

Радиотехника и электроника, 2021, T. 66, № 12, стр. 1189-1197
Ортогональное прекодирование для систем с пространственным мультиплексированием при линейном приемнике
М. Г. Бакулин a, В. Б. Крейнделин a, *, А. А. Резнёв a
a Московский технический университет связи и информатики
111024 Москва, ул. Авиамоторная, 8а, Российская Федерация
* E-mail: vitkrend@gmail.com
Поступила в редакцию 05.07.2021
После доработки 25.07.2021
Принята к публикации 30.07.2021
Аннотация
Предложен подход для разработки алгоритмов ортогонального прекодирования для достижения эффекта полного разнесения в системах связи с MIMO-каналом при линейной обработке на приемной стороне. Разработанные алгоритмы могут использоваться для любой конфигурации MIMO-канала и реализуются в виде быстрых ортогональных преобразований ${{N}_{{tx}}}$ векторов, размером $\left( {{{N}_{{tx}}} \times 1} \right)$ каждый (${{N}_{{tx}}}$ – число передающих антенн), и распределения преобразованных символов этих векторов по разным тактам и передающим антеннам. Приведены результаты моделирования предложенных алгоритмов прекодирования, которые показали, что их использование позволяет получить выигрыш 2…5 дБ, в зависимости от конфигурации MIMO-системы. При этом число операций при реализации линейного приемника увеличивается лишь на величину ${{N}_{{tx}}}{{\log }_{2}}{{N}_{{tx}}}$, т.е. сложность приемника практически не меняется.
ВВЕДЕНИЕ
Известно, что в системах связи с MIMO-каналом пропускная способность растет пропорционально $\min \left( {{{N}_{{tx}}},{{N}_{{rx}}}} \right)$ [1], где ${{N}_{{tx}}},{{N}_{{rx}}}$ – число передающих и приемных антенн соответственно. При этом также повышается энергетическая эффективность за счет разнесения, так как увеличивается число путей распространения сигнала с некоррелированными замираниями, а также за счет когерентной обработки сигналов, принимаемых разными приемными антеннами. Однако если рассмотреть систему связи с мультиплексированием в MIMO-канале более подробно, то можно отметить, что число путей распространения сигнала с независимыми замираниями равно ${{N}_{{tx}}} \times {{N}_{{rx}}}$, а число путей, по которым передается один символ, равно ${{N}_{{rx}}}$. Поэтому разные символы принимаются с разным качеством.
Для повышения энергетической эффективности в системах MIMO с пространственным мультиплексированием за счет полного разнесения используются алгебраические коды [2–6], среди которых наиболее известным является так называемый код Голден [4]. Так, например, для конфигурации ${{N}_{{rx}}} = {{N}_{{tx}}} = 2$ выигрыш от использования кода Голден составляет 1.5…2 дБ [5]. Однако данные алгебраические коды оптимизированы для оптимального приемника максимального правдоподобия, сложность которого в сочетании с алгебраическим кодированием с полным разнесением растет пропорционально ${{2}^{{{{k}_{b}}{{N}_{{tx}}}{{N}_{{rx}}}}}}$, где ${{k}_{b}}$ – число битов, передаваемых одним модулированным символом. Это обстоятельство делает данные коды непригодными для практического использования при числе передающих антенн ${{N}_{{tx}}} \geqslant 4$.
В данной статье предложен подход, позволяющий достичь эффекта полного разнесения, при котором каждый передаваемый символ распределяется по всем ${{N}_{{tx}}}{{N}_{{rx}}}$ возможным путям распространения и при этом используется линейный приемник, сложность которого практически остается такой же, как и сложность приемника с минимумом средней квадратической ошибки (МСКО) для обычной системы связи с пространственным мультиплексированием.
1. МОДЕЛЬ СИСТЕМЫ
Рассмотрим однопользовательскую MIMO-систему с ${{N}_{{tx}}}$ передающими и ${{N}_{{rx}}}$ приемными антеннами. Для передачи информации по MIMO-каналу используется пространственное мультиплексирование [1], где поток комплексных модулированных символов ${{s}_{i}}$, $i = 1,2, \ldots ,$ разбивается на последовательности векторов:
Для системы MIMO с пространственным мультиплексированием модель наблюдения описывается следующим выражением [1, 6–10]:
гдеМодель системы показана на рис. 1. Как видно из рисунка, каждый символ, излучаемый одной передающей антенной, поступает на ${{N}_{{rx}}}$ приемных антенн по ${{N}_{{rx}}}$ индивидуальным путям распространения. Всего в модели имеются ${{N}_{{rx}}}{{N}_{{tx}}}$ независимых путей распространения. Это означает, что символы будут приниматься с разным качеством и в данном случае не реализуется полное разнесение. В связи с этим возникает задача обеспечить распределение каждого символа по всем передающим антеннам таким образом, чтобы обеспечить эффект полного разнесения после демодуляции всего сигнала или, по крайней мере, повысить порядок разнесения.
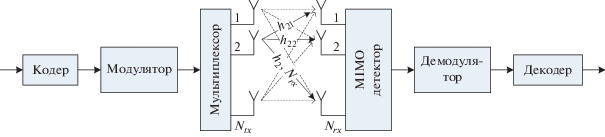
Данную задачу решают пространственные коды на основе алгебраического кодирования, представителем которых для конфигурации ${{N}_{{tx}}} = {{N}_{{rx}}} = 2$ является известный код Голден [4, 5]. Однако полностью реализовать его преимущество возможно только при оптимальном приемнике максимального правдоподобия, сложность которого в данном случае будет пропорциональна ${{2}^{{{{k}_{b}}{{N}_{{tx}}}{{N}_{{rx}}}}}}$. В связи с этим возникает задача использования более простых алгоритмов MIMO-детектирования в сочетании с линейным прекодированием, позволяющим повысить порядок разнесения.
В работе [11] предложено использовать ортогональное преобразование каждого мультиплексированного вектора и индивидуальную задержку каждого сигнала, излучаемого своей антенной. Для его реализации рассматривается приемник, использующий принципы турбообработки [12], основанные на последовательном отказе и последующем учете априорной информации о дискретном распределении и гауссовской аппроксимации [13, 14], который может быть реализован в виде линейного фильтра Калмана. Однако, несмотря на использование более простого, чем оптимальный, алгоритма обработки, его реализация остается сложной при больших значениях числа передающих антенн, так как требуется вычисление обратной матрицы размером $\left( {N_{{tx}}^{2} \times N_{{tx}}^{2}} \right)$.
Рассмотрим использование линейного алгоритма, оптимального по критерию МСКО, для обработки MIMO-сигнала модели (1). Данный алгоритм описывается следующими выражениями [1, 15–17]:
(2)
${{{\mathbf{\hat {x}}}}_{n}} = {{\left( {{{{\mathbf{H}}}^{H}}{\mathbf{H}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{{{N}_{{tx}}}}}}} \right)}^{{ - 1}}}{{{\mathbf{H}}}^{H}}{{{\mathbf{y}}}_{n}}{\kern 1pt} .$2. ОРТОГОНАЛЬНОЕ ПРЕКОДИРОВАНИЕ
Введем расширенный вектор символов
Для расширенной модели (4), как и для модели (1) можно также применить МСКО-алгоритм (2). Матрица ошибок МСКО-оценивания в данном случае будет блочно-диагональной и определяться следующим выражением:
(5)
$\begin{gathered} {\mathbf{\hat {z}}} = {{\left( {{{{\mathbf{H}}}^{H}}{\mathbf{\tilde {H}}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{{{\mathbf{H}}}^{H}}{\mathbf{\tilde {y}}}, \\ {{{{\mathbf{\tilde {V}}}}}_{z}} = {{\left( {\rho {{{\mathbf{H}}}^{H}}{\mathbf{\tilde {H}}} + {{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}. \\ \end{gathered} $Нетрудно показать, что
Очевидно, что значения диагональных элементов корреляционной матрицы для расширенного вектора периодически повторяются
(6)
${\text{diag}}{{{\mathbf{\tilde {V}}}}_{z}} = \left[ {\underbrace {{{v}^{{\left( {1,1} \right)}}}{{v}^{{\left( {2,2} \right)}}} \ldots {{v}^{{\left( {{{N}_{{tx}}},{{N}_{{tx}}}} \right)}}}}_{{\text{вектор\;1\;}}\left( {{\text{такт\;1}}} \right)}\underbrace {{{v}^{{\left( {1,1} \right)}}}{{v}^{{\left( {2,2} \right)}}} \ldots {{v}^{{\left( {{{N}_{{tx}}},{{N}_{{tx}}}} \right)}}}}_{{\text{вектор\;2\;}}\left( {{\text{такт\;2}}} \right)}\underbrace {{{v}^{{\left( {1,1} \right)}}}{{v}^{{\left( {2,2} \right)}}} \ldots {{v}^{{\left( {{{N}_{{tx}}},{{N}_{{tx}}}} \right)}}}}_{{\text{вектор\;}}{{N}_{{tx}}}\left( {{\text{такт}}{{N}_{{tx}}}} \right)}} \right].$Среднее значение дисперсий для расширенной корреляционной матрицы ошибок оценивания остается прежним, т.е.
Рассмотрим влияние ортогонального преобразования (прекодирования) на корреляционную матрицу ошибок оценивания. Введем матрицу ортогонального преобразования ${\mathbf{\tilde {F}}}$, размером $\left( {N_{{tx}}^{2} \times N_{{tx}}^{2}} \right)$, и используем ее для прекодирования расширенного вектора, т.е. имеем следующее преобразование ${\mathbf{z}} = {\mathbf{\tilde {F}\tilde {x}}}$, где ${\mathbf{\tilde {x}}}$ – расширенный вектор исходных модулированных символов. Модель наблюдения для этого случая может быть записана следующим образом [18–21]:
(7)
${\mathbf{\tilde {y}}} = {\mathbf{\tilde {H}\tilde {F}\tilde {x}}} + {\mathbf{\tilde {\eta }}}{\kern 1pt} .$Вектор оценок МСКО и соответствующая корреляционная матрица ошибок оценивания будут описываться следующими выражениями:
(8)
$\begin{gathered} {\mathbf{\tilde {x}}} = {{\left( {{{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}\tilde {F}}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {y}}}, \\ {\mathbf{\tilde {V}}} = {{\left( {\rho {{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}\tilde {F}}} + {{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}. \\ \end{gathered} $Нетрудно показать, что
(9)
$\begin{gathered} {\mathbf{\tilde {x}}} = {{\left( {{{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}\tilde {F}}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {y}}} = \\ = {{{{\mathbf{\tilde {F}}}}}^{H}}{{\left( {{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {y}}} = {{{{\mathbf{\tilde {F}}}}}^{H}}{\mathbf{\hat {z}}}{\kern 1pt} , \\ {\mathbf{\tilde {V}}} = {{{{\mathbf{\tilde {F}}}}}^{H}}{{\left( {\rho {{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}}} + {{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{\mathbf{\tilde {F}}} = {{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {V}}}}}_{z}}{\mathbf{\tilde {F}}}{\kern 1pt} . \\ \end{gathered} $Можно доказать, что ${\text{tr}}\left( {{{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {V}}}}}_{z}}{\mathbf{\tilde {F}}}} \right) = {\text{tr}}{{{\mathbf{\tilde {V}}}}_{z}}$. Это вытекает непосредственно из свойства следа для произведения матриц ${\text{tr}}\left( {{\mathbf{AB}}} \right) = {\text{tr}}\left( {{\mathbf{BA}}} \right)$ [22–25]. Поэтому можно сделать вывод, что прекодирование с использованием ортогонального преобразования не изменяет среднее значение ошибок при МСКО-оценивании. Однако, как показано в [26], на помехоустойчивость линейного приемника влияет не только среднее значение, но и максимальное значение дисперсий ошибок оценивания, а следовательно, и их разброс.
При постоянном среднем значении наименьшее значение максимальной дисперсии может быть достигнуто в том случае, когда все диагональные элементы одинаковы и равны среднему значению. Следовательно, нужно найти такой вид ортогонального преобразования, при котором все диагональные элементы матрицы ${\mathbf{\tilde {V}}}$ будут равны между собой.
Следует отметить, что ошибки оценивания символов, передаваемых на разных тактовых интервалах $n = \overline {1,{{N}_{{tx}}}} $ без прекодирования (6), принадлежат разным векторам и, в соответствии с (5), между собой не коррелированы, т.е. ошибки оценивания символов n-го вектора не коррелированы с ошибками оценивания m-го вектора при $n \ne m$ для любых элементов внутри этого вектора.
Кроме того, ошибки оценивания символов с разными номерами (разным положением внутри векторов) имеют различные дисперсии. Это обстоятельство предполагает возможность распределения символов так, чтобы уменьшить разброс дисперсий относительно среднего значения.
Рассмотрим следующий подход. Пусть имеется уравнение наблюдения:
где $z$ – M-мерный оцениваемый вектор, ${\mathbf{F}}$ – ортогональная матрица, размером $\left( {M \times M} \right)$, ${\mathbf{\mu }}$ – вектор ошибок оценивания с нулевым математическим ожиданием и диагональной корреляционной матрицей с разными диагональными элементамиКорреляционная матрица ошибок оценивания вектора ${\mathbf{z}}$ будет равна:
(11)
${\mathbf{V}} = {{\left( {{{{\mathbf{F}}}^{H}}{\mathbf{R}}_{{{\mu }}}^{{ - 1}}{\mathbf{F}} + {{{\mathbf{I}}}_{M}}} \right)}^{{ - 1}}} = {{{\mathbf{F}}}^{H}}{{\left( {{\mathbf{R}}_{{{\mu }}}^{{ - 1}} + {{{\mathbf{I}}}_{M}}} \right)}^{{ - 1}}}{\mathbf{F}}.$С учетом того, что матрица ${{{\mathbf{R}}}_{{{\mu }}}}$ является диагональной и на основании соотношения (11) для диагональных элементов корреляционной матрицы ${\mathbf{V}}$ можно записать следующее выражение:
(12)
${{v}^{{\left( {i,i} \right)}}} = \mathop \sum \limits_{j = 1}^M \left( {\frac{{{{r}^{{\left( {j,j} \right)}}}}}{{1 + {{r}^{{\left( {j,j} \right)}}}}}} \right){{\left| {{{f}^{{\left( {j,i} \right)}}}} \right|}^{2}},$Из выражения (12) следует условие, при котором обеспечивается равенство всех диагональных элементов ${{v}^{{\left( {i,i} \right)}}}$ корреляционной матрицы ошибок оценивания:
(13)
${{\left| {{{f}^{{\left( {j,i} \right)}}}} \right|}^{2}} = \frac{1}{M},\,\,\,\,i = \overline {1,M} ,\,\,\,\,j = \overline {1,M} .$В этом случае получим ${{v}^{{\left( {i,i} \right)}}} = {{v}^{{\left( {j,j} \right)}}} = {{\bar {v}}_{d}}$ для всех $i = \overline {1,M} ,\,\,j = \overline {1,M} $. Следовательно, для этого варианта $\mathop {\max }\limits_{i = \overline {1,{{N}_{{tx}}}} } \left( {{{v}^{{\left( {i,i} \right)}}}} \right) = {{\bar {v}}_{d}}$ будет минимально возможным для данных условий.
Таким образом, условие (13) определяет требование к ортогональному преобразованию, при котором обеспечивается равенство всех дисперсий ошибок оценивания. Но это условие не единственное. Другим условием, которое учитывалось при выводе выражения (13), является некоррелированность ошибок оценивания. Это условие обеспечивается тем, что символы каждого преобразованного вектора должны будут передаваться на разных тактовых интервалах. В результате получится ${{N}_{{tx}}}$ векторов, размером $\left( {{{N}_{{tx}}} \times 1} \right)$ каждый, для которых обеспечивается некоррелированность ошибок оценивания. Но и этого условия еще недостаточно. Например, если все символы преобразованного вектора передавать на разных тактах, но через одну антенну, то согласно выражению (6) ошибки оценивания этих символов будут иметь одинаковую дисперсию и в этом случае эффекта разнесения не будет. Поэтому необходимо, чтобы каждый символ преобразованного вектора передавался разными антеннами.
Можно предложить разные способы генерации последовательных номеров антенн и тактов, по которым распределяются прекодированные символы, чтобы обеспечить выполнение всех перечисленных условий. Например, можно использовать простой набор циклических сдвигов, а именно, для первого прекодированного вектора ${\mathbf{F}}{{{\mathbf{x}}}_{1}}$ используется последовательность $\left\{ {1,~2,~ \ldots ,{{N}_{{tx}}}} \right\}$, которая означает, что первый элемент прекодированного вектора передается на первом такте через первый пространственный канал (первую излучающую антенну), второй элемент этого вектора передается на втором такте через второй пространственный канал, и т.д. Следующая последовательность образуется путем циклического сдвига на один элемент, т.е. получается $\left\{ {2,~3,...,{{N}_{{tx}}},1} \right\}$. Она определяет распределение элементов второго прекодированного вектора и показывает, что первый элемент этого вектора передается на первом такте через вторую излучающую антенну, второй элемент – на втором такте через третью излучающую антенну, и так далее.
Такой алгоритм распределения является достаточно простым, но можно предложить и другие, использующие некоторую случайность. Например, можно использовать псевдослучайные числовые последовательности на основе первообразных корней и простых чисел [23]. Для этого сначала выбирается первое простое число, удовлетворяющее условию ${{N}_{s}} > {{N}_{{tx}}}$, и находится первообразный корень $\alpha < {{N}_{{tx}}}$. Последовательность номеров для первого прекодированного вектора будет определяться следующим алгоритмом: ${{I}_{n}} = {{\left[ {\alpha {{I}_{{n - 1}}}} \right]}_{{\bmod {{N}_{s}}}}}$, $n = \overline {1,{{N}_{{tx}}}} $, при начальных условиях ${{I}_{1}} = \alpha $. Так, например, для ${{N}_{{tx}}} = 4$ имеем ${{N}_{s}} = 5,\,\,\alpha = 2$ и генерируемая последовательность будет $\left\{ {2,4,3,1} \right\}$. Для последующих прекодированных векторов последовательность формируют путем циклических сдвигов исходной последовательности.
На рис. 2 приведена блок-схема предлагаемого алгоритма ортогонального прекодирования и распределения символов преобразованных векторов по разным тактовым интервалам и разным пространственным каналам.
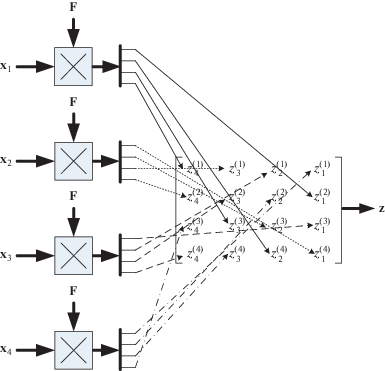
Использование псевдослучайных последовательностей позволяет избежать закономерностей в общей корреляционной матрице ошибок, которые могут проявиться неожиданным образом, например появлением блоков сильно коррелированных символов. Отметим, что дополнительную рандомизацию можно также ввести путем использования различных ортогональных матриц.
3. ОБРАБОТКА СИГНАЛА НА ПРИЕМНОЙ СТОРОНЕ
Предложенный метод ортогонального прекодирования предназначен для обработки расширенного вектора модулированных символов ${\mathbf{\tilde {x}}}$, размером $\left( {N_{{tx}}^{2} \times 1} \right)$. Для оценивания всех символов используется расширенное наблюдение ${\mathbf{\tilde {y}}}$, размером $\left( {{{N}_{{tx}}}{{N}_{{rx}}} \times 1} \right)$. Оперирование векторами с большой размерностью предполагает увеличение сложности реализации приемника. Рассмотрим, насколько увеличивается сложность обработки при использовании предложенного алгоритма прекодирования.
С учетом приведенных в разд. 2 преобразований модель наблюдения может быть записана в следующем виде:
(14)
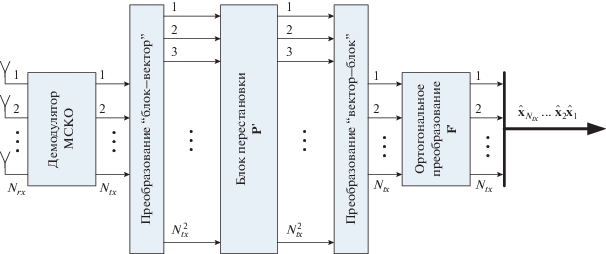
${\mathbf{\tilde {y}}} = {\mathbf{\tilde {H}\tilde {P}\tilde {F}\tilde {x}}} + {\mathbf{\eta }},$Матрица перестановок ${\mathbf{\tilde {P}}}$, размером $\left( {N_{{tx}}^{2} \times N_{{tx}}^{2}} \right)$, осуществляет распределение символов после ортогонального преобразования в соответствии с правилами перестановок, описанных в разд. 2. Для этой матрицы справедливо условие ${{{\mathbf{\tilde {P}}}}^{T}}{\mathbf{\tilde {P}}} = {\mathbf{\tilde {P}}}{{{\mathbf{\tilde {P}}}}^{T}} = {{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}$.
Для модели (14) алгоритм оценивания по критерию МСКО описывается выражениями, аналогичными выражениям (9):
(15)
$\begin{gathered} {\mathbf{\tilde {x}}} = {{\left( {{{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {P}}}}}^{H}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}\tilde {P}\tilde {F}}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {P}}}}}^{H}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {y}}} = \\ = {{{{\mathbf{\tilde {F}}}}}^{H}}{{{{\mathbf{\tilde {P}}}}}^{H}}{{\left( {{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {y}}}. \\ \end{gathered} $Нетрудно показать, что:
(16)
$\begin{gathered} {{{{\mathbf{\tilde {K}}}}}_{{МСКО}}} \triangleq {{\left( {{{{{\mathbf{\tilde {H}}}}}^{H}}{\mathbf{\tilde {H}}} + \frac{1}{\rho }{{{\mathbf{I}}}_{{N_{{tx}}^{2}}}}} \right)}^{{ - 1}}}{{{{\mathbf{\tilde {H}}}}}^{H}} = \\ = \left[ {\begin{array}{*{20}{c}} {{{{\mathbf{K}}}_{{МСКО}}}}&{\mathbf{O}}& \cdots &{\mathbf{O}} \\ {\mathbf{O}}&{{{{\mathbf{K}}}_{{МСКО}}}}& \cdots &{\mathbf{O}} \\ \vdots & \vdots & \ddots & \vdots \\ {\mathbf{O}}&{\mathbf{O}}& \cdots &{{{{\mathbf{K}}}_{{МСКО}}}} \end{array}} \right], \\ \end{gathered} $Учитывая блочно-диагональную структуру матрицы ${{{\mathbf{\tilde {K}}}}_{{{\text{МСКО}}}}}$ и матрицы ${\mathbf{\tilde {F}}}$, можно записать алгоритм вычисления оценки вектора ${{{\mathbf{x}}}_{n}}:$
На рис. 3 приведена структурная схема линейного демодулятора МСКО для системы MIMO с ортогональным прекодированием, предложенным в данной статье. Здесь хорошо видно, что по сравнению с обычным приемником МСКО для простой системы с пространственным мультиплексированием среди добавленных блоков, требующих выполнения каких-либо математических операций, можно отметить только блок ортогонального преобразования. Сложность реализации этого блока при использовании быстрых преобразований пропорциональна ${{N}_{{tx}}}{{\log }_{2}}{{N}_{{tx}}}$, что практически не изменит сложность всего приемника, так как реализация обычного алгоритма МСКО требует $ \sim {\kern 1pt} N_{{tx}}^{3}$ операций.
4. МОДЕЛИРОВАНИЕ
Для проверки эффективности предложенного метода было проведено моделирование разработанного алгоритма с ортогональным прекодированием.
Условия моделирования:
1) MIMO-канал с независимыми релеевскими замираниями;
2) модуляция QPSK;
3) турбокодирование со скоростью 3/4;
4) длина кадра 576 бит.
На рис. 4 приведены зависимости вероятности битовой ошибки ${{P}_{{{\text{бит}}}}}$ без кодирования (а) и вероятности ошибки на кадр ${{P}_{{{\text{кадр}}}}}~$ с кодированием (б) для MIMO-системы 4 × 4 с обычным пространственным мультиплексированием (кривая 1) и с предложенным ортогональным прекодированием (кривая 2) при использовании линейных алгоритмов МСКО.
Рис. 4.
Зависимости вероятности битовой ошибки без кодирования (а) и вероятности ошибки на кадр с кодированием (б) для MIMO-системы 4 × 4: с обычным пространственным мультиплексированием (1) и с предложенным ортогональным прекодированием (2).
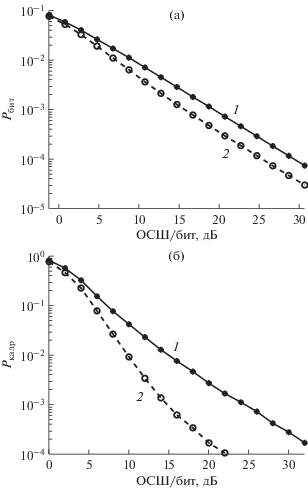
Из приведенных графиков видно, что для случая без кодирования выигрыш предлагаемого варианта с ортогональным прекодированием составляет ~3 дБ, а при кодировании выигрыш при FER = 0.01 (1%) составляет 5 дБ.
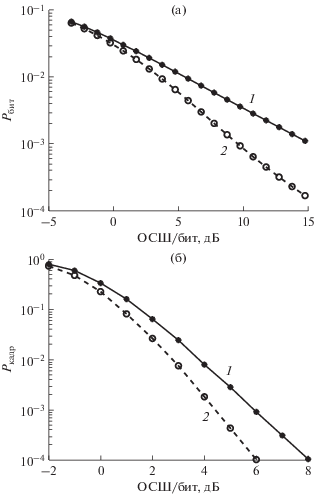
На рис. 5 представлены зависимости вероятности битовой ошибки Pбит без кодирования (а) и вероятности ошибки на кадр Pкадр с кодированием (б) для MIMO-системы 8 × 8: с обычным пространственным мультиплексированием (1) и с предложенным ортогональным прекодированием (2).
Рис. 5.
Зависимости вероятности битовой ошибки без кодирования (а) и вероятности ошибки на кадр с кодированием (б) для MIMO-системы 8 × 8: с обычным пространственным мультиплексированием (1) и с предложенным ортогональным прекодированием (2).
На рис. 6 приведены аналогичные кривые для конфигурации MIMO-канала 16 × 16.
Рис. 6.
Зависимости вероятности битовой ошибки без кодирования (а) и вероятности ошибки на кадр с кодированием (б) для MIMO-системы 16 × 16: с обычным пространственным мультиплексированием (1) и с предложенным ортогональным прекодированием (2).
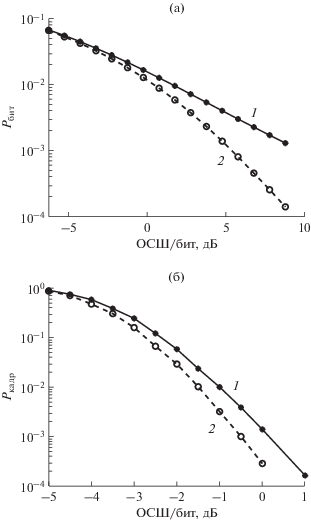
В данном случае выигрыш также наблюдается, но его величина меньше. Это объясняется тем, что при большом числе антенн уже имеется достаточно большое разнесение. Кривые приближаются к предельным характеристикам, определяемыми характеристиками гауссовского канала без замираний, поэтому дальнейшее увеличение порядка разнесения сказывается на помехоустойчивости в меньшей степени.
ЗАКЛЮЧЕНИЕ
Предложен метод ортогонального прекодирования, позволяющий получить дополнительный выигрыш в энергетической эффективности за счет увеличения порядка разнесения. Полученный алгоритм прекодирования оптимизирован для линейных алгоритмов приема пространственно-разнесенных сигналов, например такого, как алгоритм МСКО. При этом сложность обработки сигнала как на передающей, так и на приемной стороне практически не увеличивается.
Путем моделирования системы связи с MIMO-каналом с алгоритмами прекодирования, полученными предложенным методом, показано, что их использование позволяет получить энергетический выигрыш порядка 1.5 дБ при конфигурации MIMO-канала 8 × 8 и порядка 5 дБ при конфигурации 4 × 4.
Список литературы
Бакулин М.Г., Варукина Л.А., Крейнделин В.Б. Технология MIMO: принципы и алгоритмы. М.: Горячая линия – Телеком, 2014.
Dayal P., Varanasi M.K. // Proc. IEEE Global Telecommunications Conf. (GLOBECOM’03.), San Francisco. 1–5 Dec. 2003. N.Y.: IEEE, 2003. V. 4. P. 1946. https://doi.org/10.1109/GLOCOM.2003.1258577
Damen M.O., Abed-Meraim K., Belfiore J. // IEEE Trans. 2002. V. IT-48. № 3. P. 628. https://doi.org/10.1109/18.985979
Belfiore J., Rekaya G., Viterbo E. // Proc. Int. Symp. on Information Theory, 2004. (ISIT 2004). Chicago. 27 Jun.–2 Jul. N.Y.: IEEE 2004. P. 310. https://doi.org/10.1109/ISIT.2004.1365347
Lee S.J., Yeh Ch. I., Lim H. et al. // Report on IEEE 802.16’s Session #34. San Antonio. 15–18 Nov. 2004. N.Y.: IEEE, 11.11.2004. https://grouper.ieee.org/ groups/802/16/tge/contrib/C80216e-04_434r2.pdf
Hai H., Li C., Li J. et al. // Sensors 2021. V. 21. № 1. P. 109. https://dx.doi.org/10.3390/S21010109
Boccuzzi J. Signal Processing for Wireless Communications. N.Y.: McGraw-Hill, 2008.
Hampton J.R. Introduction to MIMO Communications. Cambridge: Univ. Press, 2014.
Ayach O.E., Rajagopal S., Abu-Surra S. et al. // IEEE Trans. 2014. V. WCOM-13. № 3. P. 1499. https://doi.org/10.1109/TWC.2014.011714.130846
Sampath H., Stoica P., Paulraj A. // IEEE Trans. 2001. V.COM-49. № 12. P. 2198. https://doi.org/10.1109/26.974266
Бакулин М.Г., Крейнделин В.Б., Шумов А.П. // РЭ. 2010. Т. 55. № 2. С. 206.
Бакулин М.Г. // Наукоемкие технологии. 2003. № 3. С. 18.
Бакулин М.Г., Крейнделин В.Б., Григорьев В.А. и др. // РЭ. 2020. Т. 65. № 3. С. 257.
Bakulin M., Kreyndelin V., Rog A. et al. // Internet of Things, Smart Spaces, and Next Generation Networks and Systems / Eds. O. Galinina, S. Andreev, S. Balandin, Y. Koucheryavy. Heidelberg: Springer, 2017. P. 550. https://doi.org/10.1007/978-3-319-67380-6_51
Recent Technical Developments in Energy-Efficient 5G Mobile Cells / Eds R.A. Abd-Alhameed, I. Elfergani, J. Rodriguez. Basel: MDPI, 2020.
Massive MIMO Systems / Ed. K. Maruta, F. Falcone. Basel: MDPI, 2020.
Liu L., Peng G., Wei Sh. Massive MIMO Detection Algorithm and VLSI Architecture. Beijing: Science Press, 2020.
Alkhateeb A., Leus G., Heath R.W. // IEEE Trans. 2015. V.WCOM-14. № 11. P. 6481. https://doi.org/10.1109/TWC.2015.2455980
Love D.J., Heath R.W. // IEEE Trans. 2005. V. IT-51. № 8. P. 2967. https://doi.org/10.1109/TIT.2005.850152
Куликов Г.В., Тамбовский С.С., Савватеев Ю.И., Гребенко Ю.А. // РЭ. 2019. Т. 64. № 2. С. 152.
Wang Y., Wu H., Li H. // J. Commun. Technol. and Electronics. 2015. V. 60. № 8. P. 890. https://doi.org/10.1134/S1064226915080197
Бакулин М.Г., Крейнделин В.Б. Панкратов Д.Ю. Технологии в системах радиосвязи на пути к 5G. М.: Горячая линия – Телеком, 2018.
Effinger G., Mullen G.L. Elementary Number Theory. Boca Raton: Chapman and Hall/CRC. https://doi.org/10.1201/9781003193111
George A. Seber F. A Matrix Handbook for Statisticians. New Jersey: John Wiley, 2007.
Golub G.H., Van Loan C.F. Matrix Computations. Baltimore: Johns Hopkins Univ. Press, 2013.
Резнев А.А., Крейнделин В.Б. // Электросвязь. 2020. № 2. С. 59.
Дополнительные материалы отсутствуют.
Инструменты
Радиотехника и электроника