

Известия РАН. Теория и системы управления, 2020, № 1, стр. 119-128
ДЕТЕКТИРОВАНИЕ ТЕРМАЛЬНЫХ АНОМАЛИЙ НА НОЧНЫХ СНИМКАХ ВУЛКАНОВ
А. Н. Камаев a, С. П. Королёв a, А. А. Сорокин a, И. П. Урманов a, *
a ВЦ ДВО РАН
Хабаровск, Россия
* E-mail: urmanov@ccfebras.ru
Поступила в редакцию 07.11.2018
После доработки 07.06.2019
Принята к публикации 30.09.2019
Аннотация
Обсуждается проблема выявления возникновения и развития термальных аномалий на изображениях вулканов, полученных в ночное время суток в видимом и ближнем инфракрасном диапазонах. Предложен алгоритм обнаружения и классификации подобных аномалий, а также проведена его апробация на данных архива видеонаблюдения за вулканами Камчатки. Полученные результаты позволяют говорить о возможности применения созданного решения в задачах оперативного мониторинга вулканической активности на Дальнем Востоке России.
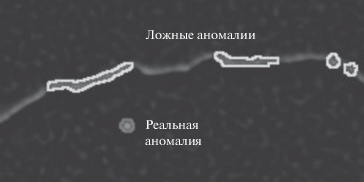
Введение. В рамках исследований по развитию программных средств системы видеонаблюдения за вулканами Камчатки [1] авторами были разработаны специализированные алгоритмы [2, 3], обеспечивающие фильтрацию и автоматизированный поиск фотоснимков с признаками активности указанных природных объектов в дневное время суток. Для обработки данных с камер, которые ведут ночную съемку, требуются отдельные решения, которые позволят выявлять возникновение и развитие термальных аномалий. В первую очередь речь идет о снимках с областью аномалии, яркость которой превышает яркость окрестности и спадает от центра к краям изображения (рис. 1).

В [4] представлен метод обнаружения аномалии в заранее выделенной области изображения, однако он не позволяет локализовать аномалию на снимке и обладает рядом ограничений, связанных с периодической посторонней засветкой и переменной видимостью вулкана. Кроме того, его применение осложняется наличием на изображениях спекл-шума [5]. Наиболее очевидный способ обнаружения термальных аномалий – это поиск участков изображения, яркость которых выше определенного порога, как это показано в [6, 7]. Данный метод хорошо подходит для термальных камер [8, 9], но неприменим для используемых камер, снимающих в широком диапазоне, который включает видимый и ближний инфракрасный спектры. Яркие области на таких снимках соответствуют не только высокотемпературным, но и освещенным областям. Солнечная или лунная засветка вдоль контура вулкана, как правило, ярче, чем температурные аномалии среднего и небольшого размера, что делает невозможным их обнаружение исключительно по яркостному признаку.
В статье рассматривается ряд признаков, позволяющих наиболее точно определить, является ли некоторая выделенная область температурной аномалией. Для выделения областей потенциальных температурных аномалий используется DoG (difference of gaussian) [10] детектор. Он позволяет не просто находить яркостные максимумы на изображениях, но и справляется с фильтрацией шума, а также дает необходимую для построения признаков информацию о масштабе области потенциальной аномалии. Дается описание процедуры построения признаков потенциальных аномалий и решение задачи классификации аномалий на истинные и ложные на основе вектора этих признаков. Применительно к настоящей задаче исследуются следующие классификаторы: наивный байесовский [11], SVM (support vector machine) [12] и K-means [13]. Представлены результаты обнаружения термальных аномалий на ночных снимках, полученных с помощью видеокамеры Axis P1343, которая осуществляет непрерывное наблюдение за вулканом Шивелуч.
1. Обнаружение термальных аномалий. 1.1. Поиск центров аномалий. Обозначим через $L(x,y,\sigma ) = G(x,y,\sigma )*I(x,y)$ изображение, полученное в результате свертки яркостной составляющей исходного изображения I(x, y) с функцией Гаусса $G\left( {x,y,\sigma } \right) = 0.5{{\pi }^{{ - 1}}}{{\sigma }^{{ - 2}}}{{e}^{{ - ({{x}^{2}} + {{y}^{2}})/(2{{\sigma }^{2}})}}}$ по координатам x и y. Построим N + 2 слоя ${{L}_{j}}\left( {x,y} \right) = L(x,y,{{\sigma }_{0}}\sigma _{\Delta }^{j})$, где параметр ${{{\sigma }}_{0}}$ задает начальный масштаб, на котором могут быть найдены аномалии, параметр ${{{\sigma }}_{\Delta }}$ определяет шаг масштаба между слоями масштабного представления изображения, $j = \overline {0,N + 1} $. Параметр ${{{\sigma }}_{0}}$ выбирается достаточно большим, чтобы снизить влияние высокочастотного шума на I(x, y), но при этом не потерять аномалии минимально допустимого размера. Для термальных аномалий, наблюдаемых в данной работе, были выбраны значения параметров ${{\sigma }_{0}} = 0.4$, ${{\sigma }_{\Delta }} = 1.3$ и количество слоев N = 14.
Для обнаружения центров термальных аномалий вычисляются DoG-уровни Dk(x, y) = Lk(x, y) – – ${{L}_{{k + 1}}}(x,y)$, $k = \overline {0,N} $. В качестве центров потенциальных аномалий рассматриваются точки с координатами ${\mathbf{c}} = \left( {{{c}_{x}},{{c}_{y}},{{c}_{i}}} \right)$, такие, что ${{D}_{{{{c}_{i}}}}}\left( {{{c}_{x}},{{c}_{y}}} \right) > {{D}_{{{{i}_{с}}}}}\left( {{{x}_{c}},{{y}_{c}}} \right)$, где ${{i}_{с}} = \left( {{{c}_{i}} - 1,{{c}_{i}},{{c}_{i}} + 1} \right)$, xc = = $({{c}_{x}} - 1,{{c}_{x}},{{c}_{x}} + 1)$, ${{y}_{c}} = \left( {{{c}_{y}} - 1,{{c}_{y}},{{c}_{y}} + 1} \right)$, и выполняется условие ${{i}_{c}} \ne {{c}_{i}} \vee {{x}_{c}} \ne {{c}_{x}} \vee {{y}_{c}} \ne {{c}_{y}}$.
1.2. Область, занимаемая аномалией. Для описания процедуры выделения областей, занимаемых аномалиями на слое ${{{\text{D}}}_{i}}(x,y)$, $i \in \{ \overline {1,N - 1} \} $, введем M(p) = = $\{ (p_{x}^{'},p_{y}^{'}){\text{||}}{{p}_{x}} - p_{x}^{'}{\text{|}} \leqslant 1 \wedge \,{\text{|}}{{p}_{y}} - p_{y}^{'}{\text{|}} \leqslant 1 \wedge {\mathbf{p}} \ne {\mathbf{p}}{\kern 1pt} '\} $ – множество соседей точки ${\mathbf{p}} = \left( {{{p}_{x}},{{p}_{y}}} \right)$ на слое ${{D}_{i}}\left( {x,y} \right)$. Результаты работы алгоритма будем записывать в изображение-маску ${\mathbf{A}} = \left\{ {{{{\mathbf{A}}}_{{x,y}}}} \right\}$, где $x = \overline {0,w - 1} $, $y = \overline {0,h - 1} $, а w и h – ширина и высота исследуемого изображения. Пусть обнаружено K центров аномалий на слое i: ${{{\mathbf{c}}}_{k}} = \left( {{{c}_{{kx}}},{{c}_{{ky}}},{{c}_{{ki}}}} \right)$, где ${{c}_{{ki}}} = i$, а $k = \overline {1,K} $, тогда алгоритм разметки областей, принадлежащих данным аномалиям, можно записать следующим образом.
Шаг 1. Зададим начальные значения ${{{\mathbf{A}}}_{{x,y}}} = 0$ для всех $x,y$.
Шаг 2. Для $k = \overline {1,K} $: присвоить ${{{\mathbf{A}}}_{{{{c}_{{kx}}},{{c}_{{ky}}}}}} = k$, поместить точку $\left( {{{c}_{{kx}}},{{c}_{{ky}}}} \right)$ в очередь Q.
Шаг 3. Пока $Q \ne \emptyset $ выполнять шаги 3а, 3б.
Шаг 3а. Извлечь точку из очереди: ${\mathbf{p}} \leftarrow Q$.
Шаг 3б. Если выполняется условие ${{D}_{i}}({{p}_{x}},{{p}_{y}}) \geqslant 0.1{{D}_{i}}({{c}_{{{{A}_{p}}x}}},{{c}_{{{{A}_{p}}y}}})$ то $\forall {\mathbf{p}}{\kern 1pt} ' \in M({\mathbf{p}}) \wedge {{{\mathbf{A}}}_{{{\mathbf{p}}{\kern 1pt} '}}}$ = = $0 \wedge {{D}_{i}}(p_{x}^{'},p_{y}^{'})$ < ${{D}_{i}}({{p}_{x}},{{p}_{y}})$: присвоить ${{{\mathbf{A}}}_{{{\mathbf{p}}'}}} = {{{\mathbf{A}}}_{{\mathbf{p}}}}$, поместить ${\mathbf{p}}{\kern 1pt} '$ в очередь $Q \leftarrow {\mathbf{p}}{\kern 1pt} '$.
После выполнения алгоритма разметки областей для каждой точки i-го изображения маска A будет содержать либо индекс аномалии, которой принадлежит точка, либо ноль, если точка не принадлежит какой-либо аномалии.
2. Признаки термальных аномалий. Лишь небольшое число найденных потенциальных термальных аномалий в действительности являются результатом вулканической активности. Можно выделить ряд признаков, позволяющих произвести классификацию выделенных областей на истинные и ложные аномалии. Далее рассмотрим эти признаки и способ их построения для $~i$-го масштабного слоя.
2.1. Признаки максимума аномалии. К признакам, которые могут быть рассчитаны для максимума потенциальной термальной аномалии, можно отнести величину максимума, вытянутость и яркость. Рассмотрим эти признаки.
Величина k-го максимума – это значение ${{D}_{i}}\left( {{{c}_{{kx}}},{{c}_{{ky}}}} \right)$. Как правило, для термальных аномалий характерны значения выше определенного порога, тогда как максимумы, вызванные шумом на изображении, имеют меньшую величину.
Признак вытянутости показывает, насколько различается скорость убывания функции вокруг максимума в разных направлениях. Для термальных аномалий, сгенерированных вулканами, различия в скорости невелики, тогда как для ярких пятен, образующихся у контура вулкана в лучах восходящего солнца, скорость убывания функции в одном направлении существенно превышает скорость убывания в другом (рис. 2).
Для вычисления признака вытянутости интерполируем участок изображения ${{D}_{i}}(u,v)$, u = ${{c}_{{kx}}} - 1,$ ${{c}_{{kx}}},{{c}_{{kx}}} + 1$, $v = {{c}_{{ky}}} - 1,$ ${{c}_{{ky}}},{{c}_{{ky}}} + 1$ квадратичной функцией
Если ${{{\lambda }}_{{{\text{min}}}}}$ и ${{{\lambda }}_{{{\text{max}}}}}$ – наименьшее и наибольшее собственное число матрицы ${\mathbf{H}}(c_{x}^{'},c_{y}^{'})$ соответственно, то признак вытянутости определяется соотношением $\sqrt {{{{\lambda }}_{{{\text{min}}}}}{\text{/}}{{{\lambda }}_{{{\text{max}}}}}} $.
Последний признак максимума аномалии – его яркость. Она описывается значением ${{L}_{i}}\left( {{{c}_{{kx}}},{{c}_{{ky}}}} \right)$. Для реальных термальных аномалий это значение, как правило, превышает некоторый порог.
2.2. Признаки области аномалии. В качестве признаков области аномалии предлагается использовать коэффициенты периметра, асимметричности границ и пика. Рассмотрим эти коэффициенты.
Коэффициент периметра $p_{k}^{'}{\text{/}}{{p}_{k}}$ показывает соотношение периметров k-й аномалии на i-м слое ${{p}_{k}}$ и минимально возможного периметра аномалии такой же площади $p_{k}^{'}$, $k = \overline {1,K} $:
где ${{{\delta }}_{{{{{\mathbf{A}}}_{{xy}}},k}}}$ – символ Кронекера. Периметр где ${{{\eta }}_{k}}(x,y) = (1 - {{{\delta }}_{{{{{\mathbf{A}}}_{{xy}}},k}}})({{{\delta }}_{{{{{\mathbf{A}}}_{{x + 1,y}}},k}}} + {{{\delta }}_{{{{{\mathbf{A}}}_{{x - 1,y}}},k}}} + {{{\delta }}_{{{{{\mathbf{A}}}_{{x,y + 1}}},k}}} + {{{\delta }}_{{{{{\mathbf{A}}}_{{x,y - 1}}},k}}}).$Для корректной обработки аномалий, которые поместились в область изображения лишь частично, следует обнулить точки карты A, находящиеся на границах изображения.
Коэффициент асимметричности границ показывает, насколько равномерно спадает яркость аномалии к ее границе. Множество яркостей граничных точек k-й аномалии ${{\Gamma }_{k}}\, = \,\{ {{L}_{i}}(x,y){\kern 1pt} |{\kern 1pt} {{\eta }_{k}}(x,y)\, > \,0\} $, в этом множестве выделим два подмножества ${\Gamma }_{{\text{k}}}^{{{\text{min}}}} \subset {{{\Gamma }}_{k}}$ и ${\Gamma }_{{\text{k}}}^{{{\text{max}}}} \subset {{{\Gamma }}_{k}}$, которые содержат 10% наименьших и 10% наибольших яркостей из Γk соответственно. С учетом этих множеств коэффициент асимметричности границ можно определить на основе отношения
Для аномалий, часть площади которых находится за границей экрана, знаменатель отношения t будет близок к нулю, что приведет к очень большим значениям, негативно влияющим на классификацию. Чтобы избавиться от этих выбросов, ограничим t интервалом $\left[ { - \pi {\text{/}}2;\pi {\text{/}}2} \right]$, для этого коэффициент асимметричности границ будем находить по формуле
где $\theta = 0.5\left( {{{t}_{{{\text{min}}}}} + {{t}_{{{\text{max}}}}}} \right)$, ${\Delta } = {{t}_{{{\text{max}}}}} - \theta $. При этом максимальное и минимальное значения t определялись на основе значений класса истинных аномалий обучающей выборки, описанной в следующем разделе. В данной работе были использованы значения θ = 20, Δ = 20.Коэффициент пика показывает, насколько яркость центра аномалии больше средней яркости границ:
3. Классификация. Каждой потенциальной аномалии может быть поставлен в соответствие вектор из шести параметров: величина максимума, вытянутость, яркость, коэффициенты периметра, асимметричности и пика. Набор этих параметров позволяет отнести аномалию к истинной (термальной) или к ложной (освещенный участок изображения или шум). Разметим вручную набор аномалий, извлеченных из архива изображений вулканов Камчатки [14]. В общей сложности на этих изображениях было размечено ${{M}_{f}} = 1000$ ложных и ${{M}_{t}} = 1000$ истинных аномалий. Будем использовать эти данные для обучения трех классификаторов: наивный байесовский классификатор, SVM и K-means.
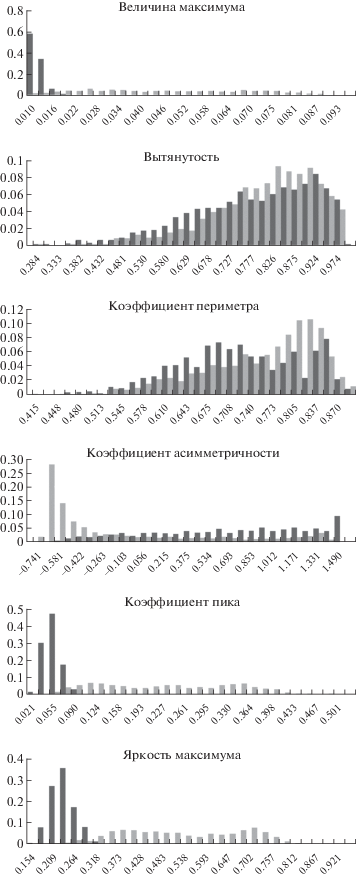
3.1. Наивный байесовский классификатор. Построим гистограммы распределения значений параметров аномалий из обучающей выборки. На рис. 3 показаны такие гистограммы для каждого из параметров, построенные для 30 интервалов. Как видно из гистограмм, ни один признак не позволяет однозначно разделить истинные и ложные аномалии. Согласно теореме Байеса, вероятность того, что аномалия принадлежит классу C ($C = {{C}_{t}}$ – класс истинных аномалий, $C = {{C}_{f}}$ – класс ложных аномалий), задается формулой
Рис. 3.
Гистограммы распределения значений каждого признака аномалий для 30 интервалов:  – ложные аномалии;
– ложные аномалии;  – истинные аномалии
– истинные аномалии
Класс, к которому относится исследуемая аномалия, определяется максимальной вероятностью:
Предположив независимость параметров, можно переписать эту вероятность следующим образом:
Знаменатель $p\left( {\mathbf{F}} \right)$ можно отбросить, так как он не зависит от класса C, а для решения задачи классификации важно не реальное значение вероятности $p\left( {C{\kern 1pt} {\text{|}}{\kern 1pt} {\mathbf{F}}} \right)$, а соотношение вероятностей $p\left( {{{C}_{t}}{\kern 1pt} {\text{|}}{\kern 1pt} {\mathbf{F}}} \right)$ и $p\left( {{{C}_{f}}{\kern 1pt} {\text{|}}{\kern 1pt} {\mathbf{F}}} \right)$. Вероятности $p\left( {{{C}_{t}}} \right)$ и $p\left( {{{C}_{f}}} \right)$ могут быть рассчитаны на основе встречаемости классов в обучающих данных. Но, учитывая то, что абсолютное значение $p\left( {C{\kern 1pt} {\text{|}}{\kern 1pt} {\mathbf{F}}} \right)$ нас не интересует, более практичным решением будет оставить $p\left( {{{C}_{t}}} \right)$ в качестве параметра классификатора, определяющего его чувствительность к истинным аномалиям. Повышая это значение, можно регулировать границу между неверно классифицируемыми истинными и ложными аномалиями. В настоящей работе были выбраны значения $p\left( {{{C}_{t}}} \right) = 0.96$ при $p\left( {{{C}_{f}}} \right) = 0.04$ как наиболее оптимальные. Вероятности $p\left( {{{F}_{i}}{\kern 1pt} {\text{|}}{\kern 1pt} C} \right)$ можно определить на основе гистограмм параметров (рис. 3), предварительно применив к ним сглаживание, чтобы избежать нулевых значений в допустимом диапазоне параметров.
3.2. Нормализация данных. Наивный байесовский классификатор рассматривает параметры независимо друг от друга, тогда как SVM и K-means работают в едином пространстве параметров. В связи с этим для использования этих методов необходимо произвести нормализацию векторов параметров, чтобы исключить доминирование одних параметров над другими. Пусть имеется два вектора, описывающие истинные и ложные аномалии из обучающих данных: ${\mathbf{F}}_{i}^{t}$ = $(F_{{i1}}^{t},F_{{i2}}^{t}, \ldots ,F_{{iN}}^{t})$ и ${\mathbf{F}}_{j}^{f} = (F_{{j1}}^{f},F_{{j2}}^{f}, \ldots ,F_{{jN}}^{f})$, где $i = \overline {1,{{M}_{t}}} $, $j = \overline {1,{{M}_{f}}} $, а N = 6 или N = 7 (см. разд. 3.3). Тогда вектор математических ожиданий параметров и их дисперсий
Векторы L и R определяют вектор масштаба $~{\mathbf{S}} = \left( {{{S}_{1}},{{S}_{2}}, \ldots ,{{S}_{N}}} \right)$, ${{S}_{k}} = {{\left( {{{R}_{k}} - {{L}_{k}}} \right)}^{{ - 1}}}$. С помощью векторов ${\mathbf{L}}$ и S нормализуем исходный вектор параметров F:
3.3. Машина опорных векторов (SVM). SVM находит делящую гиперплоскость в пространстве нормализованных параметров ${{\tilde {F}}_{1}},{{\tilde {F}}_{2}}, \ldots ,{{\tilde {F}}_{6}}$ либо в пространстве большей размерности, куда могут быть спроецированы векторы параметров аномалий. Поскольку заранее неизвестно, являются ли классы истинных и ложных аномалий линейно разделимыми, будем использовать SVM и радиальную базисную функцию (kernel trick) [15]:
Для поиска оптимальных значений параметров ${\gamma }$ и $C$ производился поиск по сетке с узлами ${{{\gamma }}_{i}} = {{2}^{{i - 1}}}$ и ${{C}_{j}} = {{10}^{j}}$, $i,j = \overline {0,7} $. Для каждого значения параметров сетки строилась делящая плоскость на основе половины обучающей выборки и оценивалось количество неверно классифицированных аномалий из второй половины выборки. В результате были выбраны значения параметров ${\gamma } = 4$, $C = 1000$.
Кроме стандартного набора из шести параметров, описывающих каждую аномалию, использовался также дополнительный седьмой параметр – номер масштабного слоя, на котором была найдена данная аномалия. Сам по себе номер слоя не позволяет различать истинные и ложные аномалии, в связи с этим он не был использован в наивном классификаторе Байеса. Но номер слоя может влиять на разделимость классов истинных и ложных аномалий через другие параметры. Чем ниже масштабный слой, тем больше шума присутствует на нем и тем больше сказывается дискретный характер изображения при определении параметров, связанных с областью аномалии. Для более высоких масштабных слоев характерны меньшие перепады яркости и полное отсутствие шума.
3.4. Классификатор K-means. Идея классификатора K-means заключается в том, чтобы расположить в пространстве параметров некоторое количество точек, каждая из которых определяет какой-либо класс. Класс анализируемой аномалии будет соответствовать классу той точки, которая лежит ближе всего в пространстве параметров. В данной работе для описания истинных и ложных аномалий использовалось по 512 точек, размещенных с помощью алгоритма K-means на основе обучающей выборки. Как и для SVM, для K-means рассматривались шестимерные, а также семимерные нормализованные векторы параметров с дополнительным параметром – номером масштабного слоя.
3.5. Результаты. Тестирование разработанных алгоритмов классификации проводилось на 114 447 ложных и 1408 истинных аномалиях, обнаруженных на изображениях вулкана Шивелуч, полученных с использованием видеокамеры Axis P1343. В камере установлена RGB CMOS-матрица (1/4 дюйма, прогрессивная развертка) и применяется вариофокальный объектив 3–8 мм со светосилой F1.0. Имеется механический отсекающий ИК-фильтр, при использовании которого возможна работа видеокамеры в условиях естественной ночной освещенности, соответствующей в видимом диапазоне 0.05 лк. Диафрагма в объективе управляется автоматически (DC-Iris).
Обработка данных выполнялась с использованием ресурсов вычислительных систем гибридной и классической архитектуры ЦКП “Центр данных ДВО РАН” [16]. Таблица содержит информацию о том, сколько истинных и ложных аномалий удалось обнаружить каждым из используемых классификаторов. Строки таблицы соответствуют используемым классификаторам: НКБ – наивный классификатор Байеса, SVM6 и SVM7 – машина опорных векторов с шестью и семью мерными векторами параметров, K6, K7 – K-means с шестью и семью мерными векторами параметров. Столбцы таблицы содержат следующую информацию: FN (false negative) – процент истинных аномалий, которые не были обнаружены, FP (false positive) – процент ложных аномалий, которые были распознаны как истинные, Err – общая ошибка классификатора в процентах.
Таблица.
Результаты классификации аномалий
| Классификаторы | FN | FP | Err |
|---|---|---|---|
| % | |||
| НКБ | 4.19 | 3.88 | 3.88 |
| SVM6 | 2.63 | 2.75 | 2.75 |
| SVM7 | 1.85 | 2.08 | 2.08 |
| K6 | 3.76 | 3.58 | 3.58 |
| K7 | 2.56 | 2.00 | 2.01 |
Как видно из таблицы, использование седьмого признака позволило снизить ошибку классификации, наилучшие результаты показали классификаторы K-means и SVM. Несмотря на то, что общая ошибка для K-means с семью параметрами меньше, чем для SVM7, процент нераспознанных истинных аномалий для SVM7 оказался ниже, что является наиболее важным фактором в задаче мониторинга вулканической активности. Хуже остальных оказался наивный классификатор Байеса, что было ожидаемо, так как он не учитывает связи между параметрами.
Дополнительно, чтобы избежать влияния реальных термальных аномалий, вызванных техногенными и иными факторами (рис. 4), на этапе поиска центров аномалий использовалась бинарная маска, выделяющая активную область вулкана. Пример такой маски представлен на рис. 5.


Ошибки в обнаружении аномалии (рис. 6) обусловлены рядом объективных причин:

неоднородность атмосферы активной части вулкана приводит к сглаживанию яркости на снимках, в связи с чем часть аномалий имеет особую нестандартную форму;
яркость некоторых аномалий не превышает перепада яркости, вызываемого шумом на изображении;
аномалии, представляющие лавовые потоки, имеют уникальную форму, что затрудняет их распознавание.
Для решения перечисленных проблем необходимо увеличение количества рассматриваемых классов аномалий и расширение обучающей выборки.
Заключение. В рамках исследований был разработан алгоритм обнаружения и классификации термальных аномалий на снимках вулканов, сделанных в ночное время суток в видимом и ближнем инфракрасном диапазонах. В качестве признаков рассматриваются: значение DoG-функции в центре, вытянутость аномалии, отношение периметра аномалии к минимально возможному периметру (сложность границы), асимметричность значений на краях, отношение перепада яркости центр-основание к значению яркости в центре, само значение яркости в центре и номер масштабного слоя DoG‑пирамиды, на котором обнаружен максимум. При этом рассматриваются только те яркостные аномалии, которые находятся в области, покрытой контурами вулкана, либо касаются этой области. Описанные признаки позволяют классифицировать аномалии на термальные и иные яркостные аномалии. Для их классификации использовались три метода – наивный классификатор Байеса, SVM на основе радиальной базисной функции и классификатор K-means. Два последних классификатора показали очень близкий процент ошибки (~2%).
Результаты апробации алгоритма и созданных на его основе программных средств позволяют говорить о возможности их применения в задачах оперативного видеомониторинга за вулканической активностью на Камчатке [17].
Список литературы
Sorokin A., Korolev S., Romanova I., Girina O., Urmanov I. The Kamchatka Volcano Video Monitoring System // Proc. of 2016 6th Intern. Workshop on Computer Science and Engineering (WCSE 2016). Tokyo, Japan, 2016. P. 734–737.
Kamaev A.N., Urmanov I.P., Sorokin A.A., Karmanov D.A., Korolev S.P. Images Analysis for Automatic Volcano Visibility Estimation // Computer Optics. 2018. V. 42. № 1. P. 128–140.
Урманов И.П., Камаев А.Н., Сорокин А.А., Королев С.П. Оценка видимости и состояния вулканов по последовательностям изображений стационарных камер наблюдения // Вычислительные технологии. 2016. Т. 21. № 3. С. 80–90.
Мельников Д.В., Маневич А.Г., Гирина О.А. Количественные характеристики активности вулканов Камчатки по данным веб-камер // Тез. Докл. XVIII региональной конф., посвященной Дню вулканолога. Петропавловск-Камчатский: ИВиС ДВО РАН, 2015. С. 92–94.
Rabal H.J., Braga J.R.A. Dynamic Laser Speckle and Applications. Boca Raton: CRC Press, 2009.
Olivo-Marin J.C. Extraction of Spots in Biological Images Using Multiscale Products // Pattern Recognition. 2002. V. 35. № 9. P. 1989–1996.
Wang F., Liu Y., Wu Ch., Chen X., Zeng K. Spot Image Ablated by Femtosecond Laser Segmentation and Feature Clustering After Dimension Reduction Reconstruction // Optik. 2018. V. 164. P. 488–497.
Andò B., Pecora E. An Advanced Video-based System for Monitoring Active Volcanoes // Computers & Geosciences. 2006. V. 32. № 1. P. 85–91.
Spampinato L., Calvari S., Oppenheimer C., Boschi E. Volcano Surveillance Using Infrared Cameras // Earth-Science Reviews. 2011. V. 106. P. 63–91.
Lowe D.G. Distinctive Image Features from Scale-invariant Keypoints // Intern. J. of Computer Vision. 2004. V. 60. № 2. P. 91–110.
Zhang H. The Optimality of Naive Bayes // Proc. Seventeenth Intern. Florida Artificial Intelligence Research Society Conf. Miami Beach, Florida, USA: AAAI Press, 2004. P. 562–567.
Shmilovici A. Support Vector Machines // Data Mining and Knowledge Discovery Handbook. Boston, MA, USA: Springer. 2009. P. 257–276.
Coates A., Ng A.Y. Learning Feature Representations with K-Means // Neural Networks: Tricks of the Trade. Lecture Notes in Computer Science. Berlin, Heidelberg: Springer, 2012. V. 7700. P. 561–580.
Sorokin A.A., Korolev S.P., Urmanov I.P., Verkhoturov A.I., Makogonov S.V., Shestakov N.V. Software Platform for Observation Networks Instrumental Data Far Eastern Branch of the Russian Academy of Sciences // Proc. of Intern. Conf. on Computer Science and Environmental Engineering (CSEE 2015). DEStech Publications Inc. Beijing, 2015. P. 589–594.
Vert J., Tsuda K., Schölkopf B. A primer on Kernel Methods // Kernel Methods in Computational Biology. Cambridge, MA: MIT Press, 2004. V. 47. P. 35–70.
Sorokin A.A., Makogonov S.V., Korolev S.P. The Information Infrastructure for Collective Scientific Work in the Far East of Russia // Scientific and Technical Information Processing. 2017. V. 44. № 4. P. 302–304.
Гордеев Е.И., Гирина О.А. Вулканы и их опасность для авиации // Вестник Российской академии наук. 2014. Т. 84. № 2. С. 134–142.
Дополнительные материалы отсутствуют.
Инструменты
Известия РАН. Теория и системы управления