

Программирование, 2019, № 4, стр. 36-45
ДЕТЕКТИРОВАНИЕ КЛЕТОК МОЗГА В ОПТИЧЕСКОЙ МИКРОСКОПИИ НА ОСНОВЕ ТЕКСТУРНЫХ ХАРАКТЕРИСТИК МЕТОДАМИ МАШИННОГО ОБУЧЕНИЯ
С. А. Носова a, *, В. Е. Турлапов a, **
a Нижегородский государственный университет им. Н.И. Лобачевского
603950 Нижний Новгород, пр. Гагарина, д. 23, Россия
* E-mail: svetlana.nosova@itmm.unn.ru
** E-mail: vadim.turlapov@itmm.unn.com
Поступила в редакцию 16.02.2019
После доработки 16.02.2019
Принята к публикации 19.03.2019
Аннотация
Рассматривается задача детектирования нейронов в оптической микроскопии на примере срезов мозга мыши, окрашенных по Нисслю. Предложенный алгоритм включает в себя следующие шаги: предобработка, извлечение текстурных признаков, классификация пикселей, кластеризация пикселей. Исследуется применение в этой задаче различных алгоритмов предобработки, алгоритмов машинного обучения, различных текстурных характеристик. На этапе классификации при помощи алгоритма k ближайших соседей (kNN) или наивного байесовского классификатора (NBC) определяется принадлежность каждого пикселя телу нейрона. В работе исследованы 2 типа текстурных признаков, построенных на основе: нормализованной гистограммы; матрицы взаимной встречаемости (GLCM). Для нахождения центров нейронов все пиксели, принадлежащие нейронам, кластеризуются при помощи алгоритма сдвига среднего (mean shift). Показано, что наилучшее качество детектирования достигается при использовании вычисления текстурных признаков по GLC-матрице с радиусом окрестности R = 6 с показателями качества: precision = 0.82, recall = 0.92, F1 = 0.86. Показано, что использование различных алгоритмов предобработки существенно влияет на результат детектирования. Алгоритм kNN показал лучший результат детектирования по сравнению с NBC. На рассматриваемом наборе данных выбор параметра k > 15 не дает существенного повышения качества детектирования. Предложенный метод показал результат того же порядка, что был достигнут в работе Inglis A., 2008: Recall(A) = 865%. При выборочном тестировании на открытых данных по гистологии портала Broad Bioimage Benchmark Collection (Image Sets) предложенный подход показал лучший или эквивалентный результат в детектировании числа клеток на изображениях. Алгоритм использует для детектирования только текстурные признаки, что снимает ограничения на распараллеливание вычислений.
1. ВВЕДЕНИЕ
Первыми задачами обработки изображений срезов коры мозга, окрашенных по Нисслю, являются: определение границ слоев коры мозга; детектирование и классификация нейронов, сбор статистики о расположении нейронов. Стоит отметить высокую техническую сложность процедуры окрашивания по Нисслю и, как следствие, отсутствие для него формализованной процедуры классификации нейронов и астроцитов.
В данной работе рассматривается задача автоматизации детектирования нейронов. Выбор методов решения задачи зависит от рассмотрения двух вопросов: особенности нейронов как объектов на изображении и качества тренировочных данных (знаний), полученных от специалиста. В настоящее время существуют решения (включая методы искусственного интеллекта) для автоматизации морфологический анализ для Nissl-окрашенных изображений срезов мозга [1]. В то же время есть много нерешенных вопросов.
Задача детектирования нейронов осложняется следующими особенностями:
1. Нейроны различны по форме.
2. Размеры нейронов на одном изображении могут различаться более, чем в 2 раза.
3. Изображения тел нейронов часто перекрываются.
4. Изображения тел нейронов могут иметь низкую контрастность с фоном.
5. Изображения нейронов одного типа могут иметь значительные различия в гистограмме.
6. Изображения нейронов могут иметь “пустоты” внутри своих тел.
Предложенный метод состоит из следующих этапов: предобработка изображений, классификация пикселей, принадлежащих телам нейронов, и нахождение центров кластеров пикселей. Для этапа предобработки используются различные алгоритмы перевода в оттенки серого [2], выравнивание гистограммы [3], квантование гистограммы [4]. На этапе классификации пикселей используется метод k ближайших соседей (kNN) [5] и наивный байесовский классификатор [6]. Каждый пиксель описывается вместе с его окрестностью радиуса R набором текстурных характеристик, которые вычисляются: по гистограмме [7] и на основе матрицы взаимной встречаемости [8].
Для нахождения центров кластеров пикселей используется алгоритм сдвига среднего (mean shift) [9]. Для оценки качества детектирования использованы оценки, описанные в [10].
Для тестирования алгоритма использован набор данных “Mus Musculus” портала BrainMaps [11] и наборы снимков биологических клеток Broad Bioimage Benchmark Collection [12]. В работе использованы реализации классификаторов библиотеки OpenCV [13].
2. ОБЗОР ПУБЛИКАЦИЙ
С точки зрения качества решения задач детектирования и классификации наилучшим вариантом является большой размер тренировочной базы, когда потрачены значительные ресурсы на качественную разметку объектов (десятки-сотни сложных объектов, тысячи простых). В этом случае для решения задач детектирования сегодня часто используются различные варианты глубокого обучения [14] или комплексные методы машинного обучения [1].
В случае меньших ресурсов, затрачиваемых на разметку, и, соответственно, при меньшем объеме тренировочной базы задача традиционно решается методами машинного обучения, в том числе с использованием методов k ближайших соседей (kNN) [15], машины опорных векторов (SVM) [16].
Когда образцы разметки единичны или отсутствуют, приходится производить довольно обширное исследование признаков, обеспечивающих приемлемую надежность детектирования и классификации объектов. В этом случае для исследования применяются классические методы обработки изображений, например, методы водораздела [17], математической морфологии, поиск по шаблону и др. [18].
Исследование в данной работе относится к случаю минимальной размеченной базы или полному ее отсутствию. Во всех случаях работы с изображениями текстурные характеристики оказываются очень полезными. Наиболее важными причинами являются:
• возможность формализовать описание структуры изображения;
• возможность иерархического (многомасштабного) применения данного описания;
• возможность автоматической параллельной обработки;
• умение работать с трехмерными изображениями.
Для ознакомления с исследованиями по текстурному анализу можно использовать работу [19].
Особое место занимает вычисление текстурных характеристик по матрице взаимной встречаемости (Gray Level Co-Occurrence Matrice), текстурные характеристики Харалика [8]. Для некоторого региона изображения строится матрица, каждый элемент которой P(i, j) показывет вероятность встречаемости пикселей с интенсивностями i, j, находящихся на некотором расстоянии d друг от друга в выбранном направлении. Матрица имеет размеры N × N. Наиболее популярными значениями N в практике применения метода являются N = 8 и Т = 16, а размеры фрагментов изображения составляют от 30 × 30 до 50 × 50. На основе данной матрицы строится небольшое количество четких, информативных и структурно-ориентированных скалярных характеристик. Благодаря своим качествам метод реализован в математической среде Matlab, он стал одной из основных функций обработки изображений при дистанционном зондировании Земли [20].
В публикации последнего десятилетия 2012 года [21] показано, что использование следа матрицы GLCM в сочетании с характеристиками Харалика обеспечивает наилучшие результаты.
Метод, предложенный в [22], использует 16 различных признаков, извлеченных из GLCM, для сбора информации о текстурах. Он может классифицировать текстуры с различной ориентацией, масштабами и областями с одинаковыми текстурами и успешно распознает текстуры, имеющие схожие значения интенсивности. Ложноположительные области удаляются с использованием морфологии. Для исследования использованы более 80 текстур Бродаца.
В публикации [23] показано, что использование расстояния d = 1 для построения матрицы встречаемости (GLCM) может дать лучшие результаты, чем использование d = 2. Использование θ = 0° показывает сопоставимые результаты с θ = 90°. Делается вывод о том, что использование детектирования границ при помощи оператора Собеля вместе с GLCM оказывается эффективным методом количественной оценки текстуры поверхности изображения.
Сегодня метод GLCM широко используется в диагностике головного мозга по данным МРТ.
Типичным примером этого является публикация [24], в которой важные особенности были выделены с помощью алгоритма GLCM. Затем набор функций разделяется на три типа с использованием машины опорных векторов (SVM). Область поражения была сегментирована с точностью 90.23%, что выше, чем у предыдущего метода с точностью 87.34%. Одной из задач данной работы является применение GLCM для детектирования нейронов головного мозга. В качестве ориентира для сравнения наших результатов, полученных для оптической микроскопии с Nissl-окрашенными срезами мозга, мы рассмотрим публикацию 2008 года [1]. Этапы алгоритма, описанные в этой статье, включают активную сегментацию контуров для определения контуров потенциальных тел нейронных клеток с последующим обучением искусственной нейронной сети с использованием таких свойств сегментации, как размер, оптическая плотность, вращение и т. д. Алгоритм положительно идентифицирует 86 ± 5% нейронов на данный набор Nissl-окрашенных изображений, в то время как полуавтоматические методы получают 80 ± 7%.
3. АЛГОРИТМЫ ПРЕДОБРАБОТКИ
3.1. Перевод в оттенки серого
Данные микроскопа могут быть представлены как изображениями в оттенках серого, так и цветными изображениями. Для расширения области применения алгоритма целесообразно использовать перевод цветного изображения, где каждый пиксель представлен вектором трех цветовых компонент {R, G, B}, в оттенки серого. Кроме того, обработка изображений в оттенках серого требует меньших вычислительных затрат, чем обработка цветных изображений. Следует отметить, что при использовании данного преобразования теряется часть информации, которая содержалась в исходном изображении.
Существуют различные алгоритмы перевода в оттенки серого [25]. Исходные изображения портала BrainMaps снимков головного мозга имеют явный фиолетовый подтон. Исходя из этого были выбраны несколько алгоритмов перевода в оттенки серого, представленные в табл. 1. На рис. 1(a)–(d) представлены результаты применения различных алгоритмов перевода в оттенки серого.

3.2. Выравнивание гистограммы
В данной работе использовано суммирующее выравнивание гистограммы (Cumulative histogram equalization, CHE). Гистограмма изображения представляет собой распределение значений серого на изображении. По данным гистограммы возможно проанализировать частоту появления различных уровней серого, содержащихся в изображении. На рис. 2(а) представлена гистограмма, показывающая, что на изображении представлена часть общего диапазона оттенков серого. Данное изображение имеет низкую контрастность. Предполагается, что гистограмма изображения хорошего качества охватывает все возможные значения в серой шкале. Это значит, что изображение имеет хорошую контрастность, различные детали изображения могут быть легко различимы. Существуют различные алгоритмы выравнивания гистограммы [3]. В данной работе использовалось суммирующее выравнивание гистограммы (Cumulative histogram equalization, CHE). На рис. 2 представлены гистограмма для исходного изображения и гистограмма изображения с применением алгоритма CHE. Ниже представлены формулы для вычисления гистограммы H для изображения I размером M × N, суммирующей гистограммы Heq, результирующего изображения (Ieq):
Рис. 2.
Гистограмма: (a) – исходного изображения, (б) – гистограмма изображения после ее выравнивания.
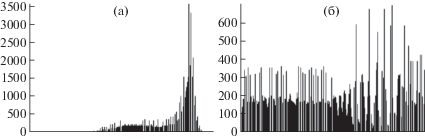
Результат применения данного алгоритма представлен на рис. 1(d).
4. ТЕКСТУРНЫЕ ХАРАКТЕРИСТИКИ
В данной работе используются текстурные признаки окрестности каждого пикселя для его классификации как пикселя фона или пикселя нейрона. Удобно задавать окрестность пикселя радиусом, но можно также описывать ее как прямоугольную область I изображения размером N × N. Здесь и далее N = 2R + 1. В данной работе используется вычисление двух типов текстурных характеристик: по гистограмме и по матрице взаимной встречаемости. Все текстурные характеристики нормализуются [0,1] по значениям тренировочных данных.
4.1. Гистограмма
Строится гистограмма p(I) распределения интенсивности изображения размером N × N с центром в текущем пикселе. Вычисляются следующие характеристики гистограммы:
Вектор <stddev, skewness, kurtosis> образует текстурную классификационную характеристику пикселя.
4.2. Матрица взаимной встречаемости
Матрица взаимной встречаемости позволяет получить статистику о частоте взаимной встречаемости пикселей интенсивности i с пикселями с интенсивности j, которые расположены на расстоянии d пикселей в направлении θ, на некотором фрагменте изображения. Обозначается Pθ,d(i, j). Размер матрицы определяется величиной (IMAX – – IMIN + 1)2, где IMAX – максимальное значение интенсивности изображения, IMIN – минимальное значение интенсивности изображения. Обозначим Np = (IMAX – IMIN + 1). Подсчет матрицы происходит по следующим формулам:
Для вычисления текстурной характеристики данная матрица рассчитывается для окрестности N × N пикселя I(x, y). N = 2R + 1, где R – “радиус” окрестности. Данная матрица рассчитывается для направлений 0°, 45°, 90°, 135°, что соответствуют векторам направлений (0, 1), (1, 1), (1, 0), (0, –1). Эксперименты показали, что при d = 1 достигается наилучшее качество детектирования (не приведены в данной работе). Таким образом, для каждой окрестности пикселя рассчитывается 4 матрицы взаимной встречаемости (для 4-х различных направлений). Для каждого из этих направлений рассчитываются следующие текстурные характеристики Харалика:
Гомогенность,
Контрастность,
Корреляция
Локальная гомогенность,
Вектор STθ, d = $\langle {\text{AS}}{{{\text{M}}}_{{\theta ,d}}},{\text{CON}}{{{\text{T}}}_{{\theta ,d}}}$, CORθ, d, ${\text{ID}}{{{\text{M}}}_{{\theta ,d}}}\rangle $ создает текстурную характеристику I(x, y) в выбранном направлении θ. Суммарная текстурная характеристика рассчитывается по формуле:
5. МЕТОДЫ МАШИННОГО ОБУЧЕНИЯ
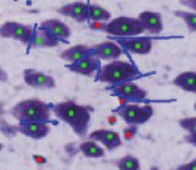
Для предварительной классификации изображения, отделения пикселей, относящихся к нейронам, от всех остальных пикселей, используются методы машинного обучения. Пример предварительной разметки специалистом приведен на рис. 3. Для каждого пикселя (x, y) разметки вычисляется набор текстурных признаков для области изображения с центром в (x, y) и радиусом R. Результат заносится в тренировочную базу.
Рис. 3.
Пример разметки специалистом. Отмечены: центры скоплений окрашенных пикселов, являющихся нейронами; не являющихся нейронами; линии разделения слившихся нейронов.
5.1. Метод k ближайших соседей
Метод k ближайших соседей (kNN, k Nearest Neighbor) является одним из самых интуитивно понятных алгоритмов классификации. Так как мы используем вектор признаков для описания некоторого пикслея x, который надо классифицировать как принадлежащий или не принадлежащий центру нейрона. Для каждого рассматриваемого пикселя x вычисляются расстояния между текстурными характеристиками рассматриваемого пикселя и всеми текстурными признаками из тренировочной базы. После чего выбираются k ближайших текстурных признаков и рассматриваются классы, к которым они принадлежат. В качестве итогового результата выбирается тот класс, за который “проголосовало” наибольшее количество тестовых признаков из k ближайших соседей. В качестве метрики расстояния использована Евклидова метрика.
5.2. Наивный байесовский классификатор
При использовании наивного байесовского классификатора (Naive Bayes Classifier, NBC) необходимо ввести предположение, что компоненты текстурных признаков являются независимыми случайными величинами, то есть, иметь сильное предположение о независимости между предикторами [19]. Ниже приведено основное уравнение, которое определяет NBC:
Т.к. P(A1..An) – постоянная величина для данного пикселя и не может повлиять на конечный результат, пиксель с набором характеристик A1..An принадлежит следующему классу пикселей Cmax:
В данной работе в качестве P(Ai|с) используется гауссово распределение вероятности:
где µi – среднее для текстурного признака i в классе С, полученное из тестовой выборки; σi – стандартное отклонение текстурного признака i в классе С из тестовой выборки; Ai – текстурный признак i из (A1..An); С – класс пикселя.5.3. Сдвиг среднего
На данном этапе происходит непосредственное вычисление центров кластеров, как центра тяжести пикселов, отнесенных к классу “нейрон” в окрестности радиуса R пикселя x. Процедура поиска центра кластера, к которому относится пиксель x, заключена в следующем:
1. Положить, что x – центр кластера.
2. Вычислить положение m(x) средней плотности пикселей, детектированных как нейрон, из квадратной окрестности S со стороной 2Rms + 1 текущего пикселя по формуле ниже
3. Вычислить сдвиг среднего m(x) – x. Если $\left| {m(x) - x} \right| > \varepsilon $, переместить x в точку m(x) и повторить процедуру, начиная с п. 2. В противном случае перейти к следующему пикселю.
6. ОЦЕНКА КАЧЕСТВА АЛГОРИТМА ДЕТЕКТИРОВАНИЯ
Для оценки качества детектирования необходимо вычислить следующие характеристики: количество верных детектирований центров нейронов (TP, true positive), количество ложных детектирований центров нейронов (FP, false positive) и количество недетектированных центров нейронов (FN, false negative) из тестовой базы. Далее вычисляются следующие оценки качества детектирования:
Для того, чтобы определить, к какому классу (TP, FP, FN) относится центр, применяется следующая процедура для всех детектированных центров нейронов ci и размеченных специалистом центров нейронов mj:
1. Положить TP = 0, FP = 0, FN = 0.
2. Для каждого детектированного центра ci:
a. Найти ближайший mj
b. Если $\left| {{{c}_{i}} - {{m}_{j}}} \right| < {{R}_{{acc}}}$, где Racc – средний радиус нейрона; то увеличить TP на 1 и удалить mj и ci из рассмотрения. В противном случае, увеличить FP на 1.
3. Для каждого центра mi: для которого не был найден ci:
a. Увеличить FN на 1.
7. РЕЗУЛЬТАТЫ
В Таблице 2 приведены характеристики реализации и особенности тестовой системы.
Таблица 2.
Характеристики тестовой системы и реализации
| Язык\компилятор | С++, MVS 2013 |
| Библиотеки\технологии | OpenCV, CUDA |
| Характеристики системы | Intel® Core™ i7-3820 CPU @ 3.6 GHz 3.6 GHz, 16Gb RAM, 64-bit OS Windows 7, Nvidia GeForce GTX 680 |
Был проведен набор экспериментов для тестирования реализаций и выбора оптимального набора алгоритмов и методов. В качестве первого набора экспериментов использовались данные портала BrainMaps, которые были размечены и для которых было подсчитано количество нейронов. Часть данных (рис. 3) была использована в качестве тестовой выборки, для тестовых изображений известно количество нейронов на них. В данном наборе экспериментов использовались следующие значения параметров:
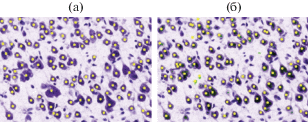
Результаты детектирования при использовании различных текстурных признаков kNN при k = 31 и использовании Yluminance представлено на рис. 4.
Рис. 4.
Результат детектирования нейронов методом kNN при k = 31 на основе текстурных признаков: (a) – по гистограмме, (б) – по матрице взаимной встречаемости.
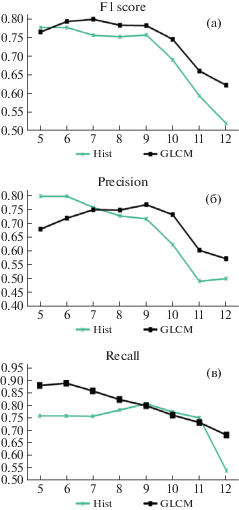
На рис. 5(a)–(c) представлены количественные характеристики качества детектирования при использовании различных текстурных характеристик в зависимости от R. Использование текстурных характеристик по матрице GLCM позволяет получить лучшее качество детектирования, поэтому далее используется вычисление текстурных характеристик Харалика, а текстурные характеристики на основе гистограммы не рассматриваются.
Рис. 5.
(a)–(в) – результаты детектирования с использованием различных текстурных характеристик в зависимости от R с использованием алгоритма kNN при k = 31, Yluminance.
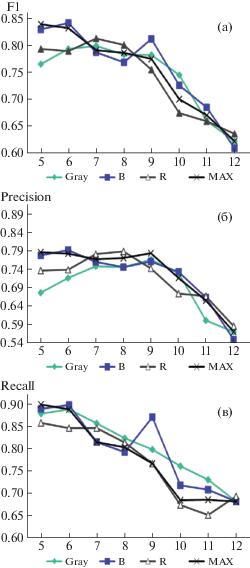
На рис. 6(a)–(b) представлены результаты, показывающие зависимость качества детектирования от выбора алгоритма перевода в оттенки серого. Наилучший результат достигается для перевода в оттенки серого по одной только синей компоненте. В следующих экспериментах используется именно этот алгоритм.
Рис. 6.
(a)–(в) –результаты детектирования с использованием различных алгоритмов перевода в оттенки серого в зависимости от R при использовании GLCM, kNN при k = 31.
На рис. 7(a) представлены результаты детектирования при использовании различного количества бинов гистограммы. Лучшие результаты детектирования достигаются при R = 6, что соответствует радиусу нейрона. Выбор числа уровней серого (2, 4 или 8 бинов) гистограммы при использовании GLCM дает схожие результаты (F1 = = 0.83–0.85). Интересно, что при использовании 2 бинов гистограммы достигается наилучший результат.
Рис. 7.
(a) – характеристика F1 результата детектирования при использовании различного количества квантов гистограммы; (б) – качество детектирования при использовании различных алгоритмов классификации в зависимости от радиуса; (в) – зависимость качества детектирования от выбора параметра k алгоритма kNN.
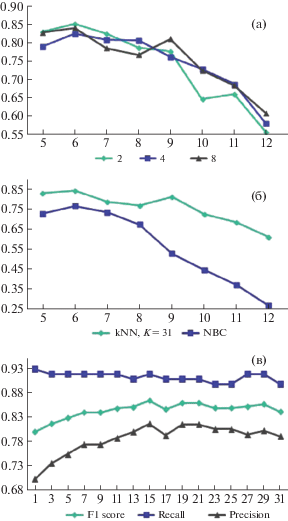
На рис. 7(b) представлены результаты детектирования с использованием различных алгоритмов классификации пикселей. Показано, что kNN представляет лучший результат детектирования.
На рис. 7(c) показана зависимость качества детектирования от выбора параметра k. При k > 15 не происходит прирост качества детектирования. Для проведения следующих экспериментов использовались данные портала Broad Bioimage Benchmark Collection [1]. Суть эксперимента заключается в подсчете количества клеток на изображениях и сравнении полученных данных со значениями, полученными от специалистов. Изображения представлены в оттенках серого. В качестве алгоритмов предобработки использованы выравнивание гистограммы и метода Otsu для бинаризации. Использован метод kNN (k = 15) и вычисление текстурных характеристик на основе матриц взаимной встречаемости. Использованы следующие параметры:
Чтобы сравнить результаты алгоритма с предложенными, сначала для каждого изображения вычисляют абсолютную разницу между полученным значением и средним числом между значениями специалистов. После чего полученное значение делится на среднее число между значениями специалистов. Среднее значение для всех изображений набора и является ошибкой. Основные результаты представлены в табл. 3. Показано, что предложенный подход позволяет получить аналогичное или лучшее качество детектирования клеток.
Таблица 3.
Ошибка подсчета количества клеток на некоторых наборах Broad Bioimage Benchmark Collection
| Набор данных | Разброс в разметке специалистов | [26] | Предложенный подход |
|---|---|---|---|
| BBBC001: Human HT29 | 11% | 6.2% | 6.47% |
| BBBC002: Drosophila Kc167 cells | 16% | 17% | 8.63% |
8. ЗАКЛЮЧЕНИЕ
Предложен алгоритм детектирования клеток на изображениях оптической микроскопии на основании принадлежности пиксела к изображению клетки по текстурным признакам. Алгоритм состоит из следующих трех шагов: предобработка; классификация пикселей на основе текстурных характеристик; применение алгоритма mean shift для кластеризации полученных пикселей (непосредственно фаза детектирования нейрона).
Эксперименты показали, что наилучшее качество детектирования достигается при использовании текстурных характеристик, построенных на основе метода GLCM с использованием радиуса окрестности R = 6 со следующими показателями качества: precision = 0.82, recall = 0.92, F1 = 0.86. Сравнение результатов использования алгоритмов kNN, NCB для классификации пикселов показало, что наилучшее качество детектирования нейронов достигается при использовании kNN. На рассматриваемом наборе данных выбор параметра k > 15 не дает существенного повышения качества детектирования. Показано, что использование перевода в оттенки серого по синей компоненте, при окрашивании срезов ткани мозга по Нисслю, позволяет повысить качество детектирования по сравнению с другими алгоритмами перевода. Это связано со способом окраски исходной ткани мозга и особенностями съемки препарата оптическим микроскопом.
По точности детектирования предложенный метод показывает результат того же порядка, что показан в работе [1]: Recall(A) = 86 ± 5%. Однако, главной целью наряду с точностью детектирования была разработка алгоритма, который использует для детектирования только текстурные признаки, что снимает ограничения на распараллеливание вычислений.
В работе [3] 2018 года, посвященной исследованию достижимой точности детектирования современн методами, в т.ч. методами искусственными интеллекта, показано, что для таких задач, как детектирование нейронов на изображениях оптической микроскопии, величина F1 = 0.8–0.9 является хорошим качеством детектирования. При попытке использования смешанных тренировочных баз (снимки оптического, электронного микроскопа, снимки мозга и др. данных гистологии) результаты ухудшаются. При выборочном тестировании предложенного подхода на открытых данных по гистологии портала Broad Bioimage Benchmark Collection (Image Sets) он показал лучший или эквивалентный результат в детектировании числа клеток на изображениях.
Исследованием применения различных уровней квантования серого диапазона в построении GLC-матриц показало, что даже бинарное квантование часто может давать нехудший или лучший результат по сравнению с квантованием на 4 или 8 уровней серого, что отмечалось также в работе [22]. Экономия уровней квантования ведет к значительному выигрышу по необходимым ресурсам памяти.
В качестве развития работы интересно исследовать возможность автоматического выбора уровня квантования, а также возможность использования в качестве многомерного признака непосредственно значений самой матрицы GLCM.
Список литературы
Inglis A., et al. Automated identification of neurons and their locations // Journal of Microscopy. Jun 2008. V. 230. № 3. P. 339–52.
Yao X., Nilanjan R. Cell Detection in Microscopy Images with Deep Convolutional Neural Network and Compressed Sensing. 21 Feb., 2018. arXiv:1708. 03307v3 [cs.CV]
Zohaib M., Shan A., Rahman A. U., Ali H. Image Enhancement by using Histogram Equalization Technique in Matlab // International Journal of Advanced Research in Computer Engineering & Technology (IJARCET). February 2018. V. 7. № 2. P. 150–154. http://ijarcet.org/wp-content/uploads/IJARCET-VOL-7-ISSUE-2-150-154.pdf
Lundin H.F. Characterization and Correction of Analog-todigital Converters // Doctoral Thesis in Sig-nal Processing, Stockholm, Sweden 2005. https://www. cis. rit.edu/class/simg712-90/notes/14-Quantization. pdf
Yang Yu B., Elbuken C., Ren C.L., Huissoon J.P. Image processing and classification algorithm for yeast cell morphology in a microfluidic chip // Journal of Biomedical Optics. 2011. V. 16. № 6. P.066008. https:// doi.org/https://doi.org/10.1117/1.3589100
Bustomi M.A., Faricha A., Ramdhan A. and F. Integrated image processing analysis and naive bayes classifier method for lungs X-ray image classification // ARPN Journal of Engineering and Applied Sciences. January, 2018. V. 13. № 2. P. 718–724. http://www.arpnjournals.org/jeas/research_papers/rp_2018/jeas_0118_6727.pdf
Park B.E., Jang W.S., Yoo S.K. Texture Analysis of Supraspinatus Ultrasound Image for Computer Aided Diagnostic System // Healthcare Informatics Research. 2016. V. 22 № 4. P. 299–304.
Haralick R.M., Shanmugam L., Dinstein I. Textural Features for Image Classification // IEEE Trans. on Systems, Man and Cybernetics. 1973. V. SMC-3. P. 610–621.
Cheng Y. Mean Shift, Mode Seeking, and Clustering // IEEE Trans. Pattern Anal. Machine Intel l. 1995. V. 17. P. 790–799.
Jiao Y., Du P. Performance measures in evaluating machine learning based bioinformatics predictors for classifications // Quantitative Biology. 2016. V. 4. № 4. P. 320–330. https://doi.org/.https://doi.org/10.1007/s40484-016-0081-2
BrainMaps: An Interactive Multiresolution Brain Atlas, http://brainmaps.org.
Broad Bioimage Benchmark Collection. Annotated biological image sets for testing and validation. https://data.broadinstitute.org/bbbc/image_sets.html
OpenCV (Open Source Computer Vision Library), 2018. https://opencv.org/
Akram S.U., Kannala J., Eklund L., Heikkilä J. Cell Segmentation Proposal Network for Microscopy Image Analysis. In: Carneiro G. et al. (eds) Deep Learning and Data Labeling for Medical Applications. LABELS 2016, DLMIA 2016. Lecture Notes in Computer Science, vol 10008. Springer, Cham. https://doi.org/https://doi.org/10.1007/978-3-319-46976-8_3
Li J., Tseng K-K., Hsieh Z.Y., Yang C.W., Huang H.-N. (2014) Staining Pattern Classification of Antinuclear Autoantibodies Based on Block Segmentation in Indirect Immunofluorescence Images. PLoS ONE 9(12): e113132. doi:https://doi.org/10.1371/ journal.pone.0113132
Han J.W., Breckon T.P., Randell D.A. Landini G. The application of support vector machine classification to detect cell nuclei for automated microscopy // Machine Vision and Applications. 2012. V. 23. № 1. P. 15–24. https://doi.org/10.1007/s00138-010-0275-y
Li S., Wu L., Sun Y. Cell Image Segmentation Based on an Improved Watershed Transformation. International Conference on Computational Aspects of Social Networks. 2010. art. no. 5636803. P. 93–96.
He Y. et al. iCut: an Integrative Cut Algorithm Enables Accurate Segmentation of Touching Cells. Scientific. Reports. July 2015. V. 5. P. 12089.
Ojala T., Pietikainen M. Texture Classification, Machine Vision and Media Processing Unit // University of Oulu, Finland, 2008. V. 230. P. 339–52. http:// homepages.inf.ed.ac.uk/rbf/CVonline/LOCAL_COPIES/OJALA1/texclas.htm
MicroImages, 2018. http://www.microimages.com/ documentation/
Bino Sebastian V., Unnikrishnan A., and Balakrishnan K., Shanmugam L., Dinstein I. Grey Level Co-occurrence Matrices: Generalisation and some new features. // Int. J. of Comp. Science, Engineering and Information Technology (IJCSEIT). 2012. V. 2. № 2. P. 151–157.
Rampun A., Strange H., Zwiggelaar R. Texture segmentation using different orientations of GLCM features // Proceedings of the 6th International Conference on Computer Vision / Computer Graphics Collaboration Techniques and Applications – MIRAGE’13. 2013. Article No. 17.
Pathak B., Barooah D. Texture Analysis Based On The Gray-Level Co-Occurrence Matrix Considering Possible Orientations. // Int. J. of Advanced Research in Electrical, Electronics and Instrumentation Engineering (IJAREEIE), Sept. 2013. V. 2. № 9. P. 4206–4212.
Subudhi A., Sahoo S., Biswal P., Sabut S. Segmentation and classification of ischemic stroke using optimized features in brain MRI // Biomedical Engineering: Applications, Basis and Communications, 2018. V. 30. № 3. 1850011 (13 pages).
Macedo S., Melo G., Kelner J. A comparative study of grayscale conversion techniques applied to SIFT descriptors // SBC Journal on Interactive Systems. 2015. V. 6. № 2. P. 3-36. https://seer.ufrgs.br/jis/article/ download/59654/35557
Carpenter A.E. et al. CellProfiler: image analysis software for identifying and quantifying cell phenotypes // Genome Biology. 2006. V. 7. № 10. https://genomebiology.biomedcentral.com/articles/10.1186/gb-2006-7-10-r100
Дополнительные материалы отсутствуют.
Инструменты
Программирование