

Поверхность. Рентгеновские, синхротронные и нейтронные исследования, 2023, № 3, стр. 79-86
Оптимизация реакции окисления угарного газа на поверхности наночастиц палладия методом машинного обучения с подкреплением
М. С. Лифарь a, b, А. А. Терещенко a, *, А. Н. Булгаков a, А. А. Гуда a, **, С. А. Гуда a, b, А. В. Солдатов a
a Международный исследовательский институт интеллектуальных материалов,
Южный федеральный университет
344090 Ростов-на-Дону, Россия
b Институт математики, механики и компьютерных наук им. И.И. Воровича,
Южный федеральный университет
344058 Ростов-на-Дону, Россия
* E-mail: tereshch1@gmail.com
** E-mail: guda@sfedu.ru
Поступила в редакцию 17.06.2022
После доработки 22.08.2022
Принята к публикации 22.08.2022
- EDN: LMOGVS
- DOI: 10.31857/S1028096023030081
Аннотация
Выход продуктов реакции зависит от взаимодействия между процессами на поверхности катализатора: адсорбции, активации, десорбции и других. Эти процессы, в свою очередь, зависят от величин потоков реакционных смесей, температуры и давления. В стационарных условиях активные центры на поверхности могут быть отравлены побочными продуктами реакции или заблокированы избытком адсорбированных молекул реагентов. Динамический контроль параметров реакции учитывает изменения свойств поверхности и соответствующим образом регулирует температуру, скорости потоков и другие параметры. Применен алгоритм обучения с подкреплением для управления реакцией окисления угарного газа CO на поверхности наночастиц палладия. Алгоритм был натренирован максимизировать скорость производства углекислого газа на основе информации о величинах потоков CO, O2 и CO2 на каждом временнóм шаге. Был выбран алгоритм градиентной политики с непрерывным пространством действий, и расширены наблюдения за скоростями потока на несколько последовательных временны́х шагов, что позволило получить набор нестационарных решений. Максимальный выход продукта достигается при периодическом изменении газовых потоков, обеспечивающем баланс между доступными центрами адсорбции и концентрацией активированных интермедиатов. Эта методология открывает перспективы для оптимизации каталитических реакций в нестационарных условиях.
ВВЕДЕНИЕ
Наночастицы благородных металлов, в частности палладия, – известные катализаторы множества химических реакций окисления [1] и восстановления [2]. Их каталитическая активность помимо размера частиц [3] и материала подложки [4] также во многом определяется и формой наночастиц [5–8]. В стационарных условиях протекания реакции поверхность катализатора может деградировать за счет формирования оксидов [9], карбидов [10] или адсорбированных молекул с большой энергией связи [11].
Для замедления процесса формирования вторичных фаз на поверхности и повышения активности катализатора условия протекания реакции можно изменять динамически [12]. Например, при проведении каталитического циклирования на отдельной стадии цикла поверхность катализатора может быть принудительно очищена от нежелательных продуктов и, таким образом, осуществлена ее регенерация для лучшего заселения желательными реагентами на других стадиях [13]. Использование внешних возмущений может привести к большему преимуществу динамического режима по сравнению со стационарным, что используется для разработки нестационарных реакторов с лучшими характеристиками. В частности, модуляции реакции монооксида углерода на поверхности нанокатализаторов благородных металлов представляют особый интерес, и их интенсивно изучают: это не только распространенная модельная реакция для фундаментальных исследований в области гетерогенного катализа [14–18], но и широко используемый в настоящее время процесс в автомобильных каталитических конвертерах. Там трехходовые катализаторы периодически подвергаются окислительному (воздушный реактор) и восстановительному (топливный реактор) режимам, и такое циклирование позволяет резко увеличить эффективность итоговой конверсии СО в СО2 [19–21].
Поиск оптимальных реакционных условий является сложной задачей даже для стационарных режимов и значительно усложняется в случае динамически изменяющихся параметров. Одним из перспективных подходов для решения данной задачи является использование машинного обучения [22, 23] и, в частности, обучения с подкреплением (известного в зарубежной литературе как Reinforcement Learning) [24–26] для прогнозирования наилучшего динамического режима и условий протекания каталитических реакций. Недавно в [27] обосновали концепцию использования машинного обучения с подкреплением для оптимизации выхода водорода в реакции частичного окисления метана. С этой целью они обучили агентов Q-обучения [28, 29] и градиента глубокой детерминированной политики [30] для прогнозирования производства водорода путем регулирования температуры, давления, скорости потока и состава подложки в смоделированном реакторе идеального вытеснения. Авторы [31] продемонстрировали применимость машинного обучения с подкреплением в сочетании с прогностическим контролем экономической модели для производства оксида этилена. Также, используя глубокое обучение с подкреплением, ранее оптимизировали различные микрокапельные химические реакции, например синтез изохинолина, замещенного хинолина и рибозофосфата [32]. В результате данный подход позволил уточнить оптимальные экспериментальные условия, что дало возможность увеличить скорость протекания реакций. В настоящей работе проведена оптимизация параметров реакции окисления СО, протекающей на поверхности наночастиц Pd, с использованием подхода машинного обучения с подкреплением.
ЭКСПЕРИМЕНТАЛЬНАЯ ЧАСТЬ
Алгоритм обучения с подкреплением требует много пробных шагов для обучения. Испытания выполняют последовательно для разных значений параметров, выбираемых алгоритмом, и таким образом покрывают важные области пространства параметров реакции. Этот подход отличается от машинного обучения с учителем (известного в зарубежной литературе как Supervised Machine Learning), когда весь набор испытаний передается алгоритму пользователем. В этом разделе опишем математическую модель реакции окисления СО, основанную на системе дифференциальных уравнений, которая служит средой для обучения алгоритма.
Схема реакции окисления CO на Pd может быть описана уравнением:
Окисление CO на наночастицах Pd можно разделить на четыре элементарных этапа по механизму Ленгмюра–Хиншельвуда [33, 34]:(2)
${\text{CO}} + {\text{Pd*}}\xrightarrow{{{{k}_{{\text{1}}}}}}{\text{C}}{{{\text{O}}}_{{{\text{Pd}}}}},$(3)
${\text{C}}{{{\text{O}}}_{{{\text{Pd}}}}}\xrightarrow{{{{k}_{{\text{2}}}}}}{\text{CO}} + {\text{Pd*}},$(4)
${{{\text{O}}}_{2}} + 2{\text{Pd*}}\xrightarrow{{{{k}_{{\text{3}}}}}}2{{{\text{O}}}_{{{\text{Pd}}}}},$(5)
${\text{C}}{{{\text{O}}}_{{{\text{Pd}}}}} + {{{\text{O}}}_{{{\text{Pd}}}}}\xrightarrow{{{{k}_{{\text{4}}}}}}{\text{C}}{{{\text{O}}}_{2}} + 2{\text{Pd*}},$(7)
${{k}_{2}} = {{\nu }_{2}}{\kern 1pt} {\text{exp}}\left( { - \frac{{{{E}_{2}}}}{{{{k}_{{\text{B}}}}T}}} \right),$(9)
${{k}_{4}} = {{\nu }_{4}}{\kern 1pt} {\text{exp}}\left( { - \frac{{{{E}_{4}}}}{{{{k}_{{\text{B}}}}T}}} \right),$(10)
$k_{4}^{'} = \left\{ {\begin{array}{*{20}{c}} {{{k}_{4}} + {{k}_{4}}{{V}_{{\text{d}}}}\left( {0.25 - \frac{{{{P}_{{{{{\text{O}}}_{2}}}}}}}{{{{P}_{{{\text{CO}}}}}}}} \right)\Delta t,\,\,\,\,~\frac{{{{P}_{{{{{\text{O}}}_{2}}}}}}}{{{{P}_{{{\text{CO}}}}}}} > 0.25~~~~~~~~~} \\ {{{k}_{4}} + (1 - {{k}_{4}}){{V}_{{\text{r}}}}\left( {0.25 - \frac{{{{P}_{{{{{\text{O}}}_{2}}}}}}}{{{{P}_{{{\text{CO}}}}}}}} \right)\Delta t,\,\,\,\,~\frac{{{{P}_{{{{{\text{O}}}_{2}}}}}}}{{{{P}_{{{\text{CO}}}}}}} \leqslant 0.25.~} \end{array}} \right.$(11)
${{F}_{{{\text{CO}}}}} = \frac{{{{P}_{{{\text{CO}}}}}}}{{\sqrt {\frac{{2\pi {{M}_{{{\text{CO}}}}}}}{{{{N}_{{\text{A}}}}{{k}_{{\text{B}}}}T}}} }},$(12)
${{F}_{{{{{\text{O}}}_{2}}}}} = \frac{{{{P}_{{{{{\text{O}}}_{2}}}}}}}{{\sqrt {\frac{{2\pi {{M}_{{{{{\text{O}}}_{2}}}}}}}{{{{N}_{{\text{A}}}}{{k}_{{\text{B}}}}T}}} }},$(13)
$\frac{{d{{\theta }_{{{\text{CO}}}}}}}{{dt}} = {{k}_{1}}{{S}_{{{\text{CO}}}}} - {{k}_{2}}{{\theta }_{{{\text{CO}}}}} - {{k}_{4}}{{\theta }_{{{\text{CO}}}}}{{\theta }_{{\text{O}}}},$(14)
$\frac{{d{{\theta }_{{\text{O}}}}}}{{dt}} = 2{{k}_{3}}{{S}_{{{{{\text{O}}}_{2}}}}} - {{k}_{4}}{{\theta }_{{{\text{CO}}}}}{{\theta }_{{\text{O}}}},$(15)
${{S}_{{{\text{CO}}}}} = S_{{{\text{CO}}}}^{0}\left( {1 - \frac{{{{\theta }_{{{\text{CO\;}}}}}}}{{{{\theta }_{{\text{\;}}}}_{{{\text{CO}}}}^{{{\text{max}}}}}} - {{C}_{T}}\frac{{{{\theta }_{{{\text{O\;}}}}}}}{{{{\theta }_{~}}_{{\text{O}}}^{{{\text{max}}}}}}} \right),$(16)
${{S}_{{{{{\text{O}}}_{2}}}}} = \left\{ \begin{gathered} S_{{{{{\text{O}}}_{2}}}}^{0}{\kern 1pt} {{\left( {1 - \frac{{{{\theta }_{{{\text{CO\;}}}}}}}{{{{\theta }_{{\text{\;}}}}_{{{\text{CO}}}}^{{{\text{max}}}}}} - \frac{{{{\theta }_{{{\text{O\;}}}}}}}{{{{\theta }_{~}}_{{\text{O}}}^{{{\text{max}}}}}}} \right)}^{2}}{\kern 1pt} ,\,\,\,\,1 - \frac{{{{\theta }_{{{\text{CO\;}}}}}}}{{{{\theta }_{{\text{\;}}}}_{{{\text{CO}}}}^{{{\text{max}}}}}} - \frac{{{{\theta }_{{{\text{O\;}}}}}}}{{{{\theta }_{~}}_{{\text{O}}}^{{{\text{max}}}}}} \geqslant 0, \hfill \\ 0;\,\,~1 - \frac{{{{\theta }_{{{\text{CO\;}}}}}}}{{{{\theta }_{~}}_{{{\text{CO}}}}^{{{\text{max}}}}}} - \frac{{{{\theta }_{{{\text{O\;}}}}}}}{{{{\theta }_{{\text{\;}}}}_{{\text{O}}}^{{{\text{max}}}}}} < 0,~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ \hfill \\ \end{gathered} \right.$РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Ключевыми параметра алгоритма обучения с подкреплением являются среда и агент. Агент выполняет действия на основе политики, задаваемой нейронной сетью, которая получает на вход значения наблюдаемых параметров из среды и на выходе выдает действия. Был использован алгоритм градиентной политики Vanilla Policy Gradient (VPG) с непрерывными значениями действий. Политика алгоритма обновлялась итерационно в ходе обучения на модели, построенной на основе дифференциальных уравнений. Целью обучения была максимизация интегрального значения награды в изменяющихся условиях среды. Модель и обучение были запрограммированы на языке Python с использованием библиотеки Tensorforce и фреймворка Tensorflow. При оптимизации коэффициентов нейронной сети использовали скорость обучения 0.001. На входы нейронной сети подавали нормированные значения потоков газов, приведенные к диапазону [0; 1]. Схема работы алгоритма показана на рис. 1.
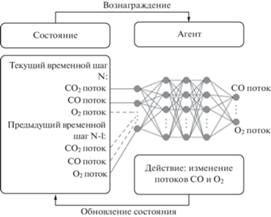
Алгоритм VPG обучения с подкреплением относится к классу алгоритмов on-policy, т.е. алгоритмов, которые оптимизируют политику агента, базируясь только на информации, полученной в ходе использования текущей политики. Политика – функция, определяющая, какое действие будет выбирать алгоритм исходя из текущего состояния системы. Обучение агента происходит в течение большого числа эпизодов обучения. Алгоритм в течение эпизода длительностью 500 с применяет политику, запрограммированную в виде нейронной сети. Задача по нахождению агентом оптимальной политики сводится к оптимизации параметров политики – весов нейронной сети. Действие агента в настоящей работе заключается в изменении потоков CO и O2 каждые 10 с произвольным образом в пределах заданного диапазона. На вход нейронной сети подают нормированные значения потоков CO, O2 и CO2 на текущем шаге и (опционально) значения соответствующих потоков на одном или двух предыдущих шагах обучения. На выходе считывали новые значения потоков CO и O2. По окончанию эпохи обучения коэффициенты нейронной сети обновляются согласно правилу:
(18)
${{\theta }_{{k{\kern 1pt} + {\kern 1pt} 1}}} = {{\theta }_{k}} + {{\left. {\alpha {{\nabla }_{\theta }}\left( {J\left( {{{\pi }_{\theta }}} \right)} \right)} \right|}_{{\theta k}}}{\kern 1pt} ,$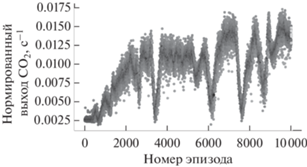
Чтобы оценить эффективность решений, найденных алгоритмом обучения с подкреплением, было проведено сравнение их с решениями, найденными иным методом. Рассматривали суммарный выход CO2 за эпизод как функцию от потоков O2(t) и CO(t): R = R(O2(t), CO(t)). Далее рассматривали только стационарные решения, т.е. такие, что O2(t) = O2 = const, CO(t) = CO = const. Затем максимизировали R как функцию двух вещественных переменных, используя метод Нелдера–Мида, или симплекс-метод [36]. Полученное стационарное решение использовали для сравнения с решением, найденным обучением с подкреплением.
В табл. 1 собраны результаты тренировки в течение 10 000 эпизодов для разных комбинаций. Как видно, наилучшее качество обучения было достигнуто при использовании информации о потоках газов на протяжении трех последних шагов по времени. После тренировки алгоритм можно применять для оптимального управления экспериментальной установкой синтеза. На рис. 3 показаны результаты найденной политики для уравнений (1)–(3) со случайными начальными условиями, полученными с помощью оптимизации (рис. 3а), и политика, найденная алгоритмом обучения с подкреплением (рис. 3б) соответственно с использованием модели без учета деградации.
Таблица 1.
Выбор состояния для тренировки алгоритма и интегральный выход продуктов реакции за одну эпоху
| Состояние | Выход продуктов реакции за эпоху, отн. ед. |
|---|---|
| Потоки газов на текущем шаге по времени: Obs0 = (CO, O2, CO2) | 8.54 |
| Потоки газов на текущем и предыдущем шаге по времени: Obs0, Obs1 | 9.35 |
| Потоки газов на трех последующих шагах по времени: Obs0, Obs1, Obs2 | 10.16 |
Рис. 3.
Решение: а, б – стационарное, найденное методом оптимизации; в, г – полученное с помощью алгоритма обучения с подкреплением. В обоих случаях использованы модели без учета деградации поверхности катализатора. Показаны задаваемые потоки СО и О2 (предсказанные политики) (а, в) и соответствующий им выход СО2 (б, г).
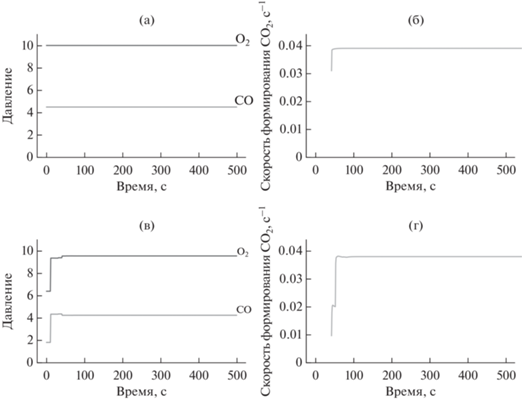
Из рисунков видно, что при отсутствии в модели учета деградации катализатора алгоритм находит стационарное решение с фиксированными потоками газов, близкое к найденному оптимизацией, с соотношением потоков CO : O2 около 0.446. Схождение алгоритма к постоянному решению можно объяснить тем, что доля поверхности, доступной для протекания реакции CO + O2, остается неизменной в процессе синтеза и близкой к оптимальной. В данном случае периодическая реактивация поверхности катализатора повышенным потоком кислорода не приведет к увеличению выхода CO2.
На рис. 4 приведены решения, полученные для моделей с учетом деградации: стационарное решение, найденное с помощью оптимизации (рис. 4а), и решение, найденное алгоритмом обучения с подкреплением (рис. 4б). Сравнение выхода CO2 показывает, что для модели с учетом деградации алгоритм смог найти динамическое решение, которое обеспечивает значительно больший выход CO2.
Рис. 4.
Решение: а, б – стационарное, найденное методом оптимизации; в, г – динамическое, полученное с помощью алгоритма обучения с подкреплением. В обоих случаях использованы модели с учетом деградации поверхности катализатора. Показаны предсказанные политики (а, в) и выход СО2 (б, г).
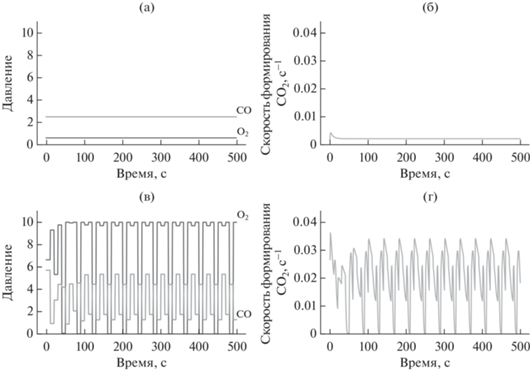
При длительном нахождении катализатора палладия в атмосфере с неравновесным содержанием кислорода или монооксида углерода может образовываться фаза карбида или оксида, которая ухудшает каталитические свойства поверхности. В частности, возможно уменьшение доли поверхности, доступной для протекания реакции CO + O2, и увеличение энергетического барьера этой реакции. Это объясняет, почему алгоритм предпочел периодическое уменьшение потоков CO и O2 в противофазе, при котором примесная фаза на поверхности не успевает сформироваться и разрушается в избытке кислорода, вследствие чего интегральный выход CO2 увеличивается.
Полученные результаты согласуются с экспериментальными данными. Как было показано ранее [37–39], переход от статических условий к динамическим может значительно ускорить протекание реакции. Например, в работе [40], описывающей окисление СО на Pd/Al2O3, периодическое переключение подачи между CO/N2 и O2/N2 позволило добиться усредненной скорости реакции, которая более чем в 40 раз превышала максимально достижимую скорость в стационарном режиме.
ЗАКЛЮЧЕНИЕ
Алгоритм обучения с подкреплением был применен для исследования пространства рабочих параметров реакции окисления CO. Агент градиента политики VPG получал на вход потоки CO, O2 и CO2 на текущем и предыдущем временны́х шагах и предсказывал оптимальные потоки CO и O2 на следующем шаге. Обучение алгоритма проводилось на модели реакции окисления монооксида углерода на поверхности палладия как без учета, так и с учетом деградации поверхности в неравновесных потоках реагентов. В результате исследования были получены стационарные политики и политики периодического переключения. Максимальный выход продукта был достигнут при использовании модели с учетом деградации катализатора при периодическом изменении газовых потоков, обеспечивающих баланс между доступными адсорбционными участками и концентрацией активированных промежуточных продуктов. Продемонстрированный подход может быть расширен для оптимизации многих других промышленно значимых реакций и каталитических систем.
Список литературы
Pakhare D., Spivey J. // Chem. Soc. Rev. 2014. V. 43. № 22. P. 7813. https://doi.org/10.1039/C3CS60395D
Pareek V., Bhargava A., Gupta R., Jain N., Panwar J. // Adv. Sci. Eng. Med. 2017. V. 9. № 7. P. 527. https://doi.org/10.1166/asem.2017.2027
Kinoshita K. // J. Electrochem. Soc. 1990. V. 137. № 3. P. 845. https://doi.org/10.1149/1.2086566
Rojluechai S., Chavadej S., Schwank J.W., Meeyoo V. // Catal. Commun. 2007. V. 8. № 1. P. 57. https://doi.org/10.1016/j.catcom.2006.05.029
DeSantis C.J., Peverly A.A., Peters D.G., Skrabalak S.E. // Nano Lett. 2011. V. 11. № 5. P. 2164. https://doi.org/10.1021/nl200824p
Sun C., Cao Z., Wang J., Lin L., Xie X. // New J. Chem. 2019. V. 43. № 6. P. 2567. https://doi.org/10.1039/C8NJ05152F
Vatti S.K., Ramaswamy K.K., Balasubramanaian V. // J. Adv. Nanomat. 2017. V. 2. № 1. P. 127. https://doi.org/10.22606/jan.2017.22006
Cuenya B.R. // Thin Solid Films. 2010. V. 518. № 12. P. 3127. https://doi.org/10.1016/j.tsf.2010.01.018
Schalow T., Brandt B., Laurin M., Schauermann S., Libuda J., Freund H.J. // J. Catal. 2006. V. 242. № 1. P. 58. https://doi.org/10.1016/j.jcat.2006.05.021
Skorynina A., Tereshchenko A., Usoltsev O., Bugaev A., Lomachenko K., Guda A., Groppo E., Pellegrini R., Lamberti C., Soldatov A. // Rad. Phys. Chem. 2018. V. 175. № 1. P. 108079. https://doi.org/10.1016/j.radphyschem.2018.11.033
Albers P., Pietsch J., Parker S.F. // J. Mol. Catal. A. 2001. V. 173. № 1–2. P. 275. https://doi.org/10.1016/S1381-1169(01)00154-6
Gromotka Z., Yablonsky G., Ostrovskii N., Constales D. // Entropy. 2021. V. 23. № 7. P. 818. https://doi.org/10.3390/e23070818
Armstrong C.D., Teixeira A.R. // React. Chem. Eng. 2020. V. 5. № 12. P. 2185. https://doi.org/10.1039/D0RE00330A
Cutlip M., Hawkins C., Mukesh D., Morton W., Kenney C. // Chem. Eng. Commun. 1983. V. 22. № 5–6. P. 329.https://doi.org/10.1080/00986448308940066
Vaporciyan G., Annapragada A., Gulari E. // Chem. Eng. Sci. 1988. V. 43. № 11. P. 2957. https://doi.org/10.1016/0009-2509(88)80049-6
Schwankner R., Eiswirth M., Möller P., Wetzl K., Ertl G. // J. Chem. Phys. 1987. V. 87. № 1. P. 742. https://doi.org/10.1063/1.453572
Eiswirth M., Ertl G. // Phys. Rev. Lett. 1988. V. 60. № 15. P. 1526. https://doi.org/10.1103/PhysRevLett.60.1526
Newton M.A., Ferri D., Smolentsev G., Marchionni V., Nachtegaal M. // Nat. Commun. 2015. V. 6. № 1. P. 8675. https://doi.org/10.1038/ncomms9675
Fang H., Haibin L., Zengli Z. // Int. J. Chem. Eng. 2009. V. 2009. № 1. P. 710515. https://doi.org/10.1155/2009/710515
Moghtaderi B. // Energy Fuels. 2012. V. 26. № 1. P. 15. https://doi.org/10.1021/ef201303d
Yoshida H., Kakei R., Fujiwara A., Tomita A., Miki T., Machida M. // Top Catal. 2019. V. 62. № 1. P. 345. https://doi.org/10.1007/s11244-018-1100-5
Toyao T., Maeno Z., Takakusagi S., Kamachi T., Takigawa I., Shimizu K.-I. // ACS Catal. 2019. V. 10. № 3. P. 2260. https://doi.org/10.1021/acscatal.9b04186
Segler M.H.S., Preuss M., Waller M.P. // Nature. 2018. V. 555. № 7698. P. 604. https://doi.org/10.1038/nature25978
Kaelbling L.P., Littman M.L., Moore A.W. // J. Artif. Intell. Res. 1996. V. 4. P. 237. https://doi.org/10.1613/jair.301
Sutton R.S., Barto A.G. Introduction to Reinforcement Learning. Cambridge: MIT Press, 1998. P. 380.
Littman M.L. // Nature. 2015. V. 521. № 7553. P. 445. https://doi.org/10.1038/nature14540
Neumann M., Palkovits D.S. // Ind. Eng. Chem. Res. 2022. V. 61. № 11. P. 3910. https://doi.org/10.1021/acs.iecr.1c04622
Watkins C.J. Learning from Delayed Rewards: PhD Thesis. Cambridge: King’s Colledge, 1989. 242 p.
Watkins C.J., Dayan P. // Mach. Learn. 1992. V. 8. № 3. P. 279. https://doi.org/10.1007/BF00992698
Lillicrap T.P., Hunt J.J., Pritzel A., Heess N., Erez T., Tassa Y., Silver D., Wierstra D. Continuous Control with Deep Reinforcement Learning; https://arxiv.org/ abs/1509.02971.pdf.
Alhazmi K., Albalawi F., Sarathy S.M. // Chem. Eng. J. 2022. V. 428. P. 130993. https://doi.org/10.1016/j.cej.2021.130993
Zhou Z., Li X., Zare R.N. // ACS Cent. Sci. 2017. V. 3. № 12. P. 1337. https://doi.org/10.1021/acscentsci.7b00492
Engel T., Ertl G. // Elementary Steps in the Catalytic Oxidation of Carbon Monoxide on Platinum Metals. Munchen: Elsevier, 1979. P. 43.
Chorkendorff I., Niemantsverdriet J.W. // Concepts of Modern Catalysis and Kinetics. Weinheim: John Wiley & Sons, 2017. P. 66.
Libuda J., Meusel I., Hoffmann J., Hartmann J., Piccolo L., Henry C., Freund H.-J. // J. Chem. Phys. 2001. V. 114. № 10. P. 4669.
Nelder J.A., Mead R. // The Comput. J. 1965. V. 7. № 4. P. 308. https://doi.org/10.1093/comjnl/7.4.308
Unni M., Hudgins R., Silveston P. // Can. J. Chem. Eng. 1973. V. 51. № 6. P. 623. https://doi.org/10.1002/cjce.5450510601
Abdul-Kareem H.K., Silveston P., Hudgins R. // Chem. Eng. Sci. 1980. V. 35. № 10. P. 2077. https://doi.org/10.1016/0009-2509(80)85029-9
Abdul-Kareem H.K., Hudgins R., Silveston P. // Chem. Eng. Sci. 1980. V. 35. № 10. P. 2085. https://doi.org/10.1016/0009-2509(80)85030-5
Zhou X., Barshad Y., Gulari E. // Chem. Eng. Sci. 1986. V. 41. № 5. P. 1277. https://doi.org/10.1016/0009-2509(86)87100-7
Дополнительные материалы отсутствуют.
Инструменты
Поверхность. Рентгеновские, синхротронные и нейтронные исследования