

Известия РАН. Теория и системы управления, 2020, № 6, стр. 42-59
ОПТИМАЛЬНЫЙ РЕКУРРЕНТНЫЙ ЛОГИКО-ДИНАМИЧЕСКИЙ ФИЛЬТР БОЛЬШОГО ПОРЯДКА И ЕГО КОВАРИАЦИОННЫЕ ПРИБЛИЖЕНИЯ
Е. А. Руденко *
МАИ (национальный исследовательский ун-т)
Москва, Россия
* E-mail: rudenkoevg@yandex.ru
Поступила в редакцию 25.05.2020
После доработки 09.07.2020
Принята к публикации 27.07.2020
Аннотация
Рассматривается задача логического распознавания режима работы и динамического оценивания внутрирежимного вектора состояния дискретной стохастической марковской системы со случайной структурой. Для создания алгоритма оценивания, реализуемого в темпе со временем на вычислителе ограниченной мощности, предлагается способ синтеза нового конечномерного фильтра оптимальной структуры. Вектор его состояния составляется из нескольких последних оценок, а текущая оценка ищется в виде оптимальной по точности ее зависимости от последнего измерения и вектора предыдущего состояния фильтра. Синтез структурных функций фильтра выполняется заранее и может быть произведен методом Монте-Карло путем получения их многомерных гистограмм. Из-за вычислительной сложности этой процедуры также предлагаются и алгоритмы построения двух численно-аналитических приближений к фильтру, которые учитывают лишь первые два момента случайных величин.
Введение. При оптимальном управлении логико-динамическими (многорежимными, переключательными) стохастическими системами по доступным наблюдениям их выходов возникает задача оперативного распознавания режима работы и оценивания внутрирежимного состояния этих систем. Однако применение для этого бесконечномерного абсолютно-оптимального фильтра (АОФ) [1–4] сопряжено с существенными вычислительными трудностями, а конечномерный условно-минимаксный фильтр [5] оптимален лишь параметрически и имеет небольшой фиксированный порядок (размерность вектора состояния), что препятствует достижению им значительной точности. В то же время потенциальная точность лишенных этих недостатков непараметрических конечномерных фильтров оптимальной структуры (ФОС) также ограничена, ибо они имеют или бесконечное время памяти и малый порядок, равный порядку объекта наблюдения [6, 7], или любой порядок, кратный размерности вектора измерений, но конечную память [8]. Программные реализации этих фильтров описаны в [9].
В настоящей работе предлагается способ преодоления этой ограниченности логико-динамических ФОС путем построения нового фильтра большого порядка (ФБП). Его вектор состояния предлагается формировать из нескольких векторов последних оценок, поэтому порядок ФБП кратен размерности оцениваемого вектора состояния системы наблюдения. Время памяти ФБП бесконечно, а противоречие между его точностью и сложностью регулируется выбором величины кратности. Нахождение структурных функций оптимального ФБП выполняется до начала процесса оценивания с помощью интегральных операций с условными распределениями вероятности, что можно реализовать численно методом Монте-Карло с построением выборочных приближений к искомым функциям обработкой их многомерных гистограмм.
Из-за вычислительной сложности этой процедуры также рассмотрено и построение двух численно-аналитических приближений к ФБП, гауссовского и линеаризованного. Они учитывают лишь вероятности дискретных случайных величин, а также соответствующие им условные средние и ковариации непрерывных случайных величин. Поэтому числовые параметры их структурных функций тоже вычисляются методом Монте-Карло, но уже довольно просто по выборочным значениям этих вероятностей и двух условных моментов. Получение же выражений для структурных функций субоптимальных ФБП выполняется аналитически и сводится либо к интегральной операции статистической линеаризации нелинейностей по Казакову, либо к более простой, но менее общей и довольно грубой дифференциальной операции обычной их линеаризации по Тейлору.
Таким образом, данная статья дополняет ранее созданные ФОС их новой перспективной модификацией. При этом сравнение сложности алгоритмов удобных в практическом применении ковариационных приближений к АОФ и ФОС, а также и обеспечиваемой ими точности требует дальнейшего исследования путем решения конкретных задач. Наибольший эффект от ФОС следует ожидать в случаях существенного проявления нелинейностей системы наблюдения и действия на нее случайных воздействий большой интенсивности, когда банк из популярных расширенных фильтров Калмана не эффективен.
1. Постановка задачи синтеза фильтра. Рассмотрим функционирующий в условиях неопределенности многорежимный объект. Пусть его поведение в каждый момент дискретного времени $k{\text{ = }}\overline {{\text{0,}}\,K} $ с конечным горизонтом K определяется одним из L случайных номеров его режима (структуры) ${{I}_{k}} \in \{ \overline {1,L} \} $ и случайным абсолютно непрерывным вектором его состояния ${{X}_{k}} \in {{\mathbb{R}}^{{{{n}_{x}}}}}$. При этом изменение во времени расширенного вектора состояния объекта ${{\bar {X}}_{k}} = {{[{{I}_{k}}\,\,X_{k}^{{\text{Т}}}]}^{{\text{Т}}}}$ описывается следующей системой разностных уравнений:
(1.1)
${{\bar {X}}_{{k + 1}}} \equiv \left[ {\begin{array}{*{20}{c}} {{{I}_{{k + 1}}}} \\ {{{X}_{{k + 1}}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {\phi _{k}^{{({{I}_{k}})}}({{X}_{k}},V_{k}^{\Delta })} \\ {a_{k}^{{({{I}_{k}})}}({{X}_{k}},{{V}_{k}})} \end{array}} \right] \equiv {{\bar {a}}_{k}}({{\bar {X}}_{k}},{{\bar {V}}_{k}}),\quad k{\text{ = }}\overline {{\text{0,}}K} ,\quad {{\bar {X}}_{0}} \equiv \left[ {\begin{array}{*{20}{c}} {{{I}_{0}}} \\ {{{X}_{0}}} \end{array}} \right] \sim {{p}_{0}}(i,x) \equiv {{p}_{0}}(\bar {x}).$Здесь $\phi _{k}^{{(i)}}(x,{v}_{{}}^{\Delta }) \equiv \phi _{k}^{{}}(i,x,{v}_{{}}^{\Delta })$ – дискретнозначная скалярная функция логического блока (переключателя) объекта, $a_{k}^{{(i)}}(x,{v}) \equiv a_{k}^{{}}(i,x,{v})$ – непрерывнозначная вектор-функция его динамического блока, ${{\bar {V}}_{k}} = (V_{k}^{\vartriangle },{{V}_{k}})$ – вектор дискретных белых возмущений (порождающих шумов) этих блоков. Эти возмущения не зависят от начального состояния объекта $({{I}_{0}},\,{{X}_{0}})$, который, как и другие системы из дискретных и абсолютно непрерывных случайных величин, будем определять совместным вероятностным распределением
Пусть также в каждый момент времени k для уточнения состояния ${{\bar {X}}_{k}}$ системы (1.1) фиксируется случайный вектор расширенных наблюдений ${{\bar {Y}}_{k}} = {{[{{J}_{k}}\,\,Y_{k}^{{\text{Т}}}]}^{{\text{Т}}}}$, состоящий из дискретной М-значной переменной индикации режима ${{J}_{k}} \in \{ \overline {1,M} \} $ и абсолютно непрерывного вектора ${{Y}_{k}} \in {{\mathbb{R}}^{{{{n}_{y}}}}}$ измерений, причем их значения определяются по формулам
(1.2)
${{\bar {Y}}_{k}} \equiv \left[ {\begin{array}{*{20}{c}} {{{J}_{k}}} \\ {{{Y}_{k}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {o_{k}^{{({{I}_{k}})}}({{X}_{k}},W_{k}^{\Delta })} \\ {b_{k}^{{({{I}_{k}})}}({{X}_{k}},{{W}_{k}})} \end{array}} \right] \equiv {{\bar {b}}_{k}}({{\bar {X}}_{k}},{{\bar {W}}_{k}}).$Здесь $o_{k}^{{(i)}}(x,{{w}^{\Delta }})$, $b_{k}^{{(i)}}(x,w)$ – известные функции логического и динамического блоков измерителя, ${{\bar {W}}_{k}} = (W_{k}^{\Delta },{{W}_{k}})$ – вектор дискретных белых погрешностей (шумов) измерений, не зависящий ни от ${{\bar {X}}_{0}}$, ни от ${{\bar {V}}_{k}}$.
Тогда априорное вероятностное поведение системы наблюдения (1.1), (1.2) полностью описывается двумя условными распределениями [7, 8], определяемыми по ее уравнениям и законам распределения шумов:
– распределением перехода объекта от старого состояния ${{\bar {X}}_{k}}$ к новому ${{\bar {X}}_{{k + 1}}}$:
(1.3)
${{\alpha }_{k}}({{i}_{{k + 1}}},{{x}_{{k + 1}}}\,{\text{|}}\,{{i}_{k}},{{x}_{k}}) = M[{{\delta }_{{{{i}_{{k + 1}}},\,\,\phi _{k}^{{({{i}_{k}})}}({{x}_{k}},\,V_{k}^{\Delta })}}}\delta ({{x}_{{k + 1}}} - a_{k}^{{({{i}_{k}})}}({{x}_{k}},{{V}_{k}}))],$(1.4)
${{\beta }_{k}}({{j}_{k}},{{y}_{k}}\,{\text{|}}\,{{i}_{k}},{{x}_{k}}) = M[{{\delta }_{{{{j}_{k}},\,\,o_{k}^{{({{i}_{k}})}}({{x}_{k}},\,W_{k}^{\Delta })}}}\delta ({{y}_{k}} - b_{k}^{{({{i}_{k}})}}({{x}_{k}},{{W}_{k}}))].$Здесь ${\text{M}}$ – оператор математического ожидания, выполняющий усреднение по случайным величинам, которые отмечены прописными буквами, ${{\delta }_{{i,\,l}}}$ – символ Кронекера, δ(x) – функция Дирака.
Замечание 1. В случае зависимости шумов ${{\bar {V}}_{k}},\,\,{{\bar {W}}_{k}}$ приходится оперировать с более общим условным распределением ${{\gamma }_{k}}({{i}_{{k + 1}}},{{x}_{{k + 1}}},{{j}_{k}},{{y}_{k}}\,{\text{|}}\,{{i}_{k}},{{x}_{k}})$ перехода от старого состояния ${{\bar {X}}_{k}}$ не только к новому состоянию ${{\bar {X}}_{{k + 1}}}$, но и к текущему наблюдению ${{\bar {Y}}_{k}}$ [7, 8]. Тогда условное распределение ${{\beta }_{k}}( \cdot )$ наблюдения ${{\bar {Y}}_{k}}$ является частным относительно ${{\gamma }_{k}}( \cdot )$, а вместо распределения перехода ${{\alpha }_{k}}( \cdot )$ нужно использовать условное распределение ${{\zeta }_{k}}({{i}_{{k + 1}}},{{x}_{{k + 1}}}\,{\text{|}}\,{{i}_{k}},{{x}_{k}},{{j}_{k}},{{y}_{k}})$ нового состояния ${{\bar {X}}_{{k + 1}}}$, уточненное еще и последним наблюдением ${{\bar {Y}}_{k}}$, которое находится как отношение ${{\gamma }_{k}}( \cdot )$ к ${{\beta }_{k}}( \cdot )$:
Требуется с целью преодоления перечисленных во Введении недостатков ФОС малого порядка (ФМП) [6, 7] и ФОС с конечной памятью (ФКП) [8] найти оценку ${{\hat {\bar {X}}}_{k}} = {{[{{\hat {I}}_{k}}\,\,\hat {X}_{k}^{{\text{Т}}}]}^{{\text{Т}}}}$ состояния ${{\bar {X}}_{k}} = {{[{{I}_{k}}\,\,X_{k}^{{\text{Т}}}]}^{{\text{Т}}}}$ системы (1.1) как некоторую функцию ${{\bar {g}}_{k}}( \cdot )$ одного последнего измерения (1.2) и не более чем $l \in \mathbb{N}$ имеющихся предыдущих оценок ${{\hat {\bar {X}}}_{{k - 1}}},{{\hat {\bar {X}}}_{{k - 2}}},\, \ldots $ Поэтому будем искать новый фильтр в виде разностного уравнения l-го порядка для вектора его оценки:
(1.5)
${{\hat {\bar {X}}}_{k}} = {{\bar {g}}_{k}}({{\bar {Y}}_{k}},\hat {\bar {X}}_{{\max (0,k - l)}}^{{k - 1}}),\quad k \geqslant 1,\quad {{\hat {\bar {X}}}_{0}} = {{\bar {g}}_{0}}({{\bar {Y}}_{0}}),$Здесь ${{\bar {g}}_{k}}( \cdot ) = {{[\begin{array}{*{20}{c}} {{{\iota }_{k}}( \cdot )}&{g_{k}^{{\text{Т}}}( \cdot )} \end{array}]}^{{\text{Т}}}}$ – искомая структурная вектор-функция фильтра, двойным верхним и нижним индексом отмечен отрезок соответствующей последовательности, например,
В оценке (1.5), в отличие от ФКП [8], старые измерения ${{\bar {Y}}_{{k - 1}}},{{\bar {Y}}_{{k - 2}}}, \ldots ,{{\bar {Y}}_{0}}$ не забываются, ибо они аккумулированы в предыдущих оценках, поэтому время памяти ФБП (1.5) как динамической системы бесконечно.
Замечание 2. Сравнивая уравнение ФБП (1.5) с уравнением двухаргументного вида
(1.6)
${{\hat {\bar {X}}}_{k}} = {{\bar {g}}_{k}}({{\bar {Y}}_{k}},{{\hat {\bar {X}}}_{{k - 1}}}),\quad k \geqslant 1,\quad {{\hat {\bar {X}}}_{0}} = {{\bar {g}}_{0}}({{\bar {Y}}_{0}})$Условием оптимальности синтезируемой оценки (1.5) выберем минимум среднего значения аддитивной квадратично-простой функции потерь от неверного распознавания номера структуры ${{I}_{k}}$ и неточного оценивания вектора состояния Xk [10]:
(1.7)
$M[{{({{X}_{k}} - {{\hat {X}}_{k}})}^{T}}{{C}_{k}}({{X}_{k}} - {{\hat {X}}_{k}}) + (1 - {{\delta }_{{{{I}_{k}},\,{{{\hat {I}}}_{k}}}}})] \to \mathop {\min }\limits_{{{{\bar {g}}}_{k}}( \cdot )} ,\quad k \geqslant 0,$2. Вектор состояния и порядок предлагаемого фильтра. Соберем учитываемые в уравнении (1.5) оценки $\hat {\bar {X}}_{{\max (0,k - l)}}^{{k - 1}}$ в блочный вектор ${{\bar {Z}}_{{k - 1}}}$, размерность которого на первых l тактах растет по мере их накопления. Осуществляя для удобства сдвиг на один такт вперед, обозначим
(2.1)
${{\bar {Z}}_{k}} \triangleq \hat {\bar {X}}_{{\max (0,k - l + 1)}}^{k} = \left\{ \begin{gathered} \hat {\bar {X}}_{0}^{k},\quad k = \overline {0,\,l - 1} , \hfill \\ \hat {\bar {X}}_{{k - l + 1}}^{k},\quad k \geqslant l. \hfill \\ \end{gathered} \right.$Процесс создания этого вектора представим как рекуррентную процедуру. Так на первых l тактах для получения вектора ${{\bar {Z}}_{k}} = \hat {\bar {X}}_{0}^{k}$ достаточно просто дополнить предыдущий вектор ${{\bar {Z}}_{{k - 1}}} = \hat {\bar {X}}_{0}^{{k - 1}}$ блоком новой оценки ${{\hat {\bar {X}}}_{k}}$, например, сверху:
(2.2)
${{\bar {Z}}_{k}} = \hat {\bar {X}}_{0}^{k} = \left[ {\begin{array}{*{20}{c}} {{{{\hat {\bar {X}}}}_{k}}} \\ {\hat {\bar {X}}_{0}^{{k - 1}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{{{\hat {\bar {X}}}}_{k}}} \\ {{{{\bar {Z}}}_{{k - 1}}}} \end{array}} \right],\quad k = \overline {0,\,l - 1} .$На всех же последующих тактах $k \geqslant l$ дополнительно необходимо выполнить еще и обновление содержащегося в векторе ${{\bar {Z}}_{{k - 1}}}$ набора предыдущих оценок $\hat {\bar {X}}_{{k - l}}^{{k - 1}}$, удаляя из него устаревший теперь нижний блок ${{\hat {\bar {X}}}_{{k - l}}}$. Последнее запишем как операцию умножения столбца $\hat {\bar {X}}_{{k - l}}^{{k - 1}}$ на “урезающую” блочную матрицу такого удаления:
Поэтому в дополнение к (2.2) имеем
(2.3)
${{\bar {Z}}_{k}} = \hat {\bar {X}}_{{k - l + 1}}^{k} = \left[ {\begin{array}{*{20}{c}} {{{{\hat {\bar {X}}}}_{k}}} \\ {\hat {\bar {X}}_{{k - l + 1}}^{{k - 1}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{{{\hat {\bar {X}}}}_{k}}} \\ {C{{{\bar {Z}}}_{{k - 1}}}} \end{array}} \right],\quad \,k \geqslant l.$Тогда, объединяя соотношения (2.2), (2.3), получаем для вектора (2.1) рекуррентную формулу
(2.4)
${{\bar {Z}}_{k}} = {{\bar {f}}_{k}}({{\hat {\bar {X}}}_{k}},{{\bar {Z}}_{{k - 1}}}) \triangleq \left\{ {\begin{array}{*{20}{c}} {{{{[\hat {\bar {X}}_{k}^{{\text{Т}}}\quad \bar {Z}_{{k - 1}}^{{\text{Т}}}]}}^{{\text{Т}}}},\quad k = \overline {0,l - 1} ,} \\ {{{{[\hat {\bar {X}}_{k}^{{\text{Т}}}\quad {{{(C{{{\bar {Z}}}_{{k - 1}}})}}^{{\text{Т}}}}]}}^{{\text{Т}}}},\quad k \geqslant l,} \end{array}} \right.\quad {{\bar {Z}}_{0}} = {{\hat {\bar {X}}}_{0}}.$Она позволяет называть ${{\bar {Z}}_{k}}$ вектором состояния фильтра, а его размерность вначале растет и достигает величины $p = l({{n}_{x}} + 1)$.
Наконец, используя обозначение (2.1) в разностном уравнении фильтра (1.5), получаем в дополнение к уравнению состояния фильтра (2.4) еще и формулу его выхода
(2.5)
${{\hat {\bar {X}}}_{k}} = \left[ {\begin{array}{*{20}{c}} {{{{\hat {I}}}_{k}}} \\ {{{{\hat {X}}}_{k}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{{\iota }_{k}}({{{\bar {Y}}}_{k}},{{{\bar {Z}}}_{{k - 1}}})} \\ {{{g}_{k}}({{{\bar {Y}}}_{k}},{{{\bar {Z}}}_{{k - 1}}})} \end{array}} \right] = {{\bar {g}}_{k}}({{\bar {Y}}_{k}},{{\bar {Z}}_{{k - 1}}}),\quad k \geqslant 1,\quad {{\hat {\bar {X}}}_{0}} = \left[ {\begin{array}{*{20}{c}} {{{{\hat {I}}}_{0}}} \\ {{{{\hat {X}}}_{0}}} \end{array}} \right] = \left[ {\begin{array}{*{20}{c}} {{{\iota }_{0}}({{{\bar {Y}}}_{0}})} \\ {{{g}_{0}}({{{\bar {Y}}}_{0}})} \end{array}} \right] = {{\bar {g}}_{0}}({{\bar {Y}}_{0}}).$В результате соотношения (2.4), (2.5) являются рекуррентной версией фильтра (1.5) и доказано следующее утверждение.
Теорема 1 (о конечномерности ФБП). Предлагаемый разностный ФБП (1.5) является конечномерным, его вектор состояния ${{\bar {Z}}_{k}}$ состоит не более чем из желаемого числа l запоминаемых им оценок, так что порядок фильтра не превосходит величины $p = l({{n}_{x}} + 1)$. При этом функция ${{\bar {f}}_{k}}( \cdot )$ его уравнения состояния (2.4) фиксирована, а оптимизации по критерию (1.7) подлежат только дискретнозначная ${{\iota }_{k}}( \cdot )$ и непрерывнозначная ${{g}_{k}}( \cdot )$ функции формулы его выхода (2.5).
Замечание 3. Разностные уравнения ФБП (2.4), (2.5) отличаются от подобных уравнений ФКП [8] наполнением вектора состояния оценками $\bar {Z}_{k}^{{{\text{ФБП}}}} = \hat {\bar {X}}_{{\max (0,k - l + 1)}}^{k}$, а не измерениями $\bar {Z}_{k}^{{{\text{ФКП}}}} = \bar {Y}_{{\max (0,k - l + 1)}}^{k}$, а от уравнения ФМП (1.6), где $\bar {Z}_{k}^{{{\text{ФMП}}}} = {{\hat {\bar {X}}}_{k}}$, – произвольным количеством содержащихся в нем оценок.
3. Оптимизация функций выхода фильтра. Подставляя формулы для оценок ${{\hat {I}}_{k}},\,\,{{\hat {X}}_{k}}$ из (2.5) в критерий (1.7) и решая задачу минимизации полученного функционала, аналогично [1, 2, 7, 8, 10] можно получить такие выражения для пар искомых оптималей.
Для начальных функций имеем известные соотношения
(3.1)
${{\iota }_{0}}({{\bar {y}}_{0}}) \in {\text{Arg}}\mathop {\max }\limits_{i = 1..L} {\rm P}_{0}^{{(i)}}({{\bar {y}}_{0}}),\quad {{g}_{0}}({{\bar {y}}_{0}}) = \sum\limits_{i = 1}^L {{\rm P}_{0}^{{(i)}}({{{\bar {y}}}_{0}})\int {x\rho _{0}^{{(i)}}(x\,{\text{|}}\,{{{\bar {y}}}_{0}})dx} ,} $(3.2)
$\begin{array}{*{20}{l}} {{{\iota }_{k}}({{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}}) \in {\text{Arg}}\mathop {\max }\limits_{i\, = 1..L} {\rm P}_{k}^{{(i)}}({{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}}),} \\ {{{g}_{k}}({{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}}) = \sum\limits_{i = 1}^L {{\rm P}_{k}^{{(i)}}({{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}})\int {x\rho _{k}^{{(i)}}(x|{{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}})\,dx} ,} } \end{array}\quad k \geqslant 1.$Здесь ${\rm P}_{k}^{{(i)}}({{\bar {y}}_{k}},{{\bar {z}}_{{k - 1}}}) = \Pr \left[ {{{I}_{k}} = i\,{\text{|}}{{\,}_{k}} = {{{\bar {y}}}_{k}},{{{\bar {Z}}}_{{k - 1}}} = {{{\bar {z}}}_{{k - 1}}}} \right]$ – условная вероятность i-го режима, $\rho _{k}^{{(i)}}(x\,{\text{|}}\,{{\bar {y}}_{k}},{{\bar {z}}_{{k - 1}}})$ = = ${{\rho }_{k}}(x\,{\text{|}}\,i,{{\bar {y}}_{k}},{{\bar {z}}_{{k - 1}}})$ – условная плотность вероятности состояния Xk при истинности i-го режима. Произведение двух последних образует условное распределение ${{\rho }_{k}}({{\bar {x}}_{k}}\,{\text{|}}\,{{\bar {y}}_{k}},{{\bar {z}}_{{k - 1}}})$ расширенного вектора состояния ${{\bar {X}}_{k}}$ объекта (1.1):
(3.3)
$\begin{gathered} {\rm P}_{k}^{{(i)}}({{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}}) = \int {{{\rho }_{k}}(i,{{x}_{k}}\,{\text{|}}\,{{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}})\,d{{x}_{k}}} , \\ \rho _{k}^{{(i)}}({{x}_{k}}\,{\text{|}}\,{{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}}) = {{{{\rho }_{k}}(i,{{x}_{k}}\,{\text{|}}\,{{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}})} \mathord{\left/ {\vphantom {{{{\rho }_{k}}(i,{{x}_{k}}\,{\text{|}}\,{{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}})} {{\rm P}_{k}^{{(i)}}({{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}})}}} \right. \kern-0em} {{\rm P}_{k}^{{(i)}}({{{\bar {y}}}_{k}},{{{\bar {z}}}_{{k - 1}}})}}. \\ \end{gathered} $Отметим, что выше все интегралы понимаются как определенные и берутся по всему евклидову пространству соответствующей размерности, например
При этом начальные функции (3.1) и соответствующие им оценки ${{\hat {I}}_{0}},{{\hat {X}}_{0}}$ совпадают с известными [1, 2] и определяются по распределению
(3.4)
${{\rho }_{0}}(i,x\,{\text{|}}\,{{j}_{0}},{{y}_{0}}) = \frac{{{{\beta }_{0}}({{j}_{0}},{{y}_{0}}\,{\text{|}}\,i,x)\,{{p}_{0}}(i,x)}}{{\sum\limits_{i = 1}^L {\int {numerator\;dx} } }}.$Здесь и далее символом numerator в знаменателе любой дроби обозначен ее числитель.
Таким образом, формулы (3.2), (3.3) сводят задачу синтеза ФБП к определению оценивающего распределения ${{\rho }_{k}}( \cdot )$ для $k \geqslant 1$.
4. Нахождение оценивающего распределения вероятности. Используя формулу Байеса, а также марковость объекта (1.1) и безынерционность измерителя (1.2), аналогично [8] можно получить следующие соотношения. Оценивающее распределение ${{\rho }_{k}}( \cdot )$ определяется аналогично (3.4) по функции правдоподобия (1.4) и по прогнозирующему распределению ${{\pi }_{k}}( \cdot )$ состояния ${{\bar {X}}_{k}}$, которое не учитывает измерения ${{\bar {Y}}_{k}}$:
(4.1)
${{\omega }_{k}}({{i}_{k}},{{x}_{k}},{{j}_{k}},{{y}_{k}}\,{\text{|}}\,{{\bar {z}}_{{k - 1}}}) = {{\beta }_{k}}({{j}_{k}},{{y}_{k}}\,{\text{|}}\,{{i}_{k}},{{x}_{k}})\,{{\pi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{\bar {z}}_{{k - 1}}}),\quad k \geqslant 1,$(4.2)
${{\rho }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{j}_{k}},{{y}_{k}},{{\bar {z}}_{{k - 1}}}) = \frac{{{{\omega }_{k}}({{i}_{k}},{{x}_{k}},j,y\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})}}{{\sum\limits_{{{i}_{k}} = 1}^L {\int {numerator\;d{{x}_{k}}} } }},\quad k \geqslant 1.$В свою очередь прогнозирующее распределение следующего такта ${{\pi }_{{k + 1}}}( \cdot )$ выражается через распределение перехода (1.3) и соответствующее условное распределение ${{\xi }_{k}}( \cdot )$:
(4.3)
${{\pi }_{{k + 1}}}({{i}_{{k + 1}}},{{x}_{{k + 1}}}\,{\text{|}}\,{{\bar {z}}_{k}}) = \sum\limits_{{{i}_{k}} = 1}^L {\int {{{\alpha }_{k}}({{i}_{{k + 1}}},{{x}_{{k + 1}}}\,{\text{|}}\,{{i}_{k}},{{x}_{k}})\,{{\xi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{k}})\,d{{x}_{k}}} } ,\quad k \geqslant 0,$(4.4)
${{\xi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{\bar {z}}_{k}}) = \frac{{{{q}_{k}}({{i}_{k}},{{x}_{k}},{{{\bar {z}}}_{k}})}}{{\sum\limits_{{{i}_{k}} = 1}^L {\int {numerator\;d{{x}_{k}}} } }},\quad k \geqslant 0.$Таким образом, выражения (4.1)–(4.4) задают функциональную зависимость ${{\rho }_{{k + 1}}}[{{q}_{k}}( \cdot )]$ и остается найти распределение ${{q}_{k}}({{\bar {x}}_{k}},{{\bar {z}}_{k}})$.
Для его получения заметим, что пара $({{\bar {X}}_{k}},{{\bar {Z}}_{k}})$ образует марковский вектор, так как определяется замкнутой системой из возмущаемых только белыми шумами ${{\bar {V}}_{k}}$, ${{\bar {W}}_{{k + 1}}}$ разностных уравнений состояния объекта (1.1) и фильтра (2.4):
Поэтому для совместного распределения ${{q}_{k}}( \cdot )$ существует рекуррентная формула, которую и запишем далее в виде двух цепочек соотношений, соответствующих этапу накопления оценок в векторе состояния фильтра и этапу их дальнейшего обновления. Учтем также, что известность распределения ${{q}_{{k - 1}}}( \cdot )$ позволяет по соотношениям (4.1)–(4.4) найти ${{\rho }_{k}}( \cdot )$, а последнее по формулам (3.2) определяет и очередные структурные функции ${{\iota }_{k}}( \cdot )$, ${{g}_{k}}( \cdot )$.
Сначала найдем начальное совместное распределение ${{q}_{0}}({{\bar {x}}_{0}},{{\bar {z}}_{0}})$ случайной величины ${{\bar {X}}_{0}}$ и ее оценки ${{\bar {Z}}_{0}} = {{\hat {\bar {X}}}_{0}} = {{\bar {g}}_{0}}({{\bar {Y}}_{0}})$, где функция ${{\bar {g}}_{0}}({{\bar {y}}_{0}}) = {{[\begin{array}{*{20}{c}} {{{\iota }_{0}}({{{\bar {y}}}_{0}})}&{g_{0}^{{\text{Т}}}({{{\bar {y}}}_{0}})} \end{array}]}^{{\text{Т}}}}$ получена по (3.1), (3.4). Используя известные свойства согласованности и умножения распределений, а также краткие обозначения повторяющихся интегрально-суммирующих операций
(4.5)
$\sum\limits_{{{i}_{k}} = 1}^L {\int {\varphi ({{i}_{k}},{{x}_{k}})\,d{{x}_{k}}} } = \int {\varphi ({{{\bar {x}}}_{k}})\,d{{{\bar {x}}}_{k}}} ,\quad \sum\limits_{{{j}_{k}} = 1}^M {\int {\psi ({{j}_{k}},{{y}_{k}})\,d{{y}_{k}}} } = \int {\psi ({{{\bar {y}}}_{k}})\,d{{{\bar {y}}}_{k}}} $(4.6)
${{q}_{0}}({{\bar {x}}_{0}},{{\hat {\bar {x}}}_{0}}) = {{p}_{0}}({{\bar {x}}_{0}})\int {\delta \,[{{{\hat {\bar {x}}}}_{0}} - {{{\bar {g}}}_{0}}({{{\bar {y}}}_{0}})]\,{{\beta }_{0}}({{{\bar {y}}}_{0}}\,{\text{|}}\,{{{\bar {x}}}_{0}})d{{{\bar {y}}}_{0}}} .$Чтобы выразить следующее распределение ${{q}_{1}}({{\bar {x}}_{1}},{{\bar {z}}_{1}})$ через найденное ${{q}_{0}}({{\bar {x}}_{0}},{{\bar {z}}_{0}})$, учтем, что ${{\bar {Z}}_{1}} = \hat {\bar {X}}_{0}^{1}$, и также используем известную связь ${{\hat {\bar {X}}}_{1}} = {{\bar {g}}_{1}}({{\bar {Y}}_{1}},{{\hat {\bar {X}}}_{0}})$. Действуя подобным образом, получим
В результате имеем подобное (4.6) соотношение
Повторяя эти преобразования для любого такта $k = \overline {1,l - 1} $, получаем, что для этапа накопления оценок распределения ${{q}_{1}}( \cdot )$, …, ${{q}_{{l - 1}}}( \cdot )$ находятся по рекуррентной цепочке из двух формул:
(4.7)
$\left\{ \begin{gathered} {{p}_{k}}({{{\bar {x}}}_{k}},\hat {\bar {x}}_{0}^{{k - 1}}) = \int {{{\alpha }_{{k - 1}}}({{{\bar {x}}}_{k}}\,{\text{|}}\,{{{\bar {x}}}_{{k - 1}}}){{q}_{{k - 1}}}({{{\bar {x}}}_{{k - 1}}},\hat {\bar {x}}_{0}^{{k - 1}})d{{{\bar {x}}}_{{k - 1}}}} , \hfill \\ {{q}_{k}}({{{\bar {x}}}_{k}},\hat {\bar {x}}_{0}^{k}) = {{p}_{k}}({{{\bar {x}}}_{k}},\hat {\bar {x}}_{0}^{{k - 1}})\int {\delta \,[{{{\hat {\bar {x}}}}_{k}} - {{{\bar {g}}}_{k}}({{{\bar {y}}}_{k}},\hat {\bar {x}}_{0}^{{k - 1}})]\,{{\beta }_{k}}({{{\bar {y}}}_{k}}\,{\text{|}}\,{{{\bar {x}}}_{k}})d{{{\bar {y}}}_{k}}} , \hfill \\ \end{gathered} \right.\quad k = \overline {1,l - 1} .$Здесь ${{\bar {g}}_{k}}( \cdot )$ – уже найденная по предыдущему распределению ${{q}_{{k - 1}}}( \cdot )$ и формулам (3.2), (3.3), (4.1)–(4.4) структурная функция фильтра, а начальное условие ${{q}_{0}}( \cdot )$ для этой процедуры вычисляется по (4.6).
Затем для этапа обновления оценок подобным же образом можно найти и все последующие распределения ${{q}_{l}}( \cdot )$, ${{q}_{{l + 1}}}( \cdot )$ и т.д. В основном это приводит к изменению в цепочке (4.7) только второго соотношения:
(4.8)
$\left\{ \begin{gathered} {{p}_{k}}({{{\bar {x}}}_{k}},\hat {\bar {x}}_{{k - l}}^{{k - 1}}) = \int {{{\alpha }_{{k - 1}}}({{{\bar {x}}}_{k}}\,{\text{|}}\,{{{\bar {x}}}_{{k - 1}}}){{q}_{{k - 1}}}({{{\bar {x}}}_{{k - 1}}},\hat {\bar {x}}_{{k - l}}^{{k - 1}})d{{{\bar {x}}}_{{k - 1}}}} , \hfill \\ {{q}_{k}}({{{\bar {x}}}_{k}},\hat {\bar {x}}_{{k - l + 1}}^{k}) = \iint {\delta \,[{{{\hat {\bar {x}}}}_{k}} - {{{\bar {g}}}_{k}}({{{\bar {y}}}_{k}},\hat {\bar {x}}_{{k - l}}^{{k - 1}})]\,{{\beta }_{k}}({{{\bar {y}}}_{k}}\,{\text{|}}\,{{{\bar {x}}}_{k}}){{p}_{k}}({{{\bar {x}}}_{k}},\hat {\bar {x}}_{{k - l}}^{{k - 1}})d{{{\bar {y}}}_{k}}d{{{\hat {\bar {x}}}}_{{k - l}}}}, \hfill \\ \end{gathered} \right.\quad k \geqslant l.$Здесь дополнительная операция “интегрирования” типа (4.5) по ${{\hat {\bar {x}}}_{{k - l}}}$ соответствует удалению из вектора ${{\bar {Z}}_{{k - 1}}} = \hat {\bar {X}}_{{k - l}}^{{k - 1}}$ его устаревшего блока ${{\hat {\bar {X}}}_{{k - l}}}$ и отражает процесс последовательной потери информации о самых старых оценках.
Итог разд. 3 и 4 представим в виде следующего утверждения.
Теорема 2 (о синтезе оптимального ФБП). Оптимальные в смысле минимума среднего риска (1.7) структурные функции предлагаемого фильтра (1.5) вычисляются по формулам (3.2) рекуррентно вместе с определяющими их оценивающим ${{\rho }_{k}}( \cdot )$ и совместным ${{q}_{k}}( \cdot )$ распределениями вероятности по интегральным соотношениям (4.1)–(4.8).
5. Алгоритм синтеза фильтра. Полученные выше соотношения задают последовательность действий по получению структурных функций фильтра (1.5). Они выполняются заранее, до появления результатов измерений, а потому практически могут быть осуществлены скорее всего численно, но на мощном вычислителе или достаточно долго. Последнее выгодно отличает этот фильтр, как и все другие виды ФОС, от классического АОФ.
Действительно, прежде всего, найдя по формулам (3.1), (3.4) начальную вектор-функцию ${{\bar {g}}_{0}}({{\bar {y}}_{0}})$, следует по (4.6) вычислить стартовое совместное распределение ${{q}_{0}}( \cdot )$. Последнее позволяет по (4.1)–(4.4) получить первое оценивающее распределение ${{\rho }_{1}}( \cdot )$, с помощью которого затем по (3.2), (3.3) находится следующая вектор-функция ${{\bar {g}}_{1}}( \cdot )$.
Далее таким же образом для любого такта $k \geqslant 1$ следует чередовать такие операции:
– нахождение совместного распределения ${{q}_{k}}( \cdot )$ по предыдущему распределению ${{q}_{{k - 1}}}( \cdot )$ и функции ${{\bar {g}}_{{k - 1}}}( \cdot )$ с помощью соотношений (4.7) для тактов $k = \overline {1,l - 1} $ накопления оценок или с помощью формул (4.8) для последующих тактов $k \geqslant l$ обновления их набора,
– преобразование совместного распределения ${{q}_{k}}( \cdot )$ в оценивающее ${{\rho }_{{k + 1}}}( \cdot )$ снова по (4.1)–(4.4) и получение новой вектор-функции ${{\bar {g}}_{{k + 1}}}( \cdot )$ опять по (3.2), (3.3).
Выборочное приближение к оптимали ${{\bar {g}}_{k}}( \cdot )$ можно найти методом Монте-Карло, осуществляя потактовое статистическое моделирование уравнений объекта (1.1), измерителя (1.2) и фильтра (2.4), (2.5). Его целью является получение достаточно больших пакетов реализаций случайных величин $\{ {{\bar {X}}_{k}}\} $, $\{ {{\bar {Y}}_{k}}\} $, $\{ {{\bar {Z}}_{{k - 1}}}\} $ и построение по ним многомерных гистограмм искомых функций (3.2), так как они определяются условными вероятностями и плотностями (3.3). Одновременно с этим выполняется и анализ точности фильтра. Краткая иллюстрация этой процедуры приведена ниже:
Однако оба указанных способа довольно сложны, поэтому далее рассмотрим два численно-аналитических ковариационных приближения к ФБП. Они позволяют находить вид субоптимальных функций оценивания аналитически, а их параметры – численно, но уже с более простым получением выборочных значений только вероятностей дискретных случайных величин и соответствующих им двух первых условных моментов (средних и ковариаций) непрерывных случайных величин.
6. Гауссовское приближение к фильтру. Воспользуемся известным методом нормальной аппроксимации плотностей вероятности [11].
6.1. Замена распределений вероятностями и плотностями. Конкретизируем соотношения (4.1)–(4.8), заменив в них вероятностные распределения систем из смешанных случайных величин произведениями соответствующих вероятностей дискретных величин и условных плотностей вероятности непрерывных величин.
Так, условное распределение (4.1) из числителя формулы Байеса (4.2) представим в виде произведения
(6.1)
${{\omega }_{k}}({{i}_{k}},{{x}_{k}},{{j}_{k}},{{y}_{k}}\,{\text{|}}\,{{\bar {z}}_{{k - 1}}}) = \Omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{\bar {z}}_{{k - 1}}})\omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{x}_{k}},{{y}_{k}}\,{\text{|}}\,{{\bar {z}}_{{k - 1}}}),$(6.2)
$\Omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{\bar {z}}_{{k - 1}}}) = \int {\int {{{\omega }_{k}}({{i}_{k}},{{x}_{k}},{{j}_{k}},{{y}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})d{{x}_{k}}d{{y}_{k}}} } .$Для подобного представления совместного распределения ${{q}_{k}}({{\bar {x}}_{k}},{{\bar {z}}_{k}}) = {{q}_{k}}({{i}_{k}},{{x}_{k}},{{\bar {z}}_{k}})$ выделим в векторе состояния фильтра (2.1) его дискретный ${{U}_{k}} \in {{\mathbb{N}}^{l}}$ и непрерывный ${{Z}_{k}} \in {{\mathbb{R}}^{{l{{n}_{x}}}}}$ блоки:
Тогда распределения из (4.4) принимают вид, аналогичный (6.1):
(6.3)
$\begin{gathered} {{q}_{k}}({{i}_{k}},{{x}_{k}},{{{\bar {z}}}_{k}}) \equiv {{q}_{k}}({{i}_{k}},{{x}_{k}},{{u}_{k}},{{z}_{k}}) = Q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}({{x}_{k}},{{z}_{k}}), \\ {{\xi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{k}}) \equiv {{\xi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{u}_{k}},{{z}_{k}}) = \Xi _{k}^{{({{i}_{k}}\,|\,{{u}_{k}})}}({{z}_{k}})\,\xi _{k}^{{({{i}_{k}}\,|\,{{u}_{k}})}}({{x}_{k}}\,{\text{|}}\,{{z}_{k}}). \\ \end{gathered} $Кроме того у сомножителей оценивающего распределения (3.3) в верхний индекс выделим еще и целочисленное условие jk:
(6.4)
${{\rho }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{j}_{k}},{{y}_{k}},{{\bar {z}}_{{k - 1}}}) = {\rm P}_{k}^{{({{i}_{k}}\,|{{j}_{k}})}}({{y}_{k}},{{\bar {z}}_{{k - 1}}})\,\rho _{k}^{{({{i}_{k}}\,|{{j}_{k}})}}({{x}_{k}}\,{\text{|}}\,{{y}_{k}},{{\bar {z}}_{{k - 1}}}).$В результате подставляя (6.1) в (4.2) и используя (6.4), легко получаем запись формулы Байеса в виде двух отдельных выражений для оценивающей вероятности ${\rm P}_{k}^{{({{i}_{k}}\,|{{j}_{k}})}}( \cdot )$ и для оценивающей условной плотности $\rho _{k}^{{({{i}_{k}}\,|{{j}_{k}})}}( \cdot )$:
(6.5)
$\begin{gathered} {\rm P}_{k}^{{({{i}_{k}}\,|{{j}_{k}})}}({{y}_{k}},{{{\bar {z}}}_{{k - 1}}}) = {{\Omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{{\bar {z}}}_{{k - 1}}})\int {\omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{x}_{k}},{{y}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})d{{x}_{k}}} } \mathord{\left/ {\vphantom {{\Omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{{\bar {z}}}_{{k - 1}}})\int {\omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{x}_{k}},{{y}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})d{{x}_{k}}} } {\sum\limits_{{{i}_{k}} = 1}^L {numerator} }}} \right. \kern-0em} {\sum\limits_{{{i}_{k}} = 1}^L {numerator} }}, \\ \rho _{k}^{{({{i}_{k}}\,|{{j}_{k}})}}({{x}_{k}}\,{\text{|}}\,{{y}_{k}},{{{\bar {z}}}_{{k - 1}}}) = {{\omega _{{\,k}}^{{({{i}_{k}},{{j}_{k}})}}({{x}_{k}},{{y}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})} \mathord{\left/ {\vphantom {{\omega _{{\,k}}^{{({{i}_{k}},{{j}_{k}})}}({{x}_{k}},{{y}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})} {\int {numerator\,d{{x}_{k}}.} }}} \right. \kern-0em} {\int {numerator\,d{{x}_{k}}.} }} \\ \end{gathered} $В свою очередь подобное (4.2) отношение (4.4) позволяет таким же образом выразить и аналогичные сомножители условного распределения ${{\xi }_{k}}( \cdot )$ через сомножители совместного распределения ${{q}_{k}}( \cdot )$:
(6.6)
$\begin{gathered} \Xi _{k}^{{({{i}_{k}}|\,{{u}_{k}})}}({{z}_{k}}) = {{Q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}\int {q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}({{x}_{k}},{{z}_{k}})d{{x}_{k}}} } \mathord{\left/ {\vphantom {{Q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}\int {q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}({{x}_{k}},{{z}_{k}})d{{x}_{k}}} } {\sum\limits_{{{i}_{k}} = 1}^L {numerator} }}} \right. \kern-0em} {\sum\limits_{{{i}_{k}} = 1}^L {numerator} }}, \\ \xi _{k}^{{({{i}_{k}}|\,{{u}_{k}})}}({{x}_{k}}\,{\text{|}}\,{{z}_{k}}) = {{q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}({{x}_{k}},{{z}_{k}})} \mathord{\left/ {\vphantom {{q_{k}^{{({{i}_{k}},\,{{u}_{k}})}}({{x}_{k}},{{z}_{k}})} {\int {numerator\,d{{x}_{k}}} }}} \right. \kern-0em} {\int {numerator\,d{{x}_{k}}} }}. \\ \end{gathered} $Кроме того, из произведения (4.1) находим такие представления используемых в (6.5) функций через прогнозирующее распределение ${{\pi }_{k}}( \cdot )$:
(6.7)
$\begin{gathered} \Omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{{\bar {z}}}_{{k - 1}}}) = \int {{\rm B}_{k}^{{({{j}_{k}}\,|\,{{i}_{k}})}}({{x}_{k}}){{\pi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})d{{x}_{k}}} , \\ \omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{x}_{k}},{{y}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}}) = {{\beta }_{k}}({{j}_{k}},{{y}_{k}}\,{\text{|}}\,{{i}_{k}},{{x}_{k}}){{{{\pi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})} \mathord{\left/ {\vphantom {{{{\pi }_{k}}({{i}_{k}},{{x}_{k}}\,{\text{|}}\,{{{\bar {z}}}_{{k - 1}}})} {\Omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{{\bar {z}}}_{{k - 1}}})}}} \right. \kern-0em} {\Omega _{k}^{{({{i}_{k}},{{j}_{k}})}}({{{\bar {z}}}_{{k - 1}}})}}. \\ \end{gathered} $Здесь ${\rm B}_{k}^{{(j\,|\,i)}}(x) = \Pr \left[ {{{J}_{k}} = j\,{\text{|}}\,{{I}_{k}} = i,{{X}_{k}} = x} \right]$ – известная из (1.4) условная вероятность индикации
(6.8)
${\rm B}_{k}^{{(j\,|\,i)}}(x) = \int {{{\beta }_{k}}(j,y\,{\text{|}}\,i,x)dy} = M[{{\delta }_{{j,o_{k}^{{(i)}}(x,W_{k}^{\Delta })}}}].$В дальнейшем для компактности записей индекс времени k у аргументов функций будем опускать, оставляя его только у идентификаторов самих функций.
6.2. Аппроксимация условной плотности и функций оценивания. С целью получения аналитических выражений для функций оценивания ${{\iota }_{k}}( \cdot )$, ${{g}_{k}}( \cdot )$ выполним гауссовскую аппроксимацию условной плотности вероятности из числителя оценивающей плотности (6.5):
(6.9)
$\omega _{k}^{{(ij)}}(x,y\,{\text{|}}\,\bar {z}) \approx N(x,y\,{\text{||}}\,\lambda _{k}^{{(ij)}}(\bar {z}),\mu _{k}^{{(ij)}}(\bar {z});\Psi _{k}^{{(ij)}}(\bar {z}),\Phi _{k}^{{(ij)}}(\bar {z}),\Delta _{k}^{{(ij)}}(\bar {z})),\quad k \geqslant 1.$Здесь $N(\theta \,{\text{||}}\,m;D)$ – плотность нормального закона распределения случайного вектора Θ с параметрами $m = {\text{M}}\,[\Theta ]$ и $D = {\text{cov}}\,[\Theta ,\Theta ]$. В качестве условия близости этих плотностей выберем стандартные равенства как их математических ожиданий:
(6.10)
$\lambda _{k}^{{(ij)}}(\bar {z}) = M\left[ {{{X}_{k}}\,{\text{|}}\,{{I}_{k}} = i,{{J}_{k}} = j,{{{\bar {Z}}}_{{k - 1}}} = \bar {z}} \right] = \iint {x\omega _{k}^{{(ij)}}(x,y\,{\text{|}}\,\bar {z})dxdy},$(6.11)
$\mu _{k}^{{(ij)}}(\bar {z}) = M\left[ {{{Y}_{k}}\,{\text{|}}\,{{I}_{k}} = i,{{J}_{k}} = j,{{{\bar {Z}}}_{{k - 1}}} = \bar {z}} \right] = \iint {y\omega _{k}^{{(ij)}}(x,y\,{\text{|}}\,\bar {z})dxdy},$(6.12)
$\Psi _{k}^{{(ij)}}(\bar {z}) = \operatorname{cov} \left[ {{{X}_{k}},{{X}_{k}}\,{\text{|}}\,i,j,\bar {z}} \right] = \iint {x{{x}^{{\text{T}}}}\omega \,_{k}^{{(ij)}}(x,y\,{\text{|}}\,\bar {z})dxdy - \lambda _{k}^{{(ij)}}}(\bar {z})\lambda {{_{k}^{{(ij)}}}^{{\text{T}}}}(\bar {z}),$(6.13)
$\begin{gathered} \Delta _{k}^{{(ij)}}(\bar {z}) = \operatorname{cov} \left[ {{{X}_{k}},{{Y}_{k}}\,{\text{|}}\,i,j,\bar {z}} \right] = \iint {x{{y}^{{\text{T}}}}\omega _{k}^{{(ij)}}(x,y\,{\text{|}}\,\bar {z})dxdy - \lambda _{k}^{{(ij)}}(\bar {z})\mu {{{_{k}^{{(ij)}}}}^{{\text{T}}}}(\bar {z})}, \\ \Phi _{k}^{{(ij)}}(\bar {z}) = \operatorname{cov} \left[ {{{Y}_{k}},{{Y}_{k}}\,{\text{|}}\,i,j,\bar {z}} \right] = \iint {y{{y}^{{\text{T}}}}\omega _{k}^{{(ij)}}(x,y\,{\text{|}}\,\bar {z})dxdy} - \mu _{k}^{{(ij)}}(\bar {z})\mu {{_{k}^{{(ij)}}}^{{\text{T}}}}(\bar {z}). \\ \end{gathered} $Видно, что моменты $\lambda _{k}^{{(ij)}}( \cdot )$, $\Psi _{k}^{{(ij)}}( \cdot )$ имеют смысл характеристик условного прогноза вектора состояния Xk объекта (1.1) по предыдущему состоянию фильтра ${{\bar {Z}}_{{k - 1}}}$, моменты $\mu _{k}^{{(ij)}}( \cdot ),\Phi _{k}^{{(ij)}}( \cdot )$ – аналогичные характеристики прогноза вектора измерения Yk, тогда как взаимная ковариация $\Delta _{k}^{{(ij)}}( \cdot )$ – характеристика их совместного прогноза.
Вследствие аппроксимации (6.9) приближение к распределению (4.1) почти, с точностью до множителя, гауссово
(6.14)
${{\omega }_{k}}(i,x,j,y|\bar {z}) \approx \Omega _{k}^{{(ij)}}(\bar {z})N(x,y\,{\text{||}}\,\lambda _{k}^{{(ij)}}(\bar {z}),\mu _{k}^{{(ij)}}(\bar {z});\Psi _{k}^{{(ij)}}(\bar {z}),\Phi _{k}^{{(ij)}}(\bar {z}),\Delta _{k}^{{(ij)}}(\bar {z})),$Лемма 1 [6, 7]. Пусть в любой момент времени $k \geqslant 1$ существуют конечные условные моменты (6.10)–(6.13) непрерывных случайных величин Xk, Yk, а их совместно-условная плотность вероятности $\omega \,_{k}^{{(ij)}}( \cdot )$ почти гауссовская (6.9). Тогда оценивающие вероятность и плотность (6.5) имеют следующие аналитические приближения:
(6.15)
${\rm P}_{k}^{{(i|j)}}(y,\bar {z}) \approx {{\Omega _{k}^{{(ij)}}(\bar {z})N(y\,{\text{||}}\,\mu _{k}^{{(ij)}}(\bar {z});\Phi _{k}^{{(ij)}}(\bar {z}))} \mathord{\left/ {\vphantom {{\Omega _{k}^{{(ij)}}(\bar {z})N(y\,{\text{||}}\,\mu _{k}^{{(ij)}}(\bar {z});\Phi _{k}^{{(ij)}}(\bar {z}))} {\sum\limits_{i = 1}^L {numerator} }}} \right. \kern-0em} {\sum\limits_{i = 1}^L {numerator} }},$(6.16)
$\rho _{k}^{{(i|j)}}(x\,{\text{|}}\,y,\bar {z}) \approx N(x\,{\text{||}}\,\sigma _{k}^{{(i|j)}}(y,\bar {z}),\Upsilon _{k}^{{(i|j)}}(\bar {z})),$(6.17)
$\begin{gathered} \sigma _{k}^{{(i|j)}}(y,\bar {z}) = \lambda _{k}^{{(ij)}}(\bar {z}) + \Delta _{k}^{{(ij)}}(\bar {z})\Phi {{_{k}^{{(ij)}}}^{ \oplus }}(\bar {z})[y - \mu _{k}^{{(ij)}}(\bar {z})], \\ \Upsilon _{k}^{{(i|j)}}(\bar {z}) = \Psi _{k}^{{(ij)}}(\bar {z}) - \Delta _{k}^{{(ij)}}(\bar {z})\Phi {{_{k}^{{(ij)}}}^{ \oplus }}(\bar {z})\Delta {{_{k}^{{(ij)}}}^{{\text{T}}}}(\bar {z}), \\ \end{gathered} $В итоге получаем соответствующие приближения к функциям оценивания (3.2).
Лемма 2 [6, 7]. В условиях леммы 1 оптимальные функции оценивания фильтра (3.2) выражаются через моменты (6.10)–(6.13) и вероятность (6.2) по следующим приближенным формулам с функциями (6.15), (6.17):
(6.18)
${{\iota }_{k}}(j,y,\bar {z}) \in {\text{Arg}}\mathop {\max }\limits_{i = \overline {1,L} } {\rm P}_{k}^{{(i|j)}}(y,\bar {z}),\quad {{g}_{k}}(j,y,\bar {z}) \approx \sum\limits_{i = 1}^L {{\rm P}_{k}^{{(i|j)}}(y,\bar {z})\sigma _{k}^{{(i|j)}}(y,\bar {z})} .$6.3. Связи между параметрами аппроксимирующей плотности. В случае приближения (6.14) прогнозирующее распределение (4.3), являясь частным по отношению к ${{\omega }_{k}}( \cdot )$:
(6.19)
${{\pi }_{k}}(i,x\,{\text{|}}\,\bar {z}) \approx \sum\limits_{\gamma = 1}^M {\Omega _{k}^{{(i\gamma )}}(\bar {z})N(x\,{\text{||}}\,\lambda _{k}^{{(i\gamma )}}(\bar {z});\Psi _{k}^{{(i\gamma )}}(\bar {z}))} .$Подставляя же в характеристики прогноза измерения (6.11), (6.13) содержащую это распределение дробь (6.7), несложно получить зависимости параметров коррекции $\mu _{k}^{{(ij)}}( \cdot ),$ $\Phi _{k}^{{(ij)}}( \cdot ),$ $\Delta _{k}^{{(ij)}}( \cdot )$ от параметров прогноза $\lambda _{k}^{{(ij)}}( \cdot )$, $\Psi _{k}^{{(ij)}}( \cdot )$, $\Omega _{k}^{{(ij)}}( \cdot )$.
Для компактной записи подобных зависимостей будем использовать такое обозначение интегральной операции усреднения некоторой нелинейности $f( \cdot )$ с гауссовским весом $N( \cdot )$:
(6.20)
${\text{M}}_{N}^{{m,D}}[f(X)] \triangleq \int {f(x)N\left( {x\,{\text{||}}\,m,D} \right)dx} = \varphi (m,D).$Ее результат $\varphi ( \cdot )$ известен как характеристика статистической линеаризации нелинейности $f( \cdot )$.
Лемма 3 [6, 7]. В условиях леммы 1 функциональные характеристики прогноза измерения (6.11), (6.13) выражаются через характеристики прогноза состояния (6.10), (6.12) и вероятность прогноза режима-индикации (6.2) по алгебраическим формулам
(6.21)
$\begin{gathered} \mu _{k}^{{(ij)}}(\bar {z}) \approx {{\sum\limits_{\gamma = 1}^M {\Omega _{k}^{{(i\gamma )}}(\bar {z})} h_{k}^{{(j\,|\,i)}}[\lambda _{k}^{{(i\gamma )}}(\bar {z});\Psi _{k}^{{(i\gamma )}}(\bar {z})]} \mathord{\left/ {\vphantom {{\sum\limits_{\gamma = 1}^M {\Omega _{k}^{{(i\gamma )}}(\bar {z})} h_{k}^{{(j\,|\,i)}}[\lambda _{k}^{{(i\gamma )}}(\bar {z});\Psi _{k}^{{(i\gamma )}}(\bar {z})]} {\Omega _{k}^{{(ij)}}(\bar {z})}}} \right. \kern-0em} {\Omega _{k}^{{(ij)}}(\bar {z})}}, \\ \Delta _{k}^{{(ij)}}(\bar {z}) \approx {{\sum\limits_{\gamma = 1}^M {\Omega _{k}^{{(i\gamma )}}(\bar {z})} G_{k}^{{(j\,|\,i)}}[\lambda _{k}^{{(i\gamma )}}(\bar {z});\Psi _{k}^{{(i\gamma )}}(\bar {z})]} \mathord{\left/ {\vphantom {{\sum\limits_{\gamma = 1}^M {\Omega _{k}^{{(i\gamma )}}(\bar {z})} G_{k}^{{(j\,|\,i)}}[\lambda _{k}^{{(i\gamma )}}(\bar {z});\Psi _{k}^{{(i\gamma )}}(\bar {z})]} {\Omega _{k}^{{(ij)}}(\bar {z})}}} \right. \kern-0em} {\Omega _{k}^{{(ij)}}(\bar {z})}} - \lambda _{k}^{{(ij)}}(\bar {z})\mu {{_{k}^{{(ij)}}}^{{\text{T}}}}(\bar {z}), \\ \Phi _{k}^{{(ij)}}(\bar {z}) \approx {{\sum\limits_{\gamma = 1}^M {\Omega _{k}^{{(i\gamma )}}(\bar {z})} F_{k}^{{(j\,|\,i)}}[\lambda _{k}^{{(i\gamma )}}(\bar {z});\Psi _{k}^{{(i\gamma )}}(\bar {z})]} \mathord{\left/ {\vphantom {{\sum\limits_{\gamma = 1}^M {\Omega _{k}^{{(i\gamma )}}(\bar {z})} F_{k}^{{(j\,|\,i)}}[\lambda _{k}^{{(i\gamma )}}(\bar {z});\Psi _{k}^{{(i\gamma )}}(\bar {z})]} {\Omega _{k}^{{(ij)}}(\bar {z})}}} \right. \kern-0em} {\Omega _{k}^{{(ij)}}(\bar {z})}} - \mu _{k}^{{(ij)}}(\bar {z})\mu {{_{k}^{{(ij)}}}^{{\text{T}}}}(\bar {z}) \\ \end{gathered} $(6.22)
$\begin{gathered} h_{k}^{{(j\,|\,i)}}(m,D) = {\text{M}}_{N}^{{m,D}}[\nu _{k}^{{(j\,|\,i)}}(X)], \\ F_{k}^{{(j\,|\,i)}}(m,D) = {\text{M}}_{N}^{{m,D}}[{\rm H}_{k}^{{(j\,|\,i)}}(X)] \\ \end{gathered} $(6.23)
$\begin{gathered} \nu _{k}^{{(j\,|\,i)}}(x) = \int \,y\,{{\beta }_{k}}(j,y\,{\text{|}}\,i,x)dy = M[{{\delta }_{{j,o_{k}^{{(i)}}(x,W_{k}^{\Delta })}}}b_{k}^{{(i)}}(x,{{W}_{k}})], \\ {\rm H}_{k}^{{(j\,|\,i)}}(x) = \int \,y{{y}^{{\text{T}}}}{{\beta }_{k}}(j,y\,{\text{|}}\,i,x)dy = M[{{\delta }_{{j,o_{k}^{{(i)}}(x,W_{k}^{\Delta })}}}b_{k}^{{(i)}}(x,{{W}_{k}})b{{_{k}^{{(i)}}}^{{\text{T}}}}(x,{{W}_{k}})], \\ \end{gathered} $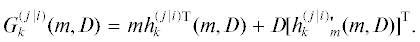
Следствие 1 [6]. В случае независимости белых шумов индикатора $W_{k}^{\Delta }$ и измерителя Wk условные средние (6.23) распадаются на произведения условной вероятности индикации (6.8) и условных средних только непрерывнозначной функции измерителя (1.2):
(6.24)
$\begin{gathered} \nu _{k}^{{(j\,|\,i)}}(x) = {\rm B}_{k}^{{(j\,|\,i)}}(x)M[b_{k}^{{(i)}}(x,{{W}_{k}})], \\ {\rm H}_{k}^{{(j\,|\,i)}}(x) = {\rm B}_{k}^{{(j\,|\,i)}}(x)M[b_{k}^{{(i)}}(x,{{W}_{k}})b{{_{k}^{{(i)}}}^{{\text{T}}}}(x,{{W}_{k}})]. \\ \end{gathered} $В оставшихся пока интегральными формулах для прогнозных характеристик как режима-индикации $\Omega _{k}^{{(ij)}}( \cdot )$, так и состояния $\lambda _{k}^{{(ij)}}( \cdot )$, $\Psi _{k}^{{(ij)}}( \cdot )$ можно выделить внутренние интегралы по переменной y, которые в соответствии с (4.1), (6.1) явно выражаются через прогнозирующее распределение ${{\pi }_{k}}( \cdot )$:
Поэтому из (6.2), (6.10), (6.12) получаем
(6.25)
$\begin{gathered} \Omega _{k}^{{(ij)}}(\bar {z}) = \int {{\rm B}_{k}^{{(j\,|\,i)}}(x)\,{{\pi }_{k}}(i,x\,{\text{|}}\,\bar {z})\,dx} , \\ \lambda _{k}^{{(ij)}}(\bar {z}) = {{\int {x{\rm B}_{k}^{{(j\,|\,i)}}(x)\,{{\pi }_{k}}(i,x\,{\text{|}}\,\bar {z})\,dx} } \mathord{\left/ {\vphantom {{\int {x{\rm B}_{k}^{{(j\,|\,i)}}(x)\,{{\pi }_{k}}(i,x\,{\text{|}}\,\bar {z})\,dx} } {\Omega _{k}^{{(ij)}}(\bar {z})}}} \right. \kern-0em} {\Omega _{k}^{{(ij)}}(\bar {z})}}, \\ \Psi _{k}^{{(ij)}}(\bar {z}) = {{\int {x{{x}^{{\text{T}}}}{\rm B}_{k}^{{(j\,|\,i)}}(x)\,{{\pi }_{k}}(i,x\,{\text{|}}\,\bar {z})\,dx} } \mathord{\left/ {\vphantom {{\int {x{{x}^{{\text{T}}}}{\rm B}_{k}^{{(j\,|\,i)}}(x)\,{{\pi }_{k}}(i,x\,{\text{|}}\,\bar {z})\,dx} } {\Omega _{k}^{{(ij)}}(\bar {z})}}} \right. \kern-0em} {\Omega _{k}^{{(ij)}}(\bar {z})}} - \lambda _{k}^{{(ij)}}(\bar {z})\lambda {{_{k}^{{(ij)}}}^{{\text{T}}}}(\bar {z}). \\ \end{gathered} $В свою очередь ${{\pi }_{{k + 1}}}( \cdot )$ выражается через условное распределение ${{\xi }_{k}}( \cdot )$ по (4.3) или, используя (6.3), через его сомножители
Подставляя это в (6.25), для значений этих трех параметров на следующем такте получим интегральные выражения:
(6.26)
$\begin{gathered} \Omega _{{k + 1}}^{{(lf)}}(u,z) \approx \sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)} \int {\varsigma _{k}^{{(lf\,|\,i)}}(x)\,} \xi _{k}^{{(i\,|\,u)}}(x\,{\text{|}}\,z)\,dx, \\ \lambda _{{k + 1}}^{{(lf)}}(u,z) \approx {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)\int {\varphi _{k}^{{(lf\,|\,i)}}(x)\,} \xi _{k}^{{(i\,|\,u)}}(x\,{\text{|}}\,z)\,dx} } \mathord{\left/ {\vphantom {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)\int {\varphi _{k}^{{(lf\,|\,i)}}(x)\,} \xi _{k}^{{(i\,|\,u)}}(x\,{\text{|}}\,z)\,dx} } {\Omega _{{k + 1}}^{{(lf)}}(u,z)}}} \right. \kern-0em} {\Omega _{{k + 1}}^{{(lf)}}(u,z)}}, \\ \Psi _{{k + 1}}^{{(lf)}}(u,z) \approx {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)\int {\Sigma _{k}^{{(lf\,|\,i)}}(x)\,} \xi _{k}^{{(i\,|\,u)}}(x\,{\text{|}}\,z)\,dx} } \mathord{\left/ {\vphantom {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)\int {\Sigma _{k}^{{(lf\,|\,i)}}(x)\,} \xi _{k}^{{(i\,|\,u)}}(x\,{\text{|}}\,z)\,dx} } {\Omega _{{k + 1}}^{{(lf)}}(u,z)}}} \right. \kern-0em} {\Omega _{{k + 1}}^{{(lf)}}(u,z)}} - \lambda _{{k + 1}}^{{(lf)}}(u,z)\lambda {{_{{k + 1}}^{{(lf)}}}^{{\text{T}}}}(u,z), \\ \end{gathered} $Используя здесь распределение перехода (1.3), эти условные средние можно непосредственно выразить через вероятность индикации (6.8) и две функции объекта наблюдения (1.1):
(6.27)
$\begin{gathered} \varsigma _{k}^{{(lf\,|\,i)}}(x) = M[{{\delta }_{{l,\,\,\phi _{k}^{{(i)}}(x,V_{k}^{\Delta })}}}{\rm B}_{{k + 1}}^{{(f|\,l)}}[a_{k}^{{(i)}}(x,{{V}_{k}})]], \\ \varphi _{k}^{{(lf\,|\,i)}}(x) = M[a_{k}^{{(i)}}(x,{{V}_{k}})\,{{\delta }_{{l,\,\,\phi _{k}^{{(i)}}(x,V_{k}^{\Delta })}}}{\rm B}_{{k + 1}}^{{(f|\,l)}}[a_{k}^{{(i)}}(x,{{V}_{k}})]], \\ \Sigma _{k}^{{(lf\,|\,i)}}(x) = M[a_{k}^{{(i)}}(x,{{V}_{k}})\,a{{_{k}^{{(i)}}}^{{\text{T}}}}(x,{{V}_{k}})\,{{\delta }_{{l,\phi _{k}^{{(i)}}(x,V_{k}^{\Delta })}}}{\rm B}_{{k + 1}}^{{(f|\,l)}}[a_{k}^{{(i)}}(x,{{V}_{k}})]]. \\ \end{gathered} $В результате доказано следующее утверждение.
Лемма 4. Если моменты (6.10), (6.12) существуют, то значения прогнозов режима-индикации $\Omega _{k}^{{(ij)}}( \cdot )$ и состояния $\lambda _{k}^{{(ij)}}( \cdot )$, $\Psi _{k}^{{(ij)}}( \cdot )$ на следующем такте k + 1 формулами (6.26) выражаются через условную вероятность $\Xi _{k}^{{(i\,|\,u)}}(z)$ и результаты усреднения с весом $\xi _{k}^{{(i\,|\,u)}}(x\,{\text{|}}\,z)$ условных средних индикации и состояния объекта (6.27).
Несложно заметить, что условные средние (6.27) упрощаются в следующих распространенных частных случаях.
Следствие 2. Если в уравнениях объекта (1.1) порождающие возмущения $V_{k}^{\Delta }$, Vk независимы, то в (6.27) выделяется сомножитель в виде условной вероятности переключения
(6.28)
$\begin{gathered} \varsigma _{k}^{{(lf\,|\,i)}}(x) = {\rm A}_{k}^{{(l\,|\,i)}}(x)M[{\rm B}_{{k + 1}}^{{(f|\,l)}}\{ a_{k}^{{(i)}}(x,{{V}_{k}})\} ], \\ \varphi _{k}^{{(lf\,|\,i)}}(x) = {\rm A}_{k}^{{(l\,|\,i)}}(x)M[a_{k}^{{(i)}}(x,{{V}_{k}}){\rm B}_{{k + 1}}^{{(f|\,l)}}\{ a_{k}^{{(i)}}(x,{{V}_{k}})\} ], \\ \Sigma _{k}^{{(lf\,|\,i)}}(x) = {\rm A}_{k}^{{(l\,|\,i)}}(x)M[a_{k}^{{(i)}}(x,{{V}_{k}})a{{_{k}^{{(i)}}}^{{\text{T}}}}(x,{{V}_{k}}){\rm B}_{{k + 1}}^{{(f|\,l)}}\{ a_{k}^{{(i)}}(x,{{V}_{k}})\} ]. \\ \end{gathered} $Следствие 3. Если индикация режима ${{J}_{k}}$ происходит без учета состояния объекта ${{X}_{k}}$, так что первое уравнение измерителя (1.2) имеет вид ${{J}_{k}} = o_{k}^{{({{I}_{k}})}}(W_{k}^{\Delta })$, то вероятность индикации (6.8) не зависит от состояния объекта: ${\rm B}_{k}^{{(j\,|\,i)}} = M[{{\delta }_{{j,o_{k}^{{(i)}}(W_{k}^{\Delta })}}}]$. Тогда из (6.28) получаем простые произведения:
(6.29)
$\begin{gathered} \varsigma _{k}^{{(lf\,|\,i)}}(x) = {\rm B}_{{k + 1}}^{{(f|\,l)}}{\rm A}_{k}^{{(l\,|\,i)}}(x), \\ \varphi _{k}^{{(lf\,|\,i)}}(x) = {\rm B}_{{k + 1}}^{{(f|\,l)}}{\rm A}_{k}^{{(l\,|\,i)}}(x)M[a_{k}^{{(i)}}(x,{{V}_{k}})], \\ \Sigma _{k}^{{(lf\,|\,i)}}(x) = {\rm B}_{{k + 1}}^{{(f|\,l)}}{\rm A}_{k}^{{(l\,|\,i)}}(x)M[a_{k}^{{(i)}}(x,{{V}_{k}})a{{_{k}^{{(i)}}}^{{\text{T}}}}(x,{{V}_{k}})], \\ \end{gathered} $Также из (6.27) легко видеть, что наибольшего упрощения эти функции достигают в случае отсутствия в измерении (1.2) переменной индикации Jk, когда ${\rm B}_{k}^{{(j\,|\,i)}}(x) = {{\delta }_{{j,1}}}$.
Следствие 4. Если в наблюдении (1.2) отсутствует переменная индикации Jk, то функции (6.27) не зависят от целочисленной переменной f и выражаются только через вероятность переключения и непрерывнозначную функцию объекта наблюдения:
6.4. Аппроксимация безусловной плотности и параметры фильтра. Так как условное распределение ${{\xi }_{k}}( \cdot )$ определяется, согласно (4.4), безусловным распределением ${{q}_{k}}( \cdot )$, то с целью получения алгебраических зависимостей и для характеристик прогноза $\Omega _{k}^{{(ij)}}( \cdot )$, $\lambda _{k}^{{(ij)}}( \cdot )$, $\Psi _{k}^{{(ij)}}( \cdot )$ аппроксимируем гауссовской, кроме условной плотности (6.9), еще и безусловную плотность
(6.30)
$q_{k}^{{(i\,u)}}(x,z) \approx N(x,z\,{\text{||}}\,m_{k}^{{x\,|\,i\,u}},m_{k}^{{z\,|\,i\,u}};D_{k}^{{x\,|\,i\,u}},D_{k}^{{z\,|\,i\,u}},D_{{kk}}^{{xz\,|\,i\,u}}).$В качестве условия близости и этих двух плотностей тоже выберем аналогичные (6.10)–(6.13) равенства всех их математических ожиданий и ковариаций:
(6.31)
$\begin{array}{*{20}{c}} {m_{k}^{{x\,|\,i\,u}} = {\text{M}}[{{X}_{k}}\,{\text{|}}\,{{I}_{k}} = i,{{U}_{k}} = u],} \\ {m_{k}^{{z\,|\,i\,u}} = {\text{M}}[{{Z}_{k}}\,{\text{|}}\,{{I}_{k}} = i,{{U}_{k}} = u],} \end{array}\quad \begin{array}{*{20}{l}} {D_{k}^{{x\,|\,i\,u}} = {\text{cov}}[{{X}_{k}},{{X}_{k}}\,{\text{|}}\,{{I}_{k}} = i,{{U}_{k}} = u],} \\ {D_{k}^{{z\,|\,i\,u}} = {\text{cov}}[{{Z}_{k}},{{Z}_{k}}\,{\text{|}}\,{{I}_{k}} = i,{{U}_{k}} = u],} \\ {D_{{kk}}^{{xz\,|\,i\,u}} = {\text{cov}}[{{X}_{k}},{{Z}_{k}}\,{\text{|}}\,{{I}_{k}} = i,{{U}_{k}} = u].} \end{array}$Тогда само распределение ${{q}_{k}}( \cdot )$, как и условное распределение (6.14), почти гауссово:
Лемма 5 [6, 7]. Если справедлива гауссовская аппроксимация безусловной плотности вероятности (6.30), то условные вероятность и плотность (6.6) имеют следующие приближения:
(6.32)
$\begin{gathered} \Xi _{k}^{{(i\,|\,u)}}(z) \approx {{Q_{k}^{{(i\,u)}}N(z\,{\text{||}}\,m_{k}^{{z\,|\,i\,u}};D_{k}^{{z\,|\,i\,u}})} \mathord{\left/ {\vphantom {{Q_{k}^{{(i\,u)}}N(z\,{\text{||}}\,m_{k}^{{z\,|\,i\,u}};D_{k}^{{z\,|\,i\,u}})} {\sum\limits_{i = 1}^L {numerator} }}} \right. \kern-0em} {\sum\limits_{i = 1}^L {numerator} }}, \\ \xi _{k}^{{(i\,|\,u)}}(x|z) \approx N[x\,{\text{||}}\,\vartheta _{k}^{{(i\,|\,u)}}(z);T_{k}^{{(i\,|\,u)}}]. \\ \end{gathered} $При этом математическое ожидание $\vartheta _{k}^{{(i\,|\,u)}}(z)$ приближения к плотности $\xi _{k}^{{(i\,|\,u)}}( \cdot )$ является линейной функцией ее условия
а ее ковариация $T_{k}^{{(i\,|\,u)}}$ от этого условия не зависит и вместе с двумя параметрами из (6.33) определяется по формулам(6.34)
$\Gamma _{k}^{{(i\,|\,u)}} = D_{{kk}}^{{xz|\,i\,u}}{{(D_{k}^{{z|\,i\,u}})}^{ \oplus }},\quad \kappa _{k}^{{(i\,|\,u)}} = m_{k}^{{x|\,i\,u}} - \Gamma _{k}^{{(i\,|\,u)}}m_{k}^{{z|\,i\,u}},\quad T_{k}^{{(i\,|\,u)}} = D_{k}^{{x|\,i\,u}} - \Gamma _{k}^{{(i\,|\,u)}}{{(D_{{kk}}^{{xz|\,i\,u}})}^{T}}.$Тогда, используя в интегральных формулах (6.26) леммы 4 гауссовость условной плотности $\xi _{k}^{{( \cdot )}}( \cdot )$, получим следующий результат.
Лемма 6 [7]. Если имеет место гауссовское приближение (6.30), то вероятность (6.2) прогноза номера структуры объекта ${{I}_{{k + 1}}}$ и его индикации ${{J}_{{k + 1}}}$, а также характеристики (6.10), (6.12) условного прогноза следующего состояния ${{X}_{{k + 1}}}$ выражаются через функции (6.32), (6.33) предыдущих измерения Yk и состояния фильтра ${{\bar {Z}}_{k}}$ по алгебраическим формулам:
(6.35)
$\begin{gathered} \Omega _{{k + 1}}^{{(lf)}}(u,z) \approx \sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)\eta _{k}^{{(lf\,|\,i\,)}}[\vartheta _{k}^{{(i\,|\,u)}}(z);T_{k}^{{(i\,|\,u)}}]} ,\quad z = {{z}_{k}}, \\ \lambda _{{k + 1}}^{{(lf)}}(u,z) \approx {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)\tau _{k}^{{(lf\,|\,i\,)}}[\vartheta _{k}^{{(i\,|\,u)}}(z);T_{k}^{{(i\,|\,u)}}]} } \mathord{\left/ {\vphantom {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z)\tau _{k}^{{(lf\,|\,i\,)}}[\vartheta _{k}^{{(i\,|\,u)}}(z);T_{k}^{{(i\,|\,u)}}]} } {\Omega _{{k + 1}}^{{(lf)}}(u,z)}}} \right. \kern-0em} {\Omega _{{k + 1}}^{{(lf)}}(u,z)}}, \\ \Psi _{{k + 1}}^{{(lf)}}(u,z) \approx {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z){\rm X}_{k}^{{(lf\,|\,i\,)}}[\vartheta _{k}^{{(i\,|\,u)}}(z);T_{k}^{{(i\,|\,u)}}]} } \mathord{\left/ {\vphantom {{\sum\limits_{i = 1}^L {\Xi _{k}^{{(i\,|\,u)}}(z){\rm X}_{k}^{{(lf\,|\,i\,)}}[\vartheta _{k}^{{(i\,|\,u)}}(z);T_{k}^{{(i\,|\,u)}}]} } {\Omega _{{k + 1}}^{{(lf)}}(u,z)}}} \right. \kern-0em} {\Omega _{{k + 1}}^{{(lf)}}(u,z)}} - \lambda _{{k + 1}}^{{(lf)}}(u,z)\lambda {{_{{k + 1}}^{{(lf)}}}^{{\text{T}}}}(u,z) \\ \end{gathered} $(6.36)
$\begin{gathered} \eta _{k}^{{(lf\,|\,i)}}(m,D) = {\text{M}}_{N}^{{m,D}}[\varsigma _{k}^{{(lf\,|\,i)}}(X)], \\ \tau _{k}^{{(lf\,|\,i)}}(m,D) = {\text{M}}_{N}^{{m,D}}[\varphi _{k}^{{(lf\,|\,i)}}(X)], \\ {\rm X}_{k}^{{(lf\,|\,i)}}(m,D) = {\text{M}}_{N}^{{m,D}}[\Sigma _{k}^{{(lf\,|\,i)}}(X)], \\ \end{gathered} $Отметим, что в построении зависимостей (6.35) по функциям (6.36) участвуют две тройки числовых параметров гауссовских приближений (6.32). Это вероятность дискретных компонентов векторов состояния объекта и фильтра $Q_{k}^{{(i\,u)}} = \Pr \left[ {{{I}_{k}} = i,{{U}_{k}} = u} \right]$ вместе с двумя условными моментами $m_{k}^{{z\,|\,i\,u}}$, $D_{k}^{{z\,|\,i\,u}}$ непрерывной части вектора состояния фильтра из (6.31), а также определяемая по (6.34) с учетом всех моментов (6.31) тройка параметров $\Gamma _{k}^{{(i\,|\,u)}},$ $\kappa _{k}^{{(i\,|\,u)}}$, $T_{k}^{{(i\,|\,u)}}$. Они находятся методом Монте-Карло в процессе последовательного статистического моделирования приведенных ниже уравнений предлагаемого фильтра так же, как и гауссовского ФМП [7].
6.5. Уравнения гауссовского фильтра. Приведенные выше леммы позволяют сформулировать следующий результат.
Теорема 3 (об уравнениях гауссовского ФБП). Если имеют место гауссовские аппроксимации плотностей вероятности (6.9), (6.30), то процедура вычисления оценок состояния многорежимного объекта (1.1) по наблюдениям (1.2) субоптимальным ФБП состоит из рекуррентной цепочки следующих шагов. После нахождения классических начальных оценок ${{\hat {I}}_{0}}$, ${{\hat {X}}_{0}}$ и задания начальных условий $\Omega _{0}^{{(ij)}},$ $\lambda _{0}^{{(ij)}},$ $\mu _{0}^{{(ij)}},$ $\Psi _{0}^{{(ij)}},$ $\Delta _{0}^{{(ij)}},$ $\Phi _{0}^{{(ij)}}$ $i = \overline {1,L} $, $j = \overline {1,M} $, на каждом такте $k \geqslant 0$ последовательно осуществляются следующие операции.
1. Регистрация новых наблюдений ${{J}_{k}}$, ${{Y}_{k}}$ и формирование вектора состояния фильтра:
Здесь ${{C}_{u}} = \left[ {\begin{array}{*{20}{c}} {{{E}_{{l - 1}}}}&{{{O}_{{(l - 1) \times 1}}}} \end{array}} \right]$, ${{C}_{z}} = \left[ {\begin{array}{*{20}{c}} {{{E}_{{(l - 1){{n}_{x}}}}}}&{{{O}_{{(l - 1){{n}_{x}} \times {{n}_{x}}}}}} \end{array}} \right]$ – матрицы удаления из векторов ${{U}_{{k - 1}}}$ и ${{Z}_{{k - 1}}}$ их последних блоков.
2. Конкретизация условных прогнозов состояния и измерения по индикации Jk:
3. Вычисление реализаций параметров гауссовского приближения к оценивающему распределению ${{\rho }_{k}}( \cdot )$ в соответствии с (6.15), (6.17) (лемма 1):
4. Определение оценок состояния объекта по (2.5) (теорема 1) и (6.18) (лемма 2):
5. Нахождение модификаций $\Xi _{k}^{{(i)}},$ $\vartheta _{k}^{{(i)}}$, соответственно, вероятности $Q_{k}^{{(i)}}$ по (6.32) и вектора ${{Z}_{k}}$ по (6.33) (лемма 5):
6. Вычисление характеристик условных прогнозов следующего состояния объекта ${{\bar {X}}_{{k + 1}}}$ и выхода индикатора ${{J}_{{k + 1}}}$ по (6.35) с использованием функций прогноза (6.36) (леммы 4, 6):
7. Нахождение значений характеристик условных прогнозов следующего измерения ${{Y}_{{k + 1}}}$ по (6.21) с использованием функций коррекции (6.22) (лемма 3):
8. Если дискретное время $k < K$, то положить $k: = k + 1$ и вернуться к п. 1, иначе завершить вычисления.
7. Линеаризованное приближение к фильтру. К сожалению, построение гауссовского фильтра требует выполнения довольно сложных интегральных операций нахождения как условных средних измерителя (6.23) и всей системы наблюдения (6.27), так и определения характеристик статистической линеаризации (6.20) этих нелинейностей. Поэтому рассмотрим и другое известное приближение, существенно более простое, а потому и более популярное.
Ограничимся частными случаями (следствия 1–3), когда, согласно (6.24), (6.28), (6.29), функции коррекции (6.22) и прогноза (6.36) находятся гауссовским усреднением более простых условных средних:
Они образуются как произведения постоянной вероятности индикации ${\rm B}_{k}^{{(j\,|\,i)}}$ соответственно на условные средние непрерывнозначной функции измерителя (1.2):
Пусть три следующие функции дифференцируемы по своим аргументам и каждую из них с достаточной точностью можно линеаризовать по Тейлору:
(7.1)
$\begin{gathered} {\rm A}_{k}^{{(l\,|\,i)}}(x) \approx {\rm A}_{k}^{{(l\,|\,i)}}(m) + {\rm A}_{k}^{{(l\,|\,i)}}{\kern 1pt} _{x}^{'}(m)\,{{x}^{o}}, \\ a_{k}^{{(i)}}(x,v) \approx a_{k}^{{(i)}}(m,m_{k}^{v}) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} _{x}^{'}(m)\,{{x}^{o}} + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} _{v}^{'}(m)[v - m_{k}^{v}]\,, \\ b_{k}^{{(i)}}(x,w) \approx b_{k}^{{(i)}}(m,m_{k}^{w}) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{b} _{k}^{{(i)}}{\kern 1pt} _{x}^{'}(m)\,{{x}^{o}} + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{b} _{k}^{{(i)}}{\kern 1pt} _{w}^{'}(m)[w - m_{k}^{w}]\,. \\ \end{gathered} $Здесь ${{x}^{o}} = x - m$ – малое отклонение, $m_{k}^{\delta }$ – среднее значение случайной величины ${{\Delta }_{k}}$, штрихами и нижними индексами обозначены матрицы частных производных по соответствующим переменным:
Тогда аналогично [6] получим такое утверждение.
Следствие 5 (о структурных функциях линеаризованного ФБП). Пусть имеют место следствия 1–3 и справедливы приближения (7.1). Тогда две основные функции гауссовской коррекции (6.22) аппроксимируются следующими выражениями:
(7.2)
$\begin{gathered} h_{k}^{{(j\,|\,i)}}(m,D) \approx {\rm B}_{k}^{{(j\,|\,i)}}\,b_{k}^{{(i)}}(m,m_{k}^{w}), \\ F_{k}^{{(j\,|\,i)}}(m,D) \approx {\rm B}_{k}^{{(j\,|\,i)}}(b_{k}^{{(i)}}(m,m_{k}^{w})\,b{{_{k}^{{(i)}}}^{{\text{T}}}}(m,m_{k}^{w}) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{b} _{k}^{{(i)}}{\kern 1pt} _{x}^{'}(m)D\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{b} _{k}^{{(i)}}{\kern 1pt} {{_{x}^{'}}^{{\text{T}}}}(m) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{b} _{k}^{{(i)}}{\kern 1pt} _{w}^{'}(m)D_{k}^{w}\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{b} _{k}^{{(i)}}{\kern 1pt} {{_{w}^{'}}^{{\text{T}}}}(m)), \\ \end{gathered} $(7.3)
$\begin{gathered} \eta _{k}^{{(lf\,|\,i)}}(m,D) \approx {\rm B}_{{k + 1}}^{{(f|\,l)}}{\rm A}_{k}^{{(l\,|\,i)}}(m), \\ \tau _{k}^{{(lf\,|\,i)}}(m,D) \approx {\rm B}_{{k + 1}}^{{(f|\,l)}}({\rm A}_{k}^{{(l\,|\,i)}}(m)a_{k}^{{(i)}}(m,m_{k}^{{v}}) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} _{x}^{'}(m)D{\rm A}_{k}^{{(i)}}{\kern 1pt} {{_{x}^{'}}^{{\text{T}}}}(m)), \\ {\rm X}_{k}^{{(lf\,|\,i)}}(m,D) \approx {\rm B}_{{k + 1}}^{{(f|\,l)}}\left[ {a_{k}^{{(i)}}(m,m_{k}^{{v}}){\rm A}_{k}^{{(l\,|\,i)}}{\kern 1pt} _{x}^{'}(m)D\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} {{{_{x}^{'}}}^{{\text{T}}}}(m) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} _{x}^{'}(m)D{\rm A}_{k}^{{(l\,|\,i)}}{\kern 1pt} {{{_{x}^{'}}}^{{\text{T}}}}(m)a{{{_{k}^{{(i)}}}}^{{\text{T}}}}(m,m_{k}^{{v}}) + } \right] \\ + \;\left. {{\rm A}_{k}^{{(l\,|\,i)}}(m)\left( {a_{k}^{{(i)}}(m,m_{k}^{{v}})\,a{{{_{k}^{{(i)}}}}^{{\text{T}}}}(m,m_{k}^{{v}}) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} _{x}^{'}(m)D\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} {{{_{x}^{'}}}^{{\text{T}}}}(m) + \overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} _{v}^{'}(m)D_{k}^{{v}}\overset{\lower0.5em\hbox{$\smash{\scriptscriptstyle\smile}$}}{a} _{k}^{{(i)}}{\kern 1pt} {{{_{v}^{'}}}^{{\text{T}}}}(m)} \right)} \right]. \\ \end{gathered} $Таким образом, линеаризации (7.1) позволяют сложные интегральные формулы нахождения структурных функций гауссовского фильтра заменить более простыми дифференциальными (7.2), (7.3), но с еще большей потерей в точности оценивания.
Заключение. Предложен метод синтеза быстрого логико-динамического ФБП, запоминающего несколько последних оценок вектора состояния дискретного многорежимного объекта. Этот фильтр обладает наивысшей точностью в своем классе, а его структурные функции находятся заранее, после чего сам фильтр может быть реализован в реальном времени на дешевом вычислителе. Получены формулы для нахождения его оптимальных функций оценивания, найдена цепочка интегральных формул для соответствующих распределений вероятности, представлены способы вычисления структурных функций фильтра как по интегральным соотношениям, так и методом Монте-Карло. Однако последний численный алгоритм громоздок технически из-за необходимости получения гистограмм искомых функций.
Поэтому рассмотрено и построение численно-аналитических ковариационных приближений к предложенному фильтру, позволяющих находить вид функций оценивания аналитически с помощью известных операций линеаризации нелинейностей системы наблюдения либо статистической (по Казакову), либо обычной (по Тейлору). Появляющиеся при этом параметры фильтра получают тем же методом Монте-Карло, но уже с вычислением только вероятностей дискретных случайных величин и соответствующих им двух первых условных моментов непрерывных случайных величин.
Отметим, что в частном случае однорежимного объекта, когда в уравнениях (1.1), (1.2) отсутствуют целочисленные переменные Ik, Jk, предложенный логико-динамический фильтр вырождается в обычный динамический вроде [13].
В последующих статьях на эту тему автор планирует продемонстрировать эффективность полученных ковариационных приближений к ФБП в их сравнении с подобными приближениями не только к классическому АОФ, но и с другими версиями ФОС, как малого порядка [6, 7], так и с конечной памятью [8]. Ранее подобные аналитические сравнения сложности самих алгоритмов дискретных АОФ и ФОС уже приводились в [13], а численные сопоставления их точности были выполнены как на модельном логико-динамическом примере [6], так и на рассмотренной в [13, 14] задаче автономного оценивания траектории однорежимного спускаемого аппарата.
Список литературы
Немура А., Клекис Э. Оценивание параметров и состояния систем со скачкообразно меняющимися свойствами. Вильнюс: Мокслас, 1988.
Бухалев В.А. Распознавание, оценивание и управление в системах со случайной скачкообразной структурой. М.: Наука, 1996.
Борисов А.В., Стефанович А.И. Оптимальная фильтрация состояний специальных управляемых систем случайной структуры // Изв. РАН. ТиСУ. 2007. № 3. С. 16–26.
Bain A., Crisan D. Fundamentals of Stochastic Filtering. N.Y.: Springer, 2009.
Босов А.В., Панков А.Р. Условно-минимаксная фильтрация в системе с переключающимися каналами наблюдения // АиТ. 1995. № 6. С. 87–97.
Руденко Е.А. Численно-аналитические приближения к оптимальному рекуррентному логико-динамическому фильтру-предиктору малого порядка // Изв. РАН. ТиСУ. 2015. № 5. С. 24–47.
Руденко Е.А. Конечномерные рекуррентные алгоритмы оптимальной логико-динамической фильтрации // Изв. РАН. ТиСУ. 2016. № 1. С. 43–65.
Руденко Е.А. Оптимальный рекуррентный логико-динамический фильтр с конечной памятью // Изв. РАН. ТиСУ. 2017. № 4. С. 56–64.
Кудрявцева И.А., Руденко Е.А., Рыбаков К.А. Программное обеспечение оптимального оценивания состояний стохастических динамических систем // Информационные и телекоммуникационные технологии. 2019. № 43. С. 23–28.
Трифонов А.П., Шинаков Ю.С. Совместное различение сигналов и оценка их параметров на фоне помех. М.: Радио и связь, 1986.
Пугачев В.С., Синицын И.Н. Теория стохастических систем. М.: Логос, 2004.
Ширяев А.Н. Вероятность. М.: Наука, 1980.
Руденко Е.А. Оптимальный нелинейный рекуррентный фильтр с конечной памятью // Изв. РАН. ТиСУ. 2018. № 1. С. 45–63.
Руденко Е.А. Автономное оценивание траектории спускаемого аппарата рекуррентными гауссовскими фильтрами // Изв. РАН. ТиСУ. 2018. № 5. С. 9–29.
Дополнительные материалы отсутствуют.
Инструменты
Известия РАН. Теория и системы управления