Автоматика и телемеханика, № 6, 2022
© 2022 г. А.И. ПАНОВ, канд. физ.-мат. наук (panov.ai@mipt.ru)
(Федеральный исследовательский центр
“Информатика и управление” РАН, Москва;
Московский физико-технический институт
(национальный исследовательский университет))
ОДНОВРЕМЕННОЕ ПЛАНИРОВАНИЕ И ОБУЧЕНИЕ
В ИЕРАРХИЧЕСКОЙ СИСТЕМЕ УПРАВЛЕНИЯ
КОГНИТИВНЫМ АГЕНТОМ1
Задачи планирования поведения и обучения принятию решений в ди-
намической среде в системах управления интеллектуальными агентами
обычно разделяют и рассматривают отдельно. Предложена новая объеди-
ненная иерархическая постановка задачи одновременно планирования и
обучения (SLAP) в контексте предметного обучения с подкреплением и
описана архитектура когнитивного агента, решающего данную задачу.
Предложен новый алгоритм обучения действиям в частично наблюдаемой
внешней среде с использованием подкрепляющего сигнала, предметного
описания состояний внешней среды и динамически обновляемых планов
действий. Рассмотрены основные свойства и преимущества предложенно-
го алгоритма, среди которых — отсутствие фиксированного когнитивного
цикла, вследствие которого ранее приходилось использовать разделение
подсистем планирования и обучения, возможность строить и обновлять
модель взаимодействия со средой, что повышает эффективность обуче-
ния. Предложено теоретическое обоснование некоторых положений дан-
ного подхода, предложен модельный пример и продемонстрирован прин-
цип работы SLAP агента при управлении беспилотным автомобилем.
Ключевые слова: обучение с подкреплением, планирование поведения, ко-
гнитивный агент, иерархическое планирование, системы управления, бес-
пилотный транспорт, мобильные роботы.
DOI: 10.31857/S0005231022060058, EDN: ACLEUU
1. Введение
Современные системы управления беспилотным транспортом и мобильны-
ми робототехническими платформами реализуют модульный подход к гене-
рации автономного поведения [1]. Различные подсистемы отвечают за выпол-
нение определенного рода подзадач: генерация траектории движения, реали-
зация предложенной траектории с учетом динамики объекта управления,
детекция и сегментирование объектов во внешней среде, планирование дей-
ствий по манипуляции объектами, обучение модели взаимодействия со средой
1 Работа выполнена при финансовой поддержке Российского фонда фундаментальных
исследований (проект № 18-29-22027).
53
и т.д. При усложнении задач, которые ставятся перед объектом управления,
увеличивается количество необходимых подсистем и усложняется их внут-
ренняя организация, усложняется межмодульное взаимодействие.
Однако в последнее время в области разработки общих систем искусствен-
ного интеллекта наметилась обратная тенденция по объединению функцио-
нальности различных модулей в связи с тем, что для повышения эффек-
тивности и адаптивности решения перечисленных выше подзадач требуется
комплексирование результатов или во многих случаях одновременная взаимо-
связанная работа разных подсистем [2]. Примерами подобных ситуаций мо-
гут служить варианты интеграции подсистем компьютерного зрения в зада-
че управления беспилотным автомобилем, двигающимся в среде с большим
количеством других автомобилей и пешеходов, когда для повышения эффек-
тивности предсказания траекторий других участников движения необходи-
мо интегрировать в этот модуль работу подсистем сегментации и трекинга
объектов [3].
Большое внимание в настоящее время уделяется применению методов
машинного обучения в подсистемах, отвечающих как за непосредственное
управление движением робототехнической платформы [4], так и за высо-
коуровневое планирование перемещения и поведения [5]. В данном случае
основной задачей является уменьшение роли заранее заданных эвристик и
вручную сформированных правил поведения на основе априорных знаний о
задаче с целью повышения адаптивности методов и робастности получаемых
решений при изменении условий внешней среды.
В настоящей статье предлагается новый подход по интеграции подсистем
планирования поведения (т.е. действий как по перемещению, так и, напри-
мер, манипуляции предметами внешней среды) и обучения поведению, в кото-
ром формируется адаптивная стратегия по достижению поставленной перед
агентом цели [6]. Такая интеграция является естественной, так как обе под-
системы представляют собой различную реализацию модуля последователь-
ного принятия решений [7]. Однако при планировании необходима модель
функционирования внешней среды, а модуль обучения может автоматически
формировать такую модель в явном или неявном виде. Для эффективного
учета возможностей обеих подсистем предлагается использовать иерархиче-
скую организацию как для всей системы управления, так и для разделения
высокоуровневого планировщика, для которого уже не требуется полной и
точной модели, и низкоуровневой стратегии, которая обучается на основе
оригинального метода обучения с подкреплением.
В данном исследовании предложена новая версия иерархической гибрид-
ной архитектуры STRL управления сложными техническими объектами [8] с
целью выделения подсистем, обучающихся в процессе взаимодействия со сре-
дой. На стратегическом уровне управления впервые выделены три подсисте-
мы — предметного представления модели среды, планирования поведения и
обучения достижению подцелей. Основным вкладом данной статьи является
новый подход к задаче интеграции подсистем планирования и обучения ко-
54
гнитивного агента, под которым подразумевается мобильная робототехниче-
ская платформа или беспилотное транспортное средство. Предлагается ори-
гинальная иерархическая постановка задачи одновременного планирования и
обучения (simultaneous planning and learning, SLAP). Во второй части статьи
данный подход представлен в виде архитектуры SLAP агента, решающего по-
ставленную задачу на основе иерархического подхода, в котором предлагает-
ся использовать планирование поведения по дереву Монте-Карло на верхнем
уровне и предметное обучение с подкреплением для частично наблюдаемой
среды на нижнем уровне иерархии действий. Представлены теоретическое
обоснование для механизма обучения актора и критика в данной постанов-
ке. Кроме иллюстративного примера на клеточной среде, предложена схема
реализации SLAP агента для задачи управления маневрами беспилотного ав-
томобиля.
2. Архитектура управления поведением STRL2
В условиях динамической среды, свойства и поведение которой заранее не
известны когнитивному агенту, в качестве которого будет пониматься мо-
бильная робототехническая платформа, предлагается использовать обнов-
ленную версию архитектуры STRL, в которой сделан акцент на возможность
обучения как в процессе выполнения действий в среде, так и на предобу-
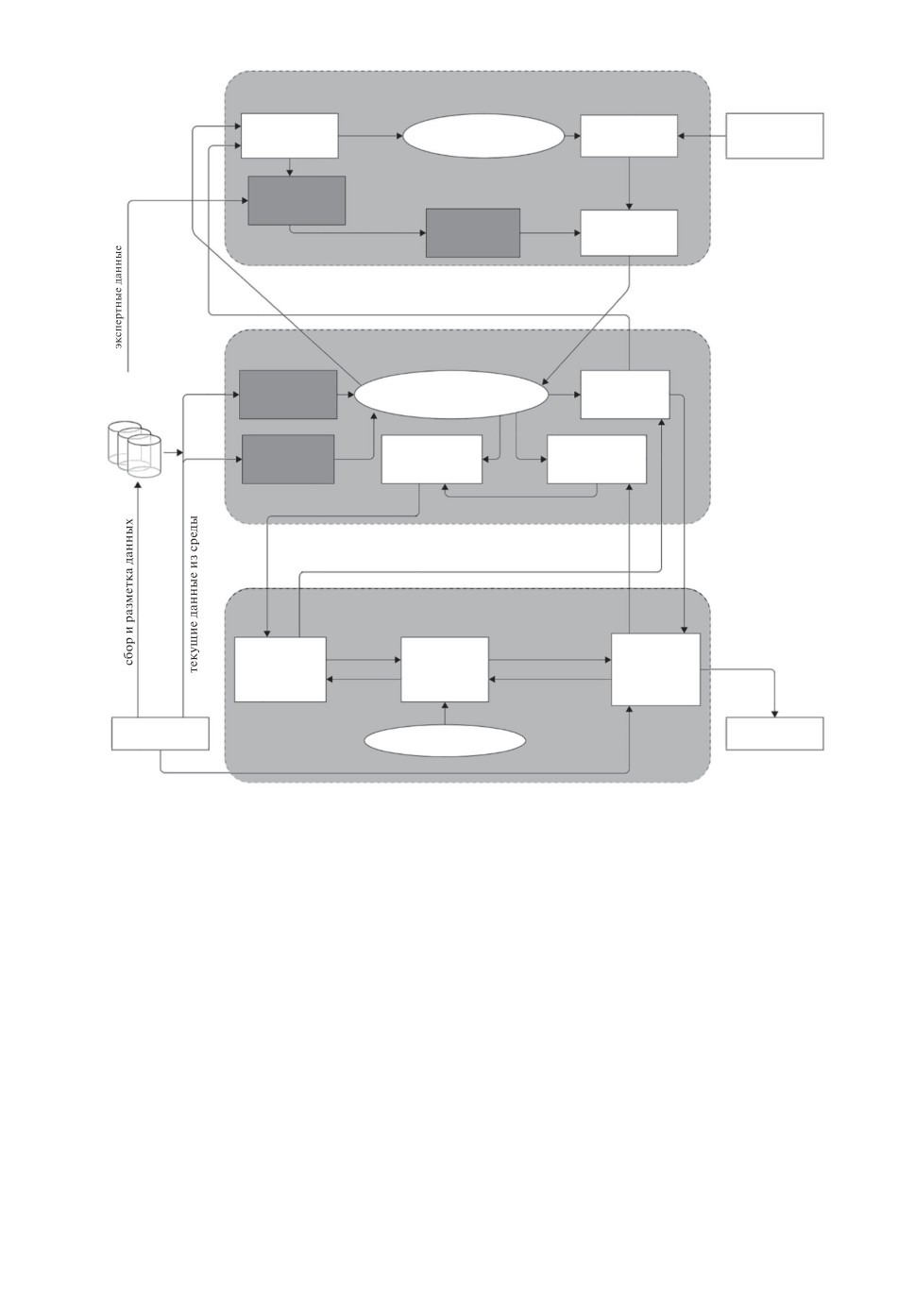
чение на заранее собранных наборах данных. На рис. 1 представлены схема
основных подсистем архитектуры и базовые процедуры управления и переда-
чи информации между модулями. Кратко рассмотрим основные особенности
этой архитектуры.
Архитектура STRL2 является иерархической и состоит из трех базовых
уровней. На среднем тактическом уровне, также как и в оригинальной вер-
сии, решаются задачи классического управления с использованием конкрет-
ной модели динамики объекта управления: задачи стабилизации, следова-
ния по траектории и т.п. Реактивный уровень осуществляет интегрирование
уравнений модели динамики с учетом геометрических ограничений, которые
накладываются при планировании траектории на верхнем уровне [9]. Резуль-
татом является выработка управляющего сигнала на органы управления.
На тактическом уровне в STRL2 предлагается уделить больше внимания
задачам компьютерного зрения, а не только построению и прогнозированию
траектории движения во внешней среде. На рис. 1 заполненными блоками
отмечены подсистемы, требующие либо интерактивного обучения или пред-
варительного обучения на заранее подготовленных наборах данных или в
симуляторах. На тактическом уровне такими обучающимися подсистемами
являются подсистемы нейросетевого картирования и локализации (SLAM),
сегментации и трекинга объектов во внешней среде по RGB-D изображе-
нию или по данным с лазерных дальномеров (лидаров). Данные подсистемы
формируют так называемую сенсорную ситуацию, по которой уже возмож-
но построение специфических представлений (графов регулярной структу-
55
Стратегический уровень
Текущая
Общая
Динамическая
Планирование
предметная
предметная модель
поведения
задача
обновление
объекты и
ситуация s
t
R, G
модели
признаки
последовательность
Иерархический
действий
критик Q j, gij
Обновляемый
Иерархический
иерархический
оценка
актор j
план {a
t}
ситуации
целевая область
траектория
и временные
построена
ограничения
либо нет
Тактический уровень
Наборы данных
Картирование и
Сенсорная
Планирование
для обучения
ситуация
локализация
движения
D
k
Сегментация и
Мониторинг
Прогнозирование
отслеживание
выполнения
траекторий
объектов
плана
параметры
движения
запрос на
перепланирование
превышен ли
геометрические
желаемая
ограничения
порог ошибки
траектория
Реактивный уровень
фазовые
параметры
координаты и
движения
Выработка
управляющий
Интегрирование
параметры движения
Расчет
управляющего
сигнал
геометрических
уравнений
сигнала и
ограничений
модели
анализ
фазовые
динамики
управляющий
динамики
координаты
сигнал
Сенсоры и
Органы
датчики
Модель динамики
управления
фазовые
координаты
Рис. 1. Основные компоненты и межмодульное взаимодействие в архитектуре
STRL2.
ры), необходимых для построения пути и мониторинга движения по траек-
тории [10].
На стратегическом уровне STRL2 информация о текущей сенсорной си-
туации используется для обновления долговременной предметной модели, по
которой агент строит высокоуровневый план поведения. На этом уровне обу-
чающимися подсистемами являются подсистема формирования оценки те-
кущей ситуации относительно итоговой цели, поставленной перед агентом
(модуль критика), и подсистемами актора, который автоматически форми-
рует стратегию по достижению подцелей, выставленных планировщиком по
модели. Зачастую критик и актор требуют предобучения в симуляционных
средах с использованием заранее заданного сигнала вознаграждения, преж-
де чем они могут быть использованы для генерации поведения в реальной
среде.
56
В предложенной архитектуре STRL2 делается акцент на формирование
адаптивного поведения когнитивного агента в заранее неизвестной динами-
ческой среде без необходимости координировать свои действия с другими
участниками общей деятельности, в то время как в первой версии архитек-
туры большее внимание уделялось именно многоагентной составляющей и
распределению ролей в коалиции [11].
В подразделе 2.1 будет дана полная постановка задачи работы агента на
стратегическом уровне, на котором предлагается объединить в единый цикл
работу подсистем планирования и обучения.
Опишем формальную постановку задачи одновременного планирования
и обучения с использованием предметно-ориентированной концепции иерар-
хического обучения с подкреплением. Вначале напомним понятие частично
наблюдаемого марковского процесса [12], формально представляющего про-
цесс взаимодействия агента и среды, затем расширим его на иерархический
случай, введем понятие предметной ситуации и, наконец, объединим это с
формальным определением плана действий агента.
2.1. Частично наблюдаемый марковский процесс принятия решений
Итак, пусть < S, O, A, T, R, G, Ω > — частично наблюдаемый марковский
процесс принятия решений (POMDP), где:
• S = {s1,...,sn} — конечное множество состояний внешней среды, в кото-
рой действует агент,
• O = {o1,...,ok} — конечное множество наблюдений агента, включающих
в себя описание объектов (предметов), выделяемых из состояний среды
(предполагается, что наблюдение содержит лишь некоторую часть инфор-
мации о состоянии, т.е. k < n),
• A = {a1,...,am} — конечное множество действий, в том числе и составных,
• T : S × A → Π(S) — функция переходов, определяющая по текущему со-
стоянию и действию распределение вероятностей на состояниях среды в
следующий момент времени (здесь и далее будем обозначать через Π(X)
множество вероятностных распределений на конечном множестве X),
• R : S × A → R — функция вознаграждений,
• G : S → {0,1} — целевая функция, определяющая момент остановки эпи-
зода взаимодействия,
• Ω : S × A → Π(O) — функция наблюдений, определяющая распределение
вероятностей для наблюдений в текущем состоянии.
В общей постановке задачи предполагается, что все функции в опре-
делении частично наблюдаемого марковского процесса принятия решений
(POMDP) T, R, G, Ω агенту неизвестны и он может лишь оценивать их в
результате взаимодействия со средой, выполняя некоторое действие at ∈ A
и получая из среды некоторое наблюдение ot+1 ∈ O и вознаграждение
rt+1 = R(st,at). Таким образом, агенту заранее известно только множество A,
множество O он может восстановить в явном виде в процессе взаимодей-
ствия со средой, а множество S он может оценить только по наблюдениям.
57
Целью агента является построение такой функции π : O → Π(A), задающей
вероятностное распределение на множестве действий A при условии текуще-
го наблюдения o ∈ O, при котором максимизируется ожидаемое суммарное
вознаграждение (отдача):
⎡
⎤
∑
(1)
Eπ ⎣
γtR(st,at)⎦ → max,
π
t:G(st)=1
где γ - дисконтирующий множитель. Здесь предполагается, что суммирова-
ние идет до тех пор, пока целевая функция G(st) не примет значение едини-
ца. Подсчет математического ожидания по стратегии подразумевает усредне-
ние по траекториям в пространстве состояний, по которым считается отдача.
Ожидаемую отдачу можно подсчитать и для каждого состояния (функция
полезности V (s)), и для пары состояние-действие (функция Q(s, a)).
Функция π(o|s) называется стратегией агента и служит для определения
последовательности действий агента по заданной последовательности состоя-
ний среды. В постановке задачи безмодельного обучения с подкреплением в
частично наблюдаемой среде предполагается реактивное поведение агента,
при котором агент не прогнозирует реакцию среды в каждый момент време-∑
τ
ни t и генерирует новое действие Eπ
γtR(st,at) в предположении, что вся
t=0
существенная информация для принятия решения содержится в состоянии∑
τ
Eπ
γtR(st,at), которое он определяет на основе текущего наблюдения ot.
t=0
Вероятность пребывания в следующем состоянии среды bt+1(st+1) (предпо-
лагаемое состояние) определяется агентом по текущему наблюдению ot в со-
ответствии с выражением:
∑
Ω(ot+1|st+1, at)
T (st+1|st, at)bt(st)
st
(2)
bt+1(st+1|ot+1
)=
(
).
∑
∑
Ω(ot+1|st+1, at)
T (st+1|st, at)bt(st)
s
t+1
st
Используя понятие предполагаемого состояния bt, можно ввести обычный
марковский процесс принятия решений на непрерывном множестве таких со-
стояний. В этом случае функции полезности будут определяться для пред-
полагаемых состояний bt:
∑
∑
(3)
Vπ(bt) = Eπ
γt
bt(s)R(s,at
).
t
s
2.2. Иерархическая постановка и параметризация
Введем иерархию на множестве действий, следуя концепции полумарков-
ского процесса принятия решений и подхода умений [13]. Введем так называе-
мое длящееся во времени действие, или умение, κ =< Iκ, πκ, βκ >, где Iκ ⊆O -
инициирующее множество наблюдений, πκ - стратегия, реализующая данное
58
умение, βκ : O → {0, 1} - терминальная функция, останавливающая реали-
зацию умения. Множество умений будем обозначать через κ. Расширение
множества действий за счет множества умений приводит к определению по-
лумарковского процесса принятия решений и введению функций полезности
состояния Vκ(b) и умения Qκ(b, κ).
В иерархической постановке агент должен сформировать как стратегию πκ
на множестве умений (высокоуровневая стратегия) внутренние стратегии для
каждого умения πκ (низкоуровневые стратегии) и функции остановки для
каждого умения βκ. Не снижая общности постановки задачи, можно считать,
что инициирующие множества для всех умений включают все возможные на-
блюдения Iκ = O. Будем параметризовать стратегию πκ и функцию останов-
ки βκ с помощью наборов параметров θ и ϑ соответственно. В иерархической
постановке цель агента - максимизировать отдачу, начиная с предполагаемо-
го состояния b0 и умения κ0, — запишется в виде
⎡
⎤
∑
∑
⎣
(4)
Eκ,θ,κ
γt
bt(s)R(s,at)
b0,κ0⎦ → max.
θ,ϑ
s
t:G(st)=1
Определим полезность выполнения конкретного действия a в рамках
умения κ в предполагаемом состоянии b(s) (Qa-функция) и полезность
самого умения κ в b(s) (Qκ-функция). Полезность умения определяется
его внутренней стратегией и полезностью каждого действия: Qκ(b, κ) =∑
= aπκ,θ(a|o)Qa(b,κ,a),гдеполезностьдействиявсвоюочередьзаписыва-
ется через функцию переходов среды (здесь и далее через штрих будем обо-
значать следующий момент времени):
∑
Qa(b,κ,a) =
b(s|o)R(s, a) +
s
)
(5)
∑(∑
∑
+γ
Ω(o′|s′, a)
T (s′|s, a)b(s|o)
Qκ(b′(s′|o),κ).
o′
s′
s
В определении полезности действия Qa используется поправка к полез-
ности умения
Qκ, которая учитывает возможность остановки умения при
следующем наблюдении o′:
(
)
(6)
Qκ(b′,κ) =
1 - βκ,ϑ(o′)
Qκ(b′,κ) + βκ,ϑ(o′)Vκ(b′
).
2.3. Предметная ситуация
Наблюдение, получаемое агентом, практически во всех значимых окру-
жениях представляет собой некоторую сцену, состоящую из объектов или
предметов. Декомпозиция предметной сцены на отдельные взаимосвязанные
составляющие может оказаться полезной в том случае, когда такие взаимо-
связи отделимы от самих предметов, а действия агента могут быть отнесены
59
не ко всей сцене, а к концертному целевому предмету. Формально такая де-
композиция для марковского процесса принятия решений описывается в так
называемой объектно-ориентированной поставке [14, 15]. В постановке зада-
чи одновременного обучения и планирования будет рассматриваться случай,
когда взаимосвязи объектов несущественны для принятия решений агентом
и принципиально только наличие тех или иных предметов в сцене.
Итак, пусть и состояние среды s, и наблюдение агента o представля-
ют собой некоторое множество независимых объектов, которые относятся
к конечному числу классов C = {c1, c2, . . . , ck}. Каждый класс характери-
зуется своим набором атрибутов или признаков {fc1, fc2, . . . , fcnc }, а объект
e ∈ E класса c(e) ∈ C описывается конкретными значениями данных призна-
ков e = {dc1, dc1, . . . , dcnc }. Как состояние s, так и наблюдение агента o, таким
⋃
образом, представляет собой объединение состояний объектов
ei. Будем
i=1
считать, что частичная наблюдаемость выражается в том, что состояние s
и наблюдение o отличаются друг от друга набором объектов и (или) значе-
ниями характеризующих их признаков. Выделение объектов по наблюдению
происходит с помощью некоторой функции Φp : O → 2E , которая будет счи-
таться заранее заданной.
В предположении независимого присутствия предметов в среде в текущем
наблюдении возможна декомпозиция функции переходов и функции возна-
граждений по отдельным классам объектов: T = {Tci |ci ∈ C}, R = {Rci |ci ∈
∈ C}. Низкоуровневая стратегия агента будет состоять из действий, усло-
виями выполнения для которых будет служить наличие объекта определен-
ного класса, т.е. множество действий также разбивается на подмножества
в соответствии с количеством классов A = {Aci |ci ∈ C}. Проведя такую де-
композицию задачи, возможно определить и выписать соотношение на по-
лезность не всего состояния или наблюдения, а на полезность конкретно-
го объекта, имеющегося в текущем наблюдении. Все соотношения на функ-
ции полезности, определенные в подразделе 2.4, остаются в силе с той лишь
поправкой, что в текущем наблюдении агент выбирает действие жадно, в
соответствии с наибольшей полезностью конкретного объекта Qa(b, κ, a) =
= arg max Qa(e, κ, ac(e)). Будем считать, что умения агента не поддаются ана-
e∈o
логичной декомпозиции и зависят от всего наблюдения целиком.
2.4. Обновление плана поведения
В постановке задачи одновременного обучения и планирования агент авто-
матически строит обновляемую модель среды M =
T,R,Ω >, которая поз-
воляет находить план B достижения цели G(sl) = 1 за счет моделирования
переходов при некоторой модельной стратегии π:
Bπ =< o0,r0,a0,o1,r1,a1,... ,al-1,ol >,
где si =
T (si-1, ai-1), ri =
R(si, ai), ai ∼ π(a|oi), а заключительное наблю-
дение ol соответствует целевому состоянию sl согласно функцииΩ. Здесь
60
по
T,ΩиM =
T, R > будем понимать приближенные (аппроксимируемые)
значения функций переходов, наблюдений и вознаграждений соответствен-
но. План поведения агента, таким образом, составляется жадным образом
в точности до небольшой поправки, отвечающей за исследование среды, в
предположении корректности текущего приближения модели M =
T, R >.
Под процессом обучения агента будет пониматься итерационное обновле-
ние модели M =
T, R >, функций полезности Q, стратегии π и соответ-
ственно плана поведения Bπ. Возможны четыре основных варианта состав-
ления общей схемы обучения агента с использованием фазы планирования
по модели. Приведем краткие алгоритмические схемы для этих вариантов.
Будем обозначать собранный агентом опыт в виде множества прецедентов
D = {(ot,rt,at)Tt=1}. Траекторией будем называть некоторую последователь-
ность таких прецедентов в порядке их формирования при взаимодействии со
средой. Первый вариант интеграции представляет собой обучение с исполь-
зованием планируемых (“воображаемых”) траекторий [16]:
1. Агент предсказывает (“воображает”) траектории с некоторого состоя-
ния st, используя модель M =
T, R >.
2. Агент обновляет свою стратегию, используя прецеденты из предсказы-
ваемых траекторий.
3. Агент набирает новый опыт взаимодействия со средой по обновленной
стратегии.
4. По собранному опыту D агент обновляет модель среды M =
T, R >.
5. Шаги 1-4 повторяются до сходимости.
Второй вариант — обучение с использованием разделения стратегий —
подразумевает использование модели только на начальной стадии взаимо-
действия со средой, постепенно расширяя горизонт ее применения в процессе
уточнения:
1. Агент планирует и выполняет первые шаги в траектории, используя
модель M =
T, R >.
2. Агент использует текущую стратегию для продолжения траекторий в
процессе взаимодействия со средой.
3. По собранному опыту агент обновляет модель и стратегию, одновремен-
но выбирая критерий остановки планирования и запуска интерактивной
стратегии.
Обучение с имитацией эпизодов возможно только в случае наличия копий
среды, в которых агент имитирует свое поведение:
1. Используем возможность запускать симуляции действий агента в среде,
чтобы с текущего шага проиграть некоторое количество эпизодов для
обновления этой модели.
2. На основе обновленной модели определяем полезность состояний и вы-
бираем действие, выполняемое в среде.
3. Обновляем стратегию, используя выбранное действие в качестве эта-
лонного.
61
В предлагаемой в данной статье постановке задачи одновременного обу-
чения и планирования используется иерархия для разделения применения
модели и интерактивной стратегии:
1. Агент на верхнем уровне иерархии действия использует модель M =
=
T, R > для получения плана на множестве умений.
2. Стратегия каждого умения формируется в интерактивном режиме в
процессе взаимодействия со средой.
3. Набранный опыт используется агентом для одновременного уточнения
модели на умениях и стратегий каждого умения.
Принимая во внимание все приведенные уточнения постановки задачи од-
новременного обучения и планирования, получается иерархическая поста-
новка, в которой агенту необходимо максимизировать получаемую в рамках
эпизода отдачу с возможностью декомпозиции наблюдения по предметному
принципу, автоматическому построению стратегий умений и при одновремен-
ном автоматическом формировании модели среды, используемой для плани-
рования на множестве умений.
3. Архитектура SLAP агента
Для решения поставленной в разделе 2 общей задачи одновременного обу-
чения и планирования в данной статье предлагается использовать следую-
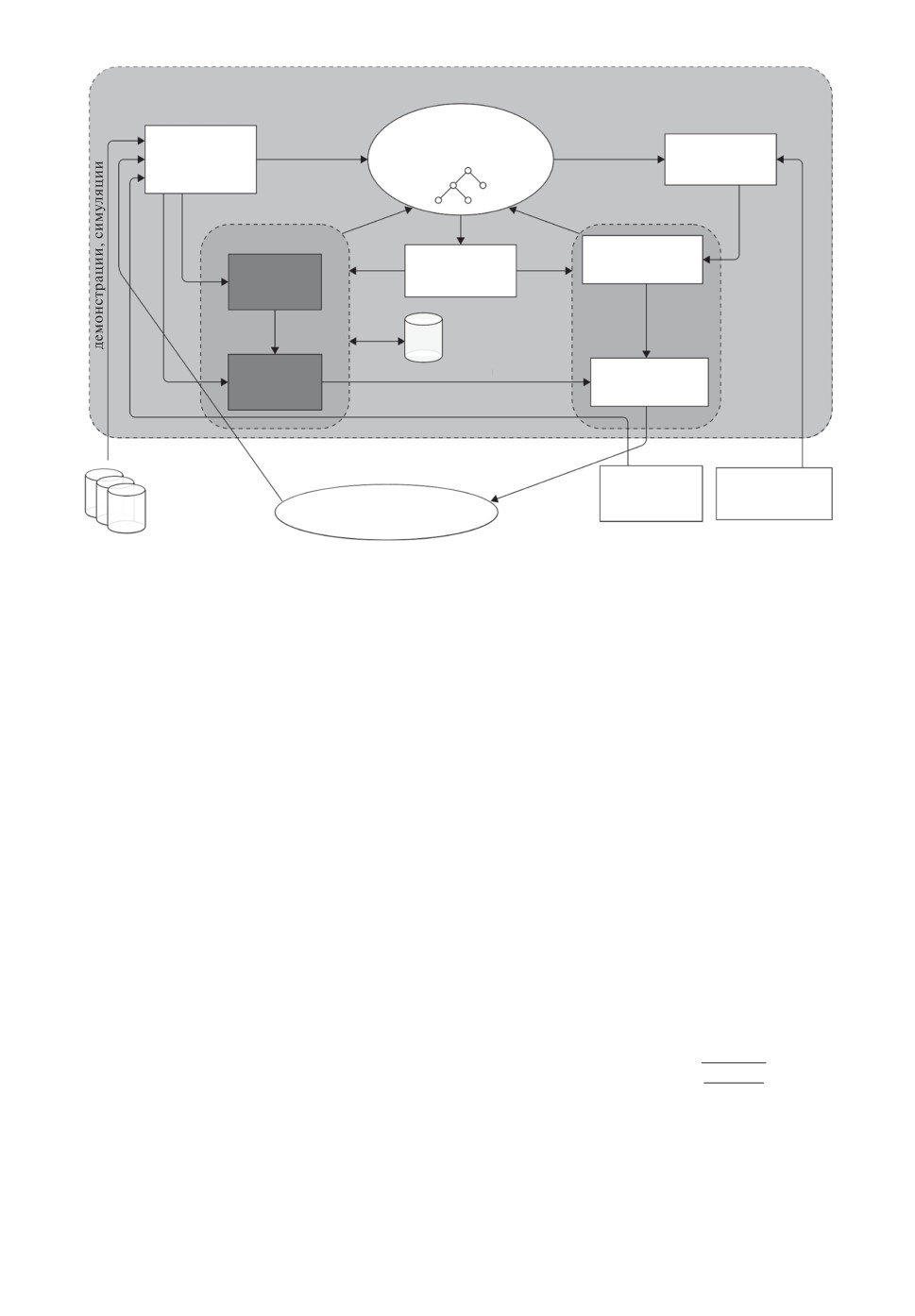
щую архитектуру интеллектуального SLAP агента (см. рис. 2). Подсисте-
му обучения агента разделим на две составляющие, как это принято в тео-
рии обучения с подкреплением. Критик обновляет функцию полезности дей-
ствия Qa, а актор формирует стратегию πκ в рамках текущего умения. Цикл
взаимодействия SLAP агента со средой будет выглядеть следующем образом:
1. Агент использует текущую модель для того, чтобы сформировать план
Bπ = < o0,r0,a0,o1,r1,a1,... ,al-1,ol > на множестве умений с помо-
щью процедуры SLAPplan. В общем случае предполагается, что уровней
иерархии действий может быть несколько (вложенные умения) и может
быть сформировано несколько вложенных планов: от высокоуровневого
до низкоуровневого. Далее считаем, что план Bπ является низкоуров-
невым.
2. В соответствии с планом агент Bπ выбирает текущее умение κt.
3. Агент получает из среды текущее наблюдение, которое с помощью
функции Φp переводится в набор предметов ot → {e1, . . . , en}.
4. В соответствии со стратегией πκ для умения κt агент выбирает текущее
действие at.
5. Агент выполняет действие at в среде и получает новые наблюдения и
вознаграждение.
6. С помощью процедуры SLAPlearn агент проводит оценку выполненно-
го действия и самого умения с помощью критика, а затем обновляет
функции аппроксимации критика и актора.
7. Если текущее умение завершилось, выполняется перепланирование, и
затем происходит переход к шагу 3.
62
Одновременное обучение и планирование
Динамическая
обновление
использование
Текущая
предметная модель
предметная
модели
модели
Планирование
M = T, R ^^
поведения
ситуация
по модели
ot
{e1, ..., en}
оценки
прецеденты
ki - по умениям
Генерация
Верхнеуровневый
Критик
подцелей
план {k1, ..., km}
{
1, ..., l}
a
действий Q
оценка
буфер
ситуации
прецедентов
Актор
уточнение действий и навыков
Низкоуровневый
для умений k
план {а1, ..., аk}
отработка движения
целевая область
объекты и
и временные
Наборы данных
признаки
ограничения
Планирование
Общая
и симуляторы
задача
для обучения
движения
Сенсорная
R, G
Dk
ситуация
Рис. 2. Архитектура SLAP агента с подсистемами обучения (выделены тем-
ным цветом) и планирования поведения. Данная схема представляет собой
верхний уровень архитектуры STRL, которая изображена на рис. 1, с детали-
зацией взаимодействия методов обучения и планирования.
Кратко изложим принципы работы процедур SLAPplan и SLAPlearn. При
планировании агент использует модель M =
T,R,Ω > для построения пла-
на своего поведения. В настоящей статье предлагается использовать реали-
зацию модели в виде расширенного дерева поиска Монте-Карло, где каж-
дый узел дерева отвечает за конкретный объект, выделяемый из наблюде-
ния. Ребро дерева соответствует выбору некоторого объекта из наблюдения,
выполнению некоторого действия (умения) и переходу к наблюдению, где
выделяется следующий объект. В случае, когда для выполнения выбирается
действие (умение), для которого в модели неизвестно следующее наблюде-
ние, образуются новые узлы с соответствующими объектами, выделенными
из наблюдения, полученного из среды.
Планирование SLAP plan(M, e) в данном дереве M =
T,R,Ω > проис-
ходит за счет поиска кратчайшего пути с учетом дополнительного веса для
действий, направленных на исследование среды:
√
log N(e)
1. Выбираем планируемое умение κ ← arg maxQκ(e) + η
. Здесь
N (e,κ)
κ
второе слагаемое отвечает за верхнюю доверительную границу (UTC)
эффективной стратегии исследования среды, η - константа, N - счет-
чики.
2. Производим переход по дереву e′
Tc(κ), r ←Rc(κ), где c - класс
объекта e.
63
3. Производим планирование для следующего объекта c подсчетом полу-
чаемого вознагражденияR ← r + γSLAP plan(M, e′).
4. Обновляются счетчики N(e, κ) ← N(e, κ) + 1, N(e) ← N(e) + 1.
5. Настраивается модель
— обновляем полезность умения Qκ(b, κ) ←
R-Qκ(b,κ)
← Qκ(b,κ) +
, где b - предполагаемое состояние, для которо-
N (e,κ)
го выделяется объект e.
В процедуре обучения критика и актора SLAPlearn производится обнов-
ление как критерия достижения подцели βκ, так и стратегии πκ конкретного,
выбранного на верхнем уровне иерархии умения. Напомним, что здесь ис-
пользуется параметризация с помощью набора параметров ϑ для условия
завершения и набора θ — для стратегии:
1. Агент выбирает действие в соответствии с текущей стратегией умения
a ∼ πκ,θ(a|o).
2. Агент выполняет действие a, наблюдает o′ и r.
3. Критик обновляет оценку полезности действия в рамках текущего уме-
ния:
Qa(b,κ,a) ← Qa(b,κ,a)+
(
(
)
)
+ α r +γ (1-βκ,ϑ(o′))Qκ(b′,κ)+βκ,ϑ(o′)maxQκ(b′,κ′) - Qa(b,κ,a) ,
κ′
где α - шаг обучения критика, g - обновляемое целевое значение для
критика.
4. Актор обновляет параметры для стратегии и для подцели
θ ← θ + αθ∇θ log πκ,θ(a|o)Qa(b,κ,a),
ϑ ← ϑ + αϑ∇ϑ Qκ(b′,κ),
где αθ и αϑ - шаги обучения.
5. Обновляем значение градиента полезности умения ∇θQκ, который мо-
жет быть использован на верхнем уровне иерархии.
6. Если в соответствии с βκ,ϑ подцель достигнута, то в соответствии с вы-
сокоуровневым планом выбирается новое умение κ.
Здесь предполагается, что полезность текущего умения передается из под-
системы планирования, где обновление полезности происходит во время об-
новления самой модели. В разделе 5 дан вывод выражений для градиен-
та ∇θQκ (теорема о градиенте критика) и для градиента ∇ϑ Qκ генератора
подцелей (теорема о градиенте актора).
4. Модельный пример
В качестве модельного примера рассмотрим задачу обучения навигации
до некоторой заданной целевой точки в клеточной среде с препятствиями
и управляемыми объектами (дверьми) (см. рис. 3,a). Среда организована в
виде комнат с узкими проходами между ними таким образом, чтобы поддер-
живать формирование двухуровневой иерархии действий. Верхний уровень:
64
а
б
в
c1
a
a
room1
0,01
0,01
k1
e1
1
0,05
2
c2
c6
room2
e1
a
room4
a
a
a
a
a
Qk , N1
0,01
0,01
1
0,01
1
1
1
k1
3
0,03
k2
c1
c5
c3
c
5
c9
c1
0,05
k1
e3
room3
room1
Qk , N1
Qk , N2
1
ai
k1
a
a
1
c6
1
1
1
room4
c36
c36
c1
c2
c3
c36
Qk , N1
Рис. 3. а - Модельный пример перемещения агента по клеточной среде с ком-
натами, открывающимися проходами между ними и опасными состояниями,
в которых завершается эпизод взаимодействия; б - соответствующая мар-
ковскому процессу принятия решения модель, которая строится агентом без
иерархической декомпозиции; в - модель клеточной среды, которую строит
агент с умениями.
умения по переходу от одной комнаты к другой, нижний уровень: действия
по перемещению в четыре стороны для достижения выхода из комнаты или
достижения целевой клетки в комнате. Опишем среду подробнее.
В данном примере наблюдение агента ot — это область видимости вокруг
агента радиусом в две клетки (на рис. 3 обозначены серым цветом). Множе-
ство действий агента A состоит из четырех действий: поворот на 90◦ по часо-
вой или против часовой стрелки, проход прямо, открытие двери. На верхнем
уровне иерархии агенту доступны умения κi, состоящие из действий ai. Под-
целями βi, в которых завершаются умения, являются клетки, обозначенные
светло-серым цветом. Выделяемыми с помощью функции Φp объектами ei
в среде являются сами комнаты, двери каждой комнаты, принадлежащие
классу объектов c0, и отдельные клетки, в которых в данный момент нахо-
дится агент. При этом каждой комнате и клетке соответствует свой класс ci.
Функция вознаграждения R реализована следующим образом: каждый мо-
мент времени агенту дает небольшое отрицательное вознаграждение (-0, 01),
за попадание в темные клетки — (-1) с завершением эпизода, за достижение
цели (темная клетка справа внизу) дается +1. В качестве выбираемой пара-
метризации используется линейная модель, взвешивающая признаки, соот-
ветствующие предметам, выделяемым по наблюдению.
Предметная модель, которую строит и обновляет агент, представлена на
рис. 3,в. Для сравнения на рис. 3,б показана модель, которую агент аппрок-
симировал бы без иерархического представления действий. Процедуры пла-
нирования SLAP plan(M, e) и обучения SLAPlearn для агента для представ-
ленного пример будут выглядеть следующим образом.
SLAPplan:
1. Выбираем планируемое умение κ по переходу из текущей комнаты e в
соседнюю e′ в соответствии с предсказываемой по дереву полезностью
данного умения с учетом параметра исследования среды.
65
2. По текущему виду дерева (так как модель обновляется в процессе обу-
чения, она может не соответствовать итоговой модели на рис. 3,в) про-
изводится переход в соседнюю комнату e′ по стратегии умения πκ с под-
счетом вознаграждения в виде суммы вознаграждений после каждого
действия стратегии πκ.
3. Рекурсивно запускается аналогичная процедура для новой комнаты e′.
4. Обновляются счетчики N(e, κ) ← N(e, κ) + 1, N(e) ← N(e) + 1.
5. Настраивается модель — обновляется полезность умения Qκ(b, κ).
SLAPLearn:
1. Агент выбирает действие по переходу в соседнюю клетку или открытию
двери в соответствии с текущей стратегией умения a ∼ πκ,θ(a|o), учиты-
вая, что сейчас агент находится в определенной комнате и выполняется
текущее умение κ.
2. Агент выполняет действие a, обновляется наблюдение — в область ви-
димости агента попадают новые предметы (клетки, дверь).
3. Критик обновляет оценку полезности действия в рамках текущего уме-
ния, вычисляя TD ошибку.
4. Актор обновляет параметры для стратегии и для подцели, вычисляя
градиент.
5. Если в соответствии с βκ,ϑ подцель достигнута, то в соответствии с вы-
сокоуровневым планом выбирается новое умение κ.
5. Теоремы о градиенте
В разделе 2 была представлена общая схема взаимодействия SLAP агента
со средой, где для обучения агента необходимо знание целевого значения
критика g и для градиента функции полезности стратегии ∇J. Проведем
краткие выкладки для вычисления их значений.
∑
∑
Выражениеs′ Ω(o|s′, a)s T (s′|s, a)b(s|o) представляет собой вероят-
ность получения агентом следующего наблюдения o′, что будем обозначать
как p(o|a, b). В начале найдем выражение для градиента полезности умения
Qκ(b,κ) относительно параметров реализующей его стратегии θ:
∑
(7)
∇θQκ(b,κ) = ∇θ πκ,θ(a|o)Qa(b,κ,a) =
a
∑
=
(∇θπκ,θ(a|o)) Qa(b,κ,a) +
a
)
∑
(∑
∑
+ πκ,θ(a|o)∇θ
b(s|o)R(s, a) + γ
p(o|a, b)Qκ(b′(s′|o), κ)
=
a
s
o
∑
∑
∑
=
(∇θπκ,θ(a|o)) Qa(b, κ, a) +
πκ,θ(a|o)
γp(o|a,b)∇θ Qκ(b′(s′|o),κ).
a
a
o′
66
Используя выражение в определении поправленной полезностиQκ, найдем
ее градиент:
∑(
)
(8)
∇θ Qκ(b′,κ) = (1 - βκ,ϑ(o′)) +
βκ,ϑ(o′)π(κ′|b′)
∇θQκ(b′,κ′
).
κ′
Подставляя это в выражение для градиента полезности умения, получим:
∑
(9)
∇θQκ(b,κ) =
(∇θπκ,θ(a|o)) Qa(b, κ, a) +
a
∑
∑
+ πκ,θ(a|o) γp(o|a,b)∇θ Qκ(b′(s′|o),κ) =
a
o′
∑
∑∑
=
(∇θπκ,θ(a|o)) Qa(b,κ,a) +
p(o′, κ′|b, κ)∇θ Qκ(b′, κ′),
a
o′ κ′
где p(o′, κ′|b, κ) задает расширенный марковский процесс принятия реше-
ний, в котором состояниям соответствует пара наблюдение-умение. Учитывая
марковское свойство при раскрытии рекурсии в определении ∇θQκ, получа-
ется доказательство теоремы 1.
Теорема 1 (о градиенте критика умений). Для фиксированного множе-
ства марковских умений со стохастической реализующей стратегией, диф-
ференцируемой по параметрам θ, градиент ожидаемой дисконтированной
отдачи по параметрам θ с начальными условиями (b0,κ0) равен
∑
∑
(10)
∇θQκ(b,κ) =
μκ(b,κ|b0,κ0)
(∇θπκ,θ(a|o)) Qa
(b, κ, a),
b,κ
a
где μκ(b, κ|b0, κ0) - дисконтированные частоты появления предполагаемого
состояния и умения по траекториям, начинающимся с начальных условий
(b0, κ0).
В разделе 4 для обновления параметров генератора подцелей было указано
на необходимость вычисления градиента ∇ϑ Qκ. Используем определение для
этой функции полезности:
∇ϑ Qκ = ∇ϑβκ,ϑ(o′)(Vκ(b′) - Qκ(b′,κ)) +
∑
∑
+ (1 - βκ,ϑ(o′))
πκ,θ(a|o′)
γp(o′′|a,b′)∇ϑ Qκ(b′′,κ).
a
o′′
Здесь также замечаем наличие рекурсии, и использование структуры рас-
ширенного марковского процесса принятия решений приводит к теореме 2.
Теорема 2 (о градиенте генератора подцелей). Для фиксированного
множества марковских умений со стохастической реализующей страте-
гией, дифференцируемой по параметрам ϑ, градиент ожидаемой дисконти-
рованной отдачи по параметрам ϑ с начальными условиями (b1,κ0) равен
∑
(11)
∇ϑ Qκ(b,κ) =
μκ(b′,κ|b1,κ0)∇ϑβκ,ϑ(o′)(Vκ(b′) - Qκ(b′
, κ)),
b′,κ
67
где μκ(b′, κ|b1, κ0) - дисконтированные частоты появления предполагаемого
состояния и умения по траекториям, начинающимся с начальных условий
(b1, κ0).
Таким образом, сформулированы две теоремы, которые позволяют полу-
чить выражения для обновления набора параметров в процедуре SLAPLearn.
6. Возможности применения подхода SLAP в управлении
беспилотным транспортным средством
Предложенная архитектура SLAP агента может служить теоретическим
обоснованием реализации адаптивной системы управления беспилотным ав-
томобилем. На рис. 4 представлена схема интеграции SLAP агента в широко
распространенную в индустрии систему управления беспилотными автомо-
билями Apollo. В данном случае предполагается, что стандартный модуль
планирования будет заменен модулем, который помимо планирования поз-
воляет сохранять опыт, дообучаться и использовать настроенные стратегии
для улучшения и ускорения этапа планирования. Таким образом, наряду с
рядом подсистем, которые используются в Apollo и в STRL (локализации, по-
строение карты и т.д.), за адаптивное планирование поведения здесь отвечает
SLAP агент. В системе Apollo интеграция всех этих модулей осуществляет-
ся на основе модифицированной робототехнической операционной системы
(Apollo Cyber RT и системы реального времени RTOS), которая позволяет
обмениваться сообщениями в асинхронном режиме различным подсистемам.
Рассмотрим задачу обгона автомобилем динамических препятствий (дру-
гих автомобилей) на многополосном шоссе (рис. 5). Модуль построения карты
выдает информацию о границах дороги, полосах и разрешенных скоростях.
Модуль локализации позволяет агенту определить свое положение и скоро-
сти на шоссе. Модуль построения сенсорной модели передает информацию о
движущихся объекта и их скоростях. Модуль предсказания траектории вы-
дает предполагаемые траектории всех объектов на сцене с некоторым гори-
зонтом планирования. В модуле одновременного планирования и обучения
реализуется схема по иерархическому адаптивному планированию. На верх-
нем уровне составляется абстрактный план по действиям, которые должен
совершить агент (перестроение направо, перестроение налево). Данный план
Открытая платформа STRL-Apollo
Построение
Построение
Предсказание
Одновременное
Управление
Взаимодействие
Локализация
сенсорной
планирование
карты
модели
траекторий
и обучение
движением
с водителем
Обмен
данными
с дорожной
Apollo Cyber RT
инфраструктурой
RTOS
Рис. 4. Схема использования SLAP агента в качестве модуля в системе управ-
ления Apollo.
68
4
(6,2 m, 5,0 m/s)
Рис. 5. Пример реализации сценария обгона динамических препятствий в си-
стеме управления Apollo с использованием предложенной концепции адаптив-
ного планирования. Светлые тонкие линии — предсказываемые траектории
объектов, светлая полоса — планируемая траектория агента.
строится путем поиска кратчайшего на графе поведенческого дерева (вы-
числительный аналог дерева Монте-Карло в Apollo), в котором реализованы
основные правила и условиях обгона (см. подробности реализации в [17]).
Каждый шаг высокоуровневого плана уточняется в процессе обучения
(реализации построенных планов) в симуляторе, и каждая часть общего ма-
невра обгона настраивается для субоптимальной реализации соответствую-
щей части общей траектории с использованием обучения с подкреплением
или с его “мягкой версией” — эволюционным программированием. Наконец,
сглаживание построенных траекторий с учетом динамики объекта управле-
ния происходит в модуле управления движением.
Интеграция в общую схему управления автомобилем, реализуемую в
Apollo, подсистемы SLAP позволяет добиться большей адаптивности полу-
чаемых решений и позволяет автоматизировать процесс задания условий для
совершения безопасного маневра.
7. Заключение
В статье представлен новый подход к задаче интеграции подсистем плани-
рования и обучения в иерархических системах управления мобильными робо-
тотехническими платформами и беспилотными транспортными средствами.
Была предложена оригинальная иерархическая постановка задачи одновре-
менного планирования и обучения, в которой предлагается провести двойную
декомпозицию задачи. Первая декомпозиция реализуется за счет выделения
абстрактных действий — умений и обучаемых стратегий, которые реализу-
69
ют их на операционном уровне. Вторая декомпозиция касается выделения
предметной среды в ситуации и упрощении модели, используемой для обуче-
ния актора, формирующего стратегию, и критика, оценивающего полезность
ситуаций. В статье предложены два примера, в которых продемонстриро-
ваны особенности работы архитектуры SLAP агента, решающего поставлен-
ную задачу: модельная задача с комнатами и важная индустриальная задача
планирования маневров беспилотного автомобиля. Предложенные принципы
обучения SLAP агента теоретически обоснованы.
В дальнейшем предполагается развитие предложенного подхода в двух
направлениях. Первое направление предполагает теоретическое исследова-
ний сложностных свойств предложенных алгоритмов, критериев сходимости
процесса обучения и нижних гарантируемых оценок качества получаемых
стратегий агента. Второе направление предполагает продолжение проработ-
ки принципов обновления и использования объектной модели сенсорной си-
туации для более эффективной работы процедур планирования.
СПИСОК ЛИТЕРАТУРЫ
1.
Trafton G.J., et al. ACT-R/E: An Embodied Cognitive Architecture for Human-
Robot Interaction // J. Human-Robot Interaction. 2013. V. 2. No. 1. P. 30-54.
2.
Goertzel B. From Abstract Agents Models to Real-World AGI Architectures:
Bridging the Gap // Lecture Notes in Computer Science / ed. Everitt T., Goertzel B.,
Potapov A. Cham: Springer International Publishing, 2017. V. 10414. P. 3-12.
3.
Wu J., et al. Track to Detect and Segment: An Online Multi-Object Tracker // 2021
IEEE/CVF Conf. on Computer Vision and Pattern Recognition (CVPR). IEEE,
2021. P. 12347-12356.
4.
Likhachev M., Ferguson D. Planning long dynamically feasible maneuvers for
autonomous vehicles // Int. J. Robotics Research. 2009. V. 28. No. 8. P. 933-945.
5.
Aitygulov E., Kiselev G., Panov A.I. Task and Spatial Planning by the Cognitive
Agent with Human-like Knowledge Representation // Interactive Collaborative
Robotics. ICR 2018. Lecture Notes in Computer Science / ed. Ronzhin A., Rigoll G.,
Meshcheryakov R. Springer, 2018. V. 11097. P. 1-12.
6.
Саттон Р.С., Барто Э.Г. Обучение с подкреплением. М.: БИНОМ. Лаборато-
рия знаний, 2011. Изд. 2-е.
7.
Moerland T.M., Broekens J., Jonker C.M. Model-based Reinforcement Learning: A
Survey. 2020. P. 421-429.
8.
Макаров Д.А., Панов А.И., Яковлев К.С. Архитектура многоуровневой интел-
лектуальной системы управления беспилотными летательными аппаратами //
Искусственный интеллект и принятие решений. 2015. № 3. С. 18-33.
9.
Yakovlev K., et al. Combining Safe Interval Path Planning and Constrained Path
Following Control: Preliminary Results // Interactive Collaborative Robotics. ICR
2019. Lecture Notes in Computer Science. 2019. V. 11659. P. 310-319.
10.
Staroverov A., et al. Real-Time Object Navigation with Deep Neural Networks and
Hierarchical Reinforcement Learning // IEEE Access. 2020. V. 8. P. 195608-195621.
11.
Киселев Г.А. Интеллектуальная система планирования поведения коалиции ро-
бототехнических агентов с STRL архитектурой // Информационные технологии
и вычислительные системы. 2020. № 2. С. 21-37.
70
12. Pack L., Littman M.L., Cassandra A.R. Planning and acting in partially observable
stochastic domains // Artificial Intelligence. 1998. V. 101. P. 99-134.
13. Bacon P.-L., Harb J., Precup D. The Option-Critic Architecture // Proc. of the
AAAI Conf. on Artificial Intelligence. 2017. V. 31.
14. Keramati R., et al. Strategic Object Oriented Reinforcement Learning. 2018.
15. Watters N., et al. COBRA: Data-Efficient Model-Based RL through Unsupervised
Object Discovery and Curiosity-Driven Exploration. 2019.
16. Hafner D., et al. Dream to Control: Learning Behaviors by Latent Imagination //
Int. Conf. on Learning Representations. 2020.
17. Jamal M., Panov A. Adaptive Maneuver Planning for Autonomous Vehicles Using
Behavior Tree on Apollo Platform // Artificial Intelligence XXXVIII. SGAI 2021.
Lecture Notes in Computer Science / ed. Bramer M., Ellis R. 2021. V. 13101.
P. 327-340.
Статья представлена к публикации членом редколлегии О.П. Кузнецовым.
Поступила в редакцию 31.10.2021
После доработки 09.01.2022
Принята к публикации 26.01.2022
71