Автоматика и телемеханика, № 3, 2022
Интеллектуальные системы управления,
анализ данных
© 2022 г. А.М. МИХАЙЛОВ, канд. техн. наук (alxmikh@gmail.com),
М.Ф. КАРАВАЙ, д-р техн. наук (mkaravay@yandex.ru),
В.А. СИВЦОВ (TheDeGe@yandex.ru)
(Институт проблем управления им. В.А. Трапезникова РАН, Москва)
МГНОВЕННОЕ ОБУЧЕНИЕ ПРИ РАСПОЗНАВАНИИ ОБРАЗОВ
Одним из основных недостатков искусственных нейронных сетей явля-
ется медленное обучение, связанное с необходимостью вычисления боль-
шого количества коэффициентов. В статье показано, что обучение мож-
но намного ускорить. Ускорение достигается за счет резкого сокращения
числа обучающих образов. Кроме того, как для формирования призна-
ков, так и для последующего распознавания объектов использован метод
обратных образов, позволяющий обойтись без коэффициентов, что суще-
ственно сокращает объемы вычислений. При мгновенном обучении, как
и при глубоком обучении, признаки формируются автоматически. Про-
веденные вычислительные эксперименты показали инвариантность пред-
ложенного метода не только к масштабированию и вращениям, но и к
значительным деформациям распознаваемых объектов.
Ключевые слова: распознавание образов, машинное обучение, глубокое
обучение, обратные образы, многомерное индексирование.
DOI: 10.31857/S0005231022030102
1. Введение
Традиционно, в задачах распознавания неизвестный образ x классифици-
руется как принадлежащий к одному из N классов. Для этого вычисляют-
ся вероятности этих классов p1(x), p2(x), . . . , pN (x), после чего образ x отно-
сится к классу с максимальной вероятностью. Существует много способов
нахождения вероятностей классов, например байесовские классификаторы,
нейронные сети и т.д. В частности, в нейронных сетях вероятности классов
пропорциональны активностям выходных узлов. Поэтому на класс объекта
указывает максимально активный узел. В отличие от нейронных сетей, где
активность узлов определяется значениями коэффициентов, найденными при
обучении, в данной статье коэффициенты не используются. Это становит-
ся возможным в результате использования метода обратных образов (МОО)
[1], позволяющего находить сходство входного образа с заданными класса-
ми образов. Систему распознавания на основе метода МОО будем называть
индекстроном.
144
Идея обратных образов аналогична идее обратных списков, используемых
в методе TF-IDF [2]. Другими словами, если признак встречается во всех
классах, то роль этого признака для оценки релевантности образа равна ну-
лю. Однако веса признаков в предложенном в статье методе не вычисляются
вообще. Также существуют другие отличия, в частности, отметим следующие
моменты:
а) В то время как в поисковиках на вход поступает текст, в данной статье
поиск проводится по числам-признакам, каждое из которых может изменять-
ся в широком диапазоне в условиях шумов.
б) В поисковиках адреса, т.е. числа, в которые переводятся слова это
адреса единой адресной области. В данной статье создаются несколько адрес-
ных областей, число которых равно размерности вектора признаков, пред-
ставляющего образ.
в) В поисковиках отсутствует понятие радиуса обобщения, который регу-
лирует степень генерализации. В результате в поисковиках автоматически не
создаются классы документов, а модели векторного пространства требуют
использования дополнительных средств кластеризации. В данной статье в
зависимости от радиуса обобщения число классов образов определяется ав-
томатически в зависимости от заданной степени обобщения.
г) Поисковики автоматически не решают задачи предсказания. В данной
статье предложенный метод обращения образов позволяет единообразно ре-
шать как задачу поиска ближайшего образа, так и задачу предсказания вре-
мени событий.
В данной статье при классификации объектов изображений с произволь-
ным задним планом использован двухуровневый классификатор. На первом
уровне в качестве признаков используются пиксели, а на втором уровне
частоты классов выделенных пикселей. При этом использование частотного
порога переводит классы в разряд бинарных объектов либо класс присут-
ствует в описании объекта, либо отсутствует. При распознавании для выде-
ления пикселей объектов на изображениях с произвольным задним планом
используются гистограммы классов пикселей объектов, которые создаются
при обучении. В таких гистограммах представлены существенные классы,
т.е. классы пикселей с частотами выше пороговой. При распознавании порог
частоты может понижаться в 2 раза, если существенных классов не найде-
но при верхнем значении порога. Критерием выделения пикселя является
его принадлежность к существенному классу. Такие пиксели группируются в
кластеры с помощью алгоритма окраски связанных объектов, т.е. объектов,
пиксели которых отстоят друг от друга не более чем на заданный радиус.
Кластеры последовательно распознаются на 2-м уровне, входными при-
знаками которого служат существенные классы в бинарной форме. Выходом
2-го уровня служит гистограмма классов второго уровня, где класс второго
уровня это идентифицированное имя неизвестного объекта, представлен-
ного кластером выделенных точек. Если на изображении без объекта был
ошибочно найден объект, то классы пикселей, приведшие к ошибке, ингиби-
145
руются, т.е. удаляются из гистограммы классов пикселей, представляющих
ошибочно найденный объект.
Это возможно, так как для обучения каждому классу достаточно одно-
го разностного изображения. Под разностным изображением, называемым
также подписью объекта, понимается изображение с объектом минус изобра-
жение без объекта. Для получения разностного изображения исходные кадры
800 × 600 редуцируются в кадры 400 × 300 с помощью фильтра (см. подраз-
дел 2.8), позволяющего компенсировать возможное смещение сравниваемых
изображений, возникающее из-за малых сдвигов камеры. Если объект дви-
жется, то для получения разностного изображения достаточно двух кадров.
Такой подход позволяет обойтись при обучении без сотен и тысяч изображе-
ний объекта одного класса объекта, снятого при разных ракурсах и мас-
штабах. Одного кадра достаточно во многих приложениях, когда цветовая
гамма пикселей объекта мало зависит от ориентации, например от вида кош-
ки сзади, спереди или сбоку. Очевидно, что при использовании разностного
изображения задний план пропадает и обучение ведется только по пикселям
объекта.
В статье описывается эксперимент с изображениями цветов и кошек с про-
извольным задним планом. Результаты представлены и аннотированы в раз-
деле 3, п. 1.
Для сравнения производительности МОО и искусственных нейронных се-
тей было выбрано еще одно приложение, в котором использован набор дан-
ных CIFAR-10 [3]. (См. раздел 3, п. 2). Комментарии представлены в разделе
Заключение. Подробно МОО рассмотрен в разделе 2.
2. Материалы и методы
2.1. Извлечение признаков
В приложении, связанном с распознаванием трехмерных объектов, ис-
пользовались признаки 2 уровней. На первом уровне признаками служили
красная, зеленая и синяя составляющие цвета каждого пикселя, образующие
трехмерный вектор. Каждый такой вектор использовался для классификации
пикселя. На втором уровне признаками служили классы пикселей, а именно:
классы, выделяемые с помощью гистограммы классов пикселей распознавае-
мого объекта. При этом класс включался в множество признаков второго
уровня, если его частота превышала установленный порог.
2.2. Классификация образов
При классификации образов, как правило [4], неизвестный вектор x отно-
сится к классу с наибольшей условной вероятностью p1(x), p2(x), . . . , pN (x).
В настоящей статье для нахождения сходства входного образа с заданными
классами используется понятие обратных образов, введенное в [5] и рассмот-
ренное также в [1]. Этот метод напоминает технологию обратных файлов,
используемую в поисковой системе Google [6] и в подходе “bag of words” [7].
146
В то время как в подходе [6, 7] для поиска объектов информация преобразу-
ется в текст, индекстрон оценивает сходство классов, анализируя обратные
образы числовых признаков.
В задачах классификации обратный образ признака x
это множе-
ство {n}x классов n, связанных с этим признаком. Класс n связан с при-
знаком x, если x является элементом образа из этого класса. Например, для
двух классов A, A, A и T, T признак “горизонтальная линия” участвует как
в А-, так и в Т-классе, тогда как признак “вертикальная линия” участвует
только в классе Т:
{A, T}0◦ ,
{T}90◦ .
Пусть N классов образов представлены строками матрицы, где индексы
строк n указывают на классы образа, а элементы строки xnm это признаки
образа:
[xnm]N×M .
Определение 1. Обратный образ {n}x,m признака xnm это множе-
ство классов n, связанных с этим признаком, т.е.
(1)
{n}xm = {n : |xnm
− x| ≤ R}.
Здесь R радиус обобщения, обсуждаемый в подразделе 2.5.
Распределение связей образа x = (x1, x2, . . . , xm, . . . , xM ) с классами су-
перпозиция
∑
(2)
F(R)n(x) =
f(R)n(xm
),
n = 1,2,...,N.
m=1
Здесь
n (xm) = 1, если n ∈ {n}xm, и
n (xm) = 0, если n ∈ {n}xm, функ-
ция связанности признака xm с классом n.
2.3. Определение класса
Можно определить класс с помощью обобщенного расстояния Хэммин-
га между векторами x и y. Такое расстояние определяется как количество
позиций, где соответствующие координаты отличаются более чем на радиус
обобщения R. Например, HR=1(x, y) = 1, если x = (1, 2, 3), y = (2, 2, 5).
По определению класс образа, который представлен вектором xn, вклю-
чает все векторы y такие, что HR(xn, y) = 0. Следовательно, любые две
строки xn, xm матрицы
[xn,k]N×K принадлежат разным классам, если
HR(xn,xm) > 0.
147
Рис. 1. Пример сегментации изображения.
2.4. Обучение
Чтобы получить распределение связей образа, его признаки xm, m =
= 1, 2, . . . , M, использовались в качестве адресов списков классов, называе-
мых колонками. Распределение (2) рассчитывается как гистограмма клас-
сов, находящихся в колонках. При обучении если
n
(x) < M, то вектор x
не может быть классифицирован и должен рассматриваться как представи-
тель нового класса N+. При этом обратные образы обновляются как {n}xm =
= {n}x,m
⋃N+, m = 1,2,... ,M, N+ = N + 1.
Если в процессе обучения N превышает предел Nmax, то память обну-
ляется и значение радиуса обобщения увеличивается. Обычно R = 5-20% от
диапазона признаков X. При этом степень обобщения растет с ростом R.
2.5. Радиус обобщения
Влияние радиуса обобщения R проиллюстрировано на рис. 1. В этой за-
даче сегментации требуется пиксели левого изображения разделить на три
класса (вода, растительность, городские строения) и раскрасить так, как по-
казано на правом изображении. Каждый пиксель на левом рисунке представ-
лен 4-мерным вектором, компоненты которого принадлежат 256-уровневым
диапазонам красного, зеленого, синего и инфракрасного спектров (показан
только один компонент, исходные изображения см. в [8]). (По техническим
причинам на рисунке красному, зеленому, синему цветам соответствуют бе-
лый, серый, черный цвета).
На изображении в центре результат сегментации при R = 0. При этом
большинство пикселей остаются неклассифицированными. На правом изоб-
ражении показана качественная сегментация, достигнутая при R = 10%.
2.6. Алгоритм индекстрона
Обучение начинается с распознавания. Если входной вектор x(m), m =
= 1, 2, . . . , M, не распознан, то он в инверсном виде включается в обратные
множества, становясь представителем нового класса. Поэтому сначала рас-
смотрим а л г о р и т м распознавания.
148
Алгоритм распознавания. Значения компонент входного вектора x(m),
m = 1,2,...,M, используются в качестве адресов обратных образов обра-
зов, являющихся множествами классов. Адресация к обратным образам про-
изводится для вычисления частот fn, n = 1, 2, . . . , N , встречаемости классов
в обратных образах {n}xm. Вычисление выполняется в следующем цикле:
m = 1,2,... ,M для всех r из [-ε,ε] и для всех n из {n}xm+r,m: fn = fn + 1.
Критерий принятия решения о классе i входного образа:
i:fi =TM,
где T (0 < T ≤ 1) порог распознавания.
Если критерий не выполнен, то входной вектор инверсируется и вводится
в обратные образы в качестве нового класса. Введение выполняется следую-
щим образом. Если уже были созданы N классов, то запускается следующий
алгоритм обновления обратных множеств:
1) если N < Nmax, то N = N + 1. В противном случае СТОП.
2) m = 1, 2, . . . , M: {n}x(m),m = {n}x(m),m
⋃N.
Пример. Сначала набор обратных множеств пуст, т.е. N = 0. Затем, при
поступлении 1-го вектора x(m), m = 1, 2, . . . , M, на первом шаге увеличива-
ется на единицу число созданных классов: N = 1. На втором шаге это но-
вое число добавляется в соответствующие обратные множества. В результате
будет создан первый набор, содержащий M обратных множеств {1}x(m),m,
m = 1,2,...,M.
Предположим, что при поступлении второго вектора
y(m), m =
= 1, 2, . . . , M, значения всех его координат, за исключением первой, совпа-
дают по абсолютной величине с координатами первого вектора с точно-
стью до R. Тогда набор обратных множеств на второй итерации принимает
вид: {1}x(m),1, {2}y(m),1, {1, 2}y(m),m, m = 2, . . . , M. В этом наборе множество
{1}x(m),1 осталось от первой итерации, множество {2}y(m),1 появилось впер-
вые, а M - 1 множеств {1, 2}y(m),m, m = 2, . . . , M, обновились, включив в
свой состав второй элемент.
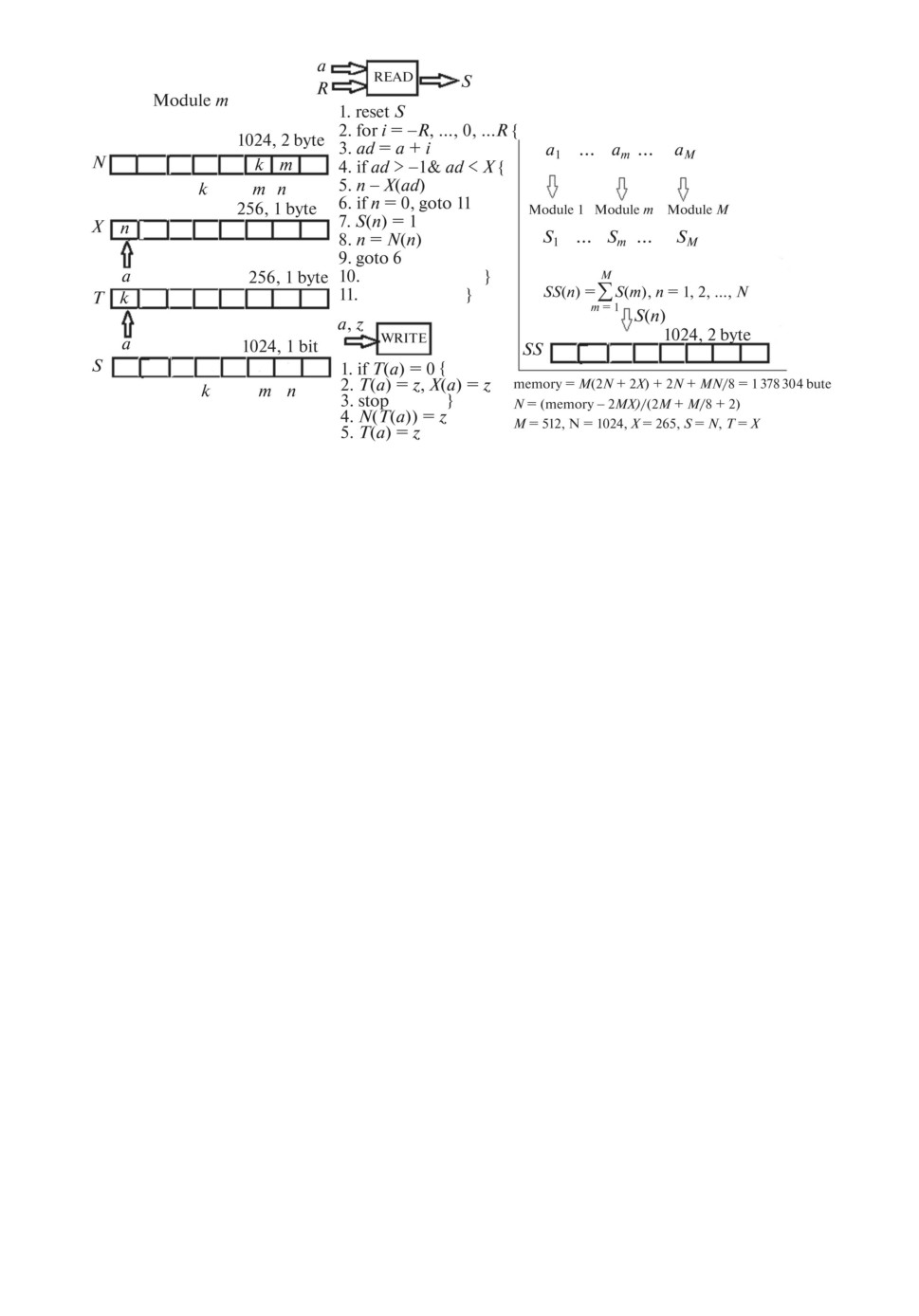
2.7. Архитектура индекстрона
Основными параметрами индекстрона являются размерность образа M,
диапазон признаков X и максимальное количество классов N, которые могут
быть им созданы. Другими словами, индекстрон содержит M групп адресов,
где каждая группа m содержит X адресов в диапазоне от 0 до X - 1. Каждый
адрес (x, m) указывает на колонку или обратный образ {n}x,m. Каждая ко-
лонка содержит имена классов n, а ее высота равна мощности соответствую-
щего обратного образа. Макроколонка определяется радиусом обобщения R
и содержит соседние колонки с адресами из интервала [x - R, x + r].
Параллельная обработка M групп колонок может быть реализована в мик-
росхеме ПЛИС, что приводит к практически мгновенному обучению. Память,
149
Рис. 2. Концептуальная схема индекстрона.
которая должна быть выделена для групп колонок, может быть организова-
на тремя способами: (а) статические колонки, (б) динамически выделяемые
колонки, (в) итерированные одномерные карты [9]. Для этих трех методов по-
требуется следующее количество ячеек памяти MXN, 2MN и MN соответ-
ственно. Здесь метод (в) выигрывает и делает возможной ПЛИС-реализацию
индекстрона (M, X, N) = (512, 256, 1024) на микросхеме с памятью в 1,44 МБ
(рис. 2).
На схеме показан один модуль из M, содержащий четыре массива
(N, X, T, S) плюс общий выходной массив SS, в котором суммируется инфор-
мация всех модулей. Заметим, что количество доступных классов N обратно
пропорционально M, т.е. длине входного вектора x: N = (память - MX -
- MT)/(2M + M/8 + 2).
Нормализованный диапазон дискретных признаков X = 256 часто доста-
точен для многих приложений распознавания образов. При этом как призна-
ки с плавающей запятой, так и целочисленные признаки могут быть преоб-
разованы в 256 дискретных уровней без ущерба для общей точности.
В этой схеме параллельно работают M идентичных модулей, где в m-й
модуль поступает m-й компонент am вектора признаков a1, . . . , am . . . , aM .
Компонент am служит адресом ячейки 256-байтового массива X.
При идентификации вектора выполняется READ-код (см. рис. 2). Выход
модуля это 1024-битное слово Sm. Затем выходы M модулей суммируются
в массиве SS, содержащем 1024 ячейки памяти, элементы которой представ-
∑M
лены 2-байтовыми словами SS(n) =
S(m), n = 1, 2, . . . , N. Массив SS
m=1
содержит распределение связей образа a1, . . . , am . . . , aM .
Если образ не идентифицирован, то после завершения цикла обучения
выполняется WRITE-код. Для этого в m-й модуль поступает m-й компо-
нент am вектора признаков a1, . . . , am . . . , aM , а также имя создаваемого клас-
150
са z. Компонент am служит адресом 256-байтового массива T . Например, при
M = 512, N = 1024, X = 256, T = 256, S = 1024 и SS = 2N общая память со-
ставит 1 378 304 байта.
2.8. Свойства преобразования образов
Каждая группа колонок, m = 1, 2, . . . , M, содержит N различных классов:
∑
|{n}x,m| = N.
x=0
Колонки группы не пересекаются: {n}x,m
⋂{n}y,m = ∅ (x = y).
Из этих свойств следует, что для вектора x максимум распределения свя-
зей
n
(x) = M достигается тогда и только тогда, когда HR(xn, x) = 0.
2.9. Получение разностного изображения
Для получения разностного изображения объекта использовалась функ-
ция, которая проводила сравнение каждого пикселя изображения с объектом,
со всеми пикселями в определенном радиусе (окне), равном 31 × 31 пиксе-
лям, вокруг соответствующего пикселя изображения без объекта. Результа-
том сравнения была сумма разницы соответствующих каналов цветов двух
пикселей. Если после сравнения всех пикселей в окне наименьшая сумма в
этом окне превышала пороговую величину 32, то текущий пиксель изобра-
жения с объектом добавлялся в подпись.
3. Результаты
1. Индекстрон был обучен на 2 разных объектах (цветок и кошка). Для
тестирования те же объекты были показаны под другими ракурсами и при
100
Пороговый уровень
75
Найденный признак
Роза 1(верх. фото). Г/грамма розы 1 (верх. часть рис.)
Роза 2(верх. фото). Г/грамма розы 2 (нижн. часть рис.)
50
25
0
25
50
75
100
25
50
75
100
125
150
175
200
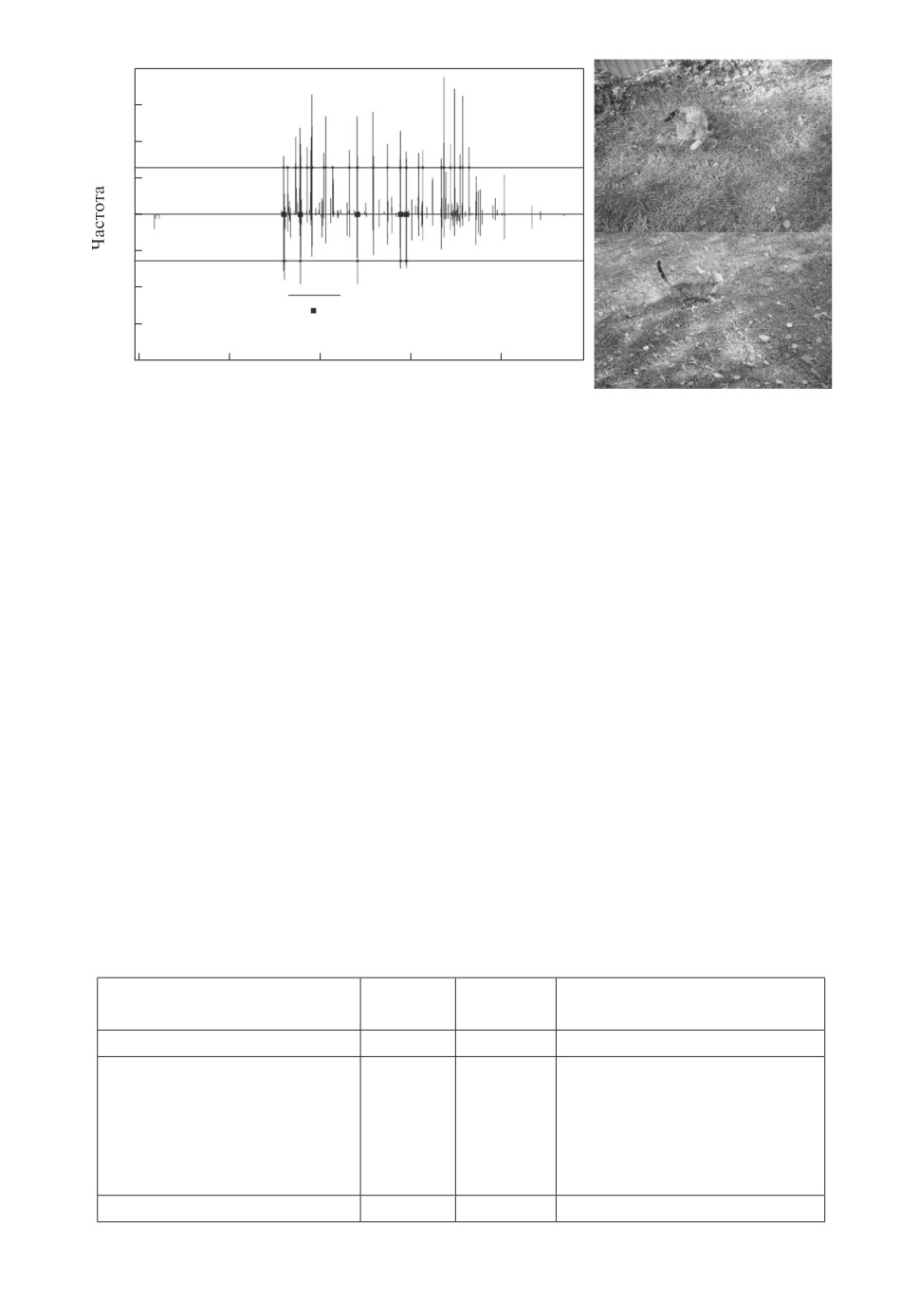
Рис. 3. Сравнение гистограмм подписей изображений объекта цветок с разных
сторон при порогах 32 и 16. Количество общих признаков равно семи.
151
100
Пороговый уровень
Найденный признак
75
Роза (верх. фото). Г/грамма розы (верх. часть рис.)
Кот (нижн. фото). Г/грамма кота (нижн. часть рис.)
50
25
0
25
50
75
100
0
200
400
600
800
Рис. 4. Сравнение гистограмм подписей изображений объектов цветок и кош-
ка. Общих признаков не найдено.
100
75
50
25
0
25
Пороговый уровень
50
Найденный признак
Кот (верх. фото). Г/грамма кота вверху (верх. часть рис.)
75
Кот (нижн. фото). Г/грамма кота внизу (нижн. часть рис.)
100
0
200
400
600
800
Рис. 5. Сравнение гистограмм подписей изображений объектов кошка (вид
спереди) и кошка (вид сбоку). Количество общих признаков равно шести.
других задних планах. Все объекты были успешно распознаны. (В связи с
техническими трудностями при публикации цветные фотографии заменены
на черно-белые, которые не показывают полную картину. При этом реальный
эксперимент проводился с цветными фотографиями.) На рис. 3 показаны ги-
стограмма классов выделенных пикселей 1-го объекта и гистограмма классов
выделенных пикселей того же объекта в другом ракурсе. При частотных по-
рогах 32 и 16 соответственно найдены 7 общих признаков, выделенных жир-
ными точками. Для сравнения на рис. 4 показаны гистограммы 1-го объекта
и 2-го объекта, где видно, что число общих признаков равно нулю. Следо-
вательно, объект в нижней части рис. 3 должен быть идентифицирован как
объект 1. Аналогично объекты в нижней части рис. 5 и рис. 6 должны быть
идентифицированы как объект 2, так как число общих признаков равно ше-
152
100
75
50
25
0
25
50
Пороговый уровень
Найденный признак
75
Кот (верх. фото). Г/грамма кота вверху (верх. часть рис.)
Кот (нижн. фото). Г/грамма кота внизу (нижн. часть рис.)
100
0
200
400
600
800
Рис. 6. Сравнение гистограмм подписей изображений объектов кошка (вид
спереди) и кошка (другое расположение). Количество общих признаков рав-
но пяти.
сти и пяти соответственно, что больше числа 0, возникающего при сравнении
с 1-м объектом. Отметим, что обучение было проведено с использованием
только 2 изображений.
2. Набор данных CIFAR-10 [3] использовался для тестирования индекстро-
на на данных для искусственных нейронных сетей. Для извлечения призна-
ков сверточная нейронная сеть VGG16 с веб-сайта KERAS [10] была предва-
рительно обучена в базе данных ImageNet [11]. Затем VGG16 была обучена
на 50 тысячах черно-белых изображений 32 × 32 (10 категорий) из набора
данных CIFAR-10, обеспечивающих 512 признаков на изображение. Наконец,
признаки 512 × 50 000 использовались для обучения как 4-слойной нейрон-
ной сети, так и индекстрона (таблица, столбец 1). Время обучения указано в
столбце 3 таблицы. При тестировании 10 000 изображений (512 × 10 000 при-
знаков) из вышеуказанного набора данных были классифицированы с ис-
пользованием как четырехслойной нейронной сети, так и индекстрона. Ре-
зультаты приведены в столбце 2 таблицы.
Таблица. Нейронная сеть в сравнении с индексным классификатором
Точность Обучение
Оборудование
Классификатор
%
(сек)
и библиотеки
1
2
3
4
Четырехслойная нейронная
85,3
900
AMD Ryzen 5 3600, Python,
сеть
Nvidia GeForce GTX 1660
Слои: Flatten, Dropout,
Super, TensorFlow, Keras,
Dense (256 нейронов, ReLu
cuDNN
функция активации), Dense
(10 нейронов, softmax)
Индекстрон
82,87
16
AMD Ryzen 5 3600, Python
153
4. Заключение
1. Общей чертой как индекстрона, так и глубокого обучения является ав-
томатическое формирование признаков, что существенно снижает трудоем-
кость проектирования систем распознавания образов. Вместе с тем произ-
водительность индекстрона при обучении намного выше, что связано с ис-
пользуемым в нем методом обратных образов. Этот метод является анало-
гом индексных поисковиков типа Google, чем в значительной степени и опре-
деляется обеспечиваемая методом обратных образов мгновенность обучения
каждому новому объекту. Однако если поисковики работают с символьными
запросами, то индекстрон с численными данными.
2. Один из вопросов, стоящих перед машинным обучением, существуют
ли некоторые фундаментальные законы, которым должны следовать опти-
мальные системы распознавания [12]. Возможно, что ответ на этот вопрос
связан с простотой и параллелизмом обратных классификаторов, которые
могут работать как индексаторы образов. Перспективным направлением ис-
следований был бы анализ, могут ли описания биологических нейронных се-
тей быть основаны на обратных множествах. Такой анализ мог бы подсказать
эксперименты для проверки гипотетического предположения, что индекса-
ция образов, а не вычисления лежат в основе биологических распознающих
систем.
3. Время обучения и энергозатраты, требуемые для обучения систем распо-
знавания при решении крупных задач, приводят к необходимости использо-
вания облачных технологий и высокопроизводительных машинных станций.
Однако простота алгоритма индекстрона позволяет реализовать его всего на
одной программируемой логической интегральной микросхеме (ПЛИС) даже
в случае таких крупномасштабных задач, как, например, прогнозирование
времени отказов авиадвигателей. Аппаратная реализация индекстрона дела-
ет возможным его использование для различных автономных устройств, где
требуется мгновенная реакция, в том числе мгновенное обучение при возник-
новении новых ситуаций.
СПИСОК ЛИТЕРАТУРЫ
1. Mikhailov A., Karavay M. Pattern Recognition by Pattern Inversion // Proc. 2nd
Int. Conf. on Image, Video Processing and Artificial Intelligence, Shanghai, China,
2019 SPIE Digital Library, V. 11321.
3. Krizhevsky A., Nair V., Hinton G. CIFAR-10. 2009.
4. Theodoridis S., Koutroumbas K. Pattern Recognition, Academic Press (3rd edition),
2006.
5. Mikhailov A., Karavay M., Farkhadov M. Inverse Sets in Big Data Processing //
11th IEEE Int. Conf. on Application of Information and Communication Technology
(AICT2017, placeCityMoscow, 2017). M.: IEEE, V. 1.
154
Processing.
6. Brin S., Page L. The Anatomy of a Large-scale Hypotextual web Search Engine //
Computer Networks and ISDN Syst. 1998. V. 30. Iss. 1-7. Stanford, CA, 94305,
7. Sivic J., Zisserman A. Efficient Visual Search of Videos Cast as Text Retrieval //
IEEE Trans. Pattern Analysis and Machine Intelligence. 2009. V. 31. Iss. 4.
8. Gonzales R., Woods R. Digital Image Processing. Pearson Prentice Hall (3rd edi-
tion). 2008.
9. Dmitriev A., Panas A., Starkov S. Storing and Recognizing Information Based on
Stable cycles of One-dimentional Maps // Phys. Lett. 1991.
12. Jordan M., Mitchell T. Machine learning: Trends, perspectives, and prospects //
Science. 2015. V. 349. Iss. 6245.
Статья представлена к публикации членом редколлегии А.А. Галяевым.
Поступила в редакцию 05.06.2021
После доработки 22.11.2021
Принята к публикации 24.12.2021
155