

Известия РАН. Теория и системы управления, 2022, № 4, стр. 49-65
ПРОСТРАНСТВЕННО-ВРЕМЕННОЕ УПРАВЛЕНИЕ СИСТЕМАМИ С РАПРЕДЕЛЕННЫМИ ПАРАМЕТРАМИ В ЛИНЕЙНО-КВАДРАТИЧНЫХ ЗАДАЧАХ ОПТИМИЗАЦИИ С РАВНОМЕРНЫМИ ОЦЕНКАМИ ЦЕЛЕВЫХ МНОЖЕСТВ
Ю. Э. Плешивцева a, Э. Я. Рапопорт a, *
a Самарский государственный технический ун-т
Самара, Россия
* E-mail: edgar.rapoport@mail.ru
Поступила в редакцию 28.10.2021
После доработки 17.01.2022
Принята к публикации 31.01.2022
- EDN: ENOBZI
- DOI: 10.31857/S0002338822030118
Аннотация
Предлагается конструктивный метод решения линейно-квадратичной задачи пространственно-временного управления в системах с распределенными параметрами параболического типа в условиях заданной точности равномерного приближения конечного состояния объекта к требуемому пространственному распределению управляемой величины. Развиваемый подход базируется на разработанном ранее альтернансном методе построения параметризуемых алгоритмов программного управления, распространяющем на широкий круг задач оптимизации результаты теории нелинейных чебышевских приближений и существенно использующем фундаментальные закономерности предметной области. Показывается, что уравнения оптимальных регуляторов с автономными модальными управлениями в открытой области их определения и с учетом ограничений на заданный по условиям технической реализации характер пространственного распределения управляющих воздействий сводятся к линейным алгоритмам обратной связи по измеряемому состоянию объекта с нестационарными коэффициентами передачи и заданной зависимостью от пространственных аргументов управляемой величины. Полученные результаты распространяются на задачи поиска неизменных во времени пространственно-распределенных управлений, рассматриваемых в роли искомых проектных решений объекта.
Введение. Одной из наиболее существенных особенностей систем с распределенными параметрами (СРП) по сравнению с сосредоточенными системами (ССП) является расширение класса допустимых управляющих воздействий за счет включения в их число пространственно-временных управлений (ПВУВ), описываемых подобно состоянию СРП функциями векторного аргумента – времени и пространственных координат [1–8]. Применение ПВУВ открывает принципиально новые возможности управления СРП, недостижимые в классе свойственных ССП сосредоточенных управлений, которые не зависят от пространственных переменных. В частности, именно использование ПВУВ специального вида привело к созданию нового перспективного класса СРП с подвижным воздействием, охватывающего широкий круг актуальных прикладных задач самого различного физического содержания [6–8].
В работе рассматривается задача оптимального по квадратичному критерию качества управления СРП, описываемой линейным пространственно-одномерным уравнением второго порядка в частных производных параболического типа с внутренним ПВУВ при заведомо неизвестном характере его зависимости как от времени, так и от пространственной координаты. Задача исследуется в специфических и типичных для приложений условиях оценки в равномерной метрике целевых множеств с негладкой границей в конечной точке оптимального процесса в бесконечномерном фазовом пространстве СРП, исключающих применение классических условий трансверсальности при аналитическом синтезе оптимальных регуляторов [5, 9–11].
Для частного случая использования скалярных сосредоточенных управлений с априори заданным характером пространственного распределения внутренних управляющих воздействий описываемая задача изучалась в [11] для детерминированных и не полностью определенных моделей объекта. В [12] были найдены оптимальные по критерию энергосбережения программные пространственно-временные управляющие воздействия для различных возможных вариантов их фактического представления.
1. Постановка задачи. Пусть управляемая величина $Q(x,t)$ объекта с распределенными параметрами описывается в зависимости от пространственной координаты $x \in [{{x}_{0}},{{x}_{1}}]$ и времени $t \in \left[ {0,{{t}_{1}}} \right]$ одномерным линейным уравнением второго порядка в частных производных параболического типа с самосопряженным дифференциальным оператором в его правой части:
(1.1)
$\frac{{\partial Q(x,t)}}{{\partial t}} = b(x)\frac{{\partial Q(x,t)}}{{\partial x}} + c(x)\frac{{{{\partial }^{2}}Q(x,t)}}{{\partial {{x}^{2}}}} + {{c}_{1}}(x)\,Q(x,t) + u(x,t)$(1.3)
${{\alpha }_{0}}Q({{x}_{0}},t) + {{\beta }_{0}}\frac{{\partial Q({{x}_{0}},t)}}{{\partial x}} = 0;\quad {{\alpha }_{1}}Q({{x}_{1}},t) + {{\beta }_{1}}\frac{{\partial Q({{x}_{1}},t)}}{{\partial x}} = 0$Допустим, что необходимо обеспечить за фиксируемое априори конечное время ${{t}_{1}}$ заданную точность $\varepsilon $ равномерного приближения результирующего пространственного распределения управляемой величины $Q\left( {x,{{t}_{1}}} \right)$ к требуемому $Q{\text{**}}\left( x \right) > {{Q}_{0}}\forall x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]$, согласно соотношению
(1.4)
$\mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} \left| {Q\left( {x,{{t}_{1}}} \right) - Q{\text{**}}(x)} \right| \leqslant \varepsilon ,$Пусть далее эффективность процесса управления объектом (1.1)–(1.4) оценивается типичным квадратичным функционалом качества, определяемым для простоты и наглядности без потери общности основных результатов в следующей типичной частной форме:
(1.5)
$I\left( u \right) = \int\limits_0^{{{t}_{1}}} {\int\limits_{{{x}_{0}}}^{{{x}_{1}}} {[{{\rho }_{Q}}{{Q}^{2}}\left( {x,t} \right) + {{u}^{2}}\left( {x,t} \right)]dxdt \to \mathop {\min }\limits_{u(x,t)} } } $Подобно тому, как применение преобразования Лапласа к обыкновенным линейным дифференциальным уравнениям модели объекта с сосредоточенными параметрами приводит к алгебраическим уравнениям относительно изображений управляемой величины, не содержащим ее производных по времени, известный аппарат конечных интегральных преобразований позволяет перейти от дифференциальных уравнений в частных производных (1.1)–(1.3) к бесконечной системе обыкновенных дифференциальных уравнений первого порядка, не содержащих производных управляемой величины по пространственной координате [13]:
(1.6)
$\begin{gathered} \frac{{d{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right)}}{{dt}} = - \mu _{n}^{2}{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right) + {{{\bar {u}}}_{n}}\left( {{{\mu }_{n}},t} \right),\quad n = 1,2,..., \\ {{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right) = {{{\bar {Q}}}^{{(0)}}}\left( {{{\mu }_{n}}} \right), \\ \end{gathered} $(1.7)
$Q\left( {x,t} \right) = \sum\limits_{n = 1}^\infty {{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right)} {{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right)$(1.8)
$u\left( {x,t} \right) = \sum\limits_{n = 1}^\infty {{{{\bar {u}}}_{n}}\left( {{{\mu }_{n}},t} \right){{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right)} $,При этом поведение каждой из модальных составляющих ${{\bar {Q}}_{n}}$ управляемой величины Q(x, t) определяется только “своим” управляющим воздействием ${{\bar {u}}_{n}}$, согласно решению каждого из уравнений (1.6) в отдельности независимо от других, обеспечивая в итоге требуемое пространственно-временное состояние Q(x, t), описываемое рядом (1.7).
Подобно [11], здесь и всюду далее в условиях выполнения усиленных условий Коши–Липшица [14] будем учитывать N1 слагаемых в суммах (1.7), (1.8). Здесь ${{N}_{1}} = \infty $ или ${{N}_{1}} = N < \infty $ в зависимости от используемой схемы анализа и возможностей практической реализации исследуемых алгоритмов управления, ограничиваясь в случае ${{N}_{1}} = N$ с любой требуемой точностью решением “укороченной” системы N первых уравнений (1.6) при достаточно большой величине $N$ и полагая при этом ${{\bar {Q}}_{n}}\left( {{{\mu }_{n}},t} \right) = 0$, $n > N$ [14].
Переход к описанию СРП в (1.6), (1.7) в терминах модальных переменных приводит в силу ортонормированности семейства собственных функций к представлению критерия оптимальности (1.5) в следующем виде:
(1.9)
$\begin{gathered} {{I}_{1}}\left( {\bar {u}} \right) = \int\limits_0^{{{t}_{1}}} {\left[ {{{\rho }_{Q}}\sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}\left( {{{\mu }_{n}},t} \right)} + \sum\limits_{n = 1}^{{{N}_{1}}} {\bar {u}_{n}^{2}\left( {{{\mu }_{n}},t} \right)} } \right]} {\kern 1pt} {\kern 1pt} dt \to \mathop {\min }\limits_{\bar {u}} , \\ \bar {u} = \left( {{{{\bar {u}}}_{n}}} \right),\quad n = \overline {1,{{N}_{1}}} , \\ \end{gathered} $(1.10)
$\mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} \left| {\sum\limits_{n = 1}^{{{N}_{1}}} {{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},{{t}_{1}}} \right)} {{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right) - Q{\text{**}}\left( x \right)} \right| \leqslant \varepsilon {\kern 1pt} {\kern 1pt} .$Рассматриваемая задача оптимизации сводится к определению программного оптимального управления $u{\text{*}}\left( {x,t} \right)$ и алгоритма обратной связи $u{\text{*}}\left( {\bar {Q},x,t} \right)$, $\bar {Q} = \left( {{{{\bar {Q}}}_{n}}} \right)$, $n = \overline {1,{{N}_{1}}} $, обеспечивающих при ${{N}_{1}} = \infty $ перевод объекта (1.6)–(1.8) за заданное время t1 в требуемое конечное состояние, удовлетворяющее (1.10) при минимально возможном значении критерия оптимальности (1.9).
При использовании усеченной модели объекта с ${{N}_{1}} = N < \infty $ все полученные далее результаты следует считать субоптимальными.
2. Программное оптимальное пространственно-временное управление. Структура модального управляющего воздействия. На сформулированную бесконечномерную задачу оптимального управления распространяется принцип максимума Понтрягина [5, 15]. Базовое условие
(2.1)
$H\left( {\bar {Q}{\text{*}}(t),\bar {u}{\text{*}}(t),\psi {\text{*}}(t)} \right) = \mathop {\max }\limits_{\bar {u}} H\left( {\bar {Q}{\text{*}}(t),\bar {u},\psi {\text{*}}(t)} \right),\quad t \in \left[ {0,{{t}_{1}}} \right]$(2.2)
$\begin{gathered} H\left( {\bar {Q}\left( t \right),\bar {u}\left( t \right),\psi \left( t \right)} \right) = - {{\rho }_{Q}}\sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}\left( {{{\mu }_{n}},t} \right) - } \sum\limits_{n = 1}^{{{N}_{1}}} {\bar {u}_{n}^{2}\left( {{{\mu }_{n}},t} \right) + } \\ + \,\sum\limits_{n = 1}^{{{N}_{1}}} {\psi _{n}^{{}}\left( t \right)( - \mu _{n}^{2}{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right) + {{{\bar {u}}}_{n}}\left( {{{\mu }_{n}},t} \right)),} \\ \end{gathered} $(2.3)
$\frac{{d{{\psi }_{p}}}}{{dt}} = - \frac{{\partial H}}{{\partial {{{\bar {Q}}}_{p}}}} = 2{{\rho }_{Q}}\bar {Q}_{p}^{{}}({{\mu }_{p}},t) + \mu _{p}^{2}{{\psi }_{p}}(t),\quad p = \overline {1,{{N}_{1}}} ,$(2.4)
$\bar {u}_{n}^{*}\left( {{{\mu }_{n}},t} \right) = \frac{1}{2}\psi _{n}^{*}\left( t \right),\quad n = \overline {1,{{N}_{1}}} .$Краевая задача принципа максимума для модальных управляющих воздействий. Каждое из уравнений (1.6) после подстановки модального управления в виде (2.4) образует совместно с соответствующим уравнением (2.3) линейную программно-управляемую систему второго порядка относительно двух переменных ${{\bar {Q}}_{n}}$, ${{\psi }_{n}}$ для каждого $n = \overline {1,{{N}_{1}}} $:
(2.5)
$\frac{{d{{\psi }_{n}}}}{{dt}} = 2{{\rho }_{Q}}{{\bar {Q}}_{n}} + \mu _{n}^{2}{{\psi }_{n}},\quad \frac{{d{{{\bar {Q}}}_{n}}}}{{dt}} = - \mu _{n}^{2}{{\bar {Q}}_{n}} + \frac{1}{2}{{\psi }_{n}}.$Система (2.5) в отличие от подобной системы порядка 2N1 для всей совокупности составляющих $\bar {Q}\left( t \right)$, $\psi \left( t \right)$ в задаче с сосредоточенным внутренним управлением [11] замыкается требованиями к ее конечному состоянию, которые считаются определенными, исходя из общего для всех $n = \overline {1,{{N}_{1}}} $ условия (1.10).
Решение этой системы может быть представлено, подобно [11], в векторно-матричной форме
(2.6)
$\left[ \begin{gathered} {{\psi }_{n}}(t) \\ {{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right) \\ \end{gathered} \right] = {{e}^{{{{A}_{n}}t}}}\left[ \begin{gathered} {{\psi }_{n}}\left( 0 \right) \\ {{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right) \\ \end{gathered} \right],$(2.7)
${{e}^{{{{A}_{n}}t}}} = \left[ {\begin{array}{*{20}{c}} {{{A}_{{n11}}}\left( t \right)}&{{{A}_{{n12}}}\left( t \right)} \\ {{{A}_{{n21}}}\left( t \right)}&{{{A}_{{n22}}}\left( t \right)} \end{array}} \right],$Параметризация пространственно-временных управлений. Согласно (2.6), $\psi _{n}^{*}\left( t \right)$, а следовательно, и программное управление $\bar {u}_{n}^{*}\left( {{{\mu }_{n}},t} \right)$ в (2.4) определяются с точностью до начальных значений $\psi _{n}^{*}\left( 0 \right)$, совокупность которых для всех $n = \overline {1,{{N}_{1}}} $ выступает, таким образом, в качестве естественного параметрического представления $u{\text{*}}\left( {x,t} \right)$, согласно (1.8), (2.4), (2.6). Однако подобный подход для СРП оказывается неконструктивным, прежде всего в силу бесконечной размерности вектора $\psi {\text{*}}\left( 0 \right)$ при ${{N}_{1}} = \infty $.
В работе [16] применительно к требованиям (1.10), предъявляемым к $\bar {Q}{\text{*}}\left( {{{t}_{1}}} \right)$, предложен конструктивный способ последовательной конечномерной параметризации управляющих воздействий (“$\psi $-параметризация”) на множестве M-мерных векторов ${{\psi }^{{\left( M \right)}}} = \left( {{{{\tilde {\psi }}}_{i}}} \right)$, $i = \overline {1,M} $; ${{\tilde {\psi }}_{i}} = {{\psi }_{i}}\left( {{{t}_{1}}} \right)$, $M < {{N}_{1}}$, конечных значений первых M сопряженных функций в (2.3) при равных нулю всех остальных значениях ${{\psi }_{i}}\left( {{{t}_{1}}} \right)$:
(2.8)
$\psi \left( {{{t}_{1}}} \right) = \left( {{{\psi }_{i}}\left( {{{t}_{1}}} \right)} \right);\quad {{\psi }_{i}}\left( {{{t}_{1}}} \right) = {{\tilde {\psi }}_{i}},\quad i = \overline {1,M} ;\quad {{\psi }_{i}}\left( {{{t}_{1}}} \right) = 0,\quad i > M.$С возрастанием $M$ обеспечивается попадание под действием параметризуемых на множестве параметров (2.8) управляющих воздействий в сужающееся к заданному состоянию $Q{\text{**}}\left( x \right)$ в пространстве $\left( {{{{\bar {Q}}}_{n}}} \right)$ целевое множество, гарантируя выполнение условий (1.10) для допустимых значений $\varepsilon $ при некотором конечном значении $M \geqslant 1$ [16].
В целях определения в явной форме $\psi $-параметризованного модального управления получим по указанной в [11] схеме путем переноса (прогонки) начальных условий в (2.6) в конечный момент времени ${{t}_{1}}$ следующее выражение в отдельности для каждой из сопряженных функций $\psi _{n}^{*}\left( t \right)$, $n = \overline {1,{{N}_{1}}} $, в оптимальном процессе в зависимости от их конечных значений $\psi _{n}^{*}\left( {{{t}_{1}}} \right)$ и начального состояния объекта ${{\bar {Q}}_{n}}\left( {{{\mu }_{n}},0} \right)$:
(2.9)
$\psi _{n}^{*}\left( t \right) = {{K}_{n}}\left( {t,{{t}_{1}}} \right)\psi _{n}^{*}\left( {{{t}_{1}}} \right) + {{K}_{{1n}}}\left( {t,{{t}_{1}}} \right){{\bar {Q}}_{n}}\left( {{{\mu }_{n}},0} \right),\quad n = \overline {1,{{N}_{1}}} ,$(2.10)
$\begin{gathered} {{K}_{n}}\left( {t,{{t}_{1}}} \right) = {{{\hat {A}}}_{{n11}}}\left( {{{t}_{1}} - t} \right) + {{{\hat {A}}}_{{n12}}}\left( {{{t}_{1}} - t} \right){{B}_{n}}\left( {{{t}_{1}}} \right), \\ {{K}_{{1n}}}\left( {t,{{t}_{1}}} \right) = {{{\hat {A}}}_{{n12}}}\left( {{{t}_{1}} - t} \right){{B}_{{1n}}}\left( {{{t}_{1}}} \right). \\ \end{gathered} $Здесь ${{\hat {A}}_{{nks}}}$, $k$, $s = 1,2$ – подобные (2.7) элементы обратной матрицы ${{e}^{{ - {{A}_{n}}t}}}$ и
(2.11)
${{B}_{n}}\left( {{{t}_{1}}} \right) = {{A}_{{n21}}}\left( {{{t}_{1}}} \right)A_{{n11}}^{{ - 1}}\left( {{{t}_{1}}} \right);\quad {{B}_{{1n}}}\left( {{{t}_{1}}} \right) = {{A}_{{n22}}}\left( {{{t}_{1}}} \right) - {{A}_{{n21}}}\left( {{{t}_{1}}} \right)A_{{n11}}^{{ - 1}}\left( {{{t}_{1}}} \right){{A}_{{n12}}}\left( {{{t}_{1}}} \right).$При определении $\psi {\text{*}}\left( {{{t}_{1}}} \right)$ в форме (2.8) будем иметь, согласно (2.9),
(2.12)
$\psi _{n}^{*}\left( t \right) = \left\{ \begin{gathered} {{K}_{n}}\left( {t,{{t}_{1}}} \right)\tilde {\psi }_{n}^{*} + {{K}_{{1n}}}\left( {t,{{t}_{1}}} \right){{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right),\quad n \leqslant M, \hfill \\ {{K}_{{1n}}}\left( {t,{{t}_{1}}} \right){{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right),\quad n > M, \hfill \\ \end{gathered} \right.$Подстановка (2.12) в (2.4) определяет ψ-параметризованные модальные управления в форме линейной зависимости от $\tilde {\psi }_{n}^{*}$:
(2.13)
$\bar {u}_{n}^{*}\left( {{{\mu }_{n}},t} \right) = \left\{ \begin{gathered} \frac{1}{2}[{{K}_{n}}\left( {t,{{t}_{1}}} \right)\tilde {\psi }_{n}^{*} + {{K}_{{1n}}}\left( {t,{{t}_{1}}} \right){{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right)],\quad n \leqslant M, \hfill \\ \frac{1}{2}{{K}_{{1n}}}\left( {t,{{t}_{1}}} \right){{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right),\quad n > M. \hfill \\ \end{gathered} \right.$Отсюда, в частности, следует, что $\bar {u}_{n}^{*}\left( {{{\mu }_{n}},t} \right)$ при $n > M$ определяются только начальным значением ${{\bar {Q}}_{n}}\left( {{{\mu }_{n}},0} \right)$.
Последующая подстановка (2.13) в (1.8), где следует учесть ${{N}_{1}} \leqslant \infty $ слагаемых бесконечной суммы, приводит к ψ-параметризованной форме оптимального пространственно-временного управления:
(2.14)
$u{\text{*}}\left( {x,t} \right) = \frac{1}{2}\sum\limits_{n = 1}^M {{{K}_{n}}\left( {t,{{t}_{1}}} \right)\tilde {\psi }_{n}^{*}{{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right) + } \frac{1}{2}\sum\limits_{n = 1}^{{{N}_{1}}} {{{K}_{{1n}}}\left( {t,{{t}_{1}}} \right){{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right){{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right){\kern 1pt} } .$Таким образом, искомое программное управление находится, согласно (2.13), (2.14), с точностью до выбора оптимального вектора параметров $\psi _{*}^{{\left( M \right)}} = (\tilde {\psi }_{i}^{*})$, $i = \overline {1,M} $, в (2.8). К его определению и сводится последующая задача, которая может быть решена специальным методом параметрической оптимизации [5, 9, 16].
Переход к задаче полубесконечной оптимизации и метод ее решения. Интегрирование системы уравнений (2.5) с ψ-параметризованным модальным управлением вида (2.8), (2.13) позволяет получить зависимости $Q(x,{{\psi }^{{\left( M \right)}}})$ управляемой величины в конце процесса управления и критерия оптимальности ${{I}_{1}}({{\psi }^{{\left( M \right)}}})$ в (1.7), (1.9) для каждого значения $\bar {Q}\left( 0 \right)$ в форме явных функций только своих аргументов. В результате осуществляется точная редукция исходной задачи оптимального управления к задаче полубесконечной оптимизации (ЗПО) [5, 9, 16]:
(2.15)
${{I}_{1}}({{\psi }^{{\left( M \right)}}}) \to \mathop {\min }\limits_{{{\psi }^{{\left( M \right)}}}} ,$(2.16)
$\mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} {\text{|}}Q(x,{{\psi }^{{\left( M \right)}}}) - Q{\text{**}}\left( x \right){\text{|}} \leqslant \varepsilon $Для заданной величины $\varepsilon $ в (2.16) размерность M вектора ${{\psi }^{{\left( M \right)}}} = \left( {{{{\tilde {\psi }}}_{i}}} \right)$, $i = \overline {1,M} $, однозначно определяется соотношением [16]
(2.17)
$M = \omega \forall \varepsilon {\text{:}}\,\,\varepsilon _{{\min }}^{{\left( \omega \right)}} \leqslant \varepsilon < \varepsilon _{{\min }}^{{\left( {\omega - 1} \right)}},$(2.18)
$\varepsilon _{{\min }}^{{\left( \omega \right)}} = \mathop {\min }\limits_{{{\psi }^{{\left( \omega \right)}}}} \{ \mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} {\text{|}}Q(x,{{\psi }^{{\left( \omega \right)}}}) - Q{\text{**}}\left( x \right){\text{|}}\} $Задача (2.15), (2.16) оказывается разрешимой, если $\varepsilon \geqslant {{\varepsilon }_{{\inf }}}$. Здесь точная нижняя грань ${{\varepsilon }_{{\inf }}}$ достижимых значений $\varepsilon $ оказывается равной минимаксу $\varepsilon _{{\min }}^{{\left( \rho \right)}}$, где $\rho = \infty $ при ${{\varepsilon }_{{\inf }}} = 0$ и $\rho < \infty $ при ${{\varepsilon }_{{\inf }}} > 0$ соответственно для управляемых и неуправляемых объектов относительно заданного конечного состояния $Q{\text{**}}(x)$ [9].
Решение ЗПО (2.15), (2.16) относительно вектора параметров ${{\psi }^{{\left( M \right)}}}$, а также априори неизвестной величины минимакса $\varepsilon _{{\min }}^{{\left( M \right)}}$ в случае, когда в (2.16) $\varepsilon = \varepsilon _{{\min }}^{{\left( M \right)}}$, может быть получено альтернансным методом [5, 9, 16] в условиях малостеснительных допущений, которые всюду далее считаются выполненными.
Метод базируется на специальных альтернансных свойствах искомого вектора $\psi _{*}^{{\left( M \right)}}$, являющихся аналогом условий экстремума в теории чебышевских приближений, и дополнительной информации о форме кривой пространственного распределения оптимального результирующего состояния $Q(x,\psi _{*}^{{\left( M \right)}}) - Q{\text{**}}\left( x \right)$ управляемой величины, диктуемой закономерностями предметной области рассматриваемой задачи.
Согласно альтернансным свойствам, равные допустимой величине $\varepsilon $ одинаковые значения максимальных отклонений $\mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} {\text{|}}Q(x,\psi _{*}^{{\left( M \right)}}) - Q{\text{**}}\left( x \right){\text{|}}$ достигаются в некоторых точках $x_{j}^{0}$, $j = \overline {1,R} $, на отрезке $\left[ {{{x}_{0}},{{x}_{1}}} \right]$. Общее число R этих точек, удовлетворяющее базовым соотношениям
(2.19)
$R = \left\{ \begin{gathered} M,\,\,{\text{если}}\,\,\varepsilon _{{\min }}^{{\left( M \right)}} < \varepsilon < \varepsilon _{{\min }}^{{\left( {M - 1} \right)}}; \hfill \\ M + 1,\,\,{\text{если}}\,\,\varepsilon = \varepsilon _{{\min }}^{{\left( M \right)}}, \hfill \\ \end{gathered} \right.$(2.20)
$\left| {Q(x_{j}^{0},\psi _{*}^{{\left( M \right)}}) - Q{\text{**}}(x_{j}^{0})} \right| = \varepsilon ,\quad j = \overline {1,R} .$При наличии дополнительной информации из предметной области о форме кривой $Q(x,\psi _{*}^{{\left( M \right)}})$ на отрезке $\left[ {{{x}_{0}},{{x}_{1}}} \right] \ni x$, позволяющей идентифицировать координаты $x_{j}^{0}$ и знаки $Q(x_{j}^{0},\psi _{*}^{{\left( M \right)}})$, равенства (2.20), дополненные условиями существования экстремума функции $Q(x,\psi _{*}^{{\left( M \right)}})$ – $Q{\text{**}}(x)$ в точках $x_{{{{j}_{g}}}}^{0} \in \operatorname{int} \left[ {{{x}_{0}},{{x}_{1}}} \right]$, $g = \overline {1,{{R}_{1}}} $, где ${{R}_{1}} \leqslant R$ и $x_{{{{j}_{g}}}}^{0} \in \{ x_{j}^{0}\} $, переводятся в систему уравнений:
(2.21)
$\begin{gathered} Q(x_{j}^{0},\psi _{*}^{{\left( M \right)}}) - Q{\text{**}}(x_{j}^{0}) = \pm \varepsilon ,\quad j = \overline {1,R} , \\ \frac{\partial }{{\partial x}}[Q(x_{{{{j}_{g}}}}^{0},\psi _{*}^{{\left( M \right)}}) - Q{\text{**}}(x_{{{{j}_{g}}}}^{0})] = 0,\quad g = \overline {1,{{R}_{1}}} \\ \end{gathered} $Явное выражение для зависимости $Q(x_{j}^{0},\psi _{*}^{{\left( M \right)}})$ от своих аргументов в системе уравнений (2.21) представляется в форме бесконечной или укороченной суммы вида (1.10) разложения в ряд (1.7):
(2.22)
$Q(x_{j}^{0},\psi _{*}^{{\left( M \right)}}) = \sum\limits_{n = 1}^{{{N}_{1}}} {{{{\bar {Q}}}_{n}}({{\mu }_{n}},\psi _{*}^{{\left( M \right)}})} {{\varphi }_{n}}({{\mu }_{n}},x_{j}^{0}),$(2.23)
${{\bar {Q}}_{n}}({{\mu }_{n}},\psi _{*}^{{\left( M \right)}}) = {{B}_{n}}\left( {{{t}_{1}}} \right)\psi _{n}^{*}\left( {{{t}_{1}}} \right) + {{B}_{{1n}}}\left( {{{t}_{1}}} \right){{\bar {Q}}_{n}}\left( {{{\mu }_{n}},0} \right).$В итоге решение системы уравнений (2.21) с подстановкой (2.22), (2.23) полностью определяет искомый алгоритм программного пространственно-распределенного управления в форме (2.14).
3. Программное управление с ограничениями на характер его пространственно-временного распределения. Техническая реализация алгоритма управления (2.14), не стесняемого дополнительными условиями, накладываемыми на форму его пространственно-временного распределения, может оказаться затруднительной, прежде всего, в виду сложной зависимости $u{\text{*}}\left( {x,t} \right)$ от пространственной координаты. В такой ситуации часто используются отвечающие подобным условиям различные частные варианты представления ПВУВ, заведомо обеспечивающие их осуществимость стандартными техническими средствами [5, 12, 17].
3.1. Редукция к задаче многоканального сосредоточенного управления. Во многих типичных случаях $u\left( {x,t} \right)$ в (1.1) ищется в форме взвешенной суммы заранее фиксируемых проектными решениями объекта и заведомо технически реализуемых (чаще всего кусочно-постоянных) зависимостей ${{F}_{m}}\left( x \right)$, $m = \overline {1,s} $; $s \geqslant 1$, от пространственной координаты с весовыми коэффициентами, в роли которых выступают искомые сосредоточенные управляющие воздействия ${{\upsilon }_{m}}\left( t \right)$ [5, 12, 17]:
(3.1)
$u\left( {x,t} \right) = \sum\limits_{m = 1}^s {{{F}_{m}}\left( x \right){{\upsilon }_{m}}} \left( t \right),\quad s \geqslant 1.$Исследуемая задача оптимизации (1.1)–(1.5) с подстановкой (3.1) в (1.1) при s = 1 сводится к рассмотренной в [11] и является ее обобщением на случай многоканального управления при s > 1 в (3.1). Конечное интегральное преобразование равенства (3.1) приводит к следующему выражению для модальных управляющих воздействий ${{\bar {u}}_{n}}\left( {{{\mu }_{n}},t} \right)$ в (1.6) [5, 13, 17]:
(3.2)
${{\bar {u}}_{n}}\left( {{{\mu }_{n}},t} \right) = \sum\limits_{m = 1}^s {{{{\bar {F}}}_{{mn}}}\left( {{{\mu }_{n}}} \right)} {{\upsilon }_{m}}\left( t \right),\quad n = \overline {1,{{N}_{1}}} ,$При этом критерий оптимальности принимает вместо (1.9) следующий вид с учетом суммирования в подынтегральной функции квадратичного функционала качества эффекта многоканального управления:
(3.3)
${{I}_{1}}\left( \upsilon \right) = \int\limits_0^{{{t}_{1}}} {\left[ {{{\rho }_{Q}}\sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}\left( {{{\mu }_{n}},t} \right)} + \sum\limits_{m = 1}^s {\upsilon _{m}^{2}\left( t \right)} } \right]dt \to \mathop {\min }\limits_\upsilon } ,$Рассматриваемая задача оптимального программного управления сводится к определению s сосредоточенных управлений $\upsilon {\text{*}}\left( t \right) = (\upsilon _{m}^{*}\left( t \right))$, $m = \overline {1,s} $, переводящих объект управления (1.6)–(1.8), (3.2) в конечное состояние (1.10) при минимально возможном значении критерия оптимальности (3.3).
Структура оптимальных управлений $\upsilon _{m}^{*}\left( t \right)$ устанавливается с использованием аппарата принципа максимума Понтрягина по аналогичной разд. 2 схеме на основании базового условия вида (2.1), где теперь функция Понтрягина представляется вместо (2.2) в следующем виде:
(3.4)
$\begin{gathered} H\left( {\bar {Q}\left( t \right),\upsilon \left( t \right),\psi \left( t \right)} \right) = - {{\rho }_{Q}}\sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}} \left( {{{\mu }_{n}},t} \right) - \sum\limits_{m = 1}^s {\upsilon _{m}^{2}} + \\ + \,\sum\limits_{n = 1}^{{{N}_{1}}} {{{\psi }_{n}}} \left( t \right)\left( { - \mu _{n}^{2}{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right) + \sum\limits_{m = 1}^s {{{{\bar {F}}}_{{mn}}}\left( {{{\mu }_{n}}} \right)\upsilon _{m}^{{}}\left( t \right)} } \right). \\ \end{gathered} $Отсюда, получаем оптимальные программные управления
(3.5)
$\upsilon _{m}^{*}\left( t \right) = \frac{1}{2}\sum\limits_{n = 1}^{{{N}_{1}}} {{{{\bar {F}}}_{{mn}}}\psi _{n}^{*}\left( t \right)} = \frac{1}{2}{{\bar {F}}_{m}}\psi {\text{*}}\left( t \right);\quad {{\bar {F}}_{m}} = \left( {{{F}_{{mn}}}} \right),\quad m = \overline {1,s} {\kern 1pt} ,$Уравнения (1.6) с подстановкой управляющих воздействий в форме (3.2), (3.5) образуют совместно с уравнениями для сопряженных переменных (2.3) краевую задачу принципа максимума относительно $2{{N}_{1}}$ переменных ${{\bar {Q}}_{n}}$, ${{\psi }_{n}}$; $n = \overline {1,{{N}_{1}}} $ в отличие от (2.5):
(3.6)
$\begin{gathered} \frac{{d{{\psi }_{n}}}}{{dt}} = 2{{\rho }_{Q}}{{{\bar {Q}}}_{n}} + \mu _{n}^{2}{{\psi }_{n}}\left( t \right),\quad n = \overline {1,{{N}_{1}}} , \\ \frac{{d{{{\bar {Q}}}_{n}}}}{{dt}} = - \mu _{n}^{2}{{{\bar {Q}}}_{n}} + \frac{1}{2}\sum\limits_{m = 1}^s {{{{\bar {F}}}_{{mn}}}\left( {{{\mu }_{n}}} \right)} \sum\limits_{p = 1}^{{{N}_{1}}} {{{{\bar {F}}}_{{mp}}}\left( {{{\mu }_{p}}} \right)} {{\psi }_{p}}\left( t \right),\quad n = \overline {1,\,{{N}_{1}}} , \\ \end{gathered} $(3.7)
$\left[ {\begin{array}{*{20}{c}} {\psi \left( t \right)} \\ {\bar {Q}\left( t \right)} \end{array}} \right] = {{e}^{{At}}}\left[ {\begin{array}{*{20}{c}} {\psi \left( 0 \right)} \\ {\bar {Q}\left( 0 \right)} \end{array}} \right];\quad \psi \left( t \right) = \left( {{{\psi }_{n}}\left( t \right)} \right);\quad \bar {Q}\left( t \right) = \left( {{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right)} \right);\quad n = \overline {1,{{N}_{1}}} $(3.8)
${{e}^{{At}}} = \left[ {\begin{array}{*{20}{c}} {{{A}_{{11}}}\left( t \right)}&{{{A}_{{12}}}\left( t \right)} \\ {{{A}_{{21}}}\left( t \right)}&{{{A}_{{22}}}\left( t \right)} \end{array}} \right].$Здесь Aij, i, $j = 1,2$, – известные матрицы размерности ${{N}_{1}} \times {{N}_{1}}$ в соответствии со структурой системы уравнений (3.6) [11].
Дальнейшее решение рассматриваемой задачи программного управления проводится по предложенной в [11] схеме, обобщающей результаты (2.8)–(2.23) на исследуемый случай многоканального управления.
На первом этапе осуществляется ψ-параметризация управлений (3.5) на конечномерном подмножестве значений ${{\psi }_{n}}\left( {{{t}_{1}}} \right)$, $n = \overline {1,M} $, согласно соотношениям (2.8). Затем путем, указанным в [11], находится вместо (2.9), (2.10) линейная зависимость вектора ψ*(t) в оптимальном процессе от его параметризуемой, согласно (2.8), конечной величины ψ*(t1) и начального состояния объекта $\bar {Q}\left( 0 \right)$:
(3.9)
$\psi {\text{*}}\left( t \right) = K\left( {t,{{t}_{1}}} \right)\psi {\text{*}}\left( {{{t}_{1}}} \right) + {{K}_{1}}\left( {t,{{t}_{1}}} \right)\bar {Q}\left( 0 \right),$(3.10)
$\begin{gathered} K\left( {t,{{t}_{1}}} \right) = {{{\hat {A}}}_{{11}}}\left( {{{t}_{1}} - t} \right) + {{{\hat {A}}}_{{12}}}\left( {{{t}_{1}} - t} \right)B\left( {{{t}_{1}}} \right);\quad {{K}_{1}}\left( {t,{{t}_{1}}} \right) = {{{\hat {A}}}_{{12}}}\left( {{{t}_{1}} - t} \right){{B}_{1}}\left( {{{t}_{1}}} \right), \\ B\left( {{{t}_{1}}} \right) = {{A}_{{21}}}\left( {{{t}_{1}}} \right)A_{{11}}^{{ - 1}}\left( {{{t}_{1}}} \right);\quad {{B}_{1}}\left( {{{t}_{1}}} \right) = {{A}_{{22}}}\left( {{{t}_{1}}} \right) - {{A}_{{21}}}\left( {{{t}_{1}}} \right)A_{{11}}^{{ - 1}}\left( {{{t}_{1}}} \right){{A}_{{12}}}\left( {{{t}_{1}}} \right) \\ \end{gathered} $Искомое программное управление (3.5) находится в ψ-параметризуемой форме после подстановки в (3.5) выражения (3.9):
(3.11)
$\upsilon _{m}^{*}\left( t \right) = \frac{1}{2}{{\bar {F}}_{m}}\left[ {K\left( {t,{{t}_{1}}} \right)\psi {\text{*}}\left( {{{t}_{1}}} \right) + {{K}_{1}}\left( {t,{{t}_{1}}} \right)\bar {Q}\left( 0 \right)} \right],\quad m = \overline {1,s} .$Дальнейшая проблема сводится к определению оптимального вектора параметров $\psi _{*}^{{\left( M \right)}}$ в составе вектора $\psi {\text{*}}\left( {{{t}_{1}}} \right)$ в (2.8) путем редукции к задаче полубесконечной оптимизации (2.15), (2.16). Альтернансные свойства (2.17)–(2.19) ее решений опять порождают замкнутую систему равенств (2.20), где в отличие от случая автономного модального управления по всем ${{\bar {u}}_{n}}$, $n = \overline {1,{{N}_{1}}} $, зависимость $Q(x,\psi _{*}^{{\left( M \right)}})$ в виде явной функции своих аргументов определяется для вектора $\bar {Q}\left( {{{t}_{1}}} \right) = \bar {Q}(\psi _{*}^{{\left( M \right)}})$ в (1.7) интегрированием системы уравнений (3.6) с подстановкой $\psi {\text{*}}\left( t \right)$ в параметризованной форме (3.9). При этом покоординатное представление ${{\bar {Q}}_{n}}({{\mu }_{n}},\psi _{*}^{{\left( M \right)}})$ в (2.23) заменяется векторным равенством [11]
(3.12)
$\bar {Q}{\text{*}}\left( {{{t}_{1}}} \right) = B\left( {{{t}_{1}}} \right)\psi {\text{*}}\left( {{{t}_{1}}} \right) + {{B}_{1}}\left( {{{t}_{1}}} \right)\bar {Q}\left( 0 \right)$(3.13)
$Q(x,\psi _{*}^{{\left( M \right)}}) = \Phi \bar {Q}{\text{*}}\left( {{{t}_{1}}} \right);\quad \Phi = \left[ {{{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right)} \right],\quad n = \overline {1,{{N}_{1}}} .$Система равенств (2.20) опять сводится к однозначно формулируемой системе уравнений вида (2.21), решение которой относительно всех искомых неизвестных известными численными методами исчерпывает решение исходной задачи программного управления (1.6)–(1.8), (1.10), (3.2), (3.3).
Если можно ограничиться учетом только ${{N}_{1}} = N$ мод ${{\bar {Q}}_{n}}$ при $n = \overline {1,N} $ в (1.6) и если возможен выбор s = N в (3.1), то равенства (3.2) при $n = \overline {1,N} $, N = s образуют линейную систему уравнений относительно $\upsilon _{m}^{*}\left( t \right)$, $m = \overline {1,s} $, для заданных значений $\bar {u}_{n}^{*}\left( {{{\mu }_{n}},t} \right)$ в (2.13), решение которой определяется формулами Крамера непосредственно по решению задачи с автономными модальными управлениями:
(3.14)
$\upsilon _{m}^{*}\left( t \right) = \sum\limits_{т = 1}^s {\frac{{{{D}_{{mn}}}}}{D}\bar {u}_{n}^{*}} \left( {{{\mu }_{n}},t} \right),\quad m = \overline {1,s} .$Здесь $D = \det \left[ {{{{\bar {F}}}_{{mn}}}} \right]$, $m$, $n = \overline {1,s} $; Dmn – алгебраическое дополнение n-го элемента m-го столбца D, и $D \ne 0$ при линейно независимых функциях ${{F}_{m}}\left( x \right)$.
3.2. Оптимизация проектных решений. В частном варианте
c заданной функцией $F\left( t \right)$ и неизменяемым во времени пространственным управляющим воздействием $\upsilon \left( x \right)$, в роли которого рассматриваются искомые проектные решения объекта, следует принять в (1.6):(3.16)
$\bar {u}_{n}^{{}}\left( {{{\mu }_{n}},t} \right) = F\left( t \right){{\bar {\upsilon }}_{n}}.$Здесь ${{\bar {\upsilon }}_{n}}$ – постоянные во времени моды управления $\upsilon \left( x \right)$, восстанавливаемого по значениям ${{\bar {\upsilon }}_{n}}$ подобно (1.8):
(3.17)
$\upsilon \left( x \right) = \sum\limits_{n = 1}^{{{N}_{1}}} {{{{\bar {\upsilon }}}_{n}}} {{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right).$Величины ${{\bar {\upsilon }}_{n}}$ следует рассматривать далее в качестве автономных модальных управлений вместо ${{\bar {u}}_{n}}$ в (1.6). Критерий оптимизации принимает в данном случае вместо (3.3) следующий вид:
(3.18)
${{I}_{1}}\left( {\bar {\upsilon }} \right) = \int\limits_0^{{{t}_{1}}} {{{\rho }_{Q}}} \sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}\left( {{{\mu }_{n}},t} \right)} dt + \sum\limits_{n = 1}^{{{N}_{1}}} {\bar {\upsilon }_{n}^{2}} \to \mathop {\min }\limits_{\bar {\upsilon }} ;\quad \bar {\upsilon } = \left( {{{{\bar {\upsilon }}}_{n}}} \right),\quad n = \overline {1,{{N}_{1}}} ,$Действительно, для одинаковых конечных значений ${{\bar {u}}_{n}}\left( {{{\mu }_{n}},{{t}_{1}}} \right)$ в (2.4) и (3.16) получаем равенство
Последующее представление $\bar {\upsilon }$ по правилу (2.8) приводит к описанию $\upsilon \left( x \right)$ в виде укороченной суммы M первых слагаемых в (3.17):
(3.19)
$\upsilon \left( x \right) = \sum\limits_{n = 1}^M {{{{\tilde {\upsilon }}}_{n}}{{\varphi }_{n}}} \left( {{{\mu }_{n}},x} \right),$(3.20)
${{\bar {\upsilon }}_{n}} = {{\tilde {\upsilon }}_{n}},\quad n = \overline {1,M} ;\quad {{\bar {\upsilon }}_{n}} = 0,\quad n > M.$В таком случае рассматриваемая задача оптимального управления непосредственно редуцируется к задаче полубесконечной оптимизации вида (2.15), (2.16):
(3.21)
$\begin{gathered} {{I}_{1}}({{{\bar {\upsilon }}}^{{\left( M \right)}}}) \to \mathop {\min }\limits_{{{{\bar {\upsilon }}}^{{\left( M \right)}}}} , \\ \mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} {\text{|}}Q(x,{{{\bar {\upsilon }}}^{{\left( M \right)}}}) - Q{\text{**}}\left( x \right){\text{|}} \leqslant \varepsilon \\ \end{gathered} $(3.22)
$\varepsilon _{{\min }}^{{\left( \omega \right)}} = \mathop {\min }\limits_{{{{\bar {\upsilon }}}^{{\left( \omega \right)}}}} \left\{ {\mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} \left| {Q\left( {x,{{{\bar {\upsilon }}}^{{\left( \omega \right)}}}} \right) - {{Q}^{{**}}}\left( x \right)} \right|} \right\}$.Явная форма зависимости $Q(x,{{\bar {\upsilon }}^{{\left( M \right)}}})$ от своих аргументов в (3.21) определяется в форме ряда (1.7) при значениях ${{\bar {Q}}_{n}}\left( {{{\mu }_{n}},{{t}_{1}}} \right)$, которые находятся интегрированием уравнений объекта (1.6) в условиях (3.16), (3.20):
(3.23)
$\begin{gathered} {{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},{{t}_{1}}} \right) = {{{\bar {Q}}}^{{\left( 0 \right)}}}\left( {{{\mu }_{n}}} \right){{e}^{{ - \mu _{n}^{2}{{t}_{1}}}}} + {{d}_{n}}\left( {{{t}_{1}}} \right){{{\bar {\upsilon }}}_{n}},\quad {{{\bar {\upsilon }}}_{n}} = {{{\tilde {\upsilon }}}_{n}},\quad n = \overline {1,M} ;\quad {{{\bar {\upsilon }}}_{n}} = 0,\quad n = \overline {M + 1,{{N}_{1}}} , \\ {{d}_{n}}\left( {{{t}_{1}}} \right) = \int\limits_0^{{{t}_{1}}} {F\left( t \right)} {{e}^{{ - \mu _{n}^{2}\left( {{{t}_{1}} - t} \right)}}}dt. \\ \end{gathered} $Решение ЗПО (3.21) по схеме альтернансного метода с последующей подстановкой результатов в (3.19) определяет искомую зависимость $\upsilon {\text{*}}\left( x \right)$. Если, подобно (2.14), техническая реализация проектного решения в форме (3.17), (3.19) оказывается затруднительной, то подобно (3.1) поиск $\upsilon \left( x \right)$ производится в классе заведомо реализуемых функций ${{F}_{m}}\left( x \right)$, суммируемых с весовыми коэффициентами hm:
Тогда в (3.16) следует принять аналогично (3.2)
(3.25)
${{\bar {\upsilon }}_{n}} = \sum\limits_{m = 1}^s {{{h}_{m}}{{{\bar {F}}}_{{mn}}}} ,\quad n = \overline {1,{{N}_{1}}} .$Критерий оптимальности представляется в отличной от (3.18) форме
(3.26)
${{I}_{1}}\left( h \right) = \int\limits_0^{{{t}_{1}}} {{{\rho }_{Q}}} \sum\limits_{n = 1}^{{{N}_{1}}} {\bar {Q}_{n}^{2}\left( {{{\mu }_{n}},t} \right)} dt + \sum\limits_{n = 1}^{{{N}_{1}}} {{{{\left( {\sum\limits_{m = 1}^s {{{h}_{m}}{{{\bar {F}}}_{{mn}}}} } \right)}}^{2}}} \to \mathop {\min }\limits_h ,\quad h = \left( {{{h}_{m}}} \right),\quad m = \overline {1,s} ,$(3.27)
$\begin{gathered} {{I}_{1}}\left( h \right) \to \mathop {\min }\limits_h ,\quad h = \left( {{{h}_{m}}} \right),\quad m = \overline {1,s} , \\ \mathop {\max }\limits_{x \in \left[ {{{x}_{0}},{{x}_{1}}} \right]} \left| {Q\left( {x,h} \right) - Q{\text{**}}\left( x \right)} \right| \leqslant \varepsilon , \\ \end{gathered} $Если требуется выбрать значения hm в (3.24) из условий достижения величины $\bar {\upsilon }_{*}^{{\left( M \right)}}$ в задаче (3.21), то такой выбор реализуется только в условиях ${{N}_{1}} = M \leqslant s$ путем определения искомых коэффициентов $h_{m}^{*}$ в подобной (3.14) форме решения относительно $h_{m}^{*}$ линейной системы уравнений, образуемой равенствами (3.25) при ${{N}_{1}} = M = s$ для заданных величин $\bar {\upsilon }_{n}^{*}$, $n = \overline {1,s} $. Следовательно, достижимые значения $\varepsilon $ в (3.27) ограничиваются в таком случае реализуемым числом s в (3.24).
4. Синтез оптимального управления. Рассмотрим далее задачу синтеза пространственно-временного оптимального управления $u{\text{*}}\left( {\bar {Q},x,t} \right)$ с обратными связями по состоянию объекта при известных алгоритмах программных управляющих воздействий.
4.1. Синтез оптимального регулятора с модальными управляющими воздействиями. Перенос граничных условий при $t = {{t}_{1}}$ в произвольный момент времени $t \in \left[ {0,{{t}_{1}}} \right)$ определяет, подобно [11], в краевой задаче (2.5) следующие зависимости конечных значений сопряженных переменных $\psi _{n}^{*}\left( {{{t}_{1}}} \right)$ и временных мод $\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},{{t}_{1}}} \right)$ от их текущих значений в оптимальном процессе $(\bar {Q}_{n}^{*}({{\mu }_{n}},t),\psi _{n}^{*}(t))$ для всех $n = \overline {1,{{N}_{1}}} $:
(4.1)
$\psi _{n}^{*}\left( {{{t}_{1}}} \right) = {{A}_{{n11}}}\left( {{{t}_{1}} - t} \right)\psi _{n}^{*}\left( t \right) + {{A}_{{n12}}}\left( {{{t}_{1}} - t} \right)\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},t} \right),$(4.2)
$\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},{{t}_{1}}} \right) = {{A}_{{n21}}}\left( {{{t}_{1}} - t} \right)\psi _{n}^{*}\left( t \right) + {{A}_{{n22}}}\left( {{{t}_{1}} - t} \right)\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},t} \right),$После умножения равенств (4.1), (4.2) соответственно на известные, согласно результатам расчета программного управления значения $\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},{{t}_{1}}} \right) = \bar {Q}_{n}^{*}({{\mu }_{n}},\psi _{*}^{{\left( M \right)}})$ и $\psi _{n}^{*}\left( {{{t}_{1}}} \right)$ в (2.8), (2.23), левые части соотношений (4.1), (4.2) становятся одинаковыми. Последующее вычитание этих уравнений приводит к следующему результату:
(4.3)
$\begin{gathered} \psi _{n}^{*}(t,\psi _{n}^{*}\left( {{{t}_{1}}} \right),{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},0} \right),\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},t} \right)) = {{T}_{{n1}}}(t,{{t}_{1}},\psi _{n}^{*}\left( {{{t}_{1}}} \right),\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},{{t}_{1}}} \right)) \times \\ \times \,{{T}_{{n2}}}(t,{{t}_{1}},\psi _{n}^{*}\left( {{{t}_{1}}} \right),\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},{{t}_{1}}} \right))\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},t} \right),\quad n = \overline {1,{{N}_{1}}} ; \\ \end{gathered} $(4.4)
${{T}_{{n1}}} = {{[\bar {Q}_{n}^{*}\left( {{{\mu }_{n}},{{t}_{1}}} \right){{A}_{{n11}}}\left( {{{t}_{1}} - t} \right) - \psi _{n}^{*}\left( {{{t}_{1}}} \right){{A}_{{n21}}}\left( {{{t}_{1}} - t} \right)]}^{{ - 1}}};$(4.5)
${{T}_{{n2}}} = \psi _{n}^{*}\left( {{{t}_{1}}} \right){{A}_{{n22}}}\left( {{{t}_{1}} - t} \right) - \bar {Q}_{n}^{*}\left( {{{\mu }_{n}},{{t}_{1}}} \right){{A}_{{n12}}}\left( {{{t}_{1}} - t} \right),$Подстановка (4.3) в выражение (2.4) для автономного программного управления приводит к линейному закону синтеза оптимального пространственно-временного управляющего воздействия в форме (1.8) с нестационарными коэффициентами обратных связей по измеряемому состоянию $\bar {Q}\left( t \right) = \left( {{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right)} \right)$, $n = \overline {1,{{N}_{1}}} $:
(4.6)
$u{\text{*}}\left( {\bar {Q}\left( t \right),x,t} \right) = \frac{1}{2}\sum\limits_{n = 1}^{{{N}_{1}}} {{{T}_{{n1}}}{{T}_{{n2}}}{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right)} {{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right).$Значения ${{T}_{{n1}}}$ и ${{T}_{{n2}}}$ представляются, согласно (4.4), (4.5), известными функциями времени с фиксируемыми на протяжении процесса управления величинами ${{\bar {Q}}_{n}}\left( {{{\mu }_{n}},0} \right)$ в (2.23), которые находятся по результатам наблюдения $\bar {Q}\left( t \right)$ в момент t = 0.
Переход в (4.6) от $\bar {Q}\left( t \right)$ к измеряемому выходу объекта ${{Q}_{u}}({{x}_{u}},t)\, = \,(Q({{x}_{{uj}}},t))$ в r точках ${{x}_{{uj}}} \in [{{x}_{0}},{{x}_{1}}]$, $j = \overline {1,r} $, определяется, согласно (1.7), векторно-матричным уравнением наблюдения
(4.7)
${{Q}_{u}}\left( {{{x}_{u}},t} \right) = {{\Phi }_{u}}\bar {Q}\left( t \right);\quad {{\Phi }_{u}} = \left[ {{{\varphi }_{n}}\left( {{{\mu }_{n}},{{x}_{{uj}}}} \right)} \right],\quad n = \overline {1,{{N}_{1}}} ;\quad j = \overline {1,r} .$В условиях $r < {{N}_{1}}$ неполного измерения состояния для восстановления вектора $\bar {Q}\left( t \right)$ по значениям ${{Q}_{u}}\left( {{{x}_{u}},t} \right)$ требуется построение наблюдателя полного или пониженного порядка [17].
Если по условиям требуемой точности моделирования объекта (1.6) можно ограничиться учетом только M первых составляющих $\bar {Q}\left( t \right) = \left( {{{{\bar {Q}}}_{n}}\left( {{{\mu }_{n}},t} \right)} \right)$, $n = \overline {1,M} $, с минимальным их числом $M < {{N}_{1}}$, необходимым для решения системы уравнений (2.21) относительно вектора $\psi _{*}^{{\left( M \right)}}$, то $\bar {Q}\left( t \right)$ непосредственно определяется решением уравнения (4.7) относительно $\bar {Q}\left( t \right)$ при $r = M$, ${{N}_{1}} = N = M$:
Подстановка (4.8) в (4.6) приводит к линейному алгоритму синтеза по измеряемому выходу объекта:
(4.9)
$\begin{gathered} u{\text{*}}\left( {{{Q}_{u}},x,t} \right) = \frac{1}{2}\Phi _{u}^{{ - 1}}{{Q}_{u}}\left( {{{x}_{u}},t} \right)\varphi \left( {x,t} \right), \\ \varphi \left( {x,t} \right) = \left( {{{T}_{{n1}}}{{T}_{{n2}}}{{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right)} \right),\quad n = \overline {1,M} , \\ \end{gathered} $4.2. Синтез оптимального регулятора с многоканальным сосредоточенным управлением. При затруднениях в решении задачи синтеза алгоритмов оптимального управления (4.6), (4.9), связанных со сложным характером зависимости u* от x и использованием в связи с этим заведомо реализуемых управляющих воздействий вида (3.1), возникает задача аналитического конструирования оптимальных регуляторов для многоканальных сосредоточенных управлений ${{\upsilon }_{m}}\left( t \right)$ при $s > 1$.
Обобщение зависимостей (4.1)–(4.5) на этот случай приводит к соответствующим векторно-матричным равенствам, базирующимся на описании оптимального процесса решениями (3.7), (3.8) краевой задачи (3.6) [11]:
(4.10)
$\psi {\text{*}}\left( {{{t}_{1}}} \right) = {{A}_{{11}}}\left( {{{t}_{1}} - t} \right)\psi {\text{*}}\left( t \right) + {{A}_{{12}}}\left( {{{t}_{1}} - t} \right)\bar {Q}{\text{*}}\left( t \right),$(4.11)
$\bar {Q}{\text{*}}\left( {{{t}_{1}}} \right) = {{A}_{{21}}}\left( {{{t}_{1}} - t} \right)\psi {\text{*}}\left( t \right) + {{A}_{{22}}}\left( {{{t}_{1}} - t} \right)\bar {Q}{\text{*}}\left( t \right).$Умножение слева равенств (4.10) и (4.11) соответственно на известные по решениям задачи многоканального программного управления ${{N}_{1}} \times {{N}_{1}}$-матрицы ${\text{diag}}{\kern 1pt} {\kern 1pt} [\bar {Q}_{j}^{*}({{\mu }_{j}},{{t}_{1}})]$, $\bar {Q}{\text{*}}\left( {{{t}_{1}}} \right) = (\bar {Q}_{j}^{*}\left( {{{\mu }_{j}},{{t}_{1}}} \right))$, $j = \overline {1,{{N}_{1}}} $, и ${\text{diag}}[\psi _{j}^{*}\left( {{{t}_{1}}} \right)]$, $\psi {\text{*}}\left( {{{t}_{1}}} \right) = (\psi _{j}^{*}\left( {{{t}_{1}}} \right))$, $j = \overline {1,{{N}_{1}}} $, и последующее вычитание результатов приводит вместо (4.3) к базовому векторному соотношению
(4.12)
$\psi {\text{*}}\left( {t,\psi {\text{*}}\left( {{{t}_{1}}} \right),\bar {Q}\left( 0 \right),\bar {Q}{\text{*}}\left( t \right)} \right) = {{T}_{1}}\left( {t,{{t}_{1}},\psi {\text{*}}\left( {{{t}_{1}}} \right),\bar {Q}{\text{*}}\left( {{{t}_{1}}} \right)} \right){{T}_{2}}\left( {t,{{t}_{1}},\psi {\text{*}}\left( {{{t}_{1}}} \right),\bar {Q}{\text{*}}\left( {{{t}_{1}}} \right)} \right)\bar {Q}{\text{*}}\left( t \right),$(4.13)
${{T}_{1}} = {{\left[ {{{W}_{1}}{{A}_{{11}}}\left( {{{t}_{1}} - t} \right) - {{W}_{2}}{{A}_{{21}}}\left( {{{t}_{1}} - t} \right)} \right]}^{{ - 1}}}$,(4.14)
${{T}_{2}} = \left[ {{{W}_{2}}{{A}_{{22}}}\left( {{{t}_{1}} - t} \right) - {{W}_{1}}{{A}_{{12}}}\left( {{{t}_{1}} - t} \right)} \right]$,(4.15)
${{W}_{1}} = {\text{diag}}{\kern 1pt} {\kern 1pt} [\bar {Q}_{j}^{*}\left( {{{\mu }_{j}},{{t}_{1}}} \right)],\quad {{W}_{2}} = {\text{diag}}{\kern 1pt} {\kern 1pt} [\psi _{j}^{*}\left( {{{t}_{1}}} \right)],\quad j = \overline {1,{{N}_{1}}} ,$(4.16)
$\bar {Q}_{j}^{*}\left( {{{\mu }_{j}},{{t}_{1}}} \right) = {{\left( {B\left( {{{t}_{1}}} \right)\psi {\text{*}}\left( {{{t}_{1}}} \right) + {{B}_{1}}\left( {{{t}_{1}}} \right)\bar {Q}\left( 0 \right)} \right)}_{j}},\quad j = \overline {1,{{N}_{1}}} ,$Подстановка (4.12) в (3.5) определяет линейный с нестационарными коэффициентами алгоритм синтеза для сосредоточенных управлений с обратными связями по $\bar {Q}\left( t \right)$
(4.17)
$\upsilon _{m}^{*}\left( {\bar {Q}\left( t \right),t} \right) = \frac{1}{2}{{\bar {F}}_{m}}\psi {\text{*}}\left( t \right) = \frac{1}{2}{{\bar {F}}_{m}}{{T}_{1}}{{T}_{2}}\bar {Q}\left( t \right),\quad m = \overline {1,s} ,$(4.18)
$u{\text{*}}\left( {\bar {Q},x,t} \right) = \frac{1}{2}\sum\limits_{m = 1}^s {{{{\bar {F}}}_{m}}} {{T}_{1}}{{T}_{2}}\bar {Q}\left( t \right){{F}_{m}}\left( x \right).$В условиях ${{N}_{1}} = N = M = r$ в (4.7) вектор $\bar {Q}{\text{*}}\left( t \right)$ в (4.18) находится непосредственно по измеряемому выходу объекта, согласно (4.8). После подстановки (4.8) в (4.18) получаем оптимальное управление с линейной обратной связью по управляемой величине:
(4.19)
$u{\text{*}}\left( {{{Q}_{u}},x,t} \right) = \frac{1}{2}\sum\limits_{m = 1}^s {{{{\bar {F}}}_{m}}} {{T}_{1}}{{T}_{2}}\Phi _{u}^{{ - 1}}{{Q}_{u}}\left( {{{x}_{u}},t} \right){{F}_{m}}\left( x \right).$Здесь в (4.19) аналогично (4.6) матрицы ${{T}_{1}}$, ${{T}_{2}}$ вычисляются с фиксируемыми на протяжении процесса управления значениями $\bar {Q}\left( 0 \right)$ в (4.16), которые задаются по измерениям начального состояния объекта при $t = 0$.
5. Пространственно-временное управление нестационарным процессом теплопроводности. В качестве примера, представляющего самостоятельный интерес, рассмотрим задачу аналитического конструирования оптимального регулятора для пространственно-временного управления процессом нагрева неограниченной пластины.
Пусть температурное поле Q(x, t) пластины в процессе ее нагрева описывается линейным неоднородным уравнением теплопроводности вида (1.1)–(1.3) в относительных единицах [10, 13]:
(5.1)
$\frac{{\partial Q\left( {x,t} \right)}}{{\partial t}} = \frac{{{{\partial }^{2}}Q\left( {x,t} \right)}}{{\partial {{x}^{2}}}} + u\left( {x,t} \right),\quad 0 \leqslant x \leqslant 1,\quad t \in \left[ {0,t{\text{*}}} \right],$(5.3)
$\frac{{\partial Q\left( {0,t} \right)}}{{\partial t}} = 0,\quad \frac{{\partial Q\left( {1,t} \right)}}{{\partial t}} + \alpha Q\left( {1,t} \right) = 0,$В пространстве модальных переменных ${{\bar {Q}}_{n}}\left( {{{\mu }_{n}},t} \right)$, $n = 1,2,...$, объект управления (5.1)–(5.3) описывается бесконечной системой уравнений (1.6) с автономными управлениями ${{\bar {u}}_{n}}\left( {{{\mu }_{n}},t} \right)$. Температурное поле Q(x, t) представляется его разложением в ряд вида (1.7) по собственным функциям ${{\varphi }_{n}}\left( {{{\mu }_{n}},x} \right) = \cos \left( {{{\mu }_{n}}x} \right)$ [10, 13]:
(5.4)
$Q\left( {x,t} \right) = \sum\limits_{n = 1}^\infty {\frac{{2{{\alpha }^{2}}\cos \left( {{{\mu }_{n}}x} \right)}}{{(\mu _{n}^{2} + {{\alpha }^{2}} + \alpha ){{{\sin }}^{2}}{{\mu }_{n}}}}} {{\bar {Q}}_{n}}\left( {{{\mu }_{n}},t} \right),$Задача заключается в определении алгоритма обратной связи $u{\text{*}}\left( {Q,x,t} \right)$, обеспечивающего перевод объекта (1.6), (5.4) за заданное время ${{t}_{1}}$ в требуемое конечное состояние $Q{\text{**}}(x) = Q{\text{**}}$ = = const > Q0 с заданной точностью равномерного приближения ε, согласно (1.10), при минимальном значении квадратичного критерия качества (1.9), где примем ${{\rho }_{Q}} = 1$.
Аналитический синтез оптимального регулятора сводится на первом этапе к вычислению программного управления u*(x, t) описанным в разд. 2 способом с последующим определением $u{\text{*}}\left( {Q,x,t} \right)$ при найденном управлении путем, указанным в разд. 4.1.
Определение программного управления. Решение краевой задачи (2.5) в форме (2.6) полностью определяется значениями элементов ${{A}_{{nks}}}$, k, $s = 1,2$, 2 × 2-матрицы ${{e}^{{{{A}_{n}}t}}}$ в (2.7). Используя технологию вычисления матричной экспоненты, описанную в [11], получаем следующие выражения для ${{A}_{{nks}}}$ в (2.7):
(5.6)
${{A}_{{nks}}}\left( t \right) = \sum\limits_{i = 1}^2 {\gamma _{k}^{{\left( i \right)}}G_{i}^{{\left( s \right)}}{{e}^{{{{p}_{i}}t}}}} ;\quad k,s = 1,2$Здесь
(5.7)
$\gamma _{1}^{{\left( i \right)}} = 1;\quad \gamma _{2}^{{\left( i \right)}} = \frac{1}{{2(\mu _{n}^{2} + {{p}_{i}})}},\quad i = 1,2;$(5.8)
$G_{i}^{{\left( s \right)}} = \frac{{{{G}_{{is}}}}}{G};\quad G = \det \left[ {\begin{array}{*{20}{c}} {\gamma _{1}^{{\left( 1 \right)}}}&{\gamma _{1}^{{\left( 2 \right)}}} \\ {\gamma _{2}^{{\left( 1 \right)}}}&{\gamma _{2}^{{\left( 2 \right)}}} \end{array}} \right];$Явная форма параметрического представления модальных управляющих воздействий ${{\bar {u}}_{n}}({{\mu }_{n}},t)$ и искомого программного управления $u{\text{*}}\left( {x,t} \right)$ на подмножестве M-мерных векторов ${{\psi }^{{\left( M \right)}}}$ в (2.8) описывается выражениями (2.13) и (2.14) соответственно, где ${{K}_{n}}\left( {t,{{t}_{1}}} \right)$, ${{K}_{{1n}}}\left( {t,{{t}_{1}}} \right)$ вычисляются по формулам (2.10) при значениях ${{A}_{{nks}}}$, определяемых, согласно (5.6)–(5.9).
Последующий переход к задаче полубесконечной оптимизации (2.15), (2.16) приводит в силу альтернансных свойств (2.19) к замкнутой системе равенств (2.20) относительно оптимальной величины $\psi _{*}^{{\left( M \right)}}$ вектора ${{\psi }^{{\left( M \right)}}}$, где $Q(x_{j}^{0},\psi _{*}^{{\left( M \right)}})$ описывается разложением в ряд (2.22), (2.23). Последний представляется в форме (5.4) с учетом соотношений (2.11) для коэффициентов ${{B}_{n}}\left( {{{t}_{1}}} \right)$, ${{B}_{{1n}}}\left( {{{t}_{1}}} \right)$, которые вычисляются опять по значениям ${{A}_{{nks}}}$ в (5.6)–(5.9).
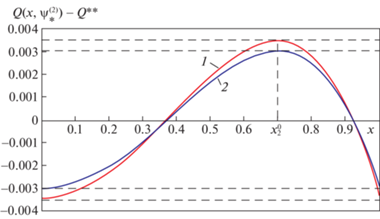
Ограничимся далее типичным в приложениях случаем $\varepsilon = \varepsilon _{{\min }}^{{\left( 2 \right)}}$ в (2.16), (2.20), для которого, согласно (2.17), (2.19), следует принять $M = 2$, $R = 3$ в (2.14), (2.20)–(2.23).
Физические закономерности поведения нестационарных температурных полей в оптимальном процессе управления нагревом пластины и альтернансные свойства $Q(x,\psi _{*}^{{\left( 2 \right)}})$, требующие выполнения строгих равенств в (2.20) в трех точках $x_{j}^{0} \in [0,\,1],\,j = 1,\,2,\,3$, при R = 3, определяют в таком случае при ${{Q}_{0}} = {\text{const}}$ в (1.2), подобно [5, 9, 10, 12], форму кривой $Q(x,\psi _{*}^{{\left( 2 \right)}}) - Q{\text{**}}$ результирующего распределения температуры по пространственной координате (см. далее рис. 1). Это позволяет перевести равенства (2.20) в систему уравнений (2.21) с заведомо идентифицируемыми точками $x_{1}^{0} = 0$; $x_{2}^{0} \in \left( {0,1} \right)$; $x_{3}^{0} = 1$ и знаками $Q(x_{j}^{0},\psi _{*}^{{\left( 2 \right)}}) - Q{\text{**}}$:
(5.10)
$Q(1,\psi _{*}^{{\left( 2 \right)}}) - Q{\text{**}} = - \varepsilon _{{\min }}^{{\left( 2 \right)}};\quad \frac{{\partial Q(x_{2}^{0},\psi _{*}^{{\left( 2 \right)}})}}{{\partial x}} = 0,$Рис. 1.
Температурные распределения в конце оптимального процесса пространственно-временного управления
Последующая подстановка $\psi _{*}^{{\left( M \right)}} = \psi _{*}^{{\left( 2 \right)}}$ в (2.13), (2.14) окончательно определяет искомое программное управление в рассматриваемой задаче оптимизации.
Синтез оптимального регулятора. Искомый алгоритм $u{\text{*}}\left( {\bar {Q}\left( t \right),x,t} \right)$ обратной связи определяется по найденному программному управлению уравнением регулятора (4.6) в условиях $M = 2$ в (2.8), (2.23). Если в первом приближении достаточно учесть только две моды ${{\bar {Q}}_{n}}\left( {{{\mu }_{n}},t} \right)$, $n = 1,2$, в выражении (5.4) при ${{N}_{1}} = N = M = 2$, то при наличии двух измерителей состояния $Q({{x}_{u}},t)\, = \,(Q({{x}_{{uj}}},t))$, $j = 1,2$, где, в соответствии с (4.7)
(5.11)
$Q\left( {{{x}_{{uj}}},t} \right) = {{\bar {Q}}_{1}}\left( {{{\mu }_{1}},t} \right){{\varphi }_{1}}\left( {{{\mu }_{1}},{{x}_{{uj}}}} \right) + {{\bar {Q}}_{2}}\left( {{{\mu }_{2}},t} \right){{\varphi }_{2}}\left( {{{\mu }_{2}},{{x}_{{uj}}}} \right),\quad j = 1,2,$(5.12)
${{\varphi }_{n}}\left( {{{\mu }_{n}},{{x}_{{uj}}}} \right) = {{q}_{n}}\cos \left( {{{\mu }_{n}}{{x}_{{uj}}}} \right),\quad n = 1,2;\quad {{q}_{n}} = \frac{{2\alpha }}{{(\mu _{n}^{2} + {{\alpha }^{2}} + \alpha ){{{\sin }}^{2}}\mu _{n}^{{}}}},$(5.13)
$\Phi _{u}^{{ - 1}} = {{\left[ {\begin{array}{*{20}{c}} {{{\varphi }_{1}}\left( {{{\mu }_{1}},{{x}_{{u1}}}} \right)}&{{{\varphi }_{2}}\left( {{{\mu }_{2}},{{x}_{{u1}}}} \right)} \\ {{{\varphi }_{1}}\left( {{{\mu }_{1}},{{x}_{{u2}}}} \right)}&{{{\varphi }_{2}}\left( {{{\mu }_{2}},{{x}_{{u2}}}} \right)} \end{array}} \right]}^{{ - 1}}}.$В итоге оптимальное управление $u{\text{*}}\left( {{{Q}_{u}},x,t} \right)$ с обратной связью по неполному измерению управляемой величины находится в форме (4.9) после подстановки (4.8), (5.13) в (4.6) при ${{N}_{1}} = M = 2$. В частности, если ${{x}_{{u1}}} = 1$, ${{x}_{{u2}}} = 0$, то в (5.12), (5.13) будем иметь
На рис. 1, 2 представлены некоторые расчетные результаты, полученные при $Q{\text{**}} = 0.5$; $\alpha = 0.5$; ${{t}_{1}} = 0.2$. На рис. 1 показаны распределения температуры по толщине пластины в конце оптимального процесса нагрева для двух различных значений ${{Q}_{0}}$ (кривая 1 – ${{Q}_{0}} = 0.15$; $\tilde {\psi }_{1}^{*} = 4.58$; $\tilde {\psi }_{2}^{*} = - 13.71$; $\varepsilon _{{\min }}^{{\left( 2 \right)}} = 0.0035$; кривая 2 – ${{Q}_{0}} = 0$; $\tilde {\psi }_{1}^{*} = 5.99$; $\tilde {\psi }_{2}^{*} = - 13.15$; $\varepsilon _{{\min }}^{{\left( 2 \right)}} = 0.003$) при выборе двух измерителей выхода объекта в точках ${{x}_{{u1}}} = 1$, ${{x}_{{u2}}} = 0$. Рисунок 2 иллюстрирует для случая ${{Q}_{0}} = 0$ поведение в процессе нагрева на пространственно-временной плоскости оптимальных управляющих воздействий, изменяющихся во времени по алгоритму (4.9) в зависимости от текущих значений измеряемых сигналов обратной связи с нестационарными коэффициентами передачи.
Рис. 2.
Поведение управляющих воздействий на пространственно-временной плоскости в зависимости от изменяющихся во времени сигналов обратной связи
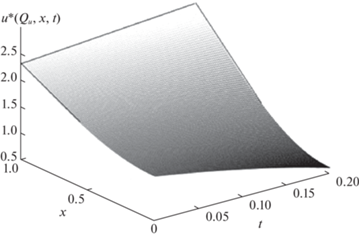
Как следует из приведенных данных, алгоритм (4.9) оптимального управления обеспечивает при различных начальных условиях заданную точность равномерного приближения к требуемому конечному состоянию объекта.
Заключение. Предлагаемые методы решения линейно-квадратичных задач пространственно-временного управления системами с распределенными параметрами параболического типа разработаны применительно к характерным для приложений оценкам целевых множеств конечных состояний объекта в равномерной метрике. Полученные уравнения регуляторов с автономными модальными управлениями, не стесняемыми дополнительными ограничениями и с учетом ограничений по условиям технической реализуемости пространственного распределения управляющих воздействий, сводятся к линейным алгоритмам обратной связи по наблюдаемым переменным с фиксируемыми предварительным расчетом нестационарными коэффициентами передачи и заданными зависимостями от пространственных аргументов.
Допустимые погрешности реализации предлагаемых алгоритмов обратной связи непосредственно по неполному измерению состояния объекта определяются требованиями к точности описания его модели укороченной системой уравнений для модальных составляющих управляемой величины.
Развиваемый подход к описанию оптимальных программных управлений распространен на задачи неизменяемого во времени пространственного управления, рассматриваемого в качестве искомого проектного решения объекта.
Список литературы
Бутковский А.Г. Методы управления системами с распределенными параметрами. М.: Наука, 1975.
Сиразетдинов Т.К. Оптимизация систем с распределенными параметрами. М.: Наука, 1977.
Егоров А.И., Знаменская Л.Н. Введение в теорию управления системами с распределенными параметрами. СПб.: Лань, 2017.
Рей У. Методы управления технологическими процессами. М.: Мир, 1983.
Рапопорт Э.Я. Оптимальное управление системами с распределенными параметрами. М.: Высш. шк., 2009.
Бутковский А.Г., Пустыльников Л.М. Теория подвижного управления системами с распределенными параметрами. М.: Наука, 1980.
Чубаров Е.П. Управление системами с подвижными источниками воздействия. М.: Энергоатомиздат, 1985.
Кубышкин В.А., Финягина В.И. Подвижное управление в системах с распределенными параметрами. М.: СИНТЕГ, 2005.
Рапопорт Э.Я. Альтернансный метод в прикладных задачах оптимизации. М.: Наука, 2000.
Рапопорт Э.Я. Оптимизация процессов индукционного нагрева металла. М.: Металлургия, 1993.
Рапопорт Э.Я. Аналитическое конструирование оптимальных регуляторов в линейно-квадратичных задачах управления системами с распределенными параметрами при равномерных оценках целевых множеств // Изв. РАН. ТиСУ. 2021. № 3. С. 23–38.
Плешивцева Ю.Э., Рапопорт Э.Я. Программное управление с минимальным энергопотреблением в системах с распределенными параметрами // Изв. РАН. ТиСУ. 2020. № 4. С. 42–57.
Рапопорт Э.Я. Структурное моделирование объектов и систем управления с распределенными параметрами. М.: Высш. шк., 2003.
Коваль В.А. Спектральный метод анализа и синтеза распределенных управляемых систем. Саратов: Саратовский гос. техн. ун-т, 1997.
Егоров Ю.В. Необходимые условия оптимальности в банаховом пространстве // Мат. сборник (новая серия). 1964. Т. 64 (106). № 1. С. 79–101.
Плешивцева Ю.Э., Рапопорт Э.Я. Метод последовательной параметризации управляющих воздействий в краевых задачах оптимального управления системами с распределенными параметрами // Изв. РАН. ТиСУ. 2009. № 3. С. 22–33.
Рапопорт Э.Я. Анализ и синтез систем автоматического управления с распределенными параметрами. М.: Высш. шк., 2005.
Дополнительные материалы отсутствуют.
Инструменты
Известия РАН. Теория и системы управления