

Поверхность. Рентгеновские, синхротронные и нейтронные исследования, 2021, № 5, стр. 84-94
Технологии искусственного интеллекта и машинного обучения для двумерных материалов
Д. Ю. Кирсанова a, *, М. А. Солдатов a, З. М. Гаджимагомедова a, Д. М. Пашков a, А. В. Чернов a, М. А. Бутакова a, А. В. Солдатов a
a Международный исследовательский институт интеллектуальных материалов,
Южный федеральный университет
344090 Ростов-на-Дону, Россия
* E-mail: dkirs27@gmail.com
Поступила в редакцию 08.08.2020
После доработки 25.10.2020
Принята к публикации 30.10.2020
Аннотация
В настоящее время важным актуальным направлением исследований в области двумерных (2D) материалов и их поверхностных характеристик является ускорение процесса поиска параметров синтеза новых структур, обладающих уникальными свойствами. Достигнутый уровень развития технологий искусственного интеллекта и особенно машинного обучения позволяет уже сейчас активно использовать эти методики для решения широкого круга задач, в том числе и в области наук о 2D-материалах. В настоящей работе приводятся описание современного состояния технологий искусственного интеллекта и его подраздела – машинного обучения. Представленный обзор литературы описывает возможности технологий машинного обучения для решения задач в области двумерных наноматериалов как на этапах компьютерного дизайна, так и химического синтеза, и диагностики полученных 2D-наноструктур и их поверхностей. Особое внимание уделено применению технологий машинного обучения для поиска новых 2D-материалов, обладающих заданными характеристиками, которые могут быть успешно использованы в целом ряде перспективных областей применения.
ВВЕДЕНИЕ
Двумерные наноструктуры занимают особое место среди наноматериалов. Важным этапом развития этой области явилось открытие графена и последовавшее за этим исследование его уникальных свойств [1]. Графеноподобные материалы благодаря своим уникальных характеристикам стали востребованными в самых разных областях, включая биомедицинские технологии [2]. Развернувшиеся широким фронтом исследования открыли пути для целого ряда инновационных применений [3]. В последнее время научный поиск в этой области не ограничивается только графеноподобными наноструктурами [4]. Крайне интересными свойствами обладают 2D-материалы для их использования в электрокаталитических процессах [5]. Не менее перспективными оказались двумерные нанокатализаторы и для фотокаталитических процессов восстановления СО2 [6].
Важной чертой двумерных наноструктур с развитой поверхностью является возможность их использования в качестве высокочувствительных сенсоров [7]. Уникальные характеристики некоторых классов двумерных наноструктур позволяют использовать их в новых типах электрохимических аккумуляторов и топливных элементов [8]. Недавние исследования в области применения инженерии дефектов позволяют повысить эффективность 2D-фотокатализаторов для процессов органического синтеза [9]. В последнее время начаты активные исследования новых классов веществ – ван-дер-ваальсовых гетероструктур, основу для которых создают двумерные слои [10]. Весьма перспективными для практического инновационного применения могут оказаться такие новые классы двумерных материалов, как борофены (borophenes) [11] и Мксены (MXenes) [12]. Следует отметить, что в связи с особыми характеристиками двумерных наноструктур для их исследования разрабатываются различные специальные подходы, в том числе для нанодиагностики с использованием источников синхротронного излучения [13]. Запросы развития высокотехнологического сектора экономики диктуют потребность ускорения поиска новых двумерных материалов, и новая сквозная технология на основе искусственного интеллекта открывает существенные перспективы в этой области.
Целью настоящей работы является обзор современных исследований в области применения технологий искусственного интеллекта и машинного обучения для двумерных материалов.
ВВЕДЕНИЕ В ТЕХНОЛОГИИ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА И МЕТОДЫ МАШИННОГО ОБУЧЕНИЯ
За более чем полувековую историю развития искусственный интеллект приобрел прочную теоретическую базу, утвердившись как самостоятельное научное направление, относящееся в основном к области компьютерных наук. Тем не менее, проблемы, затрагиваемые искусственным интеллектом, проявляются в смежных научных областях, например, в теории систем управления, нейробиологических науках, прикладной математике, лингвистике, философии и психологии.
Подходы к формированию и построению научных исследований в искусственном интеллекте также, как и в других научных областях, можно разделить на абстрактно-символические и вычислительно-прагматические, как показано на рис. 1. Абстрактно-символическое направление в искусственном интеллекте восходит своими корнями к теоретико-множественным и логическим основаниям самой абстрактной и одновременно самой практичной из всех фундаментальных наук – математике.
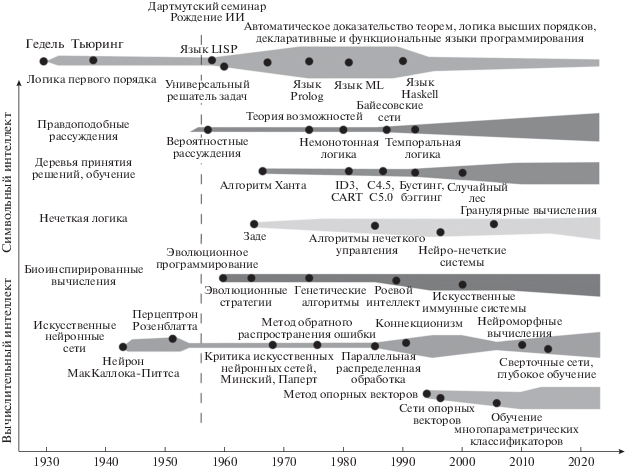
На базе предикатных логик первого порядка успешно создаются теоретические логические системы, используемые в искусственном интеллекте для автоматического доказательства теорем, например, формальная логическая система автоматического вывода на основе дедуктивной теории вычетов по модулю [14]. Достаточно интенсивно развиваются также прикладные программные реализации систем автоматического доказательства теорем средствами логики первого порядка [15] и библиотеки тестовых задач для автоматического доказательства теорем, использующие клаузальные нормальные формы [16]. Имеются и современные реализации на логическом языке SWI-Prolog, предназначенные для автоматической генерации экспертных систем обработки текстов на основе дедуктивного вывода на графах дизъюнктов [17].
Другая сторона символического интеллекта и представления знаний в искусственных интеллектуальных системах связана с очевидным фактом – исключительная часть реальной информации, которая является входной для искусственных интеллектуальных систем является плохо обусловленной и систематизированной, носящей возможностный и вероятностный характер. Одним из методов описания этой особенности символического интеллекта является нечеткая логика. Приемы и подходы, которые используются в нечеткой логике в настоящее время вышли далеко за рамки рассмотрения логики как таковой. Полувековое развитие нечеткой логики в работе [18] дается самим ее основоположником Л. Заде и в работе [19] известных в этой области ученых Д. Дюбуа и А. Прадэ. Распространение идей и методов нечеткой логики в сфере искусственного интеллекта оказалось столь широким, что в настоящее время ее можно считать одним из “символов” не только символического, но и вычислительного искусственного интеллекта. Нечеткую логику, построенную на базе математического аппарата нечетких множеств, много раз подвергали улучшениям и расширениям, имеющим особое значение для систем искусственного интеллекта, например, для комплекснозначного представления данных [20] в направлении правдоподобного вывода на интуиционистских нечетких множествах [21], нечеткого аналитического [22] и нечеткого когнитивного [23] подходов к принятию решений.
Основное внимание в современных подходах представления знаний в интеллектуальных искусственных системах уделяется не столько самим принципам организации и формализации баз знаний как набору договоренностей онтологического характера, то есть обеспечению структурированности, связности, а затем процессу интерпретируемости, переносу знаний в машинный формат. Для этого широко используются многочисленные семейства дескрипционных логик [24], в том числе дескрипционных онтологий [25] и языков представления онтологий типа OWL (Web Ontology Language).
Гораздо более сложными представляются процессы и приемы сопоставления искусственных знаний реальной действительности, причем таким образом, чтобы с одной стороны воспроизводимые искусственные знания не отрывались от реальности, не строились на догадках и обладали свойствами, находящими подтверждение во внешнем мире. С другой стороны, необходимо чтобы правдоподобные рассуждения в искусственных интеллектуальных системах являлись прагматически пригодными и эффективными для их формального исполнения в вычислительных системах, имеющих в некоторых случаях, например, в автономных мобильных платформах, ограниченные вычислительные ресурсы. Для этого различные подходы правдоподобных рассуждений теории искусственного интеллекта используют различные способы описания и формального определения меры неопределенности информации, уверенности и убежденности в знаниях вместе со степенью правдоподобности самого процесса рассуждений. Трудно формализуемые понятия о неопределенности и неуверенности как начальные предпосылки исследовательского процесса породили значительное число математических направлений и подходов, аппарат которых стал впоследствии использоваться в теории искусственного интеллекта. В их числе классический и байесовский вероятностные подходы, теория свидетельств, теория возможностей, интервальные неклассические вероятности, вероятностная логика, ситуационное и событийное исчисление, теорию пересматриваемых рассуждений, теорию аргументации, модели Крипке, мультиагентные и гранулярные вычисления, а также широкие классы правдоподобных систем логического вывода, построенных на индукции и абдукции. В условиях поступления больших объемов информации в искусственных интеллектуальных системах приобретает значение современное развитие методов теории аргументации как автоматическое экстрагирование и структуризация аргументов [26] и искусственная вычислительная аргументация [27].
Направления абстрактно-символического интеллекта, рассмотренные выше, относятся к так называемым “top-down” подходам в теории искусственного интеллекта. Не менее известными являются и “bottom-up” подходы, которые берут свое начало от задач изучения и моделирования нейробиологических принципов функционирования естественных организмов и мозга человека. Особенно известным и чрезвычайно распространенным на сегодняшнее время является аппарат искусственных нейронных сетей, который постоянно дополняется не только новыми техническими возможностями, но и постоянно подвергается пересмотру и приближению к имитации когнитивных и мыслительных способностей человека.
В настоящее время более важным является факт, что сам математический аппарат искусственных нейронных сетей, не претендуя на исключительную точность воспроизведения нейробиологических процессов, происходящих в естественных организмах, дополненный колоссальными вычислительными возможностями современных компьютеров и инфокоммуникационных сетей, может использоваться повсеместно в самых различных прикладных областях, где имеются задачи классификации объектов и распознавания образов.
Большой популярности искусственных нейронных сетей способствуют достаточно простые (если их рассматривать на начальном уровне) и понятные широкому большинству принципы их функционирования, огромное число научных и популярных статей, книг и руководств по созданию, обучению и использованию искусственных нейронных сетей, а также множество реализаций их в виде программных модулей и библиотек, которые под силу использовать даже неспециалисту в области программирования. Действительно, принцип функционирования элементарного искусственного нейрона был изначально очень простым – взвешенная сумма входных числовых значений, передаваемая от рецепторов или искусственных синаптических связей предыдущего слоя, активирует простую скачкообразную пороговую функцию, которая либо передает, либо не пропускает дальнейшее распространение выходного значения от этого элемента следующим. Естественно, что один искусственный нейрон не мог адекватным образом решить задачи классификации множества объектов, кроме того требования наличия многих входов от различных сенсорных устройств-искусственных рецепторов дали основание для появления различных вариантов соединения искусственных нейронов в сетевые структуры, называемые топологиями искусственных нейронных сетей. Со временем усложнились и разнообразные виды пороговых функций, которые принято называть функциями активации искусственных нейронов. Сейчас искусственная нейронная сеть представляет собой массивно-параллельную распределенную систему обработки информации, суперкомпьютерные реализации которых могут насчитывать десятки миллионов искусственных нейронов с гораздо большим числом искусственных синаптических связей между ними. Очевидно, что прежде, чем использовать такую сеть, либо имеющую даже существенно меньший размер, необходимо, выбрав цель и представив желаемый конечный результат, приложить усилия, направленные на минимизацию неверных вариантов классификации, некорректного отбора образцов, несоответствующего действительности выбора альтернатив, формируемого выходом искусственной нейронной сети. В упрощенном понимании обучение искусственной нейронной сети – это процедура изменения весов и смещений сети, выполняемая в соответствии с некоторым алгоритмом обучения, и предназначенная для того, чтобы “научить” сеть давать конкретный ответ на конкретный набор входных данных. Алгоритмы обучения весьма важны, как в отношении точности выходной классификации, совместно с адекватностью их входам, так и в отношении вычислительной сложности, характеризующей затраты времени на процесс предварительного обучения сети.
Выбор общей архитектуры и алгоритмов обучения искусственных нейронных сетей по сей день остается достаточно нетривиальной задачей и требует от исследователя хотя бы начальных знаний во многих смежных с искусственным интеллектом областях, особенно математических навыков. Не всегда получается успешно решить основные задачи классификации, кластеризации, распознавания образов на основе относительно простых архитектур и алгоритмов обучения искусственных нейронных сетей. В таких случаях прибегают к использованию сложных многоуровневых архитектур искусственных нейронных сетей, за счет чего появляется возможность представления входных данных под задачу на различных уровнях абстракции с помощью различных нелинейных вычислительных узлов-нейронов. Подчеркивание этого отличия фиксируется в названии группы методов машинного обучения, которые называются “глубоким обучением” и часто наличием сверхточной структуры искусственных нейронных сетей. Эта область машинного обучения использует многоуровневое представление функции, подлежащей обучению и имеющей зачастую множество параметров, а сам процесс обучения выполняется на больших данных для повышения точности классификации объектов либо прогнозирования процессов. Естественным последствием такого усложнения является существенное увеличение как технических ресурсов, так и временных затрат на обучение такой многоуровневой и разнородной на каждом из уровней архитектуры искусственной нейронной сети. С появлением соответствующих аппаратных компьютерных и эффективных вычислительных средств, технологии глубокого обучения искусственных нейронных сетей находятся сейчас на этапе подъема и значительного интереса во многих прикладных областях использования интеллектуальных искусственных систем.
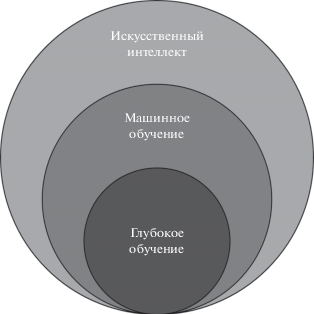
Кроме этого, в современном мире активно используются методы машинного обучения, а особенно глубокого обучения, для решения широкого спектра задач как прикладного характера, так и научного. Машинное обучение является одной из областей искусственного интеллекта (рис. 2), которая получила мощный толчок к развитию благодаря возросшим вычислительным мощностям современной компьютерной техники и наличию большого количества данных.
Задачей, которую решают методы машинного обучения, является нахождение неизвестной зависимости в данных, которые называют обучающей выборкой. Обучением называется процесс нахождения алгоритма, который аппроксимировал бы неизвестную зависимость оптимальным образом. Среди методов машинного обучения можно выделить три основных типа:
1. Обучение с учителем. Для данного типа методов обучающая выборка представлена парами “объект–ответ”. Основными задачи методов обучения с учителем являются:
а) классификация – случай, когда множество ответов является конечным; б) регрессия – случай, когда множество ответов бесконечно (вещественные числа).
2. Обучение без учителя. В этом случае обучающая выборкой является только множество объектов. Среди типичных задач обучения без учителя:
а) кластеризация – разбиение выборки на несколько непересекающихся множеств;
б) сокращение размерности – представление обучающей выборки в пространстве меньшей размерности;
в) визуализация данных – отображение данных в виде графиков на плоскости и другие.
3. Обучение с подкреплением. Метод машинного обучения, называемый агентом, обучается через взаимодействие с окружающей его средой. Агент в ходе обучения учится действовать так, чтобы максимизировать потенциальный выигрыш.
К алгоритмам обучения с учителем относятся:
1. Байесовский классификатор [28] основан на применении теоремы Байеса. После нахождения апостериорных вероятностей классов для рассматриваемого объекта, описанного набором признаков, алгоритмом выбирается наиболее вероятный класс в качестве ответа. Используется в основном для задач классификации.
2. Метод опорных векторов [29, 30] строит оптимальную разделяющую гиперплоскость в пространстве параметров обучающей выборки. Является хорошим методом для решения задач классификации, но также используется и для задач регрессии.
3. Дерево решений [31] является древовидной структурой, предназначенной для принятия решений. Деревья решений состоят из решающих правил, по которым происходит ветвление, причем в первую очередь выбираются признаки с минимальной энтропией. Метод может быть использован как для классификации, так и для регрессии.
4. Метод k-ближайших соседей [32] является простым метрическим алгоритмом классификации. Объекту ставится в соответствие тот класс, объектов которого находится больше всего среди k ближайших соседей. Метод может использоваться и для задач регрессии, в этом случае объекту присваивается среднее значение k ближайших соседей.
Примером алгоритмов обучения без учителя являются:
1. Алгоритм k-средних (k-means) [33] является итеративным алгоритмом кластеризации, который относит объект к тому кластеру, чей центр ближе. Центры кластеров пересчитываются в конце каждой итерации.
2. Метод главных компонент (PCA) [34, 35] является одним из основных методов для решения задачи уменьшения размерности, который строит новые компоненты теряя наименьшее количество информации. Главные компоненты могут быть найдены путем сингулярного разложения матрицы (SVD-разложение) объектов-признаков.
ТЕХНОЛОГИИ МАШИННОГО ОБУЧЕНИЯ ДЛЯ ПОИСКА НОВЫХ МАТЕРИАЛОВ И СТРУКТУР
Традиционные методы проб и ошибок, как правило, препятствуют крупномасштабному поиску новых функциональных материалов. Подходы многомасштабного компьютерного моделирования, усиленные методами машинного обучения, переводят процесс поиска новых функциональных материалов на принципиально новый уровень.
Так, например, Schleder с соавторами использовали технологии машинного обучения для определения термодинамически стабильных двумерных материалов [36]. Для этого была проведена классификация материалов по энергиям образования. На основе данных о составе и симметрии (без использования информации об атомных позициях) материалы были отнесены к классу с низкой, средней или высокой стабильностью. Предложенный подход позволил выявить наиболее перспективные новые двумерные материалы для более тщательного анализа. Для проверки применимости модели были сгенерированы более тысячи новых структур. Для некоторых из них классификация была подтверждена расчетами в приближении теории функционала плотности (ТФП). В результате был предложен новый материал, потенциально обладающий высокой эффективностью для фотоэлектрокаталитического разложения воды – Sn2SeTe.
В работе [37] предложили метод, объединяющий высокопроизводительные ab initio расчеты и подходы машинного обучения, для предсказания структур двумерных октаэдрических оксигалогенидов с улучшенными оптоэлектронными свойствами. Для этого была разработана модель, основанная на обширном наборе данных, включающем в себя 300 структур двухмерных октаэдрических оксигалогенидов, сгенерированных на основе вычислений в приближении ТФП. Модель позволила ускорить проверку 5000 потенциальных оптоэлектрических материалов на основе октаэдрических оксигалогенидов. Ключевую роль в прогнозировании оптоэлектронных свойства в этой модели играли факторы искажения сложенных октаэдров. На основе разработанной модели было показано, что Bi2Se2Br2, Bi2Se2BrI и Bi2Se2I2 обладают оптимальными оптоэлектронными свойствами: умеренной шириной запрещенной зоной, высокой мобильностью носителей заряда и сверхвысокими коэффициентами поглощения.
В работе [38] применили комбинацию машинного обучения и высокопроизводительного скрининга двумерных материалов для фотовольтаики [8]. В результате из 187 093 неорганических кристаллических структур были выбраны двадцать шесть наиболее перспективных кандидатов. Помимо прогнозирования материалов с наиболее высокой эффективностью преобразования энергии, модель позволила установить фундаментальную закономерность структуры и свойств: коэффициент упаковки влияет на вероятность обладания подходящими физическими свойствами. Результаты показали, что Sb2Se2Te, Sb2Te и Bi2Se3 обладают высокой эффективностью преобразования энергии и являются кандидатами для использования в фотовольтаике.
В работе [39] Frey с соавторами использовали методику обучения на основе положительных и неразмеченных данных (Positive and Unlabeled) для определения вероятности возможности синтеза теоретически предложенных двумерных материалов на основе карбидов, карбонитридов и нитридов переходных металлов. На основе модели выделены 18 материалов с наиболее высокой вероятностью возможности синтеза, при этом наиболее высокую вероятность показал двумерный материал на основе циркония – Zr2GaC.
В работе [40] Momeni с соавторами в своем обзоре рассмотрели различные комбинации теоретических расчетов двумерных материалов и методов машинного обучения. В частности, были показаны особенности прогнозирования термодинамики и кинетики синтеза двумерных материалов. Авторы предполагают, что будет развиваться два основных подхода для дизайна и синтеза новых двумерных материалов. Один подход предполагает, что перед синтезом материалов будет проведено компьютерное моделирование, учитывающее физико-химические условия синтеза. Второй подход будет включать в себя замкнутый цикл, в котором условия синтеза будут корректироваться в режиме реального времени.
В работе [41] Fujikake с соавторами использовали межатомные потенциалы для моделирования гостевых атомов лития в структуре графена, графита и аморфных углеродных наноструктурах. Для обучения нейросети использовались данные расчeтов ТФП. Вместо рассмотрения полной системы Li–C была рассмотрена разность энергий и сил, возникающая в результате интеркаляции атомов лития. Было показано, что рассмотрение парного потенциала позволило обнаружить взаимодействие между атомами лития, что улучшило модель гауссового потенциала. Таким образом была показана возможность применения парных потенциалов, полученных на основе алгоритмов машинного обучения.
Атомная структура графена, легированного бором, была исследована в работе [42]. Для анализа массива данных авторы использовали такой метод машинного обучения, как поиск по дереву Монте-Карло (Monte Carlo tree search) с байесовским развертыванием для поиска наиболее стабильной структуры B-графена с концентрацией бора до 31.25%. Было обнаружено, что в отдельно стоящем, чистом графене легированные атомы бора замещают атомы углерода в различных узлах подрешетки, причем конфигурация B–B является доминирующей в случаях высокой концентрации бора. Легирование бором может увеличить работу выхода графена на 0.7 эВ при содержании бора выше 3.1%.
В табл. 1 приведены функциональные двумерные материалы, предсказанные на основе технологий искусственного интеллекта.
ТЕХНОЛОГИИ ИСКУССТВЕННОГО ИНТЕЛЛЕКТА ДЛЯ ПРЕДСКАЗАНИЯ ФИЗИЧЕСКИХ СВОЙСТВ И СТРУКТУРНЫХ ХАРАКТЕРИСТИК 2D-МАТЕРИАЛОВ
В последние годы инструменты искусственного интеллекта были предложены для повышения эффективности методов диагностики 2D-материалов. Кроме этого, использование алгоритмов искусственного интеллекта позволяет предсказывать структурные характеристики, электронные и тепловые свойства различных двумерных структур.
Для исследования двумерных материалов алгоритмы машинного обучения, интегрированные с другими подходами, могут использоваться для количественной оценки толщины слоя графена и количества в нем примесей. Так, например, Leong вместе с соавторами представили быстрый и неразрушающий подход использования искусственного интеллекта для оценки качества (т.е. порядок упаковки и количество слоев) образцов графена сантиметрового размера путем анализа данных спектроскопии комбинационного рассеяния [43]. Чтобы использовать инструмент искусственного интеллекта для анализа данных комбинационного рассеяния, конечным пользователям нужно только загрузить спектры комбинационного рассеяния, собранные для исследуемых образцов графена, в качестве входных данных, и анализ данных комбинационного рассеяния будет выполняться автоматически. При использовании данной методики три параметра ωG, ω2D и Г2D (ωG и ω2D – положения G- и 2D-полос соответственно, Г2D – полуширина на половине высоты 2D-пика) были извлечены из каждого спектра комбинационного рассеяния, затем они были выбраны в качестве функций кластеризации в алгоритме k-средних. Например, при помощи данного метода были определенны два кластера, которые представляли собой монослой и двухслойный графен. Кроме того, было показано, что, хотя рассматриваются только три параметра, предложенный анализ позволяет распознать графен толщиной от одного до пяти слоев и приблизительно оценить их углы закручивания. Сообщается, что данный алгоритм полностью автоматизирован, не требует участия человека, отличается высокой надежностью (точность 99.95%) и может быть распространен на другие 2D-материалы, для которых анализ комбинационного рассеяния является удобным методом исследования количества слоев в слоистых соединениях типа GeS, SnS, MoS2 и др. А также разработанный метод контроля качества с помощью искусственного интеллекта не ограничивается анализом спектра комбинационного рассеяния и может быть применим к результатам анализа с помощью других методов определения характеристик 2D-материалов, таких как сканирующая электронная микроскопия, сканирующая зондовая микроскопия и т.д.
Другие характеристики графена были также исследованы при помощи алгоритмов искусственного интеллекта. Так, Garg и соавторы [44] предложили новый вычислительный подход по оценке механических свойств образцов графена. В этом методе факторы, влияющие на модуль сдвига графеновых структур, анализируются с использованием моделирования методом молекулярной динамики (МД). Затем полученные данные обрабатываются методом программирования с экспрессией генов. При этом данный подход позволяет сформулировать явную зависимость модуля сдвига графеновой наноструктуры от соотношения сторон графеновых листов, температуры, количества атомных плоскостей и количества дефектов. Было выявлено, что модуль сдвига, предсказанный с помощью предложенной модели, хорошо согласуется с экспериментальными результатами, полученными из литературы (значение R 2 составляет порядка 0.94). Кроме того, чтобы выяснить конкретное влияние каждого из входных параметров системы на модуль сдвига графеновых структур, были оценены чувствительности метода от входных величин. Результаты показали, что именно количество дефектов имеет наибольшее влияние на модуль сдвига для каждого графенового листа, а дальше в порядке убывания влияния располагаются температура, количество слоев и соотношение сторон.
В работе [45] было продемонстрировано использование машинного обучения для предсказания различий между электронными свойствами графеновых наноструктур на двух уровнях приближения: методом функционала плотности и самосогласованным методом сильной связи на основе теории функционала плотности (Self-consistent Charge Density Functional Tight Binding). При этом оптимизация модели и выбор функций были выполнены с 70% набора данных, в то время как оставшиеся 30% были использованы для проверки способности моделей к прогнозированию. В результате было определена точность предсказания предложенной модели машинного обучения, которая составила 94 и 88% для энергии уровня Ферми и для ширины запрещенной зоны соответственно. В другом исследовании вышеупомянутой научно-исследовательской группы [46] машинное обучение было использовано для прогноза энергии запрещенной зоны графеновых нанохлопьев с использованием метода топологической автокорреляции (Topological Autocorrelation Vectors). Выборка данных состояла из энергий запрещенных зон 662 оптимизированных графеновых наночастиц. Моделирование методом машинного обучения показало, что наиболее подходящие соотношения появляются на топологических расстояниях в диапазоне от 1 до 42 с точностью прогноза более 80%. Предложенная модель может статистически значимо различать графеновые нанохлопья с разной энергетической щелью на основе их молекулярной топологии.
Допирующие атомы играют ключевую роль в формировании электронных свойств многих материалов. Тем не менее, количество возможных комбинаций типов и концентраций допирующих атомов приводит к значительному числу возможных атомных конфигураций. Dong с соавторами использовали подходы глубокого машинного обучения для прогнозирования ширины запрещенной зоны графена допированного атомами бора и азота [47]. Для обучения нейросети использовались наборы данных, полученных на основе ab initio расчетов. Полученная модель успешно прогнозирует ширину запрещенной зоны с точностью выше 90% при среднеквадратичном отклонении порядка 0.1 эВ.
Кроме того, электронные свойства не только графеновых наноструктур, но и двумерных карбидов и нитридов переходных металлов (Мксенов) были исследованы при помощи моделей машинного обучения. Так, Rajan с коллегами построили модели статистического обучения для точного прогнозирования запрещенной зоны этого обширного класса материалов [48]. Модели были разработаны с использованием алгоритмов ядерной гребневой регрессии, регрессии опорных векторов, гауссовского процесса и бэггинга при использовании таких свойства Мксенов, как точки кипения и плавления, номера группы, атомные радиусы, фазы, длины связей и т.д., в качестве входных функций. Отмечается, что среди них модель гауссовского процесса предсказывает ширину запрещенной зоны с наименьшей среднеквадратичной ошибкой 0.14 эВ в течение нескольких секунд. При этом авторами работы была разработана модель классификации металл–полупроводник с точностью до 94%.
В работе [49] Patra и соавторы использовали машинное обучение с учителем, МД-моделирование и просвечивающую электронную микроскопию высокого разрешения, чтобы полностью понять фазовое превращение в двумерных дихалькогенидах переходных металлов. Генетические алгоритмы были объединены с МД для исследования расширенной структуры точечных дефектов, их динамической эволюции и роли в индуцировании фазового перехода между полупроводниковой (2H) и металлической (1T) фазами в монослое MoS2. Генетический алгоритм используется для эффективного поиска наиболее энергетически выгодного распределения атомных дефектов, которым, как было обнаружено, является организация преобладающего типа дефектов (точечных вакансий серы) в протяженные линии в слое MoS2. При помощи просвечивающей электронной микроскопии высокого разрешения были подтверждены полученные результаты и было предположено фазовое превращение из фазы 2H в 1T, которая локализуется вблизи этих линейных дефектов при воздействии высоких доз электронного пучка. Моделирование методом МД, в свою очередь, объясняет молекулярный механизм этого фазового превращения, вызванного дефектами. Он заключается в том, что атомы серы локально скользят к дефектам и приводят к образованию промежуточной α-фазы, которая запускает формирование 1Т-фазы. При этом отмечается, что конечное количество фазы 1T может быть сохранено за счет увеличения концентрации дефектов и температуры.
Yang с соавторами использовали машинное обучение для определения межфазного термического сопротивления в термопроводящих материалах на основе графена и гексагонального нитрита бора на основе данных о температуре системы, силах адгезии и деформационных растяжениях в плоскости [50]. Тренировочный набор данных был получен с помощью расчетов в приближении МД. Лучшие результаты показали методы на основе двухслойной нейросети.
В работе Han и соавторов [51] алгоритм на основе нейронной сети архитектуры (кодировщик-декодер) используется для идентификации и определения толщины 2D-образцов путем попиксельного распознавания в реальном времени изображений, полученных методом оптической микроскопии, различных 2D-материалов при помощи семантической сегментации. Было показано, что обученная сеть может извлекать графические особенности, такие как контраст, цвет, края, формы, размеры чешуек и их распределение, на основе которых разрабатывается подход для прогнозирования наиболее важных физических свойств 2D-материалов. Кроме того, было обнаружено, что алгоритм находит корреляции между изображениями, полученными методом оптической микроскопии, и физическими свойствами 2D-материалов. Например, было предсказано, что 1T'–MoTe2 и Td–WTe2 материалы в необученной группе будут аналогичны 1T–HfSe2 в обученной группе, что соответствует аналогичной кристаллической структуре этих материалов. Таким образом, предложенный подход может использоваться для прогнозирования свойств новых, пока еще не исследованных 2D-материалов.
Машинное обучение было успешно применено и для оптической идентификации 2D-наноструктур, таких как графен, MoS2 и гетероструктуры из этих двух материалов [52]. В ходе этого исследования была разработан подход, основанный на обучаемом и автоматическом анализе красной, зеленой, синей информации оптических фотографий 2D-наноструктур с использованием метода опорных векторов. При этом оказалось, что при идентификации 2D-гетероструктур области подложки, графена, MoS2, гетероперехода, а также остатки резиста от процесса переноса могут быть автоматически распознаны с точностью до 90.16%. Результаты экспериментов показывают, что разработанный подход позволяет точно охарактеризовать графен, дисульфид молибдена и их гетероструктуры с точки зрения толщины образцов, наличия в них примесей и даже порядка упаковки.
Для анализа оптических изображений 2D-материалов в [53] было предложено разработать подход для быстрой идентификации 2D-материалов, суть которого состоит в комбинации модели отражения, основанной на законе Френеля, и машинного обучения. В данном исследовании были использованы такие три эффективных индекса, как оптический контраст (OК), общая цветоразность и анализ красно-зелено-синего индекса, чтобы с помощью оптической микроскопии определить оптимальные Si/SiO2-подложки и количество слоев нанесенных на подложку 2D-материалов. При этом, во-первых, были использованы ОК и общая цветоразность для определения подходящих подложек, которые максимально увеличивают разницу не только между 2D-материалом и подложкой, но и между 2D-материалом разных слоев. При этом алгоритмы k-средних и k-ближайших соседей используются для получения базы данных толщины 2D-материалов (графена и MoS2 на подложке Si/SiO2) и тестирования их оптических изображений с помощью индекса “красный–зеленый–синий”.
В работе Wang и соавторов [54] были независимо разработаны такие подходы машинного обучения, как анализ фаз и свойств системы интеграции генома материалов (Materials Genome Integration System Phase and Property Analysis, MIPHA) и rMIPHA (на основе языка программирования R) для прогнозирования свойств 2D-материалов. При их использовании были проведены двухмерный и трехмерный микроструктурный анализ сталей, прямой анализ прогнозов свойств и обратный анализ зависимости свойств от микроструктуры. При этом количественно определенные данные о микроструктуре и свойствах составляют “геномы материалов”, используемые для последующих прямых и обратных анализов, на основе которых были затем предсказаны кривые напряжения–деформации.
Как уже отмечалось ранее, в последнее время активно проводятся исследования новых классов веществ – ван-дер-ваальсовых гетероструктур. В принципе, количество различных структур, которые можно синтезировать, не ограничено. Поэтому даже теоретическое моделирование возможных структур в приближении ТФП является весьма времязатратным. Комбинация методов компьютерного моделирования и машинного обучения является более эффективной альтернативой как ТФП-расчетам, так и химическим синтезам. На основе методов машинного обучения были предсказаны такие параметры, как межслоевое расстояние и ширина запрещенной зоны для гибридных ван-дер-ваальсовых гетероструктур [55].
В табл. 2 приведены свойства и характеристики двумерных материалов, предсказанные на основе технологий искусственного интеллекта.
Таблица 2.
Свойства и характеристики двумерных материалов, предсказанные на основе технологий искусственного интеллекта
| Материал | Свойства и характеристики | Инструменты искусственного интеллекта | Источник |
|---|---|---|---|
| Графен | Количество слоев | Алгоритм k-средних | [43, 53] |
| Графен | Модуль сдвига | Метод программирования с экспрессией генов | [44] |
| Графен | Энергия Ферми и ширина запрещенной зоны | Множественная линейная регрессия, дерево решений, случайный лес, метод опорных векторов | [45] |
| Мксены | Ширина запрещенной зоны | Регрессия гребня ядра, метод опорных векторов, регрессия гауссовского процесса и бэггинг | [48] |
| MoS2 | Распределение точечных дефектов | Генетический алгоритм | [49] |
| Графен, MoS2 | Толщины образцов, наличие в них примесей | Метод опорных векторов | [52] |
| Ван-дер-ваальсовы гетероструктуры | Межслоевое расстояние и ширина запрещенной зоны | Нейронная сеть с прямой связью, метод опорных векторов, метод релевантных векторов, случайный лес | [55] |
ЗАКЛЮЧЕНИЕ
Обзор современных литературных данных по применению технологий искусственного интеллекта и особенно машинного обучения показывает, что эта новая сквозная технология уже сейчас активно начинает использоваться для решения широкого круга задач, в том числе и в области наук о двумерных материалах на всех этапах исследования (компьютерного дизайна, химического синтеза и последующей диагностики характеристик, полученных наноматериалов). Это позволяет дать существенный новый импульс новому этапу развития исследований поверхности и двумерных наноструктур как в области поиска параметров синтеза новых 2D-материалов, так и для предсказания их физико-химических характеристик, перспективных с точки зрения практического применения.
Список литературы
Geim A.K., Novoselov K.S. // Nature Materials. 2007. V. 6. № 3. P. 183.https://doi.org/10.1038/nmat1849
Cheng C., Li S., Thomas A. et al. // Chemical Reviews. 2017. V. 117. № 3. P. 1826.https://doi.org/10.1021/acs.chemrev.6b00520
Ferrari A.C., Bonaccorso F., Fal’ko V. et al. // Nanoscale. 2015. V. 7. № 11. P. 4598.https://doi.org/10.1039/C4NR01600A
Tan C., Cao X., Wu X.-J. et al. // Chemical Reviews. 2017. V. 117. № 9. P. 6225.https://doi.org/10.1021/acs.chemrev.6b00558
Jin H., Guo C., Liu X. et al. // Chemical Reviews. 2018. V. 118. № 13. P. 6337.https://doi.org/10.1021/acs.chemrev.7b00689
Mu Q., Zhu W., Li X. et al. // Applied Catalysis B: Environmental. 2020. V. 262. P. 118 144.https://doi.org/10.1016/j.apcatb.2019.118144
Mackin C., Fasoli A., Xue M. et al. // 2D Materials. 2020. V. 7. № 2. P. 022002. https://doi.org/10.1088/2053-1583/ab6e88
Panda M.R., Raj K A., Ghosh A. et al. // Nano Energy. 2019. V. 64. P. 103 951.https://doi.org/10.1016/j.nanoen.2019.103951
Sun X., Zhang X., Xie Y. // Matter. 2020. V. 2. № 4. P. 842.https://doi.org/10.1016/j.matt.2020.02.006
Novoselov K.S., Mishchenko A., Carvalho A., Castro Neto A.H. // Science. 2016. V. 353. № 6298. P. aac9439.https://doi.org/10.1126/science.aac9439
Silvestre G.H., Scopel W.L., Miwa R.H. // Nanoscale. 2019. V. 11. № 38. P. 17 894.https://doi.org/10.1039/c9nr05279h
Anasori B., Lukatskaya M.R., Gogotsi Y. // Nature Reviews Materials. 2017. V. 2. № 2. P. 16098.https://doi.org/10.1038/natrevmats.2016.98
Ge M., Lee W.-K. // J. Synchrotron Radiation. 2020. V. 27. № 2. P. 567.https://doi.org/10.1107/s1600577520001071
Burel G., Bury G., Cauderlier R. et al. // J. Automated Reasoning. 2019. V. 64. № 6. P. 1001.https://doi.org/10.1007/s10817-019-09533-z
Tammet T. // 27th International Conference on Automated Deduction. Natal, Brazil: Springer International Publishing, 2019. P. 538. https://doi.org/10.1007/978-3-030-29436-6_32
Sutcliffe G. // J. Automated Reasoning. 2017. V. 59. № 4. P. 483.https://doi.org/10.1007/s10817-017-9407-7
Garrido Merchán E.C., Puente C., Olivas J.A. // 14th International Conference, HAIS 2019. León, Spain: Springer International Publishing, 2019. P. 14. https://doi.org/10.1007/978-3-030-29859-3_2
Zadeh L.A. // Fuzzy Sets and Systems. 2015. V. 281. P. 4.https://doi.org/10.1016/j.fss.2015.05.009
Dubois D., Prade H. // Fuzzy Sets and Systems. 2015. V. 281. P. 21.https://doi.org/10.1016/j.fss.2015.09.004
Yazdanbakhsh O., Dick S. // Fuzzy Sets and Systems. 2018. V. 338. P. 1.https://doi.org/10.1016/j.fss.2017.01.010
Wang X., Xu Z., Gou X. // Fuzzy Optimization and Decision Making. 2020. V. 19. № 3. P. 251.https://doi.org/10.1007/s10700-020-09319-8
Liao H., Mi X., Xu Z. et al. // IEEE Transactions on Fuzzy Systems. 2018. V. 26. № 5. P. 2578.https://doi.org/10.1109/tfuzz.2017.2788881
Jiang L., Liao H. // Applied Soft Computing. 2020. V. 93. P. 106374.https://doi.org/10.1016/j.asoc.2020.106374
Butakova M., Chernov A., Guda A. et al. // Advances in Intelligent Systems and Computing, 2019. P. 225. https://doi.org/10.1007/978-3-030-01821-4_24
Konev B., Lutz C., Ozaki A., Wolter F. // J. Machine Learning Research. 2018. V. 18. № 1. P. 1.
Lippi M., Torroni P. // ACM Trans. Internet Technol. 2016. V. 16. № 2. P. 10:1. https://doi.org/10.1145/2850417
Katie A., Pietro B., Massimiliano G. et al. // AI Magazine. 2017. V. 38. № 3. P. 25.https://doi.org/10.1609/aimag.v38i3.2704
Langley P., Iba W., Thompson K. // Proceedings of the Tenth National Conference on Artificial Intelligence (AAAI'92). San Jose, California: AAAI Press, 1992. P. 223.
Cortes C., Vapnik V. // Machine Learning. 1995. V. 20. № 3. P. 273.https://doi.org/10.1007/bf00994018
Drucker H., Burges C.J.C., Kaufman L. et al. // Proceedings of the 9th International Conference on Neural Information Processing Systems, NIPS'96. Denver, Colorado: MIT Press, 1996. P. 155.
Quinlan J.R. // Machine Learning. 1986. V. 1. № 1. P. 81.https://doi.org/10.1007/bf00116251
Patrick E.A., Fischer F.P. // Information and Control. 1970. V. 16. № 2. P. 128.https://doi.org/10.1016/s0019-9958(70)90081-1
Barbakh W.A., Wu Y., Fyfe C. // Non-Standard Parameter Adaptation for Exploratory Data Analysis. Berlin, Heidelberg: Springer Berlin Heidelberg, 2009. P. 7.https://doi.org/10.1007/978-3-642-04005-4_2
Pearson K. // The London, Edinburgh, and Dublin Philosophical Magazine and J. Science. 2010. V. 2. № 11. P. 559.https://doi.org/10.1080/14786440109462720
Ringner M. // Nat Biotechnol. 2008. V. 26. № 3. P. 303.https://doi.org/10.1038/nbt0308-303
Schleder G.R., Acosta C.M., Fazzio A. // ACS Appl Mater Interfaces. 2020. V. 12. № 18. P. 20149.https://doi.org/10.1021/acsami.9b14530
Ma X.Y., Lewis J.P., Yan Q.B., Su G. // J. Phys. Chem. Lett. 2019. V. 10. № 21. P. 6734. Doi 10.1021/acs.jpclett.9b02420
Jin H., Zhang H., Li J. et al. // J. Phys. Chem. Lett. 2020. V. 11. № 8. P. 3075.https://doi.org/10.1021/acs.jpclett.0c00721
Frey N.C., Wang J., Bellido G.I.V. et al. // ACS Nano. 2019. V. 13. № 3. P. 3031.https://doi.org/10.1021/acsnano.8b08014
Momeni K., Ji Y., Wang Y. et al. // npj Computational Materials. 2020. V. 6. № 1. P. 1. https://doi.org/10.1038/s41524-020-0280-2
Fujikake S., Deringer V.L., Lee T.H. et al. // J. Chem. Phys. 2018. V. 148. № 24. P. 241714.https://doi.org/10.1063/1.5016317
Dieb T.M., Hou Z., Tsuda K. // J. Chem. Phys. 2018. V. 148. № 24. P. 241716.https://doi.org/10.1063/1.5018065
Leong W.S., Arrabito G., Prestopino G. // Crystals. 2020. V. 10. № 4. P. 308.https://doi.org/10.3390/cryst10040308
Garg A., Vijayaraghavan V., Wong C.H. et al. // Molecular Simulation. 2014. V. 41. № 14. P. 1143.https://doi.org/10.1080/08927022.2014.951351
Fernandez M., Bilic A., Barnard A.S. // Nanotechnology. 2017. V. 28. № 38. P. 38LT03.https://doi.org/10.1088/1361-6528/aa82e5
Fernandez M., Abreu J.I., Shi H., Barnard A.S. // ACS Comb Sci. 2016. V. 18. № 11. P. 661.https://doi.org/10.1021/acscombsci.6b00094
Dong Y., Wu C., Zhang C. et al. // npj Computational Materials. 2019. V. 5. № 1. P. 1. https://doi.org/10.1038/s41524-019-0165-4
Rajan A.C., Mishra A., Satsangi S. et al. // Chemistry of Materials. 2018. V. 30. № 12. P. 4031.https://doi.org/10.1021/acs.chemmater.8b00686
Patra T.K., Zhang F., Schulman D.S. et al. // ACS Nano. 2018. V. 12. № 8. P. 8006.https://doi.org/10.1021/acsnano.8b02844
Yang H., Zhang Z., Zhang J., Zeng X.C. // Nanoscale. 2018. V. 10. № 40. P. 19092.https://doi.org/10.1039/c8nr05703f
Han B., Lin Y., Yang Y. et al. //. 2020. V. 32. № 29. P. 2000953. https://doi.org/10.1002/adma.202000953
Lin X., Si Z., Fu W. et al. // Nano Research. 2018. V. 11. № 12. P. 6316.https://doi.org/10.1007/s12274-018-2155-0
Li Y., Kong Y., Peng J. et al. // J. Materiomics. 2019. V. 5. № 3. P. 413.https://doi.org/10.1016/j.jmat.2019.03.003
Wang Z.-L., Adachi Y. // Materials Science and Engineering: A. 2019. V. 744. P. 661.https://doi.org/10.1016/j.msea.2018.12.049
Tawfik S.A., Isayev O., Stampfl C. et al. // Advanced Theory and Simulations. 2018. V. 2. № 1. P. 1800128.https://doi.org/10.1002/adts.201800128
Дополнительные материалы отсутствуют.
Инструменты
Поверхность. Рентгеновские, синхротронные и нейтронные исследования