

Известия РАН. Теория и системы управления, 2019, № 4, стр. 144-155
Обратная связь в прогнозирующей модели реакционно-ректификационного технологического процесса
В. В. Климченко a, *, С. А. Самотылова a, А. Ю. Торгашов a
a Институт автоматики и процессов управления ДВО РАН,
Дальневосточный федеральный ун-т
Владивосток, Россия
* E-mail: volk@iacp.dvo.ru
Поступила в редакцию 08.08.2017
После доработки 14.03.2019
Принята к публикации 25.03.2019
Аннотация
Рассматривается задача оценки параметров модели для прогнозирования показателя качества выходного продукта массообменного технологического процесса. В математической модели используется контур обратной связи по ошибке прогноза выходной переменной. Показано, что данный подход повышает точность идентификации технологического объекта. Полученная прогнозирующая модель предназначена для применения в составе усовершенствованной системы управления технологическим процессом.
Введение. Внедрение систем усовершенствованного управления технологическими процессами (СУУ ТП) позволяет промышленным компаниям нефтепереработки и нефтехимии существенно улучшить технико-экономические показатели функционирования производства [1]. В большинстве случаев управление и контроль качества выходных продуктов технологического процесса осуществляется на основе лабораторных анализов. Данный способ является дорогостоящим и отнимает много времени, что приводит к длительным временным задержкам измерений и неэффективному управлению технологическим процессом.
В настоящее время широкое распространение в составе СУУ ТП получили модели для прогнозирования показателей качества выходных продуктов в режиме реального времени. Такие прогнозирующие модели также называются виртуальными анализаторами [2]. Они описывают технологический процесс посредством связи измеряемых технологических параметров (температура, давление, расход) с результатами лабораторных анализов выходной переменной и могут быть интегрированы в СУУ ТП с использованием специализированного программного обеспечения. На основании заданных критериев в СУУ ТП с помощью прогнозирующей модели формируется оптимальное управляющее воздействие [3].
При построении прогнозирующих моделей приходится сталкиваться с различными проблемами, в том числе с зашумленностью и отсутствием данных измеряемых технологических параметров, а также с их выбросами и мультиколлинеарностью (т.е. с наличием сильной корреляции между регрессорами) [4]. Большинство прогнозирующих моделей основано на методах математической статистики, таких, как многомерная регрессия, регрессия на главных компонентах, проекции на латентные (скрытые) структуры (ПЛС). Для разработки прогнозирующих моделей также могут быть использованы методы машинного обучения, такие, как искусственные нейронные сети, метод опорных векторов и др. [5].
Широкое распространение при построении прогнозирующих моделей получил метод ПЛС. Преимуществами данного метода является способность обрабатывать большое количество коррелированных переменных [6].
Нейронные сети часто используют, когда в данных присутствует нелинейность исследуемого процесса [6]. Выходной сигнал определяется нелинейной функцией взвешенной суммы входных сигналов, которые представляют собой выходные сигналы нейронов предыдущего слоя. Основной недостаток данного подхода заключается в частом переобучении (излишне точным соответствием нейронной сети конкретному набору обучающих примеров, при котором сеть теряет точность прогнозирования на тестовой выборке данных).
Многие работы по построению прогнозирующих моделей посвящены технологическим процессам, относящимся к первичной переработке нефти. Такие процессы, как правило, представляют собой несколько последовательно соединенных ректификационных колонн. Процессы реакционно-ректификационного типа практически не рассмотрены, в то время как они широко используются для получения различных продуктов органического и нефтехимического синтеза. Особенность совмещенных реакционно-ректификационных процессов заключается в совместном протекании обратимой химической реакции с частичным или практически полным разделением образующейся смеси посредством ее ректификации. Для данного типа процессов наибольшее распространение получили прогнозирующие модели на основе нейронных сетей. В [7] рассмотрена разработка прогнозирующей модели с использованием искусственной нейронной сети на основе алгоритма Левенберга–Марквардта. В [8] для построения прогнозирующей модели применяли рекуррентную нейронную сеть для идеальной реакционно-ректификационной колонны. Такая модель позволяет учитывать не только текущие значения входных переменных, но и их предшествующие значения.
В [9] был рассмотрен алгоритм обучения нейронной сети методом обратного распространения выходной ошибки на веса промежуточных нейронов. Коррекция весов проводилась методом наискорейшего спуска, пока не будет достаточно уменьшена среднеквадратическая ошибка. Полученная модель была протестирована на реакционно-ректификационном процессе синтеза пропилпротионата. Недостаток метода заключается в сложности интерпретации физико-химического смысла рассчитанных значений весов нейронной сети.
В отличие от традиционных подходов, в данной работе используется контур обратной связи по ошибке прогноза выходной переменной в прогнозирующей модели реакционно-ректификационного блока технологического объекта. Показано, что, несмотря на отсутствие обратных связей в реальном управляемом объекте, предлагаемый подход существенно повышает точность прогнозирования показателей качества выходного продукта реакционно-ректификационного процесса.
1. Описание технологического объекта и прогнозирующей модели. Реакционно‑ректификационный процесс (рис. 1) представляет собой две ректификационные колонны (К-1 и К-2) и расположенный между ними реактор синтеза (РС) с тремя слоями свежего катализатора. В качестве сырья в РС подается реакционная смесь, полученная на отработанном катализаторе реактора форконтактной очистки сырья (РФ). Реакционная смесь подается в РС под нижний слой катализатора, откуда отходящие пары поступают в ректификационную колонну К-1, сверху которой отводится дистиллят (Д), а реакционная смесь РС поступает в нижнюю ректификационную колонну К-2. Для построения модели, предсказывающей содержание примесей в выходном (кубовом) продукте (КП), использовались измеряемые технологические переменные: u(1) – расход орошения К-1 (F1); u(2) – расход реакционной массы, поступающей в К-2 (F2); u(3) – давление низа РФ (P1); u(4) – давление низа РС (P2); u(5) –температура низа колонны К-2 (T1); u(6) – температура паров с К-2 (T2); u(7) – температура на 5-й ступени К-2 (T3).

Качество прогнозирующей модели зависит от данных, которые используются для ее построения. Обычно они хранятся в базе данных завода и не обладают достаточным объемом информации, так как могут содержать выбросы, а в данных, полученных лабораторным путем, неизвестно точное время отбора проб [10]. Также в реальных условиях довольно редко удается наблюдать статический режим технологического объекта, и обучающая выборка может содержать данные динамического режима. Для учета динамических свойств исследуемого технологического объекта его выходная переменная ${{y}_{t}}$ может быть представлена как свертка входного сигнала и импульсной характеристики [11]. Ошибка модели ${{e}_{t}}$ является разностью между наблюдаемым значением выходной переменной ${{y}_{t}}$ и значением, предсказанным по модели ${{\hat {y}}_{t}}$, поэтому измеренное значение можно представить в виде:
(1.1)
${{y}_{t}} = {{\hat {b}}_{0}} + \sum\limits_{i = 1}^N {\sum\limits_{k = 1}^h {\hat {b}_{k}^{{(i)}}u_{{t - k}}^{{(i)}}} } + {{e}_{t}},$Уравнение модели имеет следующий вид:
(1.2)
${{\hat {y}}_{t}} = {{\hat {b}}_{0}} + \sum\limits_{k = 1}^{30} {\hat {b}_{k}^{{(1)}}u_{{t - k}}^{{(1)}}} + \sum\limits_{k = 1}^{30} {\hat {b}_{k}^{{(2)}}u_{{t - k}}^{{(2)}}} + \ldots + \sum\limits_{k = 1}^{30} {\hat {b}_{k}^{{(7)}}u_{{t - k}}^{{(7)}}} ,$Набор входных переменных модели (1.2) может быть представлен в виде вектора ${\mathbf{\tilde {u}}}$ = = ${{({{\tilde {u}}_{1}} \ldots {{\tilde {u}}_{c}} \ldots {{\tilde {u}}_{{Nh}}})}^{{\text{т }}}}$, элементы которого формируются следующим образом:
Теснота связи между переменными (регрессорами) вектора ${\mathbf{\tilde {u}}}$ определялась с помощью парных коэффициентов корреляции Пирсона. Коэффициент корреляции rcd для каждой пары входных переменных оценивался по формуле [12]
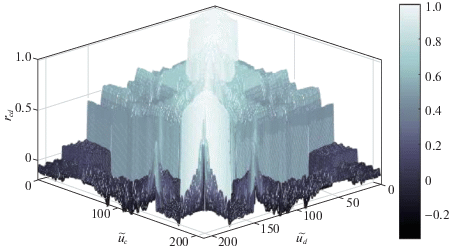
Из рис. 2 очевидно, что между регрессорами присутствует линейная зависимость (мультиколлинеарность), так как довольно много значений ${{r}_{{cd}}}$ находятся в интервале (0.4, 0.7), а также присутствуют области корреляционной матрицы, где наблюдается сильная (${{r}_{{cd}}} > 0.7$) теснота связи. Для построения моделей технологических объектов в условиях мультиколлинеарности широкое распространение получил метод ПЛС [13, 14]. В этом методе проводится одновременная декомпозиция матрицы значений входных переменных:
Для построения матриц счетов и нагрузок используется описанный ниже алгоритм. Перед началом алгоритма нормированные входные переменные U и Y центрируются следующим образом:
На данном этапе также выбирается максимальное количество главных компонент A таким образом, чтобы оно не превышало количество входных переменных в модели ($A \leqslant Nh$). Для каждой главной компоненты с номером $a = 1,\; \ldots ,\;A$ выполняются шаги 1–6.
Изначально принимаем ${{E}_{{a - 1}}} = {{U}_{0}}$, ${{F}_{{a - 1}}} = {{Y}_{0}}$ и a = 1. Далее выполняется ниже описанный алгоритм.
Шаг 1. Вычисляем вектор взвешенных нагрузок ${{w}_{a}}$:
Шаг 2. Нормировка вектора взвешенных нагрузок ${{w}_{a}}$ осуществляется следующим образом:
Шаг 3. Счета матрицы U – ${{с }_{a}}$ определяются как
Шаг 4. На данном шаге рассчитываются U-нагрузки – ${{p}_{a}}$:
Шаг 5. Расчет Y-нагрузок – ${{q}_{a}}$ производим следующим образом:
Шаг 6. Вычисляем остатки ${{E}_{a}} = {{U}_{{a - 1}}} - {{с }_{a}}p_{a}^{{\text{T}}}$ и ${{F}_{a}} = {{Y}_{{a - 1}}} - {{с }_{a}}{{q}_{a}}$. Увеличиваем номер главной компоненты на единицу $a: = a + 1$ и повторяем описанные выше шаги.
Шаг 7. После достижения равенства a = A вычисляются коэффициенты регрессии $\hat {B} = W{{({{P}^{{\text{T}}}}W)}^{{ - 1}}}{{Q}^{{\text{T}}}}$, где $W$ – матрица со столбцами, состоящими из ${{\tilde {w}}_{a}}$-векторов:
Для оценки качества полученной модели на конечном интервале времени были использованы коэффициент детерминации (R2), среднеквадратическая ошибка (СКО), а также информационный критерий Байеса–Шварца (BSC). Описанные выше критерии рассчитывались по следующим формулам.
1. Коэффициент детерминации:
(1.3)
${{R}^{2}} = 1 - {{\sum\limits_{i = 1}^M {{{{({{y}_{i}} - {{{\hat {y}}}_{i}})}}^{2}}} } \mathord{\left/ {\vphantom {{\sum\limits_{i = 1}^M {{{{({{y}_{i}} - {{{\hat {y}}}_{i}})}}^{2}}} } {\sum\limits_{i = 1}^M {{{{({{y}_{i}} - \bar {y})}}^{2}}} }}} \right. \kern-0em} {\sum\limits_{i = 1}^M {{{{({{y}_{i}} - \bar {y})}}^{2}}} }}.$2. СКО:
(1.4)
$С К О = {{\left( {{{\sum\limits_{i = 1}^M {{{{({{y}_{i}} - {{{\hat {y}}}_{i}})}}^{2}}} } \mathord{\left/ {\vphantom {{\sum\limits_{i = 1}^M {{{{({{y}_{i}} - {{{\hat {y}}}_{i}})}}^{2}}} } M}} \right. \kern-0em} M}} \right)}^{{1/2}}}.$3. Информационный критерий Байеса–Шварца:
(1.5)
${\text{BSC}}(p) = M\ln (SS{{\left( {RES{\text{'}}} \right)}_{N}}) + p\ln \left( M \right) - M\ln \left( M \right).$В (1.3)–(1.5) ${{y}_{i}}$ – наблюдаемое значение выходной переменной, ${{\hat {y}}_{i}}$ – ее значение, полученное по модели объекта, SS(RES′)N – сумма квадратов остатков, $p = N + 1$ (N – число независимых переменных). Чем меньше значения BSC и СКО и чем ближе к единице значение R2, тем лучше построенная модель соответствует исследуемому объекту.
2. Идентификация прогнозирующего фильтра в контуре обратной связи. Для повышения точности прогнозов (снижения дисперсии погрешности е) в модель был включен контур обратной связи (рис. 3). На этой схеме B(u) – символическое обозначение оператора реального объекта; $\hat {B}$ – оператор модели (1.2); $\hat {y}_{t}^{*}$ – скорректированный выход модели; q–1 – оператор сдвига на один шаг назад; $F({{q}^{{ - 1}}})$ – передаточная функция фильтра; ${{\hat {e}}_{t}}$ – прогноз ошибки et.
Рис. 3.
Прогнозирующая модель с обратной связью: ◼ – технологический объект, □ – прогнозирующий фильтр
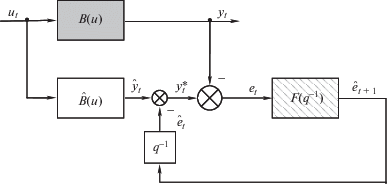
Включение обратной связи на первый взгляд представляется необоснованным, поскольку зависимость между входными и выходными переменными технологического объекта носит причинно-следственный характер и моделируемая установка не содержит обратных связей. Тем не менее, использование контура обратной связи в модель зачастую позволяет повысить точность прогнозирования (уменьшить СКО прогноза). Исключение составляет лишь случай отсутствия сериальной корреляции в последовательности ошибок прогноза, получаемого при помощи модели (1.2). Иными словами, обратная связь не оказывает влияния на точность прогноза, если без нее модель генерирует ошибки e1, e2 …, последовательность которых является белым шумом. В противном случае можно идентифицировать передаточную функцию фильтра F(q–1), выход которого в каждый момент времени t является прогнозом будущей ошибки ${{\hat {e}}_{{t + 1}}}$, причем ${\text{M}}[{{\left( {{{e}_{{t + 1}}} - {{{\hat {e}}}_{{t + 1}}}} \right)}^{2}}] < {\text{M}}[e_{{t + 1}}^{2}]$ [15]. При этом желательно предварительно преобразовать прогнозируемую случайную величину к гауссовской, поскольку большинство статистических процедур обеспечивают оптимальные результаты именно для нормально распределенных величин.
На рис. 4 представлена гистограмма ошибок модели (1.2). Символом Ji обозначено количество остатков, величина которых попала в i-й интервал; n – общее количество остатков; $\Delta = 0.3$ – ширина интервалов.
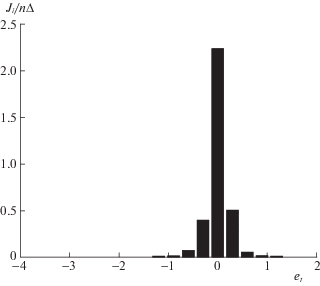
Гистограмма наводит на мысль о том, что плотность распределения случайной величины $\text{v}$ = 1.5 – et можно аппроксимировать плотностью гамма-распределения, параметры которого были оценены в среде Matlab:
(2.1)
${{f}_{\text{v}}}(\text{v}) \approx \frac{1}{{{{{0.065}}^{{20.79}}}\Gamma (20.79)}}{{\text{v}}^{{19.79}}}{\text{exp(}}{\kern 1pt} - {\kern 1pt} \text{v}{\text{/}}0.065{\text{),}}$Интегральную функцию распределения величины $\text{v}$ обозначим через ${{F}_{\text{v}}}(\text{v})$. Если теперь записать интегральную функцию распределения стандартизованной нормальной величины как FN(·) (соответственно $F_{N}^{{ - 1}}$ – функция, обратная к FN), то величину zt = g(et) = $F_{N}^{{ - 1}}$(${{F}_{\text{v}}}$(1.5 – et)) можно приближенно считать распределенной по нормальному закону с нулевым средним и единичной дисперсией.
Для временного ряда zt была построена модель авторегрессии-скользящего среднего (АРСС) порядка (Nη, Nθ), т.е. модель вида
Порядок модели был выбран путем оценки точности прогнозов на обучающей выборке при каждом из сочетаний (Nη, Nθ). С этой целью использовалась функция “pem” (prediction error model) в вычислительной среде Matlab. Эта функция оценивает параметры прогнозирующей модели по критерию СКО прогнозов (заметим, что если выборка исходных данных подчинена нормальному закону распределения вероятностей, то оценки параметров, найденные методом наименьших квадратов, являются оценками максимального правдоподобия). В результате наилучшей оказалась модель АРСС порядка (2, 1) при η1 = –0.9766 ± 0.4736; η2 = 0.1664 ± 0.225; θ1 = = –0.6164 ± 0.383; $\sigma _{\varepsilon }^{2} = {\text{0}}{\text{.8394}}$ ± 0.0833 (для оценок параметров указаны границы 95%-ных доверительных интервалов).
Таким образом, для прогнозирования использовалась модель
Воспользовавшись оператором сдвига на один шаг назад q–1, полученную модель можно представить в виде
(2.2)
$(1--0.9766{{q}^{{--1}}} + 0.1664{{q}^{{--2}}}){{z}_{t}} = (1--0.6164{{q}^{{--1}}}){{\varepsilon }_{t}},$(2.3)
${{\hat {z}}_{{t + 1}}} = \left( {1 - \frac{{1 - 0.9766{{q}^{{ - 1}}} + 0.1664{{q}^{{ - 2}}}}}{{1 - 0.6164{{q}^{{ - 1}}}}}} \right){{z}_{t}}.$Условное распределение величины zt + 1 при известных zt, zt – 1, zt – 2 … является нормальным распределением с математическим ожиданием ${{\hat {z}}_{{t + 1}}}$ и дисперсией ${\sigma }_{{\varepsilon }}^{2}$ [15]. Поэтому, принимая за прогноз невязки et + 1 условное математическое ожидание этой величины, найдем
Эффективность модели прогнозирующего фильтра, полученной в результате анализа данных обучающей выборки, оценивалась на данных тестовой выборки. Результаты прогнозов иллюстрируются на рис. 5: сплошной линией изображены ошибки et, пунктирной – их прогнозные значения.

Каждому моменту времени t (ось абсцисс) соответствует ошибка модели без обратной связи et и ее прогноз ${{\hat {e}}_{t}}$, вычисленный в момент (t – 1).
Результаты расчета критериев идентификации модели с отсутствием обратной связи и ее включением в модель на обучающей и проверочной выборках приведены в таблице.
Таблица.
Результаты вычислений критериев качества идентификации
| Прогнозирующая модель | R2 | СКО | BSC |
|---|---|---|---|
| Обучающая выборка | |||
| Без обратной связи | 0.4957 | 0.2996 | –546.0 |
| С обратной связью | 0.5637 | 0.2785 | –636.9 |
| Проверочная выборка | |||
| Без обратной связи | 0.3176 | 0.2346 | 503.9 |
| С обратной связью | 0.4502 | 0.2023 | 497.8 |
Оценка СКО модели с обратной связью, вычисленная по тестовой выборке данных, оказалась на (0.2346 – 0.2023)/0.2346 = 0.1377 ≈ 14% меньше, чем СКО модели без обратной связи.
3. Анализ остаточных ошибок. Как показано в предыдущем разделе, использование сериальной корреляции в последовательности ошибок модели (1.2) e1, e2, …, en позволяет прогнозировать ошибку et + 1, если известны ошибки et, et – 1, et – 2, …, e1. Вычисленное прогнозное значение ${{\hat {e}}_{{t + 1}}}$ можно использовать в качестве поправки, повышающей точность предсказания выходной переменной ${{y}_{t}}$. В связи с этим возникает вопрос: возможно ли дальнейшее повышение точности путем предсказания ошибок прогнозирующего фильтра (2.3)? Для ответа на этот вопрос необходим анализ ошибок рассматриваемого фильтра. Если такое исследование не выявляет статистически значимой зависимости между этими величинами, то знание предыдущих ошибок не дает информации о будущих ошибках и, следовательно, уточнение прогноза невозможно.
Из соотношений (2.2) и (2.3) следует [15]
Интересующую нас спектральную плотность можно исследовать при помощи периодограммы второго порядка выборки ε1, ε2, …, εn [16]:
Определим целое число m как (n – 1)/2 при нечетном n, при n четном полагаем m = (n – 2)/2. Если εt, $t = \overline {1,n} $, – взаимно независимые случайные величины с дисперсией ${\sigma }_{{\varepsilon }}^{2}$, то величины $4{\pi }{{I}_{k}}{/\sigma }_{{\varepsilon }}^{2}$, $k = \overline {1,m} $, также независимы и подчинены распределению $\chi $-квадрат с двумя степенями свободы [16].
Теперь рассмотрим меру отклонения эмпирической функции распределения Fm от теоретической Fχ:
Функция распределения случайной величины $\sqrt m {{D}_{m}}$ при больших m (при m > 20) близка к функции распределения Колмогорова K(x) [17]:
Для вычисления этой функции при любых значениях аргумента разработаны эффективные алгоритмы [18]. В частности, K(1.02) = 0.75; K(1.36) = 0.95. В рассматриваемом случае m = 400, поэтому вероятность того, что случайная величина Dm примет значение, превышающее 1.02/20, равна 1 – 0.75 = 0.25. Соответственно вероятность того, что Dm окажется больше, чем 1.36/20, равна 1 – 0.95 = 0.05.
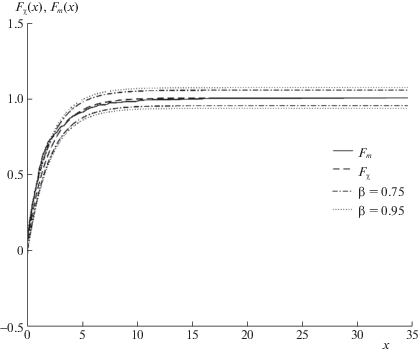
Рисунок 6 иллюстрирует применение критерия Колмогорова для проверки гипотезы о постоянстве спектральной плотности ошибок εt. Сплошной линией изображена эмпирическая функция Fm, пунктирной – гипотетическая функция Fχ, штрихпунктирной – границы 75%-ного доверительного интервала (β = 0.75), пунктиром из точек – границы 95%-ного доверительного интервала (β = 0.95).
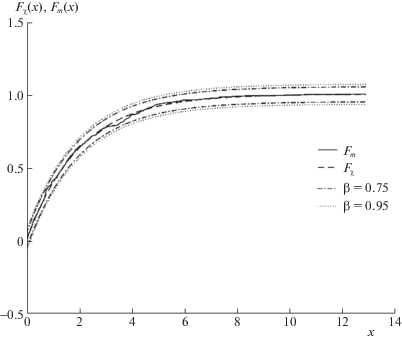
Эмпирическая функция распределения не пересекает границу интервала, соответствующего доверительной вероятности β = 0.75. Следовательно, гипотезу о постоянстве спектральной плотности ошибок εt можно считать согласованной с экспериментальными данными.
Для сравнения на рис. 7 представлен результат проверки гипотезы о постоянстве спектральной плотности ошибок модели без обратной связи.
Эмпирическая функция распределения пересекает границу доверительного интервала, соответствующего уровню доверия β = 0.95. Таким образом, проверяемую гипотезу следует отклонить, поскольку вероятность выхода за эту границу при условии постоянного спектра достаточно мала: 1 – 0.95 = 0.05.
Заключение. Использование контура обратной связи в модели технологического процесса позволило уменьшить СКО прогноза, несмотря на то, что реальная моделируемая установка не содержит обратных связей. Сравнение предсказанных значений с фактическими (рис. 5) показывает, что построенная модель прогнозирующего фильтра (2.3) дает неплохие прогнозы на “спокойных” (с небольшим и приблизительно постоянным разбросом) временных интервалах. Что же касается интервалов с “аномальными” значениями (Outliers), прогнозирующий фильтр, хоть и успешно предсказывает направление выбросов, допускает большую ошибку в предсказании их величины. По-видимому, свойства процесса et лучше описывались бы моделью с дополнительной составляющей в виде какого-либо (например, пуассоновского) потока событий (выбросов), но для оценки интенсивности потока выборка данных должна содержать хотя бы несколько десятков выбросов. Иными словами, судя по рис. 5, для рассматриваемого технологического объекта объем доступной для анализа выборки данных должен достигать не менее 1.5 тыс. измерений.
Список литературы
Дозорцев В.М., Ицкович Э.Л., Кнеллер Д.В. Усовершенствованное управление технологическими процессами (APC): 10 лет в России // Автоматизация в промышленности. 2013. № 1. С. 12–19.
Бахтадзе Н.Н. Виртуальные анализаторы (идентификационный подход) // АиТ. 2004. № 11. С. 3–24.
Fayruzov D.Kh., Bel’kov Yu.N., Kneller D.V., Torgashov A.Yu. Advanced Process Control System for a Crude Distillation Unit. A Case Study // Automation and Remote Control. 2017. V. 78. Iss. 2. P. 357–367.
Kadlec P., Gabrys B., Strandt S. Data-driven Soft Sensors in the Process Industry // Computers & Chemical Engineering. 2009. V. 33. P. 795–814.
Zhu J., Ge Z., Song Z. Robust Supervised Probabilistic Principal Component Analysis Model for Soft Sensing of Key Process Variables // Chemical Engineering Science. 2015. V. 122. P. 573–584.
Tun M.S., Lakshminarayanan S., Emoto G. Data Selection and Regression Method and its Application to Softsensing Using Multirate Industrial Data // Chemical Engineering of Japan. 2008. V. 41. № 5. P. 374–383.
Kataria G., Singh K., Dohare R.K. ANN Based Soft Sensor Model for Reactive Distillation Column // Advanced Technology and Engineering Exploration. 2016. V. 3(24). P. 182–186.
Raghavan S.R.V., Radhakrishnan T.K., Srinivasan K. Soft Sensor Based Composition Estimation and Controller Design for an Ideal Reactive Distillation Column // ISA Transactions. 2011. V. 50. P. 61–70.
Sakhre V., Jain S., Sapkal V.S., Agarwal D.P. Modified Neural Network Based Cascaded Control for Product Composition of Reactive Distillation // Chemical Technology. 2016. V. 18. № 2. P. 111–121.
Fortuna L., Graziani S., Xibilia M.G. Comparison of Soft-sensor Design Methods for Industrial Plants Using Small Data Sets // IEEE Transactions on Instrumentation and Measurement. 2009. V. 58. № 8. P. 2444–2451.
Torgashov A., Goncharov A., Zhuravlev E. Evaluation of Steady-State and Dynamic Soft Sensors for Industrial Crude Distillation Unit Under Parametric Constraints // IFAC-PapersOnLine. 2018. V. 51. Iss. 18. P. 566–571.
Asuero A.G., Sayago A., Gonzalez A.G. The Correlation Coefficient: an Overview // Critical Reviews in Analytical Chemistry. 2006. V. 36. P. 41–59.
Wold S., Sjostrom M., Eriksson L. PLS-regression: a Basic Tool of Chemometrics // Chemometrics and Intelligent Laboratory System. 2001. V. 58. P. 109–130.
De Jong S. SIMPLS: An Alternative Approach to Partial Least Squares Regression // Chemometrics and Intelligent Laboratory Systems. 1993. V. 18. P. 251–263.
Box G.E.P., Jenkins G.M., Reinsel G.C. Time Series Analysis: Forecasting and Control. 3-rd ed. Englewood Cliffs. N.J.: Prentice Hall, 1994. 680 p.
Бриллинджер Д.Р. Временные ряды. Обработка данных и теория / Пер. с англ. М.: Мир, 1980. 534 с.
Колмогоров А.Н. Об эмпирическом определении закона распределения // Теория вероятностей и математическая статистика / Под ред. Ю.В. Прохорова. М.: Наука, 1986. С. 134–141.
Marsaglia G., Tsang W.W., Wang J. Evaluating Kolmogorov’s Distribution // Statistical Software. 2003. V. 8. № 18. P. 1–4.
Дополнительные материалы отсутствуют.
Инструменты
Известия РАН. Теория и системы управления