y Î {m1, m3}
Y Î {m1, m2, m3}
X Î {g1, g2, g4}
X Î {g1, g3}
X Î {g3, g4}
X Î {g4}
Y Î {m3, m4}
Y Î {m4}
Y Î {m1, m4}
Y Î {m1, m2, m4}
X Î {g1}
X Î {g1, g2, g4}
X Î {g4}
X Î {g3}
X Î {g3, g4}
Y Î {m3, m4}
Y Î {m3}
Y Î {m1, m2}
Y Î {m1, m4}
Y Î {m1}
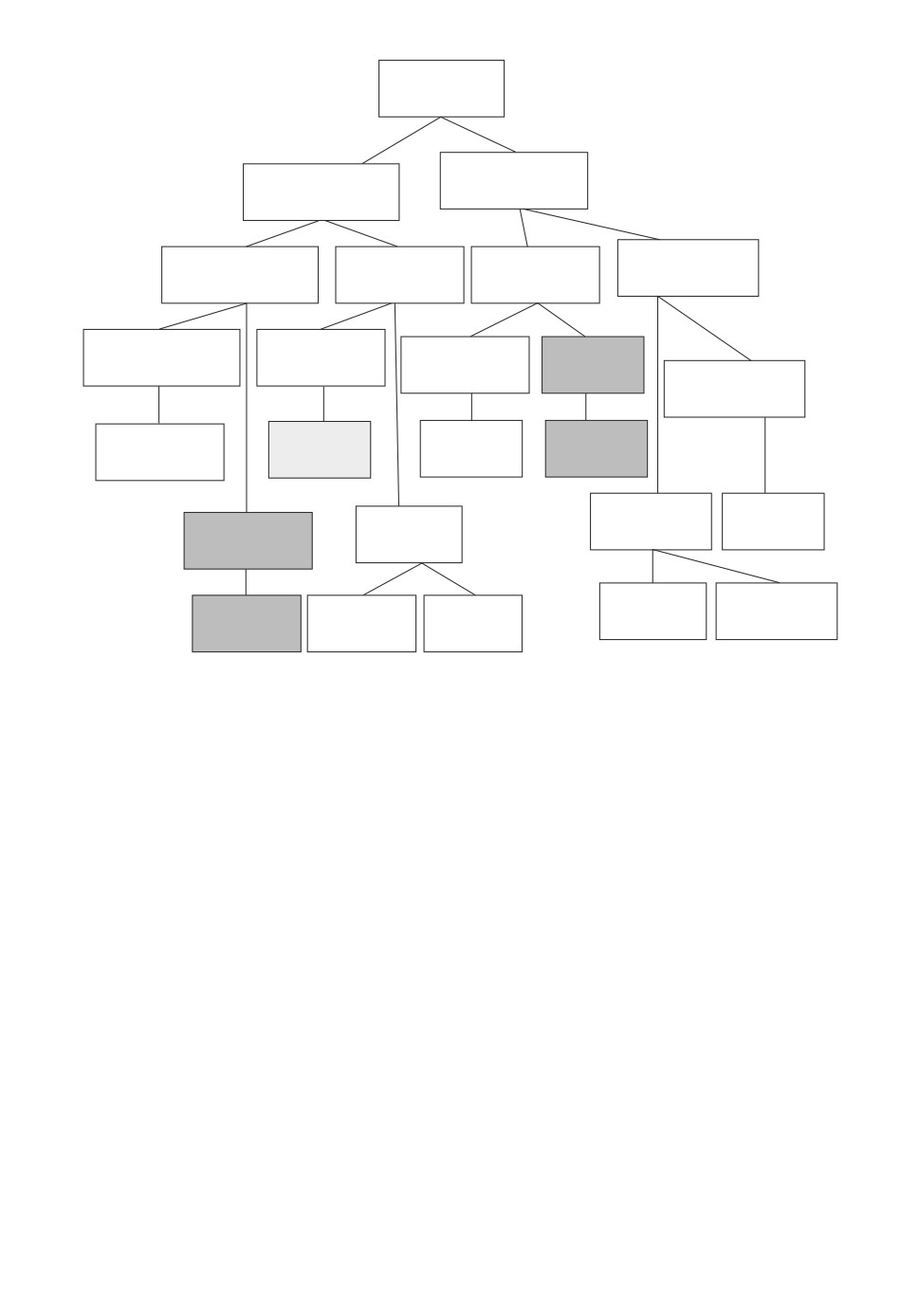
Пример дерева поиска.
Исходную объектно-признаковую таблицу в виде сжатой таблицы D-типа
можно записать и другим способом, сопоставляя кортежам сжатой таблицы
не столбцы, а строки исходной объектно-признаковой таблицы. Второй спо-
соб предназначен для случая, когда число признаков превышает число объ-
ектов, первый способ подходит для случая, когда число объектов больше чис-
ла признаков. Поскольку в рассматриваемых задачах выявления паттернов,
как правило, признаков существенно меньше, чем объектов, то дальнейшее
описание метода (без потери общности) будет опираться на первый способ
представления обучающей выборки. На рисунке приводится дерево поиска,
которое получается в результате применения предложенного принципа ветв-
ления.
Оценим в худшем случае сложность этапа генерации кандидатов в фор-
мальные понятия. Число операций, выполняемых для получения канди-
датов, соответствует числу дуг в дереве поиска, которое определяется
суммой членов геометрической прогрессии: 2 + 22 + . . . + 2min(|G|,|M|)
=
= 2∗(2min(|G|,|M|) - 1). Выполнение каждой операции сводится к |G| + |M|
операциям умножения битов, поскольку информация вида X ∈ A, Y ∈ B
может быть представлена секционированным булевым вектором размера
162
|G| + |M|. Таким образом, число битовых операций логического умножения
равно 2∗(|G| + |M|)∗(2min(|G|,|M|) - 1), а алгоритмическая сложность данного
этапа оценивается как O(2∗(|G| + |M|)∗2min(|G|,|M|)).
Пусть формальный контекст записывается в виде сжатой таблицы K[XY ]
G1
M \{m1}
{
{
}
G2
M \{m2}
def=
(X,a1),(Y,a2)
:
G|M| M\{m|M| }
}
|M|
))
: (χG (a1) ∧ χM (a2)) ∧
∧
(χG
(a1) ∨
(χM\{m
=1.
i
i} (a2)
i=1
Тогда формальное понятие описывается сжатой таблицей C-типа R[XY]
= {{(X, a1) , (Y, a2)} : (χG (a1) ∧ χM (a2)) ∧ (χA (a1) ∧ (χB (a2)) = 1} .
При этом должны выполняться два условия:
1) ∀ t = {(X, a1) , (Y, a2)} χR[XY] (t) → χK[XY] (t) = 1;
2) не существует сжатой таблицы C-типа Z[XY ] такой, что
= {{(X, a1) , (Y, a2)} : (χG (a1) ∧ χM (a2)) ∧ (χS (a1) ∧ (χV (a2)) = 1}
и
∀t χZ[XY] (t) → χK[XY] (t) = 1 и
∀t χR[XY] (t) → χZ[XY] (t) = 1.
Минимальные требования, предъявляемые к кандидату в формальные по-
нятия, состоят в том, что он должен представлять собой сжатую таблицу
C-типа R[XY ] того же вида, что и формальное понятие, и должно выпол-
няться условие 1.
Теорема 2. Получаемое в результате применения предложенного мето-
да множество кандидатов в формальные понятия содержит множество
всех формальных понятий.
Доказательство теоремы вынесено в приложение.
Рассмотрим возможности ускорения предложенного метода. Во-первых,
после выполнения операции выбора компоненты из некоторой строки можно
осуществлять распространение ограничений на основе правил редукции для
случая сжатых таблиц [12, 16]. Во-вторых, для отсечения неперспективных
ветвей дерева поиска можно использовать отношения частичного порядка на
множествах объектов и признаков. В настоящей статье сосредоточим внима-
ние на второй возможности.
163
Каждому объекту может быть сопоставлен булев вектор (строка в табли-
це “объект-признак”), каждому признаку столбец в той же таблице. Так,
объекту g2 в табл. 1 соответствует булев вектор 0110, размерность которого
совпадает с общим количеством признаков, а объекту g4 соответствует век-
тор
1110. В свою очередь, признак m2 может быть представлен булевым
вектором 0101, а например, признак m3 вектором 1101.
Будем говорить, что объект gi (признак mk) доминирует объект gj (при-
знак ml) и обозначать gi ≥ gj (mk ≥ ml) тогда и только тогда, когда булев
вектор, соответствующий объекту gi (признаку mk), покомпонентно доми-
нирует булев вектор, соответствующий объекту gj (признак ml). Так, для
данного примера: g4 ≥ g2, m3 ≥ m2.
При наличии у кандидата доминируемого признака (в примере m2) дол-
жен обязательно присутствовать и доминирующий признак (m3), аналогично,
если у кандидата множество объектов включает доминируемый объект (g2),
то оно должно включать и доминирующий объект (g4). Иначе кандидат не
является формальным понятием.
На рисунке вершины деревьев поиска, не удовлетворяющие данным требо-
ваниям, обозначены темно-серым цветом. Если какая-то вершина не удовле-
творяет описанным требованиям, то никакие из ее дочерних вершин также
не будут им удовлетворять.
Однако описанных проверок недостаточно, чтобы исключить всех непод-
ходящих кандидатов. Так, на рисунке имеется листевая вершина, обозначен-
ная светло-серым цветом, которая не соответствует определению формаль-
ного понятия. Следовательно, необходим этап отсева кандидатов, не удовле-
творяющих требованиям к формальным понятиям.
Особенности второго этапа
Для рассматриваемого примера все кандидаты в формальные понятия
представлены на рисунке в виде листевых узлов дерева поиска. Для каж-
дого листевого узла, описываемого сжатым кортежем [A, B], выполняются
следующие действия: 1) для объектов A вычисляется A′, вычисление произ-
водится путем умножения булевых векторов, соответствующих объектам из
множества A; 2) A′ сравнивается с множеством B, в случае несовпадения
выход с отрицательным результатом. Иначе проверка пройдена успешно.
Рассмотрим вершину дерева поиска, которая на рисунке затемнена светло-
серым цветом: [A = {g4}, B = {m1, m3}]. На первом шаге проверки получаем
множество признаков A′, которое описывается булевым вектором 1110 (чет-
вертая строка таблицы “объект-признак”), что соответствует множеству при-
знаков {m1, m2, m3}. На втором шаге сравнивается множество B, описывае-
мое булевым вектором 1010, и множество A′. Рассматриваемый кандидат в
формальное понятие не проходит проверку.
Сложность выполнения данного этапа зависит от количества проверяемых
кандидатов
2min(|G|,|M|). Проверка каждого из них в худшем случае сводит-
ся к выполнению (|G| - 1)(|M|) операций битового умножения при первом
164
способе представления контекста в виде сжатой таблицы D-типа и к выпол-
нению ((|M| - 1)(|G|) операций при втором способе представления. Опера-
циями сравнения для оценки можно пренебречь. Таким образом, сложность
этапа проверки: O((|G| |M| - min(|G| , |M|))∗2min(|G|,|M|)).
Общая алгоритмическая сложность двух этапов предлагаемого метода мо-
жет быть оценена как: O((|G| |M|+2∗ |M|+2∗ |G|-min(|G| , |M|))∗2min(|G|,|M|)).
5. Заключение
Разработанный метод реализует новый подход к задаче эффективного по-
рождения формальных понятий, в рамках которого данная задача ставит-
ся как задача удовлетворения табличных ограничений и используется ори-
гинальное представление обучающей выборки с помощью сжатых таблиц
D-типа. Искомыми решениями ЗУО ограничений являются не элементарные
кортежи, а сжатые кортежи C-типа, которые соответствуют формальным по-
нятиям. Получение требуемых сжатых кортежей C-типа обеспечивается за
счет разработанного способа ветвления дерева поиска и выполняемых про-
верок. Предложенный метод обладает оценкой вычислительной сложности,
которая для некоторых типов входных данных лучше оценок, упомянутых
во введении.
ПРИЛОЖЕНИЕ
Покажем, что каждый из 2|M| генерируемых кандидатов в формальные по-
нятия характеризуется уникальным множеством признаков Q, которое пред-
ставляет собой один из элементов булеана множества признаков M, а множе-
ство объектов данного кандидата в формальные понятия равно множеству Q′
(применение оператора Галуа к множеству Q), т.е. в данное множество объек-
тов нельзя добавить никаких других объектов, имеющих тот же набор общих
признаков Q. В этом случае множество генерируемых кандидатов в формаль-
ные понятия содержит множество всех формальных понятий.
Фактически предложенный метод сводится к раскрытию скобок в выраже-
нии для характеристической функции. Выполняя данное раскрытие, имеем
2|M|
(
)
χK[XY] (t) =
∨
(χG (a1) ∧ χM (a2)) ∧ ∧
χGo (a1) ∧ ∧ χM\{m
,
r} (a2)
k=1
o∈Ik
r∈Jk
где:
{
}
∀k∈
1, . . . , 2|M| Ik ∪ Jk = {1, . . . , |M|}, Ik ∩ Jk = ∅;
{
}
∀l,e ∈
1, . . . , 2|M| Il = Ie, Jl = Je.
Заметим, что
χM\{m
⋃
∧
r} (a2) = χ⋂r∈J
M \{mr } (a2)=χM\
r∈Jk
{mr } (a2),
r∈Jk
k
165
тогда
(
)
2|M|
⋃
χK[XY] (t) =
∨
(χG (a1) ∧ χM (a2)) ∧ ∧ χGo (a1) ∧ χM\
{mr } (a2)
k=1
o∈I
k
r∈Jk
Каждое слагаемое этой логической суммы может быть взаимно однозначно⋃
сопоставлено с некоторым множеством признаков M\
{mr} элементом
r∈Jk
булеана множества признаков. Слагаемое с фиксированным индексом k∗ мо-
жет быть сопоставлено сжатой таблице C-типа Rk∗ [XY ], описывающей кан-
дидата в формальные понятия
{
⋂
⋃
{mr} =
{(X, a1) , (Y, a2)} :
Go, M\
o∈Ik∗
r∈Jk∗
}
⋃
(χG (a1) ∧ χM (a2)) ∧ ∧ χGo (a1) ∧ χM\
{mr } (a2)=1
o∈I
k∗
r∈Jk∗
Очевидно, что ∀ t = {(X, a1) , (Y, a2)} χRk∗[XY] (t) → χK[XY] (t) = 1.
⋂
Чтобы показать, что
Go является результатом применения оператора
o∈Ik∗
⋃
Галуа к M\
{mr}, докажем, что не существует сжатой таблицы C-типа
r∈Jk∗
Zk∗[XY ] такой, что
⋂
⋃
⋂
{mr} , W ⊆ G\
Go ∪ W, M\
Go , W = ∅,
o∈Ik∗
r∈Jk∗
o∈Ik∗
χZk∗[XY ] (t) →χK[XY ] (t) = 1.
Распишем характеристическую функцию данной сжатой таблицы C-типа
χZk∗[XY ] (t) =
(
)
⋃
= (χG (a1) ∧ χM (a2)) ∧
∧χGo (a1) ∨ χW (a1)
∧χM\
{mr } (a2).
o∈Ik∗
r∈Jk∗
⋃
Поскольку в данном случае выполняется G0 ∪ W ⊆ G, M\
{mr} ⊆ M,
r∈Jk
то χZk∗[XY] (t)
(
)
⋃
∧χGo (a1) ∨ χW (a1)
∧χM\
χZk∗[XY ] (t) =
{mr } (a2).
o∈Ik∗
r∈Jk∗
Аналогично можно упростить и χK[XY] (t) (здесь рассматривается КНФ)
|M|
)
χK[XY] (t) =
∧
(χG
(a1) ∨ (χM\{m
i
i} (a2)
i=1
166
Выражение ∀ t = {(X, a1) , (Y, a2)} χZk∗[XY] (t) → χK[XY] (t) = 1 выпол-
няется, если верно
)
((
)
⋃
∀i ∈ {1,... ,|M|}
∧χGo (a1) ∨ χW (a1)
∧χM\
→
{mr } (a2)
o∈Ik∗
r∈Jk∗
)
→
(χG
(a1) ∨ (χM\{m
= 1.
i
i} (a2)
Другими словами, должно выполняться выражение
((
)
)
∀i ∈ {1,... ,|M|}
∧χGo (a1) ∨ χW (a1) → χGi (a1)
∨
o∈Ik∗
(
)
⋃
∨ χM\
= 1.
{mr } (a2)→χM\{mi}(a2)
r∈Jk∗
(
)
⋃
Равенство χM\
= 1 верно при i ∈ Jk∗ и не
{mr } (a2)→χM\{mi}(a2)
r∈Jk∗
верно при i ∈ Ik∗ .
Рассмотрим выражение
((
)
)
∀i ∈ Ik∗
∧χGo (a1) ∨ χW (a1) → χGi (a1)
= 1.
o∈Ik∗
Его можно преобразовать следующим образом:
((
)
)
∀i ∈ Ik∗
∧χGo (a1) → χGi (a1) ∧ (χW (a1) → χGi (a1))
= 1.
o∈Ik∗
Заметим, что при любом i ∈ Ik∗ функция χGi (a1) совпадает с одной из
функций χGo (a1) из произведения
∧
χGo (a1), поэтому при любом i ∈ Ik∗
o∈Ik∗
(
)
∧χGo (a1) → χGi (a1)
= 1. Покажем, что существует i ∈ Ik∗ , при кото-
o∈Ik∗
ром (χW (a1) → χGi (a1)) = 0. В противном случае должно выполняться вы-
(
)
ражение
∧ (χW (a1) → χGi (a1))
= 1, которое можно преобразовать так:
i∈Ik∗
(
)
(
)
= 1, а затем: χW (a1) → χ⋂G
(a1)
= 1. По-
χW (a1) → ∧ χGo (a1)
o
o∈Ik∗
o∈Ik∗
(
)
⋂
следнее выражение не может быть выполнено, поскольку W ⊆ G\
Go
o∈Ik∗
и предполагается, что W = ∅. Таким образом, доказано, что не существует
сжатой таблицы C-типа Zk∗ [XY ].
167
СПИСОК ЛИТЕРАТУРЫ
1.
Bessiere C., De Raedt L., Kotthoff L. et. al. Data Mining and Constraint Program-
ming - Foundations of a Cross-Disciplinary Approach. Lecture Notes in Com. Sci-
ence. 10101. Springer, 2016.
2.
Gan W., Lin J., Fournier-Viger P. et. al. A survey of utility-oriented pattern min-
ing // IEEE. Transactions on Knowledge and Data Engineering. 2021. V. 33. No. 4.
P. 1306-1327.
3.
Boudane A., Jabbour S., Sais L. et. al. Enumerating non-redundant association rules
using satisfiability. Springer, 2017.
4.
Финн В.К., Аншаков О.М., Виноградов Д.В. Многозначные логики и их приме-
нения. Том 2: Логики в системах искусственного интеллекта. M.: URSS, 2020.
5.
Ganter B., Wille R. Formal Concept Analysis: Math. Foundations. Springer, 1999.
6.
Кузнецов С.О. Автоматическое обучение на основе Анализа Формальных Поня-
тий // AиТ. 2001. № 10. С. 3-27.
Kuznetsov S.O. Machine Learning on the Basis of Formal Concept Analysis // Au-
tom. Remote Control. 2001. No. 62. P. 1543-1564.
7.
Wolff K. Temporal Concept Analysis with SIENA // Supplementary Proceedings of
ICFCA, Conference and Workshops. Frankfurt, Germany: Springer, 2019.
8.
Lazaar N., Lebbah Y., Loudni S. et. al. A global constraint for closed frequent pattern
mining. CP. Springer, 2016.
9.
Kuznetsov S.O., Obiedkov S.A. Comparing performance of algorithms for generating
concept lattices // J. Experiment. Theoret. Art. Int. 2002. V. 14. P. 189-216.
10.
Mackworth A. Consistency in networks of relations // Art. Int. 1977. No. 8(1).
P. 99-118.
11.
Maier D. The Theory of Relational Databases. Computer Science Press, 1983.
12.
Zuenko A. Representation and Processing of Qualitative Constraints Using a New
Type of Smart Tables // 4th Int. Conference on Computer Science and Application
Engineering (CSAE ’20), 2020. 45. P. 1-7.
13.
Yap R., Wang W. Generalized Arc Consistency Algorithms for Table Constraints: A
Summary of Algorithmic Ideas // AAAI 2020. 2020. P. 13590-13597.
14.
Ingmar L., Schulte C. Making Compact-Table Compact // CP 2018, Lecture Notes
Comput. Sci. 2018. V. 11008. P. 210-218.
15.
Mairy J., Deville Y., Lecoutre C. The Smart Table Constraint. Integration of AI
and OR Techniques in Constraint Programming // CPAIOR 2015. Lecture Notes
Comput. Sci. 2015. V. 9075. P. 271-287.
16.
Zuenko A. Local Search in Solution of Constraint Satisfaction Problems Represented
by Non-Numerical Matrices // 2nd Int. Conference on Computer Science and Appli-
cation Engineering (CSAE ’18), 2018. 138. P. 1-5.
Статья представлена к публикации членом редколлегии О.П. Кузнецовым.
Поступила в редакцию 26.01.2022
После доработки 02.06.2022
Принята к публикации 28.07.2022
168