

Журнал аналитической химии, 2022, T. 77, № 1, стр. 20-27
Спектрометрическое определение суммарного содержания однотипных аналитов с помощью традиционных многомерных градуировок
И. В. Власова a, *, В. И. Вершинин a
a Омский государственный университет им. Ф.М. Достоевского
644077 Омск, просп. Мира, 55а, Россия
* E-mail: vlaso-iri@yandex.ru
Поступила в редакцию 30.04.2021
После доработки 15.06.2021
Принята к публикации 15.06.2021
- EDN: WJPBES
- DOI: 10.31857/S0044450222010157
Аннотация
Для спектрометрического определения суммарного содержания (сΣ) однотипных веществ можно применять многомерные градуировки, связывающие обобщенные сигналы (AΣ)j, измеренные при разных длинах волн (λj) c концентрациями этих аналитов (сi) и их коэффициентами поглощения (kij). Такие градуировки традиционно используют для раздельного определения аналитов, при этом значения сi рассчитывают с помощью хемометрических алгоритмов. Для нахождения сΣ следует лишь просуммировать найденные сi. Несмотря на простоту этого варианта группового анализа, он применяется редко, а его возможности не изучены. Неясно, как зависит точность оценки сΣ от числа аналитических длин волн (АДВ), количества эталонов и других факторов. Цель данного исследования состояла в получении соответствующей информации на примере модельных смесей аренов. Спектры поглощения смесей аренов регистрировали в области 230–280 нм, где эти спектры аддитивны. Анализировали 55 гексановых растворов, содержащих от 3 до 6 аренов (суммарно 0.1–0.5 мг/мл). Формируя матрицу коэффициентов поглощения индивидуальных аренов, учитывали качественный состав модельных смесей. Значения сi находили методом MLR (прямая градуировка). При достаточно большом числе АДВ найденные значения сi для аренов, отсутствующих в пробе, были близки к 0, а для присутствующих – к действительным значениям сi. Суммирование найденных сi давало приблизительно правильные оценки сΣ (±5%). При этом единичные погрешности группового анализа были, как правило, меньше погрешностей определения компонентов смеси. Усложнение модели (введение “лишних” эталонов и увеличение числа АДВ) не снижало точность результатов группового анализа, а упрощение модели вело к росту погрешностей. Если же для формирования модели использовали лишь наиболее типичные эталоны, значения kij которых охватывают весь диапазон возможных значений kij, наличие в пробе компонентов, не учитываемых упрощенной моделью, не приводило к заметному росту погрешностей.
Как правило, суммарное содержание (сΣ) однотипных органических веществ находят спектрометрическим методом без их разделения; с той же целью применяют электрохимические методы, титриметрию и гравиметрию. В ходе анализа измеряют обобщенный аналитический сигнал АΣ и по нему вычисляют интегральный показатель состава (ИП), выраженный в пересчете на стандартное вещество (Хст). Найденное значение ИП является приблизительной оценкой сΣ. Примерами могут быть стандартные методики спектрометрического определения суммы углеводородов в водах или суммы белков в крови. Методики группового анализа, основанные на измерении ИП, составляют около 20% всех методик количественного анализа [1]. К сожалению, нередко значения ИП сильно и непредсказуемо отличаются от действительных значений сΣ [2, 3]. Главные источники неопределенности – внутригрупповая селективность и неаддитивность аналитических сигналов. Кроме того, аналитики нередко допускают ошибки при формировании группы совместно определяемых веществ, измерении АΣ и подборе Хст [4]. Неточность определения суммарных содержаний с помощью ИП увеличивает интерес аналитиков к альтернативным способам группового анализа, не требующим выражения сΣ в единицах содержания Хст (в метрологическом отношении некорректен [1, 2]). В частности, можно определять сΣ, применяя линейные многомерные градуировки; примеры приведены в табл. 1. К сожалению, неопределенность результатов группового анализа характеризуют различными способами, что затрудняет сопоставление соответствующих методик.
Таблица 1.
Примеры спектрометрических определений суммарных содержаний (сΣ) однотипных аналитов с помощью многомерных градуировок
| Объект анализа | Группы аналитов |
Диапазоны значений сΣ | Область спектра | Алгоритмы | Неопределенность | Год | Литература | |
|---|---|---|---|---|---|---|---|---|
| δс, отн. % |
SEC или RMSEP | |||||||
| Фруктовые соки | Углеводы | 10–200 мг/мл | БИК | PLS | <3 | ? | 1997 | [5] |
| Красные вина | Таннины | До 1 мг/мл | БИК | PLS | ? | 0.1 мг/мл | 2004 | [6] |
| Бензины | Парафины, нафтены, арены |
40–50 мас. % 40–65 мас. % 1.5–11 мас. % | БИК | PLS | <2 <3 <5 | <0.3% <0.3% <0.7% | 2005 | [7] |
| Чай | Полифенолы | 15–25 мг/л | БИК | PLS | ? | 1.07 мг/л (RMSEP) | 2008 | [8] |
| Модельные растворы | Полифенолы | 50–400 мкМ | УФ | МЛР PLS | <5 <3 | ? | 2012 | [9] |
| Модельные растворы | Арены | 70–400 мг/л | УФ | МЛР | <10 | ? | 2016 | [10] |
| Сточные воды | Углеводороды | 10–100 мг/л | ИК | МЛР PLS | <8 <6 | 1.5 мг/л (RMSEP) | 2016 | [11] |
| Сточные воды | Арены | До 50 мг/л | УФ | МЛР | <20 | ? | 2021 | [12] |
Применение многомерных градуировок в спектрометрическом анализе предполагает многоволновые измерения обобщенных аналитических сигналов и расчет результатов анализа с помощью хемометрических алгоритмов. Популярный алгоритм PLS обеспечивает несколько бóльшую точность расчета, чем другие алгоритмы (при прочих равных условиях) так как на результаты анализа меньше влияют компоненты пробы, не включенные в число аналитов [13]. Вместе с тем алгоритм PLS сложнее других алгоритмов; он реализуется с помощью менее доступного программного обеспечения (пакет “Unscrambler”) [14]. В связи с этим многие аналитики предпочитают использовать алгоритмы MLR или OLS, реализуемые даже с помощью пакета “Excel”. Их применение требует предварительного формирования матрицы коэффициентов поглощения аналитов при выбранных АДВ. Элементы матрицы (значения kij) вычисляют, исходя из спектров поглощения эталонных растворов индивидуальных соединений (прямая градуировка), либо из спектров поглощения их модельных смесей, составляющих обучающую выборку (непрямая градуировка). В последнем случае составляют переопределенную систему линейных уравнений вида (АΣ)j = = Σсikij и решают ее относительно неизвестных коэффициентов поглощения методом наименьших квадратов (алгоритм OLS).
Выделим два варианта определения сΣ с применением линейных многомерных градуировок. Многомерные градуировки первого типа (“традиционные градуировки”) связывают обобщенные сигналы аналитов (AΣ)j при разных длинах волн (λj) c концентрациями аналитов (сi) и их коэффициентами поглощения (kij) при разных длинах волн. Такие градуировки обычно используют для решения другой задачи, а именно для раздельного спектрометрического определения компонентов смеси по ее спектру [13]. Если же требуется провести групповой анализ, то сначала надо с помощью подходящих хемометрических алгоритмов рассчитать значения сi для всех компонентов пробы, относящихся к искомой группе, а затем просуммировать найденные сi. Этот простой и метрологически корректный вариант группового анализа обеспечивает хорошую точность определения сΣ, но применяется очень редко [9, 10].
Многомерные градуировки второго типа относятся к классу обращенных градуировок. Они связывают суммарные содержания однотипных аналитов в модельных смесях из обучающей выборки с их обобщенными сигналами, измеренными при разных АДВ, т.е. отвечают общей формуле сΣ = ΣbjAj. Используя такие градуировки, матрицу коэффициентов поглощения не составляют, а значения сi не вычисляют. Для расчета сΣ по спектру пробы используют различные хемометрические алгоритмы, в том числе PLS. При этом регрессионные коэффициенты bj заранее находят с помощью набора модельных смесей известного состава. Особенности и аналитическое применение многомерных градуировок второго типа в данной статье не рассматриваются.
Общепринятые правила построения многомерных градуировок применительно к групповому спектрометрическому анализу реальных объектов еще не выработаны. В качестве источника исходных данных в методиках группового анализа используют и однокомпонентные растворы аналитов искомой группы [5], и приготовленные из них градуировочные смеси известного состава [5, 9–11], и реальные пробы, для которых значения сΣ найдены по надежной референтной методике [7], и даже пробы неизвестного состава, охарактеризованные лишь значениями ИП [6, 8]. Метрологические аспекты определения суммарных содержаний с помощью многомерных градуировок почти не изучены. Неясно, сколько смесей следует включать в обучающую выборку для построения непрямой градуировки. Неизвестно, сколько АДВ нужно для оценки сΣ c желаемой точностью и как их выбирать. Ответы на подобные вопросы для градуировок разного типа могут быть различными. Ввиду слабого развития методологии группового анализа необходимые рекомендации можно получить лишь для частных случаев, обобщая результаты анализа модельных смесей известного состава при разных способах обработки спектров. При этом компонентами модельных смесей должны быть однотипные и устойчивые соединения, поглощающие свет в одной и той же области спектра; спектры поглощения всех смесей следует регистрировать в одинаковых условиях; отклонения от аддитивности и от закона Бугера–Ламберта–Бера нежелательны. Этим требованиям отвечают спектры поглощения смесей моноциклических аренов.
Цель настоящего исследования – оценка аналитических возможностей многомерных градуировок первого (“традиционного”) типа на примере определения суммарного содержания моноциклических аренов в многокомпонентных гексановых растворах по их светопоглощению в УФ-области спектра.
ЭКСПЕРИМЕНТАЛЬНАЯ ЧАСТЬ
В работе использовали химические реактивы марки х. ч.: н-гексан (растворитель), бензол (Б), толуол (Т), этилбензол (ЭБ), о-ксилол (ОК), п‑ксилол (ПК), кумол (К). Исходные растворы перечисленных аренов готовили, растворяя их точные навески в гексане. Концентрации исходных растворов находились в диапазоне от 1.5 до 2.0 мг/мл. Разбавляя исходные растворы, получали однокомпонентные рабочие растворы с концентрациями от 0.01 до 0.50 мг/мл. По спектрам поглощения этих растворов вычисляли удельные коэффициенты поглощения i-го арена при j-ой АДВ (kij, см2/мг). Использовали не менее пяти рабочих растворов c разными концентрациями i-го арена, причем каждый раствор готовили не менее трех раз, а все полученные значения kijусредняли.
Многокомпонентные смеси (гексановые растворы, содержащие от 3 до 6 моноциклических аренов) готовили из исходных растворов. Суммарные содержания аренов в этих смесях охватывали диапазон от 0.10 до 0.50 мг/мл, соотношение концентраций разных аренов в единичной смеси не превышало 10 : 1 (табл. 2). Всего было приготовлено 55 модельных смесей. Каждый раствор готовили не менее трех раз.
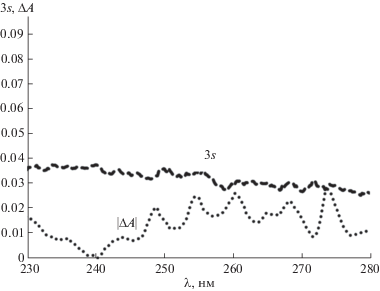
Спектры поглощения приготовленных растворов регистрировали с шагом 0.2 нм в области 230–280 нм на спектрофотометре СФ-2000-01 в кварцевых кюветах толщиной 1.0 см против чистого н-гексана. Спектры поглощения однокомпонентных растворов приведены в работе [12], спектры поглощения некоторых смесей представлены на рис. 1. Регистрацию каждого спектра повторяли 2–3 раза, значения оптической плотности измеряли при выбранных АДВ и усредняли. При повторных измерениях оптической плотности одного и того же раствора при фиксированной АДВ коэффициенты вариации (sr) не превышали 0.5%. При повторном приготовлении растворов значения sr несколько возрастали, но не превышали 1%. Для расчета kij выбирали значения АДВ, взятые с шагом 0.2, 1, 2, 5 и 10 нм. Примером могут быть удельные коэффициенты поглощения шести аренов при 11 АДВ, отобранных с шагом 5 нм (табл. 3). Аддитивность светопоглощения смесей проверяли при разных длинах волн. Для этого сопоставляли взятые по модулю значения отклонений от аддитивности (ΔА) с критерием 3s, характеризующим предел случайной погрешности при повторных измерениях оптической плотности смеси при данной АДВ. Отклонения считали статистически незначимыми, если ΔА ≤ 3s (рис. 2).
Рис. 1.
Спектры поглощения модельных смесей с разными суммарными содержаниями аренов: 1 – смесь 9 (0.24 мг/мл), 2 – смесь 1 (0.42 мг/мл), 3 – смесь 8 (0.35 мг/мл). Составы смесей приведены в табл. 2, нумерация смесей здесь и далее сохраняется.

Таблица 2.
Состав некоторых модельных смесей моноциклических аренов
| Номер смеси | Содержания индивидуальных аренов ci, мг/мл | cΣ, мг/мл | |||||
|---|---|---|---|---|---|---|---|
| Б | Т | ЭБ | ОК | ПК | К | ||
| 1 | 0.18 | 0.18 | 0.06 | 0 | 0 | 0 | 0.42 |
| 2 | 0.09 | 0.09 | 0.09 | 0 | 0 | 0 | 0.27 |
| 3 | 0 | 0.06 | 0.18 | 0 | 0 | 0.18 | 0.42 |
| 4 | 0 | 0.09 | 0.14 | 0 | 0 | 0.15 | 0.38 |
| 5 | 0.05 | 0.10 | 0 | 0 | 0.05 | 0.04 | 0.24 |
| 6 | 0.10 | 0.10 | 0 | 0.10 | 0.04 | 0 | 0.34 |
| 7 | 0.10 | 0.04 | 0 | 0.10 | 0.04 | 0 | 0.28 |
| 8 | 0.04 | 0.10 | 0 | 0.10 | 0.10 | 0 | 0.35 |
| 9 | 0.03 | 0.09 | 0.03 | 0.03 | 0.03 | 0.03 | 0.24 |
| 10 | 0.03 | 0.03 | 0.09 | 0.03 | 0.09 | 0.09 | 0.37 |
Таблица 3.
Матрица удельных коэффициентов поглощения (kij, см2/мг) шести аренов при 11 АДВ
| АДВ, нм | Б | Т | ЭБ | ОК | ПК | К |
|---|---|---|---|---|---|---|
| 230 | 0.07 | 0.22 | 1.27 | 0.29 | 0.82 | 0.04 |
| 235 | 0.20 | 0.34 | 1.40 | 0.31 | 0.41 | 0.13 |
| 240 | 0.40 | 0.54 | 1.48 | 0.44 | 0.53 | 0.29 |
| 245 | 0.70 | 0.91 | 1.46 | 0.72 | 0.87 | 0.54 |
| 250 | 1.29 | 1.38 | 1.42 | 1.14 | 1.34 | 0.82 |
| 255 | 1.96 | 2.00 | 1.70 | 1.67 | 2.14 | 1.20 |
| 260 | 0.71 | 2.25 | 1.94 | 2.00 | 3.30 | 1.47 |
| 265 | 0.07 | 1.77 | 1.48 | 2.05 | 3.88 | 1.00 |
| 270 | 0.01 | 1.42 | 0.85 | 1.59 | 3.43 | 0.28 |
| 275 | 0.00 | 0.10 | 0.15 | 0.35 | 4.59 | 0.08 |
| 280 | 0.00 | 0.00 | 0.07 | 0.01 | 0.32 | 0.00 |
Для обработки спектральных данных использовали метод MLR в варианте прямой градуировки, реализуя его с помощью авторской компьютерной программы Optic-MLR (пакет MATLAB). Преимущество данной программы по сравнению с Microsoft Excel и другими аналогами состоит в том, что она позволяет рассчитывать значения ci сразу для нескольких десятков смесей, а это сокращает затраты времени. В программу заранее вводили модель, т.е. матрицу усредненных значений kij. Перед анализом очередных проб дополнительно вводили набор значений (АΣ)j, полученных для этих смесей. Итогом работы программы Optic MLR являются массовые концентрации тех индивидуальных аренов, для которых в программу введены значения kij, т.е. концентрации предполагаемых компонентов исследуемой пробы. Найденные концентрации $(с_{i}^{*})$ суммировали, получая результат анализа $с_{\Sigma }^{*},$ приблизительно равный искомой величине сΣ. Расчеты повторяли, используя разные наборы коэффициентов поглощения (упрощение или усложнение модели), а также меняя число учитываемых АДВ. Статистическую обработку вели по алгоритму Стьюдента (n = 3, P = 0.95). Погрешности определения концентраций индивидуальных аренов вычисляли по формуле
Погрешности группового анализа единичных смесей вычисляли по формуле:
(2)
$\delta {{с}_{\Sigma }}\left( \% \right) = 100(с_{\Sigma }^{*}--{{с}_{\Sigma }}){\text{/}}{{с}_{\Sigma }}.$Обобщенную погрешность группового анализа разных смесей характеризовали, как это принято в работах по хемометрике, параметром RMSEP (root mean squared error of prediction) [5, 14], выражая этот параметр в мг/мл:
(3)
${\text{RMSEP}} = \sqrt {\frac{{\sum\limits_{q = 1}^{q = t} {{{{(с_{q}^{{\text{*}}} - c)}}^{2}}} }}{t}} ,$РЕЗУЛЬТАТЫ И ИХ ОБСУЖДЕНИЕ
Проверка условий, необходимых для построения многомерных градуировок. Следовало проверить, выполняются ли для гексановых растворов моноциклических аренов условия, позволяющие строить градуировки первого типа и применять их для расчета суммарных содержаний. Проверка показала, что все модельные соединения поглощают УФ-излучение в области 230–280 нм. В этом диапазоне длин волн фон отсутствует, градуировочные графики прямолинейны, коэффициенты линейной корреляции близки к единице (r > 0.99), т.е. в исследованной концентрационной области гексановые растворы аренов подчиняются закону Бугера–Ламберта–Бера. Независимо от природы арена и выбора АДВ, изменения концентрации однокомпонентных растворов почти не влияли на удельный коэффициент поглощения единичного арена (sr < 0.03). Коэффициенты поглощения разных аренов не пропорциональны друг другу и довольно сильно различаются. Последнее обстоятельство способствует точному определению значений сi.
Проверка показала статистическую незначимость отклонений от аддитивности для подавляющего большинства исследованных смесей; отклонения ΔА по модулю не превышали предельную величину случайных погрешностей, т.е. 3s-критерий (см. рис. 2). Небольшие, но статистически значимые отклонения от аддитивности мы выявили лишь для нескольких смесей, содержавших кумол и/или этилбензол, причем такие отклонения наблюдались только в области 260–280 нм. Отметим, что появление небольших отклонений от аддитивности на отдельных АДВ не мешает применению многомерных градуировок первого типа в групповом анализе. Однако в этом случае значения kij следует вычислять с помощью смесей известного состава, входящих в обучающую выборку.
Точность расчета индивидуальных и суммарных концентраций. Индивидуальные концентрации шести аренов, входящих в состав модельных смесей, вначале рассчитывали, используя коэффициенты поглощения всех аренов, входящих в эти смеси (“шестикомпонентная модель”). Число и природу аренов, присутствующих в единичной пробе, в ходе расчетов не учитывали. Для аренов, отсутствующих в смеси, получали значения ci, близкие к нулю. Индивидуальные концентрации присутствующих аренов определялись с довольно большими погрешностями (δci < 70 отн. %) (табл. 4). Сходимость результатов расчета ci для повторно приготовленных смесей характеризовалась коэффициентами вариации порядка 1–5% для компонентов с концентрациями 0.07–0.2 мг/мл и 7–10% – для компонентов с концентрациями меньшими 0.07 мг/мл. Абсолютные погрешности (Δci) были как положительными, так и отрицательными. Суммирование значений ci обычно приводило к частичной компенсации элементарных погрешностей. Как правило, значения δcΣ по модулю были гораздо меньше, чем значения δci. Та же закономерность наблюдалась при групповом анализе смесей углеводов [5] и полифенолов [9]. Выявленная закономерность не противоречит известным правилам расчета погрешностей при косвенных измерениях [15]. Эти правила относятся лишь к суммированию независимых погрешностей, а при одновременном расчете всех ci по одной и той же многомерной градуировке элементарные погрешности δci не являются независимыми.
Таблица 4.
Результаты и абсолютные погрешности спектрометрического определения индивидуальных аренов в шестикомпонентных смесях при 11 АДВ (метод МЛР)
| Номер смеси | Найдено, ci, мг/мл | Δci, мг/мл | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Б | Т | ЭБ | ОК | ПК | К | Б | Т | ЭБ | ОК | ПК | К | |
| 1 | 0.19 | 0.20 | 0.05 | –0.01 | 0.00 | –0.01 | 0.01 | 0.02 | 0.01 | –0.01 | 0.00 | –0.01 |
| 2 | 0.09 | 0.15 | 0.09 | –0.05 | 0.01 | –0.02 | 0.00 | 0.06 | 0.00 | –0.05 | 0.01 | –0.02 |
| 9 | 0.03 | 0.11 | 0.01 | 0.01 | 0.04 | 0.05 | 0.00 | 0.02 | –0.02 | –0.02 | 0.01 | 0.02 |
| 10 | 0.03 | 0.04 | 0.08 | 0.03 | 0.09 | 0.10 | 0.00 | 0.01 | –0.01 | 0.00 | 0.00 | 0.01 |
Примечание: действительные значения сi приведены в табл. 2; курсивом выделены данные по аренам, отсутствующим в соответствующих смесях.
Известно, что на точность определения ci влияет число используемых АДВ [11, 13]. По-видимому, число АДВ должно влиять и на точность определения суммарных содержаний. Проведенные нами эксперименты подтвердили эту гипотезу. Так, при измерении оптической плотности шестикомпонентных смесей с шагом в 10 нм с использованием шести АДВ мы получали погрешности (δc), достигающие 40 отн. % (по модулю). Этого и следовало ожидать, так как система линейных уравнений, описывающих поглощение единичной смеси, не является переопределенной. Гораздо лучшие результаты (δc < 5%) получали при измерениях в том же спектральном диапазоне с шагом в 5 нм с использованием одиннадцати АДВ. Для 40 смесей из 55 проанализированных погрешность δc не превышала 3%. Дальнейшее увеличение числа АДВ не приводило к снижению погрешностей (табл. 5). Сопоставление значений параметра RMSEP, обобщенно характеризующих погрешности анализа смесей, подтвердило этот вывод. При использовании 6 АДВ параметр RMSEP составил 0.075 мг/мл; 11 АДВ – 0.009 мг/мл, а 25, 50 и 250 АДВ – соответственно 0.01, 0.015 и 0.016 мг/мл.
Таблица 5.
Относительные погрешности (δc, %) при определении суммарного содержания аренов в модельных смесях с учетом коэффициентов поглощения шести аренов
| № смеси | Число компонентов смеси |
δc (%) при разном числе АДВ | |||
|---|---|---|---|---|---|
| 11 | 25 | 50 | 250 | ||
| 1 | 3 | 1.6 | 4.9 | 4.4 | 4.6 |
| 2 | 3 | 2.4 | 11 | 10.2 | 10.5 |
| 3 | 3 | –0.5 | 6.7 | 5.6 | 5.8 |
| 4 | 3 | –0.2 | 5.5 | 4.6 | 4.9 |
| 9 | 6 | 2.6 | 4.6 | 4.2 | 4.3 |
| 10 | 6 | 0.2 | 5.8 | 5.3 | 5.4 |
| 11 | 6 | 0.3 | 4.8 | 4.1 | 4.2 |
| 12 | 6 | –0.3 | 4.7 | 3.9 | 4.0 |
Как видно из табл. 4, суммарные содержания аренов в трех- и шестикомпонентных смесях в оптимальных условиях определяются с приблизительно одинаковой точностью. Отсутствие в трехкомпонентных смесях некоторых из шести аренов, коэффициенты поглощения которых использовались для построения градуировки, не приводило к росту погрешности. Очевидно, “лишние” эталоны при построении многомерных градуировок первого типа вполне допус-тимы.
Возможность упрощения модели. Основная проблема спектрометрического определения однотипных аналитов в неразделенных смесях – отсутствие данных о числе компонентов и качественном составе исследуемой смеси. Заранее составленная матрица коэффициентов поглощения может оказаться как избыточной (содержащей отсутствующие в пробах вещества и лишние АДВ), так и недостаточной. Возникает вопрос, можно ли получить правильные оценки cΣ с помощью упрощенных моделей, не учитывающих коэффициенты поглощения некоторых аналитов искомой группы, присутствующих в анализируемых пробах.
Чтобы получить ответ на этот вопрос, мы определяли суммарное содержание аренов в шестикомпонентных смесях разного состава, используя удельные коэффициенты поглощения всего трех аренов – бензола, этилбензола и п-ксилола. Выбор именно этих соединений для построения упрощенной модели объясняется различиями значений удельных коэффициентов поглощения аренов в области 250–270 нм (табл. 3). Бензол имеет наименьшие, п-ксилол – наибольшие, а толуол, этилбензол, кумол и о-ксилол – промежуточные значения этих коэффициентов, сходные между собой. Решено было использовать для построения упрощенной градуировки по одному представителю каждой из трех подгрупп (Б, ЭБ и ПК) и выполнять расчеты при тех же АДВ, что и в предыдущей серии опытов. Результаты расчетов по упрощенной градуировке приведены в табл. 6. Сопоставление данных табл. 5 и 6 приводит к следующим выводам:
Таблица 6.
Относительные погрешности (δc, %) при определении суммарного содержания аренов в модельных смесях с учетом коэффициентов поглощения трех аренов (Б, ЭБ, ПК)
| № смеси | Число компонентов смеси | δc (%) при разном числе АДВ | ||||
|---|---|---|---|---|---|---|
| 6 | 11 | 25 | 50 | 250 | ||
| 1 | 3 | 11 | –9.8 | –0.7 | 10 | 9.9 |
| 2 | 3 | 16 | –7.9 | 1.8 | –15 | 14 |
| 3 | 3 | –0.4 | 5.9 | 14 | –4.7 | –4.9 |
| 4 | 3 | 1.2 | 11 | 18 | –2.5 | –2.7 |
| 9 | 6 | 7.1 | –1.3 | 10 | 5.0 | 4.8 |
| 10 | 6 | –0.2 | –8.7 | 0.9 | –3.4 | –3.5 |
| 11 | 6 | 2.9 | –3.8 | 4.2 | 0.6 | 0.4 |
| 12 | 6 | 5.6 | –0.6 | 7.4 | 3.6 | 3.5 |
1) как правило, упрощение модели при прочих равных условиях снижает точность определения cΣ. Если анализ трехкомпонентных смесей с применением шести эталонов и 11 АДВ ведет к погрешностям δcΣ, не превышающим 5% (табл. 5), то анализ тех же смесей с применением трех эталонов увеличивает δcΣ до 10–15%;
2) наличие в пробах “лишних” аналитов, не учтенных при построении упрощенной градуировки, не обязательно приводит к снижению точности анализа. В противном случае анализ шестикомпонентных смесей по упрощенной градуировке давал бы гораздо большие погрешности, чем анализ трехкомпонентных смесей Б, ЭБ и ПК, чего мы не наблюдали;
3) точность определения cΣ по упрощенной градуировке мало зависит от числа используемых АДВ. Так, используя “трехмерную” градуировку для определения суммарного содержания шести разных аренов, достаточно было измерять оптическую плотность смеси при шести АДВ. Дальнейшее увеличение числа АДВ не приводило к снижению погрешностей группового анализа. Сопоставление значений RMSEP, полученных при разном числе АДВ (от 6 до 250), подтверждает этот вывод. Во всех случаях значения RMSEP были довольно близки между собой (0.015–0.025 мг/мл).
Таким образом, эксперимент, проведенный нами на модельных смесях моноциклических аренов, показал, что многомерные градуировки, традиционно применяемые для раздельного определения однотипных аналитов, могут быть с успехом использованы и для оценки суммарного содержания тех же аналитов. Более того, с помощью таких градуировок суммарные содержания аналитов в их аддитивных смесях определяются точнее, чем индивидуальные концентрации.
Используя оптимальное число АДВ, с помощью многомерных градуировок первого типа можно довольно точно (±5%) определять суммарное содержание моноциклических аренов в многокомпонентных модельных растворах. Интересно, что решение той же задачи путем расчета интегрального показателя приводит к менее точным оценкам сΣ (±7%), хотя этот показатель измеряли при оптимальной АДВ (250 нм) и выражали в пересчете на оптимальное стандартное вещество [12].
Многомерные градуировки первого типа желательно использовать для определения суммарного содержания аналитов в тех объектах, где число определяемых однотипных веществ невелико, а их перечень заранее известен. Пример – анализ синтетических лекарственных препаратов и биологически активных добавок. Градуировки первого типа можно использовать и при небольших отличиях состава проб от перечня эталонов, используемых для построения многомерной градуировки. Введение “лишних” эталонов при построении модели не приводит к росту погрешностей группового анализа (при том же числе АДВ). Для повышения точности оценки cΣ желательно формировать как можно более полную матрицу коэффициентов поглощения, по возможности включая в нее данные обо всех компонентах искомой группы. Это особенно важно при не полностью известном качественном составе смесей аналитов в исследуемых пробах.
Оценить суммарное содержание однотипных аналитов можно и с помощью упрощенных моделей, включающих коэффициенты поглощения лишь некоторых компонентов искомой группы. Конечно, в этом случае погрешность результатов группового анализа должна увеличиться. Поэтому важно включить в упрощенную модель наиболее “типичные” эталоны, выбранные так, чтобы модель охватывала весь диапазон возможных значений коэффициентов поглощения аналитов искомой группы. Этот прием позволил нам получать довольно точные результаты анализа шестикомпонентных смесей, используя всего три эталона.
Если качественный состав искомой группы очень сложен и недостаточно изучен, то матрицу коэффициентов поглощения составить не удастся. В таких случаях многомерные градуировки первого типа применять не следует. В ходе группового анализа можно использовать многомерные градуировки второго типа. Примерами могут быть определение суммарного содержания аренов в сточных водах [12] или определение суммарных содержаний алканов, циклоалканов и аренов в бензинах [7]. Аналитические возможности многомерных градуировок второго типа будут рассмотрены нами в следующем сообщении.
Авторы благодарят к. ф.-м. н. С.М. Добровольского за ценные советы и замечания. В выполнении эксперимента принимали участие студенты О.А. Казакова и П.А. Бурюкина.
Список литературы
Baena J.R., Valcarcel M. Total indices in analytical sciences // Trends Anal. Chem. 2003. V. 22. № 10. P. 641.
Vershinin V.I. Total indices as a tool to estimate sum content of similar analytes. Review // Talanta. 2015. V. 131. № 1. P. 293.
Хатмуллина Р.М., Сафарова В.И., Латыпова В.З. Достоверность оценки загрязненности вод нефтяными углеводородами и фенолами с помощью некоторых интегральных показателей // Журн. аналит. химии. 2018. Т. 73. № 7. С. 545. (Khatmullina R.M., Safarova V.I., Latypova V.Z. Reliability of the assessment of water pollution by petroleum hydrocarbons and phenols using some of total indices // J. Anal. Chem. 2018. V. 73. № 7. P. 728.)
Вершинин В.И. Формирование групп и выбор стандартных веществ при определении суммарных содержаний однотипных соединений в виде интегральных показателей // Журн. аналит. химии. 2017. Т. 72. № 9. С. 816. (Vershinin V.I. Group formation and choice of standard substances in the determination of total concentrations of similar compounds as total indices // J. Anal. Chem. 2017. V. 72. № 9. P. 947.)
Rambla F.J., Garrigues S., de la Guardia M. PLS-NIR determination of total sugar, glucose, fructose and sucrose in aqueous solutions of fruit juices // Anal. Chim. Acta. 1997. V. 344 P. 41.
Cozzolino D., Kwiatkovski M.J, Parker M.,Cunkar W.U., Dambergs R.G., Gishen M., Gerderich M.J. Prediction of phenolic compounds in red wine fermentations by visible and near infrared spectroscopy // Anal. Chim. Acta. 2004. V. 513. № 1. P. 73.
Вершинин В.И., Коптева Е.В, Троицкий В.В. Определение суммарных содержаний парафинов, нафтенов и аренов по светопоглощению бензинов в ближней ИК-области // Заводск. лаборатория. 2005. Т. 71. № 11. С. 10.
Quansheng C., Jiewen Z., Muhua L., Jianrong C., Jianchua L. Determination of total polyphenols content in green tea using FT-NIR spectroscopy and different PLS algorithms // J. Pharm. Biomed. Anal. 2008. V. 46. № 3. P. 568.
Власова И.В., Цюпко Т.Г., Шелпакова А.С. Определение суммарного содержания антиоксидантов полифенольного типа по УФ спектру поглощения смеси // Методы и объекты химического анализа. 2012. Т. 7. № 1. С. 18.
Бурюкина П.А., Власова И.В., Миргалеева Р.Р. Оценка суммарного содержания аренов в технических водах методом спектрофотометрии в сочетании с алгоритмом множественной линейной регрессии // Вестник Омского университета. 2016. № 3. С. 54.
Vershinin V.I., Petrov S.V. The estimation of total petroleum hydrocarbons in waste waters by multiwave IR spectrometry with multivariate calibrations // Talanta. 2016. V. 148. P. 163.
Антонова Т.В., Вершинин В.И., Власова И.В. УФ-спектрометрическое определение суммарного содержания аренов в сточных водах // Журн. аналит. химии. 2021. Т. 76. № 7. С. 815.
Brereton R.G. Introduction to multivariate calibration in analytical chemistry // Analyst. 2000. V. 125. № 11. P. 2125.
Esbensen K.H. Multivariate Data Analysis – in Practice. An Introduction to Multivariate Data Analysis and Experimental Design. 5th Ed. Woodbridge: Camo Process AS, 2004. 588 p.
Смагунова А.Н., Карпукова О.М. Методы математической статистики в аналитической химии. Ростов-на-Дону: Феникс, 2012. 346 с.
Берштейн И.Я., Каминский Ю.Л. Спектрофотометрический анализ в органической химии. Ленинград: Химия, 1986. 200 с.
Дополнительные материалы отсутствуют.
Инструменты
Журнал аналитической химии