

Сенсорные системы, 2020, T. 34, № 4, стр. 329-339
Устойчивая к шуму в разметке сверточная нейронная сеть в задаче сегментации глиом на МРТ изображениях
Т. Н. Сапаров 1, 2, А. И. Курмуков 1, 3, *, Б. Н. Широких 1, 2, 4, С. В. Золотова 5, А. В. Голанов 5, М. Г. Беляев 4, А. В. Далечина 6
1 Институт проблем передачи информации им. А.А. Харкевича РАН
127994 Москва, Большой Каретный пер., д. 19, Россия
2 Московский физико-технический институт (Государственный университет)
141701 Московская обл., г. Долгопрудный, Институтский пер., 9, Россия
3 Национальный исследовательский университет “Высшая школа экономики”
101000 Москва, Мясницкая ул., 20, Россия
4 Сколковский институт науки и технологий
143026 Москва, Большой бул., 30, Россия
5 Федеральное государственное автономное учреждение
“Национальный медицинский исследовательский центр нейрохирургии им. акад. Н.Н. Бурденко” МЗ РФ
125047 Москва, 4-я Тверская-Ямская ул., 16, Россия
6 Центр “Гамма-нож”, АО “Деловой центр нейрохирургии”
125047 Москва, 1-й Тверской-Ямской пер., 13/5, Россия
* E-mail: kurmukovai@gmail.com
Поступила в редакцию 05.06.2020
После доработки 24.07.2020
Принята к публикации 06.08.2020
Аннотация
Сегментация медицинских изображений – одна из важнейших задач лучевой диагностики и терапии. Современные подходы к решению этой задачи основаны на глубоком обучении и показывают высокое качество при обучении на стандартизированных и специально собранных данных. Однако при работе с реальными клиническими изображениями ситуация кардинально меняется из-за принципиально более сложного устройства данных. В задаче сегментации опухолей головного мозга для планирования лучевой терапии размеры и интенсивности изображений существенно варьируются в зависимости от настроек аппарата магнитно-резонансной томографии; отмечается неоднозначность трактовки разными экспертами выявляемых на томограммах изменений; наконец, контуры мишени не всегда соответствуют изображению магнитно-резонансной томографии вследствие использования дополнительных модальностей при планировании облучения. В силу указанных причин сформированные выборки содержат большое количество шумных аннотаций. Мы предлагаем устойчивый алгоритм обучения, основанный на модификации традиционной архитектуры сверточной нейронной сети при помощи модуля для обучения весов, используемых в результирующей функции потерь (взвешенной перекрестной энтропии). Наша модель успешно борется с наличием шума в разметке и значительно уменьшает эффект высокой гетерогенности данных, повышая качество сегментации на 38%.
ВВЕДЕНИЕ
Сегментация медицинских изображений является важнейшим этапом анализа данных медицинской визуализации, позволяющим выделить границы интересующей области (патологического очага или здоровых тканей) на изображении и получить ее количественные характеристики. Эта информация может быть использована как для постановки диагноза, так и для определения точных границ опухоли перед подготовкой к хирургическому или лучевому лечению. Создание контура патологического очага (оконтуривание) является неотъемлемой частью планирования лучевой терапии и оценки результатов лечения. Высокая детальность медицинских изображений делает ручное оконтуривание крайне трудоемкой процедурой, требующей существенных временных затрат.
Задача автоматической сегментации медицинских изображений – одна из перспективных областей применения технологий на основе глубоких сверточных сетей (Hesamian et al., 2019). На сегодняшний день наиболее активно развивающееся направление – это сегментация данных магнитно-резонансной томографии (МРТ). Сверточные нейронные сети (СНС) успешно применяются для сегментации различных органов и тканей на МРТ изображениях: сегментации очагов рассеянного склероза, опухолей головного мозга, определения контуров сердца, печени, межпозвоночных дисков и другое (García-Lorenzo et al., 2013; Dvorak, Menze, 2015; Chen et al., 2020; Zeng et al., 2019; Kim et al., 2018). Представленные в литературе алгоритмы сегментации изображений построены, как правило, на модельных задачах при условии стандартизации протоколов сканирования и данных разметки. Адаптация таких моделей к реальным клиническим данным весьма затруднительна (Wang et al., 2019; Sahiner et al., 2019; Kelly et al., 2019).
Проблема “шума” в разметке при использовании алгоритмов обучения с учителем давно известна в литературе (Frénay, Verleysen, 2013; Algan, Ulusoy, 2020), в частности, в задачах классификации (Karimi et al., 2020) и сегментации медицинских изображений (Tajbakhsh et al., 2020). Последние исследования показывают, что современные глубокие нейронные сети способны запоминать шумную разметку на этапе обучения (Zhang et al., 2017а), что приводит к переобучению, поэтому необходимо разрабатывать алгоритмы, устойчивые к шуму в разметке. К источникам “шума” относятся следующие факторы: недостаток данных, предоставленных эксперту в процессе разметки; субъективность экспертной разметки (Vinod et al., 2016; Growcott et al., 2020) (inter rater reliability); ошибки разметки. Здесь и далее мы употребляем слово “шум” в смысле шума в целевой переменной: разметке целевых областей, например патологических очагов. Изучение наличия шума в самих МРТ изображениях лежит за рамками данной работы.
Для борьбы с шумом в разметке в задачах с использованием глубоких нейронных сетей было разработано множество методов. Для задач классификации изображений авторы работы (Tanaka et al., 2018) предлагают “исправлять” разметку в процессе обучения: нейронная сеть обучается на существующей шумной разметке, затем она уточняется предсказаниями сети, и на новой итерации обучения используются уже уточненные метки. Применительно к сегментации медицинских изображений авторы используют идеи генеративно-состязательных нейронных сетей (generative adversarial network, GAN), предлагая архитектуры, в которых вместо генератора используется сегментационная СНС, а задача дискриминатора заключается в отделении точной (предсказанной) сегментации от неточной (Zhang et al., 2017 б) или экспертной разметки от предсказания сети (Nie et al., 2018).
В ряде работ предлагаются различные способы взвешивания изображений с шумом и без шума в разметке, например, авторы (Mirikharaji et al., 2019) обучали нейросеть попеременно на изображениях с шумом в разметке и без. Изображения с шумом учитываются в результирующей функции потерь с весами таким образом, чтобы изменение параметров нейросети не ухудшало предсказаний на изображениях без шума в разметке. Авторы (Xue et al., 2019) решают задачу классификации меланомы и предлагают отбирать изображения в процессе обучения: на этапе обучения нейросети, после получения предсказаний наблюдения сортируются по убыванию уверенности сети и для обновления весов используют только те примеры, для которых эта уверенность превышает некоторый, заранее заданный, порог. В работе (Zhu et al., 2019) предлагается использовать взвешенную перекрестную энтропию с автоматическим подбором весов для выявления примеров с ошибочной разметкой и снижения их влияния на об-учение.
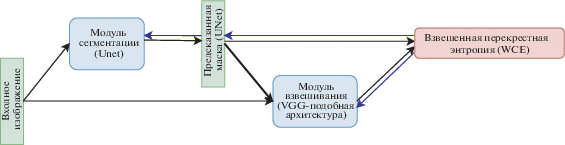
В нашей работе мы развиваем идею адаптивного перевзвешивания объектов для построения устойчивого алгоритма сегментации. Для этого используется дополнительный модуль СНС (рис. 1, Модуль взвешивания), который принимает на вход исходное изображение и предсказанную модулем сегментации СНС (рис. 1. Модуль сегментации) карту вероятностей. Задача модуля взвешивания оценить “вес” изображения, чтобы он убывал с ростом шума в разметке. Затем эти веса комбинируются с выходом модуля сегментации и подаются в функцию потерь. Оба модуля являются компонентами одной СНС и обучаются совместно (для обучения параметров модуля взвешивания не используется никакая дополнительная разметка).
Рис. 1.
Схема предложенной СНС. В экспериментах без взвешивания примеров используется только сегментационная нейросеть (Модуль сегментации). Блоки зеленого цвета – входные и выходные тензоры, блоки синего цвета – нейронные сети, блок красного цвета – функция потерь. Стрелки черного цвета обозначают прямой проход при вычислениях, синего – обратный проход (вычисление градиента). Модулю взвешивания предсказанная маска подается как независимый тензор.
Ключевые отличия нашей работы от работы (Zhu et al., 2019) состоят в следующем.
● Во-первых, в работе (Zhu et al., 2019) для оценки веса используется не карта вероятностей полученных СНС, а экспертная разметка. Это отличие кардинально меняет интерпретацию получаемых весов и повышает риски переобучения.
● Во-вторых, мы предлагаем интерпретируемую регуляризацию обучаемых весов. В зависимости от значения параметра регуляризации метод может действовать в целом диапазоне стратегий обучения, начиная от обычной сегментации без перевзвешивания (равные веса), и заканчивая занулением всех весов, кроме одного.
● В-третьих, вместо простой задачи сегментации легких с синтетическим шумом в целевых контурах мы используем реальные данные с существенно более сложной задачей сегментации опухолей головного мозга на МРТ изображениях.
ОПИСАНИЕ ДАННЫХ
МРТ изображение – трехмерный массив, элементы которого называются вокселями (volume pixel). Эти изображения могут быть получены в различных ортогональных плоскостях: коронарной, сагиттальной, аксиальной. Плоскость, в которой изображение имеет наибольшее разрешение, будем называть главной. Роль аппаратной вариабельности можно оценить на примере рис. 2 и 3. Для получения изображений, представленных на рисунках, использовалась одна импульсная МРТ последовательность T2 FLAIR (Fluid Attenuated Inversion), но разные томографы, что является причиной кардинального отличия в распределении интенсивностей пикселей. Разница в толщине двумерных срезов, расстоянии между срезами, а также разрешении главной проекции приводит к расхождениям в физическом объеме вокселей.
Рис. 2.
Изображения, на которых экспертная разметка не отличается от зоны гиперинтенсивного сигнала в режиме FLAIR. Предсказания алгоритма сегментации (1 – красный контур); экспертная разметка (2 – синий контур).
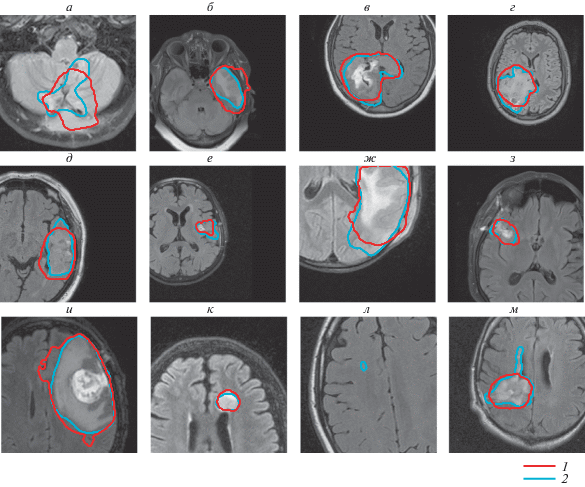
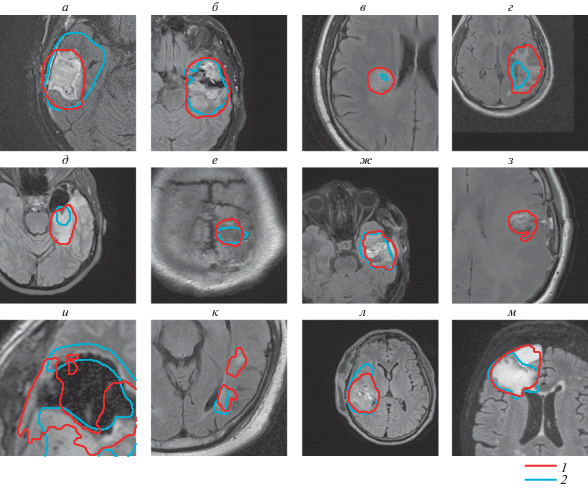
Рис. 3.
Изображения, на которых экспертная разметка отличается от зоны гиперинтенсивного сигнала в режиме FLAIR. Предсказания алгоритма сегментации (1 – красный контур); экспертная разметка (2 – синий контур).
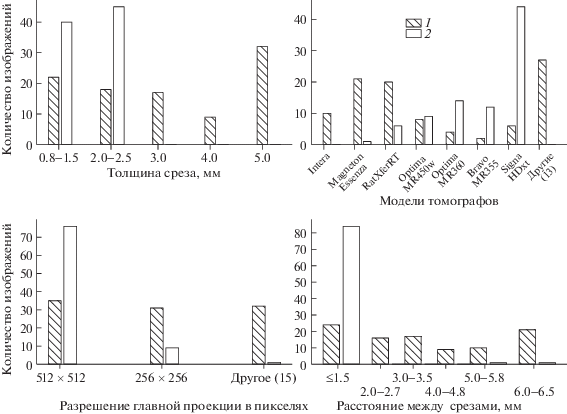
Для создания модели автоматической сегментации были использованы обезличенные трехмерные МРТ изображения пациентов со злокачественной внутримозговой опухолью – глиобластомой. Выборка включала 185 пациентов, которые получали лучевое лечение ложа удаленной опухоли с 2014 по 2019 гг. на медицинских линейных ускорителях Novalis (BrainLab) и Truebeam (Varian) в ФГАУ НМИЦ нейрохирургии им. акад. Н.Н. Бурденко: 98 изображений были представлены аксиальными срезами, 87 – сагиттальными. Толщина срезов от 0.8 до 5 мм, расстояние между срезами от 1 до 6.5 мм (рис. 4). Данные получены более чем с 20 различных моделей томографов.
Рис. 4.
Вариабельность используемых изображений по толщинам двумерных срезов, моделям томографов, разрешению изображения в главной (двумерной) проекции и расстоянию между срезами. 1 – для аксиальной проекции; 2 – для сагиттальной проекции.
Контуры мишеней были созданы в планирующих системах iPlan (BrainLab) и Eclipse (Varian). В разметке участвовали 10 врачей – радиотерапевтов с опытом работы от 5 до 15 лет (медиана 11 лет) в отделении радиохирургии и радиотерапии ФГАУ НМИЦ нейрохирургии им. акад. Н.Н. Бурденко. Во время процедуры планирования контур ложа глиобластомы GTV (gross tumor volume) определялся в большинстве случаев по МРТ в режиме FLAIR (в объем GTV включалась вся зона гиперинтенсивного сигнала в режиме FLAIR) и мог корректироваться с учетом дополнительных последовательностей.
Источники шума в разметке глиобластом
Решение задачи автоматической сегментации ложа удаленной глиобластомы для планирования лучевой терапии осложняется следующими факторами.
● Неоднозначность определения границ опухоли (в особенности после удаления) (Zhao et al., 2016).
● Отсутствие экспертной согласованности при сегментации мишени (Vinod et al., 2016; Growcott et al. 2020; Sandström et al. 2018).
● Экспертная разметка не совпадает с зоной гиперинтенсивного сигнала в режиме FLAIR.
Последняя особенность связана с тем, что контур мишени, определенный по FLAIR, как правило, наиболее объективно отражает распространенность инвазии глиобластомы, однако для уточнения границ опухоли используются несколько МРТ последовательностей (T1, T2, T1 с контрастным усилением) и другие дополнительные модальности (позитронно-эмиссионная томография, ПЭТ). Поэтому в ряде случаев контур мишени может существенно отличаться от зоны гиперинтенсивного сигнала по FLAIR (рис. 3), где на а область менее интенсивного сигнала также включена в основной контур мишени, а на г экспертный контур не захватывает всю область гиперинтенсивного сигнала по FLAIR.
Перечисленные проблемы значительно осложняют как обучение СНС, так и оценку качества работы итогового алгоритма сегментации.
МЕТОДЫ ИССЛЕДОВАНИЯ
Зафиксируем следующие обозначения: Xi – патч (прямоугольная часть изображения) размера M × M,11 подаваемая на вход сети, Yi – соответствующая экспертная разметка (матрица размера M × M, состоящая из нулей и единиц; единица означает, что соответствующий пиксель патча Xi содержит опухоль), ${{\hat {Y}}_{i}}$ – вероятностная карта (также имеет размер M × M), получаемая как выход сегментационной сети для изображения Xi, b – размер батча. Каждый батч состоит из b патчей размера M × M (патчи выбираются случайным образом из объектов тренировочной выборки).
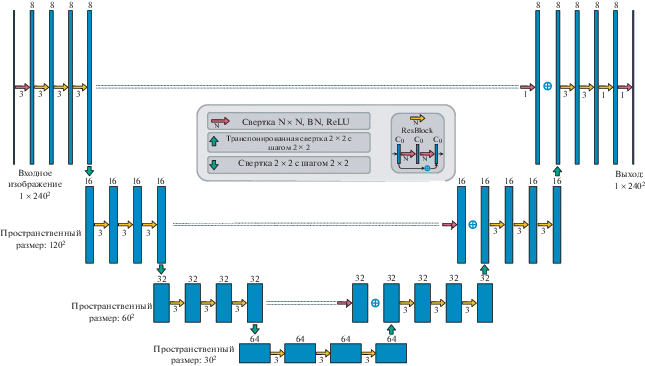
В качестве базовой модели сегментации мы используем UNet (Ronneberger et. al., 2015) (рис. 5). В связи с большой вариабельностью толщин двумерных срезов и расстояниями между срезами мы решили использовать версию Unet с двумерными свертками и учиться на отдельных двумерных срезах, а не на трехмерных изображениях. На вход сети подается батч из частей изображений размера 240 × 240. Батч состоит из 32 таких изображений. В качестве аугментаций были использованы повороты и отражения относительно горизонтальной и вертикальной осей, а также гамма преобразования интенсивностей. Аугментации проводились непосредственно во время обучения.
Рис. 5.
Архитектура модуля сегментации. Синие блоки – тензоры. Число над синим блоком обозначает число каналов.
Ключевой компонент нашего метода – это использование взвешенной функции потерь с адаптивным выбором весов для каждого изображения на каждой итерации обучения. Такой подход позволяет уменьшить вклад в общую функцию потерь тех изображений, разметка которых содержит шум. Мы предлагаем новый метод для оценки весов наблюдений при помощи дополнительного модуля СНС, а также сравниваем его с популярным подходом, в котором вес является некоторой функцией от значения функции ошибки. В обоих случаях нейронная сеть обучается первые 50 эпох без дополнительного взвешивания для предварительной настройки основной сегментационной сети.
Функция потерь
В качестве функции потерь используется взвешенная перекрестная энтропия:
Обучаемые веса
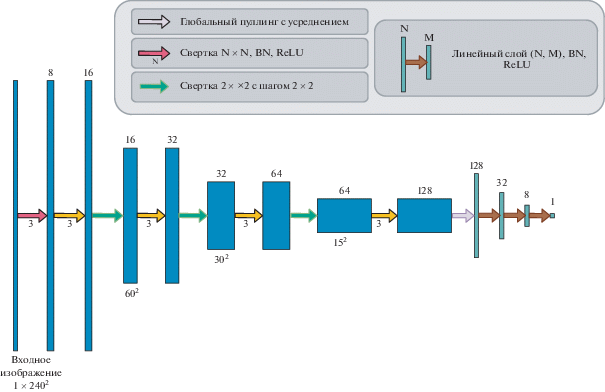
Первый подход заключается в использовании обучаемых весов. Такие веса являются выходами вспомогательного модуля сверточной сети (рис. 6). Этот модуль принимает на вход одновременно Xi и ${{\hat {Y}}_{i}}$, объединенные в двухканальное изображение. Выходом является вещественное число (li), которое преобразуется непосредственно в вес применением функции softmax:
Рис. 6.
Архитектура модуля взвешивания. Синие блоки – тензоры, зеленые блоки – векторы в полносвязной части сети.
Для того чтобы избежать ситуации, когда одно из li является много больше других по значению, вследствие чего распределение на выходе из softmax оказывается вырожденным (а эффективный размер батча становится единицей), в функцию потерь было добавлено регуляризирующее слагаемое:
Параметр α на обучении был равен 0.1. Изменение коэффициента регуляризации α позволяет балансировать между конфигурацией, в которой вес одного изображения оказывается значительно больше веса всех остальных (в результате батч-градиентный спуск вырождается в стохастический градиентный спуск), и конфигурацией, в которой используется одинаковый вес для всех изображений (и взвешенная перекрестная энтропия превращается в обычную). Дополнительный модуль СНС, выходом которого являются веса изображений (wi), используется только на этапе обучения и обучается совместно с модулем сегментации, путем минимизирования функции потерь WCE.
Веса, линейно зависящие от функции потерь
В данном случае предлагается использовать веса, которые будут линейно зависеть от значения функции потерь. Зависимость определяется таким образом, что в батче для изображения с наименьшим значением функции потерь вес будет наибольшим, и наоборот. Веса рассчитываются по следующей формуле:
где BCEmax – это максимальное значение функции потерь в батче, а BCEmin – соответственно, минимальное. После этого каждый из рассчитанных весов делится на сумму всех весов в батче для того, чтобы нормировать их к единице.МЕТРИКА КАЧЕСТВА
Для оценки качества сегментации использовался индекс Дайса × 100:
Пороговое значение, по которому вероятностная карта преобразовывалась в бинарную маску опухоли, выбирается адаптивно (индивидуально на каждом изображении) при помощи алгоритма Отсу (Otsu, 1979). В предварительных экспериментах такой способ подбора порога показал качество не хуже, чем подбор оптимального порога на отложенной выборке (при этом значительно лучше, чем при использовании постоянного порога 0.5).
Кросс-валидация
Обучение проводилось с использованием перекрестного контроля на пяти подвыборках. Экспертная разметка содержит контуры, несогласованные с зоной гиперинтенсивного сигнала на FLAIR, что не позволяет использовать всю выборку для корректного сравнения работы алгоритмов.22 Поэтому для сравнения работы моделей до начала обучения были вручную отобраны 45 снимков в аксиальной (основной) проекции и 57 – в сагиттальной, с разметкой, визуально совпадающей с изменениями по FLAIR. В каждую из подвыборок на кросс-валидации стратифицировано попадали как заранее отобранные снимки, так и оставшиеся снимки с шумом в разметке. Таким образом, для обучения использовались все данные, а для подсчета метрики Дайса на тестовой выборке только данные без шума в экспертной разметке.
РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЯ
Итоговые результаты представлены в табл. 1. Для анализа эффективности модуля автоматического взвешивания было решено сравнить качество сегментации при использовании взвешивания и без него. В качестве базовой модели использовалась архитектура Unet (рис. 5). После 50 эпох обучения (средний индекс Дайса после первых 50 эпох без дополнительного взвешивания – 0.36 для тестовой выборки с аксиальной главной плоскостью и 0.45 – для сагиттальной) оно было независимо продолжено без взвешивания, с применением линейного взвешивания и с применением обучаемых весов (табл. 1). Мы наблюдаем значительный рост качества сегментации в терминах индекса Дайса (0.65 индекс Дайса) для модели, построенной на аксиальных снимках (данные с высокой вариабельностью томографов и размеров изображений) как относительно базовой модели без взвешивания (0.47 индекс Дайса), так и относительно модели со взвешиванием на основе значений функции потерь (0.61 индекс Дайса). Для модели, построенной на сагиттальных снимках, наблюдается незначительный прирост качества сегментации, при этом взвешивание на основе значений функции потерь оказалось даже несколько лучше обучаемых весов (0.74 против 0.71 индекс Дайса). Мы предполагаем, что эффект предложенного взвешивания на сагиттальных снимках оказался ниже, потому что они содержат меньше “шума” в разметке: 57 (~66%) из 87 сагиттальных содержат разметку, совпадающую с областью гиперинтенсивности на FLAIR, тогда как среди аксиальных снимков только 45 (~46%) из 98. Кроме этого, сагиттальные снимки значительно более гомогенны (по сравнению с аксиальными) по таким параметрам, как разрешение, толщина среза и модель томографа (рис. 4). Воздействие этого фактора должно стать предметом дальнейших исследований.
Таблица 1.
Точность сегментации измерена в терминах меры Дайса. Среднее значение (стандартное отклонение)
| Эксперимент | Аксиальная проекция | Сагиттальная проекция |
|---|---|---|
| Базовая модель (без взвешивания) | 47 (23) | 71 (14) |
| Линейные веса | 61 (19) | 74 (13) |
| Обучаемые веса | 65 (17) | 71 (13) |
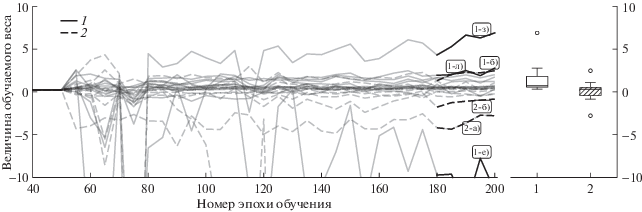
На рис. 7 изображено изменение весов, присваиваемых 24 патчам (рис. 2, а–л и рис. 3, а–л) модулем автоматического взвешивания в процессе обучения (для построения этого графика были сохранены веса нейросети на разных этапах об-учения). Можно видеть, что изображениям, на которых разметка совпадает с областью патологических изменений, в среднем присваиваются большие веса, т.е. они сильнее влияют на параметры нейросе ти.
ОБСУЖДЕНИЕ РЕЗУЛЬТАТОВ
За последние 10 лет в 100 000 медицинских центрах по всему миру приблизительно у 140 млн. человек были диагностированы онкологические заболевания. В зависимости от медицинского учреждения на каждого пациента приходится от 0.1–10 Гб различных данных. Общий объем данных оценивается в 14–1400 петабайт (Lutsberg et al., 2017). Большую часть этого массива составляют данные медицинской визуализации, использующиеся для диагностики, планирования и оценки результатов лечения. Анализ этих данных при помощи глубокого обучения является перспективным методом извлечения необходимой информации для построения систем принятия решений и автоматизации рутинных процессов в онкологии.
Тем не менее разработка подобных алгоритмов на основе ретроспективных данных сопряжена с рядом трудностей. Несмотря на огромный массив гетерогенной информации, накопленной в клинике, при построении моделей приходится использовать ограниченный набор данных (Sahiner et al., 2019). Это связано как с особенностями экспорта из планирующих систем и рентгенологических архивов, так и с особенностями самих данных. В большинстве коммерческих системах планирования, использующихся в отделениях лучевой терапии , не предусмотрена возможность автоматического экспорта планов в формате DICOM RT. Поэтому сбор ретроспективных данных является крайне трудоемким процессом, выполняющимся вручную. Так, например, в представленной работе при решении задачи сегментации глиобластомы экспорт файлов из планирующей системы Eclipse занимал в среднем 5 мин на пациента. Экспорт данных для нескольких сотен пациентов требует существенных временных ресурсов.
Вариабельность разметки является одной из самых серьезных проблем при анализе медицинских изображений. В литературе широко освещена тема отсутствия единого стандарта оконтуривания для многих патологических образований (Vinod et al., 2016; Growcott et al., 2020; Sandström et al., 2018). Особенно актуальна эта проблема для сегментации опухолей после их частичного удаления. Определение оптимального объема облучения опухолей головного мозга остается крайне спорным вопросом, ответ на который зависит от внутренних протоколов исследовательских групп и нейроонкологических клиник. В работе (Zhao et al., 2016) показана высокая субъективность при определении контура глиобластомы даже внутри одного центра. Авторы отмечают, что 61% клиницистов выбирали в качестве объема для облучения ложе удаленной опухоли и область повышенного накопления контраста с краевым захватом, 33% участников исследования включали в объем облучения область отека в дополнении к послеоперационной полости и контрастирующей части опухоли.
Результаты нашей работы также свидетельствуют о сильной вариабельности контуров глиобластомы на послеоперационных изображениях. К примеру, на рис. 3, г представлен аксиальный срез МРТ исследования пациента с глиобластомой, на котором изначальная разметка не соответствует области изменения по FLAIR. При планировании облучения GTV определялся по изображениям T1 с контрастным усилением, к которому в дальнейшем добавлялся краевой захват, включающий область гиперинтенсивного сигнала по FLAIR. При расположении мишени вблизи органов риска врач мог уменьшать краевой захват. Также контур мишени не включает всю зону гиперинтенсивного сигнала по FLAIR, если рядом с опухолью находятся изменения неопухолевого генеза (ишемия, воспаление).
В этом исследовании впервые представлены результаты работы модели сегментации глиобластомы после частичного удаления, построенной на ретроспективных данных без предварительного отбора случаев с согласованной разметкой и устранения вариабельности в протоколах сканирования. Предложенный метод модифицикации традиционной архитектуры сверточной нейронной сети позволяет добиться увеличения метрики Дайс c 47 до 65 на аксиальных изображениях. Стоит отметить, что результаты работ по сегментации, представленные в литературе, демонстрируют более высокие показатели метрик качества (например, на послеоперационных изображениях достигается Дайс более 80) (Bakas et al., 2018). Однако эти результаты получены на выборках данных большего объема, собранных по единому протоколу, в том числе в рамках проведения одноцентровых/мультицентровых исследований (Kickingereder et al., 2019). Существенным ограничением этих работ является сегментация МРТ изображений, полученных на одном томографе или при использовании одинаковых протоколов сканирования, что лимитирует адаптацию разработанных алгоритмов для клинической практики. Предложенная нами нейросетевая архитектура построена на основании МРТ исследований, выполненных на 20 моделях томографов с различными параметрами сканирования. При этом предложенный в данной работе метод позволяет повысить качество сегментации на ретроспективных данных, несмотря на вариабельность МРТ томографов и протоколов сканирования.
ЗАКЛЮЧЕНИЕ
Построение моделей автоматической сегментации МРТ изображений с использованием реальных данных, накопленных в клиниках, связано с тремя проблемами: высокий уровень вариабельности экспертной разметки, несоответствие разметки изображению и большое разнообразие в протоколах сканирования. Каждая из них вносит существенную неопределенность в обучение нейронной сети, препятствуя успешному применению технологий глубокого обучения для ретроспективных данных.
В этой работе мы продемонстрировали, как модификация традиционной архитектуры сверточной нейросети, а именно, добавление модуля обучаемых весов и использование их в результирующей функции потерь, позволяют эффективно бороться с проблемами, вызванными гетерогенностью данных и шумом в разметке.
Исследование было поддержано РФФИ (грант № 18-29-01054).
Список литературы отсутствует.
Дополнительные материалы отсутствуют.
Инструменты
Сенсорные системы