

Программирование, 2021, № 6, стр. 3-15
КОНТРОЛЬ И ВОССТАНОВЛЕНИЕ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ ПОСРЕДСТВОМ КРИПТОКОДОВЫХ КОНСТРУКЦИЙ
С. А. Диченко a, *, О. А. Финько a, **
a Краснодарское высшее военное орденов Жукова и Октябрьской Революции
Краснознаменное училище имени генерала армии С. М. Штеменко
350063 Краснодар, ул. Красина, д. 4, Россия
* E-mail: dichenko.sa@yandex.ru
** E-mail: ofinko@yandex.ru
Поступила в редакцию 09.03.2021
После доработки 31.05.2021
Принята к публикации 23.06.2021
Аннотация
Разработан метод контроля и восстановления целостности данных в многомерных системах хранения. Предложенные конструкции контроля и восстановления целостности многомерных массивов данных основаны на агрегировании методов криптографии и помехоустойчивого кодирования. На основе представленных криптокодовых конструкций показана особенность комплексирования существующих методов, заключающаяся в повышении вероятности обеспечения целостности информации в условиях разрушающих воздействий злоумышленника и среды для многомерных систем хранения данных. Получены расчетные данные вероятности обнаружения и исправления возникающих в многомерных массивах данных ошибок, приводящих к нарушению их целостности, посредством разработанного метода.
1. ВВЕДЕНИЕ
Эффективность любой информационной системы (ИС) независимо от условий ее функционирования, в первую очередь, характеризуется степенью достижения целей, поставленных при ее создании [1, 2]. Поэтому при разрушающих воздействиях злоумышленника и среды для ИС, обеспечивающих своевременность и правильность принимаемого пользователем системы решения, необходимым условием достижения требуемого качества их функционирования является обеспечение безопасности обрабатываемой информации.
Безопасность информации определяется состоянием защищенности ИС, а также систем хранения данных (СХД), применяемых в их интересах, от различных угроз и в итоге – способностью ИС обеспечить конкретному пользователю доступность, целостность и конфиденциальность требуемой информации в системе [3].
Для обеспечения целостности информации используются методы из области теоретических положений защиты информации и теории надежности, при которых для обнаружения и исправления ошибок, приводящих к искажению (или уничтожению) информации, требуется введение избыточности. При этом объем вводимой избыточности определяется, к примеру, необходимостью хранения эталонных хэш-кодов, используемых при контроле целостности данных посредством применения хэш-функции, и резервных копий данных для возможности восстановления их целостности на основе технологии резервного копирования.
Вместе с тем, в современных условиях постоянного роста объема и ценности непрерывно накапливаемой в СХД информации, введение требуемой избыточности и, как следствие, увеличение длительности загрузки новых данных в СХД, перерасход используемой памяти и снижение производительности системы в целом, приводит к необходимости разработки новых методов обеспечения целостности информации.
Формируемые в таких условиях требования к качеству функционирования ИС должны быть направлены на достижение цели применения системы за счет повышения уровня безопасности информации без увеличения при этом вводимой избыточности.
2. УГРОЗЫ БЕЗОПАСНОСТИ ИНФОРМАЦИИ И ПОСЛЕДСТВИЯ ИХ РЕАЛИЗАЦИИ
Классификация угроз безопасности информации по признаку “результат реализации”, приводящие к нарушению ее целостности, представлена на рис. 1.
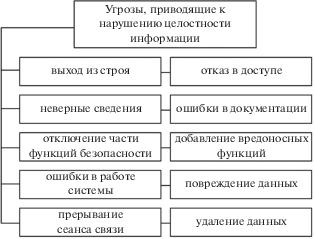
В то же время, целостность данных, хранящихся в СХД, чаще всего нарушается в результате случайных ошибок и преднамеренного несанкционированного изменения данных (например, посредством действия вредоносного кода) или выхода из строя части носителя (например, отдельных ячеек, секторов).
До настоящего времени задачу обеспечения целостности данных в СХД принято было решать путем повышения надежности средств хранения. Для этих целей широкое развитие получили системы резервирования и архивирования данных на дополнительные носители, построение каналов для их тиражирования и т.д.
3. АНАЛИЗ СУЩЕСТВУЮЩИХ МЕТОДОВ ЗАЩИТЫ ЦЕЛОСТНОСТИ ДАННЫХ
Известны методы из области теоретических положений защиты информации, позволяющие осуществить контроль целостности данных за счет вычисления значений контрольных сумм (CRC-кодов) и их сравнения со значениями эталонных [4, 5] (рис. 2).
Рис. 2.
Пояснение принципа контроля целостности данных на основе применения алгоритма вычисления контрольных сумм (CRC-кодов).
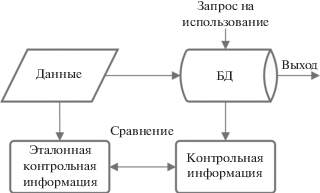
Достоинством данных методов является простота реализации, недостатком – отсутствие обеспечения криптографической стойкости выполняемых при контроле целостности данных преобразований.
Известны решения, основанные на применении криптографических методов: ключевое и бесключевое хэширование, средства электронной подписи [6–9] (рис. 3).
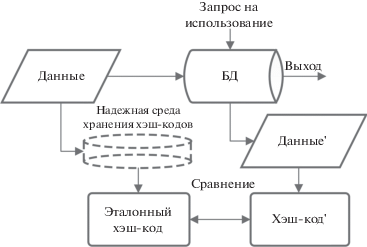
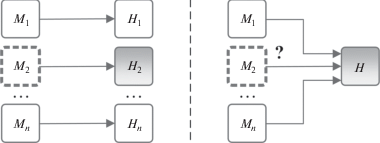
Однако контроль целостности данных, разбитых на блоки небольшой размерности, где от каждого блока данных, подлежащего защите, вычисляется хэш-код, характеризуется вводом высокой избыточности контрольной информации. При попытке устранения данного недостатка за счет вычисления одного хэш-кода от нескольких блоков данных приводит к отсутствию возможности локализации блока данных с признаками нарушения целостности (рис. 4).
Рис. 4.
Пояснение различий по выявлению блока данных ${{M}_{2}}$ при раздельном (схема слева) и общем (схема справа) применении криптографических методов (линией “---” обозначен блок данных с нарушением целостности).
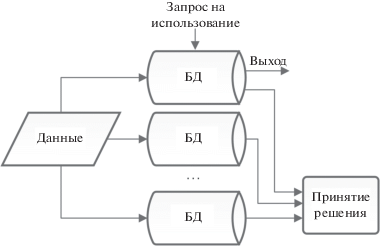
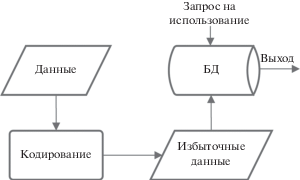
Наиболее популярные из существующих методов теории надежности, позволяющие осуществить контроль и восстановление целостности данных, основаны на применении различных видов резервирования (рис. 5), в том числе, с использованием программно-аппаратной или программной реализации технологии RAID (Redundant Array of Independent Disks) (RAID-массивы) [10] (рис. 6), методы дублирования и избыточного кодирования [11–15] (рис. 7).

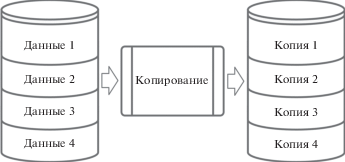
Однако они предназначены для борьбы со случайными ошибками, поэтому в условиях разрушающих воздействий злоумышленника они не всегда являются эффективными. Данное утверждение складывается из того, что современная теория надежности, помимо множества других разделов математики, в основном, базируется на математическом аппарате теории вероятностей. При этом для повышения вероятности обнаружения и исправления возникающих ошибок, приводящих к нарушению целостности данных, требуется увеличение количества вводимой избыточности. К примеру, избыточность, вводимая для восстановления целостности данных посредством применения технологии резервного копирования, равна 100% от общего объема защищаемых данных (рис. 8).
Таким образом, ввод высокой избыточности в существующих методах объясняется потребностью в повышении обнаруживающей и исправляющей способностей при контроле и восстановлении целостности данных в условиях разрушающих воздействий.
4. МЕТОД КОНТРОЛЯ И ВОССТАНОВЛЕНИЯ ЦЕЛОСТНОСТИ МНОГОМЕРНЫХ МАССИВОВ ДАННЫХ
Предложенный метод предназначен для контроля и восстановления целостности данных, представленных в виде упорядоченных многомерных массивов. Он основан на совместном использовании методов криптографической защиты информации (функции хэширования) и теории кодов, контролирующих ошибки (избыточных модулярных полиномиальных кодов (МПК)), агрегирование которых позволяет повысить обнаруживающую и исправляющую способности при контроле и восстановлении целостности данных в условиях разрушающих воздействий без увеличения для этого вводимой избыточности.
Формализованное представление многомерных массивов данных. Блоки данных M, хранящиеся в СХД в виде упорядоченных многомерных массивов, по аналогии с теорией многомерных матриц [16] могут быть представлены p-мерным массивом данных, под которым будем понимать совокупность элементов ${{M}_{{{{\psi }_{1}} \ldots {{\psi }_{p}}}}}$, где индексы ${{\psi }_{1}} \ldots {{\psi }_{p}}$ принимают значения от 1 до ka (a = 1, …, p) соответственно.
При этом p-мерный массив данных содержит ${{k}_{1}} \times {{k}_{2}} \times \ldots \times {{k}_{p}}$ элементов и обозначается как
На примере 3-мерного куба данных (рис. 9), содержащего систему координат с осями: x, y, z, по которым откладываются блоки данных ${{M}_{{ijr}}}$ (i, j, $r = 0, \ldots ,k - 1$), получим 3-мерный массив данных:
который может быть представлен в следующем виде: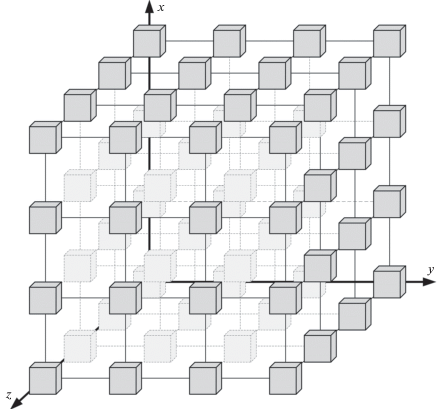
Построение модели контроля целостности многомерных массивов данных. Для осуществления контроля целостности полученного массива данных ${\mathbf{M}}[k,k,k]$ разместим его в массиве большего размера, который с помощью сечений ориентации (z) может быть представлен в следующем виде:
Контроль целостности 3-мерного массива данных ${\mathbf{M}}[k,k,k]$ осуществляется посредством применения к его элементам ${{M}_{{ijr}}}$ хэш-функции [17].
Определение 4.1. Под хэш-функцией h понимается функция, отображающая строку бит $M \in \{ 0,1\} {\kern 1pt} *$ в строку бит $H \in {{\{ 0,1\} }^{q}}$:
где “{⋅}*” – произвольный размер строки бит, “{⋅}q” – фиксированный размер, $q \in N$.Определение 4.2. Строка бит $M \in \{ 0,1\} {\kern 1pt} *$, которую хэш-функция h отображает в строку бит $H \in {{\{ 0,1\} }^{q}}$, называется блоком данных.
Определение 4.3. Под хэш-кодом понимается строка бит $H \in {{\{ 0,1\} }^{q}}$, являющаяся выходным результатом хэш-функции h.
На основе ранее разработанных схем хэширования [18–23] вычислим для блоков данных ${{M}_{{ijr}}}$ ($i,j,r = 0, \ldots ,k - 1$), подлежащих защите, хэш-коды ${{H}_{{ijr}}}$ ($i,j,r = 0, \ldots ,k$).
В соответствии с правилами построения кубических кодов [15] разместим полученные хэш-коды в свободные для записи ячейки массива ${\mathbf{W}}{\kern 1pt} '[k + 1,k + 1,k + 1]$.
Получим массив, представленный с помощью сечений ориентации (z):
Хэш-коды ${{H}_{{ijr}}}$, вычисленные посредством применения к блокам данных ${{M}_{{ijr}}}$ хэш-функции $h({{M}_{{ijr}}})$ (или ${{h}_{k}}({{M}_{{ijr}}})$, k – секретный ключ), будут являться эталонными.
Таким образом, полученный массив, содержащий (k + 1)3 ячеек, будет состоять из:
– ${{k}^{3}}$ блоков данных ${{M}_{{ijr}}}$, подлежащих защите целостности ($i,j,r = 0, \ldots ,k - 1$);
– $3{{k}^{2}}$ блоков с вычисленными эталонными хэш-кодами ${{H}_{{ijr}}}$ ($i,j,r = 0, \ldots ,k$);
– $3k + 1$ оставшихся свободных ячеек.
В соответствии с полученной моделью к каждому блоку данных, подлежащему защите, по трем осям добавляются блоки с вычисленными от них эталонными хэш-кодами, используемыми для обнаружения данных с признаками нарушения целостности.
Определение 4.4. Под нарушением целостности одного блока данных будем понимать возникновение в нем ошибки, соответственно нарушение целостности q блоков данных определяется возникновением q-кратной ошибки.
Обнаружение блока данных с признаками нарушения целостности выполняется путем сравнения значений предварительно вычисленных от него эталонных хэш-кодов и хэш-кодов, вычисленных при запросе на его использование. В случае несоответствия сравниваемых значений хэш-кодов делается вывод о возникновении ошибки и определяется ее синдром.
Определение 4.5. Под синдромом ошибки будем понимать двоичное число, полученное при написании символа “0” для каждой выполненной проверки на соответствие значений вычисленного и эталонного хэш-кода и символа “1” при несоответствии сравниваемых значений.
Порядок контроля целостности многомерных массивов данных. В соответствии с разработанной моделью разместим в 3-мерном кубе (рис. 10) блоки данных, подлежащие защите, и соответствующие им хэш-коды.
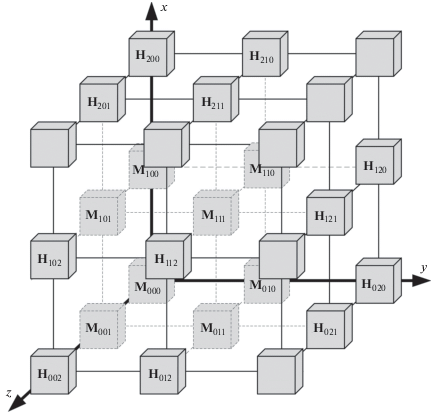
При этом блоки данных ${{{\mathbf{M}}}_{{ijr}}}$, подлежащие защите, и вычисленные от них эталонные хэш-коды ${{{\mathbf{H}}}_{{ijr}}}$ интерпретируются как двоичные векторы:
Получим массив, представленный посредством сечений ориентации (x):
Пример 4.1. Хэш-коды ${{{\mathbf{H}}}_{{002}}}$, ${{{\mathbf{H}}}_{{012}}}$, ${{{\mathbf{H}}}_{{020}}}$, ${{{\mathbf{H}}}_{{021}}}$ вычисляются следующим образом:
Построим сеть хэширования (рис. 11) для однократной ошибки, в которой каждому блоку данных ${{{\mathbf{M}}}_{{ijr}}}$ будет соответствовать неповторяющаяся совокупность из трех хэш-кодов ${{{\mathbf{H}}}_{{ijr}}}$.
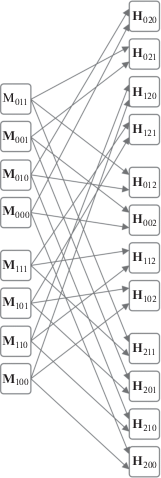
Пример 4.2. Блокам данных ${{{\mathbf{M}}}_{{100}}}$, ${{{\mathbf{M}}}_{{011}}}$ соответствуют следующие неповторяющиеся совокупности из трех хэш-кодов:
− для ${{{\mathbf{M}}}_{{100}}}$: ${{{\mathbf{H}}}_{{120}}},{{{\mathbf{H}}}_{{102}}},{{{\mathbf{H}}}_{{200}}}$;
− для ${{{\mathbf{M}}}_{{011}}}$: ${{{\mathbf{H}}}_{{021}}},{{{\mathbf{H}}}_{{012}}},{{{\mathbf{H}}}_{{211}}}$.
Построим таблицу синдромов ошибок, приводящих к нарушению целостности блока данных ${{{\mathbf{M}}}_{{ijr}}}$, в которой место ошибки определяется наличием символова “1” в соответствующих столбцах и строках.
Пример 4.3. Таблица синдромов ошибок, приводящих к нарушению целостности блоков данных $[{{{\mathbf{M}}}_{{100}}}]$ и $[{{{\mathbf{M}}}_{{011}}}]$, примет вид (табл. 1).
Таблица 1.
Таблица с синдромами ошибок
| Синдромы ошибок | ||||
|---|---|---|---|---|
| Хэш-коды | – | $[{{{\mathbf{M}}}_{{100}}}]$ | … | $[{{{\mathbf{M}}}_{{011}}}]$ |
| ${{{\mathbf{H}}}_{{020}}}$ | 0 | 0 | … | 0 |
| ${{{\mathbf{H}}}_{{021}}}$ | 0 | 0 | … | 1 |
| ${{{\mathbf{H}}}_{{120}}}$ | 0 | 1 | … | 0 |
| ${{{\mathbf{H}}}_{{121}}}$ | 0 | 0 | … | 0 |
| ${{{\mathbf{H}}}_{{012}}}$ | 0 | 0 | … | 1 |
| ${{{\mathbf{H}}}_{{002}}}$ | 0 | 0 | … | 0 |
| ${{{\mathbf{H}}}_{{112}}}$ | 0 | 0 | … | 0 |
| ${{{\mathbf{H}}}_{{102}}}$ | 0 | 1 | … | 0 |
| ${{{\mathbf{H}}}_{{211}}}$ | 0 | 0 | … | 1 |
| ${{{\mathbf{H}}}_{{201}}}$ | 0 | 0 | … | 0 |
| ${{{\mathbf{H}}}_{{210}}}$ | 0 | 0 | … | 0 |
| ${{{\mathbf{H}}}_{{200}}}$ | 0 | 1 | … | 0 |
Сеть хэширования и соответствующая ей таблица синдромов ошибок для обнаружения и локализации q блоков данных с признаками нарушения целостности строятся по аналогичным правилам.
Построение модели восстановления целостности многомерных массивов данных. Блоки данных ${{M}_{{ijr}}}$, подлежащие защите, интерпретируются как элементы GF(2t):
(4.1)
$\begin{gathered} {{\Omega }_{{ijr}}}(\varpi ) = \sum\limits_{g = 0}^{t - 1} \,\mu _{g}^{{(ijr)}}{{\varpi }^{g}} = \mu _{{t - 1}}^{{(ijr)}}{{\varpi }^{{t - 1}}} + \\ \, + \mu _{{t - 2}}^{{(ijr)}}{{\varpi }^{{t - 2}}} + \ldots + \mu _{0}^{{(ijr)}}, \\ \end{gathered} $При этом представленные согласно выражению (4.1) блоки данных и эталонные хэш-коды являются наименьшими полиномиальными вычетами по основаниям ${{p}_{{ijr}}}(\varpi )$ таким, что
(4.2)
$gcd(p_{{{{i}_{1}}jr}}^{{ \mapsto (x)}}(\varpi ),p_{{{{i}_{2}}jr}}^{{ \mapsto (x)}}(\varpi )) = 1,$Полученный массив, представленный посредством сечений ориентации (x):
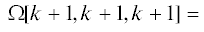
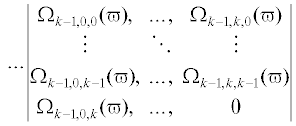
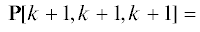
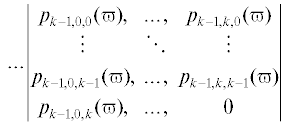
В соответствии с Китайской теоремой об остатках для многочленов, представленных в виде (4.5) и удовлетворяющих условию (4.2), и многочленов, представленных в виде (4.4) таких, что выполняется условие (4.3), система сравнений:
(4.6)
$\left\{ \begin{gathered} \Xi (\varpi ) \equiv {{\Omega }_{{000}}}(\varpi )mod{{p}_{{000}}}(\varpi ), \hfill \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \hfill \\ \Xi (\varpi ) \equiv {{\Omega }_{{0k0}}}(\varpi )mod{{p}_{{0k0}}}(\varpi ), \hfill \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \hfill \\ \Xi (\varpi ) \equiv {{\Omega }_{{00k}}}(\varpi )mod{{p}_{{00k}}}(\varpi ), \hfill \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \hfill \\ \Xi (\varpi ) \equiv {{\Omega }_{{0,k - 1,k}}}(\varpi )mod{{p}_{{0,k - 1,k}}}(\varpi ), \hfill \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \hfill \\ \Xi (\varpi ) \equiv {{\Omega }_{{k00}}}(\varpi )mod{{p}_{{k00}}}(\varpi ), \hfill \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \hfill \\ \Xi (\varpi ) \equiv {{\Omega }_{{k,k - 1,0}}}(\varpi )mod{{p}_{{k,k - 1,0}}}(\varpi ), \hfill \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \hfill \\ \Xi (\varpi ) \equiv {{\Omega }_{{k,0,k - 1}}}(\varpi )mod{{p}_{{k,0,k - 1}}}(\varpi ), \hfill \\ \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \cdots \hfill \\ \Xi (\varpi ) \equiv {{\Omega }_{{k,k - 1,k - 1}}}(\varpi )mod{{p}_{{k,k - 1,k - 1}}}(\varpi ) \hfill \\ \end{gathered} \right.$Выполним операцию расширения МПК путем введения n – k избыточных оснований: ${{p}_{{0,k + 1,0}}}(\varpi )$, ..., ${{p}_{{0,k - 1,n}}}(\varpi )$, ..., ${{p}_{{k - 1,k + 1,0}}}(\varpi ),$ …, ${{p}_{{k - 1,k - 1,n}}}(\varpi )$, ${{p}_{{k + 1,0,0}}}(\varpi )$, ..., ${{p}_{{n,k - 1,k - 1}}}(\varpi )$ и получим соответствующие им избыточные вычеты:
Причем выполняется условие (4.2), а условие (4.3) примет вид $deg{{p}_{{000}}}(\varpi )$, ..., $deg{{p}_{{k,k - 1,k - 1}}}(\varpi )$ < ...< < $deg{{p}_{{n,k - 1,k - 1}}}(\varpi )$.
Получим расширенный МПК в кольце многочленов:
(4.7)
$\begin{gathered} \{ {{\Omega }_{{000}}}(\varpi ), \ldots ,{{\Omega }_{{k,k - 1,k - 1}}}(\varpi ),{{\Omega }_{{0,k + 1,0}}}(\varpi ), \ldots , \\ \ldots ,{{\Omega }_{{n,k - 1,k - 1}}}(\varpi )\} {{\;}_{{{\text{МПК}}}}}. \\ \end{gathered} $В соответствии с правилами построения кубических кодов [15] разместим избыточные блоки данных в свободных для записи ячейках массива.
Таким образом, полученный массив, содержащий n3 ячеек, будет состоять из:
– k3 блоков данных ${{M}_{{ijr}}}$, подлежащих защите целостности;
– $3{{k}^{2}}$ блоков с вычисленными эталонными хэш-кодами ${{H}_{{ijr}}}$;
– $3{{k}^{2}}(n - k)$ избыточных блоков данных.
Данные, подлежащие защите, представленные в виде (4.7), отправляются на хранение.
Порядок восстановления целостности многомерных массивов данных. После осуществления контроля целостности данных в случае обнаружения ошибки выполняется процедура восстановления целостности данных.
В соответствии с правилами декодирования модулярных кодов [25–32] критерием отсутствия обнаруживаемых ошибок в расширенном МПК (4.7) является выполнение неравенства:
где $\Xi {\kern 1pt} '(\varpi )$ является решением системы (4.6) для $\Omega _{{000}}^{'}(\varpi ), \ldots ,\Omega _{{k,k - 1,k - 1}}^{'}(\varpi )$, $\Omega _{{0,k + 1,0}}^{'}(\varpi ), \ldots ,\Omega _{{n,k - 1,k - 1}}^{'}(\varpi )$; ${{P}_{{nnn}}}(\varpi ) = \prod\nolimits_{i,j,r = 0}^n \,{{p}_{{ijr}}}(\varpi )$, символ “$( \cdot ){\kern 1pt} '$” указывает на возможное нарушение целостности данных.Критерий обнаруживаемой ошибки – выполнение неравенства:
Восстановление целостности блока $[{{\Omega }_{{ijr}}}(\varpi )]$ выполняется путем вычисления наименьшего вычета:
где $\Xi (\varpi )$ повторно вычислено с учетом исключения искаженного блока данных $[{{\Omega }_{{ijr}}}(\varpi )]$.Проверка достоверности и полноты данных после восстановления их целостности выполняется путем повторного сравнения значений эталонных хэш-кодов и вычисленных хэш-кодов от блоков данных.
5. ОЦЕНИВАНИЕ РЕЗУЛЬТАТОВ
Оценивание выполним в сравнении с существующим решением, в котором контроль целостности данных осуществляется посредством классического хэширования блоков данных, подлежащих защите, а восстановление целостности посредством кодов, корректирующих ошибки (МПК).
Оценивание результатов при контроле целостности данных. Разработанный метод в сравнении с существующим решением при фиксированном объеме вводимой избыточности позволяет гарантированно обнаружить бóльшее количество блоков данных с признаками нарушения целостности.
Так, например, СХД объемом 432 Кбайт позволяет хранить 675 хэш-кодов (при размере 1-го хэш-кода – 512 бит [33]).
Такое количество хэш-кодов при применении разработанного метода обеспечивает гарантированное обнаружение и локализацию (без учета коллизий) всех блоков данных с признаками нарушения целостности, размещенных в 3-мерном массиве с размером от k = 2 до k = 15.
Зависимости вероятностей ${{P}_{{{\text{обн}}}}}$ обнаружения и локализации блоков данных с признаками нарушения целостности представлены на рисунке 12, где ${{P}_{{{\text{обн}}.1}}}$ – вероятность, при применении разработанного метода, ${{P}_{{{\text{обн}}.2}}}$ – вероятность, при применении существующего решения.
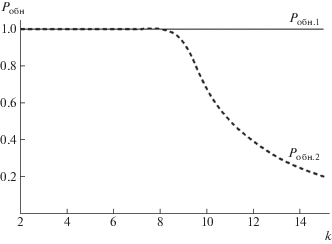
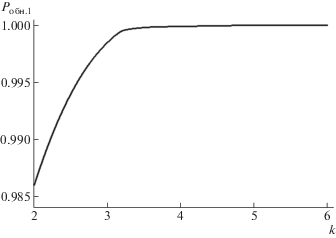
Разработанный метод позволяет повысить вероятность обнаружения и локализации q-кратных ошибок. Его применение (без учета коллизий) позволяет обнаруживать и локализовывать все 1-, 2-, 3-кратные ошибки, а также до ≈98.6% всех 4-кратных ошибок без увеличения для этого количества вычисляемых хэш-кодов.
В частности, при k = 2 в 3-мерном массиве из всех 70 возможных различных сочетаний по четыре блока данных обнаруживаются и локализуются (без учета коллизий) до ≈98.6% всех ошибок, за исключением одной (≈1.4%), возникающей в одном из следующих сочетаний блоков данных:
• первое сочетание: ${{{\mathbf{M}}}_{{001}}}$, ${{{\mathbf{M}}}_{{010}}}$, ${{{\mathbf{M}}}_{{100}}}$, ${{{\mathbf{M}}}_{{111}}}$;
• второе сочетание: ${{{\mathbf{M}}}_{{000}}}$, ${{{\mathbf{M}}}_{{011}}}$, ${{{\mathbf{M}}}_{{101}}}$, ${{{\mathbf{M}}}_{{110}}}$.
Для рассматриваемых сочетаний построим сеть хэширования (рис. 13), на основе которой составим таблицу синдромов ошибок (табл. 2), из которой видно, что для представленных сочетаний блоков данных, подлежащих защите, синдромы ошибок совпадают.
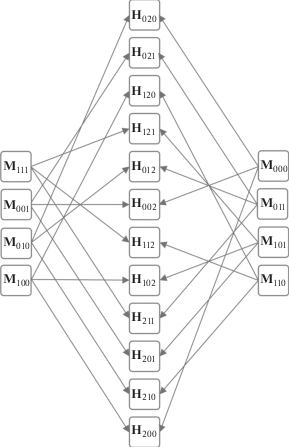
Таблица 2.
Таблица с совпадающими синдромами ошибок для двух сочетаний блоков данных
| Синдромы ошибок | ||
|---|---|---|
| Хэш-коды | 1 сочетание | 2 сочетание |
| ${{{\mathbf{H}}}_{{020}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{021}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{120}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{121}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{012}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{002}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{112}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{102}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{211}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{201}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{210}}}$ | 1 | 1 |
| ${{{\mathbf{H}}}_{{200}}}$ | 1 | 1 |
При k = 3 в 3-мерном массиве существует 17 550 различных сочетаний по четыре блока данных. В этом случае обнаруживаются и локализуются (без учета коллизий) до ≈99.85% всех ошибок, за исключением 27 (≈0.15%), которые не обнаруживаются в результате совпадения синдромов ошибок у 27 различных пар сочетаний блоков данных.
При последующем возрастании размерности k количество всех обнаруживаемых и локализуемых 4-кратных ошибок при применении разработанного метода стремится к 100% (без учета коллизий).
Зависимость вероятности ${{P}_{{{\text{обн}}.1}}}$ обнаружения и локализации 4-кратных ошибок при возрастании размерности k представлена на рис. 14.
Оценивание результатов при восстановлении целостности данных. В разработанном методе, учитывающем структуру многомерного представления данных, в соответствии с полученной моделью избыточные блоки данных располагаются по осям гиперкуба, что в сравнении с классическим применением избыточного МПК позволяет исправлять бóльшее количество возникающих ошибок.
В зависимости от размерности k максимальное количество возможных q блоков данных с нарушением целостности в кубе определяется в соответствии с: q = k3. При этом для восстановления целостности всех искаженных блоков данных в разработанном методе потребуется 3k2 избыточных блоков данных. В то же время, классическое применение избыточного МПК, при котором, как известно [25, 26] исправляется q или менее ошибок, если $n - k \geqslant 2q$, требуется 2k3 избыточных блоков данных.
Зависимости вероятностей ${{P}_{{{\text{исп}}}}}$ исправления возникающих ошибок представлены на рисунке 15, где ${{P}_{{{\text{исп}}.1}}}$ – вероятность, при применении разработанного метода, ${{P}_{{{\text{исп}}.2}}}$ – вероятность, при применении существующего решения.
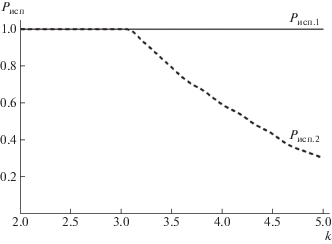
Повышение вероятности исправления возникающих ошибок за счет использования разработанного метода объясняется тем, что $n - k$ избыточных блоков данных используется для восстановления целостности не только $\tfrac{{n - k}}{2}$ искаженных блоков данных, как при классическом применении избыточного МПК, но и других блоков данных, подлежащих защите, в соответствии с введенными связями в 3-мерном кубе при построении модели восстановления целостности многомерных массивов данных.
6. ЗАКЛЮЧЕНИЕ
Представленное решение основано на агрегировании методов криптографической защиты информации (область теоретических положений защиты информации) и теории кодов контролирующих ошибки (область теории надёжности).
Объединение существующих методов контроля и восстановления целостности данных с учетом особенностей многомерной модели представления данных в современных СХД открывает новые возможности для повышения вероятности обнаружения и исправления возникающих ошибок без требуемого для этого увеличения объема вводимой избыточности, что, как следствие, приводит к сокращению времени загрузки новых данных в СХД и повышению эффективности ИС в целом.
Список литературы
Информационная технология. Комплекс стандартов на автоматизированные системы. Автоматизированные системы. Термины и определения. ГОСТ 34.003-90. М.: Стандартинформ, 2009. 48 с.
Петухов Г.Б., Якунин В.И. Методологические основы внешнего проектирования целенаправленных процессов и целеустремленных систем. М.: АСТ, 2006. 504 с.
Федеральный закон “Об информации, информационных технологиях и о защите информации” от 27.07.2006 № 149-ФЗ. 99 с.
Schneier B. Applied Cryptography Second Edition: protocols, algorithms and source code in C. John Wiley & Sons, Inc. 2016. 653 p.
Menezes A.J., Oorschot P., Vanstone S. Handbook of Applied Cryptography. CRC Press, Inc. 2015. 770 p.
Knuth D.E. The Art of Computer Programming: Volume 3: Sorting and Searching. 2nd edn. 2018. 803 p.
Biham E., Dunkelman O. A framework for iterative hash functions. – HAIFA. ePrint Archive, Report 2007/278. 2007. P. 1–20.
Wang X., Yu H. How to break MD5 and Other Hash Function. EUROCRYPT. LNCS 3494. Springer-Verlag. 2005. P. 19–35.
Bellare M. New Proofs for NMAC and HMAC: Security without Collision-Resistance.CRYPTO. ePrint Archive, Report 2006/043. 2006. P. 1–16.
Peter M. Chen, Edward K. Lee, Garth A. Gibson, Randy H. Katz, David A. Patterson. RAID: High-Performance, Reliable Secondary Storage. ACM Computing Surveys, 26, 2014. P. 14–35.
Сапожников В.В. Основы теории надежности и технической диагностики. СПб.: Лань, 2019. 588 с.
Хетагуров Я.А. Повышение надежности цифровых устройств методами избыточного кодирования. М.: Энергия, 2015. 376 с.
Зубарев Ю.М. Основы надежности машин и сложных систем. СПб.: Лань, 2017. 180 с.
Morelos-Zaragoza R.H. The Art of Error Correcting Coding. 2nd edn John Wiley & Sons, Inc. 2006. 263 p.
Hamming R. Coding and Information Theory. Prentice-Hall, 2008. 259 p.
Соколов Н.П. Введение в теорию многомерных матриц. М.: Просвещение, 2012. 175 с.
Tilborg H. Fundamentals of cryptology. A professional reference and interactive tutorial. Kluwer Academic Publishers, 2014. 414 p.
Dichenko S.A., Finko O.A. Two-dimensional control and assurance of data integrity in information systems based on residue number system codes and cryptographic hash functions // Integrating Research Agendas and Devising Joint Challenges International Multidisciplinary Symposium ICT Research in Russian Federation and Europe. 2018. P. 139–146.
Диченко С.А., Финько О.А. Гибридный крипто-кодовый метод контроля и восстановления целостности данных для защищенных информационно-аналитических систем // Вопросы кибербезопасности. 2019. № 6 (34). С. 17–36.
Диченко С.А. Контроль и обеспечение целостности информации в системах хранения данных // Наукоемкие технологии в космических исследованиях Земли. 2019. Т. 11. № 1. С. 49–57.
Диченко С.А., Финько О.А. Обобщенный способ применения хэш-функции для контроля целостности данных // Наукоемкие технологии в космических исследованиях Земли. 2020. Т. 12. № 6. С. 48–59.
Способ многоуровневого контроля и обеспечения целостности данных. Пат. на изобретение RU 2707940. Заявка № 2019103723 от 11.02.2019. Опуб. 02.12.2019. Бюл. № 34. 17 с.
Способ двумерного контроля и обеспечения целостности данных. Пат. на изобретение RU 2696425. Заявка № 2018118919 от 22.05.2018. Опуб. 02.08.2019. Бюл. № 22. 26 с.
Ananda Mohan P.V. Residue Number Systems. Springer International Publishing, 2016. 351 p.
Акушский И.Я., Юдицкий Д.М. Машинная арифметика в остаточных классах. М.: Советское радио, 1968. 604 с.
Бояринов И.М. Помехоустойчивое кодирование числовой информации. М.: Наука, 1983. 386 с.
Szabo N.S., Tanaka R.I. Residue Arithmetic and its Applications Computer Technology. New York: McGraw-Hill, 1967. 476 p.
Амербаев В.М. Теоретические основы машинной арифметики. Алма-Ата: Наука, 1976. 498 с.
Торгашов В.А. Система остаточных классов и надежность ЦВМ. М.: Советское радио, 1973. 329 с.
Mandelbaum D.M. Error correction in residue arithmetic // IEEE Trans. Comput. 1972. № 21. P. 538–545.
Omondi A., Premkumar B. Residue Number Systems: Theory and Implementation. Imperial College Press. London, 2007. 296 p.
Mandelbaum D.M. A method of coding for multiple errors // IEEE Trans. OnInformation Theory. 1968. № 14. P. 518–521.
Информационная технология. Криптографическая защита информации. Функция хэширования. ГОСТ Р 34.11-2012. М.: Стандартинформ, 2013. 30 с.
Дополнительные материалы отсутствуют.
Инструменты
Программирование