

Известия РАН. Теория и системы управления, 2021, № 3, стр. 23-38
АНАЛИТИЧЕСКОЕ КОНСТРУИРОВАНИЕ ОПТИМАЛЬНЫХ РЕГУЛЯТОРОВ В ЛИНЕЙНО-КВАДРАТИЧНЫХ ЗАДАЧАХ УПРАВЛЕНИЯ СИСТЕМАМИ С РАСПРЕДЕЛЕННЫМИ ПАРАМЕТРАМИ ПРИ РАВНОМЕРНЫХ ОЦЕНКАХ ЦЕЛЕВЫХ МНОЖЕСТВ
Э. Я. Рапопорт *
Самарский государственный технический ун-т
Самара, Россия
* E-mail: edgar.rapoport@mail.ru
Поступила в редакцию 16.06.2020
После доработки 12.09.2020
Принята к публикации 30.11.2020
Аннотация
Предлагается конструктивный метод синтеза оптимального управления детерминированными и не полностью определенными системами с распределенными параметрами параболического типа в условиях заданной точности равномерного приближения конечного состояния объекта к требуемому пространственному распределению управляемой величины. Развиваемый подход базируется на разработанном ранее альтернансном методе построения оптимальных алгоритмов программного управления, который распространяет на широкий круг параметризуемых задач оптимального управления результаты теории нелинейных чебышевских приближений и существенно использует фундаментальные закономерности предметной области. Показывается, что искомые уравнения оптимальных регуляторов сводятся к линейным с нестационарными коэффициентами законам обратной связи по управляемому выходу объекта, которые реализуются непосредственно по результатам неполного измерения состояния системы с погрешностью, уменьшающейся с ростом числа учитываемых модальных составляющих управляемой величины.
Введение. Начиная с основополагающих работ А.М. Летова [1, 2] классическая задача синтеза оптимальных регуляторов в линейных системах с квадратичными критериями оптимальности до настоящего времени остается одной из центральных в теории и технике автоматического управления [3–8]. Большинство работ в этом направлении относится к системам с сосредоточенными параметрами (ССП), для которых известные результаты получены методами вариационного исчисления, принципа максимума Понтрягина, динамического программирования для детерминированных моделей объекта [1–5] и с привлечением аппарата функций Ляпунова и линейных матричных неравенств в условиях ограниченной неопределенности модельных представлений [6–8].
Проблема аналитического конструирования оптимальных регуляторов (АКОР) в линейно-квадратичных задачах оптимизации обладает принципиальной спецификой в системах управления динамическими объектами с распределенными параметрами (СРП), в рамках моделей которых описывается широкий круг управляемых процессов самой различной физической природы [9]. Возникающие здесь особенности связаны прежде всего с необходимостью решения задачи АКОР в условиях бесконечной размерности пространственно распределенной управляемой величины [10–13].
Задачи синтеза СРП в указанной постановке рассматривались путем распространения на системы с распределенными параметрами метода динамического программирования в идеализированных и реализуемых условиях соответственно полного и неполного измерения управляемых функций состояния объекта [10–13]. Основные результаты решения проблемы АКОР в ССП и СРП получены применительно к задачам со свободным или подвижным правым концом траектории движения объекта с использованием классических условий трансверсальности на гладкой границе области допустимых конечных состояний управляемой системы.
Однако в целом ряде типичных для приложений и представляющих самостоятельный интерес ситуаций требования к конечному состоянию СРП предъявляются в чебышевской метрике в форме допустимой величины ошибки равномерного приближения управляемой величины к заданному распределению в пространственной области ее определения [13–15]. Известные условия трансверсальности неприменимы на негладкой границе соответствующего целевого множества в бесконечномерном фазовом пространстве СРП, что существенно усложняет решение краевой задачи оптимального управления. В целях опознания конечной точки оптимального процесса здесь могут быть использованы ее специальные альтернансные свойства, определяемые по схеме конструктивного альтернансного метода, который является распространением на задачи оптимизации теории нелинейных чебышевских приближений [13–15].
В настоящей работе предлагается метод решения задачи АКОР для линейных моделей СРП параболического типа в условиях равномерных оценок целевых множеств применительно к детерминированному варианту и в условиях воздействия множественных возмущений. Развиваемый подход существенно опирается на результаты решения задачи оптимального программного управления с помощью альтернансных свойств искомых экстремалей [13–15].
1. Постановка задачи. Пусть управляемая величина $Q(x,t)$ объекта с распределенными параметрами описывается в зависимости от пространственной координаты $x \in [{{x}_{0}},{{x}_{1}}]$ и времени $t \in \left[ {0,t{\kern 1pt} *} \right]$ одномерным линейным уравнением второго порядка в частных производных параболического типа с самосопряженным дифференциальным оператором в его правой части:
(1.1)
$\frac{{\partial Q(x,t)}}{{\partial t}} = b(x)\frac{{\partial Q(x,t)}}{{\partial x}} + c(x)\frac{{{{\partial }^{2}}Q(x,t)}}{{\partial {{x}^{2}}}} + {{c}_{1}}(x)\,Q(x,t) + {{f}_{v}}(x)\,{{u}_{v}}(t) + {{f}_{\eta }}(x)\,{{\eta }_{1}}(t)$(1.3)
${{\alpha }_{0}}Q({{x}_{0}},t) + {{\beta }_{0}}\frac{{\partial Q({{x}_{0}},t)}}{{\partial x}} = 0;\quad {{\alpha }_{1}}Q({{x}_{1}},t) + {{\beta }_{1}}\frac{{\partial Q({{x}_{1}},t)}}{{\partial x}} = {{u}_{s}}(t) + {{\eta }_{2}}(t);\quad 0 \leqslant t \leqslant t{\kern 1pt} *$Всюду далее исключается для простоты случай одновременного использования ${{u}_{v}}(t)$ и ${{u}_{s}}(t)$, полагая
Пусть необходимо обеспечить за фиксируемое априори конечное время t* заданную точность ε равномерного приближения конечного пространственного распределения управляемой величины $Q(x,t{\kern 1pt} *)$ к требуемому $Q{\kern 1pt} *{\kern 1pt} *(x) = Q{\kern 1pt} *{\kern 1pt} * = 0$, согласно соотношению
(1.6)
$\mathop {\max }\limits_{x \in [{{x}_{0}},{{x}_{1}}]} \left| {Q(x,t{\kern 1pt} *)} \right| \leqslant \varepsilon $,Пусть далее эффективность процесса управления объектом (1.1)–(1.6) оценивается квадратичным функционалом качества, определяемым для простоты и наглядности без потери общности основных результатов в следующей типичной для приложений частной форме:
(1.7)
$I(u,\eta ) = \int\limits_0^{t{\kern 1pt} *} {\int\limits_{{{x}_{0}}}^{{{x}_{1}}} {{{\rho }_{Q}}{{Q}^{2}}(x,t)} } \,dx\,dt + \int\limits_0^{t{\kern 1pt} *} {({{u}^{2}}(t,\,\eta (t)) - {{\rho }_{\eta }}{{\eta }^{2}}(t))} \,dt \to \mathop {\min }\limits_u $Применение к уравнениям объекта (1.1)–(1.3) конечного интегрального преобразования по пространственному аргументу с ядром, равным его собственным функциям ${{\varphi }_{n}}({{\mu }_{n}},x),$ $n = 1,2,...$, где $\mu _{n}^{2}$ – собственные числа, приводит к представлению СРП бесконечной системой обыкновенных дифференциальных уравнений первого порядка для временных мод ${{\bar {Q}}_{n}}({{\mu }_{n}},t)$ разложения $Q(x,t)$ в сходящийся в среднем ряд по ${{\varphi }_{n}}({{\mu }_{n}},x)$ [16]:
(1.8)
$\begin{gathered} \frac{{d{{{\bar {Q}}}_{n}}({{\mu }_{n}},t)}}{{dt}} = - \mu _{n}^{2}{{{\bar {Q}}}_{n}}({{\mu }_{n}},t) + {{k}_{{vn}}}{{u}_{v}}(t) + {{k}_{{1n}}}{{\eta }_{1}}(t) + {{k}_{{sn}}}{{u}_{s}}(t) + {{k}_{{2n}}}{{\eta }_{2}}(t); \\ {{{\bar {Q}}}_{n}}({{\mu }_{n}},0) = \bar {Q}_{{}}^{{(0)}}({{\mu }_{n}}),\quad n = 1,2,..., \\ \end{gathered} $(1.9)
$Q(x,t) = \sum\limits_{n = 1}^\infty {{{{\bar {Q}}}_{n}}({{\mu }_{n}},t){{\varphi }_{n}}({{\mu }_{n}},x)} .$Здесь ${{k}_{{vn}}},{{k}_{{1n}}},$ $\bar {Q}_{{}}^{{(0)}}({{\mu }_{n}})$ – моды конечных интегральных преобразований функций ${{f}_{v}}(x),\;{{f}_{\eta }}(x)$ и ${{Q}_{0}}(x)$ соответственно, ${{k}_{{sn}}},{{k}_{{2n}}}$ – известные постоянные коэффициенты [16].
Можно показать [17, 18], что в малостеснительных условиях выполнения усиленных [17, 18] условий Коши–Липшица система уравнений (1.8) имеет единственное решение при заданных воздействиях $u(t)$, $\eta (t),$ которое с любой требуемой точностью при необходимости аппроксимируется решением “укороченной” системы, образуемой достаточно большим конечным числом $N$ первых уравнений (1.8) при ${{\bar {Q}}_{n}}({{\mu }_{n}},t) = 0$ $\forall n > N$, т.е. оказывается допустимой конечномерная аппроксимация модели (1.8) при $n = \overline {1,N} ,$ $N < \infty $. Всюду далее на этом основании учитываются ${{N}_{1}}$ мод ${{\bar {Q}}_{n}},\,n = \overline {1,{{N}_{1}}} $ в (1.8), где ${{N}_{1}} = \infty $ или ${{N}_{1}} = N < \infty $ в зависимости от используемой схемы анализа и возможностей практической реализации исследуемых алгоритмов управления. Конкретный выбор числа N1 должен производиться при проектировании системы управления, исходя из практически требуемой точности описания модели объекта N1уравнениями (1.8).
Переход к описанию СРП в (1.8), (1.9) в терминах модальных переменных приводит в силу ортонормированности семейства собственных функций [16] к представлению критерия (1.7) в следующем виде:
(1.10)
${{I}_{1}}(u,\eta ) = \int\limits_0^{t{\kern 1pt} *} {\left[ {{{\rho }_{Q}}\sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}({{\mu }_{n}},t) + {{u}^{2}}(t,\eta (t)) - {{\rho }_{\eta }}{{\eta }^{2}}(t)} } \right]dt} \to \mathop {\min }\limits_u {\kern 1pt} {\kern 1pt} ,$(1.11)
$\mathop {\max }\limits_{x \in [{{x}_{0}},{{x}_{1}}]} \left| {\sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{{}}({{\mu }_{n}},t{\kern 1pt} *){{\varphi }_{n}}({{\mu }_{n}},x)} } \right| \leqslant \varepsilon {\kern 1pt} {\kern 1pt} .$Рассматриваемая задача АКОР сводится к определению алгоритма обратной связи $u(Q,\,t,\,\eta )$, обеспечивающего перевод не полностью определенного в условиях воздействия внешних возмущений бесконечномерного объекта (1.8), (1.9) в требуемое конечное состояние (1.11) при минимально возможном значении критерия оптимальности (1.10).
В типичных частных случаях внешнее возмущение η(t) в (1.5) определяется заданной кусочно-непрерывной функцией времени [3, 4].
2. Программное оптимальное управление при детерминированном возмущении. Структура оптимального управления. На сформулированную бесконечномерную задачу оптимизации распространяется принцип максимума Понтрягина [13, 19]. Базовое условие
(2.1)
$H\left( {\bar {Q}{\kern 1pt} {\text{*}}(t),u{\kern 1pt} {\text{*}}(t),\psi {\kern 1pt} {\text{*}}(t),\eta (t)} \right) = \mathop {\max }\limits_u H\left( {\bar {Q}{\kern 1pt} {\text{*}}(t),u(t),\psi {\kern 1pt} {\text{*}}(t),\eta (t)} \right),\quad t \in (0,t{\kern 1pt} {\text{*}})$(2.2)
$\begin{gathered} H(\bar {Q}(t),u(t),\psi (t),\eta (t)) = - {{\rho }_{Q}}\sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}({{\mu }_{n}},t)} - u_{{}}^{2}(t,\eta (t)) + {{\rho }_{\eta }}\eta _{{}}^{2}(t) + \\ \, + \sum\limits_{n = 1}^{{{N}_{1}}} {{{\psi }_{n}}(t)} ( - \mu _{n}^{2}{{{\bar {Q}}}_{n}}({{\mu }_{n}},t) + {{k}_{{{v}n}}}{{u}_{{v}}}(t) + {{k}_{{1n}}}{{\eta }_{1}}(t) + {{k}_{{sn}}}{{u}_{s}}(t) + {{k}_{{2n}}}{{\eta }_{2}}(t)), \\ \end{gathered} $(2.3)
$\frac{{d{{\psi }_{p}}}}{{dt}} = - \frac{{\partial H}}{{\partial {{{\bar {Q}}}_{p}}}} = 2{{\rho }_{Q}}\bar {Q}_{p}^{{}}({{\mu }_{p}},t) + \mu _{p}^{2}{{\psi }_{p}}(t),\quad p = \overline {1,{{N}_{1}}} ,$(2.4)
$u{\kern 1pt} {\text{*}}(t) = \frac{1}{2}\sum\limits_{n = 1}^{{{N}_{1}}} {{{k}_{n}}\psi _{n}^{*}(t)} .$Здесь
(2.5)
${{k}_{n}} = {{k}_{{{v}n}}},\quad {\text{если}}\quad u(t) = {{u}_{{v}}}(t),\quad {\text{или}}\quad {{k}_{n}} = {{k}_{{sn}}},\quad {\text{если}}\quad u(t) = {{u}_{s}}(t).$Краевая задача принципа максимума. Уравнения (1.8) с подстановкой управляющего воздействия в виде (2.4) образуют совместно с (2.3) линейную программно-управляемую систему, замыкаемую относительно неизвестных $\bar {Q}(t)$ и $\psi (t)$ требованиями (1.11) к конечному состоянию объекта:
(2.6)
$\begin{gathered} \frac{{d{{\psi }_{p}}}}{{dt}} = 2{{\rho }_{Q}}{{{\bar {Q}}}_{p}} + \mu _{p}^{2}{{\psi }_{p}},\quad p = \overline {1,{{N}_{1}}} ; \\ \frac{{d{{{\bar {Q}}}_{n}}}}{{dt}} = - \mu _{n}^{2}{{{\bar {Q}}}_{n}} + \frac{1}{2}{{k}_{n}}\sum\limits_{i = 1}^{{{N}_{1}}} {{{k}_{i}}{{\psi }_{i}} + {{{\tilde {k}}}_{n}}\eta (t),\quad {{{\bar {Q}}}_{n}}(0)} = \bar {Q}_{{}}^{{(0)}}({{\mu }_{n}}),\quad n = \overline {1,{{N}_{1}}} , \\ \end{gathered} $Решение этой системы может быть представлено в векторно-матричной форме [3, 4]:
(2.7)
$\left[ \begin{gathered} \psi (t) \hfill \\ \bar {Q}(t) \hfill \\ \end{gathered} \right] = {{e}^{{At}}}\left[ \begin{gathered} \psi (0) \hfill \\ \bar {Q}(0) \hfill \\ \end{gathered} \right] + \int\limits_0^t {{{e}^{{A(t - \tau )}}}C\eta (\tau )d\tau {\kern 1pt} {\kern 1pt} .} $Здесь
вектор-столбец коэффициентов ${{\tilde {k}}_{n}}$; А – матрица коэффициентов системы (2.6); ${{e}^{{At}}}$ – определяемая известными способами [3, 4, 20, 21] нормированная фундаментальная матрица размерностью $2{{N}_{1}} \times 2{{N}_{1}}$ (матричная экспонента), столбцами которой являются линейно-независимые решения однородной системы (2.6) при ${{\eta }_{1}} = {{\eta }_{2}} = 0$.
Матричная экспонента представляется в блочном виде
(2.8)
${{e}^{{At}}} = \left[ {\begin{array}{*{20}{c}} {{{A}_{{11}}}(t)}&{{{A}_{{12}}}(t)} \\ {{{A}_{{21}}}(t)}&{{{A}_{{22}}}(t)} \end{array}} \right]\,,$Параметризация управляющих воздействий. Согласно (2.7), $\psi (t)$, а, следовательно, и программное управление (2.4) определяются для каждой известной величины $\bar {Q}(0)$ с точностью до вектора $\psi (0)$ начальных значений сопряженных функций, выступающих, таким образом, в роли параметрического представления $u{\kern 1pt} {\text{*}}(t)$ [22, 23]. Однако для СРП такой подход оказывается неконструктивным, прежде всего, в силу бесконечной размерности этого вектора в (2.6) при ${{N}_{1}} = \infty $. В работе [15] применительно к требованиям (1.11), предъявляемым к $\bar {Q}{\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}})$, предложен конструктивный способ последовательной конечномерной параметризации управляющих воздействий (“$\psi $-параметризация”) на множестве М-мерных векторов ${{\psi }^{{(M)}}} = ({{\tilde {\psi }}_{i}}),$ $i = \overline {1,M} ;$ ${{\tilde {\psi }}_{i}} = {{\psi }_{i}}(t{\kern 1pt} *),$ $M < {{N}_{1}}$, конечных значений ${{\tilde {\psi }}_{i}}$ первых М сопряженных функций в (2.6) при равных нулю всех остальных значениях ${{\psi }_{i}}(t{\kern 1pt} *)$:
(2.9)
${{\psi }^{{(M)}}} = \left( {{{\psi }_{i}}(t{\kern 1pt} *)} \right) = ({{\tilde {\psi }}_{i}}),\quad i = \overline {1,M} ;\quad {{\psi }_{i}}(t{\kern 1pt} *) = 0,\quad {\text{если}}\quad i > M.$С возрастанием М обеспечивается попадание под действием параметризуемых на множестве параметров (2.9) управляющих воздействий вида (2.4) в сужающееся к началу координат в пространстве $({{\bar {Q}}_{n}})$ целевое множество, гарантируя выполнение условий (1.11) для достижимых значений $\varepsilon $ при некотором конечном значении $M \geqslant 1$ [15].
С целью определения в явной форме $\psi $-параметризованного управления найдем вектор ${{[{{\psi }^{{\text{T}}}}(0)\,\,{{\bar {Q}}^{{\text{T}}}}(0)]}^{{\text{T}}}}$ из (2.7) при $t = t{\kern 1pt} *$ и, подставляя результат опять в (2.7), получим решение системы (2.6) в форме его зависимости от конечного состояния ${{[{{\psi }^{{\text{T}}}}(t{\kern 1pt} *)\;{{\bar {Q}}^{{\text{T}}}}(t{\kern 1pt} *)]}^{{\text{T}}}}$:
(2.10)
$\left[ {\begin{array}{*{20}{c}} {\psi (t)} \\ {\bar {Q}(t)} \end{array}} \right] = {{e}^{{ - A(t{\kern 1pt} * - t)}}}\left[ {\begin{array}{*{20}{c}} {\psi (t{\kern 1pt} *)} \\ {\bar {Q}(t{\kern 1pt} *)} \end{array}} \right] - \int\limits_t^{t{\kern 1pt} *} {{{e}^{{ - A(\tau - t)}}}C\eta (\tau )\,d\tau {\kern 1pt} {\kern 1pt} } .$С учетом блочного представления (2.8) матричной экспоненты равенство (2.10) определяет векторы $\psi (t)$ и $\bar {Q}(t)$ в следующей форме:
(2.11)
$\psi (t) = {{\hat {A}}_{{11}}}(t{\kern 1pt} {\text{*}} - t)\psi (t{\kern 1pt} {\text{*}}) + {{\hat {A}}_{{12}}}(t{\kern 1pt} {\text{*}} - t)\bar {Q}(t{\kern 1pt} {\text{*}}) + {{\tilde {D}}_{{\psi \eta }}};$(2.12)
$\bar {Q}(t) = {{\hat {A}}_{{21}}}(t{\kern 1pt} {\text{*}} - t)\psi (t{\kern 1pt} {\text{*}}) + {{\hat {A}}_{{22}}}(t{\kern 1pt} {\text{*}} - t)\bar {Q}(t{\kern 1pt} {\text{*}}) + {{\tilde {D}}_{{Q\eta }}};$(2.13)
${{\tilde {D}}_{{\psi \eta }}} = - \int\limits_t^{t{\kern 1pt} *} {{{{\hat {A}}}_{{12}}}(\tau - t){{k}_{\eta }}\eta (\tau )} \,d\tau ;\quad {{\tilde {D}}_{{Q\eta }}} = - \int\limits_t^{t{\kern 1pt} *} {{{{\hat {A}}}_{{22}}}(\tau - t){{k}_{\eta }}\eta (\tau )} d\tau $После подстановки (2.8) в (2.7) будем иметь, согласно (2.7), при $t = t{\kern 1pt} *$:
(2.14)
$\psi (t{\kern 1pt} {\text{*}}) = {{A}_{{11}}}(t{\kern 1pt} {\text{*}})\psi (0) + {{A}_{{12}}}(t{\kern 1pt} {\text{*}})\bar {Q}(0) + D_{{\psi \eta }}^{{}};$(2.15)
$\bar {Q}(t{\kern 1pt} {\text{*}}) = {{A}_{{21}}}(t{\kern 1pt} {\text{*}})\psi (0) + {{A}_{{22}}}(t{\kern 1pt} {\text{*}})\bar {Q}(0) + D_{{Q\eta }}^{{}},$(2.16)
$\begin{gathered} {{D}_{{\psi \eta }}} = \int\limits_0^{t{\kern 1pt} *} {{{A}_{{12}}}(t{\kern 1pt} {\text{*}} - \tau ){{k}_{\eta }}} \eta (\tau )d\tau \,; \\ {{D}_{{Q\eta }}} = \int\limits_0^{t{\kern 1pt} *} {{{A}_{{22}}}(t{\kern 1pt} {\text{*}} - \tau ){{k}_{\eta }}} \eta (\tau )d\tau . \\ \end{gathered} $Определяя $\psi (0)$ из (2.14) и подставляя результат в (2.15), получим следующее выражение для $\bar {Q}(t{\kern 1pt} *)$ в форме линейной функции начального состояния объекта $\bar {Q}(0)$ и априори неизвестных конечных значений $\psi (t{\kern 1pt} *)$ сопряженных переменных:
(2.17)
$\bar {Q}(t{\kern 1pt} {\text{*}}) = B(t{\kern 1pt} {\text{*}})\,\psi (t{\kern 1pt} {\text{*}}) + {{B}_{1}}(t{\kern 1pt} {\text{*}})\bar {Q}(0) + {{D}_{\eta }}(t{\kern 1pt} {\text{*}}),$(2.18)
$\begin{gathered} B(t{\kern 1pt} {\text{*}}) = {{A}_{{21}}}(t{\kern 1pt} {\text{*}})A_{{11}}^{{ - 1}}(t{\kern 1pt} *); \\ {{B}_{1}}(t{\kern 1pt} {\text{*}}) = {{A}_{{22}}}(t{\kern 1pt} {\text{*}}) - {{A}_{{21}}}(t{\kern 1pt} {\text{*}})A_{{11}}^{{ - 1}}(t{\kern 1pt} *){{A}_{{12}}}(t{\kern 1pt} *); \\ {{D}_{\eta }}(t{\kern 1pt} {\text{*}}) = {{D}_{{Q\eta }}} - {{A}_{{21}}}(t{\kern 1pt} {\text{*}})A_{{11}}^{{ - 1}}(t{\kern 1pt} *){{D}_{{\psi \eta }}}. \\ \end{gathered} $При описании $\bar {Q}(t{\kern 1pt} *)$ в (2.11), (2.12) соотношением (2.17) получим, согласно (2.11), следующее выражение для вектора ψ*(t) в оптимальном процессе в зависимости от его параметризуемой конечной величины ψ*(t*) в (2.9) и начального состояния объекта $\bar {Q}(0){\text{:}}$
(2.19)
$\psi {\kern 1pt} {\text{*}}(t) = [{{\hat {A}}_{{11}}}(t{\kern 1pt} {\text{*}} - t) + {{\hat {A}}_{{12}}}(t{\kern 1pt} {\text{*}} - t)B(t{\kern 1pt} {\text{*}})]\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}) + {{\hat {A}}_{{12}}}(t{\kern 1pt} {\text{*}} - t){{B}_{1}}(t{\kern 1pt} {\text{*}})\bar {Q}(0) + {{\hat {A}}_{{12}}}(t{\kern 1pt} {\text{*}} - t){{D}_{\eta }}(t{\kern 1pt} {\text{*}}) + {{\tilde {D}}_{{\psi \eta }}}.$Искомое программное управление (2.4)
(2.20)
$u{\kern 1pt} *(t) = \frac{1}{2}\sum\limits_{n = 1}^{{{N}_{1}}} {{{k}_{n}}\psi _{n}^{*}(t)} = \frac{1}{2}K\psi {\kern 1pt} {\text{*(}}t);\quad K = ({{k}_{n}}),\quad \psi {\kern 1pt} {\text{*}}(t) = (\psi _{n}^{*}(t)),$Редукция к задаче полубесконечной оптимизации. Интегрирование уравнений системы (2.6) с ψ-параметризованным управляющим воздействием вида (2.9), (2.19), (2.20) позволяет получить при заданном детерминированном воздействии $\eta (t)$ зависимости $Q(x,{{\psi }^{{(M)}}})$ управляемой величины в конце процесса управления и критерия оптимальности ${{I}_{1}}({{\psi }^{{(M)}}})$ в (1.9), (1.10) для каждого значения $\bar {Q}(0)$ в форме явных функций только своих аргументов [15].
В результате осуществляется точная редукция исходной задачи оптимального управления к задаче полубесконечной оптимизации (ЗПО) [13–15]:
(2.21)
${{I}_{1}}({{\psi }^{{(M)}}}) \to \mathop {\min }\limits_{{{\psi }^{{(M)}}}} ;\quad \mathop {\max }\limits_{x \in [{{x}_{0}},{{x}_{1}}]} \left| {Q(x,{{\psi }^{{(M)}}})} \right| \leqslant \varepsilon $Как показано в [15], для заданной величины ε в (1.11) размерность М вектора ${{\psi }^{{(M)}}}$ однозначно определяется соотношением
(2.22)
$M = \upsilon \forall \varepsilon {\kern 1pt} :\;\varepsilon _{{\min }}^{{(\upsilon )}} \leqslant \varepsilon < \varepsilon _{{\min }}^{{(\upsilon - 1)}},$(2.23)
$\varepsilon _{{\min }}^{{(\upsilon )}} = \mathop {\min }\limits_{{{\psi }^{{(\upsilon )}}}} \{ \mathop {\max }\limits_{x \in [{{x}_{0}},{{x}_{1}}]} {\text{|}}Q(x,{{\psi }^{{(\upsilon )}}}{\text{|}}\} .$Значения $\varepsilon _{{\min }}^{{(\upsilon )}}$ образуют, как правило, убывающую цепочку неравенств с возрастанием $\upsilon $, и задача (2.21) оказывается разрешимой, если $\varepsilon \geqslant {{\varepsilon }_{{\inf }}}$. Здесь точная нижняя грань ${{\varepsilon }_{{\inf }}}$ достижимых значений $\varepsilon $ оказывается равной минимаксу $\varepsilon _{{\min }}^{{(\rho )}}$, где $\rho = \infty $ при ${{\varepsilon }_{{\inf }}} = 0$ и $\rho < \infty $ при ${{\varepsilon }_{{\inf }}} > 0$ соответственно для управляемых и неуправляемых относительно $Q{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(x) \equiv 0$ объектов [13].
Решение задачи полубесконечной оптимизации. Решение ЗПО (2.21)–(2.23) относительно вектора параметров ${{\psi }^{{(M)}}}$, а также априори неизвестной величины минимакса $\varepsilon _{{\min }}^{{(M)}}$ в (2.22) в случае, когда $\varepsilon = \varepsilon _{{\min }}^{{(M)}}$, может быть получено в условиях малостеснительных ограничений альтернансным методом [13, 14]. Метод базируется на специальных альтернансных свойствах искомого значения $\psi _{*}^{{(M)}} = (\tilde {\psi }_{i}^{*}),$ $i = \overline {1,M} ,$ являющихся аналогом условий экстремума в теории нелинейных чебышевских приближений, и дополнительной информации о форме кривой пространственного распределения результирующего состояния $Q(x,\psi _{*}^{{(M)}})$ управляемой величины, диктуемой закономерностями предметной области. Согласно альтернансным свойствам, равные допустимой величине ε одинаковые значения максимальных отклонений $\mathop {\max }\limits_{x \in [{{x}_{0}},{{x}_{1}}]} {\text{|}}Q(x,\psi _{*}^{{(M)}}){\text{|}}$ достигаются в некоторых точках $x_{j}^{0},\;j = \overline {1,R} ,$ на отрезке $[{{x}_{0}},{{x}_{1}}]$. Общее число R этих точек, где R = M при заданном ε: $\varepsilon _{{\min }}^{{(M)}} < \varepsilon < \varepsilon _{{\min }}^{{(M - 1)}}$ и $R = M + 1,$ если $\varepsilon = \,\varepsilon _{{\min }}^{{(M)}}$, равно числу искомых неизвестных в ЗПО (2.21)–(2.23), порождая тем самым замкнутую относительно этих неизвестных систему соотношений
При наличии дополнительной информации из предметной области о форме кривой $Q(x,\psi _{*}^{{(M)}})$ на отрезке $[{{x}_{0}},{{x}_{1}}] \mathrel\backepsilon x$, позволяющей при известной функции $\eta (t)$ идентифицировать координаты $x_{j}^{0}$ и знаки $Q(x_{j}^{0},\psi _{*}^{{(M)}})$, равенства (2.24), дополненные условиями существования экстремума функции $Q(x,\psi _{*}^{{(M)}})$ в точках $x_{{{{j}_{g}}}}^{0} \in \operatorname{int} [{{x}_{0}},{{x}_{1}}]$, $g = \overline {1,{{R}_{1}}} ,$ где ${{R}_{1}} \leqslant R$ и $x_{{{{j}_{g}}}}^{0} \in \{ x_{j}^{0}\} $, переводятся в систему уравнений
(2.25)
$\begin{gathered} Q(x_{j}^{0},\psi _{*}^{{(M)}}) = \pm \varepsilon ,\quad j = \overline {1,R} ; \\ \frac{\partial }{{\partial x}}Q(x_{{{{j}_{g}}}}^{0},\psi _{*}^{{(M)}}) = 0,\quad g = \overline {1,{{R}_{1}}} , \\ \end{gathered} $Пространственное распределение управляемой величины $Q(x,\psi _{*}^{{(M)}})$ в конце оптимального процесса описывается рядом (1.9) с вектором модальных переменных $\bar {Q}{\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}})$, и, следовательно, система равенств (2.25) приводится к следующему виду:
(2.26)
$\Phi \bar {Q}{\kern 1pt} *(t{\kern 1pt} *) = \bar {\varepsilon },\quad \Phi = [{{\varphi }_{n}}({{\mu }_{n}},x_{j}^{0})],$(2.27)
${{\Phi }_{1}}\bar {Q}(t{\kern 1pt} *) = 0;\quad {{\Phi }_{1}} = \left[ {\frac{d}{{dx}}{{\varphi }_{n}}({{\mu }_{n}},x_{{{{j}_{g}}}}^{0})} \right],$Подстановка (2.17) в (2.26) при $\psi (t{\kern 1pt} {\text{*}})$ = ψ*(t*) приводит к линейной системе R уравнений
(2.28)
$\Phi \left[ {B(t{\kern 1pt} *)\psi {\kern 1pt} *(t{\kern 1pt} *) + {{B}_{1}}(t{\kern 1pt} *)\bar {Q}(0) + {{D}_{\eta }}(t{\kern 1pt} *)} \right] = \bar {\varepsilon }$(2.29)
$\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}) = {{\left[ {\Phi B(t{\kern 1pt} *)} \right]}^{{ - 1}}}(\bar {\varepsilon } - \Phi {{B}_{1}}(t{\kern 1pt} {\text{*}})\bar {Q}(0) - \Phi {{D}_{\eta }}(t{\kern 1pt} {\text{*}})).$Здесь значения $x_{j}^{0}$ в элементах матрицы Ф должны быть определены дополнением (2.29) системой уравнений (2.27) с подстановкой $\bar {Q}{\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}})$ в форме (2.17). В итоге выражения (2.19), (2.20) и (2.29) полностью определяют искомый алгоритм оптимального программного управления.
Об учете ограничений на управляющие воздействия. Предлагаемый способ расчета программного оптимального управления соответствует традиционному методу исследования задачи АКОР в открытой области изменения u(t), позволяющему, во-первых, определить минимально достижимые значения квадратичного функционала качества и, во-вторых, установить по полученным результатам предельные значения u(t), необходимые для реализации максимального эффекта по величине ${{I}_{1}}$ в (1.10). Тем не менее существенный интерес представляют задачи АКОР с учетом априори заданных ограничений
с известными граничными значениями ${{u}_{{\min }}},\,{{u}_{{\max }}} = {\text{const}}$, если эти ограничения нарушаются на протяжении оптимального процесса с линейным управлением вида (2.4). Равенства могут достигаться в различные моменты времени на протяжении оптимального процесса, образуя в общем случае многочисленные возможные варианты компоновки управляющих воздействий $\tilde {u}{\kern 1pt} *(t)$ из различных участков в соответствии с (2.4), (2.31).В типичном частном случае ограничения на $\tilde {u}{\kern 1pt} {\text{*}}(t)$ достигаются только на начальной стадии процесса управления, на протяжении которой $\tilde {u}{\kern 1pt} {\text{*}}(t) = {{u}_{{\max }}},$ $t \in [0,{{t}_{1}}],$ ${{t}_{1}} < t{\kern 1pt} *$, где момент t1 определяется по найденному линейному алгоритму u*(t) как корень уравнения $u{\kern 1pt} {\text{*}}({{t}_{1}}) = {{u}_{{\max }}}$. В такой ситуации состояние объекта $\bar {Q}({{t}_{1}})$, найденное интегрированием уравнений модели (1.8) с управлением $u(t) = {{u}_{{\max }}},\,t \in [0,\,{{t}_{1}}]$, можно рассматривать в роли начального $\bar {Q}(0)$ на последующем временном интервале $[{{t}_{1}},t{\text{*}}]$, где программное управление вида (2.4) определяется по описанной выше схеме.
Аналогичным образом может быть найдено программное управление и при других вариантах его построения с учетом ограничений в (2.30).
3. Синтез оптимальной системы управления. Рассмотрим далее задачу синтеза в условиях линейного алгоритма (2.4) оптимального программного управления. Решение этой задачи построения оптимального регулятора $u{\kern 1pt} {\text{*}}(Q,t)$ существенно зависит от характера информации о внешнем возмущении $\eta (t)$ в уравнениях моделей объекта (1.1)–(1.3).
3.1. Синтез оптимального регулятора при заданном внешнем возмущении. Пусть $\eta (t)$ в (1.5), (1.8) – известная функция времени. Определим конечное состояние модели (2.6) из уравнения (2.10):
(3.1)
$\left[ {\begin{array}{*{20}{c}} {\psi (t{\kern 1pt} {\text{*}})} \\ {\bar {Q}(t{\kern 1pt} {\text{*}})} \end{array}} \right] = {{e}^{{A(t{\kern 1pt} * - t)}}}\left[ {\begin{array}{*{20}{c}} {\psi (t)} \\ {\bar {Q}(t)} \end{array}} \right] + \int\limits_t^{t{\kern 1pt} *} {{{e}^{{A(t{\kern 1pt} * - \tau )}}}C\eta (\tau )\,d\tau {\kern 1pt} {\kern 1pt} } ,$(3.2)
$\psi (t{\kern 1pt} *) = {{A}_{{11}}}(t{\kern 1pt} * - \;t)\psi (t) + {{A}_{{12}}}(t{\kern 1pt} * - \;t)\bar {Q}(t) + {{\tilde {\tilde {D}}}_{{\psi \eta }}};$(3.3)
$\bar {Q}(t{\kern 1pt} *) = {{A}_{{21}}}(t{\kern 1pt} * - \;t)\psi (t) + {{A}_{{22}}}(t{\kern 1pt} * - \;t)\bar {Q}(t) + {{\tilde {\tilde {D}}}_{{Q\eta }}},$(3.4)
${{\tilde {\tilde {D}}}_{{\psi \eta }}} = \int\limits_t^{t{\kern 1pt} *} {{{A}_{{12}}}(t{\kern 1pt} * - \;\tau ){{k}_{\eta }}} \eta (\tau )d\tau ;\quad {{\tilde {\tilde {D}}}_{{Q\eta }}} = \int\limits_t^{t{\kern 1pt} *} {{{A}_{{22}}}(t{\kern 1pt} * - \;\tau ){{k}_{\eta }}} \eta (\tau )d\tau {\kern 1pt} {\kern 1pt} .$В оптимальном процессе $(\bar {Q}{\kern 1pt} {\text{*}}(t),\psi {\kern 1pt} {\text{*}}(t))$ соотношения (3.2), (3.3) принимают следующий вид:
(3.5)
$\psi {\kern 1pt} *(t{\kern 1pt} *) = {{A}_{{11}}}(t{\kern 1pt} * - \;t)\psi {\kern 1pt} *(t) + {{A}_{{12}}}(t{\kern 1pt} * - \;t)\bar {Q}{\kern 1pt} *t) + {{\tilde {\tilde {D}}}_{{\psi \eta }}};$(3.6)
$\bar {Q}{\kern 1pt} *(t{\kern 1pt} *) = {{A}_{{21}}}(t{\kern 1pt} * - \;t)\psi {\kern 1pt} *(t) + {{A}_{{22}}}(t{\kern 1pt} * - \;t)\bar {Q}{\kern 1pt} *(t) + {{\tilde {\tilde {D}}}_{{Q\eta }}},$После умножения слева равенств (3.5) и (3.6) соответственно на известные в соответствии с (2.17), (2.29) ${{N}_{1}} \times {{N}_{1}}$-матрицы ${\text{diag}}\,[\bar {Q}_{j}^{*}(t{\kern 1pt} *)]$, $\bar {Q}{\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}) = (\bar {Q}_{j}^{*}(t{\kern 1pt} {\text{*}}))$, $j = \overline {1,{{N}_{1}}} $ и ${\text{diag}}\,[\psi _{j}^{*}(t{\kern 1pt} *)]$, ψ*(t*) = = $(\psi _{j}^{*}(t{\kern 1pt} *))$, $j = \overline {1,{{N}_{1}}} $, левые части соотношений (3.5) и (3.6) становятся одинаковыми. Последующее вычитание этих уравнений приводит к следующему результату:
(3.7)
$\begin{gathered} \psi {\kern 1pt} {\text{*}}(t,\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}(0),\bar {Q}(t)) = {{T}_{1}}(t,t{\kern 1pt} {\text{*}},\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}{\kern 1pt} {\text{*}}t{\kern 1pt} {\text{*}}),\bar {Q}(0)){{T}_{2}}(t,t{\kern 1pt} {\text{*}},\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}{\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}(0))\bar {Q}(t) + \\ \, + {{T}_{1}}(t,t{\kern 1pt} {\text{*}},\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}{\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}(0)){{D}_{\Sigma }}(t,t{\kern 1pt} {\text{*}},\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}{\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}),\bar {Q}(0),\eta ); \\ \end{gathered} $(3.8)
${{T}_{1}} = {{\left[ {{{W}_{1}}{{A}_{{11}}}(t{\kern 1pt} * - \;t) - {{W}_{2}}{{A}_{{21}}}(t{\kern 1pt} * - \;t)} \right]}^{{ - 1}}};$(3.9)
${{T}_{2}} = \left[ {{{W}_{2}}{{A}_{{22}}}(t{\kern 1pt} * - \;t) - {{W}_{1}}{{A}_{{12}}}(t{\kern 1pt} * - \;t)} \right];$(3.10)
${{D}_{\Sigma }} = W_{2}^{{}}{{\tilde {\tilde {D}}}_{{Q\eta }}} - {{W}_{1}}{{\tilde {\tilde {D}}}_{{\psi \eta }}};$(3.11)
${{W}_{1}} = {\text{diag}}[\bar {Q}_{j}^{*}(t{\kern 1pt} {\text{*}})];\quad {{W}_{2}} = {\text{diag}}[\psi _{j}^{*}(t{\kern 1pt} {\text{*}})];\quad \bar {Q}_{j}^{*}(t{\kern 1pt} {\text{*}}) = {{(B(t{\kern 1pt} {\text{*}})\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}) + {{B}_{1}}(t{\kern 1pt} {\text{*}})\bar {Q}(0))}_{j}},\quad j = \overline {1,{{N}_{1}}} ,$Подстановка (3.7) в выражение (2.20) для программного управления приводит к линейному закону синтеза оптимального регулятора с нестационарными коэффициентами обратных связей в детерминированной системе управления с полным измерением состояния $\bar {Q}(t)$:
(3.12)
$u{\kern 1pt} {\text{*}}(\bar {Q},t) = \frac{1}{2}K({{T}_{1}}{{T}_{2}}\bar {Q}(t) + {{T}_{1}}{{D}_{\Sigma }}).$Здесь матрицы ${{T}_{1}}$ и ${{T}_{2}}$ представляются, согласно (3.8)–(3.11), известными функциями времени с фиксируемыми на протяжении процесса управления значениями $\bar {Q}(0)$, которые определяются по результатам наблюдения $\bar {Q}(t)$ в момент $t = 0$.
Переход в (3.12) от $\bar {Q}(t)$ к измеряемому выходу объекта ${{Q}_{u}}({{x}_{u}},t) = (Q({{x}_{{uj}}},t))$ в $r$ точках xuj ∈ $[{{x}_{0}},{{x}_{1}}],$ $j = \overline {1,r} $, определяется, согласно (1.9), векторно-матричным уравнением наблюдения
(3.13)
$Q(x_{u}^{{}},t) = \Phi _{u}^{{}}\bar {Q}(t),\quad {{\Phi }_{u}} = \left[ {{{\varphi }_{n}}({{\mu }_{n}},{{x}_{{uj}}})} \right],\quad n = \overline {1,{{N}_{1}}} ;\quad j = \overline {1,r} .$В условиях $r < {{N}_{1}}$ неполного измерения состояния для восстановления вектора $\bar {Q}(t)$ по значениям $Q(x_{u}^{{}},\,t)$ требуется построение наблюдателя полного или пониженного порядка [21]. Если по условиям требуемой точности моделирования объекта (1.8) можно ограничиться учетом только М первых составляющих $\bar {Q}(t)$ с минимальным их числом М, требуемым для решения системы уравнений (2.28) относительно представляемого в форме (2.9) вектора $\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}})$, то $\bar {Q}(t)$ непосредственно определяется решением системы уравнений (3.13) при r = M, ${{N}_{1}} = N = M$:
Подстановка (3.14) в (3.12) приводит к линейному алгоритму детерминированного синтеза с обратными связями по измеряемому выходу объекта:
(3.15)
$u{\kern 1pt} {\text{*}}(Q_{u}^{{}},t) = \frac{1}{2}K{{T}_{1}}{{T}_{2}}\Phi _{u}^{{ - 1}}Q_{u}^{{}}(x_{u}^{{}},t) + K{{T}_{1}}{{D}_{\Sigma }}{\kern 1pt} {\kern 1pt} .$Аналитическое решение задачи синтеза с учетом ограничений на управляющие воздействия становится невозможным в силу нелинейности в таком случае П-системы принципа максимума. Широко распространенный способ определения $\tilde {u}{\kern 1pt} {\text{*}}(Q_{u}^{{}},t)$ в первом приближении заключается в дополнении алгоритма $u{\kern 1pt} {\text{*}}(Q_{u}^{{}},t)$ в (3.15) характеристикой усилительного звена с насыщением [1, 2, 4]:
Однако такой результат может не обеспечить требуемую точность ε приближения к заданному конечному состоянию объекта. Более точный результат может быть получен для известного варианта структуры программного управления $\tilde {u}{\kern 1pt} {\text{*}}(t)$ при законе регулирования $\tilde {u}{\kern 1pt} {\text{*}}(Q_{u}^{{}},t)$, компонуемом из участков (2.31) выхода $\tilde {u}{\kern 1pt} {\text{*}}(t)$ на ограничения и линейных алгоритмов обратной связи в форме (3.15) на остальных интервалах изменения $\tilde {u}{\kern 1pt} {\text{*}}(t)$ вида (2.4).
3.2. Синтез оптимального регулятора в условиях неопределенности множественных внешних возмущений. Антагонистические алгоритмы программного управления. Сложная задача синтеза в условиях воздействия множественных возмущений может быть рассмотрена в игровой постановке с антагонистическими программными управлениями $u(t)$ и $\eta (t)$ в форме линейной дифференциальной игры с объектом управления (1.8) и критерием оптимальности I1 в (1.10) [7, 24–26]. При этом оптимальное управление $u{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ и наиболее “неблагоприятное” возмущение $\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ находятся, согласно стратегии получения наилучшего гарантированного результата:
(3.16)
$u{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t) = arg\mathop {\min }\limits_u [\mathop {\max }\limits_\eta {{I}_{1}}(u,\eta )];\quad \eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t) = arg\mathop {\max }\limits_\eta [\mathop {\min }\limits_u {{I}_{1}}(u,\eta )],$При аддитивном характере зависимости подынтегральной функции критерия (1.10) от антагонистических управлений $u(t)$ и $\eta (t)$ их оптимальные значения $u{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ и $\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ в (3.16) могут быть найдены из условия существования седловой точки игры [24–26]:
(3.17)
${{I}_{1}}\left( {u{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t),\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)} \right) = \mathop {\min }\limits_u [\mathop {\max }\limits_\eta {{I}_{1}}\left( {u(t),\eta (t)} \right)] = \mathop {\max }\limits_\eta [\mathop {\min }\limits_u {{I}_{1}}\left( {u(t),\eta (t)} \right)]$(3.18)
$\mathop {\max }\limits_u \mathop {\min }\limits_\eta H(\bar {Q}(t),\,\,u(t),\psi (t),\eta (t)) = H(\bar {Q}(t),u{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t),\psi (t),\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)) = \mathop {\min }\limits_\eta \mathop {\max }\limits_u H\left( {\bar {Q}(t),u(t),\psi (t),\eta (t)} \right).$Здесь функция $H\left( {\bar {Q}(t),u(t),\psi (t),\eta (t)} \right)$ и вектор $\psi (t)$ сопряженных переменных опять определяются, согласно (2.2), (2.3).
В таком случае $u{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ по-прежнему находится в виде (2.4), а $\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ представляется аналогично (2.4) в форме линейной зависимости от $\psi {\kern 1pt} *(t)$:
(3.19)
$\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t) = - \frac{1}{{2{{\rho }_{\eta }}}}\sum\limits_{n = 1}^{{{N}_{1}}} {{{{\tilde {k}}}_{n}}\psi _{n}^{*}(t)} .$Подстановка $u(t)$ и $\eta (t)$ в виде (2.4) и (3.19) в уравнения (1.8), (2.3) приводит аналогично (2.6) к программно-управляемой системе, замыкаемой относительно неизвестных $\bar {Q}(t)$ и $\psi (t)$ условиями трансверсальности:
в задаче со свободным правым концом траектории $\bar {Q}(t{\kern 1pt} {\text{*}})$ [4, 13]:(3.21)
$\begin{gathered} \frac{{d{{\psi }_{\rho }}}}{{dt}} = 2{{\rho }_{Q}}{{{\bar {Q}}}_{p}} + \mu _{p}^{2}{{\psi }_{p}};\quad \psi _{p}^{{}}(t{\kern 1pt} {\text{*}}) = 0,\quad p = \overline {1,{{N}_{1}}} ; \\ \frac{{d{{{\bar {Q}}}_{n}}}}{{dt}} = - \mu _{n}^{2}{{{\bar {Q}}}_{n}} + \frac{1}{2}{{k}_{n}}\sum\limits_{i = 1}^{{{N}_{1}}} {{{k}_{i}}{{\psi }_{i}}} - \frac{1}{{2{{\rho }_{\eta }}}}{{{\tilde {k}}}_{n}}\sum\limits_{j = 1}^{{{N}_{1}}} {{{{\tilde {k}}}_{j}}{{\psi }_{j}};} \quad {{{\bar {Q}}}_{n}}(0) = \bar {Q}_{{}}^{{(0)}}({{\mu }_{n}}),\quad n = \overline {1,{{N}_{1}}} . \\ \end{gathered} $Решение однородной системы уравнений (3.21) представляется подобно (2.8), (2.10) в векторно-матричной форме
(3.22)
$\left[ {\begin{array}{*{20}{c}} {\psi (t)} \\ {\bar {Q}(t)} \end{array}} \right] = {{e}^{{ - \tilde {A}(t{\kern 1pt} * - t)}}}\left[ {\begin{array}{*{20}{c}} {\psi (t{\kern 1pt} {\text{*}})} \\ {\bar {Q}(t{\kern 1pt} {\text{*}})} \end{array}} \right];\quad {{e}^{{ - \tilde {A}(t)}}} = \left[ {\begin{array}{*{20}{c}} {{{{\tilde {A}}}_{{11}}}(t)}&{{{{\tilde {A}}}_{{12}}}(t)} \\ {{{{\tilde {A}}}_{{21}}}(t)}&{{{{\tilde {A}}}_{{22}}}(t)} \end{array}} \right],$Отсюда аналогично (2.19) в условиях $\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}) = 0$ получаем следующее выражение для $\psi {\kern 1pt} {\text{*}}(t)$:
(3.23)
$\psi {\kern 1pt} {\text{*}}(t) = {{\tilde {A}}_{{12}}}(t{\kern 1pt} {\text{*}} - t){{\tilde {B}}_{1}}(t{\kern 1pt} {\text{*)}}\bar {Q}(0),$Подстановка (3.23) в (3.19) позволяет найти $\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ в виде явной зависимости от t:
(3.24)
$\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t) = - \frac{1}{{2{{\rho }_{\eta }}}}\tilde {K}{{\tilde {A}}_{{12}}}(t{\kern 1pt} {\text{*}} - t){{\tilde {B}}_{1}}(t{\kern 1pt} {\text{*}})\bar {Q}(0).$Редукция к задаче синтеза с заданным детерминированным возмущением. Задача синтеза при множественных возмущениях может быть сведена к рассмотренной в разд. 3.1 задаче конструирования оптимального регулятора при заданном детерминированном внешнем воздействии $\eta (t) = \eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ в (3.24). Действительно, при любом реализуемом возмущении $\eta _{{}}^{0}(t)$ будем иметь в соответствии с (3.16)–(3.18) в условиях существования седловой точки рассматриваемой дифференциальной игры
(3.25)
$\mathop {\min }\limits_{u \in \Omega } {{I}_{1}}(u,{{\eta }^{0}}) = {{I}_{1}}(u{\kern 1pt} {\text{*}}({{\eta }^{0}}),{{\eta }^{0}}) \leqslant \mathop {\min }\limits_{u \in \Omega } (\mathop {\max }\limits_\eta {{I}_{1}}(u,\eta )) = \mathop {\max }\limits_\eta (\mathop {\min }\limits_{u \in \Omega } {{I}_{1}}(u,\eta )) = {{I}_{1}}(u{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}},\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}).$Здесь
(3.26)
$\Omega = \{ u{\kern 1pt} :\;\mathop {\max }\limits_\eta \mathop {\max }\limits_{x \in [{{x}_{0}},{{x}_{1}}]} {\text{|}}Q(x,\psi _{*}^{{(M)}}(\eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}),\eta ){\text{|}} \leqslant {{\varepsilon }_{0}}\} ,$Как следует из (3.25), синтез оптимального управления $u{\kern 1pt} {\text{*}}(\bar {Q},t)$ при заданном детерминированном возмущении $\eta _{{}}^{0}(t) = \eta {\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(t)$ в условиях (3.26) отвечает верхней оценке достижимых значений минимизируемого критерия I1 на множестве допустимых возмущений в соответствии с требованиями стратегии управления по принципу наилучшего гарантированного результата.
4. Синтез оптимального регулятора для управления нестационарным процессом теплопроводности. В качестве примера, представляющего самостоятельный интерес, рассмотрим задачу аналитического конструирования оптимального регулятора для управления процессом нагрева неограниченной пластины.
Пусть температурное поле Q(x, t) пластины описывается линейным однородным уравнением теплопроводности вида (1.1)–(1.3) в относительных единицах [16, 27]:
(4.1)
$\frac{{\partial Q(x,t)}}{{\partial t}} = \frac{{{{\partial }^{2}}Q(x,t)}}{{\partial {{x}^{2}}}},\quad 0 < x < 1,\quad t \in [0,t{\kern 1pt} *]$(4.3)
$\frac{{\partial Q(0,t)}}{{\partial x}} = 0;\quad \frac{{\partial Q(1,t)}}{{\partial x}} = {{u}_{s}}(t) + {{\eta }_{2}}(t)$(4.4)
${{\eta }_{2}}(t) = {{k}_{0}}{{u}_{s}}(t),\quad {{k}_{0}} = {\text{const}},\quad \left| {{{k}_{0}}} \right| < 1$.Модальное описание объекта (4.1)–(4.3) сводится к бесконечной системе дифференциальных уравнений вида (1.8)–(1.9):
(4.5)
$\frac{{d{{{\bar {Q}}}_{n}}}}{{dt}} = - \mu _{n}^{2}{{\bar {Q}}_{n}} + {{k}_{{sn}}}(1 + {{k}_{0}}){{u}_{s}}(t),\quad {{\bar {Q}}_{n}}(0) = \bar {Q}_{{}}^{{(0)}}({{\mu }_{n}}),\quad n = 1,2,...,$(4.6)
$Q(x,t) = \sum\limits_{n = 1}^\infty {{{{\bar {Q}}}_{n}}({{\mu }_{n}},t){{\varphi }_{n}}({{\mu }_{n}},x)} ,$(4.7)
${{\mu }_{n}} = \pi (n - 1);\quad {{\varphi }_{n}}({{\mu }_{n}},x) = \frac{1}{{{{V}_{n}}}}\cos \left( {\pi (n - 1)x} \right);\quad V_{n}^{2} = \left\{ \begin{gathered} 1,\quad n = 1 \hfill \\ \frac{1}{2},\quad n > 1 \hfill \\ \end{gathered} \right.;\quad {{k}_{{sn}}} = \frac{{{{{( - 1)}}^{{n - 1}}}}}{{{{V}_{n}}}}.$Задача сводится к определению алгоритма обратной связи ${{u}_{s}}(Q,t)$, обеспечивающего перевод объекта (4.5), (4.6) за заданное время t* в требуемое конечное состояние $Q{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}}(x) = Q{\kern 1pt} {\text{*}}{\kern 1pt} {\text{*}} = 0$ с заданной точностью равномерного приближения $\varepsilon > 0$, согласно (1.11), при минимальном значении квадратичного критерия качества (1.10), где выберем ${{\rho }_{Q}} = 1$.
Оптимальное программное управление $(1 + {{k}_{0}})u_{s}^{*}(t)$ находится в форме (2.4) при ${{k}_{n}} = {{k}_{{sn}}}$, а П-система принципа максимума представляется в виде однородной системы уравнений (2.6), где в рассматриваемом примере следует принять
Вычисление матричной экспоненты. Примем далее для большей простоты и наглядности получаемых результатов ${{N}_{1}} = N = 2$, ограничиваясь учетом только двух модальных переменных в сумме (4.6). В таком случае матричная экспонента в (2.7) является нормированной фундаментальной 4 × 4-матрицей системы (2.6) следующего вида [3, 20, 21]:
Здесь $Z(t)$ – матрица линейно-независимых решений однородной системы уравнений (2.6) [3, 20, 21]:
(4.8)
$Z(t) = \left[ {\begin{array}{*{20}{c}} {\gamma _{1}^{{(1)}}{{e}^{{{{p}_{1}}t}}}}& \cdots &{\gamma _{1}^{{(4)}}{{e}^{{{{p}_{4}}t}}}} \\ \cdots & \cdots & \cdots \\ {\gamma _{4}^{{(1)}}{{e}^{{{{p}_{1}}t}}}}& \cdots &{\gamma _{4}^{{(4)}}{{e}^{{{{p}_{4}}t}}}} \end{array}} \right],$Матричная экспонента eAt представляется в блочной форме (2.8), где
(4.11)
$\begin{gathered} {{A}_{{11}}}(t) = \left[ {\begin{array}{*{20}{c}} {{{\psi }_{{11}}}(t)}&{{{\psi }_{{12}}}(t)} \\ {{{\psi }_{{21}}}(t)}&{{{\psi }_{{22}}}(t)} \end{array}} \right];\quad {{A}_{{12}}}(t) = \left[ {\begin{array}{*{20}{c}} {{{\psi }_{{13}}}(t)}&{{{\psi }_{{14}}}(t)} \\ {{{\psi }_{{23}}}(t)}&{{{\psi }_{{24}}}(t)} \end{array}} \right]; \\ {{A}_{{21}}}(t) = \left[ {\begin{array}{*{20}{c}} {{{{\bar {Q}}}_{{11}}}(t)}&{{{{\bar {Q}}}_{{12}}}(t)} \\ {{{{\bar {Q}}}_{{21}}}(t)}&{{{{\bar {Q}}}_{{22}}}(t)} \end{array}} \right];\quad {{A}_{{22}}}(t) = \left[ {\begin{array}{*{20}{c}} {{{{\bar {Q}}}_{{13}}}(t)}&{{{{\bar {Q}}}_{{14}}}(t)} \\ {{{{\bar {Q}}}_{{23}}}(t)}&{{{{\bar {Q}}}_{{24}}}(t)} \end{array}} \right]. \\ \end{gathered} $Здесь
(4.12)
${{\psi }_{{ks}}}(t) = \sum\limits_{i = 1}^4 {\gamma _{k}^{{(i)}}G_{i}^{{(s)}}{{e}^{{{{p}_{i}}t}}}} ;\quad \bar {Q}_{{ks}}^{{}}(t) = \sum\limits_{i = 1}^4 {} \gamma _{{k + 2}}^{{(i)}}G_{i}^{{(s)}}{{e}^{{{{p}_{i}}t}}};\quad k = 1,2;\quad s = \overline {1,4} ,$Характеристическое уравнение (4.9) приводится к равенству
(4.14)
$\det \left[ {\begin{array}{*{20}{c}} {\mu _{1}^{2} - p}&0&2&0 \\ 0&{\mu _{2}^{2} - p}&0&2 \\ {\frac{{k_{1}^{2}}}{2}}&{\frac{{{{k}_{1}}{{k}_{2}}}}{2}}&{ - (\mu _{1}^{2} + p)}&0 \\ {\frac{{{{k}_{1}}{{k}_{2}}}}{2}}&{\frac{{k_{2}^{2}}}{2}}&0&{ - (\mu _{2}^{2} + p)} \end{array}} \right] = 0,$(4.15)
$\begin{gathered} {{p}_{1}} = \sqrt {{{S}_{1}} - {{S}_{2}}} ;\quad {{p}_{2}} = \sqrt {{{S}_{1}} + {{S}_{2}}} ;\quad {{p}_{3}} = - \sqrt {{{S}_{1}} - {{S}_{2}}} ;\quad {{p}_{4}} = - \sqrt {{{S}_{1}} + {{S}_{2}}} ; \\ {{S}_{1}} = \frac{1}{2}(\mu _{2}^{4} + k_{1}^{2} + k_{2}^{2});\quad {{S}_{2}} = \frac{1}{2}\sqrt {{{{(\mu _{2}^{4} + k_{1}^{2} + k_{2}^{2})}}^{2}} - 4k_{1}^{2}\mu _{2}^{4}} . \\ \end{gathered} $Решение уравнения (4.10) приводит к значениям коэффициентов $\gamma _{j}^{{(i)}}$ в (4.12):
(4.16)
$\gamma _{1}^{{(i)}} = \frac{{2k_{1}^{{}}(\mu _{2}^{2} + {{p}_{i}})}}{{k_{2}^{{}}p_{i}^{2}}};\quad \gamma _{2}^{{(i)}} = \frac{2}{{p_{i}^{{}} - \mu _{2}^{2}}};\quad \gamma _{3}^{{(i)}} = \frac{{{{k}_{1}}(\mu _{2}^{2} + {{p}_{i}})}}{{{{k}_{2}}{{p}_{i}}}};\quad \gamma _{4}^{{(i)}} = 1.$Выражения (4.8)–(4.16) полностью определяют матричную экспоненту в (2.7), (2.8) применительно к рассматриваемому примеру.
Расчетная система уравнений альтернансного метода. Предлагаемый способ $\psi _{{}}^{{(N)}}$-параметризации управляющего воздействия приводит к представлению $\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} *)$ в форме (2.9).
Для типичного в приложениях случая $\varepsilon = \varepsilon _{{\min }}^{{(2)}}$ в (2.21) здесь следует принять M = 2, согласно (2.22), и тогда в соответствии с (2.9) $\psi {\kern 1pt} {\text{*}}(t{\kern 1pt} {\text{*}}) = (\tilde {\psi }_{i}^{*}),$ $i = 1,2;$ $\psi _{i}^{*}(t{\kern 1pt} {\text{*}}) = 0,$ $i > 2$, в системе уравнений (2.28). При подстановке $B(t{\kern 1pt} *)$ и ${{B}_{1}}(t{\kern 1pt} *)$ в форме (2.18), (4.13) система (2.28) после элементарных вычислений приводится к следующему виду:
(4.17)
$\Phi [F_{{}}^{{(1)}}(t{\kern 1pt} {\text{*}})\psi _{*}^{{(M)}} + F_{{}}^{{(2)}}(t{\kern 1pt} {\text{*}})\bar {Q}(0)] = \bar {\varepsilon },$(4.18)
${{F}^{{(1)}}}(t{\kern 1pt} {\text{*}}) = \left[ {\begin{array}{*{20}{c}} {F_{{11}}^{{(1)}}(t{\kern 1pt} {\text{*}})}&{F_{{12}}^{{(1)}}(t{\kern 1pt} {\text{*}})} \\ {F_{{21}}^{{(1)}}(t{\kern 1pt} {\text{*}})}&{F_{{22}}^{{(1)}}(t{\kern 1pt} {\text{*}})} \end{array}} \right];\quad {{F}^{{(2)}}}(t{\kern 1pt} {\text{*}}) = \left[ {\begin{array}{*{20}{c}} {F_{{11}}^{{(2)}}(t{\kern 1pt} {\text{*}})}&{F_{{12}}^{{(2)}}(t{\kern 1pt} {\text{*}})} \\ {F_{{21}}^{{(2)}}(t{\kern 1pt} {\text{*}})}&{F_{{22}}^{{(2)}}(t{\kern 1pt} {\text{*}})} \end{array}} \right]$При $\varepsilon = \varepsilon _{{\min }}^{{(2)}}$ в (2.21) следует принять $R = M + 1 = 3$ в (2.24). Тогда будем иметь матрицу Ф размерностью 3 × 2 в (2.26), подстановка которой в (4.17) позволяет получить, согласно (2.24), на основании (4.6) систему трех равенств:
(4.19)
$\begin{gathered} {\text{|}}Q(x_{j}^{0},\psi _{*}^{{(2)}}){\text{|}} = \left| {(F_{{11}}^{{(1)}}(t{\kern 1pt} {\text{*}})\varphi _{1}^{{}}(\mu _{1}^{{}},x_{j}^{0}) + F_{{21}}^{{(1)}}(t{\kern 1pt} {\text{*}})\varphi _{2}^{{}}(\mu _{2}^{{}},x_{j}^{0}))} \right.\tilde {\psi }_{1}^{*} + \\ + \;(F_{{12}}^{{(1)}}(t{\kern 1pt} {\text{*}})\varphi _{1}^{{}}(\mu _{1}^{{}},x_{j}^{0}) + F_{{22}}^{{(1)}}(t{\kern 1pt} {\text{*}})\varphi _{2}^{{}}(\mu _{2}^{{}},x_{j}^{0}))\tilde {\psi }_{2}^{*} + \\ \, + (F_{{11}}^{{(2)}}(t{\kern 1pt} {\text{*}}){{{\bar {Q}}}_{1}}(0) + F_{{12}}^{{(2)}}(t{\kern 1pt} {\text{*}})\bar {Q}_{2}^{{}}(0)){{\varphi }_{1}}(\mu _{1}^{{}},x_{j}^{0}) + \\ \left. { + \;(F_{{21}}^{{(2)}}(t{\kern 1pt} {\text{*}}){{{\bar {Q}}}_{1}}(0) + F_{{22}}^{{(2)}}(t{\kern 1pt} {\text{*}})\bar {Q}_{2}^{{}}(0)){{\varphi }_{2}}(\mu _{2}^{{}},x_{j}^{0})} \right| = \varepsilon _{{\min }}^{{(2)}},\quad j = \overline {1,3} \,, \\ \end{gathered} $Физические закономерности поведения нестационарных температурных полей в оптимальном процессе нагрева пластины и альтернансные свойства $Q(x,\psi _{*}^{{(2)}})$ определяют в рассматриваемом примере, подобно [13, 14], при $M = 2$, $\varepsilon = \varepsilon _{{\min }}^{{(2)}}$, ${{Q}_{0}} = \operatorname{const} $ в (4.2) форму кривой $Q(x,\psi _{*}^{{(2)}})$ результирующего распределения температуры по пространственной координате (рис. 1), что позволяет заведомо идентифицировать в (4.19) координаты точек $x_{1}^{0} = 0$, $x_{2}^{0} = x_{{{{j}_{g}}}}^{0} = x_{{{{j}_{1}}}}^{0} \in (0,1)$, $x_{3}^{0} = 1$ и знаки $Q(x_{j}^{0},\psi _{*}^{{(2)}})$. В результате равенства (4.19), дополняемые условиями существования экстремума (2.27) в одной точке $x_{2}^{0}$, редуцируются аналогично [13, 14] к замкнутой системе линейных по $\tilde {\psi }_{1}^{*},\;\tilde {\psi }_{2}^{*}$ уравнений вида (2.25):
(4.20)
$Q(0,\psi _{*}^{{(2)}}) = - \varepsilon _{{\min }}^{{(2)}};\quad Q(x_{2}^{0},\psi _{*}^{{(2)}}) = \varepsilon _{{\min }}^{{(2)}};\quad Q(1,\psi _{*}^{{(2)}}) = - \varepsilon _{{\min }}^{{(2)}};\quad \frac{{\partial Q(x_{2}^{0},\psi _{*}^{{(2)}})}}{{\partial x}} = 0,$
Аналитическое конструирование оптимального регулятора. Согласно (3.12), получаем линейный с нестационарными коэффициентами алгоритм оптимального управления с обратными связями по состоянию $\bar {Q}(t) = \left( {\bar {Q}_{i}^{{}}(t)} \right)$, $i = 1,2$:
(4.21)
${\text{(1}}\;{\text{ + }}\;{{k}_{{\text{0}}}}{\text{)}}u_{s}^{*}(\bar {Q},t) = \frac{1}{2}K{{T}_{1}}(t){{T}_{2}}(t)\bar {Q}(t),$(4.22)
$\begin{gathered} Q_{u}^{{}}({{x}_{{u1}}},t) = \bar {Q}_{1}^{{}}(t){{\varphi }_{1}}({{\mu }_{1}},{{x}_{{u1}}}) + \bar {Q}_{2}^{{}}(t){{\varphi }_{2}}({{\mu }_{2}},{{x}_{{u1}}}); \\ Q_{u}^{{}}({{x}_{{u2}}},t) = \bar {Q}_{1}^{{}}(t){{\varphi }_{1}}({{\mu }_{1}},{{x}_{{u2}}}) + \bar {Q}_{2}^{{}}(t){{\varphi }_{2}}({{\mu }_{2}},{{x}_{{u2}}}), \\ \end{gathered} $Подстановка этого решения в (4.21) определяет алгоритм синтеза оптимальной обратной связи по выходу объекта в форме (3.15):
(4.23)
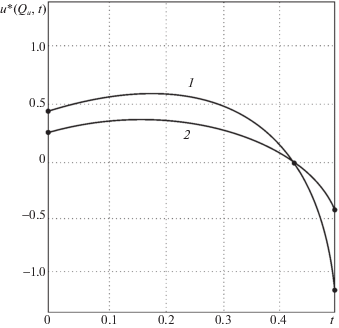
${\text{(1}}\;{\text{ + }}\;{{k}_{{\text{0}}}}{\text{)}}u_{s}^{*}({{Q}_{u}},t) = \frac{1}{2}K{{T}_{1}}(t){{T}_{2}}(t)\Phi _{u}^{{ - 1}}{{Q}_{u}}({{x}_{u}},t),$На рис. 1, 2 представлены некоторые расчетные результаты, полученные при $Q{\kern 1pt} *{\kern 1pt} * = 0,$ $t{\kern 1pt} * = 0.5,$ ${{k}_{0}}$ = 0.1 для двух различных значений ${{Q}_{0}}$ (кривые 1 – ${{Q}_{0}} = - 0.25;$ $\tilde {\psi }_{1}^{*} = 0.648;$ $\tilde {\psi }_{2}^{*} = - 1.161;$ $\varepsilon _{{\min }}^{{(2)}}$ = = 0.0043; кривые 2 – ${{Q}_{0}} = - 0.1;$ $\tilde {\psi }_{1}^{*} = 0.260;$ $\tilde {\psi }_{2}^{*} = - 0.464;$ $\varepsilon _{{\min }}^{{(2)}} = 0.0023$) при выборе двух измерителей выхода объекта в точках ${{x}_{{u1}}} = 0;$ ${{x}_{{u2}}} = 1$. На рис. 1 показаны распределения температуры по толщине пластины в конце оптимального процесса нагрева. Рисунок 2 иллюстрирует поведение в процессе нагрева оптимальных управляющих воздействий, изменяющихся во времени по алгоритму (4.23) в зависимости от текущих значений измеряемых сигналов обратной связи с нестационарными коэффициентами передачи. Как следует из приведенных данных, алгоритм (4.23) оптимального управления обеспечивает при различных начальных условиях заданную точность приближения к требуемому конечному состоянию объекта.
Заключение. Предлагаемый метод аналитического конструирования оптимальных регуляторов в линейно-квадратичной задаче управления системами с распределенными параметрами параболического типа разработан применительно к характерным для приложений оценкам целевых множеств конечных состояний объекта в равномерной метрике. Полученные уравнения регуляторов сводятся к линейным алгоритмам обратной связи с фиксируемыми предварительным расчетом нестационарными коэффициентами. Погрешности реализации предлагаемых алгоритмов обратной связи непосредственно по неполному измерению состояния системы определяются требованиями к точности описания модели объекта укороченной системой уравнений для модальных составляющих управляемой величины.
Список литературы
Летов А.М. Математическая теория процессов управления. М.: Наука, 1981.
Летов А.М. Динамика полета и управление. М.: Наука, 1969.
Ким Д.П. Теория автоматического управления. Т. 2. Многомерные, нелинейные, оптимальные и адаптивные системы. М.: Физматлит, 2007.
Теория автоматического управления / Под. ред. В.Б. Яковлева. М.: Высш. шк., 2003.
Рей У. Методы управления технологическими процессами. М.: Мир, 1983.
Поляк Б.Т., Хлебников М.В., Рапопорт Л.Б. Математическая теория автоматического управления. М.: ЛЕНАНД, 2019.
Афанасьев В.Н. Управление неопределенными динамическими объектами. М.: Физматлит, 2008.
Поляк Б.Е., Щербаков П.С. Робастная устойчивость и управление. М.: Наука, 2002.
Бутковский А.Г. Методы управления системами с распределенными параметрами. М.: Наука, 1975.
Сиразетдинов Т.К. Оптимизация систем с распределенными параметрами. М.: Наука, 1977.
Дегтярев Г.Л., Сиразетдинов Т.К. Синтез оптимального управления в системах с распределенными параметрами при неполном измерении состояния (обзор) // Изв. АН СССР. Техн. кибернетика. 1983. № 2. С. 123–136.
Дегтярев Г.Л., Сиразетдинов Т.К. Теоретические основы оптимального управления упругими космическими аппаратами. М.: Машиностроение, 1986.
Рапопорт Э.Я. Оптимальное управление системами с распределенными параметрами. М.: Высш. шк., 2009.
Рапопорт Э.Я. Альтернансный метод в прикладных задачах оптимизации. М.: Наука, 2000.
Плешивцева Ю.Э., Рапопорт Э.Я. Метод последовательной параметризации управляющих воздействий в краевых задачах оптимального управления системами с распределенными параметрами // Изв. РАН. ТиСУ. 2009. № 3. С. 22–33.
Рапопорт Э.Я. Структурное моделирование объектов и систем управления с распределенными параметрами. М.: Высш. шк., 2003.
Валеев Г.К., Жаутыков О.А. Бесконечные системы дифференциальных уравнений. Алма-Ата: Наука Казахской ССР, 1974.
Коваль В.А. Спектральный метод анализа и синтеза распределенных управляемых систем. Саратов: Саратовский гос. техн. ун-т, 1997.
Егоров Ю.В. Необходимые условия оптимальности в банаковом пространстве // Мат. сборник (новая серия). 1964. Т. 64 (106). № 1. С. 79–101.
Первозванский А.А. Курс теории автоматического управления. М.: Наука, 1986.
Андреев Ю.Н. Управление конечномерными линейными объектами. М.: Наука, 1976.
Федоренко Р.П. Приближенное решение задач оптимального управления. М.: Наука, 1978.
Васильев Ф.П. Методы оптимизации. М.: Факториал Пресс, 2002.
Гаврилов В.М. Оптимальные процессы в конфликтных ситуациях. М.: Сов. радио, 1969.
Красовский Н.Н., Субботин А.И. Позиционные дифференциальные игры. М.: Наука, 1974.
Пантелеев А.В., Бортаковский А.С. Теория управления в примерах и задачах. М.: Высш. шк., 2003.
Карташов Э.М. Аналитические методы в теории теплопроводности твердых тел. М.: Высш. шк., 2001.
Дополнительные материалы отсутствуют.
Инструменты
Известия РАН. Теория и системы управления