

Журнал вычислительной математики и математической физики, 2020, T. 60, № 5, стр. 784-801
О применении функций Гаусса в сочетании с теоремой Колмогорова для аппроксимации функций многих переменных
1 Нижегородский государственный университет
им. Н.И. Лобачевского
603950 Нижний Новгород, пр-т Гагарина, 23, Россия
2 Нижегородский государственный технический университет
им. Р.Е. Алексеева
603950 Нижний Новгород, ул. Минина, 24, Россия
* E-mail: chavnn@mail.ru
Поступила в редакцию 04.02.2019
После доработки 11.11.2019
Принята к публикации 14.01.2020
Аннотация
Исследуется специальный класс аппроксимаций непрерывных функций многих переменных на единичном координатном кубе. Основу построения этого класса составляет теорема Колмогорова о представлении функций указанного типа в виде конечной суперпозиции непрерывных функций одного переменного и их аппроксимация линейными комбинациями квадратичных экспонент (функций Гаусса). Эффективность такого представления основана на ранее доказанном автором утверждении о возможности сколь угодно точной аппроксимации на любом фиксированном конечном отрезке материнского вейвлета “мексиканская шляпа” линейной комбинацией двух функций Гаусса. Доказывается всюду плотность изучаемого класса аппроксимаций в классе непрерывных функций многих переменных на координатном кубе. Приводятся результаты численных экспериментов, подтверждающие эффективность аппроксимаций изучаемого класса на примере непрерывных функций двух переменных. Библ. 25. Фиг. 11. Табл. 3.
ВВЕДЕНИЕ
Проблема аппроксимации функций многих переменных имеет важное теоретическое и прикладное значение. Автора эта проблема интересует, главным образом, с точки зрения отыскания эффективных способов понижения размерности аппроксимирующих задач математического программирования, возникающих в результате параметрической дискретизации управляющей функции при численном решении распределенных задач оптимального управления.
При дискретизации задач оптимального управления традиционно используется кусочно-постоянная или кусочно-линейная аппроксимация управляющей функции, что даже в случае подвижной (управляемой) сетки приводит к большой размерности аппроксимирующей задачи математического программирования. В частности, в рамках техники параметризации управления (см. [1]–[6], а также указанную там библиографию) за счет предположения об однозначной разрешимости управляемой системы для каждого допустимого управления функционалы задачи сводятся к функциям конечного числа переменных – параметров аппроксимации управляющей функции, а исходная бесконечномерная задача оптимизации – к конечномерной, которая в этом случае и понимается как аппроксимирующая задача. При этом способы аппроксимации управления могут быть, вообще говоря, различными, но естественно стремиться к использованию наиболее экономных и эффективных способов. Иначе говоря, актуальным является поиск такого класса $\mathcal{E}$ функций, аппроксимирующих неизвестное управление, который, с одной стороны, обеспечивал бы высококачественную аппроксимацию для управляющих функций из достаточно обширного множества при использовании не слишком большого количества параметров аппроксимации, а с другой, позволял бы программировать те или иные полезные свойства управляющих функций (например, отсутствие быстрых осцилляций, разрушающих соответствующее техническое устройство, устойчивость приближенного решения оптимизационной задачи к искажению входных параметров – помехоустойчивость и т.п.). При использовании аппроксимации управления функциями из класса $\mathcal{E}$ значения искомого оптимального управления в контрольных точках нам, разумеется, не известны (и в этом состоит принципиальное отличие от обычной задачи аппроксимации – интерполяции). В этом случае неизвестные параметры аппроксимации определяются путем минимизации значения целевого функционала, вычисляемого на функциях из класса $\mathcal{E}$, если они являются допустимыми по смыслу задачи, либо на допустимых суперпозициях, содержащих функции класса $\mathcal{E}$ (например, в рамках метода синус-параметризации, используемого для учета ограничений на значения управления в виде условия принадлежности заданному параллелепипеду в пространстве ${{\mathbb{R}}^{s}}$). Указанное выше принципиальное отличие следует учитывать при сравнении различных подходов к аппроксимации. Действительно, в рамках обычной задачи аппроксимации (при заданном количестве параметров) на первый план выходят вопросы, связанные с минимизацией расхода времени и (прочих ресурсов) при отыскании неизвестных параметров аппроксимации. В рамках же численного решения задач оптимального управления главное – это повышение точности аппроксимации в отношении произвольной функции (неизвестного управления) при заданном количестве ее параметров, уменьшение количества параметров аппроксимации при сохранении приемлемой точности (по управлению или хотя бы по функционалу) и т.п. При этом точность аппроксимации понимается в абсолютном смысле (на всем множестве $\Pi \subset {{\mathbb{R}}^{n}}$ независимых переменных, либо на достаточно плотной сетке), а не в смысле (лишь) заданного количества узлов, соответствующего количеству параметров.
Указанная выше проблема аппроксимации тесным образом примыкает к проблеме точного представления функций многих переменных. А она, в свою очередь, имеет непосредственное отношение к 13-й проблеме Гильберта: возможно ли точное представление функции многих переменных в виде суперпозиции функций меньшего числа переменных? Для непрерывных функций, заданных на координатном кубе в ${{\mathbb{R}}^{n}}$, полное решение 13-й проблемы Гильберта было получено А.Н. Колмогоровым: оказалось, что любую такую функцию можно представить с помощью операций сложения, умножения и суперпозиции непрерывных функций одного переменного, см. [7].
Теорема А.Н. Колмогорова. При любом целом $n \geqslant 2$ существуют такие определенные на единичном отрезке ${{E}^{1}} = [0;1]$ непрерывные действительные функции ${{\psi }^{{p,q}}}(x)$, что каждая определенная на $n$-мерном единичном кубе ${{E}^{n}}$ непрерывная действительная функция $f({{x}_{1}}, \ldots ,{{x}_{n}})$ представима в виде
Впоследствии это утверждение неоднократно уточнялось и развивалось, см., например, [8]–[10] (там же см. дальнейшую библиографию).
Между тем необходимо отметить, что внутренние и внешние функции в представлении А.Н. Колмогорова не годятся для практического использования по следующим причинам: 1) алгоритм их построения очень сложен; 2) будучи непрерывными, они ни в одной точке не дифференцируемы; 3) они не допускают построения графика. Однако для практических целей точное представление не требуется, достаточно лишь указать способ их эффективной аппроксимации функциями некоторой простой, унифицированной структуры. Довольно естественно здесь возникает мысль использовать теорему Вейерштрасса об аппроксимации непрерывной функции многочленами (или одно из ее обобщений), см., например, [10]. Однако представление многочленами не всегда удобно ввиду того, что может понадобиться учет высоких степеней (что приведет к неустойчивости аппроксимации) и того, что отдельные слагаемые в таком представлении неравноценны. Поэтому актуальным является поиск иных способов.
Задача аппроксимации функций многих переменных часто возникает из потребностей компьютерной томографии, теории нейронных сетей и теории обучения и поэтому вообще достаточно актуальна. Подходы к аппроксимации функций многих переменных, идейно близкие теореме Колмогорова, условно можно разделить на следующие категории.
1. Нейросети. В [11] в качестве непосредственного следствия теоремы [8], уточняющей теорему Колмогорова, было доказано следующее. Пусть $\varphi :{{E}^{n}} \to {{\mathbb{R}}^{m}}$ – непрерывная вектор-функция, $\varphi (x) = y$. Тогда существуют число $\lambda \in \mathbb{R}$ и непрерывная монотонно возрастающая функция $\psi $ (не зависящие от $\varphi $, но зависящие от $n$) и рациональное число $\varepsilon \in (0;\delta ]$ при выбранном произвольно $\delta > 0$ такие, что
2. Многочлены. Как уже было сказано, в [10] предлагалось использовать многочлены для аппроксимации функций представления Колмогорова. Вопросы точного представления многочленов нескольких переменных суперпозициями многочленов одного переменного рассматривались, например, в [13].
3. Ридж-функции. Ридж-функцией называется функция вида $g(a \cdot x)$, где $g$ – функция одной переменной, $a = ({{a}_{1}}, \ldots ,{{a}_{n}}) \in {{\mathbb{R}}^{n}}$ – заданный вектор, называемый направлением ридж-функции, $x \in {{\mathbb{R}}^{n}}$, $a \cdot x$ – скалярное произведение. Разумеется, далеко не всякую функцию можно представить суммой ридж-функций с различными направлениями. Соответствующие условия представимости можно найти, например, в обзоре [14].
Стоит отметить, что все указанные в нашем кратком обзоре работы (там же см. дальнейшую библиографию), имеют чисто теоретический характер – результатов численных экспериментов в них нет. Отдельно укажем работу [15], где приводятся результаты численных экспериментов по восстановлению графика функции двух переменных с помощью обучаемой нейросети в виде линейного персептрона и упоминается о погрешности аппроксимации в отдельной точке не более 20%.
В [16] исследовались возможности аппроксимации функций одного переменного на конечном отрезке линейными комбинациями квадратичных экспонент (функций Гаусса) с варьируемыми параметрами; было доказано несколько утверждений о дискретно точном характере изучаемых аппроксимаций и приведены результаты численных экспериментов, подтверждающих справедливость этих утверждений и демонстрирующих высокое качество такого способа аппроксимации для гладких функций и достаточно хорошее – для непрерывных и кусочно непрерывных функций. Говоря более конкретно, для одномерного случая в качестве класса $\mathcal{E}$ в работе [16] было предложено использовать класс
(1)
$\begin{gathered} {{\mathcal{E}}_{\varepsilon }} = \left\{ {\Phi = \Phi _{\nu }^{\varepsilon }[\alpha ,\beta ,\gamma ] \in {{{\mathbf{C}}}^{\infty }}[a;b]\,|\,(\alpha ,\beta ,\gamma ) \in {{\mathbb{R}}^{{3\nu }}},\nu \in \mathbb{N}} \right\}, \\ \Phi _{\nu }^{\varepsilon }[\alpha ,\beta ,\gamma ](x) = \sum\limits_{j = 1}^\nu \,{{\alpha }_{j}}{{\varphi }_{j}}[{{\beta }_{j}},{{\gamma }_{j}}](x),\quad {{\varphi }_{j}}[{{\beta }_{j}},{{\gamma }_{j}}](x) = exp\left[ { - \tfrac{{{{{(x - {{\beta }_{j}})}}^{2}}}}{{\varepsilon + \gamma _{j}^{2}}}} \right], \\ \end{gathered} $В данной статье мы исследуем специальный класс аппроксимаций непрерывных функций многих переменных на единичном координатном кубе, основанный на аппроксимации внешних и внутренних функций в представлении, родственном представлению А.Н. Колмогорова, линейными комбинациями квадратичных экспонент. Эффективность такого способа базируется на ранее доказанном автором утверждении о возможности сколь угодно точной аппроксимации на любом фиксированном конечном отрезке материнского вейвлета “мексиканская шляпа” линейной комбинацией двух функций Гаусса. Доказывается всюду плотность изучаемого класса аппроксимаций в классе непрерывных функций многих переменных на координатном кубе. Отметим, что исходной целью автора было построение такого способа аппроксимации функций многих переменных, который при использовании сравнительно малого количества параметров позволял бы получать приближение хорошего качества для функций, устроенных “не слишком плохо” (то есть без большого количества, но в том числе и при наличии умеренного количества резких осцилляций, импульсоподобных всплесков и прочих типов “хаотизации” графика). Приводятся результаты численных экспериментов, подтверждающие эффективность аппроксимаций изучаемого класса в указанном смысле на примере непрерывных функций двух переменных.
Сделаем краткий обзор о применении квадратичных экспонент для аппроксимации функций одного переменного (в частности, непрерывных, гладких, многочленов и т.д.). Интерполяция функциями Гаусса (их еще иногда называют ядрами Гаусса – Gaussian kernels) непрерывных функций рассматривалась, главным образом, на дискретной сетке, как правило, с равномерным шагом на всей числовой оси, либо на конечном множестве отрезка числовой оси, см., например, [18]. Соответствующие алгоритмы аппроксимации иногда называют сеточными (grid). См., например, [19]. Исследовались также и многомерные аналоги, см., например, [20]. В основном, внимание исследователей концентрировалось на оценке погрешности аппроксимаций [21], [22]. Эффективность сеточных алгоритмов аппроксимации функциями Гаусса обосновывалась, например, в [23]. Помимо простой, равномерной сетки, используются также и более сложные конструкции типа многоуровневых сеток, см., например, [24]. Параметрами аппроксимации выступают обычно весовые коэффициенты функций Гаусса в соответствующих линейных комбинациях. Укажем также работу [20], где исследовался вопрос о наилучшем выборе параметров формы.
1. ОСНОВНАЯ ТЕОРЕМА
Далее мы используем модификацию теоремы А.Н. Колмогорова в стиле [8], [9]. А именно, результаты работы [9, разд. “Введение”, “Построение внутренних функций”], опирающейся в свою очередь на [8], можно суммировать в следующем утверждении.
Лемма 1.1. При произвольно заданных числах – натуральном $n \geqslant 2$, алгебраическом $\lambda > 0$ степени $\deg \lambda \geqslant n$, натуральном $\gamma \geqslant 2(n + 1)$ и $\sigma = \tfrac{1}{{\gamma - 1}}$ существует действительная непрерывная монотонно возрастающая функция одного переменного $\Psi (y)$, $y \geqslant 0$, такая, что каждая определенная на $n$-мерном единичном кубе ${{E}^{n}}$ непрерывная действительная функция $f({{x}_{1}}, \ldots ,{{x}_{n}})$ представима в виде
Отметим, что способ построения функции $\Psi $, описанный в [9], сложный и многоэтапный, причем сама функция представляется в виде бесконечного ряда. Поэтому его практическое использование затруднительно. Кроме того, функция $\Psi $ определяется неоднозначно.
Определим класс линейных комбинаций функций Гаусса:
Определим класс аппроксимаций $\mathcal{E}$ как множество
Теорема 1.1. Класс $\Gamma $ является всюду плотным в ${\mathbf{C}}[a;b]$.
Доказательство см. в разд. 2. В качестве непосредственного следствия леммы 1.1 и теоремы 1.1 получаем, что справедлива
Теорема 1.2. Класс $\mathcal{E}$ является всюду плотным в ${\mathbf{C}}({{E}^{n}})$.
2. ВСПОМОГАТЕЛЬНЫЕ УТВЕРЖДЕНИЯ
Следующее утверждение хорошо известно как теорема Вейерштрасса.
Лемма 2.1. Для любого числа $\varepsilon > 0$ и любой функции $f({{x}_{1}}, \ldots ,{{x}_{n}})$, непрерывной на компакте $Q \subset {{\mathbb{R}}^{n}}$, существует многочлен $P({{x}_{1}}, \ldots ,{{x}_{n}})$ такой, что $\mathop {max}\limits_Q {\text{|}}f({{x}_{1}}, \ldots ,{{x}_{n}}) - P({{x}_{1}}, \ldots ,{{x}_{n}}){\text{|}} < \varepsilon $.
Лемма 2.2. Для любых $[a;b] \subset \mathbb{R}$ и $\varepsilon > 0$, а также для любых $\beta \in \mathbb{R}$ и $\gamma > 0$ таких, что
(2)
$\frac{{{\text{|}}\beta {\kern 1pt} {\text{|}} + max({\text{|}}a{\kern 1pt} {\text{|}},{\text{|}}b{\kern 1pt} {\text{|}})}}{\gamma } < \sqrt {min(\varepsilon ,1)} ,$Доказательство. Верно разложение в ряд Маклорена
Лемма 2.3. Для любых $[a;b] \subset \mathbb{R}$, $a < b$, $C \ne 0$ и $\varepsilon > 0$ найдутся параметры $\alpha ,\beta ,d \in \mathbb{R}$ и $\gamma > 0$ такие, что
(3)
${\text{|}}\beta {\kern 1pt} {\text{|}} > \frac{{2{\text{|}}C{\text{|}}max({\text{|}}a{\kern 1pt} {\text{|}},{\text{|}}b{\kern 1pt} {\text{|}})(b - a)}}{\varepsilon },\quad \gamma > \tfrac{{{\text{|}}\beta {\kern 1pt} {\text{|}} + max({\text{|}}a{\kern 1pt} {\text{|}},{\text{|}}b{\kern 1pt} {\text{|}})}}{{\sqrt {min(\varepsilon {\text{/}}[2{\kern 1pt} {\text{|}}C{\kern 1pt} {\text{|}}{\kern 1pt} (b - a)],1)} }}.$Доказательство. Предварительно, считая параметры $\beta \in \mathbb{R}$, $\beta \ne 0$, $\gamma > 0$ произвольными, положим $\alpha = \tfrac{{C{{\gamma }^{2}}}}{{2\beta }}$ и оценим разность
Лемма 2.4. Пусть $[a;b] \subset \mathbb{R}$ и $\sigma > 0$ произвольно фиксированы. Тогда любой полином степени $n \geqslant 0$ можно сколь угодно точно в метрике пространства ${\mathbf{C}}{\kern 1pt} [a;b]$ аппроксимировать некоторой функцией вида $\Phi _{\nu }^{\sigma }[\alpha ,\beta ,\gamma ]$ при $\nu \leqslant n + 1$.
Доказательство. Рассмотрим на отрезке $[a;b]$, $a < b$, произвольный полином степени $n$: ${{\mathcal{P}}_{n}}(x) = {{K}_{0}} + {{K}_{1}}x + \ldots + {{K}_{n}}{{x}^{n}}$. Очевидно, нам достаточно доказать, что данный полином можно сколь угодно точно в метрике пространства ${\mathbf{C}}{\kern 1pt} [a;b]$ аппроксимировать некоторой функцией вида $\Phi _{\nu }^{0}[\alpha ,\beta ,\gamma ]$ при $\nu \leqslant n + 1$, $\gamma _{j}^{2} \geqslant \sigma $, $j = \overline {1,\nu } $. Если $n = 0$, достаточно просто сослаться на лемму 2.2. Будем считать, что $n \geqslant 1$, ${{C}_{m}} = \sqrt[m]{{\left| {{{K}_{m}}} \right|}}$, $C = 1 + \mathop {max}\limits_{m = \overline {1,n} } {{C}_{m}}$, ${{s}_{m}} = \operatorname{sign} {{K}_{m}}$, $m = \overline {1,n} $. Тогда
Зафиксируем произвольно число ${{\varepsilon }_{1}} \in (0;1)$ и найдем числа $\beta \ne 0$ и $\gamma \geqslant \sqrt {n\sigma } $ из условий (3) при замене $\varepsilon $ на ${{\varepsilon }_{1}}$. Согласно лемме 2.3, найдутся числа ${{d}_{m}}$, ${{\alpha }_{m}} \in \mathbb{R}$, $m = \overline {1,n} $, такие, чтоДоказательство теоремы 1.1 следует непосредственно из лемм 2.1 и 2.4.
3. РЕЗУЛЬТАТЫ ЧИСЛЕННЫХ ЭКСПЕРИМЕНТОВ
При проведении численных экспериментов везде использовались значения параметров $\lambda = \sqrt[n]{2}$, $\gamma = 2(n + 1)$, $\sigma = \tfrac{1}{{\gamma - 1}}$, $n = 2$. Что касается параметров $a$ и $b$, в тексте программ их задавать не требовалось, поскольку функции класса $\Phi _{\nu }^{\varepsilon }[\alpha ,\beta ,\gamma ]$ естественно определены на всей числовой оси, а не только на $[a;b]$. Формально можно считать, что $a < 0$, $b > 0$, причем ${\text{|}}a{\text{|}}$, ${\text{|}}b{\text{|}}$ достаточно велики. Фиксированный (достаточно большой) отрезок $[a;b]$ нужен был только для того, чтобы доказать плотность вложения класса аппроксимаций в класс непрерывных функций.
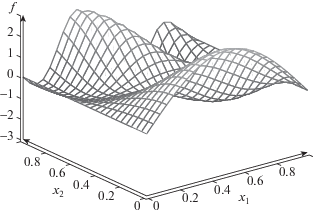
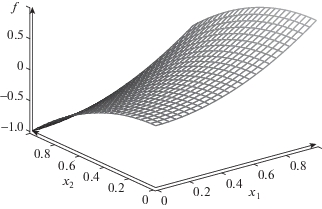
Тест № 1. Рассмотрим на квадрате ${{E}^{2}}$ функцию двух переменных, см. фиг. 1, $f({{x}_{1}},{{x}_{2}}) = 3sin(\pi {{x}_{1}})cos(\pi {{x}_{2}})cos({{\pi }^{2}}{{x}_{1}}{{x}_{2}})$. Эта функция выбиралась из следующего соображения: должно быть несколько локальных “всплесков” и “впадин”, чтобы график не имел слишком простой для аппроксимации формы. Выберем разбиение сторон квадрата
Поставим задачу найти по возможности наилучшую аппроксимацию функции $f(x)$ функцией класса ${{\mathcal{E}}_{\nu }}$. Для этого произведем минимизацию квадратичной невязки – суммы квадратов отклонений аппроксимации от аппроксимируемой функции в контрольных точках:
(4)
$\mathcal{K}[v] = \sum\limits_{i = 1}^\ell \,\sum\limits_{j = 1}^m \,{{\left\{ {f({{\xi }_{i}},{{\eta }_{j}}) - Q[v]({{\xi }_{i}},{{\eta }_{j}})} \right\}}^{2}} \to \mathop {min}\limits_{v \in {{V}_{\nu }}} .$(5)
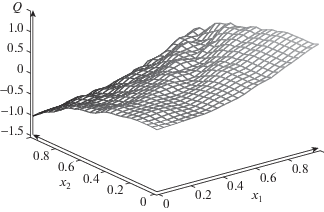
${{\mathcal{K}}_{\rho }}[v] = \mathcal{K}[v] + \rho {{\left| v \right|}^{2}} \to \mathop {min}\limits_{{v} \in {{V}_{\nu }}} ,$Случай $\nu = 5$. Получены следующие результаты. Значение квадратичной невязки: $25.0890$ (отметим, что при минимизации от значения $ \approx {\kern 1pt} 29$ до указанного продвижение очень медленное в связи с резкими изменениями нормы градиента). В случае “пробуксовки” методов первого порядка использовалось несколько сотен итераций метода Хука–Дживса. Значение нормы градиента квадратичной невязки: $0.041215$ (при критерии останова $\left\| {\nabla {{\mathcal{K}}_{\rho }}} \right\| < 0.05$). Среднее отклонение в контрольных точках: $0.14965$. Максимальное отклонение: $0.61687$. Учитывая, что аппроксимируемая функция принимает значения от $ - 3$ до $3$, соответствующие относительные погрешности: $\delta = 0.024942$, ${{\delta }_{m}} = 0.102812$, см. фиг. 2, 3. Приведем значения параметров по строкам $q = \overline {0,5} $.
Случай $\nu = 10$. Получены следующие результаты. Значение квадратичной невязки: $11.6649$ (отметим, что при минимизации от значения $ \approx {\kern 1pt} 15$ до указанного продвижение очень медленное в связи с резкими изменениями нормы градиента). Значение нормы градиента квадратичной невязки: $0.049997$ (при критерии останова $\left\| {\nabla {{\mathcal{K}}_{\rho }}} \right\| < 0.05$). Среднее отклонение в контрольных точках: $0.096934$. Максимальное отклонение: $0.51107$. Учитывая, что аппроксимируемая функция принимает значения от $ - 3$ до $3$, соответствующие относительные погрешности: $\delta = 0.016156$, ${{\delta }_{m}} = 0.085178$, см. фиг. 4, 5. Значения параметров не приводим в виду громоздкости соответствующего массива данных.
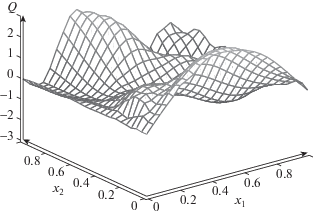
Таким образом, при увеличении количества параметров от $\nu = 5$ до $\nu = 10$ точность аппроксимации возросла.
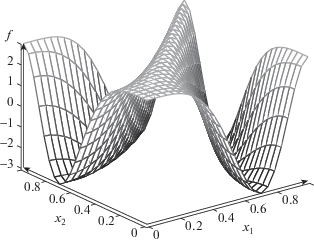
Тест № 2. Рассмотрим на квадрате ${{E}^{2}}$ непрерывную функцию двух переменных, см. фиг. 6, $f({{x}_{1}},{{x}_{2}}) = {{({{x}_{1}})}^{2}} - {{({{x}_{2}})}^{2}}$. Остальные параметры выберем такими же, как для теста № 1. Поясним выбор тестовой функции. Когда речь идет об аппроксимации с помощью функций специальной конструкции, полезно убедиться в том, что такая аппроксимация работает и в отношении функций самого простого вида. Кроме того, возможность сколь угодно точной аппроксимации многочлена функциями рассматриваемого класса – это и есть основа доказываемого теоретического результата о всюду плотном вложении. Поэтому здесь мы как бы “убиваем сразу двух зайцев”.
Аппроксимация строилась для случая $\nu = 5$. При выборе параметра регуляризации $\rho = {{10}^{{ - 15}}}$ наилучшее значение квадратичной невязки, которое удается получить, равно $\mathcal{K} \approx 21$. Если же для первых $5000$ итераций принять $\rho = {{10}^{{ - 7}}}$, а затем уже заменить его на $\rho = {{10}^{{ - 15}}}$, то решая задачу (5), получаем следующие результаты. Значение квадратичной невязки: $3.7815$. Среднее отклонение в контрольных точках: $0.061349$. Максимальное отклонение: $0.23636$. Использование “4-ступенчатого” управления параметром регуляризации ${{10}^{{ - 7}}} \to {{10}^{{ - 15}}} \to {{10}^{{ - 20}}} \to 0$ позволяет уменьшить значение квадратичной невязки до $3.22$, среднее отклонение – до $0.056002$, максимальное отклонение – до $0.21441$. Кроме того, было опробовано специальное адаптивное управление параметром регуляризации. Суть его состоит в том, что в случае критического замедления сходимости делается пробное уменьшение и увеличение параметра регуляризации и в зависимости от того, какой результат оказывается более удачным, производится коррекция этого параметра в ту или другую сторону. Адаптивное управление параметром регуляризации позволило уменьшить значение квадратичной невязки до $0.99779$, среднее отклонение – до $0.031401$, максимальное отклонение – до $0.12812$. Учитывая, что аппроксимируемая функция принимает значения от $ - 1$ до $1$, соответствующие относительные погрешности: $\delta = 0.0157005$, ${{\delta }_{m}} = 0.06406$, см. фиг. 7. Значение нормы градиента квадратичной невязки: $0.0048394$ (при критерии останова $\parallel \nabla {{K}_{\rho }}\parallel < 0.005$). Приведем значения параметров по строкам $q = \overline {0,5} $.
Тест № 3. Рассмотрим на квадрате ${{E}^{2}}$ непрерывную функцию двух переменных, см. фиг. 8, $f({{x}_{1}},{{x}_{2}}) = 3cos(2\pi [{{({{x}_{1}})}^{2}} - {{({{x}_{2}})}^{2}}])$. Функция выбиралась из следующего соображения: должно быть несколько “всплесков” и “впадин” ленточного типа (то есть локализованных лишь по одному направлению). Остальные параметры выберем такими же, как для теста № 1. Аппроксимация строилась для случая $\nu = 5$. Если для первых $5000$ итераций принять $\rho = {{10}^{{ - 7}}}$, затем заменить его на $\rho = {{10}^{{ - 15}}}$, а потом при достижении значения ${{\mathcal{K}}_{\rho }} \approx 4$ принять $\rho = {{10}^{{ - 20}}}$ и, наконец, при отсутствии убывания нормы градиента, взять $\rho = 0$, то, решая задачу (5), получаем следующие результаты. Значение квадратичной невязки: $3.4369$. Значение нормы ее градиента: $0.049951$ (при критерии останова $\left\| {\nabla {{\mathcal{K}}_{\rho }}} \right\| < 0.05$). Среднее отклонение в контрольных точках: $0.057943$. Максимальное отклонение: $0.29136$. Учитывая, что аппроксимируемая функция принимает значения от $ - 3$ до $3$, соответствующие относительные погрешности: $\delta = 0.0096572$, ${{\delta }_{m}} = 0.04856$, см. фиг. 9. Приведем значения параметров по строкам $q = \overline {0,5} $.

С учетом сказанного, в качестве критерия останова процесса численной оптимизации следует использовать не только условие малости нормы градиента, но и отсутствие существенных улучшений за некоторое количество итераций. Отметим, что такая практика является достаточно распространенной при минимизации сложно устроенных функций. Применение теоремы Колмогорова оправдывается тем, что при использовании малого количества параметров удается получать аппроксимацию хорошего качества для функций, устроенных “не слишком плохо” (а в том, чтобы построить такой способ аппроксимации, как раз и состояла исходная цель автора).
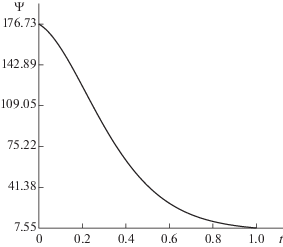
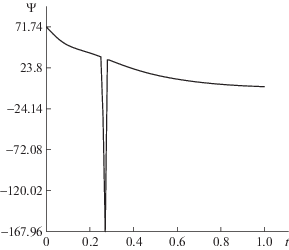
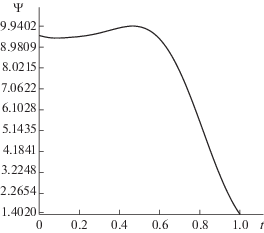
Наконец, сделаем следующее интересное наблюдение, см. фиг. 10, 11. Как указано в формулировке леммы 1.1, функция $\Psi (y)$ должна быть монотонно возрастающей. Однако за счет тривиального изменения внешних функций ${{F}_{q}}(y)$ (например, домножением аргумента на $( - 1)$) возрастающую функцию $\Psi (y)$ можно заменить на убывающую. Это согласуется с полученными графиками аппроксимации функции $\Psi $ для тестов № 1, 2. Кроме того, можно предположить, что за счет некоторой деформации функций ${{F}_{q}}$ можно для некоторых конкретных функций, подвергаемых аппроксимации, отойти от монотонности функции $\Psi $ в их представлении Колмогорова. И это подтверждается тестом № 3, см. фиг. 11.

Проводились численные эксперименты и с другими тестовыми функциями в виде суперпозиций основных элементарных функций и многочленов второй и третьей степени – в общем и целом картина наблюдалась каждый раз схожая.
Тест № 4. Для функции теста № 1 мы пробовали для аппроксимации одномерных функций в представлении Колмогорова использовать многочлены (заменив соответствующую подпрограмму в разработанном программном комплексе на языке MATLAB; поэтому количество $\mu $ параметров – коэффициентов многочлена степени $(\mu - 1)$ задавалось в виде $\mu = 3\nu $, где число $\nu $ передавалось в подпрограмму в качестве входного параметра). Оказалось, что при $\nu < 5$ такая аппроксимация работает, но такого значения $\nu $ еще не достаточно для достижения хорошей точности, см. табл. 1. Здесь случай нормы градиента, большей заданного значения $0.05$ в критерии останова, означает прерывание вычислений по причине отсутствия улучшений в смысле значения функции квадратичной невязки. При $\nu = 5$ уже наблюдаются сбои в ходе работы программы (приходится периодически перезапускать ее для продолжения вычислений с другими значениями параметров), связанные с тем, что появляются значения Inf (Infinity – бесконечность) и NaN (Not a Number – неопределенность). При $\nu = 10$ никаких значений, кроме Inf и NaN, при ненулевой начальной точке получить не удалось; при нулевой начальной точке в качестве аппроксимации получается константа. Причину описанных сбоев нетрудно понять, если провести сравнительную проверку правильности вычисления градиента $\nabla \mathcal{K}$ с помощью конечных разностей (см. следующий тест). Оказывается, что в отличие от аппроксимации функциями Гаусса, при аппроксимации многочленами наблюдается резкий рост погрешности вычисления градиента с ростом параметра $\nu $. А это, в свою очередь, происходит вследствие того, что коэффициентами при параметрах многочлена являются степени одномерной переменной $t$. При ${\text{|}}t{\kern 1pt} {\text{|}} > 1$ и больших показателях степени происходит резкий рост этих коэффициентов, а при ${\text{|}}t{\kern 1pt} {\text{|}} < 1$ их влияние становится исчезающе малым.
Таблица 1.
Аппроксимация полиномами
| $\nu $ | $\mathcal{K}$ | $\left\| {\nabla \mathcal{K}} \right\|$ | $\Delta $ | ${{\Delta }_{{max}}}$ |
|---|---|---|---|---|
| 1 | 559.3065 | 0.033963 | 0.75375 | 2.5994 |
| 2 | 350.0558 | 0.041134 | 0.58236 | 2.4418 |
| 3 | 77.6166 | 0.21433 | 0.27834 | 1.3729 |
| 4 | 30.3614 | 3.8951 | 0.17855 | 0.68308 |
| 5 | 33.4258 | 0.91582 | 0.1826 | 0.71261 |
| 6 | 27.4957 | 1.4101 | 0.1671 | 0.55097 |
Тест № 5. В табл. 2 приведены результаты проверки правильности вычисления градиента $\nabla \mathcal{K}$ функции квадратичной невязки при аппроксимации одномерных функций в представлении Колмогорова многочленами в точке $0.011$, где 1 – вектор размерности $\mu = 3\nu $, составленный из единиц. Здесь ${{\Delta }_{{min}}}$ – минимум (по всем частным производным первого порядка) абсолютных погрешностей, ${{\Delta }_{{max}}}$ – максимум абсолютных погрешностей, ${{\delta }_{{min}}}$ – минимум относительных погрешностей, ${{\delta }_{{max}}}$ – максимум относительных погрешностей. При $\nu = 10$ значения всех погрешностей равны NaN. В табл. 3 приведены результаты проверки правильности вычисления градиента $\nabla \mathcal{K}$ функции квадратичной невязки при аппроксимации одномерных функций в представлении Колмогорова функциями Гаусса в той же точке.
Таблица 2.
Полиномы: проверка правильности вычисления $\nabla \mathcal{K}$
| $\nu $ | ${{\Delta }_{{min}}}$ | ${{\Delta }_{{max}}}$ | ${{\delta }_{{min}}}$ | ${{\delta }_{{max}}}$ |
|---|---|---|---|---|
| 1 | 2.28530e–7 | 6.25008e–3 | 3.3848e–7 | 2.6785e–5 |
| 5 | 4.89217e+28 | 5.74642e+65 | 2.4827e–10 | 1 |
Таблица 3.
Функции Гаусса: проверка правильности вычисления $\nabla \mathcal{K}$
| $\nu $ | ${{\Delta }_{{min}}}$ | ${{\Delta }_{{max}}}$ | ${{\delta }_{{min}}}$ | ${{\delta }_{{max}}}$ |
|---|---|---|---|---|
| 5 | 7.33070e–4 | 1.42575e–1 | 6.0807e–6 | 0.002413 |
| 10 | 5.04264e–8 | 1.00985e–1 | 1.0604e–6 | 0.0085675 |
На основе результатов численных экспериментов, описанных выше, можно сделать следующие выводы.
1. Проведенные численные эксперименты подтверждают предположение о том, что предлагаемый метод аппроксимации функций многих переменных на основе приближения одномерных функций в их представлении А.Н. Колмогорова (здесь и далее – в стиле леммы 1.1) линейными комбинациями функций Гаусса с варьируемыми параметрами позволяет получать качественные аппроксимации непрерывных функций с “нехаотическим” графиком при сравнительно малом количестве параметров.
2. Устойчивость процесса численного решения задачи (5) наблюдается при использовании методов DFP и BFS в ходе многомерной оптимизации и метода Брента для одномерного поиска, при условии выбора начального приближения в виде вектора $\kappa \{ - 1,2, - 3, \ldots ,{{( - 1)}^{\mu }}\mu \} $, где $\mu $ – количество параметров, $\kappa $ – малая величина.
3. Погрешность вычисления градиента функционала квадратичной невязки при увеличении количества параметров в рамках предлагаемого подхода не становится критичной, в отличие от подхода, основанного на аппроксимации одномерных функций в представлении А.Н. Колмогорова полиномами. Сравнение с подходом, основанным на аппроксимации одномерных функций полиномами, было необходимо провести, поскольку теорема 1.2 о всюду плотности класса $\mathcal{E}$ в пространстве непрерывных функций доказывается посредством аппроксимации полиномов функциями класса $\mathcal{E}$. Может возникнуть резонный вопрос: почему бы сразу не использовать полиномы? Помимо уже упомянутых во введении преимуществ использования функций Гаусса, численные эксперименты дают еще один наглядный ответ на этот вопрос.
4. Для повышения точности достигаемой аппроксимации может оказаться полезным постепенное уменьшение параметра регуляризации в ходе численного решения задачи (5) от некоторого малого, но не слишком малого, значения (например, ${{10}^{{ - 7}}}$) до нуля.
5. Функция $\Psi $ в представлении А.Н. Колмогорова, судя по ее аппроксимациям, реализовавшимся в ходе экспериментов, определяется не просто неоднозначно, а проявляет своего рода гибкость, полезную для облегчения численного процесса минимизации квадратичной невязки. Упомянутая гибкость связана с тем, что, как уже было сказано, имеется некоторая компенсируемая неоднозначность в задании функций ${{F}_{q}}$ и $\Psi $.
6. Для теста № 3 результат получился несколько лучше, чем для теста № 2 (с функцией более простого вида). Вообще говоря, ничего удивительного в этом нет. Например, функцию $y = x$ на отрезке $[0;1]$ можно сколь угодно точно аппроксимировать рядом Фурье, но для этого потребуется некоторое количество членов разложения. А для аппроксимации (и даже точного представления) функции более сложного вида $y = cosx$ достаточно всего лишь одного члена разложения $y = cosx$. Однако, исходя из сравнения результатов численных экспериментов в тестах № 2 и 3, автору было интересно выяснить, насколько в принципе можно улучшить качество аппроксимации при $\nu = 5$ для теста № 2. Оказалось, что в этом смысле “4-ступенчатое” управление параметром регуляризации ${{10}^{{ - 7}}} \to {{10}^{{ - 15}}} \to {{10}^{{ - 20}}} \to 0$ более эффективно, чем “2-ступенчатое”: ${{10}^{{ - 7}}} \to {{10}^{{ - 15}}}$; адаптивное управление – еще более эффективно.
Список литературы
Teo K.L., Goh C.J., Wong K.H. A unified computational approach to optimal control problems / Pitman Monographs and Surveys in Pure and Applied Mathematics. Vol. 55. Harlow, New York: Longman Scientific & Technical, Wiley, Inc., 1991. ix+329 p.
Чернов А.В. О приближенном решении задач оптимального управления со свободным временем // Вестник Нижегородского гос. ун-та им. Н.И. Лобачевского. 2012. № 6(1). С. 107–114.
Чернов А.В. О гладких конечномерных аппроксимациях распределенных оптимизационных задач с помощью дискретизации управления // Ж. вычисл. матем. и матем. физ. 2013. Т. 53. № 12. С. 2029–2043.
Чернов А.В. О применимости техники параметризации управления к решению распределенных задач оптимизации // Вестник Удмуртского университета. Математика. Механика. Компьютерные науки. 2014. Т. 24. Вып. 1. С. 102–117.
Чернов А.В. О гладкости аппроксимированной задачи оптимизации системы Гурса–Дарбу на варьируемой области // Труды Института математики и механики УрО РАН. 2014. Т. 20. № 1. С. 305–321.
Чернов А.В. О кусочно постоянной аппроксимации в распределенных задачах оптимизации // Труды ИММ УрО РАН. 2015. Т. 21. № 1. С. 264–279.
Колмогоров А.Н. О представлении непрерывных функций нескольких переменных в виде суперпозиций непрерывных функций одного переменного и сложения // Докл. АН СССР. 1957. Т. 114. № 5. С. 953–956.
Sprecher D.A. On the structure of continuous functions of several variables // Trans. Amer. Math. Soc. 1965. V. 115. P. 340–355.
Голубков А.Ю. Построение внешних и внутренних функций представления непрерывных функций многих переменных суперпозицией непрерывных функций одного переменного // Фундамент. и прикл. матем. 2002. Т. 8. Вып. 1. С. 27–38.
Бутырский Е.Ю., Кувалдин И.А., Чалкин В.П. Аппроксимация многомерных функций // Научное приборостроение. 2010. Т. 20. № 2. С. 82–92.
Hecht-Nielsen R. Kolmogorov’s mapping neural network existence theorem // IEEE First Annual Int. Conf. on Neural Networks. San-Diego. 1987. V. 3. P. 11–13.
Алексеев Д.В. Приближение функций нескольких переменных нейронными сетями // Фундаментальная и прикл. матем. 2009. Т. 15. Вып. 3. С. 9–21.
Горбань А.Н. Обобщенная аппроксимационная теорема и точное представление многочленов от нескольких переменных суперпозициями многочленов от одного переменного // Изв. вузов. Математика. 1998. № 5. С. 6–9.
Исмаилов В.Э. Аппроксимация суммами ридж-функций с фиксированными направлениями // Алгебра и анализ. 2016. Т. 28. № 6. С. 20–69.
Кульчин Ю.Н., Денисов И.В., Панов А.В., Рыбальченко Н.А. Применение персептронов для нелинейной реконструктивной томографии // Пробл. управления. 2006. Вып. 4. С. 59–63.
Чернов А.В. Об использовании квадратичных экспонент с варьируемыми параметрами для аппроксимации функций одного переменного на конечном отрезке // Вестник Удмуртского университета. Математика. Механика. Компьютерные науки. 2017. Т. 27. Вып. 2. С. 267–282.
Чернов А.В. О применении квадратичных экспонент для дискретизации задач оптимального управления // Вестник Удмуртского университета. Математика. Механика. Компьютерные науки. 2017. Т. 27. Вып. 4. С. 558–575.
Maz’ya V., Schmidt G. Approximate approximations. Mathematical Surveys and Monographs. V. 141. Providence, RI: American Mathematical Society (AMS), 2007. xiv+349 p.
Riemenschneider S.D., Sivakumar N. Cardinal interpolation by Gaussian functions: a survey // J. Analysis. 2000. V. 8. P. 157–178.
Luh Lin-Tian. The shape parameter in the Gaussian function // Computers and Mathematics with Applications. 2012. V. 63. P. 687–694.
Hangelbroek T., Madych W., Narcowich F., Ward J.D. Cardinal interpolation with Gaussian kernels // J. Fourier Anal. Appl. 2012. V. 18. № 1. P. 67–86.
Hamm K. Approximation rates for interpolation of Sobolev functions via Gaussians and allied functions // J. Approx. Theory. 2015. V. 189. P. 101–122.
Griebel M., Schneider M., Zenger C. A combination technique for the solution of sparse grid problems / Iterative methods in linear algebra. Proc. of the IMACS international symposium, Brussels, Belgium, 2–4 April, 1991. Amsterdam: North-Holland, 1992. P. 263–281.
Georgoulis E., Levesley J., Subhan F. Multilevel sparse kernel-based interpolation // SIAM J. Sci. Comput. 2013. V. 35. № 2. P. A815–A831.
More J.J., Thuente D.J. Line search algorithms with guaranteed sufficient decrease // ACM Transactions on Mathematical Software. 1994. V. 20. P. 286–307.
Дополнительные материалы отсутствуют.
Инструменты
Журнал вычислительной математики и математической физики