Автоматика и телемеханика, № 5, 2023
Интеллектуальные системы управления,
анализ данных
© 2023 г. Х. ЧЕН, PhD (eric.hf.chen@hotman.com)
(Чжэцзян Шурен университет, Ханчжоу),
С.А. ИГНАТЬЕВА (s.ignatieva@psu.by),
Р.П. БОГУШ, д-р техн. наук (r.bogush@psu.by)
(Полоцкий государственный университет
имени Евфросинии Полоцкой, Новополоцк),
С.В. АБЛАМЕЙКО, д-р техн. наук (ablameyko@bsu.by)
(Белорусский государственный университет, Минск)
ПОВТОРНАЯ ИДЕНТИФИКАЦИЯ ЛЮДЕЙ
В СИСТЕМАХ ВИДЕОНАБЛЮДЕНИЯ
С ИСПОЛЬЗОВАНИЕМ ГЛУБОКОГО ОБУЧЕНИЯ:
АНАЛИЗ СУЩЕСТВУЮЩИХ МЕТОДОВ
Статья посвящена многостороннему анализу повторной идентифика-
ции людей в системах видеонаблюдения и современных методов ее реше-
ния с использованием глубокого обучения. Рассматриваются общие прин-
ципы и применение сверточных нейронных сетей для этой задачи. Пред-
ложена классификация систем реидентификации. Приведен анализ суще-
ствующих наборов данных для обучения глубоких нейронных архитек-
тур, описаны подходы для увеличения количества изображений в базах
данных. Рассматриваются подходы к формированию признаков изобра-
жений людей. Представлен анализ основных применяемых для реиденти-
фикации моделей архитектур сверточных нейронных сетей, их модифика-
ций, а также методов обучения. Анализируется эффективность повторной
идентификации на разных наборах данных, приведены результаты иссле-
дований по оценке эффективности существующих подходов в различных
метриках.
Ключевые слова: реидентификация, видеоданные, сверточные нейронные
сети, метрики оценки точности, дескрипторы изображений.
DOI: 10.31857/S0005231023050057, EDN: AHHWFO
1. Введение
Широкое внедрение систем видеонаблюдения позволяет решать множе-
ство практических задач, в том числе и повышения уровня общественной
безопасности. Так, важным и актуальным является определение присутствия
заданного человека по его изображениям на видеоданных в другом месте или
61
в разное время в пространственно-распределенных системах видеонаблюде-
ния. Такая задача называется повторной идентификацией или реидентифи-
кацией человека. Для ее решения необходимо выявить отличительные при-
знаки и путем выполнения запроса к базе данных сравнить их с признаками
из имеющейся выборки изображений множества людей (галереи). Причем
состав набора признаков в значительной мере определяет эффективность ре-
идентификации. Поиск и выделение наиболее отличительных особенностей
объектов на изображениях, в том числе и людей, не формализованы. Следо-
вательно, используется эмпирический подход, который в большинстве случа-
ев является долгим и трудоемким процессом. Для реидентификации людей
из-за неоднозначности внешнего вида с разных ракурсов, вариаций освеще-
ния, различных разрешений камер, окклюзий для этого требуются нерацио-
нально большие вычислительные затраты. Поэтому долгое время для повтор-
ной идентификации людей значимые результаты не достигались. Совершен-
ствование средств вычислительной техники и открытия в области глубокого
обучения, в частности развитие сверточных нейронных сетей (СНС), позво-
лили автоматизировать процесс извлечения признаков изображений людей
и обеспечить значительное увеличение точности реидентификации. Однако
несмотря на то, что данной задачей с применением методов глубокого обу-
чения занимаются многие ученые и инженеры в мире, она не решена пол-
ностью, и при разработке системы повторной идентификации по-прежнему
приходится сталкиваться с большим числом проблем, а широкое разнообра-
зие областей применения повторной идентификации, таких как пропускные
системы на режимных предприятиях, поиск пропавших людей или правона-
рушителей, сбор статистической информации о посещении людьми торговых
центров и других социальных объектов, приводят к существованию большого
числа подходов и алгоритмов для ее решения, которые имеют разные каче-
ственные характеристики.
2. Организация и оценка эффективности повторной
идентификации людей в распределенных
системах видеонаблюдения
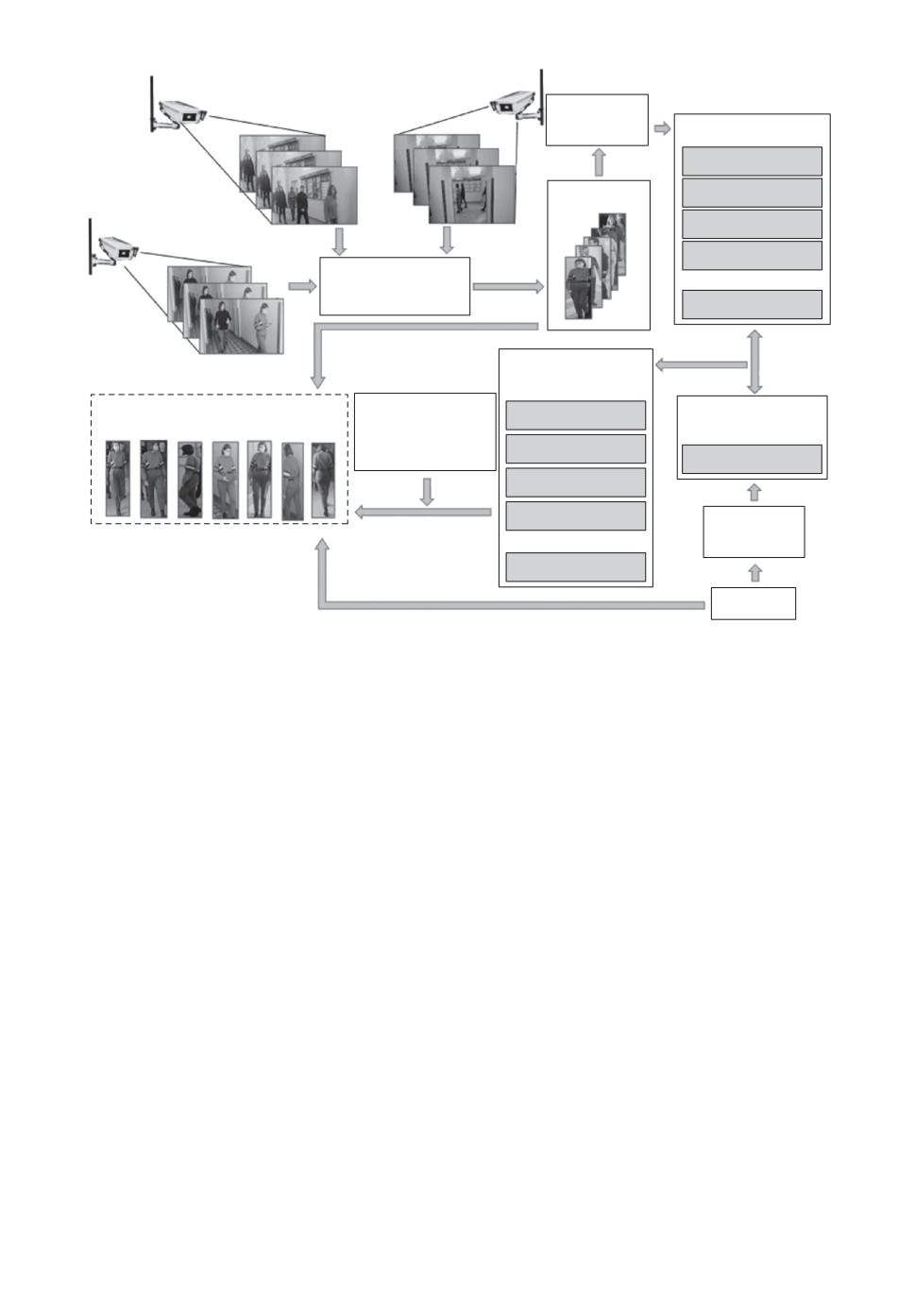
2.1. Обобщенная схема системы повторной идентификации
Пространственно-распределенная система видеонаблюдения состоит из
территориально разнесенных IP камер и организована, как правило, на осно-
ве единого центра обработки данных. На рис. 1 показана упрощенная струк-
тура повторной идентификации в такой системе, которая включает три IP
видеокамеры C1, C2, C3. На каждом кадре Fk, k — номер видеокамеры, с по-
мощью детектора выполняется обнаружение всех людей, попадающих в по-
ле зрения камер, и формирование ограничительных рамок для них, кото-
рые описывают прямоугольником обнаруженные фигуры. Изображения лю-
дей Ii, где i = 1, . . . , Nimg, Nimg — общее количество изображений, размеща-
ются в галерее. Для каждого из них с помощью СНС определяются векто-
62
С1
С1
Извлечение
2
признаков
4
FN
Таблица признаков
F
N
4
2
gen
F
2
F
2
2
f1
F14
F1
gen
f2
Галерея
С
3
f3gen
gen
f4
3
FN
K
Детектирование
F2
человека
gen
K
f
3
F1
dq
Ранжированная
таблица признаков
Результат повторной
Дополнительные
gen
fd
Вектор признаков
min
идентификации по запросу
признаки
запроса
odd
fdgen
fi
min 1
fqgen
fdgen
min 2
gen
fd
min 3
Извлечение
признаков
gen
fd
max
Запрос
Рис. 1. Общая схема системы повторной идентификации.
ры fgeni (СНС дескрипторы), формирующие общее пространство СНС при-
знаков χIi = {fgeni}, которое представляется в виде таблицы, причем каждая
строка является СНС дескриптором fgeni для одного изображения.
Для описания человека при редентификации используется составной век-
тор признаков, который может быть представлен как
(1)
PID = (pIDn,fgeni,faddi
),
где pIDn — идентификатор (метка) человека; n — количество возможных иден-
тификаторов, равное общему числу уникальных людей; fgeni — вектор СНС
признаков для i-го изображения человека, который может включать СНС
признаки, разделяемые на глобальные признаки fglobali, характеризующие
изображение в целом, и локальные flocali,j, получаемые при разделении изоб-
ражение на j частей; faddi — дополнительные признаки, которые могут со-
держать информацию, позволяющую улучшить эффективность системы ре-
идентификации, например идентификатор камеры CID, номер кадра c k-й ви-
деокамеры Fkm или др. [1].
При поступлении запроса для повторной идентификации человека вычис-
ляется его вектор признаков
q
, который используется для нахождения
расстояния dq, определяющего степень подобия между данным запросом и
63
дескрипторами изображений галереи. С использованием найденных расстоя-
ний выполняется ранжирование в таблице χIi от dmin до dmax. С учетом до-
полнительных признаков исключаются изображения, которые по каким-либо
критериям позволяют предполагать, что несмотря на схожесть визуальных
признаков, изображение-кандидат не соответствует искомому человеку. На-
пример, если на изображениях с двух неперекрывающихся камер в одно и
то же время находится объект интереса со схожими визуальными признака-
ми, то можно однозначно утверждать, что это разные люди, так как один и
тот же человек не может присутствовать в двух местах одновременно. После
исключения всех неподходящих кандидатов в качестве результата повторной
идентификации отображаются изображения людей, fgeni которых находились
вверху списка ранжированной таблицы. Первый человек из этого списка при-
нимается за результат повторной идентификации как наиболее схожий с за-
просом.
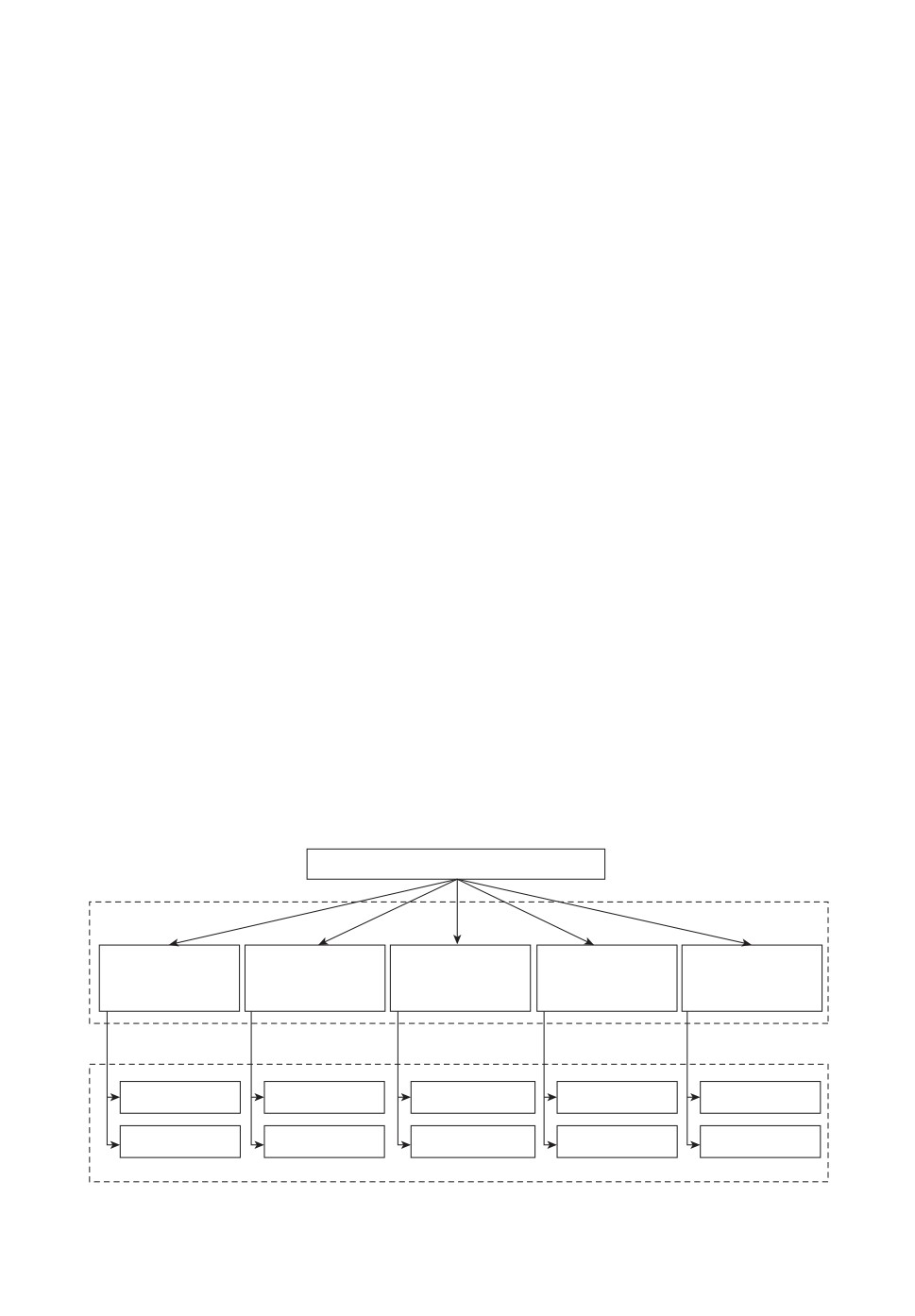
2.2. Классификация систем повторной идентификации
Широкая область применения систем повторной идентификации человека
обуславливает существование большого количества алгоритмов и подходов
для решения задачи, и, соответственно, различные способы классификации
таких систем (рис. 2). Так, по взаимодействию с внешней средой можно вы-
делить системы повторной идентификации закрытые (Close-world), исполь-
зующие готовые наборы данных для обучения и тестирования, и открытые
(Open-world), в которых галерея изображений постоянно пополняется новы-
ми кадрами [2]. Закрытые системы обычно применяются в исследовательских
целях и набор данных состоит из ограниченного количества видеопоследова-
тельностей или изображений, полученных с нескольких камер видеонаблюде-
ния. Данные в таких наборах аннотированы и подготовлены заранее, запрос
присутствует в галерее. В открытых системах используется набор данных,
Cистемы повторной идентификации
Критерии классификации
По
По типу
По количеству
По типу
По времени
взаимодействию с
анализируемых
запросов
запросов
работы
внешней средой
видеоданных
Закрытые
Статические
Одиночные
Однородные
Краткосрочные
Открытые
Динамические
Множественные
Неоднородные
Долгосрочные
Классы систем
Рис. 2. Классификация систем повторной идентификации.
64
который изменяется с течением времени, по мере поступления новых запи-
сей с камер наблюдения ограничительные рамки необходимо генерировать в
режиме реального времени. Полученные новые изображения требуется ан-
нотировать для обучения, т.е. формировать псевдо-метки (pseudo-label) для
возможности тренировки СНС при видеонаблюдении. Организация таких си-
стем намного сложнее, они требуют высокопроизводительной аппаратурной
части, но наиболее приближены к реальным условиям.
В зависимости от типа анализируемых видеоданных системы повторной
идентификации можно разделить на статические (image-based), которые об-
рабатывают отдельные кадры через некоторые интервалы времени, и дина-
мические (video-based), когда рассматривается последовательность кадров из
видео [3]. В динамических системах признаки формируются не только на ос-
нове анализа пространственной области, но и учитывают временную состав-
ляющую о человеке, например информацию о походке, направлении движе-
ния и другие дополнительные признаки.
В зависимости от количества запросов [4] системы реидентификации мож-
но разделить на одиночную повторную идентификацию (для одного челове-
ка) и множественную (для всех людей, попавших в поле зрения камер). В пер-
вом случае в наборе данных требуется найти человека по запросу, и повтор-
ная идентификация сводится к задаче поиска или проверке, присутствует ли
искомый человек в галерее. Во втором — для каждого человека устанавли-
вается уникальный идентификатор и определяется, на каких кадрах каждый
из этих людей встречается снова, и эта задача сводится к классификации [5].
По типу запросов системы повторной идентификации можно разделить на
однородные (single-modality) и неоднородные (cross-modality) [2]. При исполь-
зовании однородных данных в качестве запросов используются изображения
или видео, полученные с камер видеонаблюдения видимого диапазона. Если
в качестве запроса используется текстовое описание искомого человека, изоб-
ражение с инфракрасной камеры, рисунок или эскиз, то такие системы будут
называться неоднородными.
По времени работы системы выделяют краткосрочную повторную иден-
тификацию и долгосрочную [6]. Так, если каждый человек на изображениях
в наборе данных находится в одной и той же одежде, изменения внешности
незначительны и обусловлены только возможным изменением наличия аксес-
суаров или вещей в руках, съемка осуществлялась в течение ограниченного
интервала времени, за которое человек не мог значительно изменить образ,
то такая система будет краткосрочной. Долгосрочная повторная идентифи-
кация направлена на способность повторно идентифицировать людей, даже
если прошло уже значительное количество времени, за которое человек мог
изменить внешний вид [7].
Любая из рассмотренных выше систем может столкнуться с проблемой
смещения домена (domain shift), когда обучение и тестирование осуществля-
ются на данных из разных доменов. Под доменом понимают комплект изоб-
65
ражений, которые были получены в одинаковых условиях в одной системе
видеонаблюдения. На каждое изображение в наборе данных оказывает вли-
яние совокупность факторов, включающих разрешение камер, фон, условия
освещения и даже внешний вид людей, т.е. статистически европейцы будут
иметь отличный вид от азиатов, летняя одежда от зимней и т.д. Система,
обученная на наборе данных, полученном с внутренних камер видеонаблю-
дения, может иметь крайне низкую эффективность на тестовой выборке, со-
стоящей из изображений людей с наружных камер видеонаблюдения. Алго-
ритмы, направленные на решение этой проблемы, называются «междоменной
реидентификацией» (Cross-domain ReID) и реализуют задачу адаптации (или
переносимости) домена.
2.3. Метрики оценки точности
Одним из важнейших вопросов для оценки результатов повторной иденти-
фикации является выбор метрик, позволяющих дать численную оценку эф-
фективности алгоритма и сравнить результаты для разных подходов реиден-
тификации. Наиболее распространенными является группа метрик RankN,
включающая Rank1, Rank5, Rank10, и mAP. Группа метрик RankN харак-
теризует качество ранжирования и показывает процент числа запросов, для
которых верный выданный результат был среди первых N полученных ре-
зультатов. Соответственно, метрика Rank1 показывает процент запросов, для
которых идентификатор первого изображения-кандидата совпадает с иден-
тификатором запроса. Если N = 5, то Rank5 показывает процент запросов,
для которых среди первых пяти выданных изображений-кандидатов бы-
ло верное решение, соответственно для Rank10 учитываются первые десять
изображений-кандидатов. Для вычисления RankN определяется отношение
суммы числа запросов, для которых верное решение было найдено среди пер-
вых выданных результатов, к общему числу запросов Q:
∑Ki,N
(2)
RankN =
,
Q
где i — номер запроса; Ki,N — i-й запрос, для которого верное решение было
найдено среди первых N выданных результатов.
Метрика mAP является оценкой точности алгоритма повторной идентифи-
кации, отражающей среднее значение средних точностей для всех запросов,
и рассчитывается по формуле
∑
1
(3)
mAP =
APi,
Q
i=1
где AP — средняя точность, определяемая как площадь под кривой precision-
recall, где precision = TPTP+FP — точность, TP — количество верных пред-
сказаний запросов; F P — количество ложных положительных предсказаний
66
запросов; recall =TPTP+FN — чувствительность; F N — количество ложных
отрицательных предсказаний запросов.
В системах повторной идентификации приоритетно, чтобы верные пред-
сказания находились в начале ранжированного списка и имели как можно
меньше ложных предсказаний. Следует отметить, что метрики RankN и mAP
не отражают сложность поиска правильно идентифицированных изображе-
ний людей для поступающего запроса. Кроме этого, при одинаковых показа-
телях Rank точность AP может отличаться. Для учета поиска наиболее слож-
ных правильных предсказаний в [8] используется метрика mINP (mean Inverse
Negative Penalty), предложенная в [2], которая позволяет исключить домини-
рование легких совпадений, влияющих на метрики Rank и mAP. Для ее вы-
числения вводятся дополнительные метрики: NP (Negative Penalty) — отри-
цательный штраф, назначаемый за неверные предсказания для i-го запроса и
уменьшающий вероятность правильной реидентификации при неправильном
нахождении самого сложного совпадения; INP (Inverse Negative Penalty) —
обратная величина для NP, рост которой свидетельствует о повышении эф-
фективности системы. При этом mINP характеризует среднее значение INP
для всех запросов и вычисляется как
(
)
∑
1
1∑
Rhardi - |Gi|
1∑
|Gi|
(4)
mINP =
(1 - NPi) =
1-
=
,
Q
Q
Rhardi
Q
Rhard
i
i
i
i
где NPi =Riard-|Gi|
— отрицательный штраф; Rhardi — позиция самого слож-
Rhard
i
ного верного предсказания; |Gi| — общее количество верных предсказаний
для запроса.
На рис. 3 показан пример, когда в галерее для каждого запроса есть толь-
ко три верных изображения (True). В первых двух ранжированных списках
на рис. 3 при одинаковом значении Rank1 метрики AP различны: AP1 = 0,77
(см. рис. 3,a), AP2 = 0,63 (см. рис. 3,б ). Это связано с тем, что в начале пер-
вого ранжированного списка имеются два верных совпадения, а во втором —
только одно. При этом ближайшее верное совпадение занимает пятую пози-
цию. Если сравнивать списки на рис. 3,б и 3,в, то очевидно, что в третьем
ранжированном списке AP3 = 0,64, т.е. больше, чем во втором, но при этом
Rank1 в этом примере равен нулю. Это так же объясняется тем, что все воз-
можные правильные ответы были получены вверху ранжированной таблицы
(на второй, третьей и четвертой позиции), за исключением первого, неверно-
го, предсказания. Предпочтительнее, чтобы все верно идентифицированные
изображения людей были получены как можно раньше, однако при оценке
системы метрики AP и Rank не позволяют это определить с максимальной
точностью.
Анализ рис. 3,в показывает, чтобы иметь все возможные верные ответы,
необходимо получить только четыре первых изображения-кандидата, и со-
ответственно отрицательный штраф будет равен NP = 0,25, который мини-
мальный для примеров на рис. 3. На рис. 3,б самое сложное предсказание
67
Рис. 3. Различие в метриках Rank, AP, NP и INP в зависимости от позиции
истинных и ложных предсказаний.
соответствует шестой позиции в ранжированной таблице, на рис. 3,а непра-
вильное обнаружение человека характерно для девятой позиции. Поэтому
для примеров на рис. 3,а и 3,б увеличиваются значения NP, соответственно
уменьшается INP. Таким образом, метрика INP позволяет оценить влияние
сложности поиска всех верных совпадений. Чем больше это значение, тем
лучше система выполняет поиск всех людей с одинаковым идентификато-
ром. Соответственно следует стремиться к снижению NP и уменьшать число
позиций от начала списка ранжирования до самого сложного, который может
быть неправильно идентифицирован при поиске изображения.
3. Наборы и подготовка данных для обучения СНС
Использование СНС для извлечения признаков приводит к необхо-
димости обучения используемой модели глубокой нейронной сети. Для
этой цели обычно применяется аннотированный набор данных, который
содержит уникальный идентификатор для каждого отдельного человека
S = {(Ii,pID1),...,(Im,pIDn )}, где Ii — изображение, 1 ≤ i ≤ m, m — количество
изображений, pIDn — идентификатор человека. Часто изображения сопровож-
68
даются информацией о номере камеры, с которой они были получены, номере
кадра в видеопоследовательности. В аннотированном наборе данных для эф-
фективной работы системы необходимо извлекать такой вектор признаков
fgen(Ii) чтобы во всем пространстве признаков χIi расстояние между ними
для одинаковых идентификаторов было меньше, чем для людей с разны-
ми метками, т.е. следует стремиться к уменьшению ошибки E предсказания
идентичности в S
(5)
min E(Ii, pIDn) ∈ [pIDn - g(fgen(Ii
))],
где g — классификатор. Качество извлеченных признаков зависит от распре-
деления и разнообразия данных в S [9].
При тренировке СНС для улучшения точности повторной идентификации
рекомендуется подобирать наиболее оптимальные гиперпараметры, такие как
скорость обучения, размер пакета, количество эпох; использовать увеличе-
ние обучающей выборки, аугментацию данных, найти наиболее эффектив-
ную функцию потерь, архитектуру СНС или рассматривать изображение не
целиком, а разделяя его на фрагменты.
Для уже обученной модели улучшение работы алгоритма можно достиг-
нуть, подбирая наиболее эффективный способ ранжирования таблицы при-
знаков, использовать повторное ранжирование, учитывать дополнительную
информацию о времени и месте съемки, атрибутах. Под атрибутами пони-
мают семантическую информацию о человеке, имеющую значение для его
идентификации. К ним относятся цвет и вид одежды, длина волос человека,
наличие и особенности сумки, рюкзака, очков и других значимых деталей.
3.1. Анализ наборов данных
На точность повторной идентификации существенное влияние оказывают
размер и состав обучающей выборки. Однако алгоритм для реидентифика-
ции в значительной мере определяет требования к набору данных. Форми-
рование банка изображений для обучения и тестирования представлят тру-
доемкий и длительный процесс. Кроме этого существует проблема сдвига
домена [10, 11], когда наблюдается значительное снижение точности повтор-
ной идентификации при использовании системы в условиях, стилистически
отличающихся от обучающей выборки. Частичным решением проблемы яв-
ляется объединение разных наборов данных, что рассматривается в [12, 13],
в том числе и для необходимого домена [12, 14].
При использовании существующих наборов данных для обучения СНС,
кроме проблемы сдвига домена, приходится сталкиваться с проблемой за-
щиты персональных данных. Некоторые базы изображений являются закры-
тыми, в них авторы предоставляют для исследований только извлеченные
признаки [15]. Другие наборы данных можно использовать с ограничения-
ми [16-18], т.е. при публикации исследований авторы просят соблюдать кон-
фиденциальность студентов, изображения которых использовались при со-
69
здании, и распространение этих баз изображений возможно только при со-
гласовании с авторами. Для некоторых наборов данных ограничивается воз-
можность их использования. Например, MSMT17 [19] в настоящее время не
доступен в публичном доступе, а DukeMTMC-ReID [20] был отозван и его
использование не рекомендуется [21].
Существующие наборы изображений отличаются количеством сцен съем-
ки и разных людей, а также числом изображений для каждого отдельного
человека. Такие базы данных могут содержать отдельные кадры целиком,
например PRW [22] и CUHK-SYSU [23], или вырезанные с этих кадров прямо-
угольные фрагменты на основе ограничительных рамок, содержащие только
изображение человека. В некоторых наборах данных включены комплекты
ограничительных рамок, полученных с нескольких последовательно идущих
кадров, которые называются треклетами (tracklets), например MARS [24],
LPW [25]. Также могут содержаться ограничительные рамки, полученные с
отдельных кадров, взятых с некоторым интервалом по времени, например
Market-1501 [26], CUHN01 [16], CUHN02 [17], CUHN03 [18], VIPer [27] и др.
Изображения для наборов данных, как правило, получены при различ-
ных условиях съемки вне помещений (Market-1501 [26], LPW [25], PRID [28])
или в помещениях (QMUL iLIDS [29], Airport [30]). При формировании базы
изображений PolReID [31] использовалось 856 сцен сьемки внутреннего и на-
ружного наблюдения. В наборе данных CUHN01 изображения для каждого
человека получены с двух камер, области обзора которых не пересекаются.
В CUHN02 используется пять таких пар видеокамер, а в CUHN03 изображе-
ния формируются с шести видеокамер, но для каждого человека предостав-
ляются ограничительные рамки только с двух. Набор данных VIPeR был
сформирован на основе изображений, полученных с двух видеокамер наруж-
ного видеонаблюдения, и для каждого человека представлено всего по одному
изображению с каждой из них. При формировании LPW использовалось три
разных локации, и на первой локации было установлено три видеокамеры, на
двух других по четыре. Наборы данных PRW, Market-1501 и MARS были по-
лучены в одном и том же месте возле супермаркета в университете Циньхуа
с шести видеокамер и отличаются только способом представления данных:
кадры целиком, ограничительные рамки с изображением человека, треклеты
соответственно.
Для обучения и тестирования неоднородных систем повторной идентифи-
кации применяются специальные наборы данных, использующие в качестве
запроса текст (CUHK-PEDES [32], ICFG-PEDES [33]), изображение низко-
го разрешения (LR-PRID [34], LR-VIPeR [35]), изображение с инфракрасной
камеры (SYSU-MM01 [36], RegDB [37]) или эскиз (PKU-Sketch [38]).
Набор данных CUHK-PEDES [32] объединяет пять существующих, таких
как CUHK03 [18], Market-1501 [26], SSM [39], VIPeR [27] и CUHK01 [16], и
каждое изображение аннотируется двумя текстовыми описаниями на англий-
ском языке. Текстовое описание состоит в среднем из 23,5 слов и содержит
70
информацию о внешнем виде человека, его действиях, позах. Другим набо-
ром данных для неоднородных систем повторной идентификации является
ICFG-PEDES [33], который содержит в среднем 37,2 слов с более детальным
описанием внешности, чем CUHK-PEDES, и сформирован на основе MSMT17
[19].
Наборы данных LR-PRID [34], LR-VIPeR [35] получены с использовани-
ем PRID [28] и VIPeR [27] соответственно, и для каждого человека имеется
пара изображений, одно из которых с низким разрешением, а другое с боль-
шим, что позволяет их применять для систем повторной идентификации с
видеокамерами разного разрешения.
SYSU-MM01 [36] был получен с двух инфракрасных и четырех RGB-
камер, состоит из 15 712 инфракрасных изображений и 22 559 цветных для
491 человека. Набор RegDB [37] содержит по 10 цветных изображений, сня-
тых днем, и 10 тепловых изображений с ночной ИК-камеры для 412 человек,
что определяет возможность их использования в неоднородных системах по-
вторной идентификации c инфракрасными и RGB-видеокамерами.
В [38] предлагается набор данных для двухсот человек, включающий по
два изображения с разных камер и эскиз для каждого. Для создания эскизов
были привлечены волонтеры, которые описывали внешность людей пяти раз-
ным художникам для обучения открытой (open-world) неоднородной (cross-
modality) системы повторной идентификации. В случае отсутствия фотогра-
фии человека используется эскиз, нарисованный по описанию.
Еще одним набором данных для открытых (open-world) систем повторной
идентификации является MPR Drone [40], который отличается тем, что для
получения изображений используется одна видеокамера летающего дрона.
Весь набор состоит из двух частей, первая часть размечена для 113 610 обна-
руженных ограничительных рамок, а вторая содержит необработанные кад-
ры для первой части.
В [41] представлен большой немаркированный набор данных LUPerson, ко-
торый включает более четырех миллионов изображений для двухсот тысяч
человек и может использоваться для неконтролируемого обучения систем по-
вторной идентификации. Он сформирован с использованием видеоданных с
более чем семидесяти тысяч уличных видео из различных городов.
В табл. 1 приведены сравнительные характеристики рассмотренных набо-
ров данных.
В связи с тем, что при создании набора данных необходимо явное со-
гласие всех участников, некоторые исследователи для формирования обу-
чающей выборки применяют сгенерированные изображения. В [42] предла-
гается синтетический набор данных для повторной идентификации людей
MOTSynth, для создания которого использовались видеопоследовательности
из игры Grand Theft Auto V (GTA-V), имитирующей город с жителями в
трехмерном пространстве. Авторы вручную разметили точки обзора камеры,
спланировали маршруты и перемещения пешеходов, установили параметры,
71
Таблица 1. Сравнительная таблица наборов данных для повторной идентифика-
ции
Количество
Количество
Количество
Размер
Набор данных
ограничительных
камер
человек
изображения
рамок
PRW [22]
6
932
34304
Различный
CUHK-SYSU [23]
6
8432
96143
-
MARS [24]
6
1261
1 191003
256×128
LPW [25]
3, 4, 4
2731
592438
256×128
Market-1501 [26]
6
1501
32217
128×64
CUHN01 [16]
2
971
3884
160×60
CUHN02 [17]
10 (5 пар)
1816
7264
160×60
CUHN03 [18]
6
1360
13164
Различный
MSMT17 [19]
15
4101
126441
Различный
VIPeR [27]
2
632
1264
128×48
PRID [28]
2
934
24541
128×64
QMUL iLIDS [29]
2
119
476
Различный
Airport [30]
6
9651
39902
128×64
PolReID [31]
856
657
52035
Различный
CUHK-PEDES [32]
-
13003
80412
-
ICFG-PEDES [33]
-
4102
52522
-
LR-PRID [34]
2
100
200
-
128×48 и
LR-VIPeR [35]
2
632
1264
64×24
SYSU-MM01 [36]
6
491
38271
-
RegDB [37]
2
412
8240
-
PKU-Sketch [38]
2
200
400
-
связанные с поведением людей, характерным для людных мест. Анализиро-
валось 597 различных моделей пешеходов, для которых случайным образом
менялась одежда, рюкзаки, сумки, маски, прически и бороды. Это позволило
получить более 9519 уникальных пешеходов. Приведенные авторами резуль-
таты показывают, что обучение на синтетическом наборе позволяет повысить
точность реидентификации на 6,9 % в метрике mAP по сравнению с использо-
ванием для обучения Market-1501 [26] и на 2,5% в метрике mAP при обучении
на объединенном наборе данных из Market-1501[26] и CUHK03 [18].
В [9] рассматривается алгоритм генерации синтетических изображений
для повышения устойчивости системы к смене домена. Для создания трех-
мерных реалистичных изображений людей применяется MakeHuman [43],
а для моделирования видеонаблюдения платформа — Unreal Engine 4 (UE4)
[44] с возможностью регулирования условий съемки (ночная, в помещении, на
72
улице), количества окклюзий людей, скорости ходьбы. Используется большое
число деталей внешности, таких как маски, очки, наушники, головные убо-
ры. На полученных изображениях людей присутствуют реальные фрагменты
одежды, что отличает данный подход от существующих. При генерации наме-
ренно добавляются люди с похожей внешностью и небольшими отличитель-
ными особенностями. Представлены результаты исследования в [9], которые
показывают, что применение данного набора позволяет получить большую
точность Rank1 при междоменном тестировании с использованием MSMT17,
по сравнению с применением других синтетических баз изображений, таких
как SOMAset [45], SyRI [46], PersonX [47], RandPerson [48]. Результаты под-
тверждаются при тестировании на Market-1501 и DukeMTMC-ReID.
В [49] предлагается синтетический набор данных ClonedPerson, содержа-
щий 3D-изображения людей, при этом одежда всех сгенерированных персо-
нажей клонируется с реальных изображений, что позволяет усилить сход-
ство между виртуальным человеком и его прототипом. Всего набор данных
включает 887 766 изображений для 5621 человека. Для генерации изобра-
жений использовалась платформа Unity3D [50], как и для RandPerson [48].
Полученный таким образом набор данных используется для обучения СНС
и позволяет достигнуть лучших результатов при тестировании на изображе-
ниях из другого домена в метрике mAP на CUHK03[18], Market-1501 [26],
MSMT17 [19] по сравнению с применением для обучения RandPerson [48] и
UnrealPerson [9]. Следует отметить, что существенным преимуществом син-
тетических наборов данных является автоматическая генерация аннотаций.
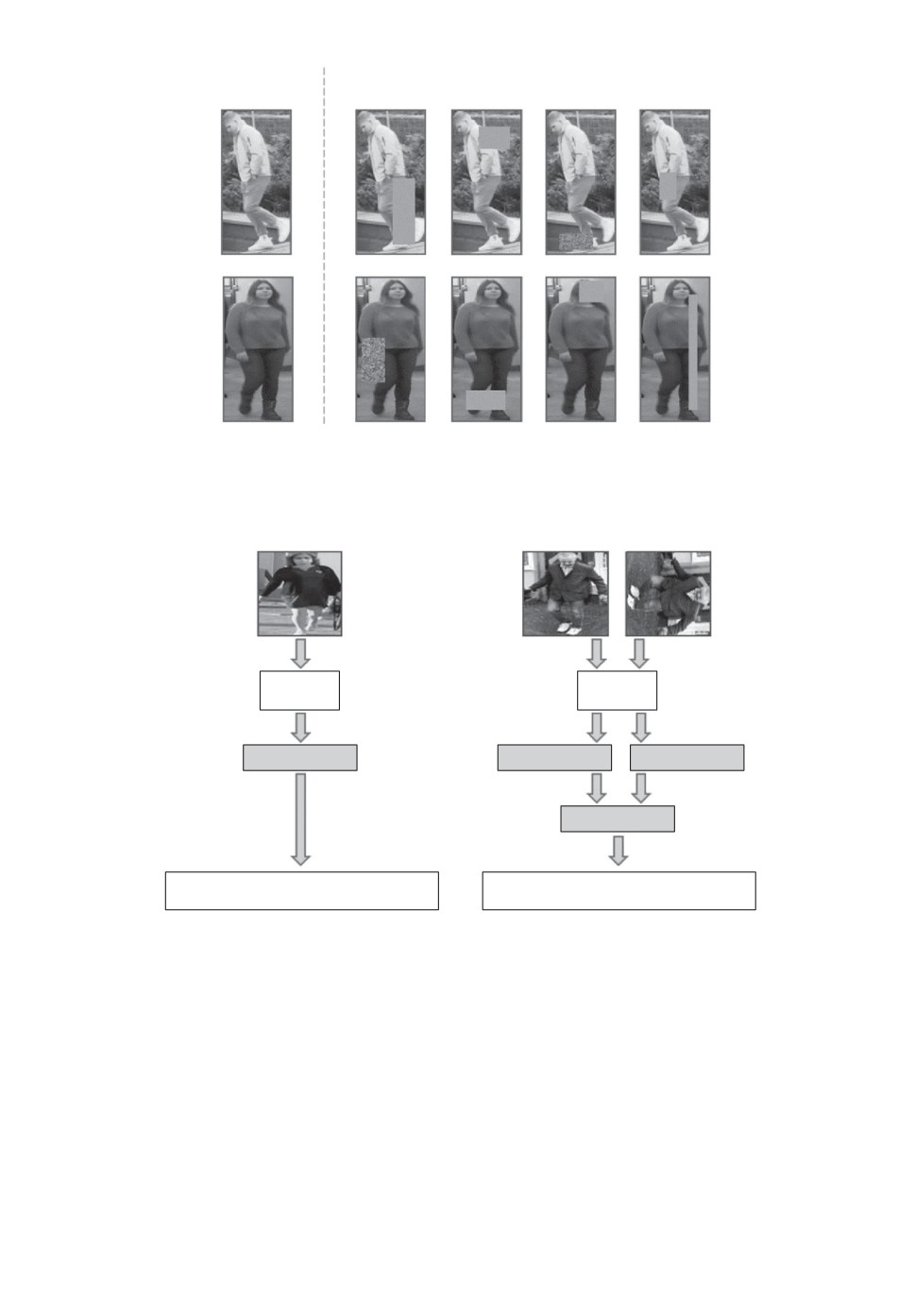
3.2. Аугментация обучающей выборки
Увеличение объема обучающей выборки за счет модификации имеющих-
ся в ней изображений называют аугментацией. Традиционными подходами
для этого являются различные преобразования изображений, такие как по-
ворот, отражение, изменение размера, контраста, яркости, вариации цвето-
вой составляющей, размытие. Для повышения устойчивости к окклюзиям
применяется метод «случайного стирания» [51]. При этом прямоугольный
фрагмент изображения, размер и форма которого выбирается произвольным
образом, заполняется нулевыми или случайными значениями (рис. 4). Тести-
рование данного метода аугментации для реидентификации осуществлялось
на наборах Market-1501, DukeMTMC-ReID и CUHK03. Результаты исследо-
ваний показали, что в некоторых случаях, например при тестировании на
CUHK03, такой способ позволяет повысить точность почти на 9% в метрике
Rank1 и более чем на 6% в метрике mAP. При использовании Market-1501 и
DukeMTMC-ReID для разных алгоритмов точность в метриках Rank1 и mAP
была увеличена на 1-4%.
Следует отметить, что в алгоритмах повторной идентификации аугмен-
тация данных используется для увеличения обучающей выборки путем слу-
чайного выбора изображения для какого-либо преобразования, но механизм
этого влияния не рассматривается, т.е. как факт принимается то, что это
73
Входное
изображение
“Cлучайное стирание”
Рис. 4. Примеры применения стирания фрагмента изображения для аугмен-
тации данных.
a
б
CНС
CНС
global
f global
f2
f2global
f gen
Классификационная модель
Классификационная модель
Рис. 5. Принцип извлечения признаков: а - базовый, б - с учетом поворота
изображений [52].
позитивно влияет на точность работы обученной модели за счет улучшения
обобщающей способности сети. В [52] используются повороты для увеличения
количества изображений, но при этом тренировка СНС осуществляется одно-
временно как для исходного изображения, так и для преобразованных, и оце-
ниваются потери, возникающие при повороте, что позволяет минимизировать
среднеквадратичную ошибку между векторами признаков для соответствую-
щей пары изображений. На рис. 5 представлено сравнение базового алгорит-
ма аугментации данных при обучении извлечению признаков и предложенно-
74
го в [52]. Базовый алгоритм предполагает, что используется один поворот для
случайного образца за один проход по сети при обучении, а рассмотренный
в [52] прдполагает, что каждое изображение поворачивается на случайный
угол и подается на вход сети одновременно с исходным. С помощью СНС
из пары изображений извлекаются признаки, которые затем усредняются.
При сравнении с другими алгоритмами повторной идентификации предло-
женный позволил повысить точность в метрике mAP: более чем на 5% для
Market-1501, более 10% для DukeMTMC-reID и более 20% для MSMT-17 по
сравнению с базовым алгоритмом (рис. 5,а). При этом для MSMT-17 достиг-
нуто максимальное значение точности повторной идентификации в метриках
mAP = 81,3 и Rank1 = 87,5 на момент публикации работы [52]. В [53] пред-
ложен алгоритм, повышающий значения метрик mAP = 84,4 и Rank1 = 89,9
для набора данных MSMT-17.
Более сложным методом аугментации данных является применение
генеративно-состязательных сетей (Generative Adversarial network — GAN),
которые используются для генерации изображений, близких к естественным,
на основе уже имеющихся данных. Генеративно-состязательная сеть пред-
ставляет собой алгоритм машинного обучения, в основе которого лежит ком-
бинация двух нейронных сетей. Одна из них генерирует изображения, а дру-
гая пытается определить, могут ли они быть онесены к подлинным. Приме-
нительно к реидентификации использование GAN может быть направлено
на улучшение способности извлечения эффективных признаков [54] или на
решение задач со смещением доменов [55].
В [54] рассматривается проблема, характерная для повторной идентифика-
ции в реальных условиях, когда возможно присутствие различных факторов,
ухудшающих качество изображений, полученных с камер видеонаблюдения.
Например, если в момент наблюдения идет дождь, то система, обученная на
данных, полученных при других условиях, не сможет с высокой точностью
интерпретировать извлеченные дескрипторы. В подобных случаях существу-
ет высокая вероятность того, что большое число сформированных признаков
будет учитывать сходства не людей, а факторов, ухудшающих качество изоб-
ражения. Для решения этой проблемы необходимо изучить признаки различ-
ных явлений, снижающих качество изображений. Однако в реальных усло-
виях сложно получить аннотации для описания подобных возмущающих воз-
действий, а в обучающей выборке может не быть эталонных примеров. Для
извлечения робастных к ухудшающим факторам изображений признаков ав-
торы используют GAN для синтезирования изображений с заранее известной
степенью искажения.
В [55] GAN применяется для аугментации данных, однако в отличие от
аналогичных систем авторы предлагают добавлять в обучающую выборку
не все сгенерированные изображения, а только те, которые позволяют по-
высить точность повторной идентификации. Для этого отбрасываются изоб-
ражения, которые имеют схожие признаки с ранее полученными, так как
они могут снижать качество обучения, увеличивать время и при этом при-
75
водить к разбалансировке при обобщении. В этом случае система будет счи-
тать, что признаки, выделенные для схожих изображений, имеют большее
значение, чем те, примеров которых было недостаточно. Для решения этой
проблемы используется метод Local Outlier Factor (LOF), который контроли-
рует количество схожих сгенерированных изображений и в случае, если их
число возрастает, часть из них случайным образом отбрасывает. Такой под-
ход позволяет не только повысить точность повторной идентификации, но
и значительно улучшить устойчивость системы к смещению домена. В [55]
приводятся результаты сравнения с другими алгоритмами, направленными
на решение проблемы смещения домена, и в рейтинге точности в метриках
Rank1, Rank5 и mAP предложенный в [55] подход занимает первые и вторые
позиции для разных наборов данных среди современных подходов.
В [56] рассматривается подход, направленный на генерацию дополнитель-
ных изображений людей, когда в системе видеонаблюдения количество изоб-
ражений с одной камеры больше, чем с другой, или вид с другой камеры для
определенного человека отсутствует. Этот подход применяется для повыше-
ния робастности алгоритмов, если необходимы пары изображений одного и
того же человека с разных камер. Однако такие образцы генерируются не
в виде изображений, а в пространстве признаков. Это обусловлено тем, что
при генерации изображений требуются значительно большие вычислитель-
ные затраты генеративной модели на качественное формирование фона и
освещенности. Однако это не всегда оказывает положительное влияние на
модель повторной идентификации, тогда как генерация только признаков не
учитывает особенностей всего изображения снимаемой сцены.
4. Анализ используемых признаков
Для повторной идентификации с помощью СНС используются: глобаль-
ные признаки (рис. 6,а), т.е. формируемые для всего изображения челове-
ка в целом; локальные, когда изображение разделяется на отдельные фраг-
менты (рис. 6,б ); ключевые точки (рис. 6,в), предполагающие для каждого
участка изображения отдельный вектор признаков; дополнительные призна-
ки (рис. 6,г), к которым можно отнести вспомогательные аннотации, инфор-
мацию о времени и месте съемки, атрибуты; признаки человека из последо-
вательности кадров (рис. 6,д).
4.1. Глобальные признаки
При повторной идентификации людей использование глобальных призна-
ков является базовым подходом, и они применяются совместно с локальными
[3] или дополнительными [57] для повышения точности повторной идентифи-
кации или в алгоритмах, в которых увеличение эффективности реидентифи-
кации достигается за счет их получения [58] или обработки [52].
При использовании глобальных признаков система повторной идентифи-
кации может оказаться недостаточно устойчивой к окклюзиям из-за того,
76
a
б
f local1
f local2
СНС
СНС
f local3
f local4
f local
5
f local6
в
г
д
Женщина,
f odd
короткие волосы,
в маске
f local
1
f local2
СНС
СНС
СНС
f local3
f local4
f local5
f local6
f local
7
Рис. 6. Стратегии изучения и использования признаков.
что в сформированном векторе признаков для скрытого изображения часть
дескрипторов будет характеризовать не внешность человека, а предмет, его
перекрывающий. Кроме того, при таком подходе могут «теряться» призна-
ки мелких отличительных деталей внешности, например таких, как очки,
фурнитура одежды или сумки, которые могли бы служить характерным от-
личием при принятии решения о принадлежности обнаруженного человека к
запросу.
4.2. Локальные признаки
Для снижения влияния недостатков глобальных признаков применяются
локальные, которые могут рассматриваться как самостоятельно, так и в сово-
купности с глобальными. Например, в [59] предлагается горизонтальное раз-
деление изображения на шесть равных частей и изучение каждой части в от-
дельности. Такой подход получил название Part-based Convolutional Baseline
(PCB) и является надстройкой над СНС, при этом осуществляется разделе-
ние на части выходных данных первого сверточного слоя. Он позволяет повы-
сить точность повторной идентификации на 1-2% в метриках Rank1 и mAP.
Недостатком является требование к расположению и содержимому каждой
части: человек должен находиться в строго вертикальном положении и фраг-
менты изображения должны располагаться в «правильных» местах. Ошибки
обнаружения, когда часть человека оказывается обрезана ограничительной
рамкой, могут приводить к ошибкам идентификации.
77
В [60] проводилось исследование по оценке влияния количества фрагмен-
тов, на которые разделяется изображение, на точность повторной идентифи-
кации. Изображение разбивалось на два, три, четыре, шесть, восемь и двена-
дцать фрагментов, и лучший результат точности повторной идентификации
в метриках Rank1 и mAP был получен при делении изображения на шесть
частей.
В [61] представлен алгоритм для реидентификации, основанный на рас-
смотрении ключевых частей тела человека. Так, с помощью HR-Net [62] из-
влекаются ключевые точки, а затем исследуются признаки в окрестностях
каждой из них. Данный подход направлен на уменьшение влияния окклюзий.
Поэтому при сопоставлении векторов признаков не учитываются дескрипто-
ры ключевых точек, которые оказались скрыты.
В [63] рассматривается алгоритм, требующий разделения изображения
фигуры человека на 6 горизонтальных частей, при этом сеть пытается пред-
сказать, есть ли на каждой из них видимая часть фигуры человека. При
положительном решении сети с помощью оценщика поз AlphaPose [64] опре-
деляются ключевые точки человека и при предсказании, является ли обна-
руженный человек искомым, признаки невидимых частей не учитываются.
Это позволяет повысить точность повторной идентификации человека и уве-
личить устойчивость системы к окклюзиям.
4.3. Дополнительные признаки
Еще одним подходом увеличения точности повторной идентификации яв-
ляется использование дополнительной информации, которая предоставляет-
ся с набором данных в виде аннотаций. Использование такого подхода пред-
лагается в [57], при этом с помощью СНС (DenseNet-121, ResNet-50 или PCB)
извлекаются визуальные признаки объектов, а номер камеры и номер кадра
содержатся в названиях самих файлов. После ранжирования таблицы ви-
зуальных признаков из нее удаляются дескрипторы изображений, которые
нерелевантны по пространственно-временным характеристикам людей, т.е.
для тех, которые физически не могли находиться в определенном месте или
в определенный час.
В большинстве случаев в алгоритмах повторной идентификации неоче-
видны типы признаков, используемых при принятии решения о сходстве или
различии запроса и изображений людей в галерее. В [65] проводится ис-
следование и предлагается подход, позволяющий определить и визуализиро-
вать признаки, которые система рассматривала при принятии решения, ка-
кие именно из них были значимыми и какой вклад вносит каждый атрибут.
Для этого разработан метод, получивший название AMD (Attributeguided
Metric Distillation), который представляет собой интерпретатор, подключае-
мый к целевой модели для оценки вклада каждого атрибута и визуализа-
ции наиболее значимых деталей. Интерпретатор учится разделять расстоя-
ние между признаками различных людей на основе атрибутов, и вводится
78
функция потерь, которая позволяет сосредоточиться на характерных отличи-
ях. Эксперименты авторов показывают, что предоставляется возможность не
только визуализировать значимые признаки, но и дополнительно улучшить
точность повторной идентификации в целевых моделях. Представлены в дан-
ной работе также результаты исследования, показывающие улучшение точно-
сти повторной идентификации при тестировании алгоритма на междоменных
данных.
В [66] предлагается повышение устойчивости систем реидентификации
к смещению домена. Как правило, для таких систем предполагается, что
есть исходный домен (sourse domain), используемый для обучения, и целевой
(target domain), на котором осуществляется тестирование. При этом считает-
ся, что они изолированы между собой. В [66] применяются промежуточные
домены в качестве дополнительной информации, которые позволят умень-
шить различие между исходной и целевой областями. На вход базовой СНС
подаются изображения как целевого, так и исходного домена, на их осно-
ве формируются дескрипторы, которые затем объединяются с различными
соотношениями смешивания для получения вектора признаков промежуточ-
ного домена. Для этого применяется технология, предложенная в [67]. При
объединении дескрипторов изображений из разных доменов возникает такой
побочный эффект, как смешение признаков изображений разных людей и ге-
нерации изображения нового человека. Это может привести к тому, что в
процессе обучения сеть сосредоточится на человеке со смешанными дескрип-
торами, вместо того чтобы учитывать разнообразие стилей в разных доме-
нах. Для компенсации этого явления применяется дополнительный модуль,
использующий подход к переносу стилей AdaIN [68], который позволяет полу-
чить дескрипторы одного и того же человека с учетом особенностей целевого
или исходного домена. Сгенерированные признаки промежуточных доменов
используются для обучения СНС и уменьшают расстояние между извлечен-
ными дескрипторами из исходного и целевого доменов.
В [69] для решения таких проблем при повторной идентификации, как из-
менение освещения, окклюзии, фоновые помехи и возможная смена внешнего
вида, предлагается использование технологии Wi-Fi, что позволяет подсчи-
тывать и определять локализацию людей. Процедура обнаружения человека
использует вариации Wi-Fi сигналов, которые могут информировать о при-
сутствии человека и их можно отслеживать с помощью информации о состоя-
нии канала (channel state information (CSI)) точек доступа. Из Wi-Fi сигна-
ла извлекаются значимые признаки, на основе которых формируется радио-
биометрическая подпись, используемая для реидентификации человека.
В [70] в качестве дополнительной информации, позволяющей повысить
точность повторной идентификации в невидимых доменах, предлагается
использовать «обучение распределению меток» (Label distribution learning
(LDL)). Для обучения СНС используется несколько наборов данных, а сам
процесс направлен на поиск взаимосвязи между изображениями разных лю-
дей. Каждый человек рассматривается как отдельный класс, и поиск соот-
79
ветствий между различными классами из разных наборов данных позволяет
извлекать признаки, инвариантные к домену. Особое внимание уделяется по-
хожим людям из разных доменов, что позволяет сформировать дескриптор,
характеризующий внешность человека, а не условия видеонаблюдения. Для
уменьшения разрыва между данными из разных доменов метки (идентифи-
каторы) изображений для обучения распределяются таким образом, чтобы
больше внимания уделять не самому домену, к которому принадлежит класс,
а междоменным связям.
В [71] в качестве дополнительных признаков используется информация о
ракурсе человека и при повторной идентификации учитываются признаки,
связанные с углом обзора. С помощью СНС определяется один из трех рас-
сматриваемых ракурсов, таких как вид спереди, сбоку и сзади, что позволяет
улучшить устойчивость системы к смене доменов.
4.4. Признаки, использующие временные особенности
Алгоритмы повторной идентификации по последовательности кадров
(video-based) используют преимущества временной составляющей, которой
обладает видеоряд, в отличие от анализа отдельных кадров [60]. В [3] пред-
лагается алгоритм, объединяющий как глобальные, так и локальные призна-
ки на изображении человека для повышения точности повторной идентифи-
кации на видео. На разных уровнях пирамиды, представленной на рис. 7,
изображение разделяется вертикальными или горизонтальными линиями и
для каждого фрагмента изображения извлекается вектор признаков. Общий
вектор признаков для каждого i-го человека в [9] определяется как
[
]
(6)
fgeni = fglobali;flocal-verticali,v;flocal-hotizontali,h;flocal-patch
,
i,patch
где v, h, patch — количество частей, на которые разделяется изображение на
каждом уровне пирамиды.
СНС
f global
СНСlocal_vertical
f1...3
СНСlocal_horizontal
f1...6
СНС
local_patch
f1.
..18
Рис. 7. Извлечение глобальных и локальных признаков на основе разделения
изображения и многоуровневой пирамиды.
80
Для последовательности из K кадров видео вектор признаков для каждого
человека описывается выражением
[
]
∑
∑
∑
∑
(7)
fgeni =
fglobali,k;
flocal-verticali,v,k;
flocal-hotizontali,h,k;
flocal-patch
i,patch,k
k=1
k=1
k=1
k=1
В [72] предлагается извлекать информацию о походке для силуэтов людей
с использованием метода вычитания фона. Несмотря на то что цветные изоб-
ражения содержат больше информации, чем образ фигуры человека, анализ
силуэта позволяет сосредоточиться на определении особенностей, характер-
ных для разных людей при движении. На первом этапе в [72] из видео уда-
ляются фон и яркостно-цветовые отличия человека, в результате выделяет-
ся образ его фигуры. После вычитания фона генерируются ограничительные
рамки для всех людей на каждом пятом кадре видео, а для расчета остальных
ограничительных рамок используется линейная интерполяция. Извлеченные
силуэты нормализуются по аналогии с методом, предложенным в [73], и на
первом этапе рассматривается верхняя и нижняя часть фигуры, а затем ана-
лизируется совокупная сумма пикселей по оси X относительно центра это-
го объекта. После этого все изображения приводятся к единому размеру с
сохранением соотношения сторон, но с высотой 224 пикселя. Согласно [72]
для реидентификации по походке необходимо сформировать изображение
(Gait Energy Images (GEI)), отражающее характерные особенности человека
при ходьбе на основе анализа последовательности кадров. Для формирова-
ния GEI определяетcя траектория движения с использованием центральных
координат ограничительных рамок. Полученная криволинейная траектория
движения человека с помощью алгоритма кусочной регрессии разделяется на
несколько прямолинейных участков. Для каждого такого участка к соответ-
ствующей последовательности кадров применяется алгоритм кластеризации
k-средних, и формируется GEI.
В [74] рассматривается подход для повторной идентификации на видео,
в котором к определенным последовательным кадрам применяется операция
3D свертки, объединяющая визуальную и временную составляющую, что поз-
воляет учитывать изменения внешности в процессе движения. Кроме этого,
используется специальная архитектура сети SSN для извлечения признаков
отдельных частей тела и разделения дескрипторов на группы с учетом дви-
гающихся и статических частей тела на видео.
В [75] предлагается выделять наиболее эффективные пространствен-
но-временные признаки на основе анализа глобальных и локальных декрип-
торов для видеопоследовательности. Для построения глобальных признаков
используется модуль Relation-Based Global Feature Learning Module (RGL),
с помощью которого формируются карты корреляций дескрипторов между
кадрами для поиска наиболее важных, а для синтеза локальных применяется
модуль Relation-Based Partial Feature Learning Module (RPL), который позво-
81
ляет определить взаимосвязь между признаками одного и того же фрагмента
на разных кадрах.
В [76] для более эффективного использования временной информации
в видео предлагается подход, который включает два модуля. Первый Key
Frame Screening with Index (KFSI) предполагает поиск похожих кадров и вы-
бор из них для обучения СНС наиболее информативных для реидентифи-
кации. Второй модуль Feature Reorganization Based on Inter-Frame Relation
(FRBIFR) предназначен для выявления наиболее значимых признаков лю-
дей на основе анализа их расположения на последовательности кадров, что
позволяет уменьшить влияние шумовых факторов, например, перекрытий
изображений людей.
4.5. Признаки ключевых областей
Для повышения устойчивости к влиянию помех фона и изменению при-
знаков объекта при движении ряд исследователей предлагают выполнять по-
иск и выделение областей с использованием модулей (моделей, механизмов)
внимания (attention module, attention model, attention mechanisms) [77]. В [78]
для этого применяются локальный и глобальный анализы и предлагается мо-
дуль RGA (Relation aware global attention), который охватывает структурную
информацию всего изображения и изучает фрагментарные отличительные
особенности. Нахождение ключевых областей позволяет определить место-
положение значимых отличительных признаков. Для их поиска выполняется
попарное сравнение каждого дескриптора со всеми остальными и вычислен-
ный результат включается в общий вектор признаков, позволяет учитывать
взаимосвязть глобальных и локальных отличий изображений людей.
Механизм внимания используется во временной области [79], в [60, 80]
анализируется пространственно-временная, может применяться в простран-
ственно-локальной [81], и направлен на оценку позы человека и предсказание
видимых частей. В [82] предлагается механизм самовнимания (self-attention)
для повышения обобщающей возможности СНС путем учета взаимосвязи
признаков.
Пирамидальный модуль для извлечения признаков с применением муль-
тивнимания (pyramid multi-part features with multi-attention) (PMP-MA) рас-
смотрен в [60]. Полученные таким путем признаки позволяют учитывать важ-
ные отличительные особенности с различной степенью детализации. В [60] по-
казана точность Rank5 = 99,3% на наборах данных iLIDS-vid и DukeMTMC-
VideoReID, а для PRID Rank5 = 100%.
В [83] предлагается добавлять модули внимания между блоками ResNet
для улучшения возможности извлечения признаков из кадров видеоряда. При
прохождении изображения по СНС, часть важной информации может быть
утеряна, но при этом сформированный вектор признаков будет содержать
избыточную информацию для реидентификации. Поэтому в [83] предлагает-
ся встраивать модули пространственного внимания на разных уровнях сети
82
ResNet. Выходные карты признаков с определенных уровней СНС объеди-
няются и формируют дескриптор для каждого отдельного кадра видеопо-
следовательности. Модуль внимания применяется для усреднения значений
полученных карт признаков и построения результирующего вектора.
4.6. Метрики для определения расстояния между признаками
Для поиска изображения человека xp в галерее G = {gi|i = 1, . . . , N} из
N изображений применяется вычисление расстояний между векторами при-
знаков p-го запроса и изображения gi. На данном этапе наиболее применимы
следующие метрики:
1. Косинусное расстояние (Cosine distance) [57, 14]:
xpxgi
(8)
d(p, gi) =
∥xp∥∥xgi∥
2. Расстояние Евклида (Euclidean distance) [7, 10, 13, 26, 84]:
(9)
d(p, gi) = ∥xp - xgi∥22.
3. Расстояние Махаланобиса (Mahalanobis distance) [85]:
√
(10)
d(p, gi) = (xp - xgi)T M-1(xp - xgi
),
где M — ковариационная матрица.
4. Расстояние Жаккара для k-ближайших соседей (Jaccard distance) [85]:
|R∗(p, k) ∩ R∗(gi, k)|
(11)
d(p, gi) = 1 -
,
|R∗(p, k) ∪ R∗(gi, k)|
где R∗(p, k) и R∗(gi, k) — множества ближайших соседей.
Следует отметить, что для повышения точности повторной идентифи-
кации в некоторых алгоритмах применяют повторное ранжирование после
первой сортировки, которое позволяет уточнить результат. В [85] для пер-
воначальной сортировки используется расстояние Махаланобиса. Из полу-
ченной таблицы выбираются первые k изображений и включаются в R(p, k),
а затем выполняется повторное ранжирование с использованием расстояния
Жаккара.
В [26] на основе расстояния Евклида выполняется первичная сортиров-
ка векторов признаков. Далее при повторном ранжировании из полученной
таблицы S(p, g) выбираются k-первых результатов и для каждого из них
осуществляется поиск в галерее. В результате формируются новые списки
1
S(ri, g) с весовыми коэффициентами, которые определяются как
, где
i+1
i = 1,...,k. Итоговая таблица признаков вычисляется по формуле
∑
1
(12)
S∗(p,g) = S(p,g) +
S(ri
,g).
i+1
i=1
83
В [84] предлагается учитывать контекстную информацию ранжирования
дескрипторов в процессе обучения СНС совместно с признаками для по-
вторной идентификации. Алгоритм использует двухпоточную архитектуру,
состоящую из внешнего и внутреннего потоков. На первом из них приме-
няется сортировка для каждого запроса, что позволяет найти наиболее эф-
фективные визуальные различия вверху ранжированного списка галереи и
сформировать предварительный набор для дальнейшей обработки. На вто-
ром потоке анализируются локальные признаки для полученного результа-
та предыдущего шага. Предполагается, что такой подход создает гибридное
ранжирование для сопоставления людей, позволяющее повысить точность
повторной идентификации по сравнению с методами, в которых применя-
ется постобработка списка. Кроме указанных метрик, для оценки схожести
признаков могут быть использованы и другие [86], однако эффективность их
требует дополнительных исследований.
5. Модели и обучение СНС для описания
изображений людей
5.1. Базовые СНС
Наиболее часто при реидентификации в настоящее время в качестве базо-
вых СНС для извлечения признаков используются ResNet-50 [87] в работах
[12, 65, 88] и DenseNet-121 [89] в работах [7, 57], а также MobileNetV2 [88, 90],
PCB [57, 84], GoogleNet [91], или оригинальные архитектуры СНС, например,
как в [92]. В [93] предлагается подход, который позволяет повысить устойчи-
вость системы к окклюзиям. При этом повторная идентификация выполня-
ется по изображению головы человека, а для обнаружения ограничительных
рамок используется СНС YOLOv3.
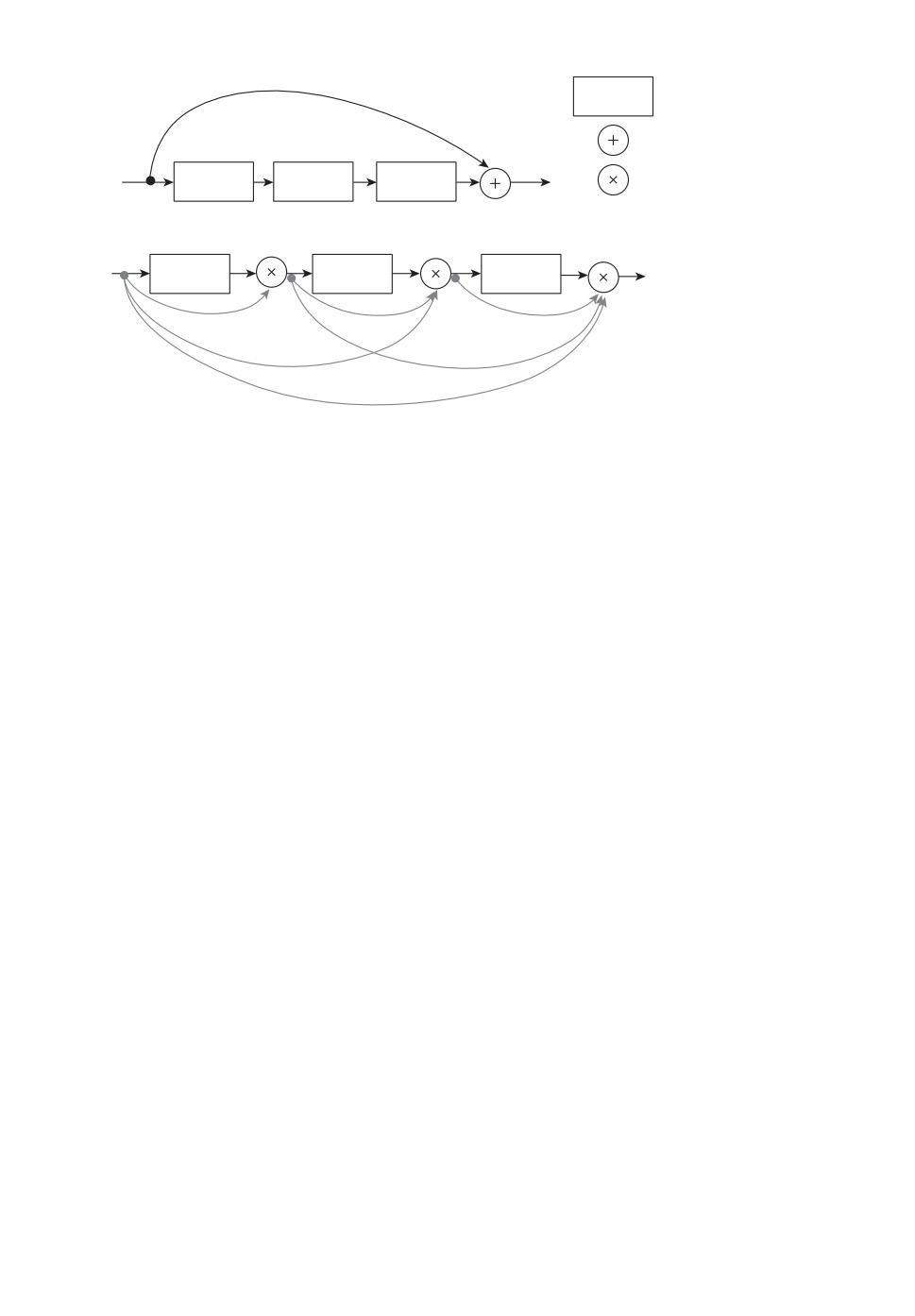
Архитектуры семейства ResNet характеризуются наличием Res-блоков
(рис. 8,а), которые используют пропуск соединений (scip-connection) для сни-
жения вероятности возникновения исчезающих градиентов при обучении.
Res-блок состоит из двух ветвей, одна из которых содержит сверточные слои,
а другая передает информацию на выход без изменений. На выходе данные
с обоих ветвей суммируются. В процессе обучения при обратном распростра-
нении ошибки такой подход не позволяет обнулить градиенты в СНС.
Архитектура DenseNet-121 (рис. 8,б ) отличается наличием соединений
между слоями, при которых карты признаков всех предыдущих слоев ис-
пользуются в качестве входных для всех последующих в блоке. Кроме этого,
карты признаков не суммируются от слоя к слою, что характерно для ResNet,
а конкатенируются. Некоторые исследователи приводят результаты сравне-
ния работы предлагаемых алгоритмов с использованием в качестве базовых
СНС для извлечения признаков различные типы архитектур. Так, в [7] вы-
полняется сравнение эффективности ResNet-50 и DenseNet-121 и показано по-
вышение точности в метриках Rank1 и mAP при использовании DenseNet-121.
В [65] для реидентификации исследованы ResNet-34, ResNet-50 и ResNet-101
84
а
CONV
Cверточный слой
Cложение
CONV
CONV
CONV
Конкатенация
б
CONV
CONV
CONV
Рис. 8. Структуры блоков DenseNet и ResNet.
и представлено, что увеличение глубины сети положительно сказывается на
точности повторной идентификации. В [57] выполнена оценка эффективно-
сти PCB [59], которая используется как надстройка для ResNet-50, ResNet-50
и DenseNet-121. Анализ результатов экспериментов показывает, что наилуч-
шей в метриках Rank1 и mAP является PCB (Rank1 = 94,0, mAP = 82,8),
более низкая точность для DenseNet-121 (Rank1 = 90,8, mAP = 76,9), а наи-
меньшия значения метрик у ResNet-50 (Rank1 = 87,7, mAP = 72,2).
В [92] для реидентификации предлагается новая архитектура СНС
SGWCNN (sparse graph wavelet convolution neural network) на основе анали-
за признаков последовательности кадров, что позволяет учитывать семан-
тическую связь между локальными фрагментами людей на видео. Такой
подход позволяет извлекать дополнительную информацию за счет простран-
ственно-временного анализа видеоданных. Предполагается, что использова-
ние предложенной нейронной сети для уточнения региональных признаков
позволяет более эффективно решать проблему кратковременных окклюзий
при движении пешеходов.
Следует отметить, что качество работы СНС в значительной мере опре-
деляется гиперпараметрами при ее тренировке: количеством эпох, скоростью
обучения, размером пакета изображений.
Количество эпох определяет, сколько раз каждое изображение из обучаю-
щей выборки пройдет по сети. При малых значениях данного параметра мо-
дель окажется не полностью обученной и в результате точность повторной
идентификации будет низкой. Слишком большое количество эпох может при-
вести к переобучению, т.е. сеть запомнит все рассмотренные изображения и
не сможет эффективно обработать даже тестовые примеры. Для повторной
идентификации тренировка СНС выполняется в большинстве случаев в тече-
ние 60-100 эпох. Как правило, на вход сети подаются пакеты с количеством
изображений от 16 до 64. Увеличение размера пакета обусловлено стремле-
85
нием к распараллеливанию вычислений, так как это позволяет сократить
время, затраченное на тренировку СНС, но снижает точность работы обу-
ченной нейронной сети. В [94] предлагается подход, согласно которому при
тренировке СНС постепенно увеличивается размер пакета, что позволяет ми-
нимизировать уменьшение точности, обеспечивая сокращение времени обуче-
ния. Наиболее полное исследование влияния размера пакета на точность при
тренировке СНС для реидентификации представлено в [60]. В данной ра-
боте показано, что наибольшей точности удалось достигнуть для пакета из
32 изображений на наборах данных DukeMTMC-VideoReID, MARS, iLIDS-
vid, PRID.
Известно, что скорость обучения показывает, как изменяются весовые ко-
эффициенты при каждом их обновлении. Для повторной идентификации при
тренировке СНС используют планировщики скорости, которые позволяют из-
менять скорость обучения после некоторого интервала времени или по опре-
деленным критериям. В [95] рассматривается механизм снижения скорости
ADEL, который отслеживает значения весов сети и каждый раз, когда они
перестают изменяться скачкообразно, скорость обучения уменьшается. Это
позволяет обеспечить более быструю сходимость в СНС.
В [96] предлагается подход, включающий три режима изменения скорости
обучения η, которые зависят от кривизны λ0 поверхности функции потерь.
Первый режим предполагает медленную фазу (lazy phase), при ней скорость
обучения имеет относительно небольшое значение η <2 и шаг измененияλ
0
весов остается практически постоянным на первом этапе обучения. Второй
режим характеризуется быстрой фазой (catapult phase), при которой ско-
2
рость обучения принимает значения
< η < ηmax. На этом этапе наблюда-
λ0
ется экспоненциальный рост потерь и быстрое уменьшение кривизны η до тех
пор, пока не стабилизируется на значении λfinal <η2 . При соответствии этому
условию достигается плоский минимум. Фаза расхождения (divergent phase)
выполняется на третьем режиме. При этом скорость тренировки превышает
значение ηmax и модель перестает обучаться. Кроме этого, в [96] выдвигается
предположение, которое затем подтверждается исследованиями, что исполь-
зование больших скоростей обучения позволяет находить плоские минимумы,
которые обобщают лучше, чем резкие. К этому же, по мнению авторов, при-
водит и использование небольших пакетов для обучения.
5.2. Модификации СНС
Изменения базовых архитектур предоставляют возможности для повыше-
ния точности работы систем повторной идентификации. В [88] исследуется
влияние способа нормализации данных на выходе сверточных слоев и пред-
лагается технология MetaBIN (Meta Batch-Instance Normalization), которая
использует комбинацию двух подходов: пакетную нормализацию и нормали-
зацию отдельных изображений [97]. Первый позволяет получать информацию
о различных стилях изображений в пакете. Однако это может приводить к
снижению точности реидентификации в невидимых доменах. Второй подход
86
позволяет игнорировать информацию об особенностях домена, однако недо-
статком является возможное уменьшение при этом полезной информации.
Для решения двух этих проблем вводится обучаемый параметр, который поз-
воляет найти баланс между рассмотренными подходами и тем самым не толь-
ко повысить эффективность повторной идентификации, но и сделать систему
более устойчивой при работе в другом домене. В [98] рассматривается влия-
ние функции активации (ФА) в СНС ResNet-50, DenseNet-121 и DarkNet-53
на точность реидентификации. Наиболее распространенной функцией акти-
вации является ReLU [99], которая представляет собой кусочно-заданную
функцию
{
x, x > 0,
(13)
φ(x) =
0, x ≤ 0,
где x — входное значение нейрона.
Основное преимущество заключается в низкой вычислительной сложности
как при прямом, так и при обратном проходе по сети. Однако значения про-
изводной на положительной части области определения функции активации
могут приводить к взрывным градиентам при обучении, а на отрицатель-
ной — к потере некоторой информации при обучении, так как все нейроны с
отрицательными значениями не будут активированы. Чтобы избежать этого,
можно применять функцию Leaky-ReLU [100]
{
x, x > 0,
(14)
φ(x) =
αx, x ≤ 0,
где α — угловой коэффициент, принимающий небольшие значения, тради-
ционно α = 0,01.
В [101] представлены результаты эмпирического исследования, в котором
определяется влияние угла наклона отрицательной части функции на задаче
классификации изображений при использовании ФА ReLU и Leaky-ReLU, а
также их модификаций: параметрической выпрямленной линейной единицы
(PReLU) и рандомизированной выпрямленной линейной единицы с утечкой
(RReLU). Проведенные исследования показали, что лучшие результаты бы-
ли получены при использовании PReLU. Однако в этом случае высока веро-
ятность переобучения СНС при использовании небольшого набора данных,
поэтому RReLU оказывается более эффективной на практике.
Кроме указанных модификаций, небольшой наклон в отрицательной части
области определения функции имеют ФА ELU, SeLU, GeLU, что позволяет
предположить эффективность их использования для повторной идентифика-
ции людей.
ФА ELU (Exponential Linear Unit) [102] определяется выражением
{
x,
x ≥ 0,
(15)
φ(x) =
α(ex - 1), x < 0,
87
где α > 0 — коэффициент, ограничивающий величину выходных значений на
отрицательном участке области определения функции.
ФА SELU (Scaled Exponential Linear Unit) является масштабированным
вариантом ELU и описывается выражением
{
x,
x ≥ 0,
(16)
φ(x) = λ
α(ex - 1), x < 0.
В исследовании, представленном в [103], определяются значения для коэф-
фициентов α = 1,67326, λ = 1,0507.
ФА GELU (Gaussian Error Linear Units) [104] определяется выражением
(
(√
))
[
)]
1
( x
2
(17)
φ(x) =
x 1 + erf
√
≈ 0,5x
1 + tan
(x + 0,044715x3)
2
2
π
или
(18)
φ(x) = xσ(1,702x),
1
где σ =
— функция активации сигмоиды.
1+e-x
В [105] для поиска наиболее эффективной ФА используется подход авто-
матической генерации, основанный на последовательном переборе унарных
и бинарных функций, которые поочередно объединяются, а результат оцени-
вается эмпирически. Полученая функция Swish определяется выражением
(19)
φ(x) = xσ(βx),
где β — коэффициент, регулирующий степень кривизны функции, σ — функ-
ция сигмоиды.
В [106] рассмотрена ФА Mish
(20)
φ(x) = x tanh(softplus(x)) = x tanh(ln(1 + ex
)).
ФА влияет как на динамику тренировки, так и на точность работы обучен-
ной модели. Из [98] следует, что использование вместо ReLU таких функций,
как GeLU, Swish и Mish, может повысить точность повторной идентифика-
ции. Дополнительные исследования показали, что применение этих функций
увеличивает время обучения модели, при этом не позволяет получить доста-
точно стабильный результат. К наиболее предпочтительным ФА для СНС
при повторной идентификации можно отнести GeLU и ReLU.
Для решения специфических задач, например для неоднородных систем
реидентификации [8], в которых используются изображения с инфракрасной
камеры и с камеры видимого диапазона, предлагается новая архитектура
СНС MCLNet (Modality Confusion Learning Network). MCLNet основывается
88
на частично разделенной двухпоточной сети. Для повышения устойчивости
СНС к разнородным данным последовательно извлекаются признаки, харак-
терные для каждого типа данных в отдельности, а затем общие дескрипто-
ры. Так как видимые и инфракрасные образцы имеют разное распределение
признаков и они не могут быть согласованы для сравнения, сеть обучается
игнорировать информацию о модальности и пытается извлекать общие от-
личительные особенности для разнородных изображений человека. Чтобы не
упустить важные особенности разных людей, создается механизм запутыва-
ния обучения, в результате чего несоответствие между разнородными изоб-
ражениями сводится к минимуму, а сходство максимизируется. В [7] предла-
гается архитектура СНС RCSANet (Clothing Status Awareness Network) для
долгосрочной повторной идентификации. Методы, применяемые для этого,
учитывают, что после некоторого интервала времени человек сменил одеж-
ду, в которой он опять попадает в поле зрения видеокамеры. Однако такие
подходы неэффективны, если в данном интервале времени человек не пере-
оделся, и точность работы систем долгосрочной реидентификации значитель-
но снижается. Для этого в [7] предлагается RCSANet, которая упорядочивает
признаки пешеходов и включает в общий дескриптор особенности состояния
одежды. RCSANet представляет собой двухпоточную систему, основанную
на DenseNet-121, и содержит ICE-поток (Inter-Class Enforcement), который
позволяет максимизировать различия для каждого человека, и ICR-поток
(Intra-Class appearance Regularization), который используется для упорядо-
чивания признаков, полученных в ICE, с учетом информации о том, имела
ли место смена одежды. Предложенный подход для тестовой выборки, в ко-
торой смены одежды не было, позволил обеспечить значения Rank1 = 100%
и mAP = 97,2%, а при наличии людей в различной одежде метрики равны
Rank1 = 48,6% и mAP = 50,2%.
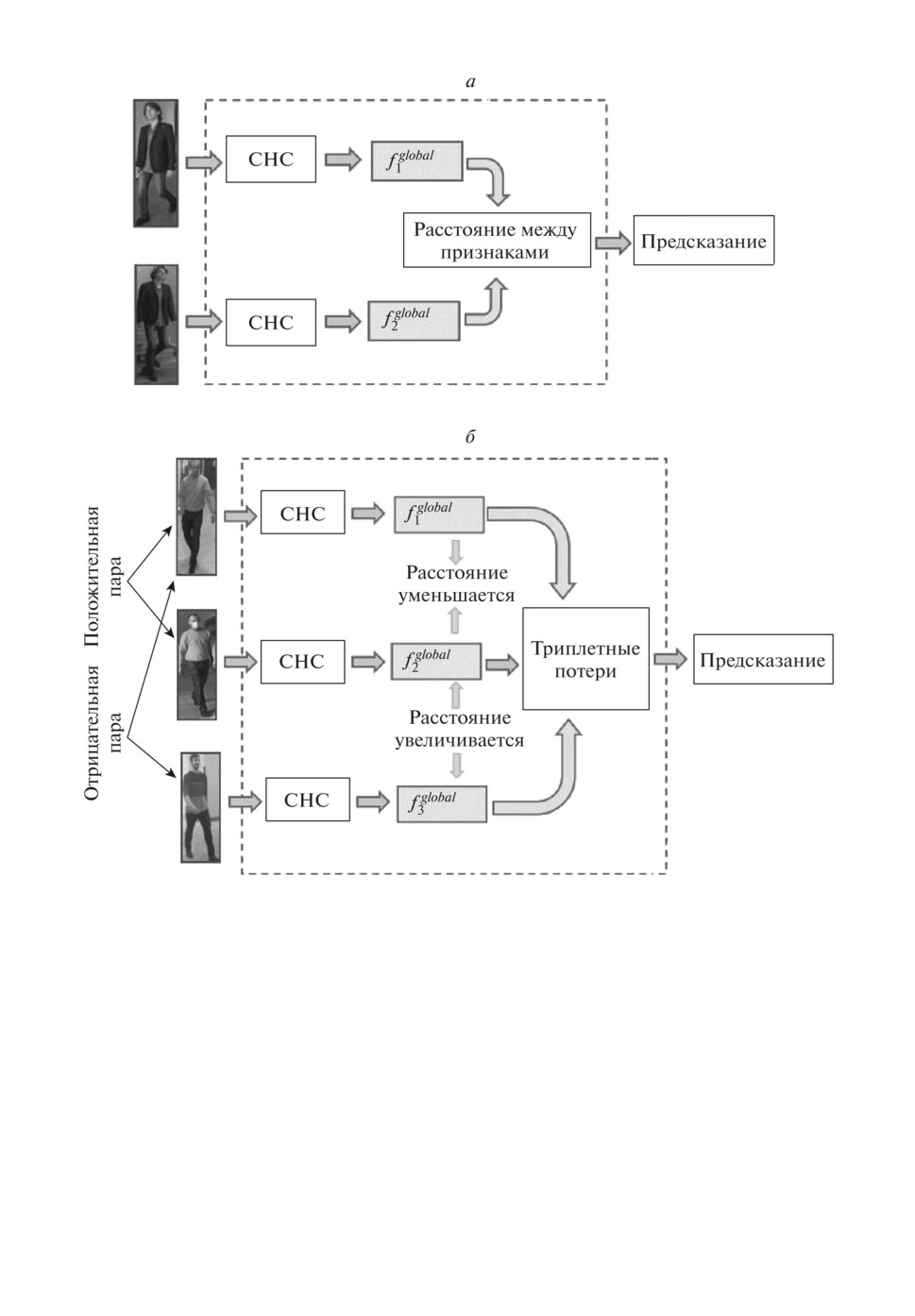
5.3. Сиамские сети
Сиамская нейронная сеть представляет собой такой тип архитектуры, ко-
торый содержит две или больше идентичных подсетей с одинаковыми архи-
тектурами, параметрами и весами. Выходом сиамской сети будет являться
показатель подобия двух изображений, поданных на вход [107].
В сиамских сетях могут использоваться парные модели (рис. 9,а), состоя-
щие из двух подсетей [108, 69], и триплетные [91], включающие три подсети
(рис. 9,б ).
В [108] сиамская архитектура используется для минимизации косинусного
расстояния между признаками двух экземпляров при контрастном обучении
для выявления сходства между ними. В [69] с помощью глубокой нейронной
сети с двумя ветвями, работающей по сиамскому принципу, обрабатывают-
ся амплитуда и фаза Wi-Fi сигналов для извлечения значимых признаков
радио-биометрической подписи, позволяющей повторно идентифицировать
человека.
89
Рис. 9. Модели сиамской нейронной сети а) — парная модель; б ) — триплетная
модель.
В [109] сиамские сети используются для предотвращения переобучения и
предлагается архитектура, состоящая из двух сиамских сетей. Первая из них
является базовой, входными данными для нее служат положительные или
отрицательные пары изображений людей. При этом положительной парой
считаются изображения, полученные для одного человека в разное время,
отрицательная пара представляет собой изображения двух разных людей.
Признаки, извлеченные каждой ветвью базовой сиамской сети, подаются на
входы другой сети, используемой для извлечения более глубоких признаков.
Каждая из двух сиамских сетей предсказывает, является ли входная пара
90
изображениями одного человека, или нет. Между двумя сетями вводится
функция потерь (verification loss), которая позволяет корректировать относи-
тельное расстояние между векторами признаков, полученными с каждой из
сиамских сетей для людей с одинаковыми или разными идентификаторами,
и тем самым улучшить точность идентификации.
В [110] предлагается глубокая архитектура для повторной идентифика-
ции, которая использует в структуре сиамской сети модуль внимания. Такой
подход позволяет обеспечить согласованность важных деталей внешности че-
ловека с различных кадров и находить более важные отличительные черты
для разных людей. Кроме этого, поиск расположения отличительных при-
знаков на изображении реализуется в процессе обучения, что делает систему
способной находить ключевые области автоматически.
Сиамская сеть с триплетными потерями предлагается в [91] с GoogleNet
в качестве базовой подсети. Признаки людей при ее использовании извлека-
ются с разных уровней сети, а затем объединяются, формируя общую карту
дескрипторов для каждого из входных изображений. Применение триплет-
ных потерь позволяет приближать в пространстве признаков положительные
пары изображений и отдалять отрицательные.
5.4. Обучение СНС
В общем обучение нейронной сети для эффективного извлечения при-
знаков заключается в поиске весовых коэффициентов с целью уменьшения
значения функции потерь L. Она отображает разницу между полученным
результатом и ожидаемым. Для задачи повторной идентификации наибо-
лее распространенными являются кросс-энтропийная функция потерь (Cross-
entropy loss) [11, 14, 42, 57] и триплетные потери (Triplet loss) [7, 63, 111, 112].
Кросс-энтропийная функция потерь позволяет рассматривать реиденти-
фикацию как классификацию и используется после softmax-слоя [113]. Для
набора из n тренировочных изображений {Ini}ni=1,...,n, содержащего nid раз-
личных людей (классов) с соответствующими идентификационными метками
{pIDn
}ni=1,...,n,
{pIDn} ∈ [1,...,nid], кросс-энтропийные потери можно рассчи-
i
i
тать как [113]
∑
epn
i
(21)
Li = -
{pIDn
= k}log
,
i
∑
k=1
epnii
l=1
где pˆnIDii—предсказанноезначение.
Отличительной чертой триплетных потерь является рассмотрение двух
пар изображений: при положительной паре изображения принадлежат одно-
му и тому же человеку (ya = yp, где ya — изображение человека с меткой
идентификатора a, yp — изображение, составляющее положительную пару,
p = a); при отрицательной паре два изображения принадлежат разным лю-
дям (ya = yn, где yn — изображение, составляющее отрицательную пару, т.е.
91
их идентификаторы не равны n = a). Таким образом, учитываются расстоя-
ние da,p между признаками для положительной пары и расстояние da,n между
признаками разных людей. Чтобы СНС не только увеличивала da,n для раз-
ных классов, но и уменьшала его для одинаковых, вводится коэффициент
регуляризации m. Если не использовать этот коэффициент, то при обучении
сеть будет увеличивать расстояние между изображениями разных людей и не
учитывать расстояние между одинаковыми классами. Это связано с тем, что
найти разницу между различными людьми легче, чем сходство между оди-
наковыми, соответственно m позволяет ограничить рост da,n и обеспечивает
уменьшение da,p. Для вычисления триплетной функции потерь используется
выражение [111]
∑
(22)
L=
max([m + da,p - da,n
], 0).
a,p,n
ya=yp=yn
В [53] при использовании триплетных потерь анализируется отрицатель-
ная пара, включающая изображения разных, но наиболее похожих людей. Та-
кой подход позволяет научиться сети находить различия для людей со схожей
внешностью. На наборе данных MSMT17 [19] метрика mAP составляет 84,4%,
а в метрике Rank1 89,9%, что является лучшим результатом для MSMT17 на
момент анализа.
В [114] предполагается, что при кластеризации изображений использова-
ние триплетных потерь является недостаточно эффективным подходом. По-
этому разработана функция потерь cluster loss, которая позволяет получить
на выходе модели большие межклассовые и меньшие внутриклассовые разли-
чия, чем при использовании триплетов. Cluster loss вычисляется по формуле:
∑
β
dintrai
(23)
LC
= ip
,
∑
γ+ dinter
i
i
∑
где dintrai =k ∥f(x) - fmi∥22 — внутриклассовая вариация для каждого
i-го идентификатора, представляющая собой расстояние между признаками
f (x) идентификатора из выборки и средним значением для этого идентифи-∑
∑
катора fmi =K f(x)K из K изображений; dinteri =
∥fmi - fimd∥22 —
∀id∈P,id=i
межклассовая вариация, представляющая собой расстояние между средним
значением признаков идентификатора и средним значением для признаков
всех P идентификаторов.
Для повышения точности повторной идентификации иногда используют
несколько функций потерь. Например, в [65] для определения наиболее эф-
фективных признаков и наиболее значимых атрибутов предлагается две со-
ставляющие для функции потерь: метрического разделения (Loss function of
metric distillation) Ld и приоритетных атрибутов (Loss function of attribute
92
Рис. 10. Схема алгоритма Clothes-based Adversarial Loss.
prior) Lp:
(24)
L = Ld + αLp1 + βLp2,
∑M
где Ld = |di,j -
dki,j| — функция потерь, определяющая расстояние di,j
k=1
между векторами признаков, выделенных алгоритмом реидентификации для
всего изображения, и признаками, выделенными модифицированным алго-
ритмом, направленным на поиск признаков различных атрибутов, что поз-
воляет оценить вклад каждого атрибута в общий вектор признаков; di,jk —
расстояние между xi и xj для k-го из M атрибутов.
Очевидно, что составляющая функции потерь Lp состоит из двух частей:
Lp1 — определяет вклад общих атрибутов, Lp2 — определяет вклад индиви-
дуальных особенностей:
(
)
v
∑
(ME)
dei,j
(25) Lp1 = max
0,
-
+
M
di,j
e=1
(
)v)
( M-ME∑
dci,j
ME
+ max
0,
-1+
,
di,j
M
c=1
(
)
∑
dei,j
(MEM)v
(26) Lp2 =
max
0, e-λ
-
+
ME
di,j
e=1
(
)
∑
dci,j
1 - (MEM )v
+
max
0,
-eλ
,
di,j
M-ME
c=1
∑M
гд
di,j ≈
dki,j — предсказанное значение расстояния между признаками,
k=1
ME — количество уникальных атрибутов.
93
В [6] предлагается использовать состязательные потери на основе анали-
за одежды (Clothes-based Adversarial Loss ( CAL)), которые позволяют из-
влекать признаки без учета одежды человека для долгосрочной повторной
идентификации. Общая схема предлагаемого подхода показана на рис. 10 и
состоит из двух классификаторов: идентификатора CIDφ и одежды CCφ . Каж-
дый классификатор обучается отдельно. На первом этапе обучения миними-
зируются потери LC (clothes classification loss) для классификатора одежды,
которые основаны на кросс-энтропии между предсказанной меткой одежды
CCφ(g0(xi)) и yCi. При этом СНС тренируется не учитывать признаки одежды
за счет минимизации функции потерь LCA (Clothes-based Adversarial Loss),
определяющей признаки, не относящиеся к одежде. После обучения класси-
фикатора одежды весовые коэффициенты для него фиксируются и дальней-
ший этап направлен на минимизацию функции потерь для классификатора
идентификатора.
Тестирование предложенного алгоритма выполнялось на наборе данных
CCVID [6], метод CAL позволил увеличить точность повторной идентифи-
кации более чем на 20% в метриках Rank1 и mAP по сравнению с базовым
алгоритмом.
В настоящее время все большее внимание уделяется неконтролируемому
или полу-контролируемому обучению, в которых данные не имеют заранее
подготовленных меток и аннотаций. В некоторых работах по реидентифика-
ции людей исследователи предлагают использовать информацию, получен-
ную с применением существующих размеченных наборов данных с извест-
ными идентификаторами, в невидимых доменах. Под невидимыми доменами
подразумеваются наборы данных, изображения из которых не использова-
лись при обучении и которые могут не иметь меток идентификаторов. В этом
случае говорят о неконтролируемой адаптации домена (unsupervised domain
adaptation (UDA)). Такой подход применяется в [115] и использует в каче-
стве исходной информации объединение нескольких наборов данных. Как
исходные и целевые домены рассматриваются Market-1501 [26], DukeMTMC-
ReID [20], CUHK03 [18] и MSMT17 [19], которые объединяются в различных
комбинациях. Кроме этого, предлагаются два модуля, позволяющие изучать
отличительные признаки, характерные для одного домена, и для объединен-
ных доменов. В первом случае предлагается модуль пакетной нормализации
RDSBN, позволяющий снизить влияние признаков, специфических для до-
мена, и улучшить различимость черт лица. Во втором — используется объ-
единение информации о доменах на основе сети Graph Convolution Network
(GCN), направленное на уменьшение расстояния между признаками разных
доменов. GCN используется для построения графа, объединяющего все эк-
земпляры в домене, т.е. создается узел, обобщающий характерные признаки
для каждого человека внутри домена, что позволяет определить глобальные
дескрипторы для домена в целом.
Неконтролируемые методы повторной идентификации, основанные на
адаптации домена для целевой области, зачастую хорошо работают только
94
на одном домене, для которого были адаптированы. Решение этой проблемы
рассматривается в [116] и предлагается проведение постоянной неконтроли-
руемой адаптации к новым данным, т.е. непрерывное обучение. При этом зна-
ния, полученные ранее для предыдущих доменов, сохраняются. Это крайне
важно в системах, применяемых в реальных условиях, когда новые данные
появляются регулярно. Причем в систему могут быть включены дополни-
тельные видеокамеры, установленные в других местах, а адаптация к новым
данным должна быть с сохранением навыков повторной идентификации в
уже известных доменах. Для решения этой задачи небольшое количество об-
разцов из существующих доменов хранится в буферах долговременной па-
мяти для сформированных ранее кластеров. В процессе адаптации модели
к новой области старые образцы также добавляются в выборку, на основе
которой выполняется контрастное обучение. Основная идея такой трениров-
ки СНС заключается в максимизации сходства между положительной парой
изображений, полученных при различных условиях.
При неконтролируемом обучении некоторые исследователи используют
методы кластеризации для создания псевдометок во время обучения модели.
При этом может возникать ситуация, когда в одном кластере объединяются
изображения разных людей, а для одного и того же человека кластер мо-
жет быть разбит на две группы. Это значительно снижает точность СНС,
обученной на таких данных. В [117] предполагается, что из-за ограничен-
ного количества выборок для каждого человека часть информации может
отсутствовать. Поэтому предлагается метод Implicit Sample Extension (ISE),
позволяющий создавать на границах кластеров образцы поддержки на основе
реальных изображений текущего и соседних с ним кластеров через страте-
гию progressive linear interpolation (PLI), которая позволяет объединить два
кластера, если они содержат изображения одного и того же человека, и раз-
делить кластер, если в нем имеются изображения разных людей.
Методы самоконтролируемого обучения (self-supervised learning (SSL)) на-
правлены на изучение отличительных признаков на основе больших массивов
неразмеченных данных. В [118] для повышения точности повторной иденти-
фикации предлагается применение самоконтролируемого предварительного
обучения с использованием немаркированных изображений людей, которое
показывает лучшие результаты по сравнению с традиционным предваритель-
ным обучением на ImageNet. Основной идеей метода из [118] является выде-
ление глобальных и локальных признаков. Структура предложенной в ра-
боте системы Part-Aware SelfSupervised pre-training (PASS) состоит из двух
частей, имеющих одинаковую архитектуру: сеть учеников (student network) и
сеть учителей (teacher network). PASS обучает сеть учеников соответствовать
выходным данным учителя. На вход этой сети передаются как глобальные,
так и локальные признаки, полученные для случайно выбранных областей.
Сеть учителей анализирует только глобальные признаки. Сходство между
результатами оценивается на основе кросс-энтропии. После предварительно-
го обучения PASS имеет возможность изучать глобальные признаки и при
95
этом автоматически фокусироваться на различных локальных особенностях
изображений.
В [119] рассматривается предварительное обучение для повторной иден-
тификации, при котором для видео из набора LUperson применяется алго-
ритм сопровождения людей. Каждому сопровождаемому человеку присваи-
ваются метки, которые используются для формирования новой обучающей
выборки LUperson-NL и, соответственно, предварительной тренировки СНС.
За счет такого подхода в LUperson-NL заносятся шумные метки (noisy labels),
которые могут содержать ошибки, возникающие при присвоении идентифи-
каторов в неразмеченных наборах данных. Примером является присвоение
одному и тому же человеку, изображения которого получены с разных ка-
мер или в различное время, отличающихся идентификаторов. Другим приме-
ром является назначение одинаковых идентификаторов схожим по внешним
признакам, но разным людям. Предполагается, что впоследствии ошибоч-
ные метки будут корректироваться. Подход из [119] предполагает три этапа.
На первом выполняется контролируемое обучение повторной идентификации
с использованием полученных шумных меток. Второй этап применяет кон-
трастное обучение, которое позволяет исправить зашумленные метки. Для
их исправления выбирается изображение-прототип, и по мере поступления
новых данных, в случае их сходства с выбранным прототипом, изображения
добавляются в кластер, и вычисляется усредненный для всех изображений в
кластере вектор признаков, который динамически обновляется. На третьем
этапе применяется контрастное обучение на основе уже исправленных меток.
В результате похожие примеры объединяются в один прототип, а зашумлен-
ные метки исправляются.
В [120] предлагается подход PPLR (Part-based Pseudo Label Refinement),
который уменьшает влияние шумных меток при неконтролируемом обуче-
нии за счет использования взаимодополняющей связи между глобальными и
локальными признаками человека на изображении. Чтобы исключить влия-
ние нерелевантных частей изображения, таких как окклюзии, которые мо-
гут появляться в разное время, искажать состав локальных и глобальных
признаков человека и в итоге приводить к неверным предсказаниям, метки
уточняются на основе введенного показателя взаимного согласования (cross
agreement score) сходства k-ближайших соседей между пространствами гло-
бальных и локальных признаков изображения человека.
В [108] рассмотрен подход для неконтролируемой повторной идентифи-
кации на основе скелета человека (skeleton-based) и предлагается схема кон-
трастного обучения для извлечения признаков немаркированных 3D-скелетов
человека. На последовательности необработанных данных накладываются
маски скелетов, выбирается маска-прототип и по наиболее характерным осо-
бенностям скелета выполняется кластеризация. Чтобы найти отличительные
особенности для различных прототипов без использования каких-либо ме-
ток, сопоставляются схожие черты скелетов. Чтобы учитывать корреляцию
внутри одной и той же видеопоследовательности, связанную с изменениями
96
в процессе движения человека, используют сиамскую архитектуру, которая
позволяет зафиксировать наиболее характерные признаки для каждого че-
ловека на основе его скелета.
6. Сравнение эффективности алгоритмов повторной
идентификации на разных наборах данных
Сравнение эффективности различных алгоритмов повторной идентифи-
кации по одиночным изображениям на наиболее крупных и распространен-
ных наборах данных Market-1501, DukeMTMC-ReID, MSMT17 представлено
в табл. 2.
Таблица 2. Точность повторной идентификации по изображениям для наборов
данных Market-1501, DukeMTMC-ReID и MSMT17
Набор
Набор
Набор
Алгоритм
Год
Метрики
Market-1501
DukeMTMC-ReID MSMT17
PCP+RPP [59]
2018
mAP
81,6
69,2
-
Rank1
93,8
83,3
-
CASN [110]
2019
mAP
82,8
73,7
-
Rank1
94,4
87,7
-
MGN+PTL [58]
2019
mAP
87,34
79,16
-
Rank1
94,83
89,36
-
st-ReID [57]
2019
mAP
95,5
92,7
-
Rank1
98,0
94,5
-
HOReID [61]
2020
mAP
84,9
75,6
-
Rank1
94,2
86,9
-
mAP
-
-
49,3
AGW[2]
2021
Rank1
-
-
68,3
mINP
-
-
14,7
mAP
84,04
-
52,4
CIL [121]
2021
Rank1
93,38
-
76,1
mINP
57,9
-
12,45
SBS [65]
2021
mAP
88,29
78,26
-
Rank1
95,55
89,21
-
Алгоритм из [55]
2021
mAP
89,2
79,6
57,2
Rank1
96,2
91,0
81,9
FlipReID [52]
2021
mAP
94,7
90,7
81,3
Rank1
95,8
93,0
87,5
HBReID [53]
2021
mAP
-
-
84,4
Rank1
-
-
89,9
RANGEv2 [84]
2022
mAP
86,8
78,2
51,3
Rank1
94,7
87,0
76,4
RANGEv2+K-
2022
mAP
91,3
84,2
-
reciprocal [84]
Rank1
95,1
88,7
-
CAL [6]
2022
mAP
87,5
-
57,3
Rank1
94,7
-
79,9
97
В незначительном количестве работ [58, 59, 110] авторами приводятся ре-
зультаты экспериментов для CUHK03. Однако данный набор включает не
более пяти изображений для человека, полученных с каждой камеры из двух
используемых, что является недостаточным для эффективной оценки точ-
ности реидентификации. Из табл. 2 очевидно, что при применении одного и
того же алгоритма для разных наборов данных получены разные результа-
ты точности: для набора Market-1501 наиболее высокие показатели, а для
MSMT17 наиболее низкие значения. Такие результаты связаны с тем, что
MSMT17 имеет значительно большее количество изображений (см. табл. 1),
чем другие, и при его формировании использован более сложный сценарий
видеонаблюдения, который охватил различное время суток и погодных усло-
вий, изображения как с внутренних, так и наружных камер видеонаблюде-
ния. Хотя показатели точности для этого набора данных значительно ниже,
чем для других рассматриваемых, но их можно считать более объективны-
ми, так как сценарий формирования MSMT17 более приближен к реальным
ситуациям при реидентификации, следовательно, корректнее отображает эф-
фективность алгоритмов для открытых систем повторной идентификации.
На момент анализа лучший результат в метрике mAP при тестировании
на наборе данных MSMT17 получен для алгоритма HBReID [53], для него
Rank1 = 89,9%.
Это обеспечено за счет тщательного отбора положительных и отрица-
тельных пар изображений для триплетных потерь и использования состя-
зательных потерь, позволяющих изучить фон и не учитывать его при клас-
сификации людей, используя только признаки человека. Наиболее близкий
по точности результат, Rank1 = 87,5, был получен с применением алгоритма
FlipReID [52]. Отличием данного алгоритма является использование усред-
ненных признаков входного и повернутого случайным образом изображения.
Для наборов Market-1501 и DukeMTMC-ReID среди рассмотренных алго-
ритмов повторной идентификации наиболее эффективный предложен в [57].
В данном алгоритме, кроме визуальных признаков, использовалась до-
полнительная информация о времени (номер кадра) и месте (идентификатор
камеры) съемки, которая предоставляется с этими наборами данных в виде
имени файла изображения из Market-1501 и DukeMTMC-ReID. При реиден-
тификации авторы использовали условие о том, что человек не может нахо-
диться в поле зрения нескольких непересекающихся камер одновременно, ему
требуется время для перехода. Таким образом, все изображения, имеющие ви-
зуальное сходство с запросом, должны быть проверены, могли ли эти люди
быть в том или ином месте в определенное время относительно предыдуще-
го, и все нерелевантные изображения по данным критериям не учитываются
при реидентификации. Несмотря на то что данный подход был предложен в
2019 г., в настоящее время в метриках Rank1 и Rank5 этот подход имеет одни
из лучших значений при тестировании на Market-1501 и DukeMTMC-ReID.
Следует отметить, что авторы алгоритма из [57] не проводили эксперимен-
ты на других наборах данных, вероятно, из-за того, что с другими базами
98
Таблица 3. Точность алгоритмов повторной идентификации по видеопосле-
довательностям для наборов данных MARS, DukeVideo, PRID, QMUL iLIDS,
iLIDS-VID, VIPer
Набор Набор Набор
Набор
Алгоритм
Год Метрики
MARS DukeVideo PRID iLIDS-VID
AGW [2]
2021
mAP
83,0
94,9
-
-
Rank1
87,6
95,4
94,4
-
mINP
63,9
91,9
95,4
-
PiT [3]
2022
mAP
97,23
-
-
86,80
Rank1
90,22
-
-
92,07
MetaBin [88]
2021
mAP
-
-
81,0
87,0
Rank1
-
-
74,2
81,3
SSN3D [74]
2021
mAP
86,2
96,3
-
-
Rank1
90,1
96,8
-
88,9
PMP-MA [60]
2022
mAP
88,1
96,3
99,3
95,3
Rank1
90,6
97,2
98,9
92,8
Rank5
99,6
99,3
100
99,3
Алгоритм из [83]
2022
mAP
82,6
94,2
-
-
Rank1
88,2
95,4
96,6
89,3
Rank5
96,5
99,3
100
98,7
изображений не предоставлялось достаточно пространственно-временной ин-
формации. Анализ табл. 2 показывает, что несмотря на отличие показателей
точности для различных наборов данных, в большинстве современных алго-
ритмов, если улучшение точности отмечается для одного из наборов данных,
то вероятно, что и на других наборах данных при тетировании будет отме-
чаться увеличение точности.
Сравнение эффективности алгоритмов повторной идентификации по ви-
деопоследовательностям представлено в табл. 3 и показывает, что для таких
систем улучшение точности на одном наборе данных не всегда приводит к
улучшению при тестировании на другом.
Наборы данных, используемые при обучении и тестировании, содержат
последовательности изображений людей из нескольких кадров (треклеты),
причем количество треклетов в отдельных наборах данных для каждого чело-
века отличается количеством изображений. Применение треклетов позволяет
учитывать временные признаки, что дает возможность исключить влияние
кратковременных окклюзий, учесть информацию о походке или усреднить
визуальные признаки для меняющих положение в пространстве частей тела
на нескольких кадрах. Следовательно, количество изображений человека в
треклете оказывает достаточно существенное влияние на оценку алгоритма.
При тестировании на наборе данных MARS (см. табл. 3) наилучшей точ-
ностью характеризуется алгоритм PiT [3] в метриках mAP и Rank1. Данный
алгоритм использует пирамиды локальных признаков с разной степенью де-
тализации и усреднение дескрипторов по нескольким кадрам. При тестиро-
99
Таблица 4. Точность повторной идентификации для алгоритмов междоменной
повторной идентификации для наборов данных Market-1501, DukeMTMC-ReID,
MSMT17, VIPeR, PRID и GRID
Тестовая выборка
Алгоритм
Набор данных
(Год)
Алгоритм
RandPerson
mAP
28,8
27,1
6,3
-
-
-
из [48]
[48]
Rank1
55,6
47,6
20,1
-
-
-
RandPerson
mAP
35,8
39,8
36,8
-
-
-
(2020)
[48] + MSMT17
Rank1
62,3
61,0
65,0
-
-
-
SNR [12]
Market-1501
mAP
84,7
33,6
-
42,3
42,2
36,7
Rank1
94,4
55,1
-
32,3
30,0
29,0
(2020)
DukeMTMC-
mAP
33,9
72,9
-
41,2
45,4
35,3
ReID
Rank1
66,7
84,4
-
32,6
35,0
26,0
Market-1501+Duke
mAP
82,3
73,2
-
65,0
60,0
41,3
MTMC-ReID+
Rank1
93,4
85,5
-
55,1
49,0
30,4
CUHK+MSMT17
NRMT[10]
Market-1501
mAP
-
62,3
19,8
-
-
-
Rank1
-
78,1
43,7
-
-
-
(2020)
DukeMTMC-
mAP
72,2
-
20,6
-
-
-
ReID
Rank1
88,0
-
45,2
-
-
-
Алгоритм
Market-1501
* mAP
-
65,2
20,4
-
-
-
из [11]
Rank1
-
79,5
43,7
-
-
-
DukeMTMC-
mAP
71,5
-
24,3
-
-
-
(2020)
ReID
Rank1
88,1
-
51,7
-
-
-
CBN [9]
UnrealPerson
mAP
54,3
49,4
15,3
-
-
-
(2021)
Rank1
79,0
69,7
38,5
-
-
-
JVTC [9]
[9]
mAP
80,2
75,2
34,8
-
-
-
(2021)
Rank1
93,0
88,3
68,2
-
-
-
MetaBin [88]
CUHK02+
mAP
-
-
-
66,0
79,8
58,1
MobileNetV2
CUHK03+
Rank1
-
-
-
56,9
72,5
49,7
(2021)
Market-1501 +
MetaBin [88]
+DukeMTMC-
mAP
-
-
-
68,6
81,0
57,9
ResNet-50
ReID+CUHK-
Rank1
-
-
-
59,9
74,2
48,4
(2021)
SYSU
QAConv [49]
ClonedPerson
mAP
21,8
-
18,5
-
-
-
(2022)
[49]
Rank1
22,6
-
49,1
-
-
-
Market-1501
mAP
-
73,2
40,2
-
-
-
IDM [66]
Rank1
-
85,5
69,9
-
-
-
(2022)
DukeMTMC-
mAP
85,3
-
40,5
-
-
-
ReID
Rank1
94,2
-
69,5
-
-
-
MSMT17
mAP
85,2
73,6
-
-
-
-
Rank1
94,1
84,6
-
-
-
-
100
вании на наборах данных Duke-Video и iLIDS-VID наилучшие результаты
получены для алгоритма PMP-MA [60] в метрике mAP. В основе PMP-MA
используется пирамидальное представление схем мультивнимания и учиты-
ваются результаты точной настройки СНС, в том числе подбор размера па-
кета данных при обучении. PMP-MA и алгоритм, предложенный в [83] при
тестировании на базе данных PRID, позволяют получить Rank5 = 100%, что
обеспечивается относительной легкостью набора для данной метрики, так как
использовалось только две камеры, фон довольно равномерный, а окклюзии
для человека с другими людьми встречаются редко.
Актуальным является сравнение точности работы алгоритмов реиденти-
фикации при обучении и тестировании на разных базах данных, что поз-
воляет оценить эффективность при смене доменов. В табл. 4 представлена
точность повторной идентификации алгоритмов, в которых для доменной
переносимости использовались подходы, направленные на поиск признаков с
учетом данной задачи.
Следует отметить, что независимо от используемого алгоритма увеличе-
ние обучающей выборки путем объединения существующих наборов данных
позволяет повысить точность повторной идентификации, что подтвержда-
ется исследованиями в [12, 48]. В [48] добавление к синтетическому набору,
используемому в качестве обучающей выборки, изображений из MSMT17 поз-
волило повысить mAP с 47,6% до 61% при тестировании на DukeMTMC-ReID.
Включение в обучающую выборку данных из целевого домена позволя-
ет увеличить Rank1 для MSMT17 с 6,3 до 36,8% в [48]. Аналогично, в [12]
использование при обучении изображений из целевого домена позволяет уве-
личить mAP для Market-1501 с 33,9 до 82,3%, для DukeMTMC-ReID также
обеспечивается значительное увеличение mAP c 33,6 до 73,2%.
Cреди современных алгоритмов для междоменной повторной идентифика-
ции (см. табл. 4) в метрике mAP наибольшая точность достигнута для алго-
ритма IDM [66] при тестировании на наборах данных Market-1501 и MSMT17.
В данном алгоритме для повышения устойчивости к смещению домена при-
менялась генерация промежуточных доменов, которые объединяли в себе
особенности исходного и целевого. При использовании в качестве целевого
домена DukeMTMC-ReID наиболее эффективным оказался подход JVTC [9]
с применением в качестве обучающей выборки синтетического набора данных
UnrealPerson [9].
Алгоритмы реидентификации по видеопоследовательностям, направлен-
ные на повышение устойчивости к смещению домена, наиболее часто ис-
пользуют наборы данных VIPeR, PRID и GRID. Среди проанализированных
подходов лучшие показатели Rank1 и mAP были получены при применении
алгоритма MetaBIN [88] (см. табл. 4), основная идея которого заключается в
обобщении слоев нормализации и снижении влияния особенностей, присущих
исходному домену.
101
Таблица 5. Точность алгоритмов повторной идентификации с неконтролируемым
и полуконтролируемым обучением для наборов данных Market-1501, DukeMTMC-
ReID и MSMT17
Алгоритм
Год Метрики
Набор
Набор
Набор
Market-1501 DukeMTMC MSMT17
-ReID
[115] обучен на
2021
mAP
-
66,6
34,9
Market-1501
Rank1
-
80,3
64,7
[115] обучен на
2021
mAP
81,5
-
33,6
Duke-MTMC-ReID
Rank1
92,9
-
64,0
[116] с непрерывной
2022
mAP
59,3
-
40,8
адаптацией домена
Rank1
82,7
-
67,5
ISE[117] +
2022
mAP
85,3
-
37,0
GeM-pooling
Rank1
94,3
-
67,6
PASS [118]
2022
mAP
93,3
-
74,4
Rank1
96,9
-
89,7
PNL[119]+MGN пред-
2022
mAP
91,9
84,3
68,0
обучен на LuPerson
Rank1
96,6
92,0
86,0
PPLR [120]
2022
mAP
81,5
-
31,4
без использования меток
Rank1
92,8
-
61,1
камеры
PPLR [120]
2022
mAP
84,4
-
42,2
c использованием меток
Rank1
94,3
-
73,3
камеры
Другим подходом для адаптации к смене домена при реидентификации
является неконтролируемое или полуконтролируемое обучение на неразме-
ченных данных. Как очевидно из табл. 5, среди рассмотренных алгоритмов
наилучшие предложены в [118, 119]. В [118] используются предварительное
обучение на немаркированных изображениях людей, двухпоточная архитек-
тура, глобальные и локальные признаки. Алгоритм из [119] предполагает
предварительное обучение на немаркированном наборе данных LUPerson,
для которого формируются и исправляются в процессе обучения шумные
метки. В большинстве работ для предварительного обучения применяется
набор данных ImageNet, однако последние исследования [118, 119] показали,
что наиболее эффективно на этом этапе использовать изображения людей.
7. Заключение
Повторная идентификация человека в распределенной системе видеона-
блюдения является достаточно новой актуальной задачей, которая в послед-
нее время стала успешно решаться с помощью технологий глубокого обуче-
ния. В работе рассмотрены общие принципы организации повторной иденти-
фикации людей с использованием сверточных нейронных сетей при видеона-
блюдении. Предложена классификация систем реидентификации. Приведен
102
анализ существующих наборов данных для обучения глубоких нейронных
архитектур, описаны подходы для увеличения количества изображений в ба-
зах данных, рассмотрены виды признаков изображений людей. Представлен
анализ основных применяемых для реидентификации моделей архитектур
сверточных нейронных сетей, их модификаций, а также методов обучения.
Проанализирована эффективность повторной идентификации людей на раз-
ных наборах данных, в том числе при междоменной реидентификации. При-
ведены результаты исследований по оценке эффективности повторной иден-
тификации в различных метриках для существующих подходов, отмечены
достоинства и недостатки разных метрик. Несмотря на то что глубокое обу-
чение и нейронные сети продемонстрировали свои большие преимущества в
анализе видеоизображений, все еще остаются проблемы, которые предстоит
решить для повторной идентификации. Одним из наиболее заметных недо-
статков глубокого обучения является то, что для процесса обучения требуется
огромное количество точных аннотированных наборов данных, что требует
утомительной работы и часто приводит к искажениям. Многие исследова-
тели начали делиться своими данными на общедоступных платформах, что
полезно для разработки единого оценочного индекса, однако некоторые на-
боры данных для реидентификации исключены из общего доступа, например
DukeMTMC-ReID [20], а MTMC17 [19] не доступен в публичном доступе и мо-
жет быть получен лишь после подписания соглашения с авторами об исполь-
зовании только в исследовательских целях без передачи третьим лицам [122].
Глубокое обучение достигло удовлетворительных результатов в задачах
классификации и сегментации изображений, однако для задачи повторной
идентификации, особенно по последовательностям изображений, производи-
тельность глубокого обучения все еще недостаточна высока. Поэтому акту-
альным направлением является разработка новых решений с использованием
СНС, обеспечивающих более высокую точность и скорость работы, особенно
для междоменной повторной идентификации.
СПИСОК ЛИТЕРАТУРЫ
1. Ye S., Bohush R.P., Chen H. Person Tracking and Re-identification for Multicamera
Indoor Video Surveillance Systems // Pattern Recognit. Image Anal. 2020. No. 30.
2. Ye M., Shen J., Lin G., Xiang T., Shao L., Hoi S.C. Deep Learning for Person Re-
identification: A Survey and Outlook // IEEE Transactions On Pattern Analysis
3. Zang X., Li G., Gao W. Multi-direction and Multi-scale Pyramid in Transformer
for Video-based Pedestrian Retrieval // ArXiv, abs/2202.06014. 2022.
4. Mihaescu R., Chindea M., Paleologu C., Carata S., Ghenescu M. Person Re-Iden-
tification across Data Distributions Based on General Purpose DNN Object Detec-
103
5.
Liu H., Qin L., Cheng Z., Huang Q. Set-based classification for person re-identi-
fication utilizing mutual-information // 2013 IEEE International Conference on Im-
6.
Gu X., Chang H., Ma B., Bai S., Shan S., Chen X. Clothes-Changing Person Re-
identification with RGB Modality // ArXiv, abs/2204.06890, 2022.
7.
Huang Y., Wu Q., Zhong Y., Zhang Z. Clothing Status Awareness for Long-Term
Person Re-Idenification // 2021 IEEE/CVF International Conference on Computer
8.
Hao X., Zhao S., Ye M., Shen J. Cross-Modality Person Re-Identification via
Modality Confusion and Center Aggregation // 2021 IEEE/CVF International Con-
ference on Computer Vision (ICCV). 2021. P. 16383-16392.
9.
Zhang T., Xie L., Wei L., Zhuang Z., Zhang Y., Li, B. Tian, Q. UnrealPerson:
An Adaptive Pipeline towards Costless Person Re-identification // 2021 IEEE/CVF
Conference on Computer Vision and Pattern Recognition (CVPR), 2021. P. 11501-
10.
Zhao F., Liao S., Xie G., Zhao J., Zhang K., Shao L. Unsupervised Domain Adap-
tation with Noise Resistible Mutual-Training for Person Re-identification // ECCV
2020. Lecture Notes in Computer Science, 2020. V. 12356. P. 526-544. Springer,
11.
Luo C., Song C., Zhang Z. Generalizing Person Re-Identification by Camera-Aware
Invariance Learning and Cross-Domain Mixup // ECCV 2020. Lecture Notes in
Computer Science, 2020. V. 12356. P. 224-241. Springer, Cham.
12.
Jin X., Lan C., Zeng W., Chen Z., Zhang L. Style Normalization and Restitution
for Generalizable Person Re-Identification // 2020 IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR), 2020. P. 3140-3149.
13.
Song J., Yang Y., Song Y., Xiang T., Hospedales T.M. Generalizable Person Re-
Identification by Domain-Invariant Mapping Network // 2019 IEEE/CVF Confer-
ence on Computer Vision and Pattern Recognition (CVPR), 2019. P. 719-728.
14.
Ihnatsyeva S., Bohush R., Ablameyko S. Joint Dataset for CNN-based Person Re-
identification // Pattern Recognition and Information Processing (PRIP’2021) Pro-
ceedings of the 15th International Conference, 21-24 Sept. 2021, Minsk, Belarus /
United Institute of Informatics Problems of the National Academy of Sciences of
Belarus. Minsk, 2021. P. 33-37.
15.
Liao S., Mo Z., Hu Y., Li S. Open-set Person Re-identification // ArXiv,
16.
Li W., Zhao R., Wang X. Human Reidentification with Transferred Metric Learn-
ing // Proceedings of the 11th Asian conference on Computer Vision (ACCV). 2012.
17.
Li W., Wang X. Locally Aligned Feature Transforms across Views // 2013 IEEE
Conference on Computer Vision and Pattern Recognition, 2013. P. 3594-3601.
104
18.
Li W., Zhao R., Xiao T., Wang X. DeepReID: Deep Filter Pairing Neural Network
for Person Re-identification // 2014 IEEE Conference on Computer Vision and
19.
Wei L., Zhang S., Gao W., Tian Q. Person Transfer GAN to Bridge Domain Gap
for Person Re-identification // 2018 IEEE/CVF Conference on Computer Vision
and Pattern Recognition, 2018. P. 79-88.
20.
Ristani E., Solera F., Zou R.S., Cucchiara R., Tomasi C. Performance Measures
and a Data Set for Multi-target, Multi-camera Tracking // ArXiv, abs/1609.01775,
21.
22.
Zheng L., Zhang H., Sun S., Chandraker M., Yang Y., Tian Q. Person Re-iden-
tification in the Wild // 2017 IEEE Conference on Computer Vision and Pattern
Recognition (CVPR), 2017. P. 3346-3355.
23.
Xiao T., Li S., Wang B., Lin L., Wang, X. Joint Detection and Identification
Feature Learning for Person Search // IEEE Conference on Computer Vision and
Pattern Recognition (CVPR), 2017. P. 3376-3385.
24.
Zheng L., Bie Z., Sun Y., Wang J., Su C., Wang S., Tian Q. MARS: A Video
Benchmark for Large-Scale Person Re-Identification // ECCV 2016. Lecture Notes
in Computer Science, V. 9910. P. 863-884. Springer, Cham. 2016.
25.
Song G., Leng B., Liu Y., Hetang C., Cai S. Region-based Quality Estimation
Network for Large-scale Person Re-identification // AAAI. ArXiv, abs/1711.08766.
26.
Zheng L., Shen L., Tian L., Wang S., Wang J., Tian, Q. Scalable Person Re-
identification: A Benchmark // IEEE International Conference on Computer Vision
27.
Gray D., Brennan S., Tao H. Evaluating Appearance Models for Recognition, Reac-
quisition, and Tracking // IEEE Workshop on Visual Surveillance and Performance
Evaluation of Tracking and Surveillance. 2007.
28.
Hirzer M., Beleznai C., Roth P.M., Bischof H. Person Re-identification by Descrip-
tive and Discriminative Classification // SCIA. Lecture Notes in Computer Science.
2011. V. 6688. P. 91-102, Springer, Berlin, Heidelberg.
29.
Zheng W., Gong S., Xiang T. UnrealPerson: An Adaptive Associating Groups of
30.
Karanam S., Gou M., Wu Z., Rates-Borras A., Camps O.I., Radke R.J. A Sys-
tematic Evaluation and Benchmark for Person Re-Identification: Features, Metrics,
and Datasets // IEEE Transactions on Pattern Analysis and Machine Intelligence,
31.
Ihnatsyeva S., Bohush R. PolReID, 2021.
32.
Li S., Xiao T., Li H., Zhou B., Yue D., Wang X. Person Search with Natural
Language Description // 2017 IEEE Conference on Computer Vision and Pattern
105
Recognition (CVPR). 2017. P. 5187-5196.
33.
Ding Z., Ding C., Shao Z., Tao, D. Semantically Self-Aligned Network for Text-to-
Image Part-aware Person Re-identification // ArXiv, abs/2107.12666, 2021
34.
Li X., Zheng W., Wang X., Xiang T., Gong S. Multi-Scale Learning for Low-
Resolution Person Re-Identification // 2015 IEEE International Conference on
Computer Vision (ICCV). 2015. P. 3765-3773.
35.
Jing X., Zhu X., Wu F., Hu R., You X., Wang Y., Feng H. Yang J. Super-
Resolution Person Re-Identification With Semi-Coupled Low-Rank Discriminant
Dictionary Learning // IEEE Transactions on Image Processing, 2015. No.
26.
36.
Wu A., Zheng W., Yu H., Gong S., Lai J. RGB-Infrared Cross-Modality Person
Re-identification // IEEE International Conference on Computer Vision (ICCV).
37.
Nguyen T.D., Hong H.G., Kim K., Park K.R. Person Recognition System Based
on a Combination of Body Images from Visible Light and Thermal Cameras //
38.
Pang L., Wang Y., Song Y., Huang T., Tian, Y. Cross-Domain Adversarial Feature
Learning for Sketch Re-identification // Proceedings of the 26th ACM international
39.
Xiao T., Li S., Wang B., Lin L., Wang X. End-to-end deep learning for person
search // ArXiv, abs/1604.01850, 2016
40.
Layne R., Hospedales T.M., Gong S. Investigating Open-World Person Re-
identification Using a Drone // ECCV Workshops. 2014.
41.
Fu D., Chen D., Bao J., Yang H., Yuan L., Zhang L., Li H., Chen D. Unsupervised
Pre-training for Person Re-identification // IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR). 2021. P. 14745-14754.
42.
Fabbri M., Brasó G., Maugeri G., Cetintas O., Gasparini R., Osep A., Calderara S.,
Leal-Taixe L., Cucchiara R. MOTSynth: How Can Synthetic Data Help Pedestrian
Detection and Tracking // 2021 IEEE/CVF International Conference on Computer
Vision (ICCV). 2021. P. 10829-10839.
43.
Makehuman community. Makehuman, 2020.
44.
Epic Games Incorporated. Unreal engine, 2020.
45.
Barbosa I.B., Cristani M., Caputo B., Rognhaugen A., Theoharis T. Looking be-
yond appearances: Synthetic training data for deep CNNs in re-identification //
46.
Bak S., Carr P., Lalonde J. Domain Adaptation through Synthesis for Unsupervised
Person Re-identification // ECCV. ArXiv, abs/1804.10094, 2018.
106
47.
Sun X., Zheng L. Dissecting Person Re-Identification From the Viewpoint of View-
point // IEEE/CVF Conference on Computer Vision and Pattern Recognition
48.
Wang Y., Liao S., Shao L. Surpassing Real-World Source Training Data: Random
3D Characters for Generalizable Person Re-Identification // Proceedings of the 28th
ACM International Conference on Multimedia. 2020.
49.
Wang Y., Liang X., Liao S. Cloning Outfits from Real-World Images to 3D Char-
acters for Generalizable Person Re-Identification // ArXiv, abs/2204.02611. 2022.
50.
Unity Technologies. 2020. Unity3D: Cross-platform game engine.
51.
Zhong Z., Zheng L., Kang G., Li S., Yang Y. Random Erasing Data Augmenta-
52.
Ni X., Rahtu E. FlipReID: Closing the Gap Between Training and Inference in
Person Re-Identification // 2021 9th European Workshop on Visual Information
Processing (EUVIP). 2021. P. 1-6.
53.
Li W., Xu F., Zhao J., Zheng R., Zou C., Wang M., Cheng Y. HBReID: Harder
Batch for Re-identification // ArXiv, abs/2112.04761, 2021.
54.
Huang Y., Zha Z., Fu X., Hong R., Li L. Real-World Person Re-Identification via
Degradation Invariance Learning // IEEE/CVF Conference on Computer Vision
and Pattern Recognition (CVPR). 2020. P. 14072-14082.
55.
Jiang Y., Chen W., Sun X., Shi X., Wang F., Li H. Exploring the Quality of GAN
Generated Images for Person Re-Identification // Proceedings of the 29th ACM
International Conference on Multimedia. 2021.
56.
Wu C., Ge W., Wu A., Chang X. Camera-Conditioned Stable Feature Generation
for Isolated Camera Supervised Person Re-Identification // ArXiv, abs/2203.15210,
57.
Wang G., Lai J., Huang P., Xie X. Spatial-Temporal Person Re-identification //
58.
Yu Z., Jin Z., Wei L., Guo J., Huang J., Cai D., He X., Hua X. Progressive
Transfer Learning for Person Re-identification // IJCAI. 2019.
59.
Sun Y., Zheng L., Yang Y., Tian Q., Wang S. Beyond Part Models: Person Re-
trieval with Refined Part Pooling // ECCV. 2018.
60.
Bayoumi R.M., Hemayed E.E., Ragab M.E., Fayek M.B. Person Re-Identification
via Pyramid Multipart Features and Multi-Attention Framework // Big Data and
61.
Wang G., Yang S., Liu H., Wang Z., Yang Y., Wang S., Yu G., Zhou E., Sun J.
High-Order Information Matters: Learning Relation and Topology for Occluded
107
Person Re-Identification // IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR). 2020. P. 6448-6457.
62.
Sun K., Xiao B., Liu D., Wang J. Deep High-Resolution Representation Learning
for Human Pose Estimation // 2019 IEEE/CVF Conference on Computer Vision
and Pattern Recognition (CVPR). 2019. P. 5686-5696.
63.
Yang J., Zhang J., Yu F., Jiang X., Zhang M., Sun X., Chen Y., Zheng W.S.
Learning to Know Where to See: A Visibility-Aware Approach for Occluded Person
Re-identification // Proceedings of the IEEE/CVF International Conference on
Computer Vision. 2021. P. 11885-11894.
64.
Fang H., Xie S., Tai Y., Lu C. RMPE: Regional Multi-person Pose Estimation //
IEEE International Conference on Computer Vision (ICCV). 2017. P. 2353-2362.
65.
Chen X., Liu X., Liu W., Zhang X., Zhang Y., Mei T. Explainable Person Re-
Identification with Attribute-guided Metric Distillation // IEEE/CVF International
Conference on Computer Vision (ICCV). 2022. P. 11793-11802.
66.
Dai Y., Sun Y., Liu J., Tong Z., Yang Y., Duan L. Bridging the Source-to-target
Gap for Cross-domain Person Re-Identification with Intermediate Domains //
67.
Zhang H., Cisse M., Dauphin Y., Lopez-Paz D. mixup: Beyond Empirical Risk
Minimization // ArXiv, abs/1710.09412, 2018.
68.
Huang X., Belongie S.J. Arbitrary Style Transfer in Real-Time with Adaptive In-
stance Normalization // 2017 IEEE International Conference on Computer Vision
69.
Avola D., Cascio M., Cinque L., Fagioli A., Petrioli C. Person Re-Identification
Through Wi-Fi Extracted Radio Biometric Signatures // IEEE Transactions on
Information Forensics and Security. V. 17. 2022. P. 1145-1158.
70.
Qi L., Shen J., Liu J., Shi Y., Geng X. Label Distribution Learning for Generaliz-
able Multi-source Person Re-identification // ArXiv, abs/2204.05903. 2022.
71.
Yang X., Zhou Z., Wang Q., Wang Z., Li X. Li H. Cross-domain unsupervised
pedestrian re-identification based on multi-view decomposition // Multimed Tools
72.
Elharrouss O., Almaadeed N., Al-Maadeed S.A., Bouridane A. Gait recognition for
person re-identification // J. Supercomput. 2021 No. 77. P. 3653-3672.
73.
Chao H., He Y., Zhang J., Feng J. GaitSet: Regarding Gait as a Set for Cross-View
Gait Recognition // ArXiv, abs/1811.06186, 2019.
74.
Jiang X., Qiao Y., Yan J., Li Q., Zheng W., Chen D. SSN3D: Self-Separated
Network to Align Parts for 3D Convolution in Video Person Re-Identification //
Proceedings of the AAAI Conference on Artificial Intelligence.
2021. No. 35(2).
108
75.
Yang F., Wang X., Zhu X., Liang B., Li W. Relation-based global-partial feature
learning network for video-based person re-identification // Neurocomputing. 2022.
76.
Lu Z., Zhang G., Huang G., Yu Z., Pun C., Ling K. Video person re-identification
using key frame screening with index and feature reorganization based on inter-
frame relation // Int. J. Mach. Learn. Cyber. 2022.
77.
Yadav A., Vishwakarma D.K. Person Re-Identification using Deep Learning Net-
works: A Systematic Review // ArXiv, abs/2012.13318. 2020.
78.
Zhang Z., Lan C., Zeng W., Jin X., Chen Z. Relation-Aware Global Attention
for Person Re-Identification // IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR), 2020. P. 3183-3192.
79.
Pathak P., Eshratifar A.E., Gormish M.J. Video Person Re-ID: Fantastic Tech-
niques and Where to Find Them // AAAI. 2020.
80.
Liu X., Zhang P., Yu C., Lu H., Yang X. Watching You: Global-guided Reciprocal
Learning for Video-based Person Re-identification // IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR). 2021. P. 13329-13338.
81.
Gao S., Wang J., Lu H., Liu Z. Pose-Guided Visible Part Matching for Occluded
Person ReID // IEEE/CVF Conference on Computer Vision and Pattern Recogni-
tion (CVPR). 2020. P. 11741-11749.
82.
Zhang S., Yin Z., Wu X., Wang K., Zhou Q., Kang B. FPB: Feature Pyramid
Branch for Person Re-Identification // ArXiv, abs/2108.01901. 2021.
83.
Yang F., Li W., Liang. B., Han S., Zhu X. Multi-stage attention network for
video-based person re-identification // IET Comput. Vis. 2022. P. 1-11.
84.
Wu G., Zhu X., Gong Sh. Learning hybrid ranking representation for person re-
identification // Pattern Recognition. V. 121. 2022.
85.
Zhong Z., Zheng L., Cao D., Li S. Re-ranking Person Re-identification with k-Re-
ciprocal Encoding // IEEE Conference on Computer Vision and Pattern Recogni-
86.
Bohush R.P., Ablameyko S.V. Adamovskiy E.R. Image Similarity Estimation Based
on Ratio and Distance Calculation between Features // Pattern Recognit. Image
87.
He K., Zhang X., Ren S., Sun J. Deep Residual Learning for Image Recognition //
IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2016.
88.
Choi S., Kim T., Jeong M., Park H., Kim C. Meta Batch-Instance Normalization
for Generalizable Person Re-Identification // IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR). 2021. P. 3424-3434.
109
89.
Huang G., Liu Z., Weinberger K.Q. Densely Connected Convolutional Networks //
IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2017.
90.
Chen P., Dai P., Liu J., Zheng F., Tian Q., Ji R. Dual Distribution Alignment Net-
work for Generalizable Person Re-Identification // AAAI. ArXiv, abs/2007.13249,
91.
Zhao C., Chen K., Wei Z., Chen Y., Miao D., Wang W. Multilevel triplet deep
learning model for person re-identification // Pattern Recognit. Lett.
2019.
92.
Yao Y., Jiang X., Fujita H., Fang Z. A sparse graph wavelet convolution neural net-
work for video-based person re-identification // Pattern Recognition. 2022. V. 129.
93.
Lu P., Lu K., Wang W., Zhang J., Chen P., Wang B. Real-Time Pedestrian De-
tection in Monitoring Scene Based on Head Model // Intelligent Computing The-
ories and Application. ICIC 2019. Lecture Notes in Computer Science. V. 11644.
94.
Lee S., Kang Q., Madireddy S., Balaprakash P., Agrawal A., Choudhary A.N.,
Archibald R., Liao W. Improving Scalability of Parallel CNN Training by Adjusting
Mini-Batch Size at Run-Time // 2019 IEEE International Conference on Big Data
(Big Data). 2019. P. 830-839.
95.
Lewkowycz A. How to decay your learning rate // ArXiv, abs/2103.12682, 2021.
96.
Lewkowycz A., Bahri Y., Dyer E., Sohl-Dickstein J., Gur-Ari G. The large learning
rate phase of deep learning: the catapult mechanism // ArXiv, abs/2003.02218,
97.
Ulyanov D., Vedaldi A., Lempitsky V.S. Instance Normalization: The Missing In-
gredient for Fast Stylization // ArXiv, abs/1607.08022, 2016.
98.
Chen H., Ihnatsyeva S., Bohush R., Ablameyko S. Choice of activation function
in convolution neural network in video surveillance systems // Programming and
computer software. 2022. No. 5. P. 312-321.
99.
Nair, Vinod, Geoffrey E. Hinton. Rectified linear units improve restricted Boltz-
mann machines // ICML / 2010. P. 807-814.
100.
Maas Andrew L. Rectifier non linearities improve neural network acoustic models //
ICML. 2013. V. 30.
101.
Xu B., Wang N., Chen T., Li M. Empirical Evaluation of Rectified Activations in
Convolutional Network // ArXiv, abs/1505.00853, 2015.
102.
Clevert D., Unterthiner T., Hochreiter S. Fast and Accurate Deep Network Learning
by Exponential Linear Units (ELUs) // arXiv: abs/1511.07289v5, 2016.
103.
Klambauer G., Unterthiner T., Mayr A., Hochreiter S. Self-Normalizing Neural
Networks // ArXiv, abs/1706.02515, 2017.
110
104.
Hendrycks D., Gimpel K. Bridging Nonlinearities and Stochastic Regularizers with
Gaussian Error Linear Units. // ArXiv, abs/1606.08415, 2016.
105.
Ramachandran P., Zoph B., Le Q.V. Swish: a Self-Gated Activation Function //
106.
Misra D. Mish: A Self Regularized Non-Monotonic Neural Activation Function //
107.
Lavi B., Ullah I., Fatan M., Rocha A. Survey on Reliable Deep Learning-Based
Person Re-Identification Models: Are We There Yet? // ArXiv, abs/2005.00355,
108.
Rao H., Miao C. SimMC: Simple Masked Contrastive Learning of Skeleton Repre-
sentations for Unsupervised Person Re-Identification // ArXiv, abs/ 2204.09826v1,
109.
Zheng Y., Zhou Y., Zhao J., Jian M., Yao R., Liu B., Chen Y. A siamese pedes-
trian alignment network for person re-identification // Multim. Tools Appl. 2021.
110.
Zheng M., Karanam S., Wu Z., Radke R.J. Re-Identification With Consistent At-
tentive Siamese Networks // IEEE/CVF Conference on Computer Vision and Pat-
tern Recognition (CVPR). 2019. P. 5728-5737.
111.
Hermans A., Beyer L., Leibe B. In Defense of the Triplet Loss for Person Re-Iden-
tification // ArXiv, abs/1703.07737, 2017.
112.
Organisciak D., Riachy C., Aslam N., Shum H. Triplet Loss with Channel Attention
for Person Re-identification // J.WSCG. 2019. No. 27.
113.
Zhai Y., Guo X., Lu Y., Li H. In Defense of the Classification Loss for Person
Re-Identification // 2019 IEEE/CVF Conference on Computer Vision and Pattern
Recognition Workshops (CVPRW). 2019. P. 1526-1535.
114.
Alex D., Sami Z., Banerjee S., Panda S. Cluster Loss for Person Re-Identification //
Proceedings of the 11th Indian Conference on Computer Vision, Graphics and Image
115.
Bai Z., Wang Z., Wang J., Hu D., Ding E. Unsupervised Multi-Source Domain
Adaptation for Person Re-Identification // 2021 IEEE/CVF Conference on Com-
puter Vision and Pattern Recognition (CVPR). 2021. P. 12909-12918.
116.
Chen H., Lagadec B., Bremond F. Unsupervised Lifelong Person Re-identification
via Contrastive Rehearsal // ArXiv, abs/2203.06468, 2022.
117.
Zhang X., Li D., Wang Z., Wang J., Ding E., Shi J., Zhang Z., Wang J.
Implicit Sample Extension for Unsupervised Person Re-Identification // ArXiv,
118.
Zhu K., Guo H., Yan T., Zhu Y., Wang J., Tang M. Part-Aware Self-Supervised
Pre-Training for Person Re-Identification // ArXiv, abs/2203.03931, 2022.
111
119. Fu D., Chen D., Yang H., Bao J., Yuan L., Zhang L., Li H., Wen F., Chen D.
Large-Scale Pre-training for Person Re-identification with Noisy Labels // ArXiv,
120. Cho Y.H., Kim W.J., Hong S., Yoon S. Part-based Pseudo Label Refinement for
Unsupervised Person Re-identification // ArXiv, abs/2203.14675, 2022.
121. Chen M., Wang Z., Zheng F. Benchmarks for Corruption Invariant Person Re-
identification // ArXiv, abs/2111.00880. 2021.
Статья представлена к публикации членом редколлегии О.П. Кузнецовым.
Поступила в редакцию 11.05.2022
После доработки 10.12.2022
Принята к публикации 26.01.2023
112