

Физиология человека, 2019, T. 45, № 3, стр. 5-15
Параллельный факторный анализ в исследовании связанных с событиями потенциалов
В. А. Пономарев 1, *, М. В. Пронина 1, Ю. Д. Кропотов 1
1 ФГБУН Институт мозга человека им. Н.П. Бехтеревой РАН,
Санкт-Петербург, Россия
* E-mail: valery_ponomarev@mail.ru
Поступила в редакцию 26.11.2018
После доработки 19.12.2018
Принята к публикации 05.02.2019
Аннотация
Целью исследования является проверка адекватности и информативности модели параллельного факторного анализа для описания потенциалов, связанных с событиями (ПСС). Исследования выполняли, используя записи ПСС в зрительном Go/NoGo тесте у 351 здорового испытуемого в возрасте 18–55 лет. Результаты исследований показали, что параллельный факторный анализ позволяет выделить компоненты ПСС, различающиеся по топографиям и форме сигналов, причем последние зависят от вида ответа испытуемого. Величины этих компонент индивидуальны, изменяются от испытуемого к испытуемому, и являются взаимно некоррелированными. На основании результатов исследований сделан вывод, что параллельный факторный анализ является адекватным подходом для описания общих характеристик и индивидуальных особенностей ПСС.
Анализ потенциалов, связанных с событиями (ПСС), является информативным методом получения информации о динамике мозговых процессов, развивающихся в ходе реализации различных поведенческих реакций, и широко используется как в фундаментальных, так и прикладных исследованиях [1, 2]. В то же время, вследствие объемной электрической проводимости мозга, регистрируемые с поверхности головы электрические потенциалы, представляют собой суперпозицию сигналов от многих мозговых источников [3], что, в свою очередь, значительно усложняет анализ ПСС и интерпретацию полученных данных.
Для решения этой проблемы предлагаются различные математические методы, позволяющие разделить ПСС на составляющие. Во-первых, это многочисленные методы локализации источников, основанные на приблизительных физических моделях распространения электрических полей в мозге [4–7]. И, во-вторых, это методы слепого разделения источников, которые основаны на анализе статистических характеристик сигналов, но не используют какой-либо физической модели [1, 8, 9].
Особенностью большинства этих методов является то, что они ориентированы на анализ индивидуальных записей ЭЭГ или ПСС, и игнорируют межиндивидуальную вариабельность этих электрических сигналов мозга. Но оказалось, что если учитывать особенности межиндивидуальной вариабельности ПСС, то можно предложить эффективный метод разложения ПСС на составляющие (компоненты) [10], использование которого в последующих исследованиях дало возможность получить значимую информацию о мозговых процессах, протекающих при выполнении зрительного Go/NoGo теста [11–13]. В то же время, интенсивное применение этого метода разложения ПСС на компоненты позволило не только оценить его эффективность, но и выявить ряд его ограничений. В частности, было выявлено, что его эффективность уменьшается при низком соотношении сигнал–шум, что, в свою очередь, предъявляет строгие требования к качеству и количеству индивидуальных записей ПСС и выбору подходящей эпохи анализа (интервала времени). Также было выявлено, что при чрезмерно длительной эпохе анализа или же большом числе условий (категорий проб) в тесте, применения этого метода разложения ПСС на компоненты также оказывается мало эффективным. Все эти факты привели к необходимости разработки другого подхода.
Как правило, в исследованиях ПСС, исходные данные представляют собой четырехмерный массив размера E × T × C × S, где E – число электродов, T – число временных отсчетов, C – число условий в тесте и S – число испытуемых. Этот массив данных в вычислительной науке принято называть “тензором” [14]. Такое тензорное представление данных предоставляет мощные средства анализа их скрытой структуры с помощью, так называемых, тензорных разложений [15–17]. Одним из таких разложений является каноническое разложение, которое также принято называть “канонической полиадической моделью” (canonical polyadic model или CP) или параллельным факторным анализом (parallel factor analysis или PARAFAC), и которое для краткости будем обозначать как “CP модель” [14]. Одним из преимуществ CP модели является то, что при достаточно большом размере исходного тензора с точностью до произвольных перестановок и масштабов это разложение является единственным [14]. В исследованиях ПСС обычно сравниваются сигналы, полученные при различных условиях в тесте. Чтобы при анализе данных с помощью CP модели была возможность выполнять аналогичные сравнения, необходимо объединить размерности T и C. Тогда получится трехмерный массив данных размера E × (TC) × S, который обозначим как Y, и для него CP модель может быть записана в виде:
(1)
$\begin{gathered} {{Y}_{{e,t,s}}} \approx \sum\limits_{r = 1}^R {A_{{e,r}}^{{(E)}}A_{{t,r}}^{{(TC)}}A_{{s,r}}^{{(S)}}} \,\,\,\,{\text{и л и }} \\ Y \approx \left[ {{{A}^{{(E)}}}{{A}^{{(TC)}}}{{A}^{{(S)}}}} \right], \\ \end{gathered} $В том случае, когда выполняется анализ ПСС, на свойства матрицы A(S) могут быть наложены дополнительные ограничения. Во-первых, предположим, что анатомическая организация мозга человека приблизительно одинаковая, тогда логично предположить также, что полярности сигналов мозговых источников, которые отражаются в ПСС, также одинаковы, отсюда следует, что все элементы матриц A(S) больше или равны 0. Во-вторых, CP модель является аддитивной, и это означает, что ПСС представляют собой сумму сигналов от нескольких мозговых источников. Предположим, что эти источники пространственно разделены, или же мозговые механизмы генерации этих сигналов различные. Также предположим, что величины этих сигналов зависят от текущего состояния нейронных сетей, в которых они генерируются. Но на это состояние случайным образом влияет огромное число факторов, как в онтогенезе, так и в момент проведения исследования. Причем эти комбинации факторов варьируют от испытуемого к испытуемому. Отсюда логично предположить, что величины компонент случайным образом и независимо друг от друга варьируют от испытуемого к испытуемому. Иными словами, можно предположить, что величины элементов в разных столбцах матрицы A(S) взаимно некоррелированы.
Суммируя вышесказанное, можно предположить, что CP модель с дополнительными ограничениями в первом приближении является адекватной для описания ПСС, но это заранее неизвестно. Задачей данного исследования являлась проверка адекватности CP модели для описания ПСС, записанных при выполнении испытуемыми зрительного Go/NoGo теста.
МЕТОДИКА
В исследованиях использовали записи ПСС, которые описывали ранее [10, 12]. Кратко методика регистрации может быть описана следующим образом.
Записи ЭЭГ выполняли у здоровых испытуемых с помощью компьютерного электроэнцефалографа “Мицар-ЭЭГ” в диапазоне 0.53–50 Гц, режекторный фильтр 45–55 Гц, частота квантования – 250 Гц. Электроды располагались в соответствии с международной системой 10–20, референт – объединенные электроды, расположенные на мочках ушей, заземляющий – в отведении Fpz. Сопротивление электродов не превышало 5 кОм. Коррекцию артефактов моргания проводили с помощью разложения ЭЭГ на независимые компоненты, и обнуления составляющих сигналов, соответствующих морганию глаз [18]. Другие артефакты удаляли с помощью эмпирически подобранных пороговых критериев [10].
Испытуемые выполняли зрительный Go/NoGo тест, в котором предъявляли изображения животных (Ж), растений (Р) и людей (Ч). Длительность стимула – 100 мс. Для поддержания уровня внимания, предъявление изображений людей сопровождали неожиданными звуками. Стимулы предъявляли парами: “Ж–Ж”, “Ж–Р”, “Р–Р” и “Р–Ч”, каждая пара соответствовала одной пробе. Интервал между стимулами в паре – 1 с. Длительность пробы – 3 с. Пары стимулов предъявляли равновероятно в псевдослучайном порядке. Испытуемому ставили задачу нажимать на кнопку как можно точнее и быстрей после предъявления пары “Ж–Ж”. Если испытуемый выполнял задание неправильно, то соответствующие пробы исключали из дальнейшего анализа. ПСС вычисляли методом усреднения для каждого из типов проб (условий) отдельно. Никакой дополнительной обработки, в том числе, коррекции изолинии, не выполняли.
Регистрацию ПСС проводили в соответствии с Хельсинкской декларацией о проведении исследований с участием добровольцев. Все испытуемые дали письменное согласие на участие в исследовании после ознакомления с сущностью процедуры.
Из всего множества записей ПСС (более 700) для последующего анализа отобрали те, которые удовлетворяли следующим условиям. Во-первых, использовали только те записи ПСС, для вычисления которых для каждого из 4-х условий усредняли не менее 80 проб. Это условие позволяло снизить влияние шума. Во-вторых, для того чтобы использовать параллельный факторный анализ необходимо, чтобы, по крайней мере, латентные периоды основных составляющих ПСС отличались незначительно. Результаты визуального анализа показали, что таким свойством обладают ПСС (всего 351 запись), которые записали у испытуемых в возрасте от 18 до 55 лет (150 мужчин), и которые в дальнейшем использовали в данном исследовании.
Оценку статистической значимости различий компонентов ПСС выполняли с помощью двухфакторного дисперсионного анализа для повторных измерений (с поправкой Гринхауза-Гейсера на число степеней свободы) с факторами “Условие” (3 уровня: пробы “Ж–Ж”, “Ж–Р” и “Р–Р”) и “Локализация” (19 уровней). Входными данными являлись средние величины электрических потенциалов в выбранном интервале для каждого испытуемого, условия и электрода в отдельности. Интервалы времени выбирали визуально на графиках усредненных по всем испытуемым ПСС и соответствовали эпохам, в которых исследуемые компоненты ПСС были наиболее выражены.
Для вычисления параметров CP модели использовали усредненные ПСС для каждого испытуемого в отдельности в пробах “Ж–Ж”, “Ж–Р” и “Р–Р” (C = 3) в интервале времени, начиная с момента предъявления второго стимула, длительностью 1600 мс (т.е., T = 400, поскольку частота квантования была 250 Гц). Размер тензора исходных данных Y был следующим: E = 19, TC = = 400 × 3 = 1200 и S = 351. Чтобы оптимизировать вычислительные процедуры, размерность тензора Y, описывающую сигналы, уменьшили с помощью метода главных компонент [19], оставляя 50 собственных векторов, соответствующих наибольшим собственным значениям и описывающих 96.8% дисперсии. Таким образом, после уменьшения размерности TC = 50.
Для оценки матриц в CP модели использовали метод наименьших квадратов, при этом целевая функция была следующей:
(2)
$\begin{gathered} J\left( {{{A}^{{(E)}}},{{A}^{{(TC)}}},{{A}^{{(S)}}}} \right) = \frac{1}{2}\left\| {Y - [{{A}^{{(E)}}},{{A}^{{(TC)}}},{{A}^{{(S)}}}]} \right\|_{F}^{2} + \\ + \,\,{{\Psi }^{1}}({{A}^{{(S)}}}) + {{\Psi }^{2}}({{A}^{{(S)}}}), \\ \end{gathered} $(3)
${{\Psi }^{1}}({{A}^{{(S)}}}) = - \nu \frac{1}{{ETC}}\sum\limits_{s = 1}^S {\sum\limits_{r = 1}^R {\ln \left( {{{A}_{{s,r}}}} \right)} } ,$(4)
${{\Psi }^{2}}({{A}^{{(S)}}}) = \lambda \frac{{{{\sigma }^{2}}ETC}}{2}\left\| {{\text{off}}({{{({{P}^{ \bot }}{{A}^{{(S)}}})}}^{T}}({{P}^{ \bot }}{{A}^{{(S)}}}))} \right\|_{F}^{2},$(5)
${{\varepsilon }_{{{\text{app}}}}} = {{\left\| {Y - \left[ {A{}^{{(E)}}{{A}^{{(TC)}}}{{A}^{{(S)}}}} \right]} \right\|_{F}^{2}} \mathord{\left/ {\vphantom {{\left\| {Y - \left[ {A{}^{{(E)}}{{A}^{{(TC)}}}{{A}^{{(S)}}}} \right]} \right\|_{F}^{2}} {\left\| Y \right\|_{F}^{2}}}} \right. \kern-0em} {\left\| Y \right\|_{F}^{2}}},$(6)
$rc(A) = \frac{2}{{(R - 1)R}}\sum\limits_{j = 1}^R {\sum\limits_{k = j + 1}^R {\left| {\frac{{\hat {A}_{{ \bullet ,j}}^{T}{{{\hat {A}}}_{{ \bullet ,k}}}}}{{{{{\left\| {{{{\hat {A}}}_{{ \bullet ,j}}}} \right\|}}_{F}}{{{\left\| {{{{\hat {A}}}_{{ \bullet ,k}}}} \right\|}}_{F}}}}} \right|} } ,$В том случае, когда целевая функция (2) не выпуклая, метод градиентного спуска может сходиться к разным локальным минимумам в зависимости от начального приближения. Более того, если исходные данные содержат шум, глобальный минимум целевой функции (2) не обязательно соответствует оптимальному решению. Чтобы хотя бы частично решить эту проблему, использовали следующий метод выбора наилучшей CP модели. Можно допустить, что имеются несколько CP моделей, полученных для различных случайным образом выбранных начальных приближений. Каждая из этих моделей характеризуется множеством параметров (элементов матриц A). Каждая из этих моделей соответствует точке в многомерном пространстве параметров. Можно предположить, что наилучшая модель находится вблизи центра распределения всех имеющихся моделей, и это пространство параметров однородно и изотропно. Тогда, модель, у которой среднее расстояние до всех других наименьшее, находится ближе всего к центру распределения и может считаться наилучшей. Этот подход можно формализовать.
Пусть имеется две CP модели [A(1), A(2), A(3)] и [B(1), B(2), B(3)]. Инвариантное по отношению к произвольному масштабу расстояние между соответствующими колонками матриц A(n) и B(n) может быть определено следующим образом:
(7)
$\delta (A_{{ \bullet ,r}}^{{(n)}},B_{{ \bullet ,q}}^{{(n)}}) = 1 - \frac{{\left\langle {A_{{ \bullet ,r}}^{{(n)}},B_{{ \bullet ,q}}^{{(n)}}} \right\rangle }}{{\left\| {A_{{ \bullet ,r}}^{{(n)}}} \right\|\left\| {B_{{ \bullet ,q}}^{{(n)}}} \right\|}},$Оценивали зависимость CP модели от начального приближения. Для этого, описанный выше алгоритм выбора наилучшей модели выполняли M раз (в данных исследованиях M = 5). Полученные M моделей сравнивали между собой, среди них выбирали наилучшую, и для нее вычисляли индекс надежности и его стандартное отклонение как ${{\Delta }^{{ig}}} = \frac{1}{{M - 1}}\sum\nolimits_{j = 1}^{M - 1} {{{{\hat {\Delta }}}_{{j,{\text{best}}}}}} $ и $SD({{\Delta }^{{ig}}})$ = = $\sqrt {\frac{1}{{M - 1}}\sum\nolimits_{j = 1}^{M - 1} {{{{\left( {{{{\hat {\Delta }}}_{{j,{\text{best}}}}} - {{\Delta }_{{ig}}}} \right)}}^{2}}} } .$ Кроме того, для каждой матрицы A и каждого ее столбца отдельно аналогичным образом вычисляли показатели надежности $\delta _{{r,n}}^{{ig}}$ и их стандартные отклонения SD($\delta _{{r,n}}^{{ig}}$), где r = 1, …, R и n = 1, …, 3, используя расстояние, вычисляемое в соответствие с формулой (7).
К сожалению, число мозговых процессов, отражающихся в компонентах CP модели, заранее неизвестно, и его необходимо оценить, но эта задача нетривиальная. Существующие количественные методы оценки числа компонент R в CP модели при анализе ПСС дают противоречивые результаты, на которые сложно опираться. Поэтому для определения оптимального числа компонент использовали качественные критерии. Прежде всего, с помощью критерия CORCONDIA [22] оценивали минимально возможное число компонент Rmin в CP модели. Далее, CP модели с приемлемой надежностью и числом компонент R ≥ Rmin визуально сравнивали с усредненными по всем испытуемым ПСС. Предпочтение отдавали модели с достаточным числом компонент, так чтобы в их сигналах наблюдалось большинство ранее описанных и относительно хорошо изученных особенностей ПСС.
Регистрацию ЭЭГ и анализ ПСС (исключая дисперсионный анализ) выполняли с помощью программного обеспечения WinEEG.
РЕЗУЛЬТАТЫ ИССЛЕДОВАНИЯ
Прежде всего, кратко рассмотрим свойства ПСС, наблюдаемые в зрительном Go/NoGo тесте после второго стимула. Усредненные по всем испытуемым ПСС представлены на рис. 1. На графиках ПСС с помощью стрелок отмечен ряд компонентов, которые обычно наблюдаются в этих условиях. К их числу относятся: затылочный N1 компонент (с латентностью пика порядка 160 мс), задневисочный P2 (250 мс), лобный N2 (260 мс), P3 Go (340 мс) и P3 NoGo (400 мс). Затылочный N1 компонент наиболее выражен в задних областях, а его величина больше в пробах “Ж–Ж” и “Ж–Р” (Go и NoGo условия), по сравнению с “Р–Р”. Величина задневисочного P2 компонента наибольшая в пробах “Ж–Р” (NoGo условие), и этот эффект наиболее выражен в задневисочных областях. Величина лобного N2 компонента наименьшая в пробах “Ж–Ж” (Go условие), и этот эффект наблюдается в лобно-центральных зонах. Пространственное распределение электрического потенциала для P3 Go компонента имеет максимум в теменных областях, а для P3 NoGo – в лобно-центральных. Все эти эффекты выявлены с высокой статистической значимостью (табл. 1), поскольку для анализа использовалось большая выборка (351 запись ПСС). Важно отметить, что свойства перечисленных компонентов ПСС описаны многими исследователями и изучены относительно подробно. В то же время, в ПСС наблюдается ряд других более поздних и мало изученных составляющих (рис. 1).
Рис. 1.
Усредненный по всем испытуемым ПСС. По оси абсцисс – время, по оси ординат – величина электрического потенциала. а – пробы “Ж–Ж” (Go условие), б – пробы “Ж–Р” (NoGo условие), в – пробы “P–Р”. Момент включения второго стимула в пробе – в начале координат, момент его выключения отмечен вертикальными пунктирными линиями. ВР – время реакции.
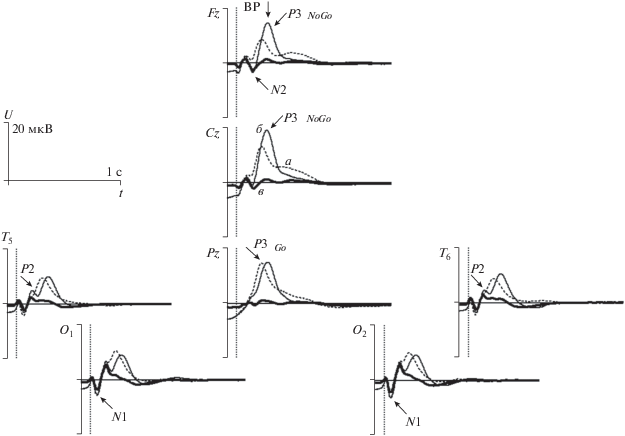
Таблица 1.
Статистическая значимость различий компонентов ПСС
| Компонент | Интервал (мс) | Основной эффект для фактора “Условие” | Взаимодействие факторов “Условие” × Локализация” | ||||
|---|---|---|---|---|---|---|---|
| F[2, 700] | ε | p | F[36, 12 600] | ε | p | ||
| N1 | 140–180 | 109.0 | 0.79 | <10–6 | 93.0 | 0.19 | <10–6 |
| P2 | 220–260 | 85.7 | 0.90 | <10–6 | 124.9 | 0.16 | <10–6 |
| N2 | 240–320 | 541.5 | 0.92 | <10–6 | 223.6 | 0.19 | <10–6 |
| P3 (Go) | 280–360 | 1018.7 | 0.98 | <10–6 | 337.6 | 0.18 | <10–6 |
| P3 (NoGo) | 360–460 | 1685.2 | 0.89 | <10–6 | 510.5 | 0.19 | <10–6 |
Далее, рассмотрим свойства CP моделей, полученных для этих исходных данных. Критерий CORCONDIA показал, что минимальное число компонент в модели Rmin должно быть равным 3 или 4, в зависимости от величины параметра регуляризации λ, влияющего на степень декорреляции столбцов матрицы A(S). Поэтому в дальнейшем рассматривались модели с числом компонент R ≥ 4. Степень декорреляции столбцов матрицы A(S) относительно мало влияет на точность описания исходных данных с помощью CP. Пример показан в табл. 2 для моделей с R = 7. Надежность оценки CP модели (индекс Δig), как правило, становится лучше с ростом величины λ, для R ≤ 7, тогда как при R > 7 это не наблюдается. Оба эти факта косвенно указывают на то, что величины компонент ПСС действительно варьируют от испытуемого к испытуемому взаимно независимо, что подтверждает справедливость предположения авторов.
Таблица 2.
Зависимость точности CP модели от степени декорреляции столбцов матрицы A(S)
| λ | (1 – εapp) × 100% | rc(A(S)) | ||
|---|---|---|---|---|
| μ | σ | μ | σ | |
| 0 | 76.9 | <0.1 | 0.493 | 0.018 |
| 10 | 76.7 | <0.1 | 0.272 | 0.015 |
| 30 | 76.5 | <0.1 | 0.129 | 0.014 |
| 100 | 76.2 | <0.1 | 0.043 | 0.003 |
| 300 | 76.1 | <0.1 | 0.013 | <0.001 |
| 1000 | 76.1 | <0.1 | 0.004 | <0.001 |
Примечание: λ – параметр регуляризации, влияющий на степень декорреляции столбцов матрицы A(S), (1 – εapp) × 100% – процент дисперсии исходных данных, описываемый CP моделью, rc(A(S)) – среднее значение модуля корреляции величин элементов в колонках матрицы A(S), μ и σ – среднее значение и среднеквадратичное отклонение.
Точность описания исходных данных с помощью CP становится больше при увеличении числа компонент R (табл. 3). Тем не менее, надежность оценки CP модели остается приемлемой только для R ≤ 7. Для этих случаев Δig ≤ 0.003 и $\delta _{{r,n}}^{{ig}}$ ≤ 0.005 для всех значений индексов r = 1, …, R и n = 1, …, 3, что подтверждает эффективность предложенного метода выбора наилучшей CP модели.
Таблица 3.
Зависимость параметров CP моделей от числа компонент
| r | (1 – εapp) × 100% | Δig | ||
|---|---|---|---|---|
| μ | σ | μ | σ | |
| 4 | 71.3 | <0.1 | 0 | <0.001 |
| 5 | 73.1 | <0.1 | 0 | 0.001 |
| 6 | 74.7 | <0.1 | 0.001 | <0.001 |
| 7 | 76.1 | <0.1 | 0.003 | 0.002 |
| 8 | 77.2 | <0.1 | 0.19 | 0.09 |
Была получена количественная оценка того, насколько CP модели лучше описывают исходные данные по сравнению с усредненными по всем испытуемым ПСС. Для этого исходные данные моделировались “CP-подобной” моделью (R = 19), в которой усредненные по всем испытуемым ПСС использовались в качестве матрицы A(TC), матрица A(E) являлась квадратной единичной матрицей, с единицами для диагональных элементов и нулями для всех остальных. Наконец, относительная величина компонент для каждого испытуемого (матрица A(S)) оценивалась методом наименьших квадратов с ограничением на неотрицательность [23]. Эта “CP-подобная” модель с числом компонент R = 19 описывала всего 65.4% дисперсии исходных данных, что заметно меньше, по сравнению с любой из CP моделей (табл. 2 и 3).
Сравнительный анализ показал, что CP модель с R = 7 удовлетворительно описывает компоненты, наблюдаемые в ПСС (рис. 2), тогда как модели с R < 7 являются слишком грубыми приближениями. Тем не менее, даже в моделях с R < 7 наблюдаются компоненты с топографиями и сигналами, похожими на те, которые показаны на рис. 2. Примером являются компоненты 3 и 5 (рис. 2), для которых аналогичные компоненты наблюдаются во всех моделях с R < 7.
Рис. 2.
Сигналы и топографии компонент в CP модели. На графиках по оси абсцисс – время, по оси ординат – величина сигнала в условных единицах (поскольку CP модель может быть оценена только с точностью до произвольного масштаба). Латентности пиков, отмеченных стрелками, – в миллисекундах. Обозначения см. рис. 1.

Сравнивая рис. 1 и 2, видно, что компоненты 7, 6 и 2 в CP модели удовлетворительно описывают свойства затылочного N1, задневисочного P2 и лобного N2 компонентов ПСС, но латентности пиков немного отличаются: 170, 230 и 290 мс. Картина выглядит сложнее для компонентов P3 Go и P3 NoGo. Они описываются с помощью компонент 1, 3, 4, 5 в CP модели, которые различаются по форме их топографий и сигналов, причем латентности “положительных” пиков находятся в интервале от 290 до 570 мс (рис. 2). При этом наблюдается весьма сложная зависимость формы сигналов этих компонент от условий (категорий проб).
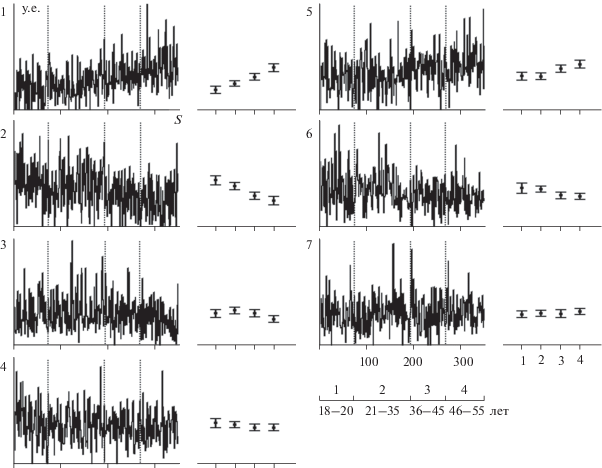
Зависимость величины компонент в CP модели от возраста испытуемых показана на рис. 3. Границы возрастных групп выбраны произвольно, но так, чтобы число испытуемых в группе не было слишком малым. Величина компонент 1 и 5 увеличивается с возрастом, тогда как у компонент 2 и 6 уменьшается. Наиболее выраженная зависимость характерна для компонент 1 и 2. В то же время, для всех компонент наблюдается значительная вариабельность их величин от испытуемого к испытуемому даже в пределах одной возрастной группы.
Рис. 3.
Зависимость величины компонент в CP модели от возраста испытуемого. На графиках по оси абсцисс – испытуемые в порядке увеличения возраста, по оси ординат – величина компоненты в условных единицах. Вертикальными пунктирными линиями отмечены границы возрастных групп (всего 4 группы). Диапазоны возрастов для каждой группы указаны справа под графиками. На диаграммах справа от графиков средние значения величины компонент (и 95% доверительные интервалы) для каждой возрастной группы.
ОБСУЖДЕНИЕ РЕЗУЛЬТАТОВ
Результаты исследований показали, что CP модели лучше описывают дисперсию исходных данных по сравнению с усредненными по всем испытуемым ПСС. Кроме того, CP модели с разной степенью декорреляции столбцов матрицы A(S) описывают исходные данные с приблизительно одинаковой точностью. Эти результаты подтверждают справедливость предположения о том, что индивидуальные величины компонент модели взаимно некоррелированы. Затылочный N1, задневисочный P2 и лобный N2, наблюдаемые в ПСС, описываются тремя разными компонентами CP модели. Четыре оставшиеся компоненты CP модели описывают P3 Go и P3 NoGo. Иными словами, в сигналах компонент CP модели отражается протекание функционально разных мозговых процессов. При этом компоненты CP модели различаются по топографиям. Как следствие, соответствующие им мозговые источники имеют разную пространственную локализацию. Все перечисленные факты указывают на то, что CP модели являются адекватными для описания ПСС.
С другой стороны необходимо подчеркнуть, что CP модели являются аппроксимацией. В частности, CP модели предполагают, что формы сигналов и топографии компонент одинаковые у всех испытуемых, а изменяются только их величины. Строго говоря, эти предположения несправедливы. Тем не менее, если предположить, что компоненты CP модели соответствуют мозговым процессам, протекающим в относительно большой области мозга, то индивидуальными вариациями положения электродов относительно источников электрического потенциала в мозге в первом приближении можно пренебречь. Также, визуальный анализ исходных данных показал, что положение и ширина полуволн индивидуальных ПСС сильно меняются в детском и пожилом возрастах, но мало различаются у испытуемых в диапазоне 18–55 лет, т.е. в том диапазоне, который был выбран в данном исследовании. И для такой группы испытуемых в первом приближении можно принять, что формы сигналов компонент одинаковы. Однако в общем случае для групп испытуемых в другом диапазоне возрастов это предположение может оказаться не справедливым, и это является ограничением на использование CP моделей.
Использование CP моделей не ограничивается только анализом ПСС, но также может найти свое применение в других областях науки, когда необходимо оценить функциональное состояние зон мозга. Действительно, CP модель обеспечивает компактное описание индивидуальных характеристик ПСС, которое при фиксированных топографиях и сигналах включает в себя только относительно небольшое число величин компонент – в данном случае 7 на каждого испытуемого. Сравнение этих величин компонент у разных групп испытуемых, в том числе пациентов, и выявление особенностей, характерных для каждой их этих групп, создает предпосылки для разработки методов объективной оценки состояния человека при различных заболеваниях нервной системы. Примером результатов, полученных с помощью такого анализа, является рис. 3, на котором иллюстрируется выявленная разнонаправленная зависимость реактивности различных зон мозга от возраста. С другой стороны, компактное представление индивидуальных характеристик ПСС с помощью CP моделей возможно будет полезным при разработке технических систем, основанных на интерфейсе мозг-компьютер.
Теперь рассмотрим кратко свойства сигналов компонент в CP модели. По крайней мере, стоит обратить внимание на три факта.
Рассматривая топографию компоненты 2, можно сделать вывод, что она описывает пространственно широко распределенный процесс. Причем только в сигналах этой компоненты наблюдается хорошо выраженный компонент N2 в NoGo условии. Иными словами, источники сигналов, отражающихся в компоненте N2, локализованы не только в лобных отделах, как это показывает анализ ПСС [24], но также могут находиться в центральных, теменных и, возможно, затылочных зонах. Однако также непротиворечивыми являются следующие возражения. Во-первых, не исключено, что пространственное разрешение использованных в работе методов недостаточно, чтобы выделить несколько составляющих с различными топографиями, описывающих компонент N2. Во-вторых, CP модель является аппроксимацией, и возможно, такое приближение оказывается слишком грубым, чтобы детально описать свойства компонента N2. Поэтому, было бы неосторожно однозначно утверждать, что компонент N2 является пространственно широко распределенным и функционально однородным процессом.
Затылочный N1 и задневисочный P2 компоненты ПСС описываются двумя различными компонентами CP модели. Однако при сравнении формы сигнала для электродов T5, T6, O1 и O2 в ПСС (рис. 1) и компонент 6 и 7 (рис. 2) CP модели, видны существенные различия. Одним из возможных объяснений этого различия является следующее. Можно представить, что компоненты 6 и 7 соответствуют различным мозговым источникам, а также, что электрические диполи этих источников имеют разную ориентацию, что подтверждается формой их топографий. При этом ориентация этих источников такова, что сигналы первого из них регистрируются как электрические потенциалы положительной полярности, а второго – отрицательной. В результате суперпозиции этих сигналов, на ПСС наблюдаются колебания электрического потенциала сложной формы с несколькими пиками положительной и отрицательной полярности, как это было описано многократно [2]. Хотя эта гипотеза непротиворечива, но, по нашему мнению, необходимы дополнительные экспериментальные данные для ее подтверждения, возможно, полученные с помощью другой методологии.
Компоненты P3 Go и P3 NoGo в CP модели описываются с помощью компонент 1, 3, 4 и 5. Причем сигналы этих компонент по-разному зависят от условий в тесте. Такие результаты позволяют сделать вывод, что P3 Go и P3 NoGo компоненты ПСС являются неоднородными, и состоят из субкомпонентов. Исследователи различных лабораторий мира, основываясь на экспериментальных данных, использующих различную методологию, уже приходили к подобному выводу. Тем не менее, дебаты о существовании и функциональной роли субкомпонентов P3 все еще продолжаются [2]. В данном случае необходимо подчеркнуть следующий факт. Сравнивая ПСС и сигналы компонент CP модели можно заметить неплохое соответствие одного другому, хотя латентности пиков все-таки различаются. Но компонента 4 выделяется из общего ряда. Основываясь только на анализе ПСС, подобный феномен трудно наблюдать, поскольку он скрыт сигналами других более мощных компонент. И, по-видимому, еще предстоит определить, действительно ли этот компонент является самостоятельным феноменом, характерным для ПСС в Go/NoGo парадигме, и какие процессы он отражает.
ВЫВОДЫ
1. Параллельный факторный анализ является адекватным подходом для исследования ПСС, позволяющим выделить такие субкомпоненты, которые скрыты от непосредственного наблюдения с помощью традиционно используемых методов.
2. Параллельный факторный анализ обеспечивает компактное представление индивидуальных особенностей ПСС, что целесообразно в различных практических областях.
3. В зрительном Go/NoGo тесте компонент P3 состоит из субкомпонентов различающихся как по форме топографий и, как следствие, локализации мозговых источников этих сигналов, так и по динамике электрического потенциала, зависящей от вида выполняемой деятельности.
Этические нормы. Все исследования проведены в соответствии с принципами биомедицинской этики, сформулированными в Хельсинкской декларации 1964 г. и ее последующих обновлениях, и одобрены Комитетом по этике Института мозга человека им. Н.П. Бехтеревой РАН (Санкт-Петербург, Россия) и Местным комитетом по этике кантона Граубюнден (округ Гризон, Швейцария).
Информированное согласие. Каждый участник исследования представил добровольное письменное информированное согласие, подписанное им после разъяснения ему потенциальных рисков и преимуществ, а также характера предстоящего исследования.
Финансирование работы. Работа поддержана РНФ (грант 16-15-10 213).
Благодарности. Авторы выражают благодарность Dr. Andreas Müller, Детский центр, г. Кур (Швейцария) за предоставленные записи ПСС в Go/NoGo тесте.
Конфликт интересов. Авторы декларируют отсутствие явных и потенциальных конфликтов интересов, связанных с публикацией данной статьи.
Список литературы
Кропотов Ю.Д. Количественная ЭЭГ, когнитивные вызванные потенциалы мозга человека и нейротерапия. Донецк: Издатель Ю.А. Заславский, 2010. 512 с.
Luck S.J., Kappenman E.S. (Eds.) The Oxford handbook of event-related potential components. Oxford: Oxford University Press. 2011. 642 p.
Nunez P.L., Srinivasan R. Electric field of the brain: The neurophysics of EEG, 2nd ed. N.Y.: Oxford Univ. Press, 2006. 612 p.
Grech R., Cassar T., Muscat J. et al. Review on solving the inverse problem in EEG source analysis // J. Neuroeng. Rehabil. 2008. V. 5. A. 25.
Wipf D., Owen J., Attias H. et al. Robust Bayesian estimation of the location, orientation, and time course of multiple correlated neural sources using MEG // Neuroimage. 2010. V. 49. P. 641.
Kamel N., Malik A.S. (Eds.) EEG/ERP Analysis: Methods and Applications. CRC Press, 2015. 320 p.
Liu K., Yu Z.L., Wu W. et al. Bayesian electromagnetic spatio-temporal imaging of extended sources with Markov Random Field and temporal basis expansion // Neuroimage. 2016. V. 139. P. 385.
Comon P., Jutten C. (Eds.) Handbook of Blind Source Separation: Independent component analysis and applications. N.Y.: Academic Press, 2010. 831 p.
Wu W., Chen Z., Gao X. et al. Probabilistic Common Spatial Patterns for Multichannel EEG Analysis // IEEE Trans. Pattern Anal. Mach. Intell. 2015. V. 37. P. 639.
Пономарев В.А., Кропотов Ю.Д. Уточнение локализации источников вызванных потенциалов в GO/NOGO тесте с помощью моделирования структуры их взаимной ковариации // Физиология человека. 2013. Т. 39. № 1. С. 36.
Kropotov J.D., Ponomarev V.A. Differentiation of neuronal operations in latent components of event-related potentials in delayed match-to-sample tasks // Psychophysiology. 2015. V. 52. P. 826.
Kropotov J., Ponomarev V., Tereshchenko E.P. et al. Effect of aging on ERP components of cognitive control // Front. Aging Neurosci. 2016. V. 8. A. 69.
Kropotov J.D., Ponomarev V.A., Pronina M., Jäncke L. Functional indexes of reactive cognitive control: ERPs in cued go/no-go tasks // Psychophysiology. 2017. V. 54. P. 1899.
Kolda T., Bader B. Tensor decompositions and applications // SIAM Review. 2009. V. 51. P. 455.
Cichocki A., Mandic D., Phan A.-H. et al. Tensor decompositions for signal processing applications from two-way to multiway component analysis // IEEE Signal Process. Mag. 2015. V. 32. P. 145.
Cong F., Lin Q.H., Kuang L.D. et al. Tensor decomposition of EEG signals: a brief review // J. Neurosci. Methods. 2015. V. 248. P. 59.
Zhou G., Zhao Q., Zhang Y. et al. Linked component analysis from matrices to high order tensors: applications to biomedical data // Proc. IEEE. 2016. V. 104. P. 310.
Vigário R.N. Extraction of ocular artefacts from EEG using independent component analysis // Electroencephalogr. Clin. Neurophysiol. 1997. V. 103. P. 395.
Comon P., Luciani X., de Almeida A.L.F. Tensor decompositions, alternating least squares and other tales // J. Chemometrics. 2009. V. 23. P. 393.
Пантелеев А.В., Летова Т.А. Методы оптимизации в примерах и задачах. 2-е изд., испр. М.: Высшая школа. 2005. 544 с.
Rajih M., Comon P., Harshman R. Enhanced Line Search: A Novel Method to Accelerate PARAFAC // SIAM J. Matrix Anal. Appl. 2008. V. 30. P. 1148.
Bro R., Kiers H.A.L. A new efficient method for determining the number of components in PARAFAC mo-dels // J. Chemometrics. 2003. V. 17. P. 274.
Bro R., De Jong S. A fast non-negativity-constrained least squares algorithm // J. Chemometrics. 1997. V. 11. P. 393.
Folstein J.R., Van Petten C. Influence of cognitive control and mismatch on the N2 component of the ERP // Psychophysiology. 2008. V. 45. P. 152.
Дополнительные материалы отсутствуют.
Инструменты
Физиология человека