

Исследование Земли из Космоса, 2020, № 3, стр. 77-92
Уточнение параметров классификации методом опорных векторов (SVM) при крупномасштабном картографировании арктических ландшафтов (на примере острова Белый, Карское море)
О. С. Сизов a, b, c, *, И. Р. Идрисов d, А. А. Юртаев d
a АО “Российские космические системы”
Москва, Россия
b Институт проблем нефти и газа РАН
Москва, Россия
c Российский государственный университет нефти и газа (национальный исследовательский университет)
им. И.М. Губкина
Москва, Россия
d Тюменский государственный университет
Тюмень, Россия
* E-mail: sizov_os@ntsomz.ru
Поступила в редакцию 03.12.2019
Аннотация
На примере острова Белый, расположенного в Карском море, изучаются вопросы автоматизации ландшафтного картографирования. Выбор острова в качестве тестового объекта обусловлен решением правительства Ямало-Ненецкого округа о создании научного стационара для планомерных фундаментальных исследований последствий антропогенного воздействия на арктические экосистемы. На примере небольшого тестового участка, полевое изучение которого выполнено летом 2016 г., рассматриваются актуальные методические подходы ландшафтного картографирования на основе объектно-ориентированного анализа изображений (OBIA) и классификации методом опорных векторов (SVM). Предлагается комбинированный способ, основанный на независимой обработке исходных данных с последующей статистической обработкой полученной информации. Результаты исследования показали, что подобный способ позволяет более детально подходить к оценке ландшафтной дифференциации территории исследований. Впервые для территории острова Белый используются высокодетальные снимки со спутника “Ресурс-П” и цифровые модели рельефа ArcticDEM. Использование объектно-ориентированного дешифрирования позволит в дальнейшем расширить набор исходных данных за счет материалов съемки с БПЛА, а результаты классификации SVM могут быть улучшены за счет дополнительных тематических слоев морфометрического анализа цифровых моделей рельефа. Предложенная технология применима для выполнения крупномасштабного ландшафтного картографирования всей территории острова Белый.
ВВЕДЕНИЕ
Многочисленные исследования (https://www.amap. no/documents/doc/arctic-arctic-climate-impact-assessment/796) показывают, что в настоящее время в арктических регионах под влиянием глобальных климатических колебаний и антропогенного воздействия, связанного с интенсификацией добычи углеводородов и традиционного природопользования (оленеводства) наблюдаются масштабные изменения природных условий. В связи с этим на севере Западной Сибири по инициативе правительства Ямало-Ненецкого автономного округа (ЯНАО) с 2014 г. организованы планомерные научные исследования происходящих изменений (http://docs.cntd.ru/document/460282983). В качестве одной из фоновых площадок мониторинга выбран остров Белый, что определяет необходимость актуализации данных о современном состоянии его природных условий и, в частности, о структуре и разнообразии ландшафтного покрова.
Наличие возможности использования в качестве фактической основы для составления ландшафтной карты различных высокодетальных мультиспектральных данных дистанционного зондирования Земли (ДЗЗ) и цифровых моделей рельефа позволяет применить современные алгоритмы автоматического дешифрирования, способные обеспечить максимальную достоверность и объективность результатов. Анализ актуальных работ в данной области (Li et al., 2014; Mountrakis et al., 2011; Blaschke, 2010; Waske, Benediktsson, 2007) показал, что одним из наиболее эффективных и доступных методических подходов является объектно-ориентированное дешифрирование (object based image analysis, OBIA) на основе метода опорных векторов (support vector machines, SVM).
В условиях большого разнообразия научных подходов и программных средств к выполнению OBIA целью данной работы является разработка оптимальной методики крупномасштабного ландшафтного дешифрировании (1 : 10 000), основанной на использовании открытых исходных данных и общедоступного программного обеспечения. При этом основной исследовательской задачей является определение интервалов значений базовых параметров метода SVM, которые непосредственно определяют точность и достоверность результатов.
РАЙОН И МАТЕРИАЛЫ ИССЛЕДОВАНИЙ
Остров Белый – небольшой (58 × 43 км) остров, расположенный в Карском море, отделятся от полуострова Ямал проливом Малыгина шириной до 9 км. Широта самой северной точки острова – мыса Белый – 73°30′ с.ш., максимальная высота над у. м. – 12 м. Средняя многолетняя температура воздуха составляет –0.3°С в мае, +4.1°С в июле, +5.3°С в августе, +1.9°С в сентябре. Влажность воздуха около 90%. Преобладают ветра северного, северо-восточного и юго-западного направления. Глубина залегания многолетнемерзлых пород (ММП) составляет в среднем 50–60 см, глубина сезонноталого слоя (СТС) изменяется от нескольких дециметров на водораздельных равнинах до 1 м и более на морском пляже (Дружинин и др., 2015).
Остров является типичным примером западно-носибирских арктических островных тундр. Важным ландшафтообразующим фактором являются приливы и отливы, сочетающиеся со сгонно-нагонными процессами и штормами. Так, в 2005 г. шторм привел к подъему уровня воды на острове на 6 м. Вдоль побережья расположены места массового гнездования, линьки и остановок во время миграций белолобого гуся и черной казарки, линьки гуменника. На острове постоянно обитает дикий северный олень, белый медведь, на песчаных отмелях встречаются атлантический морж, нерпа, морской заяц и белуха (Васильчук, Васильчук 2015). Течения Карского моря выносят на остров остатки древесины (плавник, которым нередко заполнена овражно-балочная сеть острова) и различные виды мусора.
В ноябре 1933 г. у протоки Рагозина в северо-западной части острова открыта морская гидрометеорологическая (полярная) станция. В феврале 1972 г. станции присвоено имя бывшего начальника Амдерминского РМЦ Михаила Владимировича Попова. Из-за разрушения берега протоки метеорологическая площадка несколько раз переносилась: в 1950-х гг. и в сентябре 1966 г. дважды на 50 м на юго-юго-восток, в сентябре 1973 г. на 180 м на северо-восток. В советское время неподалеку от станции располагалась военная часть, а также проводились геологоразведочные работы на нефть и газ – в северной и северо-западной частях острова пробурены 4 скважины глубиной 2.5 км (Дружинин и др., 2015). С 2012 по 2016 гг. при поддержке Администрации ЯНАО на острове проводились ежегодные экологические работы по сбору и вывозу металлолома и рекультивации нарушенных участков (Галиулин и др., 2016).
В качестве фактической основе в рамках данной работы использовались два основных источника пространственных данных:
– мультиспектральные снимки со спутника “Ресурс-П” (аппаратура Геотон) за 2016 г., обеспечивающие полное покрытие территории острова безоблачной съемкой с предельным пространственным разрешением порядка 1.6 м/пикс. (каналы R, G, B, NIR). Материалы съемки были получены на безвозмездной основе от Научного центра оперативного мониторинга Земли АО “Российские космические системы” в рамках деятельности Госкорпорации “Роскосмос” по обеспечению российских государственных потребителей, включая научные организации РАН и высшие учебные заведения, что делает их использование предпочтительным для научных исследований в условиях высокой стоимости зарубежных аналогов.
– цифровая модель поверхности (ЦМП) ArcticDEM (https://www.pgc.umn.edu/data/arcticdem/), доступная для всей территории Земли севернее 60 град. с.ш. с разрешением 2 м/пикс. ЦМП ArcticDEM обладает наилучшей детальностью по сравнению с другими глобальными ЦМП (AW3D30, AsterGDEM2 и др.). В условиях отсутствия растительности на острове Белом ArcticDEM может использоваться как полноценная цифровая модель рельефа (ЦМР), отражающая все особенности мезо- и микрорельефа района работ при небольших относительных высотных перепадах.
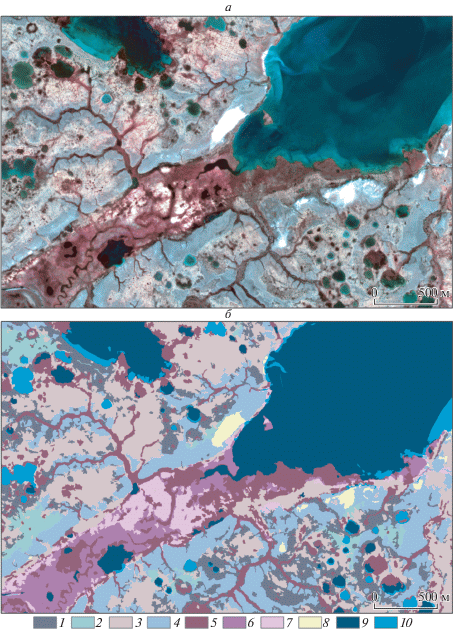
Непосредственно для проведения тестового картографирования был выбран небольшой участок размером 3.6 × 2.3 км, распложенный в центральной части острова и примечательный тем, что здесь проходит сквозная долина рек Пахаяха и Нябилахаяха (рис. 1). Максимальные высотные отметки достигают 11 м над у. м., минимальные – 2 м. Участок полностью покрывается фрагментом снимка с КА “Ресурс-П” от 7 июля 2016 г. (разрешение 1.6 м/пикс., маршрут 01772_02) и фрагментом ЦМП ArcticDEM, созданном на основе съемки с КА WorldView-1,2 (разрешение 2 м/пикс., тайл мозаики № 48_57_2_2).
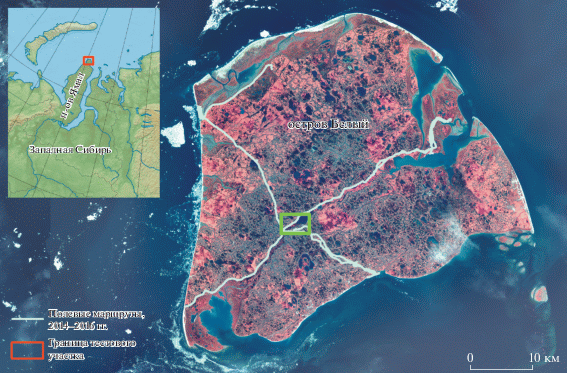
Описание эталонов дешифрирования выполнено в ходе экспедиций сотрудниками Тюменского госуниверситета в 2014–2016 гг. (Дружинин и др., 2015, Юртаев, 2016, Юртаев, Сулкарнаев, 2018). В полевых условиях изучены формы рельефа, почвенный и растительный покров, глубина сезонного протаивания грунтов, установлена приуроченность ПТК к той или иной форме рельефа (пойме, лайде, водораздельной равнине и др.). Особое внимание уделялось формам мезорельефа как важным факторам ландшафтной дифференциации на уровне типов урочищ. Всего охарактеризованы 12 ландшафтных профилей с шагом наблюдений от 10 до 20 м и протяженностью до 1 км, выполнены детальные комплексные описания на 70 ключевых участках и репрезентативных точках (из них 5 точек находятся в пределах тестового участка).
МЕТОДИКА ДЕШИФРИРОВАНИЯ
Согласно принятым научно-методическим подходам (Козин, 2007; Мильков, 1986) базовой единицей крупномасштабного ландшафтного картографирования является вид урочища, представляющий собой закономерный комплекс фаций, достаточно хорошо обособленный в природе в связи с неровностями рельефа и неоднородным составом почв и верхней части толщи четвертичных отложений. Ведущими факторами в дифференциации видов урочищ являются растительность и микрорельеф при относительно однородном литолого-фациальном комплексе, что определяет необходимость использования при классификации урочищ дополнительно к мультиспектральной информации тематических слоев ЦМР и вегетационных индексов.
Выделение контуров и определение видов конкретных природных комплексов ландшафтной структуры (урочищ и типов местности) традиционно выполняется на основе визуального дешифрирования экспертом-ландшафтоведом и является наиболее трудоемким этапом при создании ландшафтной карты (Идрисов и др., 2017; Козин, 2008). Для автоматизации этой процедуры в рамках подхода OBIA выполнялись следующие действия:
1. Создание на тестовый участок единого 6-канального изображения, включающего 4 мультиспектральных канала снимка с КА “Ресурс-П” (рис. 2, а), а также слои ЦМП ArcticDEM и вегетационного индекса NDVI, рассчитанного на основе данных с КА “Ресурс-П”. Для объединения каналов использовался модуль Semi-Automatic Classification Plugin (https://www.researchgate.net/ publication/265031337_Semi-Automatic_Classification_Plugin_User_Manual) в открытом программном обеспечении (ПО) QGIS 3.6 (https://qgis.org/ ru/site/).
Рис. 2.
а – фрагмент исходного мультиспектрального снимка “Ресурс-П”, разрешение 1.6 м/пикс., б – результат сегментации исходных данных, в – результат растеризации сегментов со средними значениями по каждому.
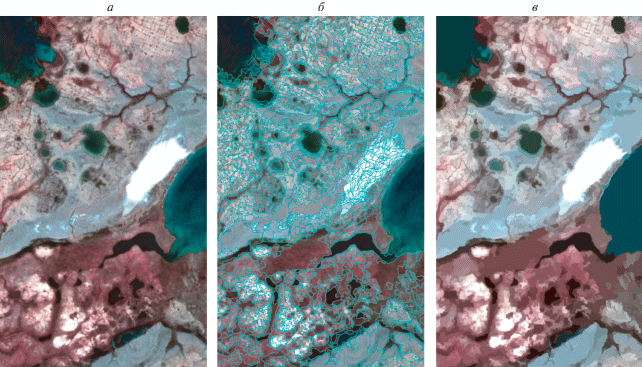
2. Сегментация полученного изображения с помощью инструмента Large-Scale MeanShift (LSMS) в открытом ПО OrfeoToolbox 6.6.0 (https://www.orfeo-toolbox.org/CookBook/Applications/app_LargeScaleMeanShift.html). Инструмент основан на алгоритме среднего смещения (MeanShift algorithm), который чувствителен к пространственному разрешению и адаптирован для обработки растров большого объема (Comaniciu, Мееr, 2002). Настройка инструмента ограничивается выбором параметров минимальной площади сегмента и размера используемой виртуальной памяти ПК. Полученный векторный слой сегментов (рис. 2, б) в таблице атрибутов содержит средние значения яркости в каждом спектральном канале, что позволяет провести растеризацию с помощью QGIS и получить исходное сегментированное изображение для классификации (рис. 2, в).
3. Классификация с обучением методом SVM с помощью инструмента SVM Classification в открытом ПО SAGA 7.3.0 (System for Automated Geoscientific Analyses) (Conrad et al., 2015). Инструмент основан на широко распространенной библиотеке libSVM (Chang, Lin, 2011), которая используется во многих приложениях (EnMAP box, ENVI, eCognition, PCI Geomaica и др.) и позволяет задавать все необходимые параметры SVM для повышения качества классификации.
4. Оценка качества классификации проводилась с помощью инструмента Confusion Matrix (Polygons/Grid) в ПО SAGA 7.3.0, который рассчитывает все стандартные характеристики – матрицу ошибок по классам (Confusion Matrix), точность разработчика (Accuracy Producer), точность пользователя (Accuracy User), коэффициент Каппа (Kappa) и общую точность (Overall Accuracy).
Таким образом, все используемые инструменты относятся к классу открытого ПО, имеющего полноценный функционал. Наиболее сложным и неопределенным моментом данной методики является выбор параметров классификации SVM, который определяется особенностями данного метода.
ХАРАКТЕРИСТИКА МЕТОДА SVM
SVM представляет собой набор контролируемых методов обучения, используемых для классификации, регрессии и обнаружения статистических выбросов. В случае линейной разделимости исходных данных метод основан на построении гиперплоскости, разделяющей объекты выборки наиболее оптимальным способом (оптимальной разделяющей гиперплоскости, ОРГ) (Вапник, 1974). Алгоритм работает в предположении, что чем больше расстояние (зазор) между ОРГ и объектами разделяемых классов, тем меньше будет средняя ошибка классификатора (рис. 3).
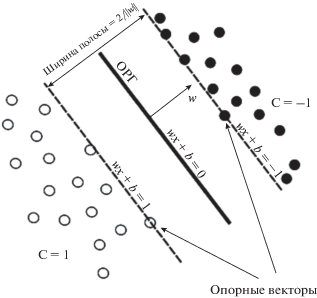
Пусть имеется обучающий набор точек вида {(x1, c1), (x2, c2), …, (xn, cn)}, где xi – это n-мерный вещественный вектор, а ci принимает значение 1 или –1 в зависимости от того, какому классу принадлежит точка xi. Для классификации необходимо построить разделяющую гиперплоскость следующего вида: wx + b = 0, где w – перпендикуляр к разделяющей гиперплоскости, b определяется кратчайшим расстоянием между гиперплоскостью и началом координат. Так как мы определяем оптимальное разделение, то нас интересуют ближайшие к опорным векторам детерминируемых классов гиперплоскости, которые могут быть описаны следующими уравнениями: wx + b = 1 и wx + b = –1, ширина полосы между которыми равна 2/|w|. Таким образом, задача сводится к оптимизации при условии, что ci(wxi + b) ≥ 1, 1 ≤ i ≤ n, которая является стандартной задачей квадратичного программирования и решается с помощью множителей Лагранжа (Романов, Рубанов, 2012). В итоге алгоритм классификации может быть записан в виде:
(1)
$f(x) = {\text{sign}}\left( {\sum\limits_{i = 1}^n {{{\lambda }_{i}}{{c}_{i}}{{x}_{i}}x + b} } \right),$Для нелинейного разделения классов было предложено заменить скалярные произведения нелинейными функциями ядра. При этом все образцы обучающей выборки Rn переводятся в пространство более высокой размерности H с помощью специального отображения φ: Rn → H так, чтобы в новом пространстве объекты были линейно разделимы (Boser et al., 1992, Cortes, Vapnik, 1995).
Существует несколько типов ядер (22 Chang et al., 2011):
– линейное: K(xi, xj) = $x_{i}^{T}{{x}_{j}}.$
– полиномиальное: K(xi, xj) = (γ$x_{i}^{T}{{x}_{j}}$ + r)d, γ > 0.
– радиальная базисная функция (radial basis function, RBF): K(xi, xj) = exp(–γ|xi – xj|2), γ > 0.
– сигмоид: K(xi, xj) = th(γ$x_{i}^{T}{{x}_{j}}$ + r),
где γ, r, и d – параметры ядра.
К преимуществу метода SVM относится возможность выбора наиболее подходящего ядра для решения конкретной задачи, включая возможность создания собственных типов ядер. Однако существует и ряд недостатков SVM, которые усложняют его практическое применение (Mountrakis et al., 2011):
– не существует общего подхода к автоматическому выбору ядра и его параметров в случае нелинейной разделимости классов;
– напрямую не рассчитываются оценки вероятности, они получаются дополнительно с использованием затратной перекрестной проверки (кросс-валидации).
Для успешной классификации методом SVM должны быть определены оптимальный тип ядра и его параметры (Chang, Lin, 2011).
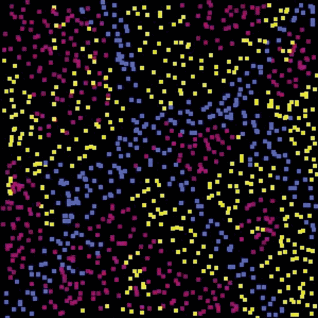
Для выбора типа ядра с помощью инструмента, предложенного на странице разработчиков библиотеки libSVM (https://www.csie.ntu.edu.tw/ ~cjlin/libsvm/) была создана простейшая выборка, имитирующая ландшафт тестового участка (рис. 4). Сравнение различных вариантов классификаций показало, что наилучшие результаты дает ядро RBF (табл. 1). Использование RBF рекомендовано для большинства задач, поскольку в ядре локализованные и конечные отклики наблюдаются по всему спектру действительной оси х.
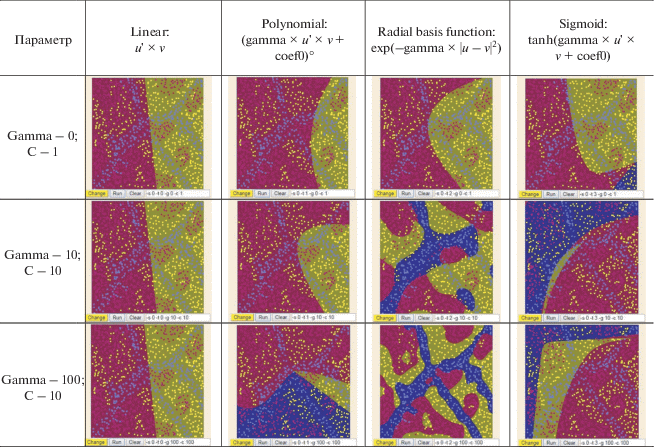
Параметры ядра определяются моделью классификатора опорных векторов (Support Vectors Classifier, SVC) и в случае использования RBF фактически ограничиваются двумя переменными (https://chrisalbon.com/machine_learning/support_ vector_machines/svc_parameters_using_rbf_kernel/, https://scikit-learn.org/stable/auto_examples/svm/ plot_rbf_parameters.html):
– параметр гамма (γ) – определяет как далеко распространяется влияние эталона (чем ниже значение, тем дальше влияние, но выше дисперсия и наоборот), рассматривается как обратная величина радиуса влияния выборок, выбранных моделью в качестве опорных векторов.
– параметр регуляризации или штрафной параметр (С) – противопоставляет правильность классификации значению решающей (определяющей границы) функции – для больших значений параметра запас решающей функции будет минимальным для всех объектов выборки и наоборот, снижение С будет увеличивать запас функции за счет снижения точности обучения.
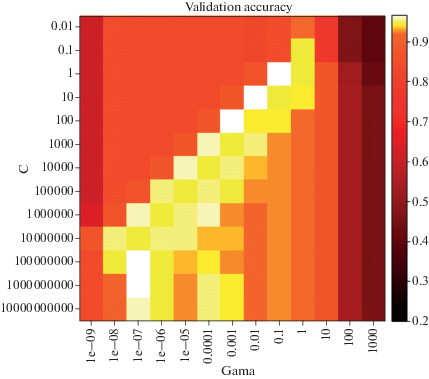
Программная реализация метода SVM включает алгоритм поиска оптимальных значений γ и С методом кросс-валидации (cross-validation) путем сравнения точности классификации для различных сочетаний параметров по эталонам и по объектам тестовой выборки (Chang, Lin, 2011, https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation) (рис. 5). Сложность такого подхода состоит в том, что в результате статистического перебора рассчитываются оптимальные интервалы значений параметров, реальную достоверность которых из-за возникающего эффекта переобучения невозможно подтвердить математически, т.е. требуется дополнительный экспертный анализ исходя из особенностей исходных данных и требований к их моделированию.
Рис. 5.
Пример определения наилучшего сочетания параметров γ и С с помощью кросс-валидации на примере тестовой выборки (результат γ = 0.1; C = 1.0, точность 0.97).
В программной реализации SVM также предлагается важный методический прием, существенно повышающий точность классификации и сокращающий объем требуемых вычислений – масштабирование (scaling) исходных многопараметрических данных (Chang, Lin, 2011, https://scikit-learn.org/stable/modules/preprocessing.html). Существует два способа масштабирования, которые могут рассматриваться как взаимозаменяемые:
– нормализация (normalization) – линейное приведение значений всех атрибутов объектов классификации к общему интервалу [–1, +1] или [0, 1],
– стандартизация (standardization) – приведение значений всех атрибутов объектов к стандартному гауссовому распределению с нулевым средним значением и границами в пределах единичной дисперсии.
Наиболее распространенной моделью SVC является модель С-SVC на основе параметра регуляризации С, однако в качестве улучшенной версии предложена модель nu-SVM, ограничивающая значения С в пределах [0, 1] (Scholkopf, Smola, 2000). Результаты тестирования показали, что модель nu-SVM не показывает существенной разницы по качеству классификации с С-SVC, но более сложна в оптимизации (требует большего объема вычислений) (Chang, Lin, 2011).
Таким образом, оптимальными исходными параметрами SVM для проведения классификации являются: ядро – RBF, модель классификатора – С-SVC. В рамках исследования требуется оценить влияние масштабирования данных и различных сочетаний параметров γ и С на точность классификации на основе статистической и экспертной оценки.
РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЯ
На основе материалов полевых описаний была составлена легенда, включающая 10 основных классов (табл. 2). Эталоны обучения и верификации выбирались визуально при соблюдении условия равномерного распределения. Всего было выбрано 125 эталонов обучающей выборки (от 3 до 29 на класс) и 34 тестовых эталона (от 2 до 8 на класс).
Таблица 2.
Характеристика классов ландшафтной карты
| № | Описание урочища |
|---|---|
| Водораздельно-тундровый тип местности | |
| 1 | Плоские недренированные поверхности первой морской террасы с мезотрофными местами обводненными осоково- сфагновыми и пушицево-травяно-моховыми болотами в сочетании с травяно-моховыми влажными тундрами и прогрессивно заторфовывающимися хасыреями молодых генераций на глееземах перегнойных тундровых, глееземах торфянистых и торфяных болотных |
| 2 | Плоские слабодреннированные слабонаклонные с мелкокочковатым микрорельефом поверхности первой морской террасы с травяно-моховыми влажными тундрами на глееземах арктических и глееземах перегнойных тундровых |
| 3 | Слабонаклонные с сетью вытянутых ложбин поверхности первой морской террасы с травяно-моховыми влажными тундрами по основной поверхности и ивнячково-травяно-моховыми болотами по ложбинам на глееземах арктических и глееземах торфянистых в сочетании с полигональными тундрами |
| Склоновый тип местности | |
| 4 | II. Пологие с мелкокочковатым и местами мелкобугристым микрорельефом склоны долины с травяно-моховыми влажными и лишайниково-мохово-травяными тундрами на арктотундровых слабооглеенных гумусовых почвах и почвах пятен |
| Мелкодолинный тип местности | |
| 5 | VIII. 6. Плоские слабодренированные долины рек малых порядков с травяно-моховыми и пушицево-злаковыми влажными тундрами и низинными травяно-моховыми болотами на глееземах торфянистых в сочетании с хасыреями и приозерными понижениями |
| Пойменный тип местности | |
| 6 | VII. 5. Плоские мелкокочковатые по межбугорным понижениям обводненные поверхности высокой поймы с низинными мохово-травяными болотами на торфяных болотных почвах |
| 7 | VII. 4 . Редко затапливаемые поверхности высокой поймы с травяно-моховыми тундрами и низинными осоково-сфагновыми болотами по ложбинам стока |
| Прочие территории | |
| 8 | Песчаные раздувы на дренированных водоразделах первой морской террасы |
| 9 | Водная поверхность, тип 1 |
| 10 | Водная поверхность, тип 2 |
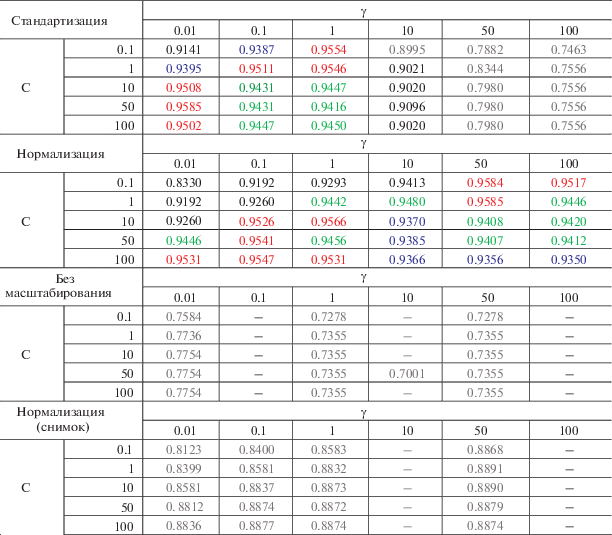
На основе рекомендаций (Chang, Lin, 2011, https://scikit-learn.org/stable/auto_examples/svm/ plot_rbf_parameters.html) и опыта подобных исследований (Qian et al., 2014) были выбраны пары параметров γ и С, для которых выполнена классификация с двумя вариантами масштабирования и проведена статистическая оценка ее точности. Для сравнения на примере отдельных сочетаний параметров γ и С, показавших наибольшую достоверность, была выполнена классификация и оценка точности без масштабирования. Кроме того, для ряда сочетаний была выполнена классификация и оценка точности исходного космического снимка (с использованием нормализации). Всего выполнено 142 тестовых классификации, результаты оценки общей точности (Overall Accuracy) по 96 классификациям представлены в табл. 3. Максимальные показатели составили 0.9547–0.9585.
Таблица 3.
Оценка общей точности (Overall Accuracy) классификации для различных параметров ядра RBF (значения более 0.95 выделены красным; 0.94–0.949 – зеленым; 0.93–0.939 – синим; 0.9–0.929 – черным; менее 0.9 – серым)
Итоги экспериментов показали следующее:
– наилучшие результаты при стандартизации данных дают значения γ = 0.01, С = 50 (0.9585) и γ = 1, С = 0.1 (0.9554). Увеличение γ более 1 существенно снижает качество классификации для любых значений С;
– наилучшие результаты при нормализации данных дают значения γ = 0.1, С = 100 (0.9547) и γ = 50, С = 1 (0.9585);
– без нормализации данных точность классификации не превышает 0.78 для любых сочетаний параметров γ и С;
– классификация исходного несегментированного снимка при условии нормализации данных показывает худшую точность по сравнению с сегментированным изображением для любых сочетаний параметров γ и С (максимальная точность составила 0.8891 при γ = 50, С = 1).
Наглядно видно, что для обоих типов масштабирования существуют интервалы наиболее эффективных значений параметров γ и С, формирующие две обособленные группы. Поскольку не существует математических способов выбора единственного наилучшего значения, для окончательного решения использовался визуальный анализ путем попарного сравнения с исходным снимком. Сравнение показало, что при незначительных отличиях, связанных с точностью выделения долин мелких водотоков и небольших озер, лучший результат достигается при стандартизации с параметрами γ = 0.01 и С = 50 (коэффициент Каппа – 0.94623, общая точность – 0.95845). Матрица ошибок по отдельным классам представлена в табл. 4. Наглядно результат классификации показан на рис. 6.
Таблица 4.
Матрица ошибок для классификации с параметрами ядра γ = 0.01 и С = 50 (стандартизация), номера классов – см. табл. 2
| Класс | 1 | 2 | 9 | 4 | 5 | 10 | 3 | 7 | 8 | 6 | Точность пользователя, % | Точность разработчика, % |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 3065 | 274 | 0 | 460 | 45 | 0 | 24 | 0 | 0 | 0 | 79 | 55 |
| 2 | 0 | 5736 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 94 |
| 9 | 0 | 0 | 39 439 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 100 | 100 |
| 4 | 92 | 0 | 0 | 14 084 | 0 | 0 | 13 | 0 | 2 | 0 | 99 | 97 |
| 5 | 181 | 112 | 0 | 0 | 2343 | 0 | 0 | 0 | 0 | 0 | 89 | 98 |
| 10 | 0 | 0 | 0 | 0 | 0 | 2791 | 0 | 0 | 0 | 0 | 100 | 100 |
| 3 | 2203 | 0 | 0 | 0 | 2 | 0 | 19 561 | 0 | 0 | 0 | 90 | 100 |
| 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2486 | 0 | 0 | 100 | 76 |
| 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4442 | 0 | 100 | 100 |
| 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 766 | 0 | 2347 | 75 | 100 |
| Итого | 5541 | 6122 | 39439 | 14 544 | 2390 | 2791 | 19 598 | 3252 | 4444 | 2347 | ||
| Точность, % | 55 | 94 | 100 | 97 | 98 | 100 | 100 | 76 | 100 | 100 |
ОБСУЖДЕНИЕ РЕЗУЛЬТАТОВ
SVM зарекомендовал себя как эффективный метод классификации с обучением, позволяющий получать достаточно высокие результаты при относительно небольшом объеме обучающей выборки (Романов, Рубанов, 2012; Foody, 2004). При этом он менее чувствителен к явлению Хьюза, которое состоит в том, что при ограниченной обучающей выборке точность классификации имеет тенденцию уменьшаться по мере увеличения пространства признаков (Hughes, 1968; Plaza et al., 2009). Это свойство делает его предпочтительным при классификации гиперспектральных данных, а также мультиспектральных данных с привлечением дополнительных тематических слоев (ЦМР, NDVI и др.) (Watanachaturaporn et al., 2008, Борзов, Потатуркин, 2017). Также можно отметить, что процесс настройки SVC существенно проще настройки и обучения нейронной сети.
В отношении точности SVM по сравнению с другими алгоритмами можно привести результаты обзора 220 исследований (Ma et al., 2017), из которых 64 используют классификатор NN, 55 – классификатор SVM, 44 – классификатор RF, 33 – классификатор DT, 14 – классификатор максимального правдоподобия (MLC) и 10 – другие классификаторы. Анализ показал, что метод RF обычно характеризуется максимальной общей точностью классификации (85.81%), за которым с небольшим отставанием следуют SVM (85.19%) и DT (84.15%), тогда как показатели NN и MLC в среднем ниже – 81.58 и 81.55% соответственно. Несмотря на то, что исходные данные и обучающая выборка в исследованиях отличаются, результаты оценки точности различных классификаторов в целом отражают реальные возможности алгоритмов с небольшим разбросом значений (Li et al., 2016). Наиболее перспективным подходом в настоящее время является использование нейронных сетей (сверточных нейронных сетей, глубоких сетей доверия и сложенных автоэнкодеров), которые на основе пространственно-спектральных признаков позволяют в отдельных случаях достичь точности 93–99% (Li et al., 2018).
На точность классификации в рамках любого метода оказывает воздействие выбор пространства признаков. В ряде исследований (Борзов, Потатуркин, 2017; Li et al., 2018) показано, что при учете только спектральных или пространственных признаков точность на 6–14% ниже, чем при объектно-ориентированном подходе. Выбор алгоритма сегментации в данном случае является самостоятельной исследовательской задачей, но, при существующих различиях разработанных алгоритмов (Dey, 2010), общим приемом при ландшафтном дешифрировании является сокращение минимальной площади сегмента при сохранении семантического смысла и различимости границ различных фаций в пределах базового урочища. Расширение пространства признаков может происходить как на этапе сегментации, так и позже, на этапе классификации за счет любых дополнительных тематических слоев (морфометрических характеристик, вегетационных и почвенных индексов, сведений о подстилающих породах и др.). Решающую роль при этом играет методическая обоснованность выбора индикаторов с учетом минимизации эффекта слияния сходных по характеристикам классов.
Существует также ряд факторов неопределенности влияющих на точность классификации, связанный с выбором эталонов и объектов тестовых участков (Ma et al., 2017). В большинстве случаев используются алгоритмы случайного (рандомного) выбора сегментов равномерно по всему полю изображения. Тем не менее, для экономии времени в условиях мозаичной структуры ландшафтов представляется целесообразным сокращать количество эталонов для однородных участков. Эталоны могут выбираться на основе имеющихся сегментов, что также ускоряет подготовительный этап дешифрирования. Предельные значения объема обучающей и тестовой выборок зачастую определяются эмпирически, однако полноценных исследований на эту тему не проводилось (Li et al., 2014; Ma et al., 2017). Тем не менее отдельные работы (Qian et al., 2014) показывают, что рост числа объектов приводит к незначительному и нелинейному повышению точности. С другой стороны, можно привести пример, демонстрирующий высокую эффективность метода SVM даже в условиях ограниченной обучающей выборки (Романов, Рубанов, 2012). В рамках данного исследования общая площадь обучающей выборки составила 6.5% от общей площади участка, площадь тестовой выборки – 3%.
Необходимо отметить, что недостатком метода SVM является отсутствие учета весовых коэффициентов эталонов, поэтому для сложных классов рекомендуется введение дополнительных уточняющих подклассов с последующим объединением. Также отсутствует возможность введения весовых коэффициентов для индикационных признаков.
Метод SVM в настоящее время является основным в модулях объектно-ориентированного дешифрирования наиболее распространенного коммерческого ПО ENVI, eCognition и Geomatica (https://www.harrisgeospatial.com/docs/backgroundsvmgeneral.html, http://www.pcigeomatics.com/geomatica-help/concepts/focus_c/oa_classif_intro_svm.html), не считая пробных попыток внедрения алгоритмов глубокого обучения (deep learning). Судя по доступным руководствам пользователя, во всех случаях аналогично открытым SAGA и OrfeoToolbox используется общедоступная библиотека libSVM (Chang, Lin, 2011), поэтому выбор конкретного ПО с позиции качества результатов SVM не имеет существенного значения. Отличия программной реализации состоят в части интерфейса, быстродействия и доступности выбора отдельных параметров (например, в ENVI отсутствует выбор способа масштабирования исходных данных). Другими словами, наличие открытой библиотеки libSVM позволяет эффективно использовать возможности метода SVM без привязки к ПО, которые дополняются выполнением подготовительных и постклассификационных операций в открытом геоинформационном ПО.
В качестве перспективной альтернативы SVM может рассматриваться использование алгоритмов глубокого обучения, доступных в частности с помощью модуля otbtf в ПО OrfeoToolbox (https://www.orfeo-toolbox.org/a-remote-module-for-deep-learning/, https://arxiv.org/pdf/1807.06535.pdf). Фактически модуль является фрейворком открытой библиотеки TensorFlow (https://www.tensorflow.org/), куда интегрированы инструменты потоковой обработки данных ДЗЗ, реализованные в OrfeoToolbox.
Таким образом, результаты исследования показали, что для небольших территорий при оптимальном выборе параметров ядра, равномерной обучающей выборке и достаточном наборе признаков метод SVM позволяет получить точность классификации более 90%, что сопоставимо с уровнем точности нейронных сетей с современной архитектурой, требующих при этом трудоемкого обучения и значительных вычислительных ресурсов. Собственно, SVM может рассматриваться как аналог простой двухслойной нейронной сети, где число нейронов на скрытом слое определяется автоматически как число опорных векторов.
ЗАКЛЮЧЕНИЕ
По итогам выполненных работ можно сделать вывод, что подход OBIA для ландшафтного дешифрирования может демонстрировать высокие показатели точности при следующих условиях:
1. Наличие кондиционных исходных данных, включая высокодетальные мультиспектральные снимки и ЦМР с сопоставимым разрешением, кроме этого могут использоваться вспомогательные тематические слои, дающие значимую индикационную информацию.
2. Сегментирование многоканального изображения до уровня различимости границ различных фаций в пределах базового урочища на основе алгоритмов, учитывающих значения пространственного разрешения и эффективных для работы с большими объемами исходных данных.
3. Классификация сегментированного изображения на основе метода SVM, при этом рекомендуется использовать ядро RBF, модель классификатора С-SVC, масштабирование данных (стандартизацию или нормализацию) и параметры ядра γ в интервале [0.01; 1] и С в интервале [10; 100]. Наилучшее сочетание параметров ядра для тестового участка – γ = 0.01, С = 50, метод масштабирования – стандартизация, при этом коэффициент Каппа составил 0.94623, а общая точность – 0.95845.
4. Увеличение числа и площади эталонов обучающей выборки незначительно способствует повышению точности классификации, на тестовом участке площадь эталонов составила 6.5% от общей площади.
Все операции по подготовке данных, классификации и постклассификации (оценки точности) могут быть успешно выполнены в открытом ПО без потери качества (QGIS, SAGA, OrfeoToolbox).
В целом, разработанная на основе OBIA методика крупномасштабного ландшафтного дешифрировании (1 : 10 000 и крупнее) показала на тестовом участке свою высокую эффективность, перспективы продолжения работ связаны с построением на ее основе ландшафтно-экологической карты на всю территорию острова Белый.
Список литературы
Борзов С.М., Потатуркин О.И. Исследование эффективности спектрально-пространственной классификации данных гиперспектральных наблюдений // Автометрия. 2017. Т. 53. № 1. С. 32–42. https://doi.org/10.15372/AUT20170105
Вапник В.Н. Теория распознавания образов // M.: Наука, 1974. 416 с.
Васильчук А.К., Васильчук Ю.К. Инженерно-геологические и геохимические условия полигональных ландшафтов острова Белый (Карское море) // Инженерная геология. 2015. № 1. С. 50–72.
Галиулин Р.В., Башкин В.Н., Алексеев А.О., Галиулина Р.А., Арабский А.К. Остров Белый: рекультивация почв // Neftegaz.RU. 2016 № 7–8. С. 96–100. https://neftegaz.ru/science/ecology/331565-ostrov-belyy-rekultivatsiya-pochv/
Дружинин А.Н., Идрисов И.Р., Маршинин А.В. Опыт картографирования ландшафтов арктической тундры на примере северо-западной части острова Белый (Карское море) // Геоинформационное картографирование в регионах России: Матер. VII Всерос. науч.-практ. конф. (Воронеж, 10–12 декабря 2015 г.). Воронеж: Научная книга, 2015. С. 46–54.
Идрисов И.Р., Маршинин А.В., Марьинских Д.М. Опыт крупномасштабного картографирования арктических ландшафтов Западной Сибири // Геодезия и картография. 2017. Т. 78. № 7. С. 31–37.
Козин В.В. Ландшафтный анализ в нефтегазопромысловом регионе. // Тюмень: Изд-во ТюмГУ, 2007. 240 с.
Козин В.В., Холодилов И.В. Ландшафтно-экологический подход при комплексной оценке экологического состояния участков перспективного нефтегазового освоения на Севере Западной Сибири // Вестник Тюменского государственного университета. Социально-экономические и правовые исследования. 2008. № 3. С. 234–240.
Мильков Ф.Н. Физическая география: учение о ландшафте и географическая зональность. Воронеж. 1986. 328 с.
Постановление Правительства Ямало-Ненецкого автономного округа от 25 декабря 2013 года № 1096-П “Об утверждении государственной программы Ямало-Ненецкого автономного округа “Развитие научной, научно-технической и инновационной деятельности на 2014–2021 годы”. http://docs.cntd.ru/document/460282983
Романов А.А., Рубанов К.А. Эффективность непараметрических классификаторов в условиях лимитированной обучающей выборки // Журн. СФУ. Техника и технологии. 2012. № 5. С. 495–506.
Юртаев А.А. Комплексные исследования почвенного покрова о. Белый: первые итоги // Научный вестник Ямало-Ненецкого автономного округа. 2016. № 4(93). С. 8–11.
Юртаев А.А., Сулкарнаев Ф.Р. Комплексные исследования почвенного покрова о. Белый: промежуточные итоги // Научный вестник Ямало-Ненецкого автономного округа. 2018. № 1(98). С. 74–78.
A remote module for Deep learning [Электронный ресурс] https://www.orfeo-toolbox.org/a-remote-module-for-deep-learning/, дата обращения 30.07.2019.
Arctic Climate Impact Assessment – Scientific Report. 2006. P. 1046. https://www.amap.no/documents/doc/arctic-arctic-climate-impact-assessment/796
Boser B.E., Guyon I., Vapnik V. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual // Workshop on Computational Learning Theory. 1992. P. 144–152.
Blaschke T. Object based image analysis for remote sensing // ISPRS J. Photogrammetry and Remote Sensing. 2010. № 65. P. 2–16. https://doi.org/10.1016/j.isprsjprs.2009.06.004
Chang C.C., Lin C.J. LIBSVM: a library for support vector machines // ACM Transactions on Intelligent Systems and Technology. 2011. № 2/3. P. 1–27.
Conrad O., Bechtel B., Bock M., Dietrich H., Fischer E., Gerlitz L., Wehberg J., Wichmann V., Boehner J. System for Automated Geoscientific Analyses (SAGA) v.2.1.4 // Geosci. Model. 2015. Dev., 8, 1991–2007. https://doi.org/10.5194/gmd-8-1991-2015
Comaniciu D., Meer P. Mean shift: a robust approach toward feature space analysis // IEEE Transactions on Pattern Analysis and Machine Intelligence. 2002 № 24(5). P. 603–619. https://doi.org/10.1109/34.1000236
Cortes C., Vapnik V. Support-vector network // Machine Learning. 1995. № 20. P. 273–297.
Cresson R. A framework for remote sensing images processing using deep learning techniques [Электронный ресурс] https://arxiv.org/pdf/1807.06535.pdf, дата обращения 30.07.2019.
Cross-validation: evaluating estimator performance [Электронный ресурс] https://scikit-learn.org/stable/modules/cross_validation.html#cross-validation, дата обращения 30.07.2019.
Dey V., Zhang Y., Zhong M. A review on image segmentation techniques with remote sensing perspective // ISPRS TC VII Symposium – 100 Years ISPRS, Vienna, Austria, July 5–7, 2010, IAPRS, V. 38. № 7A. P. 31–42.
Foody G.M. Toward intelligent training of supervised image classifications: directing training data acquisition for SVM classification // Remote Sensing of Environment. 2004. № 1(93). P. 107–117.
Hughes G.F. On the mean accuracy of statistical pattern recognizers / G.F. Hughes // IEEE Transactions on Information Theory. 1968. № 1(14). P. 55–63.
LIBSVM – A Library for Support Vector Machines [Электронный ресурс] https://www.csie.ntu.edu.tw/~cjlin/libsvm/, дата обращения 30.07.2019.
Li M., Zang S., Zhang B., Li S., Wu C. A Review of Remote Sensing Image Classification Techniques: the Role of Spatio-contextual Information // European J. Remote Sensing. 2014. № 47(1). P. 389–411. https://doi.org/10.5721/EuJRS20144723
Li M., Ma L., Blaschke T., Cheng L., Tiede. D. A systematic comparison of different object-based classification techniques using high spatial resolution imagery in agricultural environments // International J. Applied Earth Observation and Geoinformation. 2016. № 49. P. 87–98. https://doi.org/10.1016/j.jag.2016.01.011
Li Y., Zhang H., Xu, X., Jiang Y., Shen Q. Deep learning for remote sensing image classification: A survey // Wiley Interdisciplinary Reviews: Data Mining and Knowledge Discovery. 2018. № 1264. https://doi.org/10.1002/widm.1264
Ma L., Li M., Ma X., Cheng L., Du P., Liu Y. A review of supervised object-based land-cover image classification // ISPRS J. Photogrammetry and Remote Sensing. 2017. V. 130. P. 277–293. https://doi.org/10.1016/j.isprsjprs.2017.06.001
Mountrakis G., Im J., Ogole C. Support vector machines in remote sensing: A review // ISPRS Journal of Photogrammetry and Remote Sensing. 2011. № 66(3). P. 247–259. https://doi.org/10.1016/j.isprsjprs.2010.11.001
Plaza A. Recent advances in techniques for hyperspectral images / Plaza A, Benediktsson J.A., Boardman J.W., Brazile J., Bruzzone L. et al. // Remote Sensing of Environment. 2009. № 10(113). P. 110–122.
Preprocessing data [Электронный ресурс] https://scikit-learn.org/stable/modules/preprocessing.html, дата обращения 30.07.2019.
RBF SVM parameters [Электронный ресурс] https://scikit-learn.org/stable/auto_examples/svm/plot_rbf_parameters.html, дата обращения 30.07.2019.
Scholkopf B., Smola A., Williamson R. C., Bartlett P. L. New support vector algorithms. // Neural Computation. 2000. V. 12. P. 1207–1245.
Support Vector Machine Background [Электронный ресурс] https://www.harrisgeospatial.com/docs/backgroundsvmgeneral.html, дата обращения 30.07.2019.
Support Vector Machine classifier [Электронный ресурс] http://www.pcigeomatics.com/geomatica-help/concepts/focus_c/oa_classif_intro_svm.html, дата обращения 30.07.2019.
SVC Parameters When Using RBF Kernel [Электронный ресурс] https://chrisalbon.com/machine_learning/support_ vector_machines/svc_parameters_using_rbf_kernel/, дата обращения 30.07.2019.
TensorFlow [Электронный ресурс] https://www.tensorflow.org/, дата обращения 30.07.2019.
Trimble. Ecognition Developer 8.7 Reference Book; Trimble: Munich, Germany, 2011.
Qian Y., Zhou W., Yan J., Li W., Han L. Comparing Machine Learning Classifiers for Object-Based Land Cover Classification Using Very High Resolution Imagery // Remote Sensing. 2014. V. 7 № 1. P. 153–168. https://doi.org/10.3390/rs70100153
Waske B., Benediktsson J.A. Fusion of support vector machines for classificationof multisensor data // IEEE Transactions in Geoscience and Remote Sensing. 2007. V. 45. P. 3858–3866.
Watanachaturaporn P., Arora M.K., Varshney P.K. Multisource classification using support vector machines: An empirical comparison with decision tree and neural network classifiers // Photogrammetric Engineering and Remote Sensing, 2008. V. 74. № 2. P. 239–246.
[Электронный ресурс] https://www.pgc.umn.edu/data/ arcticdem/, дата обращения 30.07.2019.
[Электронный ресурс] https://www.researchgate.net/ publication/265031337_Semi-Automatic_Classification_ Plugin_User_Manual, дата обращения 30.07.2019.
[Электронный ресурс] https://qgis.org/ru/site/, дата обращения 30.07.2019.
[Электронный ресурс] https://www.orfeo-toolbox.org/ CookBook/Applications/app_LargeScaleMeanShift.html, дата обращения 30.07.2019.
Дополнительные материалы отсутствуют.
Инструменты
Исследование Земли из Космоса