

Программирование, 2020, № 1, стр. 29-38
Алгоритм кластеризации множества деталей по чертежам
В. Н. Кучуганов a, *, А. В. Кучуганов a, **, Д. Р. Касимов a, ***
a ФГБОУ ВО “Ижевский государственный технический университет им. М.Т. Калашникова”
426069 Ижевск, ул. Студенческая, 7, Россия
* E-mail: kuchuganov@istu.ru
** E-mail: Aleks_KAV@udm.ru
*** E-mail: kasden@mail.ru
Поступила в редакцию 15.01.2019
После доработки 19.05.2019
Принята к публикации 27.05.2019
Аннотация
В статье для задач производственной логистики предлагается алгоритм кластеризации заданного множества деталей по чертежам. С целью ускорения процесса выполняется фаззификация значений каждого параметра и поиск локальных максимумов на N-мерной гистограмме, отличающийся способом выборки соседних векторов, который состоит в пересчете координат из N-мерного пространства в одномерное и обратно и сравнении с координатами соседних векторов. За счет этого алгоритм осуществляет поиск вершин кластеров за один проход и не требует создания множества локальных списков или графов соседства векторов, благодаря чему повышается эффективность алгоритма кластеризации. Приведены результаты эксперимента по автоматическому группированию деталей на основе чертежей.
1. ВВЕДЕНИЕ
Классификаторы деталей достаточно широко применяются в машиностроении с целью унификации конструкций, технологий и технологической оснастки [1]. Но применение их для разработки групповых технологий, обеспечивающих повышение эффективности производства, сдерживается проблемами автоматизации процесса группирования (кластеризации) деталей по их чертежам или 3D геометрическим моделям. Оперативная кластеризация деталей по геометрическим, техническим, технологическим, производственным параметрам могла бы повысить степень унификации технологических процессов, повысить обоснованность и качество нормирования труда, оптимизировать планы производства. Для этого необходимо привлечение методов Image Mining – автоматического извлечения признаков формы и относительного расположения структурных элементов из чертежей, 3D геометрических моделей, технологических эскизов.
На современных предприятиях применяются системы класса PLM (Product Lifecycle Management), решающие задачи накопления и управления всей информацией, возникающей на этапах конструкторского и технологического проектирования, изготовления, сопровождения и т.д. [2]. Благодаря этому практически у каждого чертежа имеется подробный “паспорт”, что позволяет использовать эту информацию и для автоматизации группирования деталей.
Целью данной работы является создание эффективного алгоритма кластеризации машиностроительных деталей по набору параметров, включающего:
– геометрические признаки, которые могут быть извлечены из чертежей деталей с помощью алгоритмов автоматической векторизации чертежей, структурного анализа и распознавания типовых конструктивных элементов (ТКЭ);
– дополнительные технологические параметры, которые могут быть получены из электронного архива чертежей.
Особенностью предлагаемого алгоритма является фаззификация значений каждого параметра, что помимо ускорения процесса кластеризации также дает пользователю отчетливую обратную связь в качественных терминах.
Статья организована следующим образом. В разделе 2 анализируются существующие методы кластеризации объектов, в том числе по параметрам формы. В разделе 3 описывается укрупненный алгоритм кластеризации. В разделе 4 рассматриваются функции пересчета координат из одномерного массива в многомерное пространство и обратно, посредством которых устанавливается соседство (близость) объектов. В разделе 5 описаны эксперименты по автоматическому группированию деталей на основе чертежей. Заключение по работе дается в разделе 6.
2. ОБЗОР МЕТОДОВ КЛАСТЕРИЗАЦИИ
В настоящее время существует множество методов кластерного анализа. С их помощью аналитики получают возможность классифицировать информацию об объектах, т.е. на основе известной информации группировать объекты в целях анализа, лучшего понимания, принятия управленческих решений.
Наиболее популярными можно считать методы, использующие подход на основе k-средних, и гистограммные методы.
Алгоритм кластеризации методом k-средних (k-means) [3] минимизирует среднеквадратичное отклонение векторов признаков с целью получения k-кластеров – компактных множеств объектов, близких по свойствам. Алгоритм является итерационным, т.е. требует значительных ресурсов. Недостатком считается отсутствие возможности определить реально существующее количество кластеров. Чтобы уменьшить объем вычислений обычно сокращают количество итераций, но при этом появляется риск пропустить кластеры, важные для решаемой прикладной задачи.
Гистограммные методы отыскивают все вершины кластеров за один проход, но это требует слишком больших вычислений. Чтобы ускорить процесс, предварительно осуществляют квантование пространства путем огрубления значений параметров. Так, в работе [4] предлагается осуществлять разбиение векторного пространства на множество подпространств и строить многомерную гистограмму полученных векторов, исключая пустые подпространства. Список этих векторов (подпространств) организован по типу алфавитного словаря, т.е. в порядке возрастания значений цифр очередной координаты. Для удобства анализа соседних подпространств строится множество локальных графов векторов и их соседей. Далее применяется гистограммный алгоритм Нарендры [5], не требующий задания числа кластеров или количества итераций. Время классификации линейно зависит от числа различных векторов. С помощью алгоритма осуществлялась сегментация областей на спутниковых снимках по ряду спектральных каналов.
Кластеризация широко применяется для сегментации изображений по цветовым характеристикам пикселей. Так, в статье [6] проблема сегментации изображения решается посредством иерархической последовательности кусочно-постоянных приближений с использованием метода кластеризации Уорда [7], применяющего принципы дисперсионного анализа для оценки расстояний между кластерами. Мерой различия объектов служит евклидово расстояние, которое, к сожалению, невозможно применить к атрибутам, которые по своей сути являются качественными и не могут быть выражены в количественной шкале. А в задаче группирования деталей такого рода атрибуты (например: вид детали, тип заготовки, группа материала и т.п.) имеют существенное значение, и их не следует игнорировать.
Нечеткие классификаторы часто применяют в системах поддержки принятия управленческих решений при анализе больших объемов данных. В работе [8] задачу построения нечетких классификаторов, формулируемую как задачу отбора признаков, генерации базы нечетких правил, оптимизации условий правил, предлагается решать путем отбора классифицирующих признаков на основе бинарного гармонического поиска [9], использования метаэвристических алгоритмов непрерывного гармонического поиска, являющихся дальнейшим развитием эволюционных вычислений, а также путем генерации базы правил по экстремальным значениям признаков. Эффективность предлагаемого подхода проверена на реальных данных из KEEL и KDD Cup хранилищ текстовых сообщений. К сожалению, для построения классификаторов в задачах производственной логистики такой принцип, как правило, не подходит, поскольку производственники – конструкторы, технологи, плановики – обычно сами решают (назначают) критерии группирования, которые они считают важнейшими в той или иной производственной ситуации.
Для кластеризации объектов по параметрам формы обычно используют статистические характеристики, в частности, скелетные и контурные дескрипторы. Так в работе [10] для повышения надежности кластеризации предлагается алгоритм спектральной кластеризации, основанный на спектральном анализе множества пикселей, составляющих изображение. Алгоритм не требует представления формы в виде вектора.
В работе [11] предлагается осуществлять кластеризацию плоских фигур путем формирования графов скелетонов и обнаружения общей структуры фигур на основе результатов сопоставления графов. Используется стандартная агломеративная итерационная схема кластеризации. В каждой итерации графы скелетонов из двух кластеров объединяются в один граф, вычисляется мера сходства в качестве критерия близости кластеров. Эксперименты выполнены на популярных тестах для форм – рисунках людей, животных, рыб и т.п. – проблема весьма актуальная в задачах поиска изображений по контенту (CBIR – Content-Based Image Retrieval).
Коммерчески предлагаемая система CADFind [12, 13] способна выполнять поиск машиностроительных чертежей и 3D моделей по произвольному образцу, задаваемому пользователем, а также производить автоматическое группирование деталей по их чертежам и 3D моделям. Система автоматически идентифицирует потенциальные семейства деталей и позволяет уточнять их в интерактивном режиме. В доступных описаниях принципов работы этой системы указывается, что она индексирует геометрию детали, а также текстовую информацию, связанную с ней, включая материал, техпроцесс. Извлекаемая из чертежа/3D модели информация представляется в виде кода групповой технологии (GT кода) – строки буквенно-цифровых символов. Сопоставление деталей происходит путем нечеткого сравнения соответствующих GT кодов. К сожалению, ни на официальном сайте продукта, ни в публикациях авторов нам не удалось найти более подробной информации о том, какие именно геометрические признаки детали описывает формируемый GT код, каким образом осуществляется автоматическое извлечение этих признаков из чертежей и 3D моделей, в чем заключается нечеткий характер процедуры сравнения GT кодов. Не раскрывается также и применяемый метод кластеризации, на котором базируется процесс автоматического группирования деталей. Остается только сделать вывод о том, что проблема весьма актуальна, а нацеленные на ее решение программные системы – востребованы.
В части контентного поиска машиностроительных чертежей по образцу существуют также другие исследовательские работы (например, [14, 15]). Однако в этих работах не делается акцент на задаче автоматической классификации деталей.
3. УКРУПНЕННЫЙ АЛГОРИТМ КЛАСТЕРИЗАЦИИ
Предлагаемый алгоритм кластеризации относится к категории гистограммных и состоит в следующем:
1. Подготовка исходных данных. Подбор репрезентативной выборки объектов, заполнение массива измерений (таблица 1), где M – количество объектов в обучающей выборке, N – количество параметров.

2. Фаззификация значений атрибутов, описывающих объекты. Предварительная (перед собственно кластеризацией) фаззификация параметров существенно сокращает объем вычислений.
В результате фаззификации для каждого параметра pi, i ∈ {1 … N} с диапазоном значений Di получаем линейно упорядоченное множество качественных значений параметра Fi = {pij}, где j ∈ {1 … h(i)}, h(i) – количество качественных значений параметра pi и (сюръективную) функцию vali: Di → Fi, которая сопоставляет каждому возможному значению параметра pi соответствующее качественное значение. За счет этого диапазон значений каждого параметра pi разбивается на конечное количество качественных значений Dij = {x ∈ Di|vali(x) = pij}.
3. Построение N-мерной гистограммы. Гиперпространство содержит не более чем HN локусов (ячеек, подпространств), где H – максимальное количество различных качественных значений параметра (например, по каждому из параметров может быть получено одно из H = 5 возможных качественных значений). В цикле по массиву измерений сформировать массив локусов (таблица 2), где для каждого локуса указать количество объектов в нем, т.е. объектов, имеющих соответствующие качественные значения всех N параметров. В массиве измерений отметить, к какому локусу относится объект. Номер кластера на данном этапе отсутствует.
Таблица 2.
Массив локусов
| Локус | Координаты (качественные) локуса | № кластера | Вес (количество объектов) | |||
|---|---|---|---|---|---|---|
| 1 | 2 | … | N | |||
| 1 | 1 | W(1) | ||||
| . | . | . | ||||
| . | . | . | ||||
| . | . | . | ||||
| L | K | w(L) | ||||
4. Поиск локальных максимумов в N-мерном пространстве измерений. Для этого с помощью локального анализатора окрестности локуса просканировать пространство и найти такие локусы, в которых по каждому из N направлений выполняется условие:
(1)
$\begin{gathered} \forall l = 1..L(\exists i \in \{ {{i}_{1}},{\text{ }}...,{{i}_{N}}\} (w(F1({{i}_{1}}, \ldots ,h(i)--1, \ldots ,{{i}_{N}})) \\ < w(l) \geqslant w(F1({{i}_{1}}, \ldots ,h(i) + 1, \ldots ,{{i}_{N}})))) \Rightarrow {{L}_{l}} \in \{ C\} , \\ \end{gathered} $F1(i1,…,iN) – функция, вычисляющая положение локуса в одномерном массиве L, где i1, …, iN – координаты локуса в N-мерном пространстве измерений;
h(i) = 0..H – положение локуса вдоль i-той оси координат, i∈ {i1, …, iN};
w(l), w(F1) – вес локуса (количество объектов, по своим значениям попавших в соответствующее подпространство);
{C} – множество локальных максимумов.
Найденные локусы в гиперпространстве параметров служат “вершинами” кластеров – скоплений объектов с близкими характеристиками. Получаем список кластеров
5. Определение границ кластеров. Для этого из вершины кластера ck, имеющего координаты x1, …, xN, выше описанный локальный анализатор запускается рекурсивно. Если вес w(F1(x1, …, h(i) ± 1, … xN)) соседнего по какому-либо i-тому направлению локуса меньше или равен весу локуса, принадлежащего кластеру, то этот соседний локус присоединяется к тому же кластеру:
h(i) = 0..H – положение локуса вдоль i-той оси координат, i ∈ {x1, …, xN};
H – количество возможных значений i-го параметра;
l – индекс локуса в одномерном массиве локусов L;
L(F1(x1, …, h(i) ± 1, … xN)) – локус соседний с анализируемым;
сk – кластер с номером k.
Очевидно, таким же образом процесс кластеризации можно осуществлять в каждом из полученных кластеров – фаззифицировать и кластеризовать, по вышеописаному алгоритму не всю “обучающую” выборку, а уже полученный кластер, что дает возможность более детально анализировать интересующие области пространства измерений и детализировать классификацию объектов.
Функция, определяющая принадлежность нового объекта тому или иному кластеру – это мера относительной близости, вычисляемая как расстояние в N-мерном метрическом пространстве между объектом и каждым из “центров” кластеров.
4. ФУНКЦИИ ПЕРЕСЧЕТА КООРДИНАТ
Пусть N – количество осей пространства параметров, H – количество возможных значений каждого параметра.
Создадим одномерный (линейный) массив L локусов. Количество элементов в массиве будет HN.
Координаты 〈x1, x2, …, xN〉 локуса (ячейки) в N‑мерном пространстве запишем в виде числа в позиционной системе счисления с основанием H. Это число содержит N цифр, а каждая цифра может принимать значения от 0 до H – 1.
Чтобы вычислить значение индекса l элемента в одномерном массиве L, достаточно отобразить координаты локуса в H-ричное число и перевести это число из позиционной системы счисления с основанием H в десятичную систему счисления. И наоборот, если известен номер локуса в одномерном массиве, то для определения его координат в N-мерном пространстве нужно перевести этот номер в H-ричное число. Для выборки ближайших к нему соседних по i‑той оси локусов нужно увеличить или уменьшить на 1 i-тую цифру H-ричного числа и полученные числа перевести в десятичные. Чтобы проверить всех ближайших соседей, то же самое надо сделать по всем другим цифрам H-ричного числа.
Если в одномерном массиве не хранить пустые локусы, то в оставшихся должны быть в качестве ключа записаны их координаты с целью извлечения нужных локусов. Выбор того или другого способа хранения информации зависит от ожидаемого числа пустых ячеек.
С другой стороны, существование пустых локусов может оказаться интересным для какой-то предметной области, например, в социологических исследованиях, где параметры, как правило, качественные.
Перевод H-ричного числа в десятичную систему и обратно (см. например, [16]) осуществляется по формулам:
где Х – значение числа в десятичной системе, B – основание H-ричной системы счисления, R – цифра H-ричного числа, k – позиция цифры в записи числа.Алгоритм поиска центров кластеров выглядит следующим образом:
k := 0;
FOR l = 1..L // Цикл по всем локусам, L = HN
IF p[l] = 0 THEN Continue(l); // Переход к следующему l
FN(l, ZH); // Перевод l → ZH в Н-ричную систему счисления (с основанием Н)
// Сформировать массив (или список) из цифр числа ZH
FOR i = 1..N // Цикл по цифрам числа ZH
// Сформировать число ZL такое, что i-тая цифра ZL меньше на 1,
// чем i-тая цифра в ZH
F1(ZL, ll); // Выдает индекс ll соседнего локуса в одномерном массиве L
IF p[l] < p[ll] THEN Continue(l); // Переход к следующему l
// Сформировать ZR такое, что i-тая цифра ZR больше на 1, чем i-тая цифра в ZH
F1(ZR, lr); // Выдает индекс lr соседнего локуса в одномерном массиве L
IF p[l] ≤ p[lr] THEN Continue(l); // Переход к следующему l
END i
k := k + 1; c[k] := 〈 p[l], l, ZH〉 // Центр k-го кластера
END l
Функции FN, F1 – это несколько команд. Можно не искать границы кластеров. Обычно объект относят к тому центру, до которого ближе.
Сложность алгоритма не превосходит значения функции О:
где N – количество параметров;H – максимальное количество различных качественных значений параметра.
В практических задачах это зачастую оказывается меньше, чем линейная зависимость от числа анализируемых объектов, поскольку редко требуется оперировать более чем 5 качественными значениями параметра, и числом анализируемых параметров обычно управляет лицо, принимающее решение, с целью повышения наглядности результатов. А если параметров много, то применяют факторный анализ, заменяя группу свойств одним обобщенным свойством.
5. ЭКСПЕРИМЕНТ
Алгоритм кластеризации, описанный выше, был использован для синтеза классификатора деталей.
В эксперименте анализировались такие параметры деталей как: вид детали (корпусная, плоская, тело вращения); сложность внешнего контура (количество перегибов – смен знака приращения угла наклона); число поверхностей, рассчитываемое на основе выделения минимальных примыкающих контуров; количество простых и ступенчатых отверстий; количество окон, колодцев и карманов; количество пазов, канавок и проточек. Дополнительные параметры классификации: группа материала (сталь, чугун, силумин, пластмасса); заготовка (пруток, плита, литье, прессование, прокат); габариты; твердость; квалитет точности; шероховатость (без обработки, шлифование/точение, полирование, зеркальная). Общее количество анализируемых параметров – 12. Числовые параметры преобразовывались в качественные значения (нет, мало, средне, много).
На рис. 1 показано окно запуска процесса кластеризации деталей. Здесь пользователь, обычно, конструктор-технолог, выбирает анализируемые признаки, с помощью инструмента “Параметры фаззификации” корректирует функции преобразования количественных значений признаков в качественные, указывает множество кластеризуемых деталей и задает ограничения на количество и размер целевых кластеров. Чем больше кластеров он хочет получить, тем точнее будет выполнена кластеризация. Соответственно, придется разрабатывать больше групповых техпроцессов.

Процесс перевода количественных значений признаков в качественные является одним из инструментов управления точностью и производительностью процесса кластеризации. На рис. 2 показано окно программы, содержащее средства анализа отдельного признака. Первое, что видит эксперт в данном окне – гистограмму распределения значения признака в выборке деталей (рис. 2а). По нажатию на какой-либо отсчет гистограммы, на экране отображаются примеры деталей, имеющих соответствующее значение признака. Получив общую характеристику набора данных, эксперт затем определяет:
Рис. 2.
Инструментарий перевода количественных значений признака в качественные: а) исходная гистограмма распределения количественных величин; б) диапазоны качественных значений, предложенные системой (автоматически).
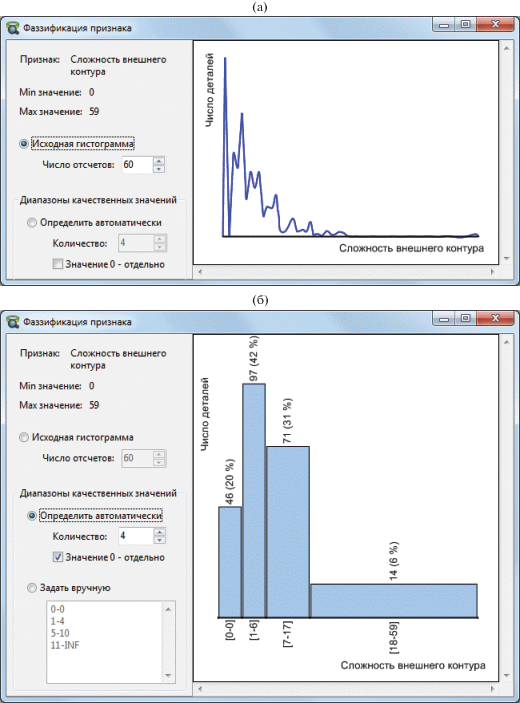
1) число качественных значений признака, которыми целесообразно оперировать в процессе кластеризации;
2) соответствия между качественными и количественными значениями.
Качественное значение представляет определенный диапазон количественных величин. Основная задача, возлагаемая на эксперта, состоит в установлении границ диапазонов. Для упрощения этого процесса, мы предусмотрели возможность автоматического получения рекомендуемых границ диапазонов (рис. 2б). Программа выявляет на исходной гистограмме локальные максимумы (в количестве, равном заданному числу целевых диапазонов). В примере на рис. 2б были получены следующие локальные максимумы (отсчеты): 0, 4, 12, 25. Затем к ним программа относит остальные отсчеты гистограммы по критерию близости. В результате формируется опорная разбивка на диапазоны, которую эксперт может затем подкорректировать в ручном режиме.
На рис. 3 приведен пример результата кластеризации. При визуализации полученных кластеров помимо чертежей деталей отображаются также значения их признаков в качественном представлении. Это помогает инженеру интерпретировать результаты.
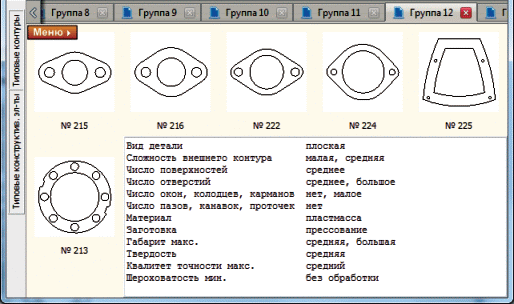
Для экспериментального исследования был подготовлен набор данных, содержащий 98 чертежей корпусных деталей, 82 чертежа плоских деталей и 48 чертежей тел вращения, всего 228 деталей. Чертежи деталей и часть данных о материале и габаритах взяты из открытых онлайн-каталогов (TraceParts, PARTcommunity, Mitutoyo) и архивов студенческих работ. Значения дополнительных технологических параметров, отсутствующие в первоисточнике, задавались вручную экспертом-технологом. При необходимости выполнялась векторизация сканированных чертежей [17]. Извлечение признаков формы и распознавание ТКЭ на чертежах осуществляла разработанная подсистема графического поиска чертежей [18].
Синтаксическое распознавание ТКЭ на чертежах осуществлялось с помощью порождающих грамматик, их описывающих. Ниже показаны примеры функций описания конструктивных элементов деталей: “окно” – сквозная прорезь в стенке, “колодец”, “карман” – углубление, у которого один край совпадает с краем детали:
<Элемент> ::= type, xs, ys, xe, ye, xc, yc, r, α, β,
где type – тип элемента, type ∈ {Line, Arc, Circle};
xs, ys – координаты точки начала элемента;
xe, ye – координаты точки конца элемента;
xc, yc – координаты центра дуги/окружности;
r – радиус дуги/окружности;
α, β – углы векторов от центра к концам дуги.
<Цепочка элементов> ::= e1, e2, …, ek : <Усл1>, <Усл2>,
где <Усл1> ::= ∀i ∈ [1..k] (ei is <Элемент> ∧ ei .type ≠ Circle);
<Усл2> ::= ∀i ∈ [1..k – 1] (Соединяются(ei, ei+1) ∧ ∀j ∈ [i + 2..k] ¬ Пересекаются(ei, ej)).
<Контур> ::= (<Цепочка элементов> : <Усл1>) | (<Элемент> : <Усл2>),
где <Усл1> ::= Соединяются(ek, e1),
<Усл2> ::= type = Circle.
<Узел> ::= e1, e2, e3 : <Усл1>,<Усл2>,
где <Усл1> ::= ∀i ∈ [1..3] ei is <Элемент>;
<Усл2> ::= Соединяются(e1, e2) ∧ Соединяются(e2, e3) ∧ Соединяются(e1, e3).
<2СвязанныхКонтура> ::= С1, C2: <Усл1>, <Усл2>,
где <Усл1> ::= (C1is <Контур>) ∧ (С2is <Контур>);
<Усл2> ::= ПроекционноСвязаны(C1, С2).
<Окно> ::= <2СвязанныхКонтура>: <Усл1>, …, <Усл3>,
где <Усл1> ::= ¬∃U (U is <Узел> ∧ U ∩ C1≠ ∅);
<Усл2> ::= ∀i ∈ [1..k] ei∈ C1 (ПриращениеУглаВектораКасательной(ei, ei+1) ≤ 0);
<Усл3> ::= ∃≥4U (U is <Узел> ∧ U ∩ C2≠ ∅).
<Колодец> ::= <2СвязанныхКонтура>: <Усл1>, …, <Усл3>,
где <Усл1> ::= ¬∃U (U is <Узел> ∧ U ∩ C1≠ ∅);
<Усл2> ::= ∀i ∈ [1..k] ei∈ C1 (ПриращениеУглаВектораКасательной(ei, ei+1) ≤ 0);
<Усл3> ::= ∃=2U (U is <Узел> ∧ U ∩ C2≠ ∅).
<Карман> ::= <2СвязанныхКонтура>: <Усл1>, <Усл2>,
где <Усл1> ::= ∃=2U (U is <Узел> ∧ U ∩ C1≠ ∅);
<Усл2> ::= ∃=2U (U is <Узел> ∧ U ∩ C2≠ ∅).
Описание ТКЭ выполнено с помощью аппарата формальных грамматик и первопорядковой логики предикатов.
На этапе определения локальных максимумов было получено 89 кластерообразующих точек. В результате рекурсивного поиска границ кластеров была получена 51 группа деталей. Общее время работы алгоритма с учетом загрузки информации из базы данных составило 8 секунд на персональном компьютере.
На рис. 4 показана характеристика полученных кластеров. В значимые кластеры (размером от 2 шт.), представляющие пользу для последующей реализации групповой технологии, было отнесено 211 деталей (92.5%).
Рис. 4.
Распределение деталей по кластерам (по горизонтальной оси – размер кластера, по вертикальной оси – число кластеров и общее количество деталей в них).
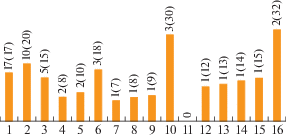
На рис. 5 показаны некоторые из полученных кластеров.
С точки зрения эксперта-технолога, в значимых кластерах неверно классифицированными оказались 13 деталей, и еще 3 детали, попавшие в кластеры-синглтоны, следовало отнести в значимые кластеры. В целом, точность кластеризации составила 0.93.
Некоторые ошибки классификации были обусловлены тем, что не всегда удавалось правильно извлечь признаки геометрической формы из чертежей или используемый набор характеристик был недостаточен. Требуется усовершенствовать методы автоматического анализа чертежей, ввести новые признаки, учитывающие относительное расположение структурных элементов.
Некоторые кластеры (7 шт.) требуют повторной (иерархической) кластеризации – это удобнее для разработки групповых технологий. Чем меньше размер группы деталей, тем проще технологу с ней работать.
6. ЗАКЛЮЧЕНИЕ
Таким образом, предлагаемый алгоритм кластеризации множества деталей по чертежам на основе N-мерной гистограммы отличается от известных способом выборки соседних векторов, который состоит в пересчете координат из N‑мерного пространства в одномерное и обратно и сравнении с координатами соседних векторов. Алгоритм осуществляет поиск вершин кластеров за один проход. Основным достоинством алгоритма является отсутствие необходимости создания множества локальных списков или графов соседних векторов, благодаря чему повышается эффективность алгоритма кластеризации. Также следует отметить, что алгоритм осуществляет кластеризацию деталей в терминах, обычно употребляемых технологами, за счет механизма перевода количественных значений признаков в качественные.
Оперативная (например, в ходе планирования позаказного многономенклатурного производства) кластеризация деталей по геометрическим, техническим, технологическим, производственным параметрам позволяет повысить степень унификации технологических процессов и за счет этого оптимизировать план производства.
Список литературы
Halevi G. Expectations and Disappointments of Industrial Innovations. Lecture Notes in Management and Industrial Engineering. Springer, 2017. 131 p.
Barladian B.Kh., Voloboy A.G., Galaktionov V.A., Shapiro L.Z. Integration of Realistic Computer Graphics into Computer-Aided Design and Product Lifecycle Management Systems // Programming and Computer Software. 2018. V. 44. Is. 4. P. 225–232.
MacQueen J. Some methods for classification and analysis of multivariate observations // In Proc. 5th Berkeley Symp. on Math. Statistics and Probability. 1967. P. 281–297.
Sidorova V.S. Histogram Hierarchical Algorithm and the Reduction of the Dimensionality of the Spectral Features Space // Zh. Sib. Fed. Univ., Ser. Tekhn. Tekhnol. 2017. V. 10. Is. 6. P. 714–722.
Narendra P.M., Goldberg M. A non-parametric clustering scheme for LANDSAT // Pattern Recognition. 1977. V. 9. Is. 4. P. 207–215.
Kharinov M.V. Pixel clustering for color image segmentation // Programming and Computer Software. 2015. V. 41. Is. 5. P. 258–266.
Ward J.H. Hierarchical grouping to optimize an objective function // Journal of the American Statistical Association. 1963. V. 58. Is. 301. P. 236–244.
Hodashinsky I.A., Mekh M.A. Fuzzy classifier design using harmonic search methods // Programming and Computer Software. 2017. V. 43. Is. 1. P. 37–46.
Wang L., Yang R., Xu Y., Niu Q., Pardalos P.M., Fei M. An improved adaptive binary harmony search algorithm // Information Sciences. 2013. V. 232. P. 58–87.
Bai S., Liu Z., Bai X. Co-spectral for robust shape clustering // Pattern Recognition Letters. 2016. V. 83. P. 3. P. 388–394.
Shen W., Wang Y., Bai X., Wang H., Latecki L.J. Shape clustering: Common structure discovery // Pattern Recognition. 2013. V. 46. Is. 2. P. 539–550.
Barton J., Love D. Retrieving designs from a sketch using an automated GT coding and classification system // Production Planning & Control. 2005. V. 16. Is. 8. P. 763–773.
CADFind. URL: http://www.cadfind3d.com/
Liu R., Wang Y., Baba T., Masumoto D. Shape detection from line drawings with local neighborhood structure // Pattern Recognition. 2010. V. 43. Is. 5. P. 1907–1916.
Fonseca M.J., Ferreira A., Jorge J.A. Sketch-Based Retrieval of Vector Drawings // Sketch-based Interfaces and Modeling. 2011. V. 12. P. 181–204.
Knuth D. The Art of Computer Programming. Volume 2: Seminumerical Algorithms. 3-rd Ed. Massachusetts: Addison–Wesley, 1997. 762 p.
Kasimov D.R., Kuchuganov A.V., Kuchuganov V.N. Vectorization of Raster Mechanical Drawings on the Base of Ternary Segmentation and Soft Computing // Programming and Computer Software. 2017. V. 43. Is. 6. P. 337–344.
Kasimov D.R., Kuchuganov A.V., Kuchuganov V.N. Individual Strategies in the Tasks of Graphical Retrieval of Technical Drawings // Journal of Visual Languages and Computing. 2015. V. 28. P. 134–146.
Дополнительные материалы отсутствуют.
Инструменты
Программирование