

Программирование, 2021, № 6, стр. 16-29
БЫСТРЫЙ АЛГОРИТМ ПОИСКА РАСПРЕДЕЛЕННЫХ РАССЕИВАТЕЛЕЙ SQUEESAR В ЗАДАЧЕ ПОСТРОЕНИЯ СКОРОСТЕЙ СМЕЩЕНИЙ ЗЕМНОЙ ПОВЕРХНОСТИ
С. Е. Попов a, *, В. П. Потапов a, **
a Федеральное государственное бюджетное научное учреждение
“Федеральный исследовательский центр информационных и вычислительных технологий”
630090 Новосибирск, пр. Академика Лаврентьева, 6, Россия
* E-mail: popov@ict.sbras.ru
** E-mail: vadimptpv@gmail.com
Поступила в редакцию 23.12.2020
После доработки 27.04.2021
Принята к публикации 15.06.2021
Аннотация
В статье описывается программная реализация быстрого алгоритма поиска распределенных рассеивателей для задачи построения скоростей смещений земной поверхности на базе платформы Apache Spark. Рассматривается полная схема расчета скоростей смещений методом постоянных рассеивателей (PS). Предложенный алгоритм интегрируется в схему после этапа совмещения с субпиксельной точностью стека изображений временной серии радарных снимков космического аппарата Sentinel-1. Поиск распределенных рассеивателей происходит независимо в окнах сдвига по всей площади снимка. Наличие последних определяется путем предположения о гомогенности пар выборок в окне, составленных из векторов комплексных значений пикселей в каждом из N изображений. Данное предположение вытекает из выполнимости критерия Колмогорова–Смирнова для каждой из пар. Для оценки значений фаз гомогенных пикселей решается задача максимизации. Показано, что предложенный алгоритм не является итерационным и может быть реализован в парадигме параллельных вычислений. Применяемая платформа Apache Spark позволила распределенно обрабатывать массивы стека радарных данных (от 60 изображений) в памяти на большом количестве физических узлов в сетевой среде. При этом, время поиска распределенных рассеивателей удалось снизить в среднем в 10 раз по сравнению с однопроцессорной реализацией алгоритма. Приведены сравнительные результаты тестирования вычислительной системы на демонстрационном кластере. Алгоритм реализован на языке программирования Python c подробным описанием объектов и методов алгоритма.
1. ВВЕДЕНИЕ
Основная ценность космической информации, поступающей при мониторинге земной поверхности, зачастую, заключается в возможности ее оперативного анализа. Поэтому, активное развитие методов дифференциальной интерферометрии и средств дистанционного зондирования кроме совершенствования аппаратной части спутников, также требует создания проблемно-ориентированных алгоритмов для автоматизированной и оперативной обработки большого объема радарных данных. Для стандартного в радарной интерферометрии аналитического аппарата DInSAR [1] для оценки скоростей смещений земной поверхности широкое распространение получил метод постоянных отражателей (Persistent Scatterer, PS) [2]. PS направлен на идентификацию когерентных радиолокационных целей, демонстрирующих высокую фазовую стабильность в течение всего периода наблюдения. Эти цели (пиксели изображения), на которые лишь незначительно влияет временная и геометрическая декорреляция, часто соответствуют точечным рассеивателям и обычно характеризуются высокими значениями отражательной способности [3]. В работах [4, 5 и др.] показано, что эти пиксели также соответствуют пикселям изображения, принадлежащим областям умеренной когерентности в некоторых интерферометрических парах доступного набора данных. Здесь многие соседние пиксели имеют одинаковые значения отражательной способности, поскольку они принадлежат к одному объекту. Эти цели, называемые распределенными рассеивателями (Distributed Scatterers (DS)), обычно соответствуют участкам небольших строений, необрабатываемых земель с короткой растительностью, промышленному мусору, металлическим завалам или пустынным территориям. Хотя средняя временная когерентность этих естественных радиолокационных целей обычно низкая из-за явлений как временной, так и геометрической декорреляции, количество пикселей с одинаковым статистическим поведением может быть достаточно большим, чтобы некоторые из них могли превысить порог когерентности и стать постоянными рассеивателями.
В работах [4–6] описывается решение актуальной задачи слияния данных для правильного объединения рассеивателей PS и DS для увеличения плотности точек измерения. Это позволяет увеличить пространственную плотность точек областей, характеризующимися DS при сохранении высококачественной информации, полученной с помощью метода PS по детерминированным целям. Данные пространственно усредняются по статистически однородным областям, увеличивая отношение сигнал/шум (SNR), без ущерба для идентификации когерентных точечных рассеивателей. Данный алгоритм назван SqueeSAR [7, 8]. Он позволяет проводить поиск и обработку точек распределённых рассеивателей, интегрируя их в общую схему расчета скоростей смещений методом PS.
Тщательный анализ алгоритма SqueeSAR выявил места, критически влияющие на его производительность. Весь алгоритм строится на переборе начальных данных. На каждом шаге выполняются нетривиальные преобразования данных. Так, например, ощутимо сложными в плане вычислительных затрат оказались этапы поиска смежных точек в окне сдвига и решение задачи максимизации при оценке реальных значений интерферометрических фаз [9]. Кроме того, при уменьшении размеров окна, увеличивалось общее количество шагов проходки по всей площади снимка.
Для устранения выявленных проблем вычислительного характера было предложено использование платформы массово-параллельных вычислений Apache Spark [10]. Apache Spark – это фреймворк с открытым исходным кодом для распределённой пакетной и потоковой обработки неструктурированных и слабоструктурированных данных, входящий в экосистему проектов Hadoop. В отличие от классического обработчика ядра Apache Hadoop c двухуровневой концепцией MapReduce на базе дискового хранилища, Spark использует специализированные примитивы (Resilient Distributed Data) для рекуррентной обработки в оперативной памяти. Благодаря этому появляется возможность многократного доступа к загруженным в память радарным данным с каждого узла кластера. Это позволяет логически разделять стек снимков на подобласти и проводить вычисления независимо.
Целью данной работы является разработка высокопроизводительного алгоритма поиска распределенных рассеивателей для математической модели SqueeSAR.
Для выполнения поставленной цели предлагается решение следующих задач:
1. Разработка программного алгоритма на основе математической модели SqueeSAR на базе открытых библиотек с возможностью его интеграции в схему расчета скоростей смещений методом постоянных отражателей.
2. Адаптация представленного алгоритма для запуска его в среде массово-параллельного исполнения заданий.
2. МАТЕМАТИЧЕСКАЯ МОДЕЛЬ АЛГОРИТМА SqueeSAR
Алгоритм SqueeSAR базируется на идее поиска статистически однородных пикселей, в результате чего выявляются подмножества точечных, распределенных рассеивателей, и выполняется пространственно-адаптивная фильтрация последних. Вследствие чего резко возрастает суммарный набор постоянных отражателей, что позволяет повысить эффективность решения задач дифференциальной радарной интерферометрии [9]. Алгоритм состоит из следующих этапов [11]:
1. Определение статистически однородных точек (Statistically Homogeneous Pixels – SHP) по всей площади стека интерферометрических изображений.
2. Формирование наборов распределенных рассеивателей путем фильтрации по количественному порогу SHP-пикселей.
3. Поиск для каждого DS-набора уточненных (оценка) значений интерферометрической фазы SHP-пикселей, используя специальную матрицу когерентности, и решение на ее основе задачи максимизации.
4. Фильтрация полученных уточненных интерферометрических фаз пикселей DS-набора на основе оценки параметра ${{\gamma }_{{PTA}}}$.
5. Замена значений первоначальных фаз в интерферометрическом стеке их уточненными значениями. Модифицированные изображения далее участвуют в процессе обработки методом постоянных рассеивателей [2].
Будем рассматривать стек из $N$ совмещенных с субпиксельной точностью радарных изображений длинной временной серии (от 60 снимков). Здесь субпиксельная точность означает, что любая произвольно взятая точка на мастер-изображении будет иметь абсолютно одинаковые географические координаты и на N–1 подчиненных изображениях (рис. 1). Обозначим W и H ширину и высоту изображений в пикселях, соответственно.
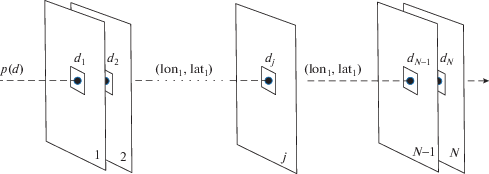
Делается предположение, что данные радарных изображений и рассчитываемые на их основе геофизические параметры являются общими для каждой статистически однородной выборки близлежащих пикселей. В соответствии с этим предположением однородность (гомогенность) пикселей оценивается в пределах заданного окна размером $mxn$ (обычно 21 × 15 пикселей). Сдвиг окна происходит по ширине и высоте изображения с шагом равным ширине и высоте окна.
На каждом шаге выбирается центральный пиксель p0 в окне сдвига. Так как на изображениях каждый пиксель характеризуется комплексным представлением (каналами I и Q, для данных Sentinel-1), то можно сформировать вектор комплексных чисел d в стеке из N изображений (1)
(1)
${{d}_{k}} = {{\left[ {{{d}_{{k,1}}},{{d}_{{k,2}}} \ldots {{d}_{{k,N}}}} \right]}^{T}}{\text{,}}$Два пикселя p0 и pk в окне будем считать однородными если для них выполняется тест Колмогорова–Смирнова. Каждая пара пикселей (p0, ${{p}_{k}}$) рассматривается как две независимые выборки $\left| {{{p}_{0}}({{d}_{j}})} \right|$ и $\left| {{{p}_{k}}({{d}_{j}})} \right|$, где $k = 1 \ldots mxn$, $\left| {{{p}_{k}}({{d}_{j}})} \right|$ = [|dk, 1|, |dk, 2|, $ \ldots \left| {{{d}_{{k,N}}}} \right|{{]}^{T}}$, |*| – модуль комплексного числа. Здесь тест Колмогорова–Смирнова выполняется следующим образом:
1. Выдвигаются две гипотезы: H0 – различия между двумя выборками недостоверны, H1 – противоположная (различия между выборками достоверны), соответственно для заданного уровня значимости $\alpha $.
2. Строится частотное распределение каждой выборки.
3. Вычисляются относительные частоты, равные частному от деления частот на объём выборки, для каждой из имеющихся выборок.
4. Определяется модуль разности соответствующих относительных частот.
5. Определяется наибольший модуль ${{D}_{{max}}}$.
6. Вычисляется эмпирическое значение критерия ${{\lambda }_{{emp}}}$.
7. Определяется критическое значение критерия для выбранного уровня значимости $\alpha = 0.05$.
8. Если эмпирическое значение критерия меньше критического, то нулевая гипотеза принимается, и выборки по рассмотренному признаку не отличаются существенно, т.е. пара пикселей считается однородной.
В получившемся наборе пикселей, прошедших тест, отбрасываются те пиксели, которые не являются смежными с центральным (p0) либо напрямую, либо через соседние (рис. 2).
Рис. 2.
Вариант расположения пикселей в наборе DS. Белые пиксели не являются гомогенными с центральным, заштрихованные пиксели прошли тест Колмогорова–Смирного и являются гомогенными с центральным.
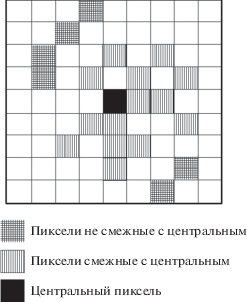
Оставшиеся пиксели (обозначим их количество параметром ${{N}_{{ds}}}$) образуют DS-набор. Если параметр ${{N}_{{ds}}}$ меньше порогового значения (${{N}_{p}}$ = 20), то такой набор не принимается. Таким образом, при проходе всего снимка образуются наборы распределенных рассеивателей. В каждом корректном DS-наборе (2) для центрального пикселя p0 выполняется процедура уточнения значения его “свернутой” интерферометрической фазы в каждом из $N$ изображений стека.
(2)
$DS = \left\{ {{{p}_{i}}\left( d \right)} \right\},\quad i = 1 \ldots {{N}_{{ds}}},\quad {{N}_{{ds}}} > {{N}_{p}}$Значения интерферометрических фаз пикселей в DS-наборе могут быть статистически охарактеризованы с использованием матрицы когерентности, которая определяется следующим образом (3):
(3)
$T = \frac{1}{{{{N}_{{ds}}}}}\mathop \sum \limits_{i = 1}^{{{N}_{{ds}}}} {{\hat {p}}_{i}}\hat {p}_{i}^{{ + ~}},$+ – операция эрмитового сопряжения вектора ${{\hat {p}}_{i}}$,
Ключевой проблемой является нахождение вектора $\theta = {{\left[ {{{\theta }_{1}},{{\theta }_{2}} \ldots {{\theta }_{N}}} \right]}^{T}}$, который бы служил оценкой полученных значений фаз $\varphi $ для недиагональных элементов в матрице T. Для этого представим матрицу T в параметрическом виде, заменив диагональные элементы на 1 (4):
(4)
$T = \left[ {\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} 1 \\ {{{\gamma }_{{2,1}}}{{e}^{{j{{\varphi }_{{2,1}}}}}}} \\ {\begin{array}{*{20}{c}} \vdots \\ {{{\gamma }_{{N,1}}}{{e}^{{j{{\varphi }_{{N,1}}}}}}} \end{array}} \end{array}}&{\begin{array}{*{20}{c}} {{{\gamma }_{{1,2}}}{{e}^{{j{{\varphi }_{{1,2}}}}}}}& \ldots &{{{\gamma }_{{1,N}}}{{e}^{{j{{\varphi }_{{1,N}}}}}}} \\ 1& \ldots &{{{\gamma }_{{2,N}}}{{e}^{{j{{\varphi }_{{2,N}}}}}}} \\ {\begin{array}{*{20}{c}} \vdots \\ {{{\gamma }_{{N,2}}}{{e}^{{j{{\varphi }_{{N,2}}}}}}} \end{array}}&{\begin{array}{*{20}{c}} \ddots \\ \ldots \end{array}}&{\begin{array}{*{20}{c}} \vdots \\ 1 \end{array}} \end{array}} \end{array}} \right]$При этом значения фаз ${{\varphi }_{{m,n}}} = - {{\varphi }_{{n,m}}}$, $n.m = 1 \ldots N$, а матрица |T| будет представлена элементами ${{\gamma }_{{m,n}}}$.
Рассматривается метод максимального правдоподобия (ML estimator (MLE)). Построение корректной формы MLE проводится путем анализа статистических свойств матрицы когерентности (4), используя комплексное распределение Уишарта. На основе центральной предельной теоремы, делается предположение, что нормализованный вектор радарных данных ${{\hat {p}}_{i}}$ соответствует комплексному многомерному нормальному распределению с нулевым средним и дисперсионной матрицей Σ [12–14]. Предполагается, что матрица T логически может быть представлена комплексным распределением Уишарта с ${{N}_{{ds}}}$ – степенями свободы в виде $T \sim {{W}_{c}}\left( {N,{{N}_{{ds}}},\Sigma } \right)$, где Σ для пикселя ${{p}_{0}}\left( d \right)$ может быть определена с использованием уточненных значений когерентности и фазы как (5)
где $\Theta = \left[ {\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} {{{e}^{{j{{\theta }_{1}}}}}} \\ 0 \\ {\begin{array}{*{20}{c}} \vdots \\ 0 \end{array}} \end{array}}&{\begin{array}{*{20}{c}} 0& \ldots &0 \\ {{{e}^{{j{{\theta }_{2}}}}}}& \ldots &0 \\ {\begin{array}{*{20}{c}} \vdots \\ 0 \end{array}}&{\begin{array}{*{20}{c}} \ddots \\ \ldots \end{array}}&{\begin{array}{*{20}{c}} \vdots \\ {{{e}^{{j{{\theta }_{N}}}}}} \end{array}} \end{array}} \end{array}} \right],\Upsilon = \left[ {\begin{array}{*{20}{c}} {\begin{array}{*{20}{c}} 1 \\ {{{\gamma }_{{2,1}}}} \\ {\begin{array}{*{20}{c}} \vdots \\ {{{\gamma }_{{N,1}}}} \end{array}} \end{array}}&{\begin{array}{*{20}{c}} {{{\gamma }_{{1,2}}}}& \ldots &{{{\gamma }_{{1,N}}}} \\ 1& \ldots &{{{\gamma }_{{2,N}}}} \\ {\begin{array}{*{20}{c}} \vdots \\ {{{\gamma }_{{N,2}}}} \end{array}}&{\begin{array}{*{20}{c}} \ddots \\ \ldots \end{array}}&{\begin{array}{*{20}{c}} \vdots \\ 1 \end{array}} \end{array}} \end{array}} \right]$,$\theta = {{\left[ {{{\theta }_{1}},{{\theta }_{2}} \ldots {{\theta }_{N}}} \right]}^{T}}$ – вектор оптимальных (уточненных) фаз для вектора ${{\varphi }_{{}}} = \left[ {{{\varphi }_{1}},{{\varphi }_{2}} \ldots {{\varphi }_{N}}} \right]$. При вычисленной матрице T корректная форма MLE для Σ может быть получена путем максимизации абсолютного значения логарифма следующей функции плотности вероятности [12]:
(6)
$\begin{gathered} \hat {\Sigma } = \arg {{\max }_{\Sigma }}\{ \ln [p(T|\Sigma )]\} = \\ = \arg \max \{ - {\text{trace}}({{N}_{{dc}}}{{\Sigma }^{{ - 1}}}T) - {{N}_{{ds}}}\ln ({\text{Det}}(\Sigma ))\} = \\ = \arg {{\max }_{{\Upsilon ,\Theta }}}\{ - {\text{trace}}(\Theta {{\Upsilon }^{{ - 1}}}{{\Theta }^{H}}T) - \ln ({\text{Det}}(\Sigma ))\} \\ \end{gathered} $Для оценки Θ в (6) требуется значения γ матрицы $\Upsilon $. Не теряя общности, их можно заменить значениями γ из |T| [12]. Следовательно, (6) примет следующий вид:
(7)
$\begin{gathered} {{\Theta }_{{ML}}} = \arg {{\max }_{\Theta }}\{ - {\text{trace}}(\Theta {\text{|}}T{{{\text{|}}}^{{ - 1}}}{{\Theta }^{H}}T) - \ln ({\text{Det}}({\text{|}}T{\text{|}}))\} \\ = \arg {{\max }_{\Theta }}\{ - {\text{trace}}(\Theta {\text{|}}T{{{\text{|}}}^{{ - 1}}}{{\Theta }^{H}}T)\} = \\ = \arg {{\max }_{\Theta }}\{ {{\Lambda }^{H}}( - {\text{|}}T{{{\text{|}}}^{{ - 1}}}\,^\circ \,T)\Lambda \} , \\ \end{gathered} $Для удобства программной реализации преобразуем (7) в следующий вид, используя тригонометрическую форму комплексного числа:
(8)
$\begin{gathered} {{\Theta }_{{ML}}} = \arg {{\max }_{\Theta }}\{ {\text{sum}}(( - {\text{|}}T{{{\text{|}}}^{{ - 1}}}\,^\circ \,{\text{|}}T{\text{|}})\,^\circ \,\Phi \,^\circ \,{{(\Lambda {{\Lambda }^{H}})}^{T}})\} = \\ = \arg {{\max }_{\Theta }}\{ {{F}_{{\max }}}\} , \\ {{F}_{{\max }}} = \sum\limits_{m = 1}^N {\sum\limits_{n > m}^N {{{{\hat {\gamma }}}_{{m,n}}}\cos ({{\varphi }_{{m,n}}} - {{\theta }_{m}} - {{\theta }_{n}}),} } \\ \end{gathered} $Решение (8) можно проводить различными методами. В данной работе будем использовать итерационный метод численной оптимизации BFGS (Broyden, Fletcher, Goldfarb, Shanno). После того, как будет найден вектор оптимальных решений $\theta = {{\left[ {{{\theta }_{1}},{{\theta }_{2}} \ldots {{\theta }_{N}}} \right]}^{T}}^{{}}$, необходимо оценить качество полученной оптимизации. Для этого используется следующий фильтр:
(9)
${{\gamma }_{{PTA}}} = \frac{2}{{{{N}^{2}} - N}}{\text{Rе}}\mathop \sum \limits_{n = 1}^N \mathop \sum \limits_{k = n + 1}^N {{e}^{{i{{\varphi }_{{n,k}}}}}}{{e}^{{ - i\left( {{{\theta }_{n}} - {{\theta }_{k}}} \right)}}},$3. ПРОГРАММНАЯ РЕАЛИЗАЦИЯ
Программная реализация алгоритма построена на базе языка Python, параллельные вычисления – на базе Apache Spark API For Python [10]. Параллелизация строится на том факте, что каждое окно является независимой сущностью. Вычисления над входными данными не используют результаты аналогичных вычислений. Значения переменных и объектов внутри окна не влияют на выполнение вычислений в других окнах сдвига. Количество окон определяется только размером исходных изображений в стеке. Совмещение всех изображений в стеке с субпиксельной точностью гарантирует равный размер и количество окон. Таким образом, можно утверждать, что представленный алгоритм не является итерационным, и может быть реализован в парадигме параллельных вычислений.
Исходный программный код находится в открытом доступе по адресу https://bitbucket.org/ ogidog/pysqueesar/src/master/.
Для удобства работы координаты пикселей изображений будем представлять в одномерном виде, т.е. пиксель с координатами (x, y) ↔ xy = yW + x. x $ \in $ [0,W–1], y $ \in $ [0, H–1], W и H – ширина и высота изображений в пикселях, соответственно (переменные: width и height).
Создаются следующие программные переменные (табл. 1):
Таблица 1.
Начальные переменные
| Переменная | Тип | Размерность | Описание |
|---|---|---|---|
| img_width, img_height, N | int | 1 | Ширина, высота изображений, их количество в серии |
| i, q | Array, float32 | width*height, N | Массивы значений пикселей для полос Q и I для каждого изображения в серии, соответственно |
| Np | int | Пороговое значение для количества пикселей в DS-наборе | |
| shift_win_widt, shift_win_height | int | 1 | Ширина и высота окна сдвига |
| num_slices | int | 1 | Количество разделов (partitions) во вновь создаваемом RDD [10] |
Формируется массив, содержащий координаты центральных пикселей central_pixels, тип int, заполняем массивы i, q. Данная процедура называется get_input_data() (см. исходный код). На основе данного массива происходит полный расчет распределенных отражателей и их уточненных значений фаз согласно алгоритму, представленному в разделе “Математическая модель алгоритма SqueeSAR”.
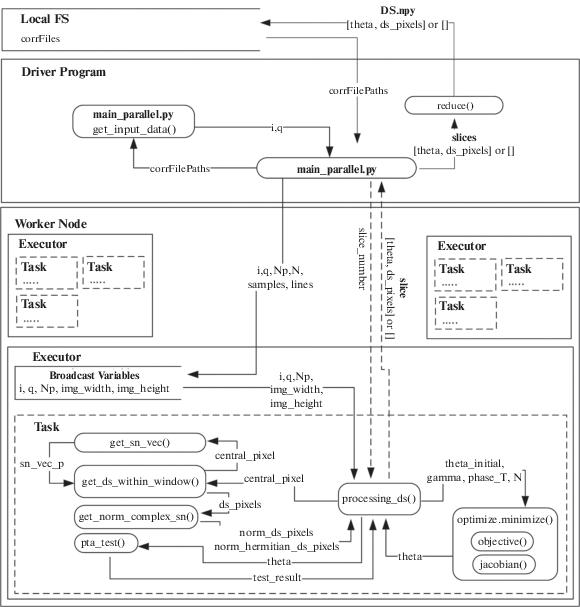
Для подключения, управления и инициализации вычислений на кластере применяется технология контекстного запуска независимых разделяемых исполнителей (Executors) Spark Context (объект SparkContext из библиотеки pyspark). SparkContext предоставляет методы соединение с кластером Spark и может использоваться для создания RDD и широковещательных переменных в кластере (рис. 3). Настройка контекста происходит непосредственно в коде и в командной строке запуска программы-драйвера (см. исходный код, файл main_parallel.py)
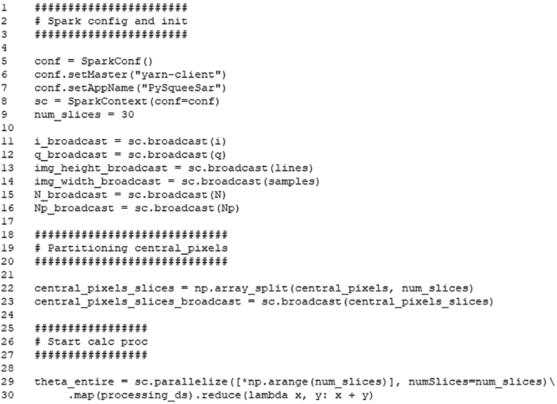
Для эффективного предоставления каждому узлу копии большого входного набора данных применяются широковещательные переменные (broadcast). Они позволяют хранить данные только для чтения в кэше на каждой машине, а не отправлять их копию вместе с задачами. Spark автоматически передает данные, необходимые для задач на каждом этапе, если эти данные являются глобальными для функции, которая исполняется на map-стадии (рис. 3). Общие данные кэшируются в сериализованной форме и десериализуются перед запуском каждого расчетного задания.
Для создания broadcast-переменных используется метод объекта SparkContext.broadcast() (рис. 3, переменные i_broadcast, q_broadcast, Np_broadcast, N_broadcast, img_width_broadcast, img_height _broadcast для соответствующих переменных из табл. 1). Данные, хранящиеся в перечисленных переменных, являются общими и неизменяемыми на протяжении всех преобразований в алгоритме.
Массив координат центральных пикселей central_pixels разбивается на разделы (slices). Для этого используется функция numpy.array_split() (рис. 3), и создается broadcast-переменная central_pixels_ slices_broadcast размерностью (num_slices, len(central_pixels)// num_slices).
Для работы с данными в среде Apache Spark в параллельном режиме создаются специальные объекты RDD (Resilient Distributed Dataset). RDD – это отказоустойчивый набор элементов, с которыми можно работать параллельно [10]. Формирование RDD происходит путем логического распараллеливания входной коллекции/массива данных в управляющей программе-драйвере при помощи метода SparkContext.parallelize() (рис. 3). При этом на получившихся RDD-наборах возможно использование классических функций map-трансформаций, которые имплементируют алгоритм построения DS-наборов и поиска оптимальных решений (метод processing_ds(), рис. 3,4).

В качестве входного параметра в метод parallelize() передается массив, содержащий индексы разделов (slices) переменной central_pixels_slices_broadcast. Все разделы обрабатываются расчетными заданиями на map-стадии параллельно. В то время как отдельно взятое расчетное задание обрабатывает свой конкретный набор центральных пикселей в разделе последовательно на выделенном заданию ядре, используя метод processing_ds().
Ниже представлена последовательность действий и их описание для процедуры processing_ds.
1. По индексу раздела из broadcast-переменной central_pixels_slices_broadcast получаем список central_pixels_slice (тип List), содержащий координаты центральных пикселей окон сдвига (mxn) для данного раздела (рис. 4, строка 1). Координаты записаны в формате xy = yW + x, как упоминалось выше.
2. Для каждого пикселя в текущем разделе получаем массив (DS-набор, тип List, рис. 4, строка 5), в котором хранятся индексы тех точек серии изображений, которые могут считаться кандидатами в распределенные рассеиватели (2), метод get_ds_ within_window() (см. исходный код, файл main_parallel.py). В данном методе для каждого пикселя-кандидата выполняется тест Колмогорова–Смирнова, описанный в разделе “Математическая модель алгоритма SqueeSAR”.
Используется вспомогательный метод get_sn_ vec() (рис. 5) для получения относительных частот по каждому пикселю в окне. В данном методе происходит обращение к broadcast-переменным i_broadcast и q_broadcast (рис. 5, строки 1,2), расчет амплитуд, их частотного распределения и кумулятивного накопления (рис. 5, строки 5–9).

Далее, в методе get_ds_within_window() для каждого пикселя в окне рассчитывается модуль разности соответствующих относительных частот и его наибольшее значение Dmax (рис. 6, строка 13), вычисляется эмпирическое значение критерия lambda_emp (рис. 6, строка 14). Если эмпирическое значение критерия lambda_emp меньше критического lambda_crit, то индекс текущего пикселя добавляется в массив window_ds_pixels (рис. 6, строка 15, 16). После того как найдены все пиксели-кандидаты в распределенные отражатели в окне сдвига необходимо отсеять те, которые не являются смежными с центральным.

3. Алгоритм поиска смежных пикселей строится на базе k-мерного дерева, используя объект scipy.spatial.cKDTree, которому передается массив window_ds_pixels (рис. 7, строка 21). Метод query_ball_point() объекта cKDTree (рис. 7, строка 32), позволяет находить ближайшие соседние точки к заданной с координатами (x,y), находящиеся на определенном расстоянии в декартовой системе координат. Данный метод возвращает список координат (x,y) всех соседних элементов, принадлежащих k-мерному дереву. Примем расстояние (радиус) D равным $\sqrt 2 $, т.е. значения координат (x, y) смежных пикселей отличаются ровно на 1.
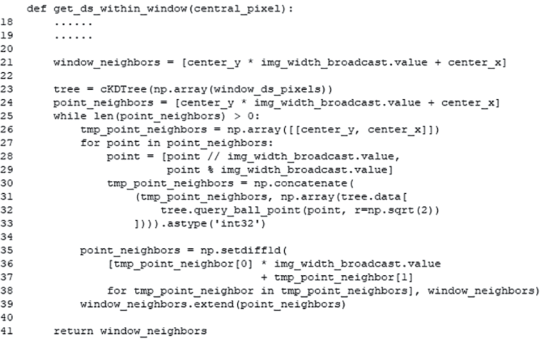
Создается массив window_neighbors, тип List, с начальным элементов – индексом центральной точки. Он будет содержат все индексы смежных пикселей, после завершения работы метода. Так как метод query_ball_point() принимает координаты точек в формате (x,y), то на каждом шаге итерации будем преобразовывать индексы элементов массива window_ds_pixels в такой формат (рис. 7, строки 28, 29).
Создается временный массив tmp_point_ neighbors (рис. 7, строка 26), который на каждой итерации для каждой точки из window_ds_pixels будет заполняться смежными с ней. Создается массив point_neighbors. Он будет содержать индексы точек, которых еще нет в основном массиве window_neighbors, и, соответственно, дополнять основной массив ими.
На первой итерации выполняется метод query_ball_point() для центрального пикселя в массиве point_neighbors. Получается модифицированный массив tmp_point_neighbors, содержащий не только координаты центральной точки, но и координаты смежных пикселей, находящихcя на расстоянии $\sqrt 2 $ от нее (рис. 7, строки 30–33). Ищется различие массива tmp_point_neighbors с основным window_neighbors и записывается в массив point_neighbors (рис. 7, строки 35–38). Соответственно, расширяется массив window_neighbors (рис. 7, строки 39).
Следующая итерация начинается с проверки длины массива point_neighbors. Если длина массива больше 0, т.е. на предыдущей итерации были найдены смежные пиксели, отличные от уже содержащихся в массиве window_neighbors по значениям индексов, то выше описанная процедура повторяется. Другими словами, область поиска в окне сдвига расширяется на расстояние $\sqrt 2 $ от центральной (рис. 8).
Рис. 8.
Схем поиска смежных пикселей. Цифрой обозначен номер итерации и, соответственно, пикселы, найденные как смежные с центральным на текущей итерации.
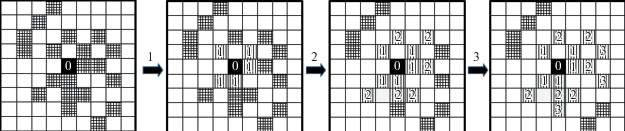
В конечном итоге данный итерационный метод позволит перебрать каждый пиксель-кандидат из массива window_ds_pixels, достигнув самых отдаленных пикселей от центрального. То есть, метод numpy.setdiff1d() (рис. 7, строка 35) вернет пустой массив point_neighbors, так как вновь найденные смежные точки уже будут содержаться в основном массиве window_neighbors. Итерации прекращаются.
4. Если количество смежных пикселей в сформированном массиве ds_pixels (рис. 4, строка 5) больше заданной переменной Np_broadcast (не менее 20), выполняем расчет уточненных значений вектора фаз theta.
Рассчитываются нормированные комплексные значения (3) ($\widehat {{{p}_{i}}}$ и $\hat {p}_{i}^{{ + ~}}$) каждого пикселя из массива ds_pixels, метод get_norm_complex_sn() (см. исходный код, файл main_parallel.py). Рассчитывается матрица когеренции T (3) (рис. 4, строки 11–12, тип complex). Согласно математической модели алгоритма задается начальное значение для theta, переменная theta_initial (рис. 4, строки 13).
5. Для оценки значений интерферометрических фаз каждого центрального пикселя из central_pixels_slices_broadcast для соответствующего DS-набора ds_pixels используется объект scipy.optimize. Объект optimize не содержит методов, позволяющих решать задачу максимизации. Поэтому применяется метод minimize() (рис. 4, строки 16–21) для решения задач минимизации. Другими словами, мы минимизируем функцию $ - {{F}_{{max}}}$ из (8) (параметр fun) для всех θ (theta), при заданном ограничении $ - \pi \leqslant \theta \leqslant \pi $ (параметр bounds). Параметр method задает тип решателя для проблемы минимизации. В данном случае модификация метода BFGS с возможностью задания нижней и верхней границ поиска решения. Параметр x0 – вектор начального приближения, равен theta_initial. В предположении того, что изначальные фазы уже являются оптимальными для достаточно большого значения отношения сигнал/шум в стеке интерферометрических изображении [1, 15]. Параметром jac_fun задается якобиан (метод jacobian(), см. исходный код) для функции параметра fun (метод objective(), см. исходный код). Данные методы принимают на вход искомое значение (приближение на каждой итерации метода minimize()), а на выходе возвращают вычисленное значение согласно выражению внутри этих методов. То есть, это значение функции $ - {{F}_{{max}}}$ (8) и ее якобиана (см. исходный код), вычисленные при заданных параметрах (args) равных numpy.angle(T) и gamma (рис. 4, строки 15, 16) и векторе искомых значений theta на каждой итерации.
6. Качество полученной оптимизации theta оценивается на основе специального теста (метод pta_test()) (рис. 9).

7. Если массив theta прошел тест, то все его значения в текущем окне сдвига добавляются в специально созданный массив theta_slice (тип List) вместе с индексами смежных пикселей (массив ds_pixels). Если нет, то в массив theta_slice добавляется пустой массив, ровно как и в случае длины массивы ds_pixel меньше чем заданное пороговое значение переменной Np_broadcast (рис. 4, строки 24–29).
Массив theta_slice содержит все результаты работы одного задания в среде Apache Spark, соответствующие текущему разделу.
Для объединения результатов в единый массив theta_entire используется метод объекта pyspark.RDD reduce() (рис. 3, строки 29, 30). Массив theta_entire сохраняется в бинарный файл в программе-драйвере (см. исходный код, файл main_ parallel.py). В дальнейшем из этого файла считываются значения theta всех центральных пикселей и индексы смежных точек ds_pixels. Значения в каналах I и Q исходных снимков заменяются соответствующими расчетными значениями. При этом вещественная часть (полоса I) будет равна cos(theta), а мнимая (полоса Q) – sin(theta) (см. исходный код, файл main.py, метод modify_images()).
Ниже приведена диаграмма потоков данных (DFD) при выполнении программного кода алгоритма поиска распределенных рассеивателей (рис. 10).
4. ТЕСТ ПРОИЗВОДИТЕЛЬНОСТИ
Запуск программы-драйвера (см. исходный код, файл main_parallel.py), содержащего код (рис. 3) выполняется при помощи скрипты spark-submit [10] (рис. 11).

Параметр spark.driver.memory задает количество оперативной памяти, выделяемое для программы драйвера на управляющем узле Spark/ Yarn (Master Node). Данный параметр влияет на объем предварительно подготавливаемых данных перед непосредственно их копированием на исполняющие узлы кластера. Устанавливать значение параметра необходимо с учетом суммарного объема всех переменных определяемых вне метода map(). Это переменные i, q, lines, samples, N, Np, central_pixels, central_pixels_slices (рис. 3).
Параметр spark.executor.memory задает количество оперативной памяти, выделяемое для каждого контейнера-исполнителя (Executor). При этом на одном узле-исполнителе (Worker Node) менеджером ресурсов Yarn может быть создано несколько контейнеров-исполнителей. Следовательно, общее количество выделяемой оперативной памяти на узле может быть увеличено на величину равной spark.executor.memory* (кол-во контейнеров-исполнителей). Также, данный параметр должен коррелировать с количеством создаваемых broadcast-переменных, т.к. каждая переменная копируется для каждого контейнера-исполнителя [10]. Это переменные i_broadcast, q_broadcast, img_height_broadcast, img_width_broadcast, N_broadcast, Np_broadcast, central_pixels_slices_broadcast (рис. 3).
Параметр spark.executor.instances задает общее количество контейнеров-исполнителей. При выборе значения данного параметра необходимо учитывать общий объем оперативной памяти, необходимой для всех broadcast-переменных. Непосредственно каждый физический узел должен обладать памятью способной разместить объем равный spark.executor.instances *(суммарный размер в байтах broadcast-переменных).
Параметр spark.executor.cores задает количество ядер процессора на один исполнитель. При этом параметр неявно задает количество заданий Task, которое сможет выполнить исполнитель за один запуск. То есть в контексте алгоритма – это будет количество разделов (slices), для которых ведется расчет всех центральных точек в текущем разделе (рис. 10).
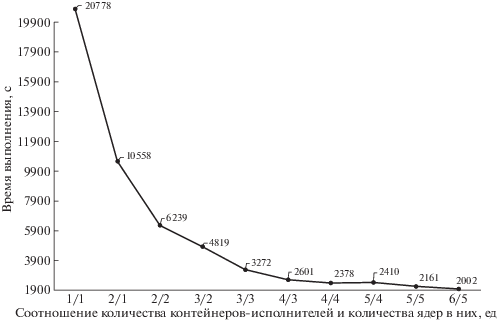
Тест производительности проводился для области снимка размером 6000 × 4000 пикселей, стек из 50 снимков (N = 60), на кластере, состоящем из 3 узлов со следующими аппаратными характеристиками: 3 сервера (AMD Ryzen 1700 (8 + 8 cores (Simultaneous Multi-Threading)) 3.2 GHz, 32 Gb RAM, 1 Gb/s скорость передачи данных между серверами). Один узел выступал в роли управляющего, два других – в роли узлов-исполнителей. Именно на них проводился расчет. В скрипте запуска spark-submit менялись значение параметров spark.executor.instances и spark.executor.cores. Остальные параметры были зафиксированы со значениями: spark.driver.memory=8g и spark.executor.memory=8g (рис. 11).
Ниже праведен график времени выполнения алгоритма с учетом вариативности вышеописанных параметров (рис. 12).
5. ПРИМЕНЕНИЕ АЛГОРИТМА SqueeSAR
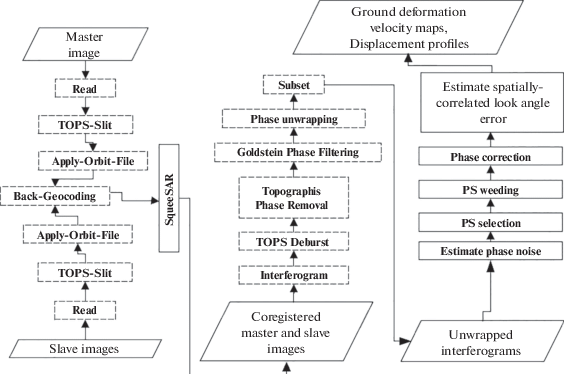
Расчет скоростей смещений для тестовых радарных данных проводился в открытом пакете библиотек StamPS [16]. В стандартную схему пред- и постобработки был добавлен дополнительный шаг “SqueeSAR” (рис. 13), проводящий расчет DS-наборов и заменяющий исходные значения интерферометрических фаз их оптимальными значениями. Исходными данными для полного цикла расчета скоростей смещений методом постоянных рассеивателей (PS) послужили спутниковые радарные снимки аппарата Sentinel-1B. Для дифференциальной интерферометрии использовался канал типа IW (Interferometric Wide swath) с вертикальной поляризацией VV. Территория охвата – г. Норильск, и прилегающие территории (ТЭЦ-3), Россия. Данные были получены с открытого ресурса в сети Интернет “Copernicus Open Access Hub” (URL: https://scihub. copernicus.eu/dhus/#/home) Европейского космического агентства (URL: https://sentinel.esa.int/ web/sentinel/home). Всего получено 60 снимков временной серии с февраля 2019 г. до апреля 2020 г. Модифицированная схема полного цикла расчета скоростей смещений представлена на рис. 13. Полное описание методов схемы приводится в [17, 18].
Рис. 13.
Модифицированная схема полного цикла расчета скоростей смещений методом постоянных рассеивателей.
Рассматривалась географическая область, где 29 мая на территории ТЭЦ-3 в Норильске произошла утечка из резервуара, в котором было около 21 тысячи тонн дизельного топлива. На рис. 14 приведены расчеты смещений для аварийных баков. Показано облако точек (постоянных рассеивателей) с применением метода SqueeSAR и без него. Общее количество точек для расчетной области возросло в среднем до 130 000 точек с интегрированным методом SqueeSAR, против 53 000 в стандартном выполнении схемы.
Рис. 14.
Результат расчета полной схемы скоростей смещений с интегрированным алгоритмом SqueeSAR а) и без б).

Ниже приведен фрагмент области снимка для визуального сравнения облака постоянных рассеивателей с представленным методом и без него (рис. 14).
6. ЗАКЛЮЧЕНИЕ
Разработан быстрый алгоритм поиска распределенных отражателей для задачи построения скоростей смещений методом постоянных рассеивателей. Предложенный алгоритм позволяет увеличить количество искомых рассеивателей в два-три раза по сравнению с традиционным алгоритмом. Примеры расчетов на спутниковых радарных данных Sentinel-1A/B показывают увеличенную плотность и компактность точек расположения в местах возвышенностей и средних построек (от 10 м). Это позволяет точнее строить карты цифровых моделей рельефа на базе временных серий снимков.
Показано, что предложенный алгоритм не является итерационным, и может быть реализован в парадигме параллельных вычислений. Применяемая платформа параллельной обработки Apache Spark позволила распределено обрабатывать массивы стека радарных данных (от 60 изображений) в памяти, на большом количестве физических узлов в сетевой среде. При этом время поиска распределенных рассеивателей удалось снизить в среднем в 10 раз по сравнению с однопроцессорной реализацией алгоритма.
Предложенный алгоритм и его параллельная имплементация позволят применять разработанные подходы в других задачах и типах спутниковых данных дистанционного зондирования земли из космоса.
Список литературы
Ferretti A., Prati C., Rocca F., Wasowski J. Satellite interferometry for monitoring ground deformations in the urban environment // Proc. of the 10th Congress of the International Association for Engineering Geology and the Environment (IAEG). 2006. P. 1–4.
Crosetto M., Monserrat O., Cuevas-González M., Devanthéry N., Crippa B. Persistent Scatterer Interferometry: A review // ISPRS Journal of Photogrammetry and Remote Sensing. 2016. V. 115. P. 78–89.
Perissin D., Ferretti A. Urban target recognition by means of repeated spaceborne SAR images. IEEE Trans. Geosci. Remote Sens. 2007. V. 45. № 12. P. 4043–4058.
Hooper A.A multi-temporal InSAR method incorporating both persistent scatterer and small baseline approaches // Geophysics Research Letter. 2008. V. 35. P. 302
Rocca F. Modeling interferogram stacks // IEEE Transactions on Geoscience and Remote Sensing. 2007. V. 45. № 10. P. 3289–3299.
Zebker H.A., Shanker A.P. Geodetic imaging with time series persistent scatterer InSAR // American Geophysical Union all Meeting Abstracts. San Francisco. CA. 2008.
Ferretti A., Fumagalli A., Novali F., Prati C., Rocca F., Rucci A. Exploitation of distributed scatterers in interferometric data stacks // International Geoscience Remote Sensing Symposium (IGARSS). Cape Town. South Africa. 2009.
Ferretti A., Fumagalli A., Novali F., Prati C., Rocca F., Rucci A. The second generation PSInSAR approach: SqueeSAR. International Workshop ERS SAR Interferometry (FRINGE). Frascati. Italy. 2009.
Ferretti A., Fumagalli A., Novali F., Prati C., Rocca F., Rucci A. A New Algorithm for Processing Interferometric Data-Stacks: SqueeSAR // IEEE Transactions on Geoscience and Remote Sensing. 2011. V. 49. P. 3460–3470.
Apache Spark Documentation // Apache Spark. https://spark.apache.org/docs/latest/index.html (дата обращения: 12.09.2020)
Феоктистов А.А., Захаров А.И., Денисов П.В., Гусев М.А. Исследование зависимости результатов обработки радиолокационных данных ДЗЗ от параметров обработки. Часть 4. Основные направления развития метода постоянных рассеивателей; ключевые моменты методов SQUEESAR И STAMPS // Журнал радиоэлектроники [электронный журнал]. 2017. № 7. http://jre.cplire.ru/jre/jul17/5/text.pdf
Cao N., Lee H., Chul Jung H. Mathematical Framework for Phase-Triangulation Algorithms in Distributed-Scatterer Interferometry // IEEE Geoscience and remote sensing letters. V. 12. № 9. P. 1838–1842.
Guarnieri A.M., Tebaldini S. On the exploitation of target statistics for SAR interferometry applications // IEEE Transactions on Geoscience and Remote Sensing. 2008. V. 46. № 11. P. 3436–3443.
Bamlery R., Hartlz P. Synthetic aperture radar interferometry // Inverse Problems. 1998. V. 14. № 4. P. R1–R54.
Shamshiri R., Nahavandchi H., Motagh M., Hooper A. Efficient Ground Surface Displacement Monitoring Using Sentinel-1 Data: Integrating Distributed Scatterers (DS) Identified Using Two-Sample t-Test with Persistent Scatterers (PS) // Remote Sensing. 2018. V. 10. № 5. P. 794–808.
STAMPS // A software package to extract ground displacements from time series of synthetic aperture radar (SAR) acquisitions. https://homepages.see.leeds.ac.uk/~earahoo/stamps/ (дата обращения: 12.09.2020)
Потапов В.П., Попов С.Е., Костылев М.А. Информационно-вычислительная система массивно-параллельной обработки радарных данных в среде Apache Spark // Вычислительные технологии. 2018. Т. 23. № 4. С. 110–123.
Попов С.Е., Замараев Р.Ю., Миков Л.С. Массово-параллельный подход к обработке радарных данных // Современные проблемы дистанционного зондирования Земли из космоса. 2020. Т. 17. № 2. С. 49–61.
Дополнительные материалы отсутствуют.
Инструменты
Программирование