ПРОБЛЕМЫ ПЕРЕДАЧИ ИНФОРМАЦИИ
Том 58
2022
Вып. 2
УДК 621.391 : 519.724.6 : 519.725.3
© 2022 г.
А.А. Курмукова, Ф.И. Иванов, В.В. Зяблов
ТЕОРЕТИЧЕСКИЕ И ЭКСПЕРИМЕНТАЛЬНЫЕ ОЦЕНКИ СВЕРХУ И СНИЗУ
ДЛЯ ЭФФЕКТИВНОСТИ СВЕРТОЧНЫХ КОДОВ В ДВОИЧНОМ
СИММЕТРИЧНОМ КАНАЛЕ1
Предлагается новый подход для построения аналитических оценок вероят-
ности появления пакета ошибок заданной длины, вероятности ошибочного де-
кодирования и вероятности ошибки на бит для сверточных кодов в двоичном
симметричном канале с декодированием Витерби. Выражения, полученные для
верхней и нижней оценок вероятности ошибки на бит, а также для вероятности
ошибочного декодирования, основаны на активных расстояниях и спектре ак-
тивных расстояний сверточного кода. Предложенные оценки справедливы для
сверточных кодов скорости 1/2, но их можно обобщить и для сверточных ко-
дов скорости 1/n. Вычисление описанных оценок имеет линейную сложность от
длины наиболее коротких пакетов ошибок при известных метрических харак-
теристиках сверточного кода, при этом сложность вычисления не зависит от
входной вероятности ошибки на бит. Результаты моделирования показывают,
что рассматриваемые оценки достаточно точны, особенно для малых вероятно-
стей искажений в канале.
Ключевые слова: сверточные коды, активное расстояние, вероятность ошибки
на бит, решетка кода.
DOI: 10.31857/S055529232202003X, EDN: DZBRSC
§ 1. Введение
Сверточные коды, предложенные Элайесом в [1], являются предметом изучения
уже на протяжении более 60 лет. Несмотря на то, что они уступают с точки зрения
вероятности ошибки на блок при заданном уровне помех в канале передачи инфор-
мации полярным кодам [2] или кодам с малой плотностью проверок на четность
(МПП-кодам) [3], сверточные коды могут существенно снизить вероятность ошибки
на бит при фиксированном отношении сигнал-шум [4]. Полярные коды и большин-
ство классов МПП-кодов этим свойством не обладают [4]. Кроме сверточных кодов
таким свойством обладают всего несколько классов кодов: например, коды Хэм-
минга [5], некоторые МПП-коды с порождающей матрицей низкой плотности [6],
кодовые конструкции с повторениями [7].
Уменьшение величины ошибки на бит - это очень важное свойство для внут-
ренних кодов в любых каскадах. Это одна из главных причин, почему сверточные
коды широко используются в различных каскадных кодовых конструкциях, напри-
мер, в плетеных кодах [8] и в других последовательных и параллельных каскадных
конструкциях [9, 10]. Также рекурсивный систематический кодер сверточного кода
часто используется в турбо-кодах [11, 12]. В каскаде с линейным кодом такой кодер
1 Работа выполнена в рамках Программы фундаментальных исследований НИУ ВШЭ в 2022 г.
24
также может использоваться и показывать высокую эффективность, как, напри-
мер, в параллельном каскаде с систематическим полярным кодом и итеративным
декодированием [13].
Таким образом, аналитические методы расчета вероятности ошибки для свер-
точного кода являются важным направлением исследований. Существует ряд работ,
в которых изучались вопросы теоретического анализа эффективности сверточных
кодов. В работе [14] представлен классический способ подсчета вероятности ошиб-
ки с помощью производящей функции спектра кода и функции спектра ошибки на
бит. Для двоичного симметричного канала используется уточненная граница Мибер-
га [15]. В работе [16] используется простая цепь Маркова для оценки вероятности
ошибки на бит сверточного кода с ограничением длины пакетов. Но эксперимен-
тальные данные, представленные в работе, показывают, что предложенная оценка
является достаточно грубой и неточной для малых значений вероятности искажений
в канале. Некоторые модификации этого подхода описаны в [17], где авторы исполь-
зуют марковскую цепь для описания конструкции сверточного кода. В этом случае
процесс декодирования Витерби [18] может рассматриваться с помощью специаль-
ных переходов между состояниями марковской цепи. Оценка вероятности ошибки
на бит для сверточного кода с выкалываниями была предложена в работе [19]. На-
конец, в [20] показано, как оценить вероятность ошибки на бит для любого сверточ-
ного кода как для двоичного симметричного канала, так и для канала с гауссовским
шумом. Но описанный в этой работе подход сложен в реализации, а также практи-
чески не применим для сверточных кодов с большой памятью из-за вычислительной
сложности.
В данной статье предложен подход к оцениванию вероятности ошибки на бит и
на блок для сверточного кода в двоичном симметричном канале при декодировании
кода по максимуму правдоподобия. Предложенный метод основан на спектре актив-
ных расстояний сверточного кода и аналитических оценках вероятности появления
пакета ошибок заданной длины [21, 22]. Вычисление вероятности ошибки на блок
для терминированного сверточного кода было описано в работе [23]. В этой работе
мы предлагаем вычислительно простые аналитические оценки сверху и снизу для
вероятности ошибки на бит.
§ 2. Сверточные коды
2.1. Сверточный код с рекурсивным кодером. Для простоты последующих вы-
кладок в данной статье рассмотрим двоичный сверточный код скорости 1/2 с рекур-
сивным систематическим кодером. Однако сразу отметим, что полученные результа-
ты могут быть обобщены для кода скорости 1/n, n > 1, n ∈ N. Также все полученные
результаты верны для двоичного симметричного канала и декодера Витерби.
Порождающая матрица сверточного кода скорости 1/2 с систематическим коде-
ром с обратной связью может быть задана с помощью отношения многочленов:
(
)
g(2)
G(D) =
1
,
(1)
g(1)
где порождающие полиномы -
g(ℓ)(D) = g(ℓ)0 + g(ℓ)1D + g(ℓ)2D2 + . . . + g(ℓ)mDm, g(ℓ)i ∈ {0, 1},
для ℓ = 1, 2. Память кода здесь обозначена через m, скорость кода 1/2. Обратная
связь в кодере задана знаменателем в отношении полиномов. Мы рассматриваем
взаимно простые порождающие полиномы одинаковой степени. Состояние кодера в
каждый момент времени может быть задано либо с помощью m битов, либо деся-
тичным числом s: 0 ≤ s < 2m. Всего возможно 2m различных состояний.
25
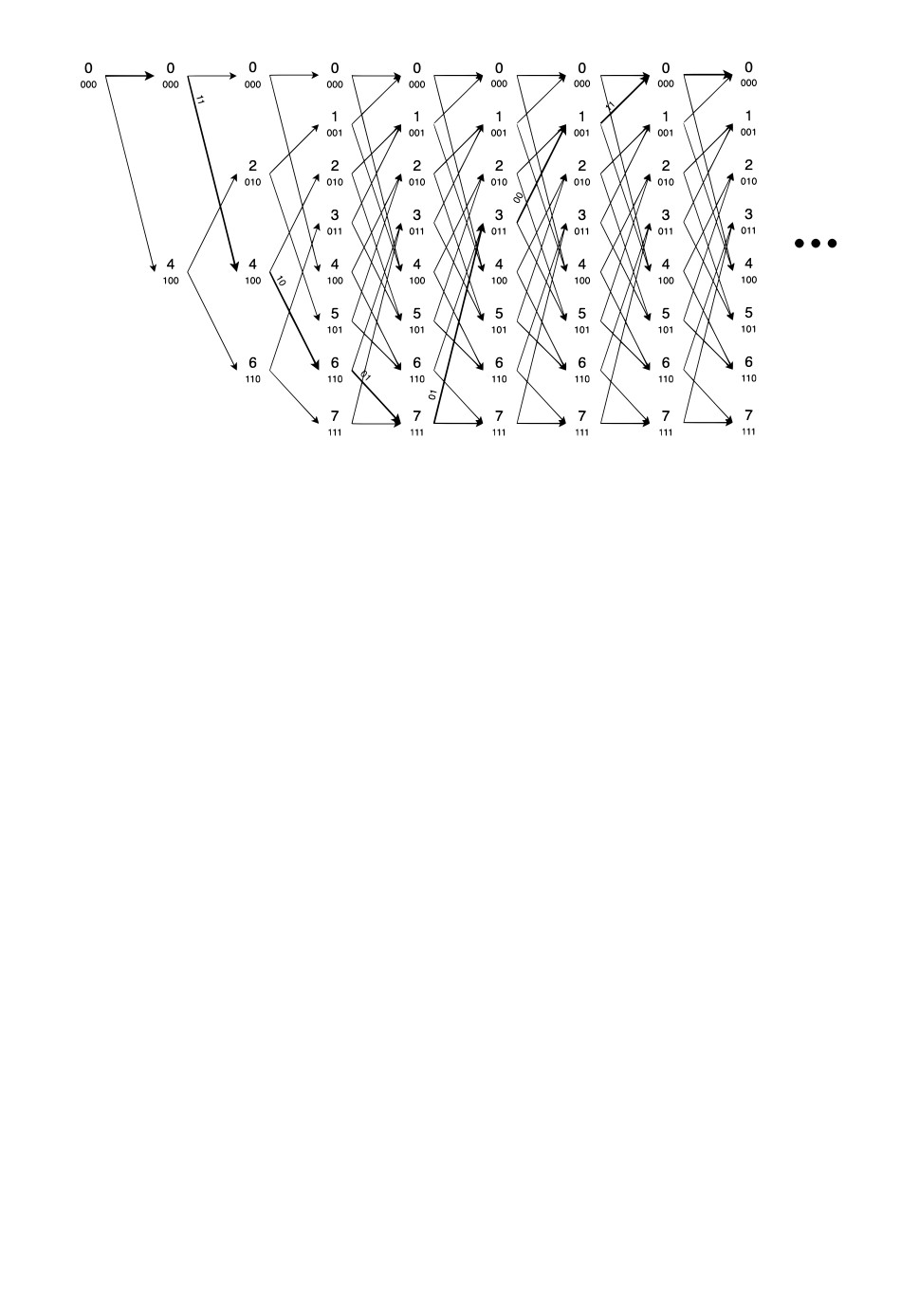
Рис. 1. Решетка для сверточного кода (13, 17) с рекурсивным кодером
Кодовое слово сверточного кода может быть записано как полином с помощью
оператора задержки D:
v(D) = v0 + v1D + v2D2 + . . . , vi ∈ {0, 1}2, i ∈ N ∪ {0},
где (v0, v1, v2, . . .) - последовательность выходных кортежей длины 2. Кодовое слово
сверточного кода полубесконечно и может быть однозначно задано последователь-
ностью входных битов и начальным состоянием кодера.
Для представления кодовых слов сверточного кода и понимания процесса деко-
дирования удобно использовать решетчатую диаграмму состояний кодера. Решетка
изображается в виде состояний кодера, отложенных в последовательные моменты
времени. Переход из состояния st в момент времени t в состояние st+1 в момент
времени t + 1 соответствует некоторому входному биту и выходному кортежу. На-
чальное состояние кодера в момент времени t = 0 считают нулевым. Каждому кодо-
вому слову соответствует уникальная последовательность выходных кортежей, по-
следовательность состояний решетки и последовательность входных битов. Таким
образом, каждое кодовое слово может быть записано как путь в решетке (после-
довательность состояний решетки). Решетчатая диаграмма состояний важна также
для понимания метрических свойств сверточного кода.
На рис. 1 приведен пример решетки для сверточного кода памяти m = 3 с по-
рождающими полиномами g(1) = 1 + D + D3, g(2) = 1 + D + D2 + D3, которые
можно также представить в восьмеричном виде как (13, 17). На рис. 1 выделенный
полужирным путь соответствует началу одного из кодовых слов. Более подробное
изложение концепции решетчатых диаграмм приведено в работе [18].
2.2. Активные расстояния и спектр активных расстояний. Одним из важнейших
метрических характеристик сверточного кода является свободное расстояние.
Определение 1. Свободное расстояние сверточного кода - это минимальный
вес ненулевого кодового слова.
Кроме свободного расстояния, у сверточных кодов есть ряд других не менее важ-
ных метрических характеристик, которые определяют вероятность ошибочного де-
кодирования.
26
Для блочных кодов при оценивании вероятности ошибки на блок обычно рас-
сматривают весовой спектр кода [24]. В данной статье мы предлагаем использо-
вать активные расстояния, предложенные в [25], и спектр активных расстояний для
анализа сверточных кодов. Если рассматривать обычный спектр весов сверточного
кода, то веса не будут увеличиваться при увеличении длины рассматриваемого пу-
ти, если путь начиная с некоторого момента пойдет только по нулевым состояниям
решетки. Поэтому имеет смысл исключать из рассмотрения пути, как только они
сливаются с нулевым путем. В этом заключается основное различие двух понятий:
спектр весов и спектр весов активных расстояний.
Для начала введем дополнительное построение, чтобы определить активные рас-
стояния.
Определение 2. Подмножество кодовых слов сверточного кода C с одним ко-
нечным ответвлением от нулевого пути обозначим через Cf . Это подмножество Cf
состоит из кодовых слов v(D), которым соответствует конечный ненулевой путь
некоторой длины j, этот ненулевой путь начинается сразу после начального нуле-
вого состояния решетки: s0 = 0, s1 = 0, и не имеет двух последовательных нулевых
состояний до слияния с нулевым путем решетки sj = sj+1 = sj+2 = . . . = 0 в момент
времени j.
Кодовые слова из подмножества Cf имеют конечный вес, и этот вес равен весу
ненулевого пути в решетке. Для определения активного расстояния рассматривается
только начальная ненулевая часть пути. Отметим, что подмножество Cf не вклю-
чает в себя нулевое кодовое слово. Минимально возможная длина ненулевого пути
составляет m+1, где m - память кода. Здесь и далее длиной пути считается количе-
ство выходных кортежей (или число переходов между состояниями решетки). Тогда
кодовое слово с ненулевым путем длины j из подмножества Cf обозначим через v(j).
Определение 3. Активное расстояние длины j сверточного кода C - это мини-
мальный вес Хэмминга кодового слова v(j) из подмножества Cf , имеющего конечный
ненулевой путь длины j:
aj = min w(v(j)),
v(j)∈Cf
где w(v(j)) - вес Хэмминга кодового слова v(j).
Свободное расстояние сверточного кода можно также определить через актив-
ные расстояния, так как при рассмотрении подмножества кодовых слов Cf мы не
исключаем кодовые слова минимального веса. Тогда свободное расстояние можно
ввести как минимальное активное расстояние minaj, j ≥ m+1. Также отметим, что
j
свободное расстояние не всегда соответствует минимальной длине j.
Так как вес кодового слова v(j) ∈ Cf определяется весом ненулевого пути в решет-
ке, то можно записать вес кодового слова с помощью первых j выходных кортежей:
∑
w(v(j)) =
w(v(j)i).
i=0
Число кодовых слов v(j) ∈ Cf с весом w(j) будем обозначать через Nw(j) . Приве-
дем определение спектра активных расстояний, впервые предложенное в работе [21].
Определение 4. Спектр Daj активных расстояний aj длины j сверточного
кода - это множество наборов
{
}
Daj = j, aj, w(j), Nw(j) | w(j) = w(v(j)), v(j)
∈Cf
27
Таблица 1
Таблица 2
Спектр активных расстояний для сверточ-
Спектр активных расстояний для сверточ-
ного кода (13, 15) с рекурсивным кодером
ного кода (13, 17) с рекурсивным кодером
w\j
4
5
6
7
8
9
10
11
12
13
14
15
w\j
4
5
6
7
8
9
10
11
12
13
14
15
6
1
1
6
1
7
7
1
1
1
8
1
1
2
2
2
1
1
8
1
1
1
2
9
9
4
1
3
3
10
2
4
6
8
8
8
6
4
2
10
1
1
3
6
4
5
5
11
11
1
4
5
5
15
7
10
8
12
2
5
13
19
29
34
36
34
12
1
2
4
13
10
18
27
16
13
13
3
3
13
14
30
32
37
14
2
6
20
38
68
100
132
14
1
5
7
22
34
40
81
15
15
3
5
15
40
60
96
16
1
8
25
64
132
230
16
2
17
21
79
105
17
17
2
7
20
62
119
18
8
30
93
220
18
2
21
36
100
19
19
2
7
26
90
20
6
32
121
20
5
12
71
21
21
1
11
27
22
4
32
22
6
11
23
23
6
24
2
24
3
25
25
3
Минимальный вес в спектре активных расстояний Daj - это активное расстоя-
ние aj длины j сверточного кода в соответствии с определением активных расстоя-
ний. Подсчет спектра кода является вычислительно более трудной задачей, чем рас-
чет спектра активных расстояний, так как при подсчете спектра активных расстоя-
ний исключаются кодовые слова, идущие по нулевому пути. Объединение спектров
активных расстояний длины j для всех возможных длин формирует весь спектр
активных расстояний.
Определение 5. Спектр Da активных расстояний сверточного кода - это объ-
единение множеств наборов Daj для всех возможных длин j:
⋃
Da =
Daj ,
j=m+1
где m - память кода.
Спектр активных расстояний удобно представлять в виде таблицы. Приведем
примеры спектров активных расстояний для двух кодов.
Пример 1. В табл. 1 и 2 представлены спектры активных расстояний для свер-
точных кодов с рекурсивным кодером и памятью m = 3: (13, 15) и (13, 17). Число
в таблице, находящееся на пересечении i-й строки и j-го столбца, обозначает коли-
чество кодовых слов в подмножестве Cf с весом, указанным в i-й строке, и длиной
ненулевого пути, указанной в j-м столбце. Полужирным шрифтом выделены те ко-
эффициенты спектра, для которых веса соответствуют активным расстояниям.
§ 3. Теоретические оценки вероятности ошибки на блок и на бит
для сверточных кодов в двоичном симметричном канале
Приведем оценки сверху и снизу для вероятности появления пакета ошибок за-
данной длины и вероятности ошибочного декодирования терминированного свер-
точного кода, а также выведем оценку для вероятности ошибки на бит. Предпола-
28
гается, что передача данных осуществляется через двоичный симметричный канал,
а в качестве декодера используется алгоритм Витерби.
3.1. Вероятность появления пакета ошибок. Вероятность появления пакета оши-
бок и ее оценка были подробно описаны в работе [21]. Приведем здесь вывод и
итоговую формулу.
Рассматривается двоичный симметричный канал с декодированием по максиму-
му правдоподобия с вероятностью ошибки на бит p. Декодер Витерби всегда возвра-
щает слово, принадлежащее исходному коду C. Если при декодировании появился
пакет ошибок, то декодированное слово v′ ∈ C не будет совпадать с переданным
v ∈ C. На месте возникновения пакета ошибок будет ответвление от корректно-
го пути на решетке. Пакеты ошибок считаются независимыми, если между ними
есть хотя бы два корректных состояния решетки подряд. Так как сверточный код
является линейным, то v + v′ ∈ C, и на месте пакета ошибок в сумме возникнет
ненулевой путь на решетке, вес которого определяется спектром активных рассто-
яний Da сверточного кода. В декодированном слове возникнет пакет ошибок, если
aj
произошло хотя бы
ошибок на позициях единиц в сумме v + v′ в месте, соот-
2
ветствующему пакету ошибок, где aj - минимальный вес пакета ошибок длины j
(активное расстояние).
Вероятность появления фиксированного числа ошибок среди нулей и единиц
в двоичной последовательности может быть записана так:
)
(w)( 2j - w
P (eall, e1, j, w, p) =
peall (1 - p)2j-eall ,
e1
eall - e1
где eall - общее число ошибок, e1 - число ошибок среди единиц, j - длина после-
довательности в терминах количества кортежей, w - вес последовательности, p -
вероятность ошибки на бит в канале.
Как было отмечено ранее, пакет ошибок возникнет при декодировании, если на
местах единиц в пакете количество ошибок больше половины веса, а количество оши-
бок на местах нулей может быть любым. Если число ошибок среди единиц состав-
ляет ровно половину веса пакета, то пакет ошибок возникнет с вероятностью 1/2.
Таким образом, вероятность пакета ошибок длины j и веса w для двоичного симмет-
ричного канала с вероятностью ошибки на бит p может быть записана следующим
образом:
∑
∑
Pburst(j, w, p) =
P (eall = i, e1 = i1, j, w, p) +
w
i>w
2
i1>
2
⎧
⎪0
для нечетного веса w,
⎨
2j-w2∑
(
)
+
1
w
(2)
⎪
P eall = i,e1 =
, j, w, p
для четного веса w.
⎩2
2
i=w
2
Оценку снизу для вероятности появления пакета ошибок будем считать как ве-
роятность появления наиболее вероятного пакета ошибок, т.е. пакета ошибок с ми-
нимальным весом. Тогда оценку сверху можно посчитать как сумму вероятностей
появления всех возможных пакетов ошибок. Тогда оценки снизу и сверху для веро-
ятности появления пакета ошибок длины j могут быть заданы с помощью активных
расстояний и спектра активных расстояний соответственно:
Plow(j, p) = (1 - p)4mPburst(j, w = aj, p)
(3)
29
и
∑
Pup(j, p) =
NwiPburst(j, w = wi, p),
(4)
wi=wmin
где {wi, Nwi } ∈ Daj , а m - память кода. Для нижней оценки мы также используем
множитель (1 - p)4m - вероятность того, что 2m битов до и после пакета ошибок бу-
дут корректными, чтобы исключить ситуации, при которых рассматриваемый уча-
сток является частью другого пакета ошибок. Более подробный вывод можно найти
в работе [23].
3.2. Вероятность ошибочного декодирования. В общем случае кодовое слово свер-
точного кода имеет неограниченную длину, но на практике мы имеем дело с конеч-
ным объемом данных, поэтому используются усеченные сверточные коды. Мы будем
использовать сверточные коды “с нулевым хвостом” (нулевым терминированием),
но иногда используются также и циклически усеченные сверточные коды. В канале
передаются блоки фиксированной длины, состоящие из кортежей усеченного свер-
точного кода, которые соответствуют конечному пути по решетке для сверточного
кода, причем начальное и конечное состояния решетки нулевые. Так как переход
кодера из любого состояния в нулевое гарантированно может произойти за m так-
тов (при последовательном записывании в память кодера нули), где m - память
кода, то терминирование кода приводит к небольшому уменьшению скорости. Та-
ким образом, мы передаем на m информационных битов меньше, что обычно мало
по сравнению с длиной блока L ≫ m.
Будем оценивать вероятность ошибочного декодирования блока длины L с помо-
щью средней доли блоков, пораженных хотя бы одним пакетом ошибок. Нижнюю
оценку вероятности ошибочного декодирования мы получим как среднюю долю бло-
ков, в которых появился наиболее вероятный пакет ошибок. Наиболее вероятный па-
кет ошибок обладает минимальным возможным весом wmin = minaj. Вероятность
j
ошибочного декодирования блока обозначается через FER (Frame Error Rate). Для
вероятности появления наиболее вероятного пакета ошибок мы будем использовать
нижнюю оценку (3) для Plow(j, p). Чтобы получить более точную нижнюю оценку,
мы умножаем вероятность появления в отдельно взятом кортеже наиболее вероят-
ного пакета ошибок на количество таких различных пакетов Nwmin, и умножив на
длину блока L “в терминах количества кортежей”, получим нижнюю оценку веро-
ятности ошибочного декодирования:
FERlow(p) = LNwminPlow(j = jwmin, p),
(5)
где jwmin - длина пакета ошибок с минимальным весом, {wmin, Nwmin} ∈ Da.
Верхнюю оценку мы выводим как аддитивную границу, суммируя средние доли
блоков с различными ошибками по всем возможным длинам пакетов ошибок. Для
вероятности появления пакета будем использовать верхнюю оценку (4) для Pup(j, p).
Так как в нее уже входит количество пакетов, то нет необходимости в дополнитель-
ном множителе. Таким образом, получаем верхнюю оценку вероятности ошибочного
декодирования:
{
}
∑
FERup(p) = min
1,
LPup(j = ℓ, p)
,
(6)
ℓ=m+1
где m - память кода.
Верхняя оценка может быть несколько уточнена, но так как вероятность блока,
содержащего два и более пакетов ошибок, меньше на несколько порядков (так как
30
Рис. 2. Зависимость между длиной пакета j и верхней оценкой вероятности ошибоч-
ного декодирования для сверточного кода (13, 17) с рекурсивным систематическим
кодером и памятью m = 3
перемножаются вероятности пакетов ошибок по отдельности), то для упрощения
выражения мы учитываем такие блоки несколько раз в нашей аддитивной оценке.
Сумма в формуле (6) берется по всем возможным длинам пакетов ошибок в блоке,
но для практического использования достаточно взять сумму только по самым ко-
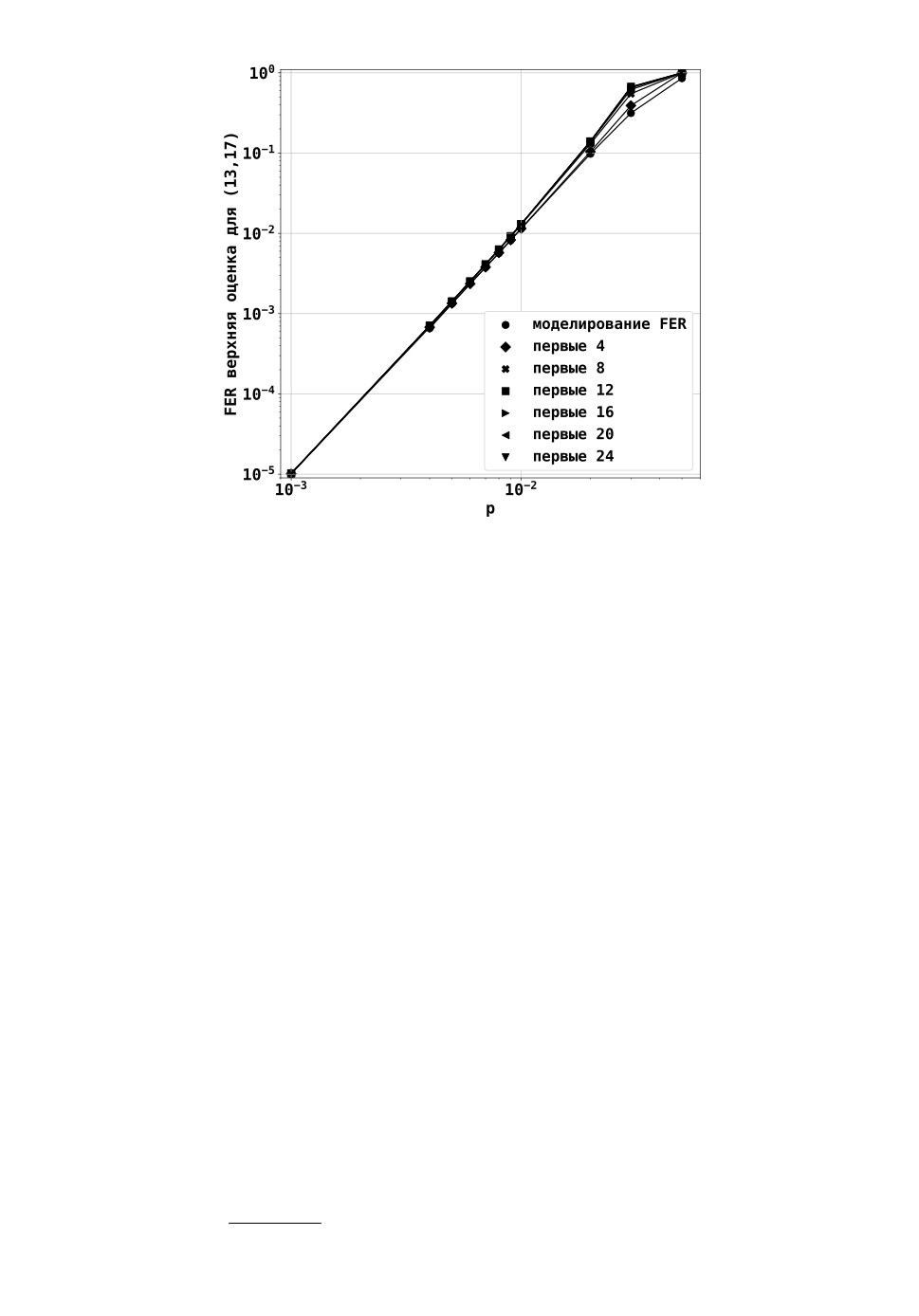
ротким пакетам ошибок, что видно из рис. 2. Даже при рассмотрении небольшого
числа самых коротких пакетов ошибок оценка FERup(p) лежит выше значений ве-
роятности ошибочного декодирования, полученных моделированием. Для малых p
рассмотрение большего числа различных длин пакетов ошибок практически не вли-
яет на точность оценки.
3.3. Вероятность ошибки на бит. Выходная вероятность ошибки на бит для свер-
точного кода - это доля битов с ошибками в декодированном слове. Некорректные
биты появляются только в местах пакетов ошибок.
Мы будем оценивать вероятность ошибки на бит в декодированном слове как
среднюю долю битов с ошибками. Вероятность ошибочного декодирования бита обо-
значается через BER (Bit Error Rate). Мы выводим нижнюю оценку вероятности
ошибки на бит как долю ошибочных битов в предположении появления наиболее
вероятных пакетов ошибок. Тогда нижняя оценка - это вес наиболее вероятного па-
кета ошибок, умноженный на вероятность его появления в каком-либо бите. Для
уточнения нижней границы мы используем в качестве вероятности появления па-
кета ошибок с минимальным весом wmin = minaj - нижнюю оценку вероятности
j
появления одного такого пакета в кортеже (3), умноженную на количество таких
пакетов (они равновероятные) и нормированную по числу битов в кортеже. Таким
образом, предложенная нижняя оценка вероятности ошибки на бит имеет вид
wminNwmin
BERlow(p) =
Plow(j = jwmin , p),
(7)
2
31
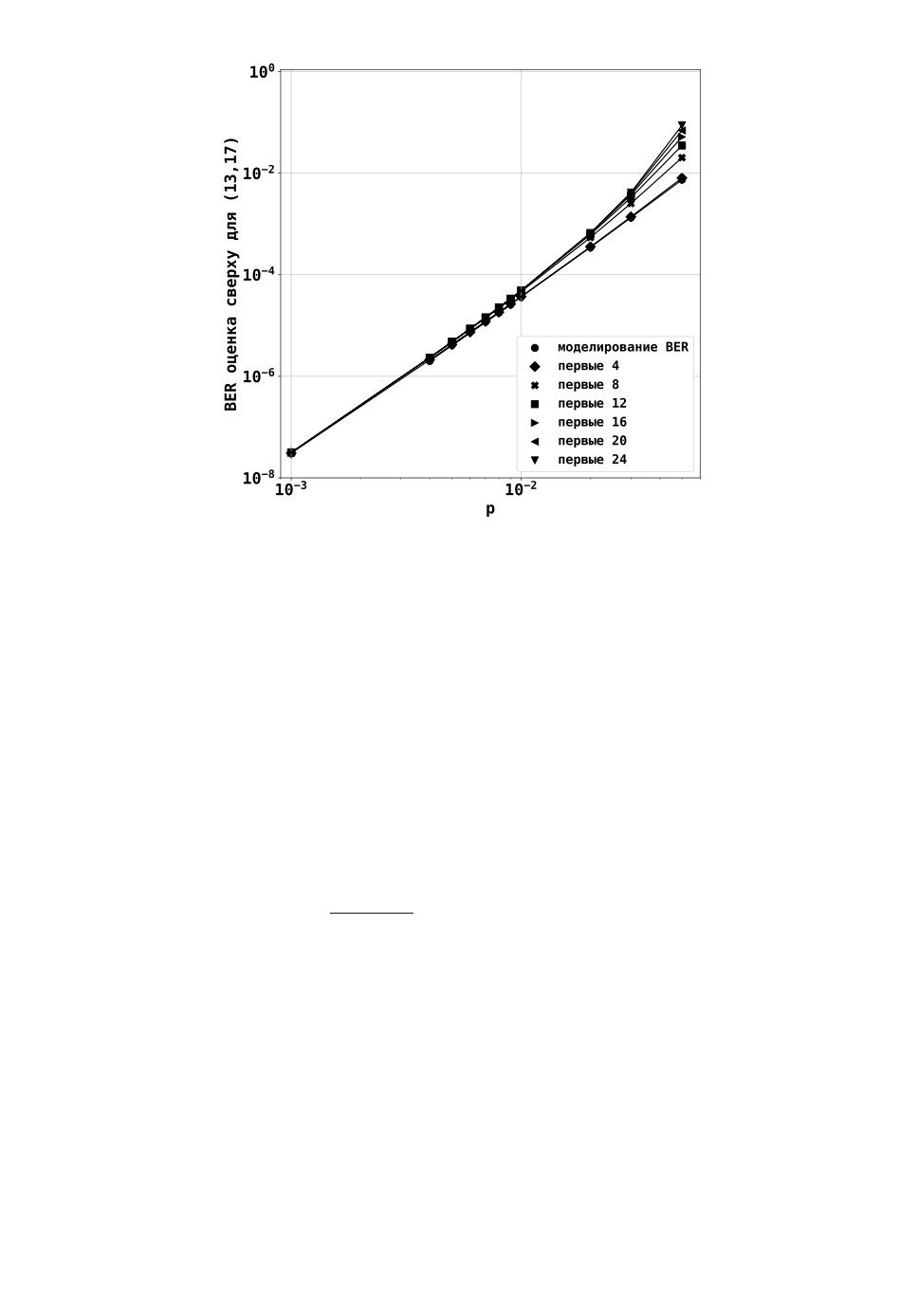
Рис. 3. Зависимость между длиной пакета j и верхней оценкой вероятности ошибки
на бит для сверточного кода (13, 17) с рекурсивным систематическим кодером и
памятью m = 3
здесь Nwmin - число пакетов ошибок с минимальным весом, jwmin - длина пакета
ошибок с минимальным весом, {wmin, Nwmin} ∈ Da, а знаменатель n = 2 - число
битов в кортеже.
Верхнюю оценку вероятности ошибки на бит мы строим как аддитивную оценку
с помощью средних долей ошибочных битов по всем длинам пакетов ошибок с наи-
большим возможным весом. Верхняя оценка вероятности появления пакета ошибок
в кортеже (4) уже учитывает количество таких пакетов, поэтому нет необходимости
в дополнительном множителе. Как и для случая BERlow, мы нормируем оценку по
числу битов в выходном кортеже n = 2, чтобы получить вероятность появления
пакета в конкретном бите. Тогда верхняя оценка вероятности ошибки на бит:
⎧
⎫
max wj
⎨
∑
⎬
wj ∈D
aj
BERup(p) = min
1,
Pup(j, p)
(8)
⎩
2
⎭
j
В формуле (8) берется минимум из 1 и оценки, так как оценка аддитивна и
может превысить 1. В формуле (8) сумма берется по всем возможным j, в то время
как для практических расчетов достаточно взять сумму лишь по самым коротким
длинам. Действительно, на рис. 3 видно, что верхняя оценка сходится к одному
значению с увеличением предела суммирования j в сумме (8). Более того, даже для
небольшого количества рассматриваемых длин пакетов ошибок оценка лежит выше
реальных значений вероятности ошибки на бит. Для малых вероятностей ошибки на
бит p (p ≤ 0,01) оказывается достаточным взять всего несколько наиболее коротких
пакетов ошибок, что еще более снижает сложность вычисления оценки.
3.4. Сложность вычисления теоретических оценок. Для расчета предложенных
теоретических оценок необходимо вычислить активные расстояния и их спектр для
32
сверточного кода. Отметим, что для сверточного кода необходимо вычислить мет-
рические характеристики всего один раз.
Расчет активных расстояний aj для длины j основан на алгоритме Витерби и
происходит следующим способом:
1. В начальный момент времени t = 0 инициализируем один путь в нулевом состо-
янии решетки длины 0.
2. В момент времени t > 0 продолжаем все сохраненные пути в решетке из узлов
в момент времени t - 1 в узлы в момент времени t. Каждый путь может быть
продолжен 2k, k = 1, способами, не считая путей в нулевом состоянии на решетке.
Из нулевого состояния решетки продолжаем путь только в ненулевое состояние
решетки. Считаем вес полученных путей, всего 2m+k -1, k = 1, путей (при t > m,
где m - память кода).
3. Для каждого состояния в решетке в момент времени t сохраняем только путь
с наименьшим весом, оставляя 2m путей (при t ≥ m).
4. Если t = j, то возвращаем вес пути, который сохранен для нулевого состояния
в момент времени t = j. Если t < j, переходим к шагу 2.
Удобно представлять процесс вычисления активных расстояний как движение
по решетке вправо. Так как необходимо найти ненулевой путь в решетке длины j
с минимальным весом, то достаточно для каждого узла решетки в каждый момент
времени хранить только “лучший” путь, т.е. путь минимального веса, входящий сле-
ва в этот узел. Сложность такого алгоритма зависит от длины ненулевого пути j
и от количества состояний 2m, где m - память кода. Из алгоритма подсчета следу-
ет, что сложность вычисления активных расстояний aj составляет O(j(2m+1 - 1)).
Отметим, что вычисляя активные расстояния для длины j, мы при этом можем
вычислить еще активные расстояния для всех длин, меньших j.
Расчет спектра активных расстояний имеет большую алгоритмическую слож-
ность, которая экспоненциально растет с ростом длины ненулевого пути j, для кото-
рой необходимо посчитать спектр. Спектр также вычисляется с помощью решетки,
только теперь мы не отбрасываем пути с большим весом, а храним все возмож-
ные пути в решетке. При продолжении путей путь из нулевого состояния также не
продолжается в нулевое состояние. Вычислительную сложность алгоритма можно
записать как O(2j (2m+1 - 1)), где m - память кода. Из формулы видно, что вычис-
ление спектра активных расстояний для больших расстояний трудоемко и быстро
растет с увеличением длины j.
Теперь оценим сложность вычисления предложенных оценок вероятности ошиб-
ки для сверточных кодов, если метрические характеристики кода (активные рас-
стояния или спектр активных расстояний) уже известны. Сложность вычисления
нижней Plow(j, p) (3) и верхней Pup(j, p) (4) оценок вероятности появления пакета
ошибок длины j оценим как максимальное количество вычислений P(eall, e1, j, w, p):
((
((
)
)
aj )aj )
w
min
wmax
O
2j -
и O
2j -
(wmax - wmin) ,
{wmin, wmax} ∈ Daj.
2
2
2
2
Сложность вычисления нижних оценок (5) и (7) для FERlow(p) и BERlow(p) не от-
личаются от сложности расчета Plow(j = jwminp), где jwmin - длина пакета ошибок с
минимальным весом. Сложность вычисления верхних оценок (6) и (8) для FERup(p)
и BERup(p) совпадает со сложностью вычисления верхней оценки появления пакета
ошибок Pup(j, p), умноженной на количество рассмотренных наименьших различных
возможных весов пакетов ошибок. На практике достаточно рассмотреть порядка 5-8
весов, как видно из рис. 3. Таким образом, хотя сложность расчета теоретических
оценок зависит от вероятности ошибки на бит p, но для практически значимых зна-
чений p, для получения достаточно точных значений величин вероятности ошибки
33
на бит, достаточно ограничиться небольшим числом слагаемых. Кроме того, следует
отметить, что сложность расчета теоретических оценок линейна по j.
3.5. Экспериментальные результаты. Представим экспериментальные результа-
ты и их сравнение с теоретическими оценками. В экспериментах рассматривался
двоичный симметричный канал с вероятностью ошибки на бит p. По каналу переда-
вались кодовые слова усеченного сверточного кода с рекурсивным систематическим
кодером скорости 1/2 длины 1000 кортежей (2000 бит). Рассматривались различные
сверточные коды с различной памятью.
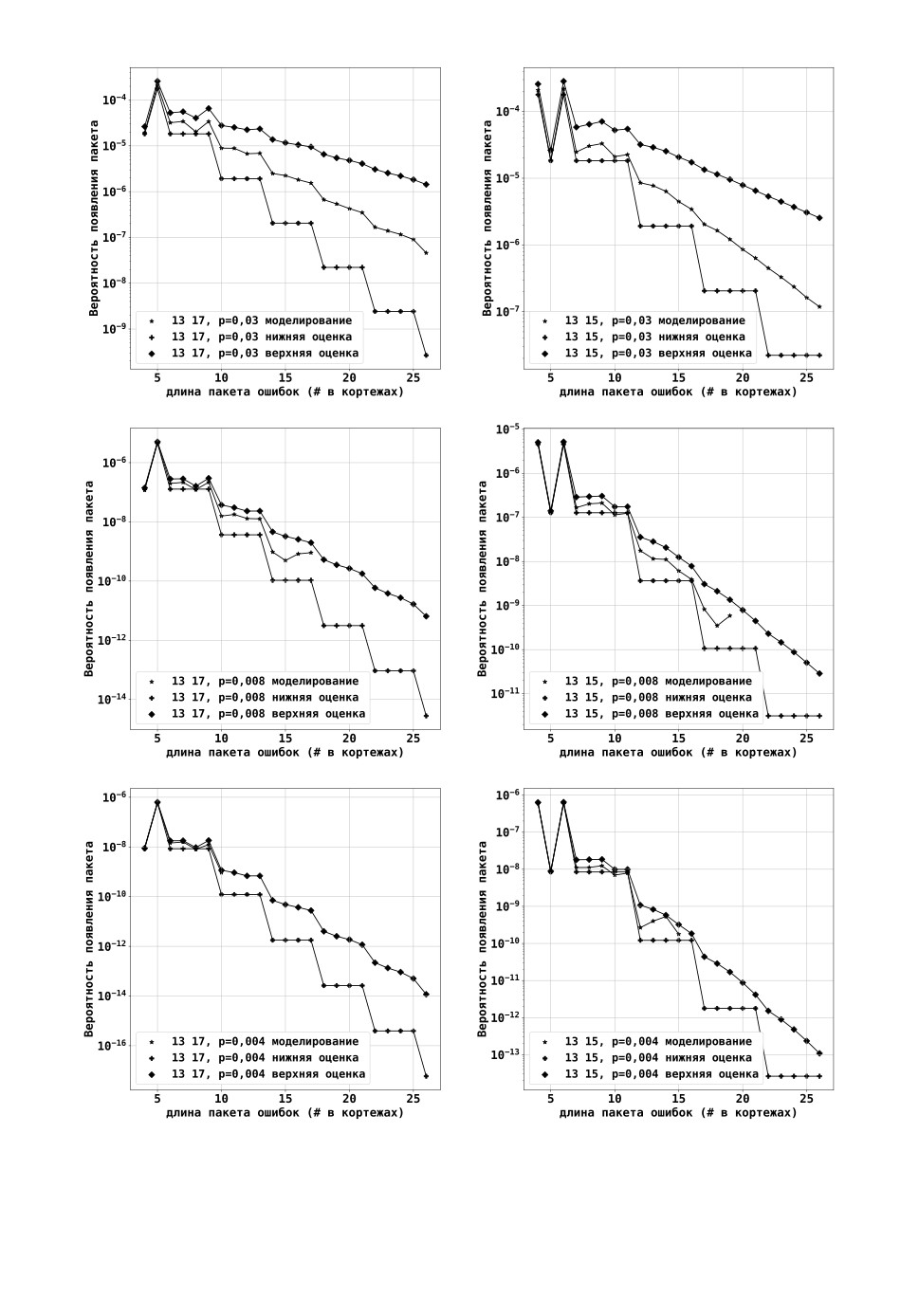
Приведем результаты для вероятности появления пакета ошибок. Графики на
рис. 4 приведены для трех различных вероятностей ошибки на бит p: 0,03, 0,008 и
0,004. Для вероятности p = 0,004 приведено существенно меньше точек, получен-
ных с помощью моделирования, так как для получения экспериментальных оценок
время, требуемое на моделирование, резко возрастает.
Из рис. 4 видно, что ближе всего теоретические оценки лежат к результатам мо-
делирования при малых длинах пакетов, для которых существует всего одно или
несколько слов, в которые они могут перейти. С увеличением длины пакета резко
увеличивается число возможных слов, в которые может перейти слово при декоди-
ровании, что наглядно иллюстрируется таблицами 1 и 2 спектра активных рассто-
яний. Отметим также, что пакеты ошибок небольшой длины имеют наибольшую
вероятность и, соответственно, имеют наибольший вклад в вероятность ошибочно-
го декодирования блока и в вероятность ошибки на бит. По графикам на рис. 4
также можем отметить, что с уменьшением вероятности ошибки на бит p оценки
сходятся, что объясняется экспоненциальным уменьшением вероятностей длинных
пакетов ошибок. Таким образом, для небольших p предложенные в статье оценки
становятся достаточно точными даже для больших длин пакетов ошибок.
Принято считать, что распределение пакетов ошибок можно приблизить с помо-
щью геометрического распределения [26,27]. Это справедливо только для наименее
вероятных ошибок, т.е. геометрическое распределение хорошо приближает вероят-
ности появления длинных пакетов ошибок и плохо приближает наиболее вероятные
пакеты с наименьшей длиной.
На рис. 5, 6 представлены вероятности ошибочного декодирования (FER) и вы-
ходные вероятности ошибки на бит (BER) для двух сверточных кодов (13, 17) и
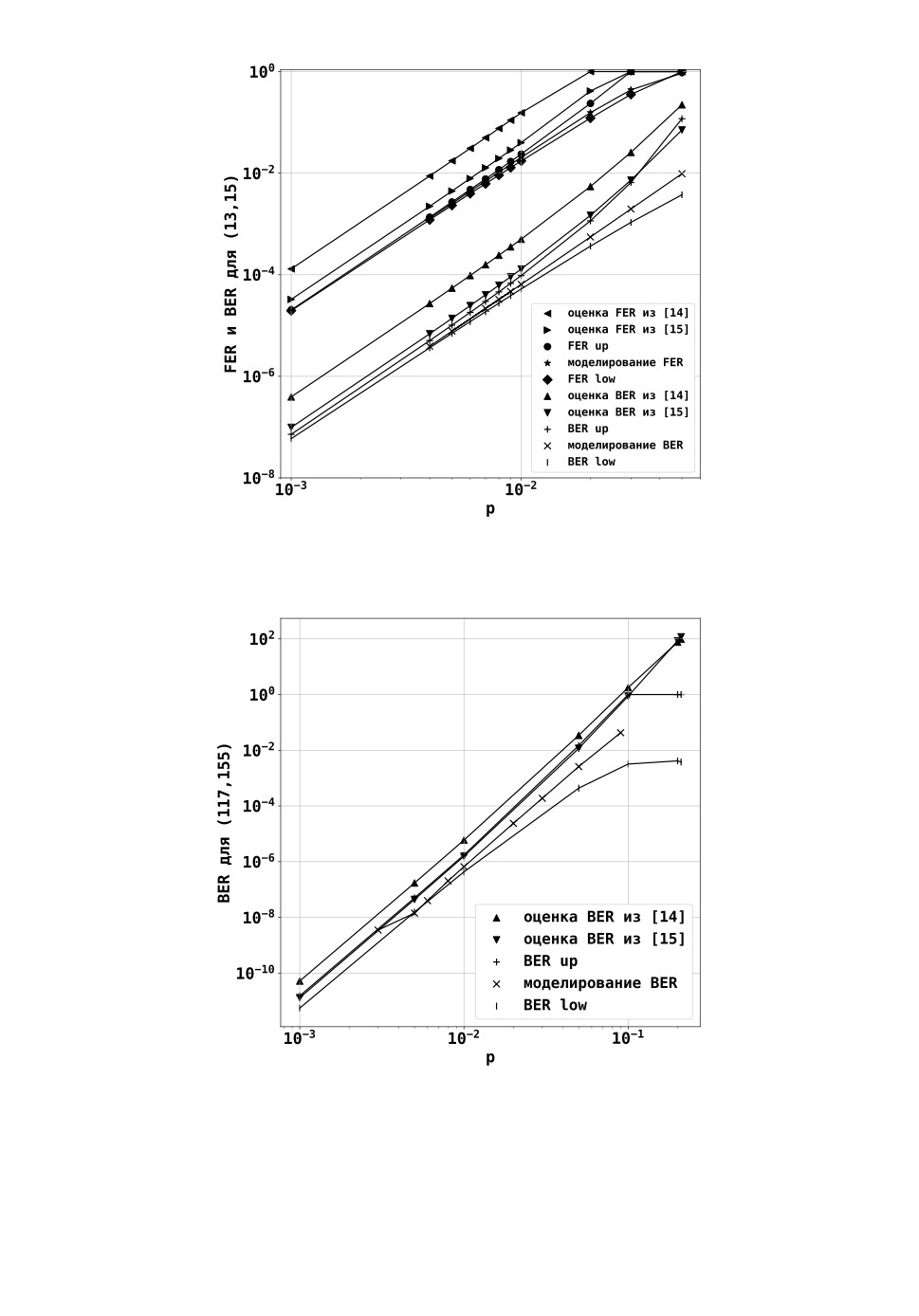
(13, 15) с памятью m = 3. Мы также привели на рис. 7 BER для кода (117, 155) с па-
мятью m = 6, чтобы показать, что наши оценки применимы и для кодов с большей
памятью. Для сравнения также приведены классические аддитивные верхние оцен-
ки FER и BER из работ [14,15], вычисленные с помощью производящей функции
спектра кода и функции спектра ошибки на бит соответственно.
Оценки вероятности ошибочного декодирования были также представлены в ра-
боте [23]. Эти результаты можно сравнить с результатами из работы [20] для ко-
да (13, 17), и очевидно, что результаты практически совпадают. Но метод из рабо-
ты [20] вычислительно трудоемкий, особенно с увеличением памяти кодера. Более
того, в работе говорится о том, что предложенный метод не применим к кодам с па-
мятью больше 4.
Предложенный в данной статье подход, основанный на активных расстояниях
сверточного кода и их спектре, позволяет вычислить оценки для кодов большей па-
мяти, не требуя особых вычислительных ресурсов. Для вычисления точных оценок
не требуется рассматривать пакеты ошибок большой длины, достаточно рассмотреть
несколько пакетов с наименьшими весами. Программы для вычисления активных
расстояний и их спектра могут быть найдены на портале GitHub [28]. Здесь мы так-
же приводим пример выходной вероятности ошибки на бит для сверточного кода
(117, 155) с памятью m = 6 на рис. 7, где для сравнения также приведены верхние
оценки BER из работ [14, 15].
34
a)
b)
c)
d)
e)
f)
Рис. 4. Вероятностное распределение появления пакетов ошибок для сверточного
кода с рекурсивным систематическим кодером и памятью m = 3: a) (13, 17), p = 0,03,
b) (13, 15), p = 0,03, c) (13, 17), p = 0,008, d) (13, 15), p = 0,008, e) (13, 17), p = 0,004,
f) (13,15), p = 0,004
35
Рис. 5. Вероятности ошибочного декодирования и ошибки на бит для сверточного
кода (13, 17) с рекурсивным систематическим кодером и памятью m = 3
Из рис. 5-7 видно, что верхняя и нижняя оценки приближаются друг к дру-
гу при небольших вероятностях ошибки p. Таким образом, для этих вероятностей
теоретические оценки достаточно точны, и нет необходимости использовать метод
Монте-Карло для получения экспериментальных значений, что на практике может
быть достаточно трудоемко для малых значений p. Мы также сравнили наши верх-
ние оценки для вероятности ошибки на бит и для вероятности ошибочного декоди-
рования с классическими верхними оценками из [14, 15], полученными с помощью
производящих функций.
3.6. Сравнение с другими границами. Оценки вероятности ошибочного декоди-
рования были также представлены в работе [23]. Эти результаты можно сравнить
с результатами из работы [20] для кода (13, 17), и очевидно, что результаты прак-
тически совпадают. Но метод из работы [20] вычислительно трудоемкий, особенно
с увеличением памяти кодера. Более того, в работе говорится о том, что предложен-
ный метод не применим к кодам с памятью больше 4, тогда как мы показали, что
расчет наших оценок возможен и для кодов с большей памятью.
Предложенный в нашей статье подход, основанный на активных расстояниях
сверточного кода и их спектре, позволяет вычислить оценки для кодов большей па-
мяти, не требуя особых вычислительных ресурсов. Для вычисления точных оценок
не требуется рассматривать пакеты ошибок большой длины, достаточно рассмотреть
несколько пакетов с наименьшими весами. Программы для вычисления активных
расстояний и их спектра могут быть найдены на портале GitHub [28].
На рис. 5-7 приведено сравнение предложенных нами оценок с классическими
границами из работ [14,15]. Из результатов видно, что предложенная в нашей статье
аддитивная верхняя оценка лежит ближе либо сравнима с классическими. Оценка
из работы [15] лежит ближе к экспериментальным данным и к нашей границе, чем
оценка из работы [14], что можно объяснить более точной оценкой сверху с помо-
щью границы Миберга для вероятности ошибки в двоичном симметричном канале.
36
Рис. 6. Вероятности ошибочного декодирования и ошибки на бит для сверточного
кода (13, 15) с рекурсивным систематическим кодером и памятью m = 3
Рис. 7. Вероятность ошибки на бит для сверточного кода (117, 155) с рекурсивным
систематическим кодером и памятью m = 6
Используемые нами оценки для вероятности появления пакета ошибок и активные
расстояния позволяют вычислить оценки для FER и BER более точно. Отдельно
отметим, что мы также предлагаем оценку снизу, что не было ранее предложено
37
в работах, и оценка снизу оказывается очень близка к экспериментальным резуль-
татам.
§ 4. Заключение
В статье получены наиболее важные теоретические оценки эффективности свер-
точного кода в двоичном симметричном канале. А именно, получены верхние и ниж-
ние оценки вероятности появления пакета ошибок, ошибочного декодирования и ве-
роятности ошибки на бит. Предложенные оценки основаны на активных расстояниях
и спектре активных расстояний и справедливы для сверточных кодов скорости 1/2
с декодированием Витерби. Полученные результаты могут быть обобщены для свер-
точных кодов скорости 1/n. Проведен анализ сложности вычисления метрических
характеристик и теоретических оценок. Показано, что для заданной длины слож-
ность вычисления активных расстояний экспоненциально зависит от памяти кода и
линейно от длины, в то время как сложность вычисления спектра активных расстоя-
ний экспоненциально зависит и от памяти кода, и от длины. Сложность вычисления
теоретических оценок при известных метрических характеристиках линейно зависит
от длины наиболее коротких пакетов ошибок и не зависит от входной вероятности
ошибки на бит в канале. Также рассмотрены различные коды с разной памятью,
и для них представлено сравнение теоретических и экспериментальных результа-
тов. Предложенные оценки наиболее точны при небольших входных вероятностях
ошибки на бит.
В дальнейшем с помощью активных расстояний и его спектра могут быть выве-
дены оценки эффективности сверточных кодов также и для канала с гауссовским
шумом.
СПИСОК ЛИТЕРАТУРЫ
1. Elias P. Coding for Noisy Channels // IRE Conv. Rec. 1955. V. 4. P. 37-46. Reprinted in:
Key Papers in the Development of Information Theory. New York: IEEE Press, 1974.
P. 102-111.
2. Yang C., Zhan M., Deng Y., Wang M., Luo X.H., Zeng J. Error-Correcting Performance
Comparison for Polar Codes, LDPC Codes and Convolutional Codes in High-Performance
Wireless // Proc. 6th Int. Conf. on Information, Cybernetics, and Computational Social
Systems (ICCSS’2019). Chongqing, China. Sept. 27-30, 2019. P. 258-262. https://doi.
org/10.1109/ICCSS48103.2019.9115442
3. Deng Y., Zhan M., Wang M., Yang C., Luo X., Zeng J., Guo J. Comparing Decoding Per-
formance of LDPC Codes and Convolutional Codes for Short Packet Transmission // Proc.
IEEE 17th Int. Conf. on Industrial Informatics (INDIN’2019). Helsinki, Finland. July 22-25,
4. Tahir B., Schwarz S., Rupp M. BER Comparison between Convolutional, Turbo, LDPC,
and Polar Codes // Proc. 24th Int. Conf. on Telecommunications (ICT’2017). Limassol,
5. Rurik W., Mazumdar A. Hamming Codes as Error-Reducing Codes // Proc. 2016 IEEE
Information Theory Workshop (ITW’2006). Cambridge, UK. Sept. 11-14, 2016. P. 404-408.
6. Liu K., Garcıa-Fr´ıas J. Error Floor Analysis in LDGM Codes // Proc. 2010 IEEE Int.
Symp. on Information Theory (ISIT’2010). Austin, TX, USA. June 13-18, 2010. P. 734-738.
7. Gao W., Polyanskiy Y. On the Bit Error Rate of Repeated Error-Correcting Codes // Proc.
48th Annu. Conf. on Information Sciences and Systems (CISS’2014). Princeton, NJ, USA.
8. Höst S., Johannesson R., Zyablov V.V. Woven Convolutional Codes. I. Encoder Proper-
1109/18.971745
38
9.
Freudenberger J., Bossert M., Shavgulidze S., Zyablov V. Woven Turbo Codes // Proc.
7th Int. Workshop on Algebraic and Combinatorial Coding Theory (ACCT’2000). Ban-
viewdoc/download?doi=10.1.1.23.345&rep=rep1&type=pdf
10.
Benedetto S., Montorsi G. Design of Parallel Concatenated Convolutional Codes // IEEE
11.
Berrou C., Glavieux A., Thitimajshima P. Near Shannon Limit Error-Correcting Coding
and Decoding: Turbo-Codes. 1 // Proc. IEEE Int. Conf. on Communications (ICC’93).
ICC.1993.397441
12.
Douillard C., Berrou C. Turbo Codes with Rate-m/(m + 1) Constituent Convolutional
1109/TCOMM.2005.857165
13.
Zhang Q., Liu A., Zhang Y., Liang X. Practical Design and Decoding of Parallel Concate-
nated Structure for Systematic Polar Codes // IEEE Trans. Commun. 2016. V. 64. № 2.
14.
Viterbi A.J. Convolutional Codes and Their Performance in Communication Systems //
TCOM.1971.1090700
15.
van De Meeberg L. A Tightened Upper Bound on the Error Probability of Binary Convo-
lutional Codes with Viterbi Decoding // IEEE Trans. Inform. Theory. 1974. V. 20. № 3.
16.
Herro M., Hu L., Nowack J. Bit Error Probability Calculations for Convolutional Codes
with Short Constraint Lengths on Very Noisy Channels // IEEE Trans. Commun. 1988.
17.
Chiaraluce F., Gambi E., Mazzone M., Pierleoni P. A Technique to Evaluate an Exact
Formula for the Bit Error Rate of Convolutional Codes in Case of Finite Length Words //
Proc. IEEE Region 10 Annu. Conf. on Speech and Image Technologies for Computing and
Telecommunications (IEEE TENCON’97). Queensland Univ. of Technology, Brisbane, Aus-
18.
Forney G. The Viterbi Algorithm // Proc. IEEE. 1973. V. 61. № 3. P. 268-278. https:
//doi.org/10.1109/PROC.1973.9030
19.
Yoshikawa H. Theoretical Analysis of Bit Error Probability for Punctured Convolutional
Codes // Proc. 2012 IEEE Int. Sympos. on Information Theory and Its Applications
(ISITA’2012). Honolulu, HI, USA. Oct. 28-31, 2012. P. 658-661.
20.
Bocharova I.E., Hug F., Johannesson R., Kudryashov B.D. A Closed-Form Expression for
the Exact Bit Error Probability for Viterbi Decoding of Convolutional Codes // IEEE
2012.2193375
21.
Smeshko A., Ivanov F., Zyablov V. Theoretical Estimates of Burst Error Probability for
Convolutional Codes // Proc. 2020 Int. Symp. on Information Theory and Its Applications
(ISITA’2020). Kapolei, HI, USA. Oct. 24-27, 2020. P. 136-140.
22.
Smeshko A., Ivanov F., Zyablov V. The Influence of Active Distances on the Distribution
of Bursts // Proc. XVI Int. Symp. “Problems of Redundancy in Information and Control
Systems” (REDUNDANCY’2019). Moscow, Russia. Oct. 21-25, 2019. P. 110-114. https:
//doi.org/10.1109/REDUNDANCY48165.2019.9003349
23.
Smeshko A., Ivanov F., Zyablov V. Upper and Lower Estimates of Frame Error Rate for
Convolutional Codes // Proc. 2020 Int. Symp. on Information Theory and Its Applications
(ISITA’2020). Kapolei, HI, USA. Oct. 24-27, 2020. P. 160-164.
24.
Кудряшов Б.Д. Основы теории кодирования. СПб.: БХВ-Петербург, 2016.
25.
Höst S., Johannesson R., Zigangirov K., Zyablov V. Active Distances for Convolutional
1109/18.749009
26.
Miller R.L., Deutsch L.J., Butman S.A. On the Error Statistics of Viterbi Decoding and the
Performance of Concatenated Codes // NASA STI/Recon Tech. Rep. N 81-33364. Sept. 1,
39
27. Justesen J., Andersen J. Critical Lengths of Error Events in Convolutional Codes // IEEE
681339
convolutional-code [GitHub online repository]. 2021.
Курмукова Анастасия Андреевна
Поступила в редакцию
Институт проблем передачи информации
12.12.2021
им. А.А. Харкевича РАН
После доработки
Национальный исследовательский университет
08.03.2022
“Высшая школа экономики”
Принята к публикации
Сколковский институт науки и технологий
11.03.2022
Anastasiia.Kurmukova@skoltech.ru
Иванов Федор Ильич
Институт проблем передачи информации
им. А.А. Харкевича РАН
Национальный исследовательский университет
“Высшая школа экономики”
fivanov@hse.ru
Зяблов Виктор Васильевич
Институт проблем передачи информации
им. А.А. Харкевича РАН
zyablov@iitp.ru
40