Автоматика и телемеханика, № 8, 2021
Обзоры
© 2021 г. П.А. МУХАЧЁВ (petr.mukhachev@skoltech.ru),
T.Р. САДРЕТДИНОВ (tagir.sadretdinov@skoltech.ru),
Д.А. ПРИТЫКИН, канд. физ.-мат. наук (d.pritykin@skoltech.ru),
А.Б. ИВАНОВ, д-р философии (anton.ivanov2@skoltech.ru)
(Сколковский институт науки и технологий, Москва),
С.В. СОЛОВЬЕВ, канд. техн. наук (sergey.soloviev@scsc.ru)
(Публичное акционерное общество “Ракетно-космическая корпорация “Энергия”,
Королев, Московская обл.)
СОВРЕМЕННЫЕ МЕТОДЫ МАШИННОГО ОБУЧЕНИЯ
ДЛЯ АНАЛИЗА ТЕХНИЧЕСКОГО СОСТОЯНИЯ КОСМИЧЕСКИХ
АППАРАТОВ ПО ДАННЫМ ТЕЛЕМЕТРИЧЕСКОЙ ИНФОРМАЦИИ
Приводится обзор основных достижений в области методов интеллек-
туального анализа данных о техническом состоянии космических аппа-
ратов (КА). Основной акцент делается на анализе телеметрической ин-
формации (ТМИ), позволяющем идентифицировать нехарактерные для
нормальной работы состояния КА и предсказывать возможные сбои в
работе КА или его составных частей. Рассмотрены основные этапы, необ-
ходимые для создания систем мониторинга состояния КА общего назна-
чения, подробно представлены методы обнаружения аномалий в ТМИ с
учетом специфики КА и проанализированы известные авторам публика-
ции по этой тематике. Приведены примеры внедрения таких систем в цен-
трах управления полетами разных стран. Обсуждаются перспективные
направления развития методов анализа технического состояния сложных
систем, которые актуальны для решения задач в космической технике,
а также отмечаются основные факторы, препятствующие развитию ме-
тодов машинного обучения для анализа телеметрической информации.
Ключевые слова: интеллектуальный анализ данных, поиск аномалий,
управление полетом, техническая диагностика, телеметрическая инфор-
мация.
DOI: 10.31857/S0005231021080018
1. Введение
Космические аппараты (КА) и их составные части проектируются с уче-
том большого количества факторов: выполняемой программы полета, внеш-
ней среды, других систем, с которыми предстоит взаимодействие, и возмож-
ных управляющих воздействий. Однако неизбежные погрешности проектиро-
вания, моделирования и верификации не позволяют создать точные модели
каждой из составных частей и КА в целом, и всех его возможных отказов в
реальном космическом полете. Таким образом, во время функционирования
КА могут возникать различного рода непредвиденные ситуации, приводящие
к сбоям в работе составных частей КА, и ситуации, не просчитывавшиеся при
создании КА и планировании программы полета.
Общий подход к обнаружению, локализации и устранению неисправно-
стей (fault detection, isolation and recovery FDIR) призван обеспечить беспе-
ребойное выполнение функций КА [1]. Этот подход предполагает обеспечение
резервирования, применение систем автоматического управления, осуществ-
ляющих диагностику и запускающих процедуры восстановления, а также
3
тщательное изучение выявленных отказов, непредвиденных ситуаций и со-
ответствующую корректировку программы полета.
В работах [2, 3] отмечается, что в настоящее время основными способами
контроля технического состояния КА являются мониторинг пороговых зна-
чений и постоянный контроль ключевых телеметрических параметров (ТМП)
оператором [2, 3]. Однако время специалиста дорого, а в его поле зрения могут
постоянно находиться лишь несколько ТМП. В то же время число ТМП в КА
часто достигает нескольких тысяч, к примеру космический аппарат GOCE
имел 1300 ТМП, а в более крупных КА число ТМП может доходить до 50 ты-
сяч [4], что делает невозможным ручной контроль параметров оператором.
Мониторинг пороговых значений, вообще говоря, не позволяет обнаружить
приближение нештатной ситуации (НШС) или выделить нехарактерное по-
ведение КА. С развитием проектов по развертыванию мега-группировок ав-
томатизация и интеллектуализация процесса мониторинга технического со-
стояния спутников становятся еще более актуальными [5, 6].
Как показывает практика, нехарактерное поведение значений ТМП пред-
ставляет интерес, поскольку часто предшествует сбоям в работе тех или иных
составных частей КА. Такое аномальное поведение обычно не детектирует-
ся стандартными методами мониторинга пороговых значений. Задача поиска
аномалий в телеметрической информации (ТМИ) очень сложна. Как прави-
ло, об аномалиях не хватает исторической информации, а появление анома-
лий не всегда предваряет отказ. Аномалии могут быть вызваны случайными
сбоями в работе датчиков или канала передачи информации, нехарактерными
ситуациями как безвредными, так и потенциально опасными для работы КА;
они не имеют четкой границы, номинальное состояние может эволюциониро-
вать в процессе эксплуатации КА, а понятие аномалии будет отличаться для
разных составных частей. Тем не менее задача обнаружения аномалий в ТМИ
важна для последующей диагностики и анализа функционирования КА.
Для обнаружения аномалий используют два основных подхода. Первый
предполагает наличие модели, которая явным количественным образом опи-
сывает работу системы. В этом случае несоответствие поведения системы и
модели может служить индикатором неисправности. С одной стороны, такой
подход позволяет явным образом моделировать неисправности и их послед-
ствия, с другой стороны, очевидным недостатком является сложность созда-
ния лежащих в его основе моделей. Второй подход заключается в применении
методов машинного обучения, с помощью которых можно создавать модели
работы системы на основе имеющихся данных. В [3, 6] подчеркивается важ-
ность развития таких систем для анализа технического состояния КА [3, 6].
В случае когда база данных обширна, на основе таких моделей могут быть
созданы экспертные системы для диагностики КА. Обзору последних дости-
жений в области применения методов машинного обучения для анализа со-
стояния КА и посвящена настоящая статья.
Автоматизации обнаружения аномалий в данных из различных областей
в последнее время было посвящено множество обзорных публикаций, осве-
щающих как общие, так и более узкие тематики. Среди них можно выделить
Chandola [7], Pimentel [8] и Wang [9], которые группируют методы по основ-
ным предположениям о природе анализируемых данных, дают оценки вычис-
лительной сложности применяемых алгоритмов и перечисляют основные их
4
практические приложения. Chalapathy и соавт. [10] подробнее рассматривают
методы, основанные на применении искусственных нейронных сетей и глубо-
кого обучения. Zimek [11] и Thudumu [12] обсуждают особенности анализа
данных с очень большой размерностью. Gavrilovski [13], Khan и Yairi [14],
Basora [15] сделали обзоры по применениям методов поиска аномалий, в том
числе в авиационной отрасли.
Несмотря на наличие перечисленных выше публикаций, насколько извест-
но авторам настоящей статьи, на данный момент не существует обзора, рас-
крывающего современное состояние методов интеллектуального анализа дан-
ных космической техники. Настоящий обзор заполняет этот пробел, учиты-
вает специфику, связанную именно с космической техникой, и возможные
методы анализа ТМИ, выделяя направления, необходимые для дальнейшего
развития и обозначая наиболее перспективные методы.
Обзор состоит из восьми разделов. В разделе 2 описаны основные исполь-
зуемые определения и постановки задачи с точки зрения анализа данных.
Различные методы выделения признаков для улучшения работы алгоритмов
обсуждаются в разделе 3. Раздел 4 посвящен классификации методов обнару-
жения аномалий и основным примерам их использования. Раздел 5 обсужда-
ет, каким образом принимаются решения об отнесении некоторого состояния
системы к аномальным, если используемые методы анализа данных не клас-
сифицируют состояния, а отображают их на непрерывный интервал числовой
оси. В разделе 6 описаны методы определения качества работы алгоритмов,
основанных на данных. В разделе 7 обсуждаются применения систем, осно-
ванных на данных, в различных центрах управления полетами на постоян-
ной основе, перечислены открытые источники данных, на которых возможно
проверять работу некоторых алгоритмов, а также обсуждаются перспектив-
ные методы анализа данных. Наконец, в разделе 8 кратко сформулированы
основные результаты данной статьи.
2. Основные понятия
2.1. Аномалии и выбросы в телеметрической информации
В литературе термины выброс (outlier) и аномалия часто употребляют-
ся в одном значении, и четкого разграничения не существует, поскольку ис-
следователи из разных областей используют разную терминологию. Тем не
менее, как отметил Pimentel [8], выбросами часто называют малую часть нор-
мальных данных, которые лежат далеко от большинства по-настоящему нор-
мальных данных. Таким образом, поиск выбросов сосредоточен на выделении
именно таких данных, которые могут существенно ухудшать работу некото-
рых алгоритмов.
Некоторые исследователи используют термин “новая информация” (no-
velty) для обозначения данных, которые не соответствуют модели, построен-
ной с использованием данных, априори считающихся нормальными. В этот
класс уже не будут входить случайные выбросы, о которых изложено в преды-
дущем абзаце, если они присутствуют в модели “нормальных” данных.
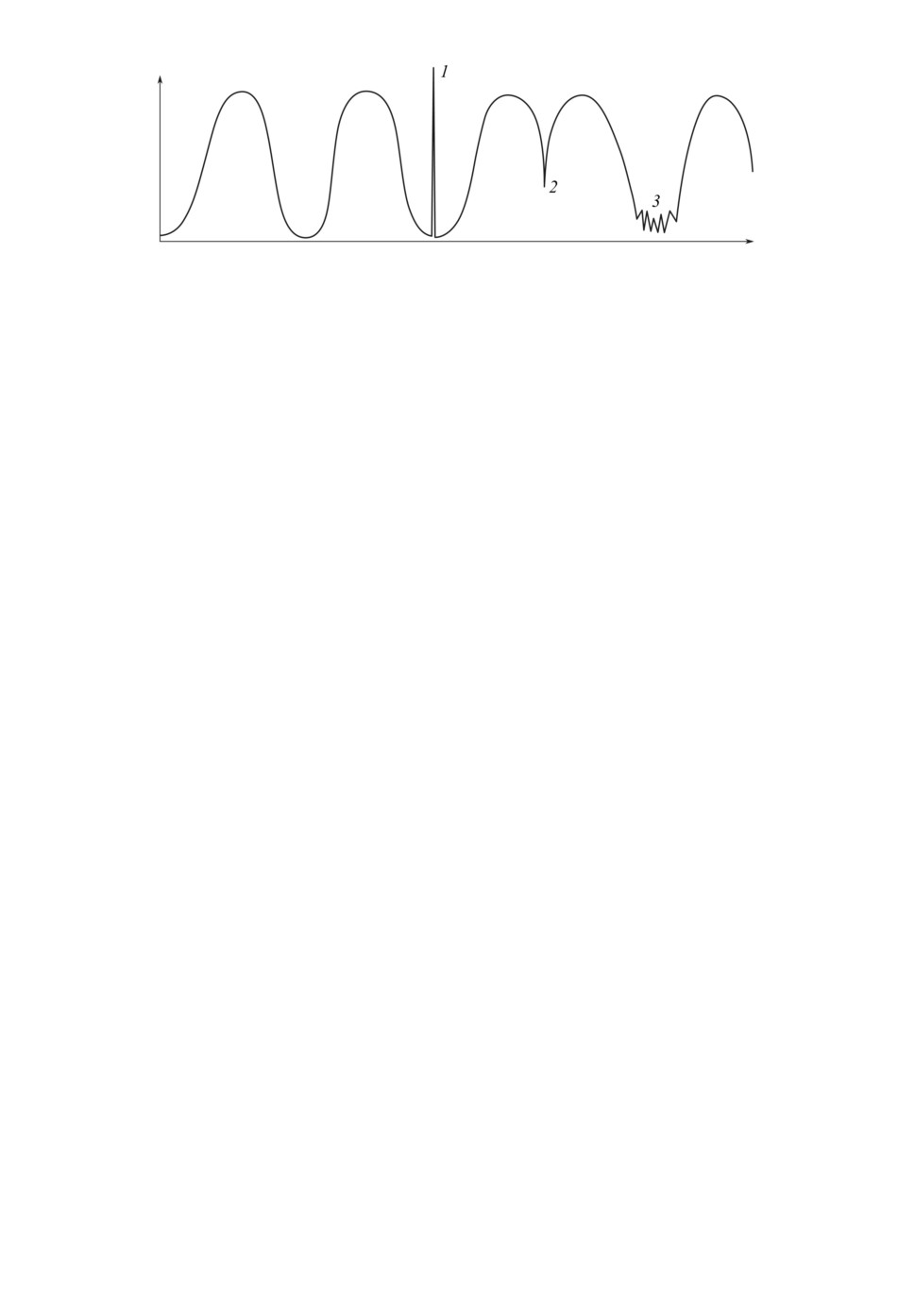
В [7] аномалии подразделяются на точечные, контекстные и коллективные.
Точечные аномалии характеризуются выбросом единственного экземпляра из
своего окружения и являются самыми простыми для обнаружения. Контекст-
ные аномалии представляют собой ситуации, появление которых зависит от
5
Рис. 1. Типы аномалий: 1 — точечная, 2 — контекстная, 3 — коллективная.
некоторого внешнего контекста или других переменных, без учета которых
они не будут считаться аномальными. Коллективные аномалии характерны
для временных рядов или других упорядоченных данных. Они имеют ме-
сто, если несколько ближайших точек образуют аномальное поведение, но не
могут считаться аномальными по отдельности (рис. 1).
Телеметрическая информация (ТМИ) представляет собой показания бор-
товых датчиков КА и программные события, циркулирующие в контуре
управления и передаваемые на землю. Общая структура потоков информа-
ции в контуре управления космическим аппаратом приведена в [16]. Пока-
зания датчиков чаще всего структурируются во временные ряды, которые
могут быть неравномерными (или неэквидистантными), т.е. с переменным
шагом по времени, причем шаг может быть различным для разных телемет-
рических параметров (ТМП). ТМИ является основным источником инфор-
мации о состоянии КА и в этом смысле ТМИ наиболее полна и достоверна.
На основании анализа ТМИ делаются заключения о техническом состоянии
КА и его составных частей и принимаются решения о планировании даль-
нейшего полета. Далее сосредоточимся на анализе ТМИ, представленной в
виде многомерных временных рядов, и опустим рассуждения об анализе про-
граммных событий.
ТМИ принимается и обрабатывается системой мониторинга, реализован-
ной бортовыми и наземными системами. Эта система реализует различ-
ные алгоритмы для извлечения полезной информации о состоянии КА и,
при необходимости, последующего совершения корректирующего воздей-
ствия или оповещения оператора для принятия решения о таком воздействии.
2.2. Возможные постановки
Можно выделить следующие крупные классы алгоритмов для анализа со-
стояния технических систем: основанные на данных и основанные на моде-
лях. Алгоритмы, основанные на моделях, характеризуются тем, что они тре-
буют наличия заранее созданной разработчиком явной схемы и, в отличие от
алгоритмов, основанных на данных, не имеют широкой возможности к адап-
тации на основе исторической информации о работе системы [17]. Алгоритмы,
основанные на данных, в свою очередь требуют достаточно большого корпуса
исторической информации для подбора коэффициентов модели (обучения) и
валидации правильности ее работы.
В общем виде задачу технической диагностики можно поставить следую-
щим образом. Для краткости введем обозначения: Z(t)|t = t0 - состояние си-
стемы в определенный момент времени, Y = y(Z(t)) - некоторый дискретный
6
набор классов оценки качества работы системы либо такая оценка по непре-
рывной шкале, X(t) = f(Z(t)) + ξ - набор видимых наблюдений показаний
различных датчиков. Как правило, функция f известна с некоторой точно-
стью в соответствии со спецификацией рассматриваемого датчика, однако это
не всегда так. Вектор ξ представляет собой набор остаточных ошибок измере-
ния. Общая постановка заключается в восстановлении значения Y по X, т.е.
в нахождении как можно более точной аппроксимации некоторой функции
g : Y = g(X). Функция f не всегда обратима, а ошибки ξ не всегда могут быть
точно описаны, поэтому в общем виде задача не имеет строгого решения.
Далее подробно обсудим методы, основанные на данных. Они имеют боль-
шое практическое значение, поскольку применимы к системам, в которых
формальное описание работы представляет существенные трудности. Поста-
новки задачи машинного обучения в самом общем виде можно сформулиро-
вать так [18]:
— обучение с учителем или контролируемое обучение. Пусть известна
некоторая обучающая выборка D = {(xn, yn), n = 1, . . . , N}. Задача заключа-
ется в восстановлении функции f, такой что предсказание f(x∗) = y∗ будет
точным на новом экземпляре (x∗, y∗) из тестовой выборки. При этом крите-
рий точности определяется заданной функцией ошибок;
— обучение без учителя или неконтролируемое обучение. Пусть дан неко-
торый корпус данных D = {xn, n = 1, . . . , N}. Задача стоит в том, чтобы опи-
сать эти данные некоторым более компактным образом, который определя-
ется некоторой целевой функцией.
Совокупность обучающей и тестовой выборок называют корпусом данных
(dataset). Совокупность векторов yn называют разметкой. Задача обучения с
учителем будет называться классификацией, если область значений yn дис-
кретна, и регрессией, если область значений yn непрерывна.
Поскольку на практике истинное состояние КА часто не поддается непо-
средственному наблюдению, обычно предполагается, что показания датчиков
достаточно точно определяют состояние, и задачи мониторинга технического
состояния сводятся к следующим постановкам:
1) классификация состояний и их последовательностей. В этом случае
Y ∈ N дискретна и имеется некоторое количество наблюдений Y = g(Z(ti));
2) выделение аномалий. В этой постановке Y = {0, 1} и известны наблю-
дения только одного из двух классов Z : g(Z) = 0;
3) поиск выбросов. При этом необходимо оценить значение g(Z) на осно-
вании только наблюдений X при отсутствии наблюдений Y ;
4) ранжирование результатов по важности (степени аномальности), так-
же называемое скоринг. Эта задача характеризуется непрерывной областью
значений Y ∈ R;
5) прогноз состояния КА: нахождение значений ТМП X(t1 + n), оценки
качества работы Y = y(X(t1 + n)) или непосредственно состояния системы
Z(t1 + n) на основании истории значений ТМП {X(t) : t0 ≤ t ≤ t1};
6) оценка остаточного ресурса КА или его частей аналогична предыдущей
постановке, однако в этом случае, как правило, представляет интерес более
долгосрочный прогноз.
7
В задаче поиска выбросов алгоритму дается неразмеченный корпус дан-
ных, среди которых требуется выделить маловероятные состояния или их
последовательности, т.е. эта постановка является задачей обучения без учи-
теля. Однако при поиске аномалий эти методы могут давать большую долю
ложных положительных и ложных отрицательных результатов, поскольку
не каждая аномалия представляет из себя выброс и не каждый выброс мож-
но считать аномалией. В [7, 8] отмечается, что эта постановка в основном
применяется для избавления от случайных редких шумов и выбросов, по-
скольку при этом исходные данные содержат в себе очень мало информации
о правильности функционирования КА.
При поиске аномалий эта постановка может применяться для локализации
найденной аномалии или для предоставления оператору более подробной ин-
формации о штатном функционировании КА. Как правило, в этой постанов-
ке используются методы контролируемого обучения (или, что то же самое,
обучение с учителем). Контролируемое обучение заключается в нахождении
аппроксимации неизвестной функции по набору ее наблюдаемых значений.
Задача классификации в этом случае представляет собой нахождение функ-
ции с дискретной областью значений.
В задаче классификации обучающая выборка X состоит из предваритель-
но размеченных данных: каждое состояние или ситуация Xi принадлежит од-
ному или нескольким из отдельных классов Yi. В процессе работы алгоритм
относит каждую новую ситуацию к тому классу, которому она принадлежит
с наибольшей вероятностью.
При поиске аномалий обучающая выборка, как правило, состоит только из
представителей одного класса — нормальной работы системы. В некоторых
постановках в обучающей выборке может находиться сравнительно малое ко-
личество представителей аномальной работы. При работе алгоритм выделяет
ситуации, которые не похожи на те, что встречались в обучающей выборке.
Кроме того, начинают появляться алгоритмы, способные к активному об-
учению. Эти алгоритмы обучаются в полуконтролируемом режиме, т.е. когда
разметка данных доступна не для всех Xi, и способны запросить у пользо-
вателя разметку, когда это необходимо [19, 20]. Такие алгоритмы подходят
для очень больших баз данных, когда полная ручная разметка при создании
корпуса данных невозможна. Этот класс алгоритмов появился сравнительно
недавно и требует дальнейшего изучения.
2.3. Основные этапы анализа телеметрической информации
Несмотря на последние успехи в создании математического аппарата и
алгоритмов интеллектуального анализа данных, человек все еще должен вы-
брать алгоритм и адаптировать его под стоящую перед ним задачу и ее осо-
бенности. Методология ASUM-DM [21] выделяет шесть основных этапов про-
екта по работе с данными: анализ предметной области, разработка, создание
и настройка рабочей модели, ввод в эксплуатацию, эксплуатация и оптими-
зация, управление проектом.
При создании рабочей модели и настройке ее параметров важно знать
объективное качество ее работы по сравнению с другими моделями и опера-
тором. Для оценки качества требуется эталонная разметка данных, которая
8
Анализ
Выделение и
восстановление
Предварительная
Формирование набора параметров
Постобработка
достоверной
обработка
ТМИ
Отображение
Запись в архив
Обучение
Применение
Рис. 2. Основные этапы анализа ТМИ.
часто отсутствует в реальных задачах. Обычно при отсутствии объективного
критерия качества работы модели или алгоритма, основанного на данных,
обоснование правильности его работы носит спекулятивный характер. Этот
феноменологический принцип верификации в корне отличается от верифика-
ции модельно-ориентированных систем, где правильность работы показыва-
ется верностью изначальных предположений и логических умозаключений.
На этапе эксплуатации системы мониторинга (рис. 2) анализу обычно
предшествуют выделение и, при наличии механизмов, восстановление досто-
верной ТМИ (отсеивание случайных выбросов) и изменение частоты дискре-
тизации, для чего необходимо знание о характеристиках датчика и природе
измеряемой величины. После этого производится анализ с использованием
различных алгоритмов, речь о которых пойдет далее. Анализ также можно
разделить на несколько этапов:
1) формирование набора параметров (признаков), с которыми непосред-
ственно будет работать алгоритм интеллектуального анализа данных;
2) построение или уточнение модели;
3) ее применение для получения результата.
Выделение признаков может происходить как силами экспертов, так и ав-
томатически, однако для автоматического выделения признаков, как прави-
ло, требуется больший объем обучающих данных, а построенную модель
сложнее интерпретировать. В этом случае этап выделения признаков не вы-
ражен явно, так как происходит во время построения и применения алгорит-
мов. Так, например, происходит в случае использования глубоких нейронных
сетей.
Последним этапом производится постобработка результатов анализа для
формирования отчетов и их вывода на экран оператора.
3. Формирование набора параметров для анализа
В контексте задач машинного обучения любые измеримые или вычисли-
мые характеристики объекта исследования, которые каким-либо образом по-
могают в решении задачи, принято называть признаками. Например, при
определении текущего состояния КА признаками могут считаться значения
ТМП, параметры космической погоды и т.п. В сложных задачах бывает важ-
но выделить вспомогательные признаки, которые являются некоторой функ-
цией исходных и помогают улучшить результат и/или уменьшить вычисли-
тельную сложность. При автоматическом выделении признаков, как это про-
исходит при применении глубоких нейронных сетей, признаки могут быть
лишены конкретного физического смысла и являться только математической
функцией исходных данных.
9
Выделение признаков не является самостоятельным способом поиска ано-
малий или определения технического состояния КА, но имеет большое зна-
чение, особенно при анализе многомерных временных рядов в сложных си-
стемах, где встречается большое количество как взаимосвязанных ТМП и
резервированных датчиков, так и ТМП, которые не имеют отношения к вы-
делению тех или иных типов аномалий, вносят шумы и затрудняют их поиск.
Правильное выделение признаков из исходных данных может значительно
облегчить задачу поиска аномалий, улучшить показатели работы алгоритма
и его интерпретируемость. В большинстве случаев выбор ТМП, по которым
будет осуществляться контроль состояния, происходит при помощи эксперта.
Suo и соавт. в [22] ввели понятие нечеткого Байесовского риска для выбо-
ра подмножества переменных для дальнейшей классификации. В [22] пока-
зано, что при использовании функции потерь определенного вида возможно
построить жадный алгоритм для выбора подпространства, в котором отде-
ление классов друг от друга будет оптимальным с точки зрения этой мет-
рики. Вычислительная сложность алгоритма составила O(knm2), где k —
число выбранных ТМП, n — число классов, m — число точек. В [22] были
использованы размеченные результаты численного моделирования системы
энергопитания (СЭП) для демонстрации работы алгоритма и сравнения с
алгоритмами ReliefF [23], mRMR [24], NRS [25] и другими.
Для анализа периодических сигналов, особенно высокочастотных, в ка-
честве представления сигнала часто используют дискретное преобразование
Фурье, вейвлет-преобразования [26]. При анализе многомерных временных
рядов большое значение имеют техники понижения размерности, такие как
метод главных компонент, факторный анализ, а также экспертный выбор
и создание информативных признаков, поскольку они могут значительно
уменьшить вычислительные ресурсы, необходимые для проведения анализа.
Масштабная работа по исследованию качества выделения аномалий в за-
висимости от выбранных признаков на одномерных временных рядах была
проведена Barreyre в [27]. Авторы настоящей статьи исследовали признаки,
выделенные с помощью преобразования Фурье, вейвлет-преобразований, соб-
ственных функций Гауссова ядра, метода главных компонент, периодограмм,
и методы выявления аномалий, основанные на расстоянии и локальной плот-
ности (подраздел 4.1), а также метод опорных векторов (подраздел 4.4). В [27]
использованы искусственно сгенерированные данные, а также реальные дан-
ные для валидации результатов (1700 ТМП, собранных более чем за 12 лет).
В статье приведены практические выводы об используемых методах и при-
знаках.
С другой стороны, O’Meara и Schlag [28] показали, что использование при-
знаков, заданных вручную с учетом физики наблюдаемого процесса, способ-
но значительно улучшить качество предсказаний и поиска аномалий. К тому
же выводу приходит Gowda в [29]: “Выделение признаков является практиче-
ски решающим фактором. Оно имеет большее значение, чем использование
тех или иных моделей машинного обучения” — пишет он. Gowda использо-
вал данные ТМИ Mars Express [30] для построения предсказательной модели
потребления системы обеспечения теплового режима (СОТР).
10
4. Методы анализа телеметрической информации и примеры их применения
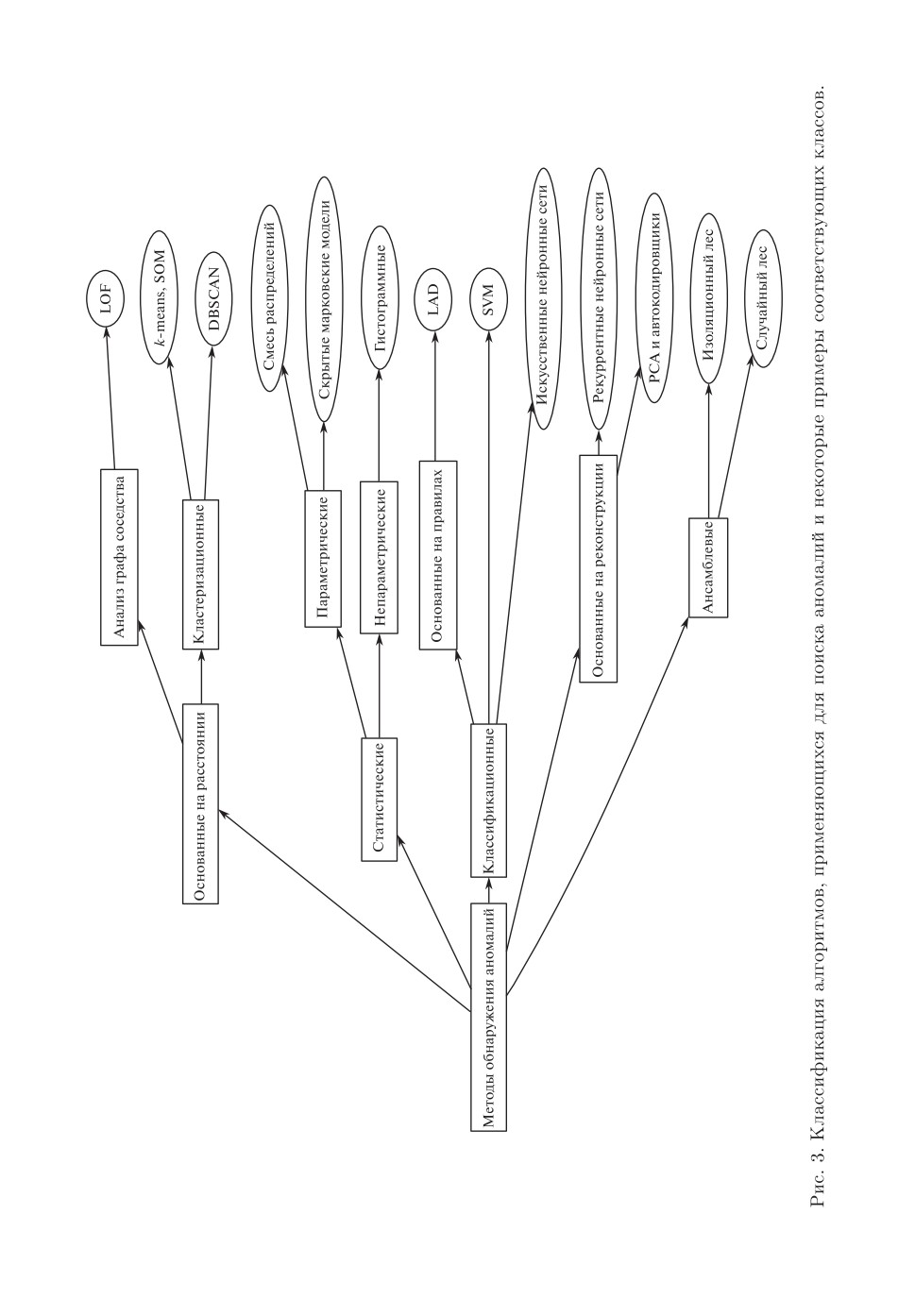
Многие публикации [7, 8, 15] выделяют следующие типы алгоритмов, ко-
торые основаны на базовых предположениях о нормальных и аномальных
данных:
1) основанные на расстоянии:
a) основанные на анализе графа соседства,
б) основанные на кластеризации;
2) статистические:
a) параметрические:
— смесь распределений,
— стохастические процессы;
б) непараметрические;
3) классификационные,
4) основанные на реконструкции,
5) ансамблевые.
На рис. 3 изображены классификация и типичные представители классов
алгоритмов. Отметим, что несмотря на то что представленная классифика-
ция включает многие алгоритмы, она не может считаться полной и учиты-
вающей все аспекты существующих алгоритмов.
Большая часть этих методов специально не приспособлена для анализа
временных рядов, однако может быть адаптирована соответствующим выбо-
ром признаков или применена к отдельным состояниям без использования
последовательной структуры временного ряда.
Кроме того, во многих системах не все ТМП несут полезную информацию
для поиска определенных типов отказов. Например, ТМП одной из составных
частей КА будут нести мало информации о работоспособности другой. По-
этому для уменьшения потенциально затрачиваемых ресурсов и увеличения
точности поиска могут применяться различные техники выбора признаков
(см. раздел 3).
При выборе алгоритма и его параметров необходимо пользоваться объек-
тивными критериями оценки качества алгоритмов, а также сравнивать каче-
ство алгоритмов с качеством работы оператора (см. раздел 6).
Для удобства рассмотренные статьи собраны в Приложении.
4.1. Методы на основе анализа графа соседства
Методы, основанные на ближайших соседях, исходят из гипотезы о том,
что точки, характеризующие нормальные состояния, располагаются близко
друг к другу, в то время как аномальные данные находятся далеко от нор-
мальных в некотором пространстве признаков. Изначально в качестве сте-
пени аномальности использовалось расстояние до К-го ближайшего соседа.
Методы этой группы отличаются друг от друга тем, что они определяют
понятие соседства разными способами.
Bay и Schwabacher в [31] предложили метод ORCA, показав, что в неко-
торых случаях частичным отсеканием поиска можно оптимизировать метод
ближайших соседей до почти линейного масштабирования.
11
К этому классу можно отнести и методы, которые используют локальную
плотность точек. Метод локального уровня выброса (Local Outlier Factor,
LOF) [32] основан на вычислении локальной плотности вокруг точки и вокруг
ее соседей:
⎛
∑
⎞
-1
lrdkNN (o)
lrdkNN (p)
⎜
o∈kNN(p)
⎟
LOFkNN(p) =
⎜
⎟
⎝
⎠
|NkNN (p)|
Значение LOF представляет собой обратную локальную доступную плот-
ность точки по отношению к средней локальной доступной плотности ее со-
седей, где локальная доступная плотность (local reachability density)
|NkNN (p)|
lrdkNN(p) =
∑
RDkNN(p,o)
o∈kNN(p)
обратна среднему расстоянию доступности RDk(p, o) = max(dk(o), d(p, o))
точки по k ее ближайших соседей. Отметим, что NkNN (p) может быть боль-
ше k, если есть несколько точек, равноудаленных от точки p.
Значение LOFkNN (p) можно интерпретировать как изолированность рас-
сматриваемой точки p по сравнению с изолированностью k своих ближайших
соседей. Для этого метода необходимо эмпирически задать число ближай-
ших точек, которые считаются соседями рассматриваемой. Метод LOCI (local
correlation integral) работает похожим образом и частично решает проблему
ручного задания числа соседей, заменяя этот параметр расстоянием, точ-
ки внутри которого считаются соседями. Отношение k-го соседства в общем
случае не является симметричным, поэтому многие методы используют от-
ношения обратного и симметричного соседства для определения выбросов.
Von Brunken в [33] переработал метод LOF, предложив использовать
локальную оценку естественной размерности данных (Intrinsic Dimension)
[34, 35] в качестве оценки плотности. Новый метод был назван IDOS (Intrinsic
Dimension Outlier Score) и показал очень хорошие результаты по сравнению
с другими современными методами: LOF, SOD [36] и FastABOD [37] - на
различных корпусах данных, при этом требуя меньших вычислительных ре-
сурсов.
Некоторые алгоритмы также используют ядерные методы для оценки
плотности [38], как это происходит в статистических методах для оценки
плотности распределения. Например, одна из последних публикаций [39]
предлагает оценивать степень выброшенности точки с использованием ядер-
ной оценки плотности вероятности на основе соседей рассматриваемой точки.
Чаще всего для этих методов выбирают евклидово расстояние в некото-
ром пространстве признаков. Однако существуют и другие варианты выбора
расстояния, например, манхеттенское расстояние, или, что то же самое, мет-
рика L1, или расстояние динамического преобразования временной шкалы
(dynamic time warping, DTW) [40] в случае сравнения временных рядов.
Преимущества методов на основе анализа графа соседства:
— работу этих методов сравнительно просто интерпретировать;
13
— многие алгоритмы работают без учителя и могут быть адаптированы
под полуконтролируемое обучение;
— их просто адаптировать под новые типы данных: для этого достаточно
задать на них метрику;
— некоторые модификации хорошо масштабируются по времени, необхо-
димому на вычисления на пространство большой размерности.
Недостатки методов на основе анализа графа соседства:
— эти алгоритмы опираются на метрику, поэтому может быть сложно
иметь дело с категорийными переменными и сложными типами данных, на-
пример графами;
— они плохо масштабируются на большие объемы данных;
— сложно адаптировать к временным рядам;
— многие методы опираются на расстояние, поэтому их эффективность
снижается на пространстве большой размерности;
— если у аномальных точек много соседей любого типа, получим ложно-по-
ложительный результат.
Главным недостатком этих методов является необходимость составления
графа соседства, которое требует вычисления расстояния между каждыми
двумя точками в выборке, и поэтому большинство алгоритмов этого класса
масштабируются как O(N2). Эта зависимость не позволяет эффективно ими
пользоваться на больших выборках.
Применения методов на основе анализа графа соседства
O’Meara и соавт. в [41] на основе метода IDOS создали систему мониторин-
га ATHMoS (Automated Telemetry Health Monitoring System), которая исполь-
зуется в немецком центре управления полетами (GSOC). Эта система допол-
няет метод IDOS автоматическим подбором порогового значения аномально-
сти точки для заданной базы номинальных значений ТМП. Получившийся
в [41] метод был назван OPVID. Он дает возможность анализировать мно-
го подсистем и большое количество ТМП без значительного вмешательства
оператора в процесс обучения системы. В рассмотренном в [41] примере была
показана способность алгоритма выделять аномалии в исходных данных, а
также сравнили работу OPVID с алгоритмом, предложенным Martinez-Heras
в [42], получив значительно меньшее количество ложных положительных сра-
батываний. Schlag и O’Meara [43] позже провели подробную эмпирическую
проверку качества работы OPVID на различных корпусах данных с исполь-
зованием как вручную созданных признаков, так и полученных с помощью
автоэнкодера, где показали хорошее качество работы OPVID по сравнению с
LOF и LoOP.
4.2. Методы, основанные на кластеризации
Кластеризация в общем виде используется для группировки похожих эле-
ментов. Большая часть алгоритмов кластеризации не предназначена специ-
ально для поиска выбросов или аномалий, однако они могут использовать
структуру имеющихся данных и на ее основе выделить аномалии по опреде-
ленному критерию. В основном эти методы могут обучаться в неконтроли-
руемом или полуконтролируемом режиме. Chandola [7] выделяет три класса
14
алгоритмов поиска аномалий, основанных на кластеризации, исходя из гипо-
тез о том, что представляют собой аномалии в исходных данных:
1) нормальные данные принадлежат какому-либо кластеру, а аномалии
никаким кластерам не принадлежат. В этом случае можно использовать алго-
ритмы кластеризации, которые не требуют принадлежности каждой точки к
кластеру, например DBSCAN, ROCK [44], SNN (shared nearest neighbours) [45]
и их модификации;
2) нормальные данные лежат близко к одному из выделенных центроидов,
в то время как аномальные расположены далеко от них. В этом классе можно
использовать методы, которые вычисляют центроид кластера, такие как ме-
тод k-средних, самоорганизующиеся карты (self-organizing maps, SOM) [46].
Кластеризация методом k-средних является самым популярным алгоритмом
в этом классе;
3) нормальные данные принадлежат крупным плотным кластерам, а ано-
малии образуют маленькие или редкие кластеры. К этому подклассу отно-
сятся такие алгоритмы, как FindCBLOF [47], CD-trees [48].
Алгоритмы DBSCAN, ROCK и SNN основаны на исследовании графа со-
седства. Алгоритм DBSCAN требует установить расстояние соседства и осно-
ван на исследовании непосредственной доступности друг к другу точек полу-
чившегося графа соседства. В этом смысле DBSCAN тесно связан с предыду-
щей группой методов. Алгоритм способен выделять ядро кластера — точки,
которые имеют по меньшей мере n соседей, точки, относящиеся к кластеру,
но не являющиеся ядром, и выбросы.
Алгоритмы ROCK и SNN (Shared Nearest Neighbours) используют понятие
связи, которое представляет собой количество потенциальных общих сосе-
дей между двумя кластерами, или, что то же самое, количество возможных
связей длины два между кластерами в графе соседства. Алгоритм ROCK
разработан для случаев, когда необходимо кластеризовать векторы из кате-
горийных переменных, и может использовать неметрическую функцию сход-
ства, которая основана на таблице сходства. В этом методе для кластеризации
предлагается считать каждую точку отдельным кластером и используют ре-
курсивный механизм их объединения. Таким образом, в отличие от k-средних
ROCK не требует задания числа кластеров. Использование количества общих
соседей для вычисления сходства двух векторов смягчает проблемы, связан-
ные с большой размерностью данных и уменьшающейся плотностью.
Метод k-средних, k-medoids и самоорганизующиеся карты широко извест-
ны. Они используют понятие центроида и группируют элементы на основа-
нии удаленности от него, после чего меняют координаты центроида на центр
масс принадлежащих ему элементов. При применении этих алгоритмов ано-
мальными считают данные, лежащие далеко от обнаруженных центроидов.
Третий подкласс алгоритмов производит кластеризацию одним из суще-
ствующих алгоритмов кластеризации, после чего объявляет некоторые кла-
стеры аномальными на основе таких критериев, как, например, плотность
кластера, количество точек в нем или по некоторой существующей разметке.
Алгоритм FindCBLOF [47] — модифицированный для кластеризации алго-
ритм, основанный на локальной плотности точек.
15
Преимущества методов, основанных на кластеризации:
1) могут обучаться без учителя;
2) могут работать с разными типами данных;
3) хорошо подходят к небольшим сферическим датасетам.
Недостатки методов, основанных на кластеризации:
1) аномалии бинарны, т.е. алгоритмы не присваивают значения аномаль-
ности;
2) многие методы чувствительны к начальному выбору числа кластеров,
однако при анализе временного ряда в реальном времени число кластеров
невозможно узнать заранее;
3) многие методы опираются на расстояние, и потому их эффективность
снижается на пространстве большой размерности;
4) методы, основанные на центроидах, чувствительны к их начальным рас-
положениям, страдают от проклятия размерности в очень больших датасе-
тах, чувствительны к выбросам.
Применения методов, основанных на кластеризации
Iverson в [49] представил алгоритм, который назвал индуктивной систе-
мой мониторинга (inductive monitoring system, IMS). За основу Iverson взял
алгоритм k-средних и предложил механизм увеличения числа выделяемых
кластеров в процессе анализа данных. Для этого используется пороговое зна-
чение удаленности вновь наблюдаемой точки от уже существующих класте-
ров. Алгоритм обучается на данных номинальных режимов работы и пред-
полагается, что точки, лежащие вдали от выделенных центров кластеров,
являются аномальными. Системы, основанные на IMS, использовались для
мониторинга состояния гиродинов и системы обеспечения теплового режима
на международной космической станции [50]. Похожие принципы для постро-
ения системы контроля состояния наноспутника предлагает Singh в [51].
Chen и соавт. в [52] использовали данные наземного эксперимента с измере-
ниями вибраций в подшипниках управляющих двигателей-маховиков (УДМ),
чтобы отличить нормально функционирующие подшипники от подшипни-
ков с проблемами во внешнем кольце или сепараторе. В этом исследовании
в качестве признаков использована корреляционная размерность показаний
акселерометров. Для улучшения результатов они применяют k-medoid кла-
стеризацию последовательно два раза: на данных корреляционной размерно-
сти и на полученных центрах кластеров в результате первой кластеризации.
Результаты были валидированы на экспериментальных данных и показали
хорошую различающую способность алгоритма.
Suo и соавт. в [53], предложили метод сеточной кластеризации на основе
соседства и верифицировали работу метода на данных численного моделиро-
вания системы электропитания (СЭП). Алгоритм использует заранее опре-
деленный шаг сетки для определения соседних точек и использует получен-
ную сеточную плотность для оптимизации квадратичной по количеству точек
сложности классических методов, основанных на расстоянии до соседей.
16
4.3. Статистические методы
Статистические (или вероятностные) методы применяют в том предполо-
жении, что нормальные и аномальные данные имеют статистически разные
плотности распределения вероятностей, по которым их можно различить.
Основным достоинством этих методов является то, что, помимо вероятно-
сти отнесения ситуации к тому или иному классу, они позволяют вычислить
и доверительные интервалы получившихся оценок. Однако в случае задачи
поиска аномалий существует проблема определения пороговой вероятности,
начиная с которой состояние нужно считать аномальным.
Существуют следующие подклассы статистических методов:
Параметрические методы:
1) смесь гауссовых распределений (Gaussian Mixture Model, GMM),
2) фильтры Калмана,
3) скрытые марковские модели,
4) ARIMA (autoregressive integrated moving average);
Непараметрические методы:
1) ядерные оценки плотности,
2) гистограммные.
Параметрические методы делают некоторое предположение о распреде-
лении наблюдаемых величин. Фильтры Калмана предполагают существова-
ние фиксированного набора параметров, образующих оцениваемый вектор
состояния системы, который эволюционируют по известному закону (с точ-
ностью до аддитивно входящей в этот закон нормально распределенной слу-
чайной переменной). Также предполагается заданной модель наблюдения, в
соответствии с которой данные измерений связаны с вектором состояния из-
вестной функцией (опять же с точностью до нормально распределенной слу-
чайной переменной). Различные модификации фильтра Калмана применяют-
ся и для оценки матрицы ковариации ошибки предсказываемых параметров.
В случае если фактическое измерение произошло в области с низкой плотно-
стью вероятности, точка помечается как аномальная.
Скрытые марковские модели работают аналогичным образом в дискрет-
ном пространстве переменных и позволяют задать функции в табличном
виде.
Модель ARIMA аппроксимирует экспериментальные данные зависимо-
стью
(
)
(
)
∑
∑
1-
φiLi
(1 - L)dXt =
1+ θiLi εt,
i=1
i=1
которая имеет короткое обозначение ARIMA(p, d, q), где Xt — временной ряд;
Li — оператор эволюции; εt — независимые случайные переменные, взятые
из N(0, σ); p, d, q — параметры авторегрессионной (AR), интегральной (I) мо-
делей и модели бегущего среднего (MA) соответственно; φi и θi — параметры
модели. Частными случаями этой модели являются:
— ARIMA(0,0,n) — скользящее среднее в окне шириной n,
— ARIMA(0,n,0) означает, что n-я производная временного ряда является
постоянной,
17
— ARIMA(n,0,0) — авторегрессия по n предыдущим состояниям.
Гистограммные методы являются способом оценки функции вероятности
для категорийных или дискретных переменных, которые работают путем
простого подсчета и нормировки. Ядерная оценка плотности вероятности —
естественное обобщение этого метода для оценки непрерывных функций рас-
пределения.
Достоинства статистических методов:
— хорошая математическая обоснованность;
— модель не требует много памяти для хранения.
Недостатки статистических методов:
— возникновение проблем при несоответствии экспериментальных данных
сделанным предположениям о функции распределения;
— малая эффективность при небольшом количестве данных или большой
размерности;
— непараметрические методы не могут эффективно обрабатывать взаимо-
связи между переменными.
Применения статистических методов
Azevedo и соавт. в [54] применяют алгоритмы кластеризации k-средних
и expectation maximization, предполагая, что нормальные данные представ-
ляют собой смесь нормальных распределений. Они показали, что оба алго-
ритма достаточно чувствительны, чтобы обнаружить аномалию, связанную
со слишком большим зарядом аккумуляторной батареи, за шесть часов до
превышения порогового значения.
Rahimi и соавт. в [55] представили подход, основанный на сигма-точечном
фильтре Калмана для определения аномалий в управляющих двигателях-ма-
ховиках (УДМ). Аномальное функционирование системы детектируется при
выходе значений контролируемых ТМП за три среднеквадратичных откло-
нения, вычисленных в окне некоторой наперед заданной ширины. В случае
аномального функционирования в [55] предлагается предлагают адаптиро-
вать алгоритм фильтрации, изменяя соответствующие аномальным значени-
ям контролируемых параметров диагональные элементы матрицы ковариа-
ции ошибок. Демонстрируется работа алгоритма на модели УДМ в случае
разных сценариев нештатной работы (при модельных аномалиях во входном
напряжении УДМ). Показано, что разработанный алгоритм способен детек-
тировать указанные модельные аномалии, при этом оценка контролируемых
параметров УДМ остается удовлетворительной, что позволяет поддерживать
функционирование системы.
Yairi и соавт. в [56] предложили алгоритм, который объединяет вероят-
ностный анализ главных компонент непрерывных переменных и вероятности
дискретных состояний, расширив, таким образом, подход к моделированию
распределения, предложенный Tipping и Bishop в [57]. В результате анализа
получается временной ряд с оценкой аномальности исходных данных. В [56]
используются данные японского спутника JAXA SDS-4, включая его системы
ориентации и стабилизации (СОС), электропитания (СЭП), обеспечения теп-
лового режима (СОТР). В результате анализа можно было отличить друг от
друга разные режимы работы КА, а также выявить аномалию в работе СОС.
18
Также в [56] обсуждаются различные варианты предварительной обработки
исходных данных.
Adnane и соавт. в [58] демонстрируют модификацию обобщенного фильтра
Калмана для улучшения оценки состояния в контуре СОС при различных
сценариях ошибок в измерениях магнитометра. Показано, что предложен-
ный алгоритм способен в реальном времени определять и оценивать ошибки
магнитометра. Алгоритм был протестирован на данных моделирования мик-
роспутника высокой точности.
Ahmed и соавт. в [59] предложили применить метод Каплана—Мейера [60]
после предварительной классификации, основанной на логическом анализе
данных (LAD). В [59] используется датасет от NASA Ames Prognostics для
классификации аккумуляторных батарей по их состоянию на основе емкости
и показали, что этот способ улучшает результат оценки вероятности отказа
по сравнению только с методом Каплана—Мейера.
4.4. Классификационные методы
Классификационные методы исходят из общего предположения о том, что
может быть создан классификатор, который способен надежно отделять нор-
мальные состояния от аномальных в заданном пространстве признаков. В ос-
новном эти методы служат для идентификации известных аномалий. К клас-
сификационным методам можно отнести следующие типы алгоритмов:
1) основанные на методе опорных векторов, в том числе с использованием
ядерных функций,
2) основанные на нейронных сетях,
3) основанные на правилах,
4) основанные на байесовских сетях.
Все эти алгоритмы работают в режиме обучения с учителем, поэтому тре-
буют размеченных данных для обучения.
Метод опорных векторов (support vector machine, SVM) ищет гиперплос-
кость в пространстве признаков, способную разделить обучающую выбор-
ку на два класса. Этот метод может быть адаптирован для обнаружения
нелинейной границы при помощи механизма ядерной функции. Весьма по-
пулярным является классификация методом k ближайших соседей (k nearest
neighbours, kNN).
Для классификации также могут быть использованы различные типы ней-
ронных сетей, такие как сети прямого распространения (их также называют
MLP, multilayer perceptron), рекуррентные сети, в том числе с GRU (gated
recurrent unit) из [61] или LSTM (long short-term memory) из [62] нейрона-
ми, сверточные сети (convolutional neural net, CNN), а также другие типы,
используемые самостоятельно или последовательно с другими алгоритмами.
Методы, основанные на правилах, включают в себя поиск ассоциатив-
ных правил [63], логический анализ данных (logical analysis of data, LAD)
и основанные на них методы. К ним иногда относят методы, основанные на
решающих деревьях. При этом на обучающей выборке строится некоторое
интерпретируемое правило. Данные, ему не подчиняющиеся, считаются ано-
мальными. Все методы, основанные на Байесовских сетях, делают оценку
постериорной вероятности наблюдения метки определенного класса. Простой
19
Байесовский классификатор является самым простым и самым популярным
методом этой группы. Базовая техника предполагает независимость перемен-
ных друг от друга. Однако возможно ее обобщение с использованием более
сложных байесовых сетей.
Часто к классификационным методам относят методы одноклассовой
классификации. Они характеризуются тем, что в обучающей выборке присут-
ствуют представители только одного класса, а в случае поиска аномалий —
представители нормальной работы системы. Алгоритм строит границу обла-
сти, в которую попадают все эти представители, а объекты вне этой области
считаются аномальными. Наиболее часто применяемым методом этой кате-
гории является OC-SVM (one-class support vector machine) [64].
Das и Mattews в [65] разработали метод MKAD (Multiple Kernel Anomaly
Detection), который комбинирует в одном ядре метрику LCS (longest common
subsequence) из [66] для дискретных переменных и ядро на основе SAX
(symbolic aggregate approximation) из [67] представления непрерывных пере-
менных для одноклассовой классификации методом OC-SVM. В [65] проде-
монстрировано преимущество предложенной схемы над алгоритмами ORCA
и SequenceMiner при поиске значимых отклонений в полетных данных.
Преимущества классификационных методов:
— возможно использование готовых алгоритмов классификации;
— достаточно быстрая работа созданных моделей.
Недостатки классификационных методов:
— классификационные методы опираются на эталонную разметку в об-
учающей выборке, которая далеко не всегда доступна;
— присваивают только дискретную метку, что усложняет ранжирование
результатов.
Применения классификационных методов
Ke Li и соавт. исследовали различные методы классификации временных
рядов. В [68] используется алгоритм fuzzy c-means и выделение признаков
с помощью метода главных компонент (principal component analysis, PCA),
которые могут использоваться для облегчения разметки данных операто-
ром, после чего применили модификацию метода опорных векторов WPSVM
(weighted proximal support vector machine) для классификации сигналов си-
стемы электропитания космического аппарата (КА) на нормальные и ано-
мальные. Было изучено качество работы алгоритма при разных подходах к
многоклассовой классификации методом опорных векторов: разграничение
классов попарно и один из классов с остальными, а также сравнили WPSVM
с работой наивного Байесовского классификатора и метода K ближайших со-
седей (kNN). Кроме того, было показано, что быстродействие WPSVM позво-
ляет использовать его в режиме реального времени. В [69] исследован способ
выделения признаков на основе глубокой сети доверия (deep belief network) и
последующую классификацию с помощью случайного леса. Предварительно
была произведена фильтрация данных с помощью вейвлет-преобразования.
Для сравнения в [69] приведены также привели результаты классификации
другими алгоритмами: kNN, SVM, наивным Байесовым классификатором с
использованием нескольких методов выделения признаков: PCA, многоуров-
невых автокодировщиков (stacked autoencoder), а также на исходных данных.
20
Воронцов в [70] предложил использовать сеть прямого распространения
для классификации режимов работы СОТР и СЭП. На выборке из 50 тестов
была продемонстрирована работа алгоритма и достигнута частота ложных
положительных и ложных отрицательных срабатываний до 20 и 10 % соот-
ветственно.
Nassar, Hussein и соавт. в [71, 72] сравнили два алгоритма, обучающих-
ся с учителем: дискриминантный анализ при помощи частных наименьших
квадратов (partial least squares discriminant analysis, PLS-DA), ядерный метод
опорных векторов (kernel support vector machine, KSVM) и результаты рас-
чета в коммерческом пакете. В работах [71, 72] заявляется что подход, осно-
ванный на PLS-DA, отделяет аномальные данные лучше, чем PCA, который
только ищет направление максимальной изменчивости в данных. Система
была протестирована на 16 ТМП системы ориентации и стабилизации КА.
Fuertes и соавт. в [73] представили ограничения классических подходов
поиска аномалий по пороговым значениям и описали созданный программ-
ный продукт NOSTRADAMUS, который использовался для контроля ТМИ
аппарата CNES. Этот продукт уменьшает размерность данных и производит
одноклассовую классификацию методом опорных векторов. Авторы описали
примеры использования этой системы на ошибках СОТР и осцилляциях по-
казаний звездного датчика. Кроме того, они сравнили методы OC-SVM, kNN
и LOF, кратко описали достоинства и недостатки этих методов. В заключение
авторы описали концепцию работы, функционал и архитектуру выбранного
решения для внедрения и большей автоматизации работы операторов.
Galal и соавт. в [74] использовали метод главных компонент и байесовский
классификатор на ТМИ аккумуляторной батареи КА. Для разметки ано-
мальных данных они использовали режим штатной проверки работоспособ-
ности СЭП, поскольку в этом режиме батарея испытывает аномально боль-
шие для нормальной работы нагрузки. Для валидации использовались дан-
ные деградировавшей после аварии аккумуляторной батареи. В [74] удалось
понизить размерность исходных данных с 30 до 5 без существенных потерь в
качестве классификации и достигнуть точности 0,95 по метрике AUC ROC.
На данных ТМИ СЭП космического аппарата EgyptSat-1 Ibrahim и со-
авт. [75] применили SVM регрессию из [76] для предсказания поведения вре-
менного ряда и продолжили работать над интерпретируемостью результата
с использованием метода под названием логический анализ данных (logical
analysis of data, LAD) [77], который тренируется на результатах K-means кла-
стеризации. Комбинируя этот подход с анализом дерева отказов, в [75] оце-
нили наиболее вероятную причину возникновения отказа для расследования
возможных причин потери КА EgyptSat.
К сожалению, во многих публикациях авторы приводят только метрику
правильности классификации и не указывают показатели точности и пол-
ноты распознавания каждого класса или матрицы ошибок. Именно эти по-
казатели являются критически важными для практических применений и
анализа результатов при несбалансированных выборках, которые имеют ме-
сто при работе с отказами и аномалиями. Кроме того, эти метрики обычно
применяются к неструктурированным данным, а их применение к временным
рядам имеет некоторые особенности.
21
4.5. Методы, основанные на реконструкции
Методы, основанные на реконструкции, предполагают, что можно постро-
ить некоторую модель данных. Сравнивая текущие показания датчиков с
данными, рассчитанными с помощью этой модели, можно обнаружить ано-
малию. Другими словами, основанные на реконструкции методы используют
ошибку реконструкции данных для разделения их на нормальные и аномаль-
ные. Обученный на нормальных данных алгоритм будет давать существен-
ную ошибку восстановления на аномальных данных.
Можно условно разделить эти методы на методы, основанные на восста-
новлении сигнала, и на методы, основанные на предсказании.
Методы первого класса, по сути, предполагают, что в каждом состоянии
показания датчиков связаны некоторой зависимостью, поэтому могут быть
полностью описаны меньшим количеством переменных. Одним из самых по-
пулярных методов является метод главных компонент (PCA), в том числе с
использованием ядерных функций. К этому классу также относятся методы,
основанные на автокодировщиках.
Методы, основанные на предсказании, предполагают, что исходя из дан-
ных можно построить модель их эволюции при номинальном режиме работы.
К таким методам можно отнести различные типы нейронных сетей, в том
числе рекуррентные, прямого распространения и генеративные.
Преимущества методов, основанных на реконструкции:
— облегчают проблемы, связанные с многомерными данными, поскольку
автоматически понижают их размерность;
— могут быть использованы в режиме неконтролируемого обучения.
Недостатки методов, основанных на реконструкции:
— полезны только в случае, если в некотором пространстве признаков
аномалии отделимы;
— обычно имеют высокую вычислительную сложность.
Применения методов, основанных на реконструкции
Абрамов и соавт. в [78] предложили использовать нейронную сеть прямого
распространения для рекурсивного предсказания временного ряда, после че-
го были использованы пороговые методы для обнаружения аномалий в пред-
сказанном временном ряде. Этим методом была предсказана работа системы
на 4 мин и достигнута точность предсказания нештатной ситуации в 0,887
при полноте 0,938.
O’Meara и соавт. [28] исследовали возможности нейронных сетей прямого
распространения для предсказания временного ряда из агрегированной за ви-
ток статистики ТМП и детектировали появление аномалии по рассогласова-
нию значений измеренных параметров с предсказанными. Кроме того, в [28]
были исследованы возможности поиска аномалий системой ATHMoS с помо-
щью признаков, выделенных с помощью автокодировщика, а также в сочета-
нии с признаками, заданными вручную. В первой части [28] удалось коррект-
но предсказать поведение агрегированных параметров на три витка вперед.
Во второй части было показано, что для надежного выделения аномалий при-
знаки, заданные вручную, играют большую роль при обнаружении аномалий.
22
Martinez-Heras и Donati в [79] использовали глубокий автокодировщик для
поиска аномалий в телеметрии КА Mars Express и предположили, что рекур-
рентные нейронные сети могут быть использованы для определения порого-
вых значений.
Petković и соавт. [80] предлагают метод конвейерной обработки (batch
processing) для предсказания потребления системы обеспечения теплового
режима на КА Mars Express. Они использовали ручное выделение призна-
ков и ансамблевые методы, такие как случайный лес и градиентный бустинг
на решающих деревьях, для создания предиктивной модели. Их модель ис-
пользовалась для распределения энергии на научные эксперименты. В [80]
отмечается отмечают, что модель может использоваться для поиска анома-
лий по разладке предсказанного и измеренного энергопотребления.
Ibrahim и соавт. [81] сравнили различные методы глубокого обучения на
ТМИ, полученной от одной из составных частей КА EgyptSat. Они использо-
вали различные архитектуры, такие как ARIMA, MLP(Multilayer perceptron),
RNN, LSTM, GRU, DLSTM и DGRU, для предсказания поведения временно-
го ряда. Сравнение производилось по метрикам качества точности предска-
зания: среднеквадратичной ошибке, средней абсолютной ошибке, коэффици-
енту корреляции, метрике r2 и времени обучения. В результате был сделан
вывод, что для КА с небольшим временем активного существования, око-
ло 3-5 лет, лучше подходят более простые методы, такие как ARIMA, для
предсказания временного ряда во время штатной работы.
Omran и Murtada исследовали возможности извлечения признаков для
классификации отказов при помощи метода Прони. В [82] была использована
рекуррентную нейронную сеть, натренированную на признаках, выделенных
с помощью метода Прони для поиска аномалий в работе маховиков. В каче-
стве исходных данных были использованы данные высокоточного численного
моделирования. После этого была использована простая сеть прямого рас-
пространения для классификации найденных аномалий на известные клас-
сы нештатной работы рассматриваемой подсистемы. В результате алгоритм
был способен корректно определять все виды моделируемых неисправностей
и корректно выделять ранее неизвестные ему режимы работы с точностью,
близкой к 100 % и превосходящей точность таких алгоритмов, как ARMA,
PCA и SVM. В [83] были исследованы возможности метода Прони для извле-
чения признаков и последующей идентификации отказов солнечной батареи
и устойчивости такого алгоритма к шуму. В качестве исходных данных ис-
пользовались данные численного моделирования. С помощью сети прямого
распространения в [83] были затем идендтифицированы десять различных
видов отказов в шумных данных.
Shin и Tariq в [84] описали систему, внедренную для мониторинга состоя-
ния КА KOMPSAT-2 в Korea Aerospace Research Institute (KARI). Как и
в [28], были использованы статистически агрегированные по каждому ТМП
за каждые 10 мин признаки: среднее, максимальное и минимальное, меди-
анное значение, среднюю энергию сигнала и т.п. В отличие от [28], эти дан-
ные обрабатывались как тензор третьего порядка, используя CANDECOMP/
PARAFAC разложение из [85]. После этого была применена кластеризация на
строках одной из матриц в разложении, чтобы зарегистрировать момент воз-
23
никновения аномалии. В заключительной части анализа был применен метод
определения динамического порога, предложенный Hundman в [86].
Pilastre [87] предложил метод обнаружения аномалий, основанный на раз-
реженном линейном представлении отрезков сигнала. Метод работает с вре-
менными рядами с дискретными и непрерывными ТМП и работает в два
этапа. На первом этапе находятся представление проекции только дискрет-
ных переменных и соответствующий этим дискретным переменным словарь
непрерывных переменных. В случае, если такое представление может быть
найдено, второй этап конструирует непрерывный сигнал из линейной комби-
нации компонент словарь непрерывных переменных. Детектирование анома-
лии возможно на первом этапе, если представление дискретных переменных
из словаря невозможно, и на втором этапе, если ошибка реконструкции сиг-
нала превышает заданный порог.
4.6. Ансамблевые методы
Ансамблевые методы подробно обсуждались Aggarwal [88]. К ним прежде
всего относятся различные мета-алгоритмы, т.е. алгоритмы, использующие и
комбинирующие другие алгоритмы в своей работе. Можно выделить две ка-
тегоризации ансамблевых методов: по независимости компонент и по их типу.
В ансамблях с независимыми компонентами различные алгоритмы при-
меняются на разных частях исходных данных или их разных компонентах,
после чего комбинируются для получения более устойчивого результата. Слу-
чайный лес является типичным представителем этого класса. При последо-
вательном построении ансамбля каждый следующий алгоритм зависит от
результата предыдущего. Это происходит, например, при использовании гра-
диентного бустинга.
В категоризации по типу компонент Aggarwal выделяет ансамбли, ориен-
тированные на модели, и ансамбли, ориентированные на данные. Первые аг-
регируют результаты различных по своей природе базовых алгоритмов. При
этом возникают проблемы, связанные с различными типами результатов каж-
дого из алгоритмов. Например, результатом одного алгоритма может быть
значение от (-1) до 1, а результатом другого - условная вероятность выброса.
Ансамбли, ориентированные на данные, могут использовать часть данных
для построения каждой предсказательной модели, после чего агрегировать их
результаты для получения более устойчивого результата. Случайный лес —
представитель этого класса алгоритмов.
Преимущества ансамблевых методов:
— в некоторых случаях возможно сочетать преимущества различных ме-
тодов;
— в случае независимых компонент ансамбля алгоритмы легко масштаби-
руются на многопроцессорные вычисления.
Недостатки ансамблевых методов:
— как правило, высокая вычислительная сложность из-за необходимости
строить несколько моделей.
Применения ансамблевых методов
Carlton и соавт. в [89] использовали статистические подходы для поиска
интересующих их точек временного ряда, после чего группировали резуль-
24
таты по одинаковым компонентам в разных КА или по разным компонентам
одного КА исходя из близости найденных точек по времени. Если точек в
одной или нескольких группах в какой-то момент оказывалось много, то этот
момент времени получал большой показатель аномальности и соответствую-
щие данные выводились на экран оператора. В [89] была проведена валидация
этого подхода с использованием данных с телекоммуникационных спутников
Intelsat и Inmarsat и базы данных SpaceTrak1.
Nozari и соавт. в [90] предложили анализировать при помощи нейронной се-
ти прямого распространения результаты различных классификаторов и про-
демонстрировали работу сети на методе опорных векторов, PLS (partial least
squares), случайном лесе с использованием данных о работе УДМ.
5. Определение пороговых значений
В результате применения многих из описанных методов, в частности ста-
тистических методов или методов, основанных на реконструкции, получается
временной ряд с оценкой аномальности соответствующего состояния. Однако
при этом возникает упомянутая проблема определения порогового значения
аномальности, начиная с которого необходимо предупреждать оператора о
возможном приближении нештатной ситуации. Часто это происходит путем
эмпирического определения некоторого порогового значения, исходя из ин-
формации об уже известных отказах и выбирая соотношение между количе-
ством ложных положительных и ложных отрицательных ответов.
Как правило, длительная работа на режимах, близких к пороговым, яв-
ляется признаком аномальных процессов. Тем не менее поиск аномалий с
использованием пороговых значений не способен выявить такие режимы ра-
боты. Hundman и соавт. [86] предложили метод динамического определения
порогового значения при анализе временных рядов, который способен спра-
виться с этой проблемой. В [86] было предложено предложили определять
пороговое значение в зависимости от длительности и величины ошибки пред-
сказания сигнала, а также механизм фильтрации ложных положительных
результатов. Работа алгоритма была продемонстрирована с использованием
Numenta Anomaly Benchmark, а также данных КА Soil Moisture Active Passive
(25 ТМП) и Mars Science Laboratory (55 ТМП).
Pang [91] предложил критерий ширины покрытия (coverage width criterion)
для вычисления порогового значения аномальности состояния как гипер-
параметра модели при использовании вероятностных моделей. Эффектив-
ность данного метода была проверена на ТМИ системы электропитания КА
Fengyun.
6. Метрики качества методов
Для задач классификации и кластеризации типичными мерами качества
алгоритма являются точность (precision) и полнота (recall):
Точность = ИП/(ИП + ЛП),
Полнота = ИП/(ИП + ЛО),
25
где ИП - истинные положительные, ЛО - ложные отрицательные, ЛП - лож-
ные положительные результаты классификации. Таким образом, точность
отражает долю правильных ответов из всех точек, которые система отнесла
к данному классу, а чувствительность, которую также называют полнотой,
отражает долю правильно классифицированных точек из всех точек данного
класса. Как правило, совместное улучшение этих показателей оказывается
невозможным, и необходимо выбирать баланс между ними для каждой зада-
чи. Например, в очень крупных системах с большой устойчивостью можно
пожертвовать точностью. В то время как если цена ошибки очень высока,
то необходимо оптимизировать чувствительность ценой появления большего
количества ложных положительных результатов. Точность и полноту часто
комбинируют в F-меру, которая определяется как их среднее геометрическое.
Эти метрики предназначены для анализа классификации отдельных объ-
ектов, однако они не полностью применимы к временным рядам, поскольку
игнорируют их структуру. Lavin и соавт. [92] предложили метрику Numenta
anomaly benchmark, которая в некоторой мере учитывает последовательную
структуру временного ряда и вознаграждает раннее обнаружение аномалий.
В [92] предполагается, что идеальный детектор обладает следующими свой-
ствами:
1) выделяет все аномалии в данных,
2) выделяет аномалии как можно раньше, в идеале - до того, как их за-
метит человек,
3) не дает ложных срабатываний,
4) работает с данными в реальном времени,
5) полностью автоматизирован для работы с разными наборами данных.
Исходя из этих требований окно заданной ширины вокруг точечной ано-
малии, в котором срабатывание детектора вознаграждается, а срабатывание
вне этого окна считается ложным и штрафуется. Таким образом, эта метрика
работает с аномалиями как с точечными, но учитывает временную структу-
ру данных. В дополнение к этим методам вычисления метрик в работе [92]
представлен корпус данных Numenta NAB Data Corpus2, который содержит
одномерные временные ряды из различных областей, таких как информаци-
онные и коммуникационные технологии, системы кондиционирования в зда-
ниях и др. Эти данные имеют эталонную разметку и алгоритмы для оценки
эффективности поиска аномалий.
Lee и Tatbul [93] предложили настраиваемые метрики качества поиска ано-
малий во временных рядах, которые обобщают понятия точности и полноты
для множеств. Эти метрики учитывают частичное пересечение идентифици-
рованных и настоящих аномалий путем введения функций, которые некото-
рым образом штрафуют разные виды неточностей определения аномальных
интервалов. Эта метрика может учитывать специфику решаемой задачи пу-
тем введения других функций для штрафа за ошибки и вознаграждения за
найденные аномалии. При этом путем выбора определенных функций возна-
граждений и штрафов эта метрика может быть сведена к метрике, предло-
женной в [92], и потому является более общей.
26
Отметим, что для корректной оценки качества и количественного сравне-
ния работы различных алгоритмов обе метрики требуют наличия эталонной
разметки аномалий.
7. Применения и перспективы развития в космической технике
Опишем существующие промышленные системы мониторинга, основан-
ные на анализе данных, которые использовали или используют различные
космические агентства для облегчения эксплуатации космических аппаратов,
возможные варианты развития использующихся методов, а также открытые
источники данных, которые могут быть использованы для тестирования раз-
рабатываемых открытым сообществом алгоритмов.
Одной из первых систем, основанных на анализе данных, стала Inductive
Monitoring System, разработанная Iverson и соавт. в NASA [49]. Ее принцип
работы основан на алгоритме k-means, однако существенным отличием яв-
ляется доработка, позволяющая динамически увеличивать количество кла-
стеров. Этот метод требует наличия базы данных номинальных состояний
и обеспечивает выделение состояний, которые лежат достаточно далеко от
известных номинальных состояний.
O’Meara [41] представил систему, использующуюся в немецком центре
управления полетами (GSOC) DLR. Система берет за основу алгоритм IDOS
[33], работающий на основе анализа плотности точек, вычисленной на основе
оценки локальной естественной размерности данных, и дополняет его алго-
ритмом для выбора порогового значения для каждого ТМП. Кроме того,
в [28] кратко описывается основная инфраструктура системы мониторинга.
Columbus Control Centre DLR внедрил Project Sibyl [94] в качестве систе-
мы обнаружения аномалий для контроля пилотируемых космических поле-
тов. В системе реализован алгоритм LoOP на основе фреймворка ELKI
[95]. В дальнейших планах стоит использование наработок Sibyl в проекте
ATHMoS для создания единой системы мониторинга ТМИ для всех миссий
GSOC.
CNES разработал совместно с TESA и внедрил систему NOSTRADAMUS
[73] для контроля полета своих КА. В [73] описан основной функционал си-
стемы и концепция ее работы, основные промежуточные шаги анализа дан-
ных. В заключение [73] приведено описание основных недостатков системы,
выяснившихся в процессе эксплуатации, таких как повышенная чувствитель-
ность к входным данным (из-за особенностей работы выбранного за основу
алгоритма OC-SVM) и сложности интерпретации результата.
Системы мониторинга, основанные на данных, также работают в JAXA
[56] и NASA JPL [86], Korea Aerospace Research Institute (KARI) [84]. Одна-
ко в [56, 84, 86] приведено описание только математического метода анализа
информации и не описана инфраструктура решения.
Видно, что многие космические агентства активно эксплуатируют и зани-
маются внедрением различных математических методов для анализа ТМИ,
организуют необходимую для этого вычислительную инфраструктуру и до-
ступ к многолетней ТМИ для необходимой валидации созданных алгоритмов.
27
Существует также несколько открытых источников с информацией:
— Nasa Prognostics Center of Excellence3 предоставляет доступ к данным от
различных организаций и университетов, которые могут быть использованы
для изучения и отладки алгоритмов4;
— с 2019г. открыт доступ к ТМИ космического аппарата GOCE [96], ко-
торый содержит около 13 000 ТМП, однако он не содержит разметки данных
с указанием поломок и аномалий;
— в 2016 г. были проведены открытые соревнования по созданию эффек-
тивной предсказательной модели системы терморегуляции для аппарата Mars
Express Orbiter [30]. Данные представляют собой архив за три марсианских
года, включающих в себя контекст (например углы на Солнце, журналы от-
данных команд и т.п.) и данные наблюдений (потребление 33 ТМП СОТР).
Задача состояла в предсказании потребления СОТР на четвертый год;
— SpaceTrak5 — коммерчески поддерживаемая база данных происшествий
с космической техникой. Эта база не содержит ТМИ, но может служить ис-
точником данных для валидации или других исследований надежности.
К сожалению, по имеющейся на данный момент информации, не существу-
ет корпуса данных спутниковой ТМИ с разметкой аномалий или неисправ-
ностей. Ограниченное наличие данных значительно затрудняет разработку и
валидацию как специализированных методов, так и методов общего назначе-
ния для мониторинга КА.
Несмотря на значительные успехи и широкое применение в промышленно-
сти, существует значительный запрос на новые разработки. К ним относят-
ся технологии активного обучения для поиска аномалий. Этот запрос обус-
ловлен большим количеством поступающей информации и принципиальной
невозможностью полной ручной разметки.
Кроме того, большая часть алгоритмов машинного обучения предполага-
ет, что тренировочные и тестовые данные принадлежат одному и тому же
распределению. Однако на практике данное условие не выполняется ввиду
нестабильности производства и различных условий, в которых находятся КА.
Поэтому при применении модели, обученной на работе одного из КА группи-
ровки, к другому КА будут возникать неточности. Недавно для преодоления
этих сложностей начали использоваться техники предметной адаптации [97].
Эта тема требует дополнительных исследований для задач технической диаг-
ностики.
Остается открытым вопрос об использовании экспертного знания и физи-
ческих моделей, их интеграции в процесс автоматизированной технической
диагностики. Некоторые исследования показали, что это может улучшить
точность и интерпретируемость результата [98]. Tipaldi [3] предложил воз-
можную архитектуру такого решения. Подробный обзор перспектив глубо-
кого обучения для задач управления техническим состоянием был проведен
Fink и соавт. [99].
28
8. Заключение
В статье рассмотрены основные типы методов анализа данных, использую-
щихся для анализа телеметрической информации (ТМИ) и поиска аномалий
в ней, и основные публикации о применении этих методов. Были описаны
особенности постановки задачи и валидации работающих на этом принципе
систем мониторинга состояния КА, а также обсуждались возможные метрики
качества работы алгоритмов и вопросы выбора пороговых значений степени
аномальности для необходимого баланса между этими метриками. Кратко
обозначены возможные перспективы развития в этой области.
Можно видеть [11], что большинство алгоритмов быстро теряет свою эф-
фективность при увеличении количества анализируемых ТМП, поэтому мно-
гие работы так или иначе старались выделить признаки, имеющие меньшую
размерность, чем исходные данные. Эта проблема широко известна под назва-
нием “проклятие размерности”. Для борьбы с ней может быть полезна разум-
ная сегментация задачи мониторинга по параметрам отдельных составных
частей КА с последующей агрегацией результатов.
Самыми популярными методами для обнаружения аномалий являются ме-
тоды, основанные на плотности, которая вычисляется тем или иным спосо-
бом, а также методы, основанные на реконструкции, а одним из самых эффек-
тивных способов улучшить качество моделей является проработка особенно-
стей конкретных составных частей КА и тщательная подготовка признаков.
Часто этот фактор является решающим в качестве модели, а не алгоритм,
по которому эта модель работает. Несмотря на это можно видеть, что боль-
шинство публикаций учитывает только ТМИ, принятую с борта конкретного
КА, не принимая во внимание факторы космической погоды и ее прогноза,
что является крайне важным в работе КА.
Многие работы (см. приложение) используют искусственно сгенерирован-
ные данные для валидации своих алгоритмов. При этом остается открытым
вопрос о возможности распространения таких результатов на реальные по-
летные данные. Многие космические агентства, имеющие доступ к данным
для создания и валидации алгоритмов, разрабатывают и внедряют собствен-
ные системы для мониторинга технического состояния. Эти системы пока-
зывают эффективную работу в промышленном использовании и снижают
нагрузку на операторов.
К сожалению, на данный момент не существует достаточного количества
различных открытых данных с ТМИ КА и эталонной разметкой. Это делает
невозможным повторение и подтверждение публикуемых работ, учет различ-
ных особенностей составных частей КА, а также сравнение эффективности
работы экспертов и алгоритмов различных типов. Эти факторы значительно
затормаживают развитие и внедрение автоматизированных систем контро-
ля технического состояния КА. Для адаптации систем общего назначения
под специфику работы КА необходимо создание соответствующего корпуса
размеченных данных, а также объективных метрик для оценки и сравнения
качества работы различных алгоритмов и операторов.
Кроме того, для улучшения качества прогноза технического состояния КА
необходимо учитывать условия космической погоды и интегрировать эту ин-
формацию в системы поддержки принятия решений. С другой стороны, необ-
29
ходимы методы разбиения задачи контроля состояния всего КА на задачи
меньшей размерности, например по его составным частям, методы пониже-
ния размерности путем более эффективного представления информации для
улучшения работы алгоритмов, поскольку их эффективность напрямую свя-
зана с плотностью исходных данных.
Несмотря на перечисленные сложности и нерешенные задачи, системы мо-
ниторинга технического состояния КА, основанные на данных, уже исполь-
зуются во многих космических агентствах по всему миру и зарекомендовали
себя как важный инструмент технической диагностики.
ПРИЛОЖЕНИЕ
Таблица. Перечень работ
Выделение
Публикация
Данные
Метод
признаков
1
2
3
4
Iverson, 2004
Columbia Space
нет
Кластеризация
[49]
Shuttle
Azevedo,
СЭП бразильского
нет
K-means, Статистические
2012 [54]
КА
(EM)
Li, 2015 [68]
Данные моделиро-
PCA
Fuzzy C-means, WPSVM
вания СЭП
Fuertes, 2016
КА CNES
статистические
PCA + OC-SVM
[73]
параметры сиг-
нала в окне
O’Meara,
Маховики КА
Вектор из свод-
OPVID
2016 [41]
TET-1
ной информации
по каждому
ТМП за виток
Verzola, 2016
запоминающее
Время дня, коор-
Вероятностные парамет-
[94]
устройство (Mass
динаты, положе-
рические
Memory Unit)
ние солнца, дан-
Columbus Orbital
ные космической
Laboratory
погоды
Nassar,
2017
16 ТМП СОС
нет
классификация PLS-DA,
[72]
KSVM
Rahimi, 2017
Численное
Р-адаптивный фильтр
[55]
моделирование
Калмана
Yairi,
СЭП КА JAXA
Байесовская классифика-
2017 [56]
SDS-4
ция + Stochastic PCA
Chen,
Лабораторный
Корреляционная
K-medoids(2 раза)
2018 [52]
эксперимент
размерность
с УДМ СОС
Pang,
СЭП с КА
нет
LS-SVM, Gaussian Process
2018 [91]
FENGYUN
Regression,
Restricted Vector Machine
Adnane, 2018
Численное моде-
Обобщенный фильтр Кал-
[58]
лирование СОС
мана
30
Таблица (продолжение)
1
2
3
4
Carlton, 2018
Intelsat, Inmarsat
Поиск временных явлений,
[89]
точек перехода статисти-
ческими методами, груп-
пировка событий
O’Meara,
Несколько лет
Выделены как
Сеть прямого распростра-
2018 [28]
исторической
вручную, так и с
нения
информации о
помощью автоко-
работе КА
дировщика
Martinez,
991 ТМП КА Mars
нет
Определение пороговых
2018 [79]
Express
значений с помощью
нейронной сети прямого
распространения
Gowda, 2018
ТМИ Mars Express
ручное выделе-
XGBoost
[29]
Challenge
ние признаков
Suo, 2019 [22]
СЭП геостацио-
Выбраны с помо-
SVM
нарного КА
щью предложен-
(искусственные)
ной методики
Galal,
30 переменных
PCA
Байесовский
2019 [74]
СЭП
(7 компонент)
классификатор
Ibrahim, 2019
EgyptSat-1
ARIMA, MLP, RNN,
[81]
LSTM, GRU, DLSTM,
DGRU
Ahmed, 2019
Nasa Ames
Классификация + метод
[59]
Prognostics
Каплана-Мейера
Petkovic,
СЭП
ручное
Случайный лес, градиент-
2019 [80]
Марс-Экспресс
ный бустинг
Suo, 2019 [53]
СЭП геостацио-
нет
NGC Сеточная кластери-
нарного КА
зация на основе соседства
(искусственные)
Omran, 2019
Численное моде-
Метод Прони
Elman RNN для детек-
[82]
лирование высо-
тирования по разладке и
кой точности
сеть прямого распростра-
маховика СОС
нения для классификации
аномалий
Murtada,
Численное моде-
Метод Прони
Сеть прямого распростра-
2019 [83]
лирование работы
нения
солнечных пане-
лей с шумами
Nozari,
2019
Численное моде-
Результаты дру-
Мета-классификатор на
[90]
лирование
гих классифика-
основе SVM, NB, PLS, RF
торов
Ibrahim, 2020
СОТР EgyptSat-1
OC-SVM, K-means, LAD
[75]
Pilastre, 2020
18 дней ТМИ: 1000
Дискретные и
Anomaly Detection using
[87]
ТМП (90 затрону-
непрерывные па-
Dictionary (ADDICT)
то аномалиями)
раметры из окна
фиксированной
ширины
31
СПИСОК ЛИТЕРАТУРЫ
1.
Zolghadri A. Advanced Model-Based FDIR Techniques for Aerospace Systems:
Today Challenges and Opportunities // Progress in Aerospace Sciences. 2012. V. 53.
2.
Абанин О.И., Соловьёв С.В. Содержание и структура задач диагностики ано-
малий в работе бортовых систем космического аппарата // Инж. ж.: наука и
инновации. 2019. № 6 (90). C. 7. ISSN 2308-6033.
3.
Tipaldi M., et al. On Applying AI-Driven Flight Data Analysis for Operational
Spacecraft Model-Based Diagnostics // Annual Reviews in Control. 2020. V. 49.
4.
Соловьев С.В., Мишурова Н.В. Анализ текущего состояния процесса контроля
при управлении полетом космических аппаратов // Инж. ж.: наука и инновации.
2016. № 3 (51). C. 3. ISSN 2308-6033.
5.
Соловьев В.А., Любинский В.Е., Жук Е.И. Текущее cостояние и перспективы
развития системы управления полетами космических аппаратов // Пилотируе-
мые полеты в космос. 2011. № 1 (1). C. 27-37. ISSN 2226-7298.
6.
Балухто А.Н., Романов А.А. Искусственный интеллект в космической технике:
состояние, перспективы развития // Ракетно-космическое приборостроение и
информационные системы. 2019. T. 6. № 1. C. 65-75. ISSN 2409-0239, 2587-9057.
7.
Chandola V., Banerjee A., Kumar V. Anomaly Detection: A Survey // ACM Comp.
8.
Pimentel M.A.F., et al. A Review of Novelty Detection // Signal Processing. 2014.
9.
Wang H., Bah M.J., Hammad M. Progress in Outlier Detection Techniques:
A Survey // IEEE Access. 2019. V. 7. P. 107964-108000. ISSN 2169-3536.
10.
Chalapathy R., Chawla S. Deep Learning for Anomaly Detection: A Survey. 2019.
17.04.2020).
11.
Zimek A., Schubert E., Kriegel H.-P. A Survey on Unsupervised Outlier Detection
in High-Dimensional Numerical Data // Statistical Analysis and Data Mining: The
ASA Data Science J. 2012. V. 5. No. 5. P. 363-387. ISSN 1932-1872.
12.
Thudumu S., et al. A Comprehensive Survey of Anomaly Detection Techniques for
High Dimensional Big Data // J. of Big Data. 2020. V. 7. No. 1. P. 42.
13.
Gavrilovski A., et al. Challenges and Opportunities in Flight Data Mining: A Review
of the State of the Art // AIAA Infotech @ Aerospace. SanDiego, California, USA:
14.
Khan S., Yairi T. A Review on the Application of Deep Learning in System Health
Management // Mech. Systems and Signal Processing. 2018. V. 107. P. 241-265.
15.
Basora L., Olive X., Dubot T. Recent Advances in Anomaly Detection Methods
Applied to Aviation // Aerospace. 2019. V. 6. No. 11. P. 117.
16.
Соловьев В.А., Лысенко Л.Н., Любинский В.Е. Управление космическими по-
летами. Уч. пос. Ч.1. М.: МГТУ им. Баумана, 2009. ISBN 978-5-7038-3351-3.
32
17.
Gao Z., Cecati C., Ding S. A Survey of Fault Diagnosis and Fault-Tolerant Techni-
ques - Part I: Fault Diagnosis with Model-Based and Signal-Based Approaches //
IEEE Trans. on Industrial Electronics. 2015. V. 62. No. 6. P. 3757-3767.
18.
Barber D. Bayesian Reasoning and Machine Learning. 1st edition. Cambridge; N.Y.:
Cambridge UniversityPress, 2012. ISBN 978-0-521-51814-7.
19.
Pimentel T., et al. Deep Active Learning for Anomaly Detection. 2020. arXiv:
20.
Das S., et al. Incorporating Expert Feedback into Active Anomaly Discovery // 2016
IEEE 16th Int. Conf. on Data Mining (ICDM). 2016. P. 853-858.
21.
IBM Analytics. ASUM Analytics Solutions Unifed Method. 2015.
22.
Suo M., et al. Data-Driven Fault Diagnosis of Satellite Power System Using Fuzzy
Bayes Risk and SVM // Aerospace Science and Technology. 2019. V. 84. P. 1092-
23.
Kononenko I. Estimating Attributes: Analysis and Extensions of RELIEF //
Machine Learning: ECML-94/ Eds. F. Bergadano, L. De Raedt. Berlin, Heidelberg:
Springer, 1994. P. 171-182. (Lecture Notes in Computer Science.)
24.
Hanchuan Peng, Fuhui Long, Ding C. Feature Selection Based on Mutual
Information Criteria of Max-Dependency, Max-Relevance, and Min-Redundancy //
IEEE Transactions on Pattern Analysis and Machine Intelligence. 2005. V. 27. No. 8.
25.
Hu Q., et al. Neighborhood Rough Set Based Heterogeneous Feature Subset
Selection // Information Sciences. 2008. V. 178. No. 18. P. 3577-3594. ISSN 0020-
26.
Mallat S. A Wavelet Tour of Signal Processing: The Sparse Way. 3rd edition.
Academic Press, 2008. ISBN 978-0-12-374370-1.
27.
Barreyre C., et al. Statistical Methodsfor Outlier Detectionin Space Telemetries //
Space Operations: Inspiring Humankind’s Future / Eds. H. Pasquier, et al. Cham:
Springer Int. Publishing, 2019. P. 513-547. ISBN 978-3-030-11536-4.
28.
O’Meara C., Schlag L., Wickler M. Applications of Deep Learning Neural Networks
to Satellite Telemetry Monitoring // 15th Int. Conf. on Space Operations. Marseille,
29.
Gowda G.M., et al. The Added Value Of Advanced Feature Engineering And
Selection For Machine Learning Models In Spacecraft Behavior Prediction // 2018
SpaceOps Conf. Marseille, France: AIAA, 2018. ISBN 978-1-62410-562-3.
30.
Lucas L., Boumghar R. Machine Learning for Spacecraft Operations Support — The
Mars Express Power Challenge / 2017 6th Int. Conf. on Space Mission Challenges
for Inf. Technology (SMC-IT). 2017. P. 82-87.
31.
Bay S.D., Schwabacher M. Mining Distance-Based Outliers in near Linear Time with
Randomization and a Simple Pruning Rule // Proc. 9th ACM SIGKDD Int. Conf.
on Knowledge Discovery and Data Mining. Washington, D.C.: ACM, 2003. P. 29-38.
32.
Breunig M.M., et al. LOF: Identifying Density-Based Local Outliers // Proc. 2000
ACM SIGMOD Int. Conf. on Management of Data. Dallas, Texas, USA: ACM, 2000.
P. 93-104. (SIGMOD ’00). ISBN 978-1-58113-217-5.
33
33.
Von Brünken J., Houle M.E., Zimek A. Intrinsic Dimensional Outlier Detection in
High-Dimensional Data // NII Technical Reports. 2015. V. 2015. No. 3. P. 1-12.
34.
Houle M.E., Kashima H., Nett M. Generalized Expansion Dimension // 2012 IEEE
12th Int. Conf. on Data Mining Workshops. 2012. P. 587-594.
35.
Houle M.E. Dimensionality, Discriminability, Density and Distance Distributions //
2013 IEEE 13th Int. Conf. on Data Mining Workshops. 2013. P. 468-473.
36.
Kriegel H.-P., et al. Outlier Detection in Axis-Parallel Subspaces of High Dimen-
sional Data // Adv. in Knowledge Discovery and Data Mining / Eds. T. Theera-
munkong, et al. Berlin, Heidelberg: Springer, 2009. P. 831-838. (Lecture Notes in
Computer Science). ISBN 978-3-642-01307-2.
37.
Kriegel H.-P., Schubert M., Zimek A. Angle-Based Outlier Detection in High-
Dimensional Data // Proc. 14th ACM SIGKDD Int. Conf. on Knowledge Discovery
and Data Mining. New York, NY, USA: ACM, 2008. P. 444-452. (KDD ’08). ISBN
38.
Rosenblatt M. Remarks on Some Nonparametric Estimates of a Density Function //
Annals of Mathematical Statistics. 1956. V. 27. No. 3. P. 832-837. ISSN 0003-4851,
39.
Tang B., He H. A Local Density-Based Approach for Outlier Detection // Neuro-
computing. 2017. V. 241. P. 171-180. ISSN 0925-2312.
40.
Dynamic Time Warping // Inf. Retrieval for Music and Motion / Eds. M. Muller.
Berlin, Heidelberg: Springer, 2007. P. 69-84. ISBN 978-3-540-74048-3.
41.
O’Meara C., et al. ATHMoS: Automated Telemetry Health Monitoring System at
GSOC Using Outlier Detection and Supervised Machine Learning // SpaceOps 2016
Conf. Daejeon, Korea: AIAA, 2016. ISBN 978-1-62410-426-8.
42.
Martinez J. New Telemetry Monitoring Paradigm with Novelty Detection //
SpaceOps 2012 Conf. AIAA, 2012. (SpaceOps Conf.s).
43.
Schlag L., O’Meara C., Wickler M. Numerical Analysis of Automated Anomaly
Detection Algorithms for Satellite Telemetry // 15th Int. Conf. on Space Operations.
Marseille, France: AIAA, 2018. ISBN 978-1-62410-562-3.
44.
Guha S., Rastogi R., Shim K. Rock: A Robust Clustering Algorithm for Categorical
Attributes // Inf. Systems. 2000. V. 25. No. 5. P. 345-366. ISSN 0306-4379.
45.
Ertöz L., Steinbach M., Kumar V. Finding Clusters of Different Sizes, Shapes, and
Densities in Noisy, High Dimensional Data // Proc. 2003 SIAM Int. Conf. on Data
Mining. Society for Industrial, Applied Mathematics, 2003. P. 47-58. (Proceedings).
46.
Kohonen T. Exploration of Very Large Databases by Self-Organizing Maps //
Proc. of Int. Conf. on Neural Networks (ICNN’97). V. 1. IEEE, 1997. PL1-PL6.
47.
He Z., Xu X., Deng S. Discovering Cluster-Based Local Outliers // Pattern Recog-
nition Letters. 2003. V. 24. No. 9. P. 1641-1650. ISSN 0167-8655.
34
48.
Sun H., et al. CD-Trees: An Efficient Index Structure for Outlier Detection // Adv.
in Web-Age Inf. Management / Eds. Q. Li, G. Wang, L. Feng. Berlin, Heidelberg:
Springer, 2004. P. 600-609. (Lecture Notes in Computer Science). ISBN 978-3-540-
49.
Iverson D.L., Field M. Inductive System Health Monitoring. 2004.
50.
Iverson D.L., et al. General Purpose Data-Driven Monitoring for Space Opera-
tions // J. of Aerospace Computing, Inf., and Communication. 2012. V. 9. No. 2.
51.
Singh S. A Data-Driven Approach to Cubesat Health Monitoring // Master’s Theses
52.
Chen C., et al. A Fault Diagnosis Method for Satellite Flywheel Bearings Based
on 3D Correlation Dimension Clustering Technology // IEEE Access. 2018. V. 6.
53.
Suo M., et al. Neighborhood Grid Clustering and Its Application in Fault
Diagnosis of Satellite Power System // Proc. Inst. of Mech. Engineers, Part G:
J. of Aerospace Engineering. 2019. V. 233. No. 4. P. 1270-1283. ISSN 0954-4100.
54.
Azevedo D.R., Ambrosio A.M., Vieira M. Applying Data Mining for Detecting
Anomalies in Satellites // 2012 9th European Dependable Computing Conf. 2012.
P. 212-217. https:// doi.org/ 10.1109/EDCC.2012.19
55.
Rahimi A., Kumar K.D., Alighanbari H. Fault Estimation of Satellite Reaction
Wheels Using Covariance Based Adaptive Unscented Kalman Filter // Acta
Astronautica. 2017. V. 134. P. 159-169. ISSN 0094-5765.
56.
Yairi T., et al. A Data-Driven Health Monitoring Method for Satellite Housekeeping
Data Based on Probabilistic Clustering and Dimensionality Reduction // IEEE
Trans. on Aerospace and Electronic Systems. 2017. V. 53. No. 3. P. 1384-1401. ISSN
57.
Tipping M.E., Bishop C.M. Mixtures of Probabilistic Principal Component
Analyzers // Neural Computation. 1999. V. 11. No. 2. P. 443-482. ISSN 0899-7667.
58.
Adnane A. et al. Real-Time Sensor Fault Detection and Isolation for LEO Satellite
Attitude Estimation through Magnetometer Data // Adv. Space Res. 2018. V. 61.
59.
Ahmed A.M., et al. Prediction of Battery Remaining Useful Life on Board Satellites
Using Logical Analysis of Data // 2019 IEEE Aerospace Conf. 2019. P. 1-8.
60.
Kaplan E.L., Meier P. Nonparametric Estimation from Incomplete Observations //
J. of the American Statistical Association. 1958. V. 53. No. 282. P. 457-481. ISSN
61.
Chung J., et al. Empirical Evaluation of Gated Recurrent Neural Networks on
Sequence Modeling. 2014. arXiv: 1412.3555 [cs].
62.
Hochreiter S., Schmidhuber J. Long Short-Term Memory // Neural Computation.
63.
Agrawal R., Imielinski T., Swami A. Mining Association Rules between Sets of Items
in Large Databases // ACM SIGMOD Record. 1993. V. 22. No. 2. P. 207-216. ISSN
64.
Schölkopf B., et al. Estimating the Support of a High-Dimensional Distribution //
Neural Computation. 2001. V. 13. No. 7. P. 1443-1471. ISSN 0899-7667.
35
65.
Das S., et al. Multiple Kernel Learning for Heterogeneous Anomaly Detection:
Algorithm and Aviation Safety Case Study // Proc. 16th ACM SIGKDD Int. Conf. on
Knowledge Discovery and Data Mining. New York, NY, USA: ACM, 2010. P. 47-56.
66.
Budalakoti S., Srivastava A.N., Otey M.E. Anomaly Detection and Diagnosis
Algorithms for Discrete Symbol Sequences with Applications to Airline Safety //
IEEE Trans. on Systems, Man, and Cybernetics. Part C: Applications and Reviews.
2009. V. 39. No. 1. P. 101-113. ISSN 1094-6977.
67.
Patel P., et al. Mining Motifs in Massive Time Series Databases // Proc. 2002 IEEE
68.
Li K., et al. A Spacecraft Electrical Characteristics Multi-Label Classification
Method Based on Off-Line FCM Clustering and On-Line WPSVM // PLOS ONE.
2015. V. 10. No. 11. e0140395. ISSN 1932-6203.
69.
Li K., et al. Multi-Label Spacecraft Electrical Signal Classification Method Based
on DBN and Random Forest // PLoS ONE. 2017. V. 12. No. 5. ISSN 1932-6203.
70.
Воронцов В.А., Федоров Е.А. Разработка прототипа интеллектуальной системы
оперативного мониторинга и технического состояния основных бортовых систем
космического аппарата // Тр. Маи. 2015. № 82. C. 35. ISSN 1727-6942.
71.
Nassar B., Hussein W. State-of-Health Analysis Applied to Spacecraft Telemetry
Based on a New Projection to Latent Structure Discriminant Analysis Algorithm //
2015 IEEE Aerospace Conf. 2015. P. 1-11.
72.
Nassar B., Hussein W., Medhat M. Supervised Learning Algorithms for Spacecraft
Attitude Determination and Control System Health Monitoring // IEEE Aerospace
and Electronic Systems Magazine. 2017. V. 32. No. 4. P. 26-39. ISSN 1557-959X.
73.
Fuertes S., et al. Improving Spacecraft Health Monitoring with Automatic Anomaly
Detection Techniques // SpaceOps 2016 Conf. AIAA, 2016.
74.
Galal M.A., et al. Satellite Battery Fault Detection Using Naive Bayesian
Classifier // 2019 IEEE Aerospace Conf. 2019. P. 1-11.
75.
Ibrahim S.K., et al. Machine Learning Techniques for Satellite Fault Diagnosis //
Ain Shams Engineering J. 2020. V. 11. No. 1. P. 45-56. ISSN 2090-4479.
76.
Trafalis T.B., Ince H. Support Vector Machine for Regression and Applications
to Financial Forecasting // Proc. IEEE-INNS-ENNS Int. Joint Conf. on Neural
Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for
the New Millennium. V. 6. IEEE, 2000. P. 348-353.
77.
Chikalov I., et al. Logical Analysis of Data: Theory, Methodology and Applications //
Three Approaches to Data Analysis: Test Theory, Rough Sets and Logical Analysis
of Data / Eds. I. Chikalov, et al. Berlin, Heidelberg: Springer, 2013. P. 147-192.
(Intelligent Systems Reference Library). ISBN 978-3-642-28667-4.
78.
Абрамов Н.С. и др. Высокопроизводительная нейросетевая система мониторин-
га состояния и поведения подсистем космических аппаратов по телеметриче-
ским данным // Программные системы: теория и приложения. Россия, Весько-
во, 2017. № 3 (30).
36
79.
Martinez J., Donati A. Novelty Detection with Deep Learning // 2018 SpaceOps
80.
Petkovic M., et al. Machine Learning for Predicting Thermal Power Consumption of
the Mars Express Spacecraft // IEEE Aerospace and Electronic Systems Magazine.
2019. V. 34. No. 7. P. 46-60. ISSN 1557-959X.
81.
Ibrahim S.K., et al. Machine Learning Methods for Spacecraft Telemetry Mining //
IEEE Trans. on Aerospace and Electronic Systems. 2019. V. 55. No. 4. P. 1816-1827.
82.
Omran E.A., Murtada W.A. Efficient Anomaly Classification for Spacecraft Reaction
Wheels // Neural Computing and Applications. 2019. V. 31. No. 7. P. 2741-2747.
83.
Murtada W.A., Omran E.A. Robust Anomaly Identification Algorithm for Noisy
Signals: Spacecraft Solar Panels Model // Neural Computing and Applications. 2019.
84.
Shin Y., et al. ITAD: Integrative Tensor-Based Anomaly Detection System for
Reducing False Positives of Satellite Systems // Proc. 29th ACM Int. Conf. on
Inf. & Knowledge Management. New York, NY, USA: ACM, 2020. P. 2733-2740.
85.
Kiers H.A.L. Towards a Standardized Notation and Terminology in Multiway Ana-
lysis // J. of Chemometrics. 2000. V. 14. No. 3. P. 105-122. ISSN 1099-128X.
2-I.
86.
Hundman K., et al. Detecting Spacecraft Anomalies Using LSTMs and Nonpa-
rametric Dynamic Thresholding // Proc. ACM SIGKDD Int. Conf. on Knowledge
Discovery and Data Mining. 2018. P. 387-395.
87.
Pilastre B., et al. Anomaly Detection in Mixed Telemetry Data Using a Sparse Repre-
sentation and Dictionary Learning // Signal Processing. 2020. V. 168. P. 107320.
88.
Aggarwal C.C. Outlier Ensembles: Position Paper // ACM SIGKDD Explorations
Newsletter. 2013. V. 14. No. 2. P. 49-58. ISSN 1931-0145.
89.
Carlton A., et al. Telemetry Fault-Detection Algorithms: Applications for Spacecraft
Monitoring and Space Environment Sensing // J. of Aerospace Inf. Systems. 2018.
90.
Nozari H.A., et al. Novel Non-Model-Based Fault Detection and Isolation of
Satellite Reaction Wheels Based on a Mixed-Learning Fusion Framework //
IFACPapersOnLine. 2019. V. 52. No. 12. P. 194-199. (21st IFAC Symposium on
Automatic Control in Aerospace ACA 2019). ISSN 2405-8963.
91.
Pang J., et al. Anomaly Detection for Satellite Telemetry Series with Prediction
Interval Optimization // 2018 Int. Conf. on Sensing, Diagnostics, Prognostics, and
92.
Lavin A., Ahmad S. Evaluating Real-Time Anomaly Detection Algorithms - The
Numenta Anomaly Benchmark // 2015 IEEE 14th Int. Conf. on Machine Learning
and Applications (ICMLA). 2015. P. 38-44.
93.
Tatbul N., et al. Precision and Recall for Time Series // Adv. in Neural Inf. Processing
Systems 31 / Eds. S. Bengio, et al. Curran Associates, Inc., 2018. P. 1920-1930.
37
94. Verzola I., et al. Project Sibyl: A Novelty Detection System for Human Spaceflight
Operations // SpaceOps 2016 Conf. AIAA, 2016. (SpaceOps Conf.)
02.11.2020).
96. European Space Agency. GOCE Telemetry Data Collection. 2019.
97. Ganin Y., et al. Domain-Adversarial Training of Neural Networks // J. of Machine
Learning Research. 2016. V. 17. No. 59. P. 1-35.
98. Von Rueden L., et al. Informed Machine Learning — A Taxonomy and Survey of
Integrating Knowledge into Learning Systems. 2020. arXiv: 1903.12394 [cs, stat].
99. Fink O., et al. Potential, Challenges and Future Directions for Deep Learning in
Prognostics and Health Management Applications // Eng. Appl. Artif. Intell. 2020.
Статья представлена к публикации членом редколлегии В.М. Глумовым.
Поступила в редакцию 04.12.2020
После доработки 04.01.2021
Принята к публикации 16.03.2021
38