

Теплоэнергетика, 2021, № 10, стр. 37-44
Модель раннего обнаружения аварийных ситуаций на оборудовании электростанций на основе метода наименьших потенциалов
А. А. Коршикова a, *, О. М. Идзон a
a ООО “Инконтрол”
115280 Москва, ул. Ленинская Слобода, д. 23, стр. 2, Россия
* E-mail: korshikova@inctrl.ru
Поступила в редакцию 02.12.2020
После доработки 12.01.2021
Принята к публикации 20.01.2021
Аннотация
Рассматривается метод обнаружения и предсказания аномальности функционирования оборудования энергоблоков на примере газотурбинной установки. Формулируется задача обнаружения аномальности функционирования как математическая задача моделирования критерия аномальности, принимающего значения от 0 до 1. Сделано предположение о возможности и эффективности применения методов предиктивной аналитики для прогнозирования будущего состояния технологического оборудования на основе существующего парка измерений без какого бы то ни было его увеличения. Предполагается, что, даже когда каждое отдельное измерение не выходит из диапазона, принятого за диапазон нормального функционирования, по их совокупной динамике можно судить о развивающемся дефекте, т.е. о переходе диагностируемого технологического оборудования (ДТО) в аномальную зону функционирования. Для решения поставленной задачи предложен подход, основанный на вычислении значения “показателя аномальности”, который можно интерпретировать как условный потенциал, создаваемый точками в многомерном пространстве признаков, характеризующих состояние оборудования в данный момент времени. Обучая модель на признаках, задающих области состояний (состояние нормальной эксплуатации и состояния для разного рода фиксированных дефектов), можно затем применить обученную модель для определения типа состояния: чем ближе значение показателя аномальности к значениям, присущим той или иной области функционирования, тем больше вероятность того, что состояние ДТО соответствует этой области. Показано, что в связи с определенными объективными обстоятельствами отсутствует практическая возможность обучения модели на данных, которые получены в периоды аномальной эксплуатации с конкретными видами дефектов ДТО. Это сводит задачу к адаптации метода к ситуации, когда в качестве обучающей имеется только область нормальной эксплуатации. Предложенная модель была обучена и протестирована в период нормального функционирования оборудования. Результат тестирования позволяет говорить о непротиворечивости предложенного метода (отсутствии ложноположительных реакций).
Во время работы технологического оборудования неизбежно происходят события, которые могут оказать негативное влияние на его производительность или даже привести к выходу из строя. Модель, предсказывающая будущую аварийную ситуацию, позволила бы своевременно предотвратить ее развитие и повысить тем самым эффективность использования технологического оборудования. Построением и исследованием таких моделей занимается предиктивная аналитика [1, 2].
Главная идея предиктивной аналитики в энергетике, по мнению авторов, состоит в том, что возникновение аварии можно с некоторой вероятностью предсказать, основываясь на непрерывном анализе совокупности данных, которые характеризуют функционирование диагностируемого оборудования и измеряются штатными средствами контроля.
Для определения состояния технологического оборудования применяют различные методы классификации [3], базирующиеся на многоклассовой и одноклассовой классификации.
Главная идея методов, основанных на многоклассовой классификации, состоит в построении классификатора нормальных и аномальных данных. В качестве примеров таких методов можно привести:
нейросетевые классификаторы [4];
статистические классификаторы, в частности байесовский подход, анализ распределений (применительно к оборудованию энергоблока рассматривается в статьях [5, 6]);
машинное обучение (деревья решений, SVM и пр.) [7].
Методы, в которых обучение базируется на прецедентах, предоставляют возможность диагностировать конкретные типы аварий, но их главный недостаток – это сложность, а часто и невозможность получения данных о возникших на энергоблоке дефектах и произошедших авариях. Поэтому для первичного выявления возможных отклонений в состоянии технологического оборудования перспективно применение методов, обучение которым не требует данных о прецедентах.
Идея методов, основанных на одноклассовой классификации, состоит в построении границы области нормальных данных. Все данные, лежащие вне этой области, считаются аномальными. Примерами таких методов могут быть:
нейросетевые классификаторы (автоэнкодеры и пр.) [8];
машинное обучение (one-class SVM, one-class Fisher Discriminant, MSET [9] и пр.).
Однако приведенные методы довольно сложны в реализации при высокой неоднозначности результата для энергетического оборудования.
Предиктивная диагностика, которая ориентирована на одноклассовую классификацию, может приводить к технически некорректным результатам анализа конкретной ситуации, так как удаление данных по этой ситуации от границ известной (ранее определенной) области нормальной эксплуатации не обязательно будет входом в реальную область аномальных данных и, соответственно, сигналом об аварийной ситуации. Возможно, это будет входом в ранее не зафиксированную нормальную область. Поэтому в такой системе возможны ложные сообщения о дефектной ситуации и для уменьшения их вероятности крайне желательно “дообучение” системы на верифицированных данных, которые имело диагностируемое оборудование в выбранный определенный период его работы с известными дефектами (далее обучение на периоде).
Описанный в настоящей статье метод предназначен для диагностики технологического оборудования энергоблоков, оснащенных средствами индивидуальных измерений, которые, с одной стороны, могут непосредственно диагностировать возникновение дефектов/неисправностей, но, с другой стороны, оказываются не в состоянии обнаружить дефекты на ранних стадиях их развития, а также тогда, когда эти дефекты вообще не проявляются при индивидуальных измерениях вплоть до возникновения аварии. Метод дает шанс на раннее обнаружение дефектов с помощью анализа как самих измеряемых параметров в их совокупности, так и статистических производных этих параметров. А в частном случае метод не требует обязательного наличия верифицированных периодов ДТО с известными неисправностями/дефектами, т.е. обучение может проводиться только на нормальных периодах работы ДТО. Проверка адекватности модели при таком подходе заключается в том, что в результате ее испытания на другом (необучающем) периоде нормальной эксплуатации критерий аномальности не должен выходить за заданные уставки, т.е. не выдавать ложноположительных прогнозов аномальности.
ПОСТАНОВКА ЗАДАЧИ
Исходными данными служат архивы программно-технических комплексов автоматизированных систем управления энергоблоков, хранящие массивы данных за длительный период работы ДТО: ${\mathbf{P}}\left( t \right) = {{\left[ {{{P}_{1}}\left( t \right),...,{{P}_{m}}\left( t \right)} \right]}^{{\text{т}}}},$ где ${\mathbf{P}}\left( t \right)$ – вектор показателей в момент времени t; ${{P}_{1}}\left( t \right),...,{{P}_{m}}\left( t \right)$ – показатели функционирования ДТО в момент времени t; m – количество этих показателей. Под показателями функционирования ДТО далее понимаются не только индивидуальные измерения, но и их статистические производные (средние значения за период, дисперсии, корреляционные функции и др.). Векторы ${\mathbf{P}}\left( {{{t}_{r}}} \right),$ взятые в моменты времени ${{t}_{r}}$ (r = 1, 2, …), образуют точки в m-мерном пространстве. Кроме того, дано конечное множество прецедентов (аварий, неисправностей, дефектов), каждый из которых можно классифицировать, т.е. отнести к определенному виду дефекта ДТО. Каждому прецеденту приписана метка времени его обнаружения ${{t}_{{i,j}}},$ здесь ${{t}_{{i,j}}}$ – моменты обнаружения i-го прецедента класса (типа дефекта) j (j = 1, …, l; l – количество классов; i = 1, …, …, k; k – количество прецедентов в классе j).
Можно предположить, что область пространства с точками нормального функционирования ДТО отличается от областей пространства, которые образованы точками функционирования этого же объекта в периоды времени, совпадающие с моментами возникновения прецедента ${{t}_{{i,j}}},$ так же как различаются между собой и области пространства прецедентов разных классов. Более того, для технологического оборудования энергоблоков вполне обоснованно считать эти множества линейно разделимыми. Период функционирования оборудования длительностью от $\left( {{{t}_{{i,j}}} - \Delta {{t}_{{b,j}}}} \right)$ до $\left( {{{t}_{{i,j}}} + \Delta {{t}_{{a,j}}}} \right)$ можно назвать аномальным периодом эксплуатации в классе j. Здесь $\Delta {{t}_{{b,j}}}$ – период времени до прецедента, когда наличие развивающегося дефекта начинает оказывать влияние на совокупность признаков функционирования ДТО; $\Delta {{t}_{{a,j}}}$ – период времени от возникновения прецедента до устранения его последствий.
Совокупность всех имеющихся описаний прецедентов называется обучающей выборкой. Требуется по ней выявить общие зависимости, позволяющие определять аномальное функционирование ДТО с указанием класса аномальности. При этом должен быть сформирован обобщенный критерий аномальности, по изменению которого можно с некоторой достоверностью определять возможность возникновения прецедента.
ПОСТРОЕНИЕ МОДЕЛИ ДЛЯ ОБЩЕГО СЛУЧАЯ
Пусть даны несколько множеств из n-мерного евклидова пространства признаков состояния ДТО. Каждая точка этого пространства образована значениями признаков, полученными через определенные отрезки времени. Первое множество точек составлено в период исправного состояния оборудования. Другие множества образованы в аномальные периоды работы оборудования, причем каждое из них связано с определенным видом аномальности, характеризующим конкретную неисправность. Далее множества нормального и аномального функционирования называются базовыми множествами. На рис. 1 изображены в двумерном пространстве (Р1 и Р2 – 1-я и 2-я координаты вектора) расстояния от точки процесса в текущий момент времени t до точек подмножеств нормального (индекс “норм”) и аномального (индексы “а1” и “а2”) функционирования ДТО; Nнорм, Mа1, Mа2 – количество точек в подмножествах нормального и аномального функционирования ДТО, а значения Nнорм, Mа1, Mа2 соответствуют длительности нормального и аномальных периодов.
Рис. 1.
Пространство параметров функционирования оборудования. Обучающее множество – точки подмножества функционирования ДТО: 1 – нормального; 2 – аномального с типом дефекта 1; 3 – аномального с типом дефекта 2. Пунктирные линии иллюстрируют линейную разделимость нормальной и аномальных областей
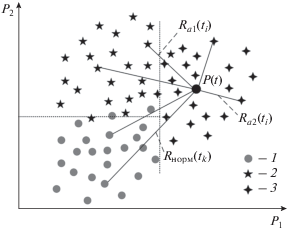
С каждой точкой из базовых множеств можно связать некоторую функцию, аналогичную по форме электрическому потенциалу, т.е. максимальную в этой точке и убывающую по всем направлениям от нее (точка таким образом окажется как бы источником потенциала). Такой функцией может быть, например,
где W – “вес” точки; R – расстояние между точкой-источником и точкой, в которой вычисляется потенциал, которое рассчитывается по формулездесь $P{{\left( t \right)}_{i}}$ – i-я координата (признак ДТО) t-й точки m-мерного множества (точки в момент времени t), относительно которой определяется потенциал $\varphi \left( t \right)$ точки с координатами ${{P}_{i}}.$
Значение функции $\varphi \left( t \right)$ в каждой точке пространства можно считать мерой близости этой точки к точке-источнику.
Пусть источниками служат точки пространства нормального функционирования. Тогда средний потенциал, создаваемый в данной точке пространства всеми точками, т.е. суммарный потенциал, деленный на число точек (потенциал нормального функционирования), будет характеризовать близость данной точки ко всему базовому множеству в целом:
Аналогично можно определить в этой же точке пространства потенциалы j-го базового множества, где j = 1, …, l – тип неисправности [l – количество типов неисправностей (классов дефектов) в обучающей выборке]:
Поскольку множества нормального и аномального функционирования при расчете считаются линейно разделимыми, естественно будет отнести точку к тому базовому множеству, чей потенциал в этой точке наибольший.
Однако, как уже было отмечено, получить данные по аномальным классам крайне затруднительно, а чаще всего вообще невозможно. Поэтому в дальнейшем будет рассмотрена модификация изложенного общего подхода, а именно построение модели только по данным нормального периода эксплуатации.
ПОСТРОЕНИЕ МОДЕЛИ ПО ДАННЫМ ТОЛЬКО НОРМАЛЬНОГО ПЕРИОДА ЭКСПЛУАТАЦИИ
В этом частном случае имеется лишь одно базовое множество – множество нормального функционирования ${{{\mathbf{N}}}_{{{\text{норм}}}}}$ с количеством точек Nнорм. Тогда алгоритм обучения модифицируется следующим образом. Для каждой k-й точки базового множества, где $k \in \left( {1,{{N}_{{{\text{норм}}}}}} \right),$ нужно вычислить ее средний потенциал относительно остальных ${{N}_{{{\text{норм}}}}} - 1$ точек:
Далее рассчитывается минимальный потенциал базового множества ${{{\mathbf{N}}}_{{{\text{норм}}}}}$
Тогда в режиме run-time потенциал в каждый новый момент времени будет определяться по формуле:
На этом построение модели можно считать законченным. Теперь, если окажется, что потенциал ${{\varphi }^{{{\text{ср}}}}}\left( t \right)$ для точек, образованных текущими значениями параметров ДТО относительно точек обучающего множества, меньше, чем значение φmin, можно считать, что ДТО вошло в аномальную зону функционирования. Отслеживая тенденцию дальнейшего уменьшения ${{\varphi }^{{{\text{ср}}}}}\left( t \right),$ можно прогнозировать возможность возникновения аварии. Вычисленный потенциал изменяется в пределах (1, 0) и, по сути, является критерием аномальности.
При реальной эксплуатации модели можно задать граничную уставку потенциала и такой период времени Ta, что при $\varphi \left( t \right) < \left( {{{\varphi }^{{\min }}} - \Delta a} \right)$ в течение периода времени, превышающего Ta, будет срабатывать сигнализация (Δa – максимально допустимое снижение условного потенциала). Далее специалист-технолог должен оценить правильность поведения модели и при совпадении предсказания и фактического состояния ДТО принять необходимые меры по устранению неисправности. Если же предсказание модели окажется ложным, то модель должна быть дообучена путем расширения пространства нормальной эксплуатации вследствие включения в него новых точек.
АЛГОРИТМ РАСЧЕТА КРИТЕРИЯ АНОМАЛЬНОСТИ ФУНКЦИОНИРОВАНИЯ ДТО
В связи с тем что предлагаемый метод предполагает вычислительную нагрузку, экспоненциально растущую с ростом количества точек базового множества, представляется необходимым ввести ограничения на их количество, не потеряв при этом точки, определяющие конфигурацию этого множества.
Формирование базового множества точек в пространстве признаков
Пусть: Nнорм – общее количество точек (моментов времени), полученных из архивных данных в период нормального функционирования ДТО (множество ${{{\mathbf{N}}}_{{{\text{норм}}}}}$);
NF – количество точек в указанном периоде, не имеющих ни одного недостоверного признака (см. далее раздел Учет недостоверности);
NL – предельное количество точек, при котором все вычисления, требуемые методом, заканчиваются за приемлемое время;
m – количество признаков (координат пространства базового множества), m << NL.
Тогда:
если ${{N}_{F}} \leqslant {{N}_{L}},$ то базовое множество тождественно множеству архивных данных нормального функционирования ДТО;
иначе базовое множество нужно формировать следующим образом, включая в него:
все точки множества ${{{\mathbf{N}}}_{{{\text{норм}}}}},$ имеющие ${{\min }_{{t = 1,...,{{N}_{{{\text{норм}}}}}}}}$ P(t)i – минимальное значение координаты (признака) ${{P}_{i}}$ среди всех ${{N}_{{{\text{норм}}}}}$ точек множества ${{{\mathbf{N}}}_{{{\text{норм}}}}},$ i = 1, …, m;
все точки множества ${{{\mathbf{N}}}_{{{\text{норм}}}}},$ имеющие ${{\max }_{{t = 1,...,{{N}_{{{\text{норм}}}}}}}}$ P(t)i – максимальное значение координаты (признака) ${{P}_{i}}$ среди всех ${{N}_{{{\text{норм}}}}}$ точек множества ${{{\mathbf{N}}}_{{{\text{норм}}}}},$ i = 1, …, m;
из оставшихся ${{N}_{{{\text{норм}}}}} - \,\,\,2m$ точек следует через равные интервалы $\Delta t = \frac{{{{N}_{{{\text{норм}}}}} - \,\,2m}}{{{{N}_{L}} - \,\,2m}}$ добрать точки до количества ${{N}_{L}}.$
Итоговое количество точек базового множества можно обозначить ${{N}_{B}}.$ Тогда из всего изложенного следует:
Определение весов W(t)
Вес является атрибутом точки, т.е. атрибутом каждого из моментов времени базового множества. Представляется разумным давать бо́льшие веса тем моментам времени, в которые с большей уверенностью можно предположить нормальный режим работы, чем в другие моменты записи исторических данных. Таковыми могут быть, например, периоды работы ДТО сразу после ремонта.
Формирование признаков
Признаками, характеризующими функционирование ДТО, служат, прежде всего, его измеряемые параметры.
Для расширения возможности улавливания эффектов аномального функционирования ДТО возможно дополнить перечень признаков производными от измеряемых параметров, например их дисперсиями $D\left( t \right).$ Предполагается, что такое расширение может оказаться полезным, когда развивающийся дефект первоначально оказывает влияние не столько на сами параметры или их совокупность, сколько на их изменчивость:
У некоторых параметров поддерживаются заданные значения благодаря воздействию автоматизированных систем регулирования. При этом возможно, что в довольно широком диапазоне развития некоторого теоретически оказывающего влияние на такой параметр дефекта сам параметр существенно изменяться не будет. Однако будет меняться положение поддерживающего этот параметр регулирующего органа. Это означает, что в перечень признаков ДТО желательно включать значения указателей положения регуляторов.
Фильтрация помех усреднением на интервале
Временны́е ряды признаков функционирования ДТО известны в виде дискретного ряда значений через равные интервалы времени.
В статистике выделяют три компонента временно́го ряда: тренд, сезонные колебания и случайную составляющую. Для решения поставленной задачи представляет интерес именно тренд, а случайная составляющая является вредным шумом, который и должен быть отфильтрован усреднением на интервале, сезонные же колебания для большинства признаков практически отсутствуют.
Усреднение признаков на временно́м интервале:
Так как в архивах программно-технического комплекса автоматизированной системы управления технологическим процессом данные хранятся с дискретностью по времени, то интеграл на самом деле является суммой значений каждого признака.
Значение ${{T}_{m}}$ определяется периодом помехи в спектре частот временны́х рядов технологических параметров. Исходя из имеющихся архивных данных, представляется разумным принять ${{T}_{m}}$ = = 10 мин.
Нормализация выборок данных
Необходимость нормализации выборок данных обусловлена различной природой используемых признаков, которые могут изменяться в широком диапазоне и, будучи разнообразными по физическому смыслу, отличаться один от другого на несколько порядков. Например, температура выражается трехзначным числом, тогда как перепад давлений – однозначным.
Работа моделей с такими показателями окажется некорректной: дисбаланс между значениями признаков может привести к совершенно неадекватным результатам.
На практике при вычислении расстояний между точками или векторами чаще всего используется Z-масштабирование координат этих векторов:
где
${{N}_{B}}$ – итоговое количество точек базового множества; $t = 1,...,{{N}_{B}};$ $i = 1,...,m.$
После нормализации все числовые значения входных признаков приводятся к одинаковой области их изменения – некоторому узкому диапазону. Это позволяет свести их вместе в одной модели и обеспечить корректную работу вычислительных алгоритмов.
Учет недостоверности измерений
Для построения адекватной модели необходимо иметь возможность тем или иным образом отфильтровывать недостоверные измерения. Так как все современные программно-технические комплексы, служащие источниками данных для работы любой предиктивной модели, несут информацию не только о значениях измеряемых параметров, но и об их достоверности (так называемый бит достоверности), то, используя эту информацию, можно различными способами обрабатывать недостоверные значения и тем самым не допускать ошибок обучения, если эти измерения относятся к обучающему периоду (базовому множеству), или ложных прогнозов, когда эти измерения и основанные на них показатели работы ДТО берутся при работе модели в режиме run-time.
При формировании базового множества все точки, в числе координат которых имеется хотя бы один недостоверный признак, отбрасываются.
При работе модели в режиме run-time наиболее рационально заменять значение недостоверного параметра на его последнее достоверное значение.
РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТАЛЬНЫХ ИССЛЕДОВАНИЙ
Для повышения чувствительности модели и конкретизации технологического узла, имеющего развивающийся дефект, весь набор измерений был разделен на группы в соответствии с технологией.
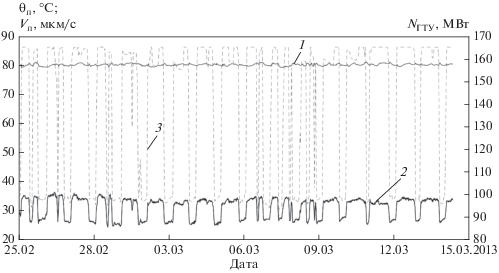
Экспериментальные исследования проводили на исторических данных функционирования газотурбинной установки (ГТУ), записанных в течение трех лет. В каждый момент времени с интервалом Δt = 10 мин регистрировалось m = 45 показателей функционирования ГТУ (активная мощность, вибрации подшипников, температуры баббитов подшипников и др.). На рис. 2 показан фрагмент исходных данных.
Рис. 2.
Показатели работы газовой турбины в интервале времени от 25.02.2013 до 15.03.2013, охарактеризованном специалистами-технологами как период нормального функционирования. 1 – температура подшипника θп; 2 – относительная вибрация подшипника Vп; 3 – активная мощность ГТУ ${{N}_{{{\text{ГТУ}}}}}$
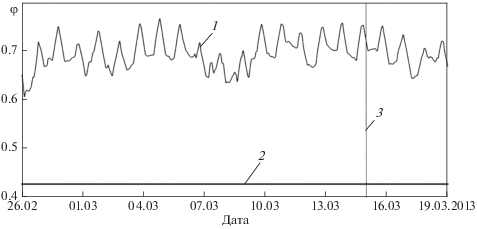
На рис. 3 приведен график зависимости рассчитанного критерия аномальности φ (кривая 1) функционирования газовой турбины. Горизонтальной прямой показано минимальное значение потенциала, полученное при обучении модели. На основании экспертного мнения, исходя из оценки каждого отдельного измерения в качестве тестового периода был выбран еще один период нормальной эксплуатации оборудования. Из графика видно, что в тестовый период эксплуатации показатель аномальности диагностирует нормальное состояние исследуемого объекта. Таким образом, в тестовом периоде разработанный метод показывает непротиворечивые результаты определения нормального/аномального функционирования ДТО.
Рис. 3.
Критерий аномальности φ (потенциал) функционирования газовой турбины в интервале времени от 26.02.2013 до 19.03.2013, включающем в себя нормальный (до 15.03.2013) и тестовый (после 15.03.2013) периоды функционирования. 1 – рассчитанный критерий аномальности (потенциал); 2 – определенный ранее минимальный потенциал; 3 – 15 марта 2013 г.
ВЫВОДЫ
1. Предложенный метод, обладая простотой и наглядностью, продемонстрировал адекватность и непротиворечивость результатов определения нормального/аномального функционирования ДТО на имеющихся архивных данных.
2. При наличии соответствующих исходных (архивных) данных о фиксированных неисправностях в ДТО модель может быть обучена на их поиск. Однако и при отсутствии информации, достаточной для обучения модели для поиска конкретных неисправностей (что есть практически всегда и на всех энергоблоках), модель может успешно работать, обучаясь только на данных, которые получены в период нормальной эксплуатации ДТО.
3. К недостаткам метода следует отнести экспоненциально возрастающую вычислительную сложность по мере увеличения массива обучающих данных. Однако эта проблема присутствует практически во всех имеющихся моделях предиктивной аналитики, а в данной статье предложен метод ее решения.
4. Представленный метод, как и все другие методы предиктивной аналитики, применяемые для диагностики технологического оборудования, универсален по отношению к виду этого оборудования. Единственное условие – оборудование должно иметь достаточное для диагностики количество измеряемых параметров, характеризующих его работу.
5. Предложенный метод требует дополнительного апробирования на других архивных выборках, содержащих (что желательно) верифицированный экспертом период аномальной эксплуатации в режимах как офлайн, так и онлайн на текущих данных, оптимизации обучающего набора данных, совершенствования в части прогнозирования сроков выхода на предаварийное и аварийное техническое состояние, определения вероятностных оценок факта возникновения и развития дефекта во времени.
Список литературы
Siegel E. Predictive analytics: The power to predict who will click, buy, lie, or die. John Wiley & Sons Inc., 2016. https://doi.org/10.1002/9781119172536
Waller M.A., Fawcett S.E. Data science, predictive analytics, and big data: a revolution that will transform supply chain design and management // J. Business Logistics. 2013. V. 34. № 2. P. 77–84. https://doi.org/10.1111/jbl.12010
Khan S.S., Madden M.G. One-class classification: taxonomy of study and review of techniques // The Knowledge Engineering Review Cambridge University. 2014. V. 29. Is. 3. P. 345–374. https://doi.org/10.1017/S026988891300043X
Trofimov A.G., Kuznetsova K.E., Korshikova A.A. Abnormal operation detection in heat power plant using ensemble of binary classifiers // Advances in Neural Computation, Machine Learning, and Cognitive Research. II. Neuroinformatics 2018. Studies in Computational Intelligence / Ed. by B. Kryzhanovsky, W. Dunin-Barkowski, V. Redko, Y. Tiumentsev. Springer, 2019. V. 799. P. 227–233. https://doi.org/10.1007/978-3-030-01328-8_27
Коршикова А.А., Трофимов А.Г. Модель раннего обнаружения аварийных ситуаций на оборудовании электростанций на основе методов машинного обучения // Теплоэнергетика. 2019. № 3. С. 49–56. https://doi.org/10.1134/S0040363619030044
Korshikova A.A., Trofimov A.G. Predictive model for calculating abnormal functioning power equipment // Cyber-Physical Systems: Industry 4.0 Challenges. Studies in Systems, Decision and Control / Ed. by A. Kravets, A. Bolshakov, M. Shcherbakov. Springer, 2020. V. 260. P. 249–259. https://doi.org/10.1007/978-3-030-32648-7_20
Random forest as a predictive analytics alternative to regression in institutional research / H. Lingjun, R.A. Levine, J. Fan, J. Beemer, J. Stronach // Practical Assessment, Research & Evaluation. 2018. V. 23. № 1. [Электрон. ресурс.] Режим доступа: https://doi.org/10.7275/1wpr-m024
Dietterich T.G. Ensemble learning. The Handbook of Brain Theory and Neural Networks / Ed. by M.A. Arbib. 2nd ed. Cambridge: MIT Press, 2002. V. 3. P. 110–125.
Липатов М. Новая реальность диктует новые правила // Прана. Новости. [Электрон. ресурс.] Режим доступа: https://prana-system.com/novosti/novosti/novaya-realnost-diktuet-novye-pravila/ (Дата обращения 23.11.2020.)
Дополнительные материалы отсутствуют.
Инструменты
Теплоэнергетика