Автоматика и телемеханика, № 6, 2022
© 2022 г. А.О. ИСХАКОВА, канд. техн. наук (shumskaya.ao@gmail.com),
Д.А. ВОЛЬФ, канд. техн. наук (runsolar@mail.ru),
Р.В. МЕЩЕРЯКОВ, д-р техн. наук (mrv@ieee.org)
(Институт проблем управления им. В.А. Трапезникова РАН, Москва)
СПОСОБ СНИЖЕНИЯ РАЗМЕРНОСТИ ПРОСТРАНСТВА
ПРИЗНАКОВ ПРИ РАСПОЗНАВАНИИ РЕЧЕВЫХ
ЭМОЦИЙ С ИСПОЛЬЗОВАНИЕМ СВЕРТОЧНЫХ
НЕЙРОННЫХ СЕТЕЙ1
Рассматриваются архитектуры сверточных нейронных сетей, исполь-
зуемые для оценки эмоционального состояния человека по его речи. Ре-
шается задача повышения эффективности распознавания эмоций за счет
снижения вычислительной сложности данного процесса. Для этого пред-
лагается способ преобразования входных данных в форму, подходящую
для алгоритмов машинного обучения.
Ключевые слова: распознавание речевых эмоций, речевой сигнал, звук,
идентификация эмоционального состояния, выявление агрессии, класси-
фикация речевых сигналов, социо-киберфизическая система, сверточная
нейронная сеть.
DOI: 10.31857/S0005231022060046, EDN: ACJOSQ
1. Введение
Основным средством человеческого общения является речь, которая со-
держит характеристические параметры, отражающие в том числе психоэмо-
циональное состояние говорящего. Распознавание эмоций человека играет
важную роль во взаимодействии человека с компьютером, так как оно явля-
ется дополнительным каналом информации. У людей распознавание эмоций
является естественной частью речевого общения, в то время как способность
распознавать автоматически с помощью программируемых устройств все еще
остается предметом исследований. Возможность автоматического определе-
ния эмоций по голосу и речи человека необходима для развития успешных
диалоговых систем [1], например, в процессах обучения, мониторинга пожи-
лых людей, людей с ограниченными возможностями, в системах интерактив-
ного развлечения и т.д. Задача идентификации эмоционального состояния
человека востребована в различных сферах: телекоммуникации, индустрии
развлечений, обучении, медицине и др.
1 Исследование выполнено при финансовой поддержке Российского фонда фундамен-
тальных исследований в рамках проекта № 18-29-22104.
38
Решение задачи автоматического распознавания речевых эмоций (РРЭ,
англ. SER) с помощью вычислительных систем является предметом иссле-
дований ученых на сегодняшний день [2]. Это позволит более эффективно
решать задачи определения эмоциональной составляющей мультимедиа ма-
териалов, распространяющихся в виртуальной среде. Автоматический анализ
содержимого, выявление гнева, злости, агрессии в видео- и аудиоматериалах
позволит решить задачу классификации разнородного Интернет-контента по
степени его деструктивного воздействия на пользователя [3, 4]. Разработ-
ка методов РРЭ в данном случае должна отвечать требованиям, продикто-
ванным соответствующей платформой применения — исследовать материалы
быстро и не затрачивая значимых вычислительных ресурсов. При таких усло-
виях становится реальным создание социо-киберфизической системы управ-
ления и мониторинга информации в целях противодействия проявлению де-
структивного воздействия на пользователей. Повышение скорости вычисле-
ний и снижение их сложности возможны за счет уменьшения размерности
обучающих данных.
Цель данной статьи — представление нового способа снижения размерно-
сти пространства входных признаков, использующего современные сверточ-
ные нейронные сети, в задачах распознавания речевых эмоций.
2. Создание обучающих выборок и предобработки
при разработке систем РРЭ
В качестве обучающих выборок (данных) в задачах РРЭ обычно использу-
ются признаки в виде коэффициентов LPC (Linear Predictive Coding — коди-
рование с линейным прогнозированием), LPCC (линейные прогнозирующие
кепстральные коэффициенты) и MFCC (Mel Frequency Cepstral Coefficients —
частотные кепстральные коэффициенты мел). Создается вектор признаков
для каждого высказывания путем анализа глобальной статистики (среднее,
медиана и т.д.) по всем кадрам [5]. Качество извлечения признаков напрямую
влияет на точность распознавания речевых эмоций. Наиболее распространен-
ный метод извлечения признаков включает MFCC [6]. Признаки MFCC по-
лучаются в результате применения кратковременного преобразования Фурье
(STFT) к исходному сигналу с использованием типа постобработки, кото-
рая включает кепстральный анализ. Подробное описание процесса извлече-
ния MFCC-признаков рассматривается в [7, 8]. MFCC были доминирующими
функциями, используемыми для распознавания речи сверточными нейрон-
ными сетями (СНС). Успех использования СНС был обусловлен их способ-
ностью представлять спектр амплитуд речи в компактной форме в качестве
информации для обучения и распознавания. Между тем MFCC содержат не
только информацию об эмоциональных характеристиках, но и важную ин-
формацию о говорящем. Исследования, направленные на то, какие характер-
ные признаки эмоций извлекать из речевого сигнала, имеют большое значе-
ние [9].
39
Недостатком является сложность качественной оценки признаков, что мо-
жет влиять на снижение точности распознавания. Трудно гарантировать, что
хорошие результаты могут быть достигнуты за счет использования различ-
ных баз данных, так как люди выражают эмоции по-разному, а признаки
однозначного определения эмоций отсутствуют. Успех и производительность
методов машинного обучения во многом зависят от выбора представленных
данных [10, 11].
На основе выделяемого набора информативных признаков строится клас-
сификатор, который обучается на предварительно подготовленном наборе
звуковых фрагментов. Наиболее популярными техниками классификации
являются следующие: поиск ближайших соседей, метод опорных векторов,
скрытые марковские модели, модель смеси нормальных распределений, мо-
дели на основе нечеткой логики, байесовские классификаторы максимума
вероятности [12].
Классификация эмоциональных состояний производится в соответствии
либо с задачами построения анализатора (оценки удовлетворенности, уров-
ня стресса, усталости и т.п.), либо с выбранной моделью описания (набор
базовых эмоций, непрерывная классификация и т.п.). Как правило, с ростом
числа возможных вариантов классификации точность распознавания эмоцио-
нальных состояний снижается. Поэтому количество классов, используемых
для обучения, выбирается небольшим.
3. Двумерные СНС для решения задач РРЭ
Основные виды СНС основаны на двух общих архитектурах: AlexNet и
GoogleNet [13]. Ключевая идея СНС состоит в локальной связности и рас-
пределении весов нейронов, которые объединяются в слои. Каждый нейрон в
слое получает входные данные от набора нейронов, расположенных в преды-
дущем слое. Активации, вычисленные каждым ядром, собираются в матри-
цы, которые называются картами признаков и представляют собой фактиче-
ские выходные данные сверточных слоев. Последний слой СНС — это слой
вывода фактического предсказания сети, он состоит из полностью связанных
нейронов так, что каждый из них принимает в качестве входных данных все
выходные данные предыдущих слоев. С учетом успеха проектирования архи-
тектур СНС для классификации двумерных массивов классификация рече-
вых эмоций следовала тенденции использования массивов спектральных ве-
личин, известных как речевые спектрограммы. Для решения проблемы РРЭ
типичная СНС также предназначена для анализа речевых характеристик,
которые представлены в виде многомерного массива [11].
В меньшей степени, чем AlexNet или GoogleNet, для приложений распо-
знавания обычно используют более простые виды СНС, основанные на архи-
тектурах типа LeNet-5 [14]. Выбор размера как традиционной (полносвязной)
нейронной сети, так и СНС является сложной задачей. Например, для дости-
жения приемлемой эффективности должны подстраиваться размеры весовых
40
Рис. 1. Блок-диаграмма сверточной нейронной сети, предложенной Мишелем
Валенти (Valenti-CNN).
Рис. 2. Блок-диаграмма сверточной нейронной сети, предложенной Н. Хад-
жароласвади и Х. Демирелем (3D-CNN).
матриц в слоях. В общих случаях СНС выбираются эмпирически, в зависи-
мости от характеристик обучающих данных, прошедших предварительную
обработку.
В работе Мишеля Валенти [15] была предложена сеть CNN-Valenti-CNN
(рис. 1). На вход сети подаются аудиопоследовательности в виде специаль-
но подготовленных логарифмических спектрограмм. Для этого применено
кратковременное преобразование Фурье (STFT) с перекрытием окнами Хэм-
минга, далее абсолютные значения каждого полученного бина возведены в
квадрат и применен мел-фильтр.
Еще одно интересное решение было предложено в работе Ноушини Хад-
жароласвади и Хасана Демиреля — 3D-CNN [16] (рис. 2). На вход сети там
подается 88-мерный вектор, содержащий различные аудиохарактеристики в
виде MFCC, частоты основного тона, интенсивности сигнала и т.д. Парал-
лельно на вход подается частотный спектр каждого кадра.
Яфенг Ню и др. в [17] предложили оригинальную двумерную сверточную
нейронную сеть (рис. 3), основанную на принципе визуализации сетчатки
глаза и выпуклой линзы. На вход сети подаются спектрограммы разных раз-
меров с эффектом, полученным при изменении фокусного расстояния. Таким
образом достигалось увеличение числа тренировочных данных (аугментация)
41
Рис. 3. Блок-диаграмма сверточной нейронной сети, основанной на принципе
визуализации сетчатки глаза и выпуклой линзы.
путем изменения расстояния между спектрограммой и выпуклой линзой. Для
этого были выбраны изображения в различных точках фокусирования, при-
надлежащие интервалам L1(F<L1<2F), L2(L2=2F) и L3(L3>2F).
В настоящее время СНС применяется к РРЭ многими исследователями, и
в этом направлении уже достигнуты значительные результаты. Например:
1. Для сети, предложенной Яфенгом Ню и др., эксперименты проводились
для речевых баз EmoDB [18] и SAVEE [19, 20]. Достигнута точность
около 99% из семи видов эмоций.
2. Ч. Хуан и др. [21] обучили модель СНС, которая является стабиль-
ной и надежной в сложных сценах и превосходит некоторые хорошо
зарекомендовавшие себя способы для решения задач РРЭ. Достигнуты
результаты: точность 78% по базе SAVEE, 84% по базе Emo-DB.
3. С. Прасомфан [22] обнаружил эмоции, используя информацию внутри
спектрограмм. Затем с помощью нейронной сети осуществил классифи-
кацию эмоции, используя базу EmoDB, и получил точность до 83,28%
по пяти эмоциям.
4. Н. Семвал [23] предложила способ автоматического определения рече-
вых эмоций с использованием многодоменных акустических моделей
выбора и классификации. Этот подход был протестирован c базами
EmoDB и BML (RED). Для мультиклассовой классификации достига-
ется точность 80% для EmoDB и 73% для RED.
Однако для обучения глубокой нейронной сети требуется значительный
объем данных, в то время как данные, предоставляемые существующими ба-
зами общих речевых эмоций, очень ограничены.
4. Одномерные СНС для решения задач РРЭ
Двумерные СНС были исследованы переходом к одномерным архитекту-
рам, которые позволяют существенно снизить размерность обучающих при-
42
Рис. 4. Нейронная сеть (Reza 1-D CNN) для распознавания эмоций в речи,
предложенная Реза Чу.
Рис. 5. Нейронная сеть (Vandana-Raian 1-D CNN-RNN) для распознавания
эмоций в речи, предложенная В. Раджан.
знаков. Широкая популярность применения одномерных сверточных нейрон-
ных сетей для решения задач РРЭ возникла относительно недавно — начиная
с 2019 г.
Так, Реза Чу в [24] предложил одномерную нейронную сеть — Reza 1-D
CNN. Указанная нейронная сеть — это наиболее подходящая модель СНС
для представления аудио-кортексиального органа слуховой системы человека
в формальном описании (рис. 4, табл. 2 в справочной информации).
В это же время Ц. Чжао [25] предлагает СНС (реализация Vandana-
Raian 1-D CNN-RNN [26]) с дополнительными рекуррентными слоями LSTM
(рис. 5, табл. 3 в справочной информации). В отличие от модели Reza 1-D
CNN в сети отсутствует регуляризация (dropout). Число сверточных ядер
увеличивается в направлении выходного слоя с целью моделирования после-
довательностей. Полносвязный слой (Dense) получает выход из ячейки LSTM
и рассчитывает логиты для каждого элемента выходной последовательности.
Указанная нейронная сеть представляет собой гибридную архитектуру.
43
Можно заметить, что структура СНС для решения задач РРЭ имеет ти-
пичную архитектуру. Основное отличие заключается либо в расширении чис-
ла сверхточных ядер к полносвязному слою, либо к их уменьшению, а также
отсутствием или наличием LSTM каскадов. В данной статье не рассматрива-
ются параллельные архитектуры, так как такие сети нацелены на повышение
точности классификации и используют иные акустические признаки допол-
нительно к MFFC. В настоящем исследовании допускается, что особенностей
MFFC достаточно для того, чтобы решать задачу РРЭ.
5. Результаты экспериментальных расчетов
Для достижения поставленной цели была проведена собственная реализа-
ция рассмотренных выше архитектур нейронных сетей и проведено их обу-
чение с наиболее популярными базами данных.
В первом эксперименте были обучены двумерные СНС для того, чтобы
получить собственные оценки классификации. Во втором эксперименте был
осуществлен переход к одномерным архитектурам. В третьем эксперимен-
те проведены снижение размерности пространства обучающих признаков и
сопоставление полученных результатов с предыдущим экспериментом.
Для тестирования двумерных СНС были выбраны следующие базы дан-
ных эмоций: Surrey Audio-Visual Expressed Emotion (SAVEE), Ryerson Audio-
Visual Database of Emotional Speech and Song (RAVDESS) [27], Toronto
emotional speech set (TESS) [28], Crowd-sourced Emotional Multimodal Actors
Dataset (CREMA-D) [29] и Emo-DB.
Для каждого акустического образца из базы были извлечены мел-
кепстральные коэффициенты со следующими параметрами: длительность
аудио 1-4 с, частота дискретизации 44 100 Гц, 64 MFCC коэффициента.
Архитектура нейронной сети, предлагаемая Яфенг Ню и др., была заме-
нена на архитектуру сети LeNet-5 [30]. В эксперимент была добавлена одно-
Таблица 1. Результаты тестирования сверточных нейронных сетей
Accuracy
Сверточная нейронная сеть
(оценки абсолютной
точности для MFCC) LeNet-5 Valenti-cnn
3D-CNN
1D-cochlea-cnn
Входной слой
64 x 774
64 x 774
64 x 774
64
Обуч. параметров
5,942,666
60,614,922
1,642,954
160,202
CREMAD
0,39
0,44
0,43
0,41
SAVEE
0,48
0,5
0,5
0,6
RAVDESS
0,43
0,39
0,54
0,42
TESS
0,99
0,99
0,99
0,99
EMO-DB
0,34
0,13
0,31
0,64
UNITED
0,67
0,71
0,74
0,68
44
мерная СНС (1D-cochlea-cnn), рассматриваемая в [31]. После обучения ней-
ронных сетей были получены результаты, которые представлены в табл. 1.
Числовые значения в таблице показывают абсолютную точность классифика-
ции каждой из СНС для соответствующей базы. Решения для баз CREMAD,
SAVEE, RAVDESS, TESS и Emo-DB являются частными случаями, а муль-
тилингвальное решение United — общим (объединенная база).
Результаты экспериментов с применением одномерных сверточных ней-
ронных сетей показывают, что одномерные СНС для задач РРЭ не уступают
двумерным аналогам. В [31] представлены эксперименты с одномерной свер-
точной сетью для задачи распознавания эмоционального состояния агрессии,
где достигается точность в 75%.
В эксперименте каждый признак - это массив, состоящий из 49 536-131 072
элементов. В общем случае на вход двумерных СНС подаются матрицы раз-
мерностями 32, . . . , 64 на 774, . . . , 2048, . . . , N. Для снижения размерности
пространства признаков была принята гипотеза о том, что признак, задаю-
щий эмоцию в речи, сохраняется в случае усреднения мел-кепстральных ко-
эффициентов по частотной шкале [31].
Для следующего эксперимента были выбраны две базы CREAMD и
IEMOCAP, которые были объединены в единую базу. Из нее были отобраны
восемь эмоций в следующих пропорциях по гендерному типу: male_happy
(радость) — 671, male_angry (злость) — 671, male_sad (печаль) — 671,
female_angry — 600, female_happy — 600, female_sad — 600, male_neutral —
575, female_neutral — 512.
После приведения двумерных признаков MFCC (2D-MFCC) к среднему
вектору получены одномерные MFCC признаки (1D-MFCC). Длина каждого
обучающего признака представляла собой массив размерностью 2048 элемен-
тов.
Данные для обучения выбранных одномерных сетей получились следую-
щими:
— размер тренировочных признаков для обучения — 7042;
— набор тестовых признаков — 2347 (кросс-валидация);
— объем тренировочных признаков для каждой эпохи — 50.
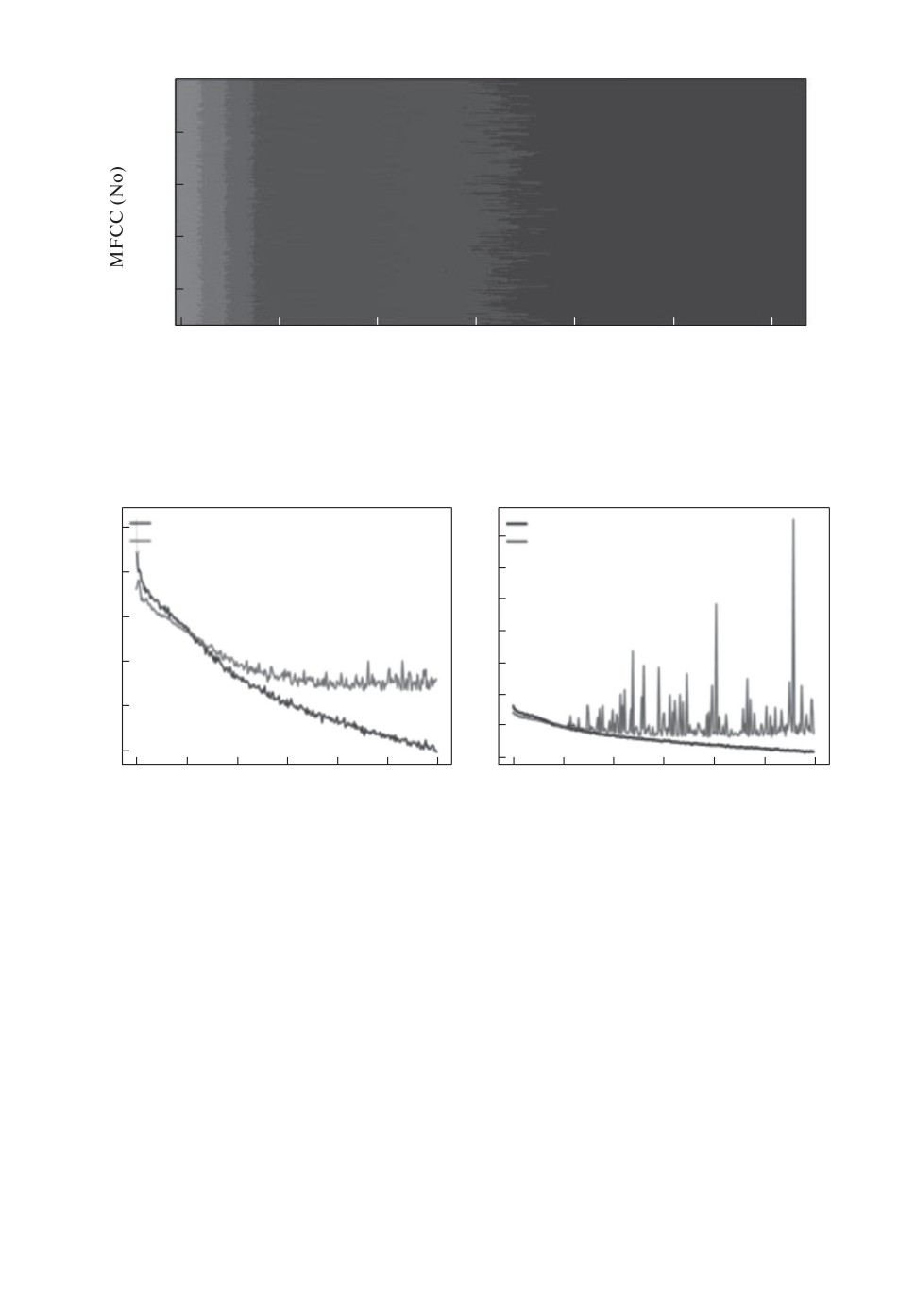
На рис. 6 показаны одномерные MFCC-признаки для последующего ма-
шинного обучения. Полученные признаки не масштабированы по временной
шкале.
После трехсот эпох обучения точность данных проверки для сети Reza-1-
D-CNN варьируется в пределах 26%, а для сети Vandana-Raian-CNN-RNN —
в пределах 24%. На графиках ошибки (рис. 7) заметно, что модель не спо-
собна хорошо сходиться даже с восемью целевыми классами. Однако для
речевой базы RAVDESS Р. Чу декларирует, что для сети Reza-1-D-CNN до-
стигает более 70% точности. Осуществляется это за счет упрощения модели
в виде разбиения MFCC-признаков только на мужские или женские эмоции.
Для сети Vandana-Raian-CNN-RNN и базы Emo-DB достигается результат
45
8000
6000
4000
2000
0
250
500
750
1000
1250
1500
1750
2000
Length of frame
Рис. 6. Одномерные MFCC признаки на основе баз данных эмоций CREMAD
и IMPOCAP.
Vandana-Raian 1-D CNN-RNN
Reza 1-D CNN
2,2
train
train
test
test
2,0
2,05
1,8
2,00
1,6
1,4
1,95
1,2
1,90
1,0
0,8
1,85
0,6
0
50
100
150
200
250
300
0
50
100
150
200
250
300
epoch
epoch
Рис. 7. Графики ошибки в процессе обучения моделей Reza-1-D-CNN и
Vandana-Rajan-1-D-CNN-RNN с 1-D MFCC на основе баз данных эмоций
CREMAD и IMPOCAP.
в 61%. Тем не менее для объединенных баз оценки классификации остав-
ляют желать лучшего. Полученные результаты демонстрируют низкую эф-
фективность классификации из-за усложнения структуры данных. Следует
отметить, что в табл. 1 оценки для базы Emo-DB также невысоки.
В следующем эксперименте одномерные признаки MFCC были рассмот-
рены как временной ряд. Далее было применено преобразование Фурье к
каждому из признаков. После преобразования были получены масштабиро-
ванные признаки, представляющие собой массив из 64 элементов (рис. 8).
После повторного обучения точность данных проверки для сети Reza-1-
D-CNN достигла 28%, а для сети Vandana-Raian-CNN-RNN — 27%. Графики
46
8000
6000
4000
2000
0
10
20
30
40
50
60
Length of frame
Рис. 8. 1-D-MFCC-FT признаки на основе баз данных эмоций CREMAD и
IMPOCAP.
Reza 1-D CNN
Vandana-Raian 1-D CNN-RNN
train
train
2,15
test
3,2
test
2,10
3,0
2,8
2,05
2,6
2,00
2,4
2,2
1,95
2,0
1,90
1,8
0
50
100
150
200
250
300
0
50
100
150
200
250
300
epoch
epoch
Рис. 9. Графики ошибки в процессе обучения моделей Reza 1-D CNN и
Vandana-Rajan-1-D-CNN-RNN с 1-D MFCC-FT признаками, на основе баз дан-
ных эмоций CREMAD и IMPOCAP.
ошибок для сетей Reza-1-D-CNN и Vandana-Rajan-1-D-CNN-RNN с новыми
признаками (1-D-MFCC-FT) показаны на рис. 9.
Из графиков видно, что оценки классификации согласуются с оценками
предыдущего эксперимента. По сравнению со вторым экспериментом полу-
ченный способ позволяет снизить размерность обучающего признака в 32 ра-
за.
Несмотря на то что расчет спектрограмм не полностью соответствует кон-
цепции сквозной сети, поскольку он допускает дополнительный этап пред-
варительной обработки (преобразование 1D-MFCC в спектрограмму) перед
моделью СНС, обработка минимальна, и наиболее важно, что сохраняется це-
лостность сигнала. Предлагаемый подход к выделению признаков позволяет
47
значительно сократить длину обучающих признаков, обеспечивая простую
трансформацию данных в новое пространство признаков. С практической
точки зрения данный подход можно использовать для улучшения характери-
стик пространственного хранения или для вычислительной продуктивности
алгоритмов обучения. Данный способ снижения размерности предлагается
использовать в задачах РРЭ.
6. Заключение
Предложен подход приведения речевых данных, содержащих эмоциональ-
ную составляющую в речи, в форму, подходящую для алгоритмов машинного
обучения. Очевидно, что качество и объем акустических признаков определя-
ют, насколько хорошо алгоритмы машинного обучения способны обучаться.
Следовательно, критически важно провести исследование и предваритель-
ную обработку признаков, прежде чем передавать их значения алгоритму
обучения. Результаты эксперимента показывают, что небольшие сети, или се-
ти, имеющие относительно малое число параметров, обладают недостаточной
емкостью, а потому присутствует эффект недообученности, демонстрирует-
ся низкая эффективность, поскольку они не могут выявлять внутреннюю
структуру сложных данных.
Предложенный авторами статьи подход для предобработки данных и вы-
деления признаков способствует улучшению характеристик пространственно-
го хранения и вычислительной продуктивности алгоритмов обучения. Полу-
ченные результаты важны для исследований, связанных с обработкой и ана-
лизом речевых сигналов, выделением определенных эмоциональных свойств
говорящих [32]. Применение предложенного в статье метода в задачах ана-
лиза электронной информации позволит повысить эффективность работы за
счет снижения вычислительной нагрузки, уменьшения пространства призна-
ков и, соответственно, повышения скорости расчетов.
Справочная информация
1) Сокращения для конфигураций нейронных сетей:
Layer — слой;
LT — layer type (тип слоя);
SF — same filters (фильтры одного рода);
KS — kernel size (размер ядра свертки);
Strides — шаг свертки;
Activation — функция активации;
BN — batch Normalization (нормализация);
Dropout — регуляризация;
MP (P) — Max pooling (слой понижения размерности);
LSTM — Long short-term memory (слой с рекуррентной нейронной сетью);
AA — attention activation (слой активации рекуррентного слоя);
48
Flatten — полносвязный слой;
Dense — выходной полносвязный слой.
2) Конфигурации нейронных сетей (табл. 2, 3)
Таблица 2. Конфигурация одномерной нейронной сети — Reza-1-D-CNN
Layer
LT
SF KS Strides Padding BN Activation Dropout
1
CNN (SF)
256
8
1
same
ReLu
2
CNN (SF)
256
8
1
same
+ ReLu
0,25
3
MP (P)
8
1
4
CNN (SF)
128
8
1
same
ReLu
5
CNN (SF)
128
8
1
same
ReLu
6
CNN (SF)
128
8
1
same
ReLu
7
CNN (SF)
128
8
1
same
+ ReLu
0,25
8
MP (P)
8
1
9
CNN (SF)
64
8
1
same
ReLu
10
CNN (SF)
64
8
1
same
ReLu
11
flatten
12
Dense
Softmax
Таблица 3. Конфигурация одномерной нейронной сети — Vandana-Raian
1-D CNN-RNN
Layer
LT
SF KS Strides Padding BN Activation Dropout
1
CNN (SF)
64
3
1
same
+
elu
2
MP (P)
4
4
3
CNN (SF)
64
3
1
same
+
elu
4
MP (P)
4
4
5
CNN (SF)
128
3
1
same
+
elu
6
MP (P)
4
4
7
CNN (SF)
128
3
1
same
+
elu
8
MP (P)
4
4
9
LSTM
64
10
AA
tanh
11
LSTM
64
12
Dense
Softmax
СПИСОК ЛИТЕРАТУРЫ
1. Мещеряков Р.В., Бондаренко В.П. Диалог как основа построения речевых си-
стем // Кибернетика и системный анализ. 2008. № 2. С. 30-41.
49
2.
Papakotas M., Siantikos G., Giannakopoulos T. et al. IoT Applications with 5G
Connectivity in Medical Tourism Sector Management: Third-Party Service Scenar-
ios // GeNeDis 2016. Advances in Experimental Medicine and Biology. 2016. V. 989.
3.
Okhapkin V., Okhapkina E., Iskhakova A. et al. Application of neural network mod-
eling in the task of destructive content detecting // CEUR workshop proceedings.
Proceedings of the 3rd International Conference on R. Piotrowski’s Readings in Lan-
guage Engineering and Applied Linguistics, PRLEAL 2019. St. Petersburg, Russia,
2020. P. 85-94.
4.
Iskhakova A., Iskhakov A., Meshcheryakov R. Research of the estimated emotional
components for the content analysis // Journal of Physics: Conference Series. 2019.
5.
Scheirer E., Slaney M. Construction and evaluation of a robust multifeature
speech/music discriminator // IEEE International Conference on Acoustics, Speech,
and Signal Processing. Munich, Germany, 2002. P. 1331-1334.
6.
Hossan M.A., Memon S., Gregory M.A. A novel approach for MFCC feature extrac-
tion // 2010 4th International Conference on Signal Processing and Communication
Systems. Gold Coast, QLD, Australia, 2010. P. 1-5.
7.
Logan B. Mel Frequency Cepstral Coefficients for Music Modeling.
https: //ismir2000.ismir.net/papers/logan_abs.pdf
8.
Rabiner L.R., Juang B.H. Fundamental of Speech Recognition. USA: Prentice Hall,
1993.
9.
Nwe T.L., Foo S.W., Silva L.C. Speech emotion recognition using hidden Markov
models // Speech Communication. 2003. V. 41. No. 4. P. 603-623.
10.
Zou D., Niu Y., He Z., Tan H. A breakthrough in speech emotion recognition using
deep retinal convolution neural networks. https: //arxiv.org/abs/1707.09917
11.
Lim W., Jang D., Lee T. Speech Emotion Recognition using Convolutional and
Recurrent Neural Networks // 2016 Asia-Pacific Signal and Information Processing
Association Annual Summit and Conference (APSIPA). Jeju, Korea (South), 2016.
12.
Prasomphan S. Improvement of speech emotion recognition with neural network
classifier by using speech spectrogram // 2015 International Conference on Systems,
Signals and Image Processing (IWSSIP). London, UK, 2015. P. 73-76.
13.
Pakoci E., Popovic B., Pekar D. Improvements in Serbian Speech Recognition using
Sequence-Trained Deep Neural Networks // SPIIRAS Proceedings. 2018. Vol. 3(58).
14.
Bengio Y., Hinton G. Deep learning // Nature. 2015. V. 521. P. 436-444.
15.
Valenti M., Squartini S., Diment A. et al. A convolutional neural network approach
for acoustic scene classification // 2017 International Joint Conference on Neural
Networks (IJCNN). Anchorage, AK, 2017. P. 1547-1554.
50
16.
Hajarolasvadi N., Demirel H. 3D CNN-Based Speech Emotion Recognition Using
K-Means Clustering and Spectrograms // Entropy. 2019. V. 21(5) 479. P. 1-17.
17.
Niu Y., Zou D., Niu Y., He Z., Tan H. A breakthrough in speech emotion recognition
using deep retinal convolution neural networks. Preprint.
18.
Burkhardt F., Paeschke A., Rolfes M., Sendlmeier W.F., Weiss B. A Database of
German Emotional Speech // INTERSPEECH 2005 — Eurospeech, 9th European
Conference on Speech Communication and Technology. Lisabon, Portugal, 2005.
19.
Haq S., Jackson P.J.B., Edge J.D. Audio-Visual Feature Selection and Reduction for
Emotion // Proceedings of the International Conference on Auditory-Visual Speech
Processing 2008, Tangalooma Wild Dolphin Resort, Moreton Island, Queensland,
Australia, 2008. P. 185-190.
20.
Haq S., Jackson P.J.B. Speaker-Dependent Audio-Visual Emotion Recognition //
Proceedings of the International Conference on Auditory-Visual Speech Processing,
Norwich, UK, 2009. P. 53-58.
21.
Huang Z., Dong M., Mao Q., Zhan Y. Speech Emotion Recognition Using CNN //
MM ’14: Proceedings of the 22nd ACM international conference on Multimedia.
22.
Prasomphan S. Improvement of speech emotion recognition with neural network
classifier by using speech spectrogram // 2015 IEEE International Conference on
Systems, Signals and Image Processing. London, UK, 2015. P. 73-76.
23.
Semwal N., Kumar A., Narayanan S. Automatic speech emotion detection system
using multi-domain acoustic feature selection and classification models // 2017 IEEE
International Conference on Identity, Security and Behavior Analysis (ISBA). New
Delhi, India, 2017. P. 1-6.
24.
Chu R. Speech Emotion Recognition with Convolutional Neural Network. 2019.
neural-network-1e6bb7130ce3
25.
Jianfeng Z., Mao X., Chen L. Speech emotion recognition using deep 1D & 2D
CNN LSTM networks // Biomedical Signal Processing and Control. 2019. V. 47.
26.
Rajan V. 1D Speech Emotion Recognition. 2021.
https: //github.com/vandana-rajan/1D-Speech-Emotion-Recognition
27.
Livingstone S.R., Russo F.A. The Ryerson Audio-Visual Database of Emotional
Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal
expressions in North American English // PLoS ONE. 2018. V. 13(5). P. 1-35.
28.
Dupuis K., Pichora-Fuller M.K. Toronto emotional speech set (TESS).
doi:10.5683/SP2/E8H2MF
29.
Cao H., Cooper D.G., Keutmann M.K. et al. CREMA-D: Crowd-sourced emotional
multimodal actors dataset // IEEE transactions on affective computing.
2014.
51
30. Franti E., Ispas I., Dragomir V. et al. Voice Based Emotion Recognition with
Convolutional Neural Networks for Companion Robots // Romanian Journal of
Information Science and Technology. 2018. V. 20(3). P. 222-240.
31. Iskhakova A., Wolf D., Meshcheryakov R. Automated Destructive Behavior State
Detection on the 1D CNN-Based Voice Analysis // Speech and Computer. SPECOM
2020. Lecture Notes in Computer Science. 2020. V. 12335. P. 184-193.
32. Исхакова А.О., Вольф Д.А., Исхаков А.Ю. Неинвазивный нейрокомпьютерный
интерфейс для управления роботом // Высокопроизводительные вычислитель-
ные системы и технологии. 2021. Том 5. № 1. C. 166-171.
Статья представлена к публикации членом редколлегии О.П. Кузнецовым.
Поступила в редакцию 17.11.2021
После доработки 19.01.2022
Принята к публикации 26.01.2022
52