

Доклады Российской академии наук. Математика, информатика, процессы управления, 2022, T. 508, № 1, стр. 19-27
ФУНДАМЕНТАЛЬНЫЕ ИССЛЕДОВАНИЯ И РАЗРАБОТКИ В ОБЛАСТИ ПРИКЛАДНОГО ИСКУССТВЕННОГО ИНТЕЛЛЕКТА
Е. В. Бурнаев 1, 2, *, А. В. Бернштейн 1, В. В. Вановский 1, А. А. Зайцев 1, А. М. Булкин 1, В. Ю. Игнатьев 1, Д. Г. Шадрин 1, С. В. Илларионова 1, И. В. Оселедец 1, 2, А. Ю. Михалев 1, А. А. Осипцов 1, А. А. Артемов 1, М. Г. Шараев 1, И. Е. Трофимов 1
1 Сколковский институт науки и технологий
Москва, Россия
2 Научно-исследовательский институт искусственного интеллекта
Москва, Россия
* E-mail: e.burnaev@skoltech.ru
Поступила в редакцию 28.10.2022
После доработки 28.10.2022
Принята к публикации 01.11.2022
- EDN: DBRSQV
- DOI: 10.31857/S2686954322070049
Аннотация
Настоящий этап развития искусственного интеллекта (ИИ) характеризуется развитием технологий, методов и алгоритмов машинного обучения (МО), в том числе глубокого машинного обучения, интеллектуального анализа данных и других фундаментальных научных направлений и созданием на их основе прикладных решений практически во всех сферах цифровой экономики. Однако расширение сферы приложений ИИ, усложнение класса решаемых задач и спектра и объема данных, используемых для создания прикладных ИИ-моделей и интеллектуальных систем на базе ИИ, потребовали существенного расширения теоретической и алгоритмической базы ИИ, включая необходимость развития методов МО с использованием математических и физических моделей объектов и явлений предметных областей, методов консолидации мультимодальных данных, методов создания геометрических и топологических компонентов нейронных глубоких сетей, методов моделирования изучаемых 3D-объектов и др. Для ответа на эти вызовы в 2021 г. в рамках федерального проекта “Искусственный интеллект” на базе Сколтеха был создан Исследовательский центр прикладного искусственного интеллекта, задачами которого является создание научно-технологической базы для решения широкого спектра актуальных прикладных задач для целей устойчивого развития экономики РФ, включая задачи оптимизации управленческих решений в целях снижения углеродного следа и другие актуальные задачи направления ESG; задачи мониторинга окружающей среды с целью выявления аномалий и прогнозирования развития экстремальных ситуаций; оценка экономических и социальных рисков и их динамики, вызванных климатическими изменениями; задачи предиктивной аналитики и др. В статье описаны развиваемые в Центре новые технологии, модели, методы и алгоритмы ИИ, основные прикладные направления исследований Центра и уже достигнутые научные и прикладные результаты.
1. ВВЕДЕНИЕ
Исследовательский Центр прикладного искусственного интеллекта был создан в 2021 г. в рамках федерального проекта “Искусственный интеллект” национальной программы “Цифровая экономика Российской Федерации” на базе нескольких научных групп Сколковского института науки и технологии.
Целью Центра являются проведение ориентированных фундаментальных и прикладных исследований в области искусственного интеллекта и использование полученных результатов для поддержки управленческих решений на базе разрабатываемых инструментов для мультимасштабного мониторинга и управления климатическими и экологическими рисками для реализации Национальной стратегии развития искусственного интеллекта (далее ИИ) на период до 2030 г. и Энергетической стратегии РФ до 2035 г.
Основные направления фундаментальных и прикладных исследований Центра в области ИИ включают в себя:
• развитие теоретических и прикладных методов машинного обучения, таких как методы
• создания глубоких нейронных сетей,
• создания крупномасштабных генеративных моделей [1, 3],
• создания интерпретируемых и устойчивых физически информированных нейронных сетей с использованием знаний и моделей предметных областей (Physics Informed ML),
• машинного обучения для решения обратных задач, в том числе для обнаружения ошибок входных данных и их корректировки,
• исключения систематических ошибок моделирования, связанных с неполным соответствием реальных явлений и процессов их аналитическим представлениям, и минимизации ошибок прогноза,
• адаптации предиктивных моделей под изменяющиеся со временем границы пространства условий и входных данных и др.;
• развитие теоретических и прикладных методов повышения вычислительной эффективности больших нейросетевых моделей (быстрое обучение, сжатие моделей, поиск новых архитектур) для снижения вычислительной нагрузки на симуляцию на основе математических моделей процессов, включая
• алгоритмические методы экономии памяти (использование attention-слоев, вычисление неточных градиентов линейных слоев и нелинейных слоев активаций, малопараметрическое представление линейных слоев при помощи тензоров в ТТ-формате и др.), позволяющие уменьшить нагрузку на память (с возможностью одновременной работы с большим количеством входных данных) и снизить итоговое время обучения,
• новые стохастические методы оптимизации, основанные на тонкой настройке внутренних гиперпараметров оптимизатора для каждой нейросетевой модели,
• параллельные алгоритмы на основе task-based парадигмы программирования, основанной на описании всех вычислений в виде направленного графа без циклов. Этот граф вычислений используется для распределения вычислений и асинхронной пересылки данных для роста общей “утилизации” всех устройств;
• развитие теоретических и прикладных методов интеллектуального анализа данных, таких как
• дифференциально-геометрические, топологические, графовые и стохастические методы анализа данных [2],
• методы обработки и анализа сигналов и изображений,
• методы консолидации мультимодальных данных различной физической природы и извлечения из них релевантной информации,
• методы 3D компьютерного зрения [18, 20],
• методы обнаружения и идентификации аномалий в данных и разладок в динамических системах и др.;
• развитие прикладных технологий построения моделей предиктивной аналитики и создания систем поддержки принятия решений, учитывающих знания и модели предметной области (включая особенности носителя обрабатываемых многомерных данных), их стохастического характера, дизайна процессов получения выборки эмпирических данных и степень их неопределенности.
На базе разрабатываемых методов и алгоритмов создается программный инструментарий ИИ в виде программных средств и платформенных решений (универсальных программных фреймворков и библиотек) для решения с их помощью прикладных задач развития научно-технологического комплекса РФ и устойчивого развития российской промышленности и экономики.
Программный инструментарий ИИ, развиваемый в Центре, используется для разработки ряда прикладных пилотных проектов для повышения эффективности и формирования новых направлений деятельности индустриальных партнеров Центра и ключевых отраслевых предприятий экономики РФ (в соответствии с Программой Центра), включая
• формирование нового направления финансового мониторинга и учета ESG рисков при кредитовании промышленных предприятий (для Сбера),
• повышение эффективности анализа корпоративной информации за счет применения методов ускорения обучения и сжатия больших нейросетевых моделей (для Сбера),
• оптимизацию управленческих решений на повышение нефтеотдачи и снижения экологического ущерба; разработку самообучающейся модели нефтегазоносного пласта (для Газпромнефти),
• повышение эффективности, надежности и масштабирование системы мониторинга качества атмосферного воздуха (для СитиЭйр),
а также для разработки актуальных прикладных решений и сервисов для других объектов реальной экономики и социальной сферы, включая ФОИВы, министерства и др.
В следующих разделах будут более подробно описаны нескольких текущих проектов (в рамках перечисленных выше направлений):
• прогнозирование экономических последствий от наступления физических и климатических рисков (для Сбера),
• снижение ресурсоемкости обучения больших нейросетевых моделей (для Сбера),
• прогнозирование ледовой обстановки в Арктике (для Газпромнефти),
• самообучающаяся модель пласта (для Газпромнефти), иллюстрирующих актуальность и востребованность исследований, необходимость разработки и использования технологий ИИ, а также достигнутые промежуточные результаты.
2. АНАЛИЗ ФИЗИЧЕСКИХ И ФИНАНСОВЫХ РИСКОВ, СОЗДАВАЕМЫХ КЛИМАТИЧЕСКИМИ ИЗМЕНЕНИЯМИ
2.1. Предпосылки проекта
Территория Российской Федерации находится в зоне высокого риска стихийных бедствий, таких как паводки, штормы, засухи, лесные пожары и др., а также рисков, связанных с изменениями климата, такими как таяние мерзлоты в Арктической зоне Российской Федерации, и др. [4, 5]. Таким образом возникает задача расчета стоимости ESG рисков (по E-компоненте) и их влияния на принятие управленческих решений в промышленной, социальной и финансовой областях (например, при кредитовании промышленных предприятий). Поэтому необходима разработка технологий расчета вероятности реализации различных экстремальных событий в конкретных областях РФ, прогнозирования релевантных последствий от наступления экстремальных событий и изменения климата на различных горизонтах планирования.
Использование новых методов машинного обучения и анализа данных для решения перечисленных выше задач определяется:
• необходимостью обработки и анализа больших массивов взаимосвязанных климатических данных, в связи с тем, что методы машинного обучения значительно превосходят по вычислительной эффективности и точности стандартные методы многомерного статистического анализа, упрощая процессы, связанные с построением моделей экстремальных климатических событий и использованием климатических сценариев;
• наличием неопределенности в климатических проекциях моделей экстремальных рисков при различных климатических сценариях;
• наличием моделей, основанных на первых принципах (напр., физические уравнения теплопроводности по Кудрявцеву [7]), с использованием которых возможно строить физически информированные модели машинного обучения. Например, модели, обученные на данных сети глобального мониторинга криолитозоны (данные GTNP) с использованием современных методов искусственного интеллекта (нейронные обыкновенные дифференциальные уравнения, модели на основе гауссовских процессов, градиентного бустинга и др.), уточняют прогнозы моделей на основе физических процессов и ускоряют расчет полученных прогнозов.
2.2. Результаты
В рамках проекта поставлены и решены следующие научные задачи:
• построены различные прогнозы (протаивания грунта, влияния климата на условия землепользования и др.), а также построены модели глубины протаивания и температуры грунта,
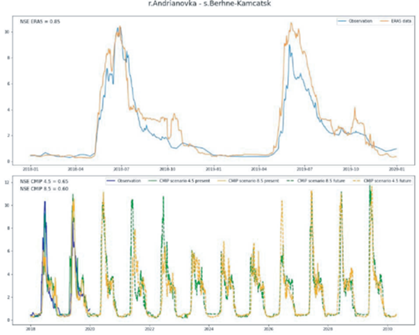
• вычислены вероятности реализации различных экстремальных событий в конкретных точках Российской Федерации (в масштабе 27 × 27 км), такие как сильный ветер (более 20 м/с), наводнения (разливы рек), град (вероятность возникновения конвективных явлений), засухи (индекс Палмера [6]). Например, на рис. 1 показан предсказанный уровень наводнений в зависимости от климатического сценария (сценария выбросов),
Рис. 1.
Предсказанный уровень наводнений в зависимости от климатического сценария (сценария выбросов парниковых газов).
• построена модель кредитного риска с поправкой на климатические риски, в которой использование модели волатильности определенного типа позволило существенно реже калибровать модель.
3. СНИЖЕНИЕ РЕСУРСОЕМКОСТИ ОБУЧЕНИЯ БОЛЬШИХ НЕЙРОСЕТЕВЫХ МОДЕЛЕЙ
3.1. Предпосылки проекта
Основной задачей проекта является ускорение обучения больших нейросетевых моделей [8]. Уменьшение времени обучения фактически экономит денежные средства и сокращает углеродный след от вычислений в одинаковых пропорциях. Например, полное обучение всемирно известной GPT-3 модели со 175 миллиардами параметров потребовало бы примерно 3640 Петафлоп/c-дней при стопроцентной утилизации вычислительных устройств. Это эквивалентно 8650 мес вычислений на одной видеокарте Nvidia V100. Экономия даже 10 процентов времени обучения имеет большое экономическое и экологическое значение. В данный момент по проекту ведутся работы в трех основных направлениях: экономия памяти, стохастические методы оптимизации и параллельные алгоритмы на основе т.н. task-based парадигмы программирования.
Экономия памяти при обучении моделей экономит итоговое время обучения, но эта зависимость не очевидна. Уменьшение нагрузки на память открывает возможность одновременной работы с большим количеством входных данных. Чем больше данных обрабатывается одновременно, тем точнее вычисляется градиент по параметрам модели. Таким образом, параметры модели примут свои окончательные значения за меньшее количество эпох обучения и итоговое время снизится.
Без параллельного обучения невозможно обучить хоть какую-то действительно большую нейронную сеть. В настоящее время большинство, если не все, методы параллелизации основаны на т.н. Bulk synchronous парадигме программирования. Этот подход подразумевает чередование параллельных вычислений и обмена данными. В рамках проекта ведется разработка параллельных алгоритмов на основе т.н. task-based парадигмы, основанной на описании всех вычислений в виде направленного графа без циклов. Этот граф вычислений передается специальной библиотеке, в нашем случае это StarPU, которая сама распределяет вычисления и организует пересылки данных асинхронно. За счет асинхронности вычислители не простаивают во время пересылки данных, и общая утилизация всех устройств растет. К сожалению, данный подход требует полного переписывания программного кода с нуля, что является времязатратным процессом.
3.2. Результаты
Инструменты, разработанные в ходе реализации проекта, позволяют экономить память при обучении нейросетевых моделей при помощи следующих алгоритмических улучшений: attention-слой, использующий в три раза меньше временных данных, вычисление неточных градиентов линейных слоев [9, 10] и нелинейных слоев активаций и малопараметрическое представление линейных слоев при помощи тензоров в ТТ-формате.
Разработан новый метод стохастической оптимизации. Безусловно, существует много различных методов оптимизации такого типа, однако, в рассматриваемом случае основной упор делается на тонкую настройку внутренних гиперпараметров оптимизатора для каждой нейросетевой модели, что позволяет получить конкурентноспособный продукт [11].
Созданные подходы уже применены для обучения больших нейросетевых моделей (ruDALLE, “Малевич”), получены снижение памяти, ускорение вычислений, затраченной энергии и углеродного следа на 15% [9, 12].
4. ПРОГНОЗИРОВАНИЕ ЛЕДОВОЙ ОБСТАНОВКИ В АРКТИКЕ
4.1. Предпосылки проекта
Глобальное потепление сделало Арктику доступной для морских операций и создало потребность в надежных оперативных прогнозах движения морского льда для обеспечения их безопасности. Для прогнозирования ледовой обстановки представляют интерес такие регионы, как Баренцево и Карское моря (1), море Лабрадор (2), море Лаптевых (3). Красной и зеленой изолиниями на рис. 2 ограничена зона маргинального льда (концентрация 15–80%), которая дает основной вклад в ошибку прогноза из-за высокой изменчивости ледового покрова.
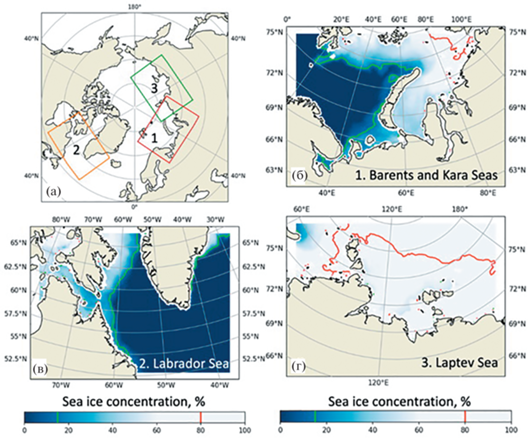
В то время как численные модели океанского льда требуют больших вычислительных ресурсов, относительно легковесные методы на основе машинного обучения могут показывать себя более эффективно в этой задаче. Необходимость использования новых методов машинного обучения определяется тем, что лишь немногие из существующих исследований сосредоточены на разработке систем реального времени для построения ежедневных оперативных прогнозов, учитывающих доступные данные.
4.2. Результаты
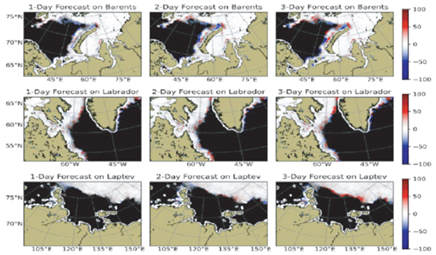
В рамках проекта была усовершенствована технология обучения глубоких сетей с архитектурой U-Net (обучение проводилось в двух режимах), позволившая строить краткосрочные прогнозы морского льда на срок до 10 дней [13]. Было показано, что построенная модель глубокого обучения значительно превосходит простые бейзлайны, а использование дополнительных данных об оперативных прогнозах погоды позволяет дополнительно улучшить качества работы модели. Обучение модели на данных сразу нескольких регионов способствовало улучшению ее обобщающей способности при использовании в новых регионах. В результате получен быстрый и гибкий инструмент для оперативных прогнозов состояния морского льда в регионах Баренцева моря, Лабрадорского моря и моря Лаптевых. На рис. 3 показаны примеры прогнозов наилучшей конфигурации обученной модели U-Net. Представлены результаты для трех различных периодов прогноза (от одного до трех дней). Красно-синей шкалой отражены ошибки прогнозирования модели – прогноз избыточной и недостаточной концентрации морского льда соответственно.
5. САМООБУЧАЮЩАЯСЯ МОДЕЛЬ ПЛАСТА
5.1. Предпосылки проекта
Нефтегазовая отрасль остается и в XXI веке одной из самых наукоемких и цифровизированных и имеет хорошо развитую систему подходов и численных моделей для моделирования и управления нефтедобычей. Обилие методов и продуктов для моделирования нефтегазовых пластов не решает главной проблемы – неопределенности и скудности имеющейся информации, вытекающей из несовершенства методов ее получения, а также вечного противоборства стратегий исследования неизученных областей и применения имеющихся знаний (exploration vs exploitation), что приводит к естественному желанию максимально эффективно использовать имеющуюся информацию. Неопределенности информации бывают разных типов, это, как и относительно понятные неопределенности измерений, как геологических, так и промысловых, численные погрешности гидродинамических симуляций, погрешности процесса адаптации геологогидродинамической модели, так и более сложные и концептуальные источники неопределенностей, как то: некорректность полуэмпирических зависимостей и формул, закладываемых в расчеты, отсутствие или несоответствие геологического реализма моделируемых подземных структур реальным.
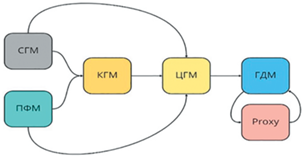
Общая схема взаимодействия различных взаимосвязанных между собой моделей пласта, описывающих различные аспекты функционирования пласта (Петрофизических моделей (ПФМ), Гидродинамических моделей (ГДМ), Сейсмогеологических моделей (СГМ), Концептуальных геологических моделей КГМ, Цифровых геологических моделей (ЦГМ)), при котором выходные данные одной модели зачастую являются входными для другой, изображена на рис. 4. Итоговая Гидродинамическая модель (ГДМ) объединяет все полученные знания о месторождении, адаптируется на реальные данные из месторождения (используя иногда прокси-модели типа IsobarProxy). Далее, происходит долгий ручной процесс адаптации модели на добычу, а весь процесс построения модели месторождения может занимать до полугода и требовать большого количества ресурсов.
Необходимость использования новых методов машинного обучения и анализа данных для построения модели месторождения определяется следующими обстоятельствами:
• данные измерений имеют очень разную локальность и степень надежности, их требуется объединять процедурой, которая будет настраиваться по целевым метрикам,
• данные сейсмических измерений не имеют однозначной интерпретации, процедура интерпретации в идеале должна быть настраиваемой на каждом месторождении,
• решение обратной задачи крайне неэффективно проводить в исходном пространстве кубов гидродинамических параметров месторождения размерностью порядка миллионов или даже миллиардов, поэтому требуются алгоритмы представления месторождения в пространстве параметров меньшей размерности,
• для ускорения процесса адаптации гидродинамической модели требуется значительно ускорить симуляции с возможной потерей точности,
• для адекватного учета рисков и определения конечных коридоров неопределенности по прогнозам добычи требуется проброс неопределенности из исходных данных измерений в конечные прогнозы.
Основной задачей комплексной исследовательской программы СМП (Самообучающаяся Модель Пласта) является одновременный учет с помощью технологий ИИ максимального числа имеющихся данных с их неопределенностями для построения цифровой модели месторождения и оценки будущих показателей добычи, извлекаемых запасов и других важных параметров с доверительными интервалами для принятия обоснованных управленческих решений и, в конечном итоге, повышении экономической эффективности разработки месторождения за счет увеличения количества извлекаемых углеводородов, уменьшения числа неоптимально пробуренных скважин и уменьшения трудозатрат специалистов для построения цифровой модели месторождения. Самообучающаяся модель пласта представляет собой иерархию моделей и методов, принимающую на вход разного типа исходные данные с их неопределенностями, алгоритмы расчета добычи по исходным данным, историю добычи, проводящую автоматическую адаптацию моделей на добычу, уточняющую оценку неопределенностей и выдающую прогнозы добычи с доверительными интервалами.
5.2. Результаты
В рамках проекта поставлены и решены следующие задачи:
Задача объединения данных о месторождении [16]. Стандартные алгоритмы объединения имеющихся на месторождении данных дают не слишком хорошие результаты в силу разной локальности и достоверности данных, а также наличия большого числа выбросов и пропусков в данных. В рамках проекта был разработан новый алгоритм комплексирования данных с помощью алгоритмов непараметрической регрессии с адаптивным ядром, которое настраивается по целевым метрикам для автоматического учета различного качества имеющихся данных. На рис. 5 изображены результаты такого комплексирования на одном из тестовых месторождений (карта проницаемости, полученная комплексированием данных ГИС, ГДИС и сейсмики на участке реального месторождения).
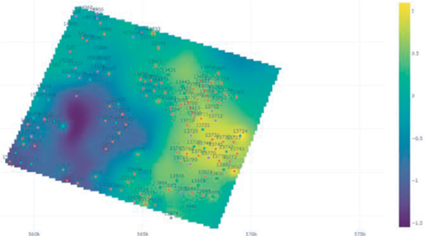
В метрике leave-one-out предложенный подход значительно превзошел результаты спектрального моделирования и кригинга.
Задача обусловленной генерации карт параметров месторождения. Существующие алгоритмы обусловленной генерации карт параметров месторождения плохо справляются с обусловливанием на данные гидродинамических исследований. Разработан новый способ привлечения экспертных знаний геолога о месторождении (таких как типы осадконакопления, преимущественное направление анизотропии и т.д.) и последующей генерации карт месторождения с обусловливанием на эти экспертные знания, а также на все данные, использованные для решения первой задачи. Данный способ реализован с помощью архитектур генеративных состязательных сетей WGAN и PatchGAN, также ведутся эксперименты с технологиями оптимального транспорта [1, 3, 19]. Сотрудники Научно-Исследовательского Института Искусственного Интеллекта (AIRI) и Сколковского Института Науки и Технологий уже использовали разработанные в проекте инструменты оптимального транспорта для повышения разрешения реальных изображений [17]. Полученные результаты подтверждают эффективность методов оптимального транспорта при обработке изображений и позволяют рассчитывать и на хорошую точность при обработке карт распределений физических свойств.
Задача ускорения и уточнения процесса прокси-адаптации гидродинамической модели. Процесс адаптации являет собой наиболее сложную для реализации часть проводимых работ по построению единой модели месторождения. На рис. 6 изображена общепринятая последовательность действий для байесовской адаптации с учетом неопределенности [14, 15]. Сложность процесса адаптации состоит в решении обратной задачи коррекции модели для соответствия расчетов добычи данным измерений, при этом прямая задача расчетов добычи решается обычно с помощью вычислительно сложных недифференцируемых гидродинамических симуляторов по типу Schlumberger Eclipse или tNavigator. Поэтому для решения данной задачи применимы в основном методы на основе Монте-Карло, а также для ускорения процесса – представления в сжатом пространстве признаков и разного рода методы глобальной оптимизации.
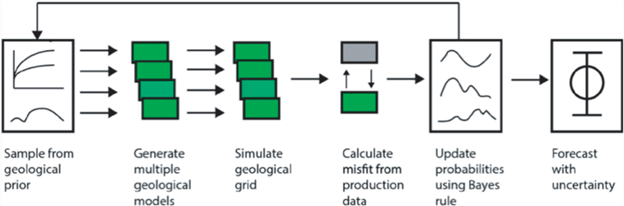
Однако в любом случае остается проблема медленности расчета симулятора и сложности всего процесса адаптации в многомерном пространстве параметров. Одним из возможных решений является предварительная адаптация с помощью быстрых упрощенных (прокси) моделей, и затем точная адаптация с помощью симулятора. Ведутся работы по прокси-адаптации гидродинамической модели месторождения с учетом неопределенностей исходных данных. Также важным направлением исследований являются ускорение и уточнение расчетов прокси-моделей с помощью физически информированных нейронных сетей, это направление является одним из наиболее многообещающих и ключевых для работы центра.
Конечной целью программы исследований СМП является сокращение времени построения модели месторождения и ее адаптации от месяцев до нескольких недель, причем большая часть действий будет выполняться в автоматическом режиме с помощью развитых для этого технологий ИИ. Для достижения этой цели требуется не только развивать отдельные части вычислительной цепочки (см. рис. 6), но также выстраивать верхнеуровневое управление процессом построения модели месторождения с помощью автоматизированных инструментов, интегрирующее в себя как классические методы, так и разные инновационные решения, доступные для использования, и позволяющие с помощью умного планирования выбрать путь решения отдельных задач в зависимости от требуемых метрик качества финального результата и имеющихся ограничений. Для решения этой задачи в центре развиваются методы иерархического моделирования и мультиагентного взаимодействия на основе технологий общего научного и инженерного ИИ.
6. ЗАКЛЮЧЕНИЕ
Миссия Исследовательского Центра Прикладного ИИ состоит в создании моделей и фреймворков ИИ для решения задач устойчивого развития промышленности и экономики РФ. Для разработки модулей ИИ и решения соответствующих прикладных задач в Центре разрабатывается программный инструментарий ИИ в виде платформы с универсальными фреймворками для повышения вычислительной эффективности нейросетевых решений ИИ, учета физики исследуемых процессов в моделях машинного обучения, и консолидация мультимодальных данных от разнородных источников. В свою очередь, программный инструментарий ИИ имплементирует разрабатываемые в Центре методы и алгоритмы машинного обучения и интеллектуального анализа данных. В работе описаны основные прикладные направления исследований Центра Прикладного ИИ и приведены уже достигнутые научные и прикладные результаты.
Список литературы
Rout L., Korotin A., Burnaev E. Generative Modeling with Optimal Transport Maps. ICLR, 2022.
Barannikov S., Trofimov I., Balabin N., Burnaev E. Representation Topology Divergence: A Method for Comparing Neural Network Representations. ICML, 2022.
Korotin A., Kolesov A., Burnaev E. Kantorovich Strikes Back! Wasserstein GANs are not Optimal Transport? Neurips datasets track, 2022.
Lloyd E., Shepherd T. Environmental catastrophes, climate change, and attribution. Annals of the New York Academy of Sciences, 1469, 02 2020.
Эксперты раскрыли данные МЧС по регионам с самыми частыми затоплениями. https://www.rbc.ru/society/26/08/2021/612639f29a79473d011e9e1, 2021. Online;accessed 13-June-2022.
Alley W.M. The Palmer drought severity index: limitations and assumptions. Journal of Applied Meteorology and Climatology. 1984. Vol. 23. No. 7. pp. 1100–1109.
Anisimov O.A., Shiklomanov N.I., Nelson F.E. Variability of seasonal thaw depth in permafrost regions: a stochastic modeling approach. Ecological modelling. – 2002. – Vol. 153. – No. 3. – pp. 217–227.
Gusak J., Cherniuk D., Shilova A., Katrutsa A., Bershatsky D., Zhao X., Eyraud-Dubois L., Shlyazhko O., Dimitrov D., Oseledets I. Beaumont O.Survey on Large Scale Neural Network Training. Proc. of the 31st Int. Joint Conf. on Artificial Intelligence and the 25th European Conf. on Artificial Intelligence (IJCAI-ECAI), 2022.
Novikov G., Bershatsky D., Gusak J., Shonenkov A., Dimitrov D., Oseledets I. Few-Bit Backward: Quantized Gradients of Activation Functions for Memory Footprint Reduction. arXiv:2202.00441, 2022.
Bershatsky D., Mikhalev A., Katrutsa A., Gusak J., Merkulov D., Oseledets I. Memory-Efficient Backpropagation through Large Linear Layers. arXiv:2201.13195, 2022.
Leplat V., Merkulov D., Katrutsa A., Bershatsky D., Oseledets I. NAG-GS: Semi-Implicit, Accelerated and Robust Stochastic Optimizers. arXiv:2209.14937, 2022.
Budennyy S., Lazarev V., Zakharenko N., Korovin A., Plosskaya O., Dimitrov D., Arkhipkin V., Oseledets I., Barsola I., Egorov I., Kosterina A., Zhukov L. Eco2AI: Carbon Emissions tracking of Machine Learning models as the first step towards sustainable AI. arXiv:2208.00406, 2022.
Grigoryev T., Verezemskaya P., Krinitskiy M., Anikin N., Gavrikov A., Trofimov I., Balabin N., Shpilman A., Eremchenko A., Gulev S., Burnaev E., Vanovskiy V. Data-Driven Short-Term Daily Operational Sea Ice Regional Forecasting. arXiv: 2210.08877, 2022.
Arnold D. et al. Uncertainty quantification in reservoir prediction: part 1 – model realism in history matching using geological prior definitions. Mathematical Geosciences. – 2019. – Vol. 51. – No. 2. – pp. 209–240.
Demyanov V. et al. Uncertainty quantification in reservoir prediction: part 2 – handling uncertainty in the geological scenario. Mathematical Geosciences. – 2019. – Vol. 51. – No. 2. – pp. 241–264.
Вановский В.В., Дупляков В.М., Попков Д.О., Морозов А.Д., Вайнштейн А.Л., Осипцов А.А., Бурнаев Е.В. Построение куба проницаемости с адаптацией на ГИС ГДИС и сейсмические исследования. Тезисы конференции “Интеллектуальный анализ данных в нефтегазовой отрасли. Третья научно-практическая конференция”, 21–23 сентября 2022 г., Новосибирск, Россия, 2022.
Gazdieva M., Rout L., Korotin A., Kravchenko A., Filippov A., Burnaev E. An Optimal Transport Perspective on Unpaired Image Super-Resolution. arXiv:2202.01116, 2022.
Rakhimov R., Ardelean A.-T., Lempitsky V., Burnaev E. NPBG++: Accelerating Neural Point-Based Graphics. CVPR, 2022.
Asadulaev A., Korotin A., Egiazarian V., Burnaev E. Neural Optimal Transport with General Cost Functionals. arXiv:2205.15403, 2022.
Matveev A., Rakhimov R., Artemov A., Bobrovskikh G., Egiazarian V., Bogomolov E., Panozzo D., Zorin D., Burnaev E. DEF: Deep Estimation of Sharp Geometric Features in 3D Shapes. ACM Transactions on Graphics. Volume 41, Issue 4July 2022, Article No.: 108 pp. 1–22.
Дополнительные материалы отсутствуют.
Инструменты
Доклады Российской академии наук. Математика, информатика, процессы управления